Agent Teams------当子 Agent 开始互相说话
AI Coding 系列第 11 篇 · 多 Agent 编排
上一篇文章我们说清楚了一件事:Sub-agent 是 Claude Code 里唯一一个"执行完即丢弃"的东西------独立上下文窗口,噪声进去,结论出来,主对话永远看不到中间过程。但 Sub-agent 有一个硬约束:子代理只能向主对话汇报,不能互相通信。 这篇文章讲的就是打破这个约束的东西------Agent Teams。
注意 :Agent Teams 是 Claude Code 的实验性功能,默认关闭。需要在
~/.claude/settings.json中设置CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1才能启用。生产环境请谨慎评估------每个 teammate 是独立的 Claude 进程,token 消耗远高于单会话。本文第六节有完整的使用指南,包含常见故障的排查方法。
一、问题在哪:从一次失败的 Bug 排查说起
用户报告三个症状:会话偶尔丢失、API 时快时慢、订单数据偶尔串号。你用三个 Sub-agent 分别调查 session 中间件、数据库连接池、缓存层------三个报告都回来了,结论却让人抓狂:每个单独看都没问题。
但根因不是三个独立的 bug------是级联故障链。订单查询有个 N+1 问题,高峰期吃满了连接池;连接池一满,Redis session 写入开始静默失败;session 一丢,缓存层竞态条件把用户 A 的数据写进了用户 B 的缓存 key。三个调查各自独立,谁也看不到别人的证据链,自然拼不出这条线。
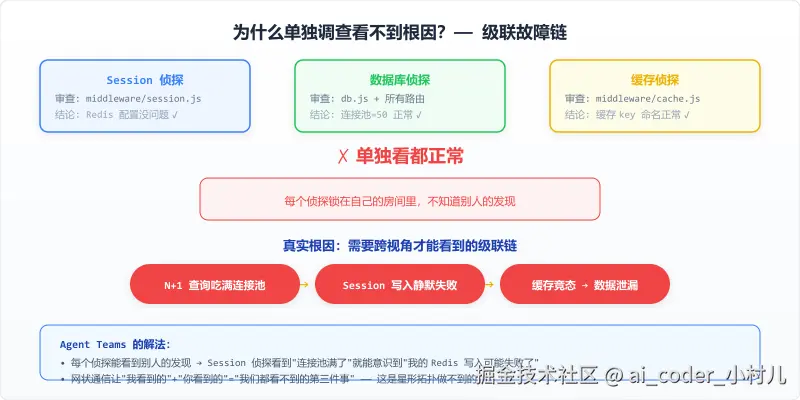
Sub-agent 缺的不是能力,是一个根本性的东西------Agent 之间的通信通道。 这个通道打开之后会发生什么?下一节展开。
二、从通信拓扑到消息落地------Agent Teams 的骨架与血脉
星形 vs 网状
Sub-agent 的通信拓扑是星形:主 Agent 在中间,子代理像卫星绕行,只和中心通信,子代理之间沉默如谜。Agent Teams 的通信拓扑是网状:Team Lead 只是发起人,所有 Teammate 之间可以直接对话------Researcher 发现疑点直接告诉 Implementer,不用绕道 Leader。
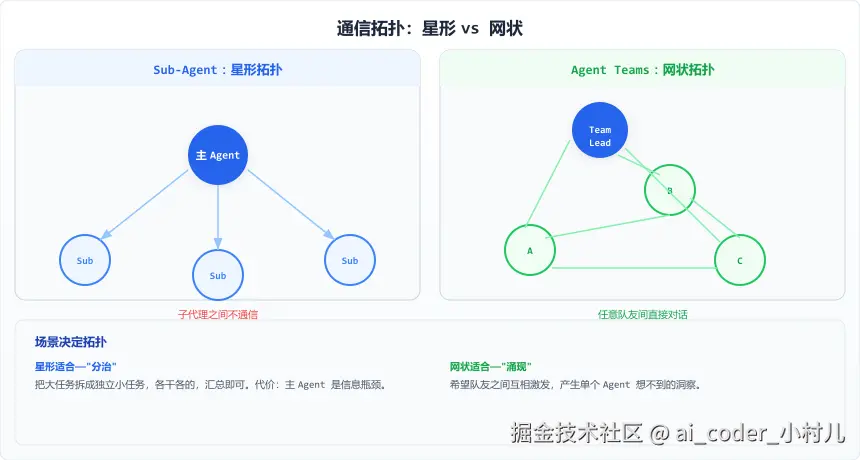
区分这两种拓扑的经验法则:问自己"这些 Workers 需要互相通信吗?"不需要 → Sub-agent。需要 → Agent Teams。
理解了拓扑差异,下一个问题是:这些网状通信具体是怎么落地的?
四种投递路径
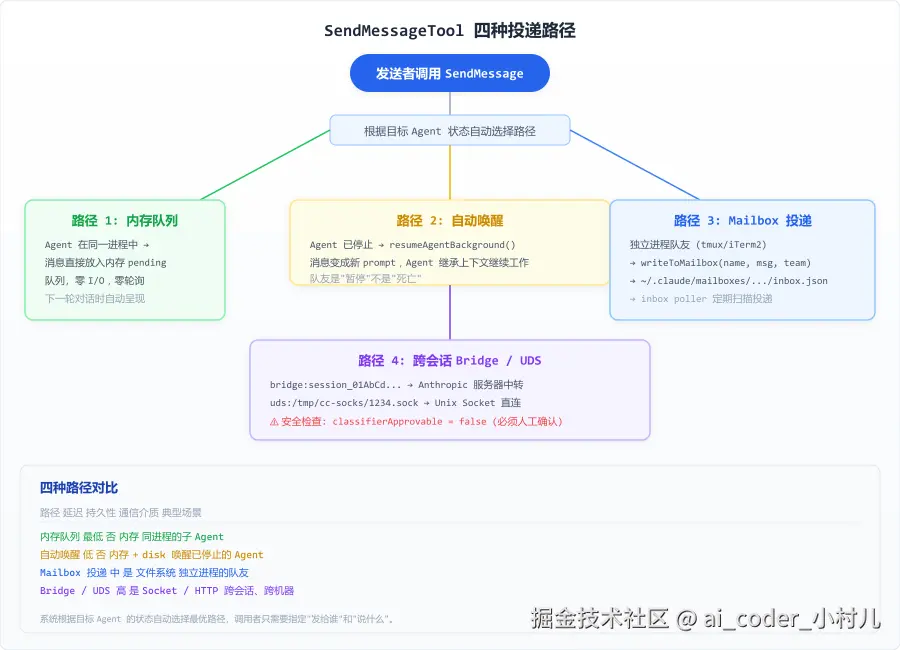
SendMessageTool 是一个看似简单但内部做了四层分支路由的模块------它的核心逻辑判断约 200 行,其余是四条路径的实现细节。当一个 Agent 调用 SendMessage 时,系统根据接收者当前状态自动选择最优路径:
- 同进程活跃 → 内存队列。 消息直接追加到 pending 队列,零磁盘 I/O,下一轮对话自然呈现。
- 已停止 → 自动唤醒。 不只投递,还调用
resumeAgentBackground恢复 Agent。消息变成新 prompt,Agent 继承上下文继续干活。 - 独立 tmux 面板 → Mailbox 文件投递。 消息写入
~/.claude/mailboxes/{team-name}/{agent-name}/inbox.json,接收方 inbox poller 定期扫描。 - 跨机器 → Bridge/UDS。 走 Anthropic 服务器中转或 Unix Socket 直连。硬编码安全约束:
classifierApprovable: false,跨机器消息永不自动通过。
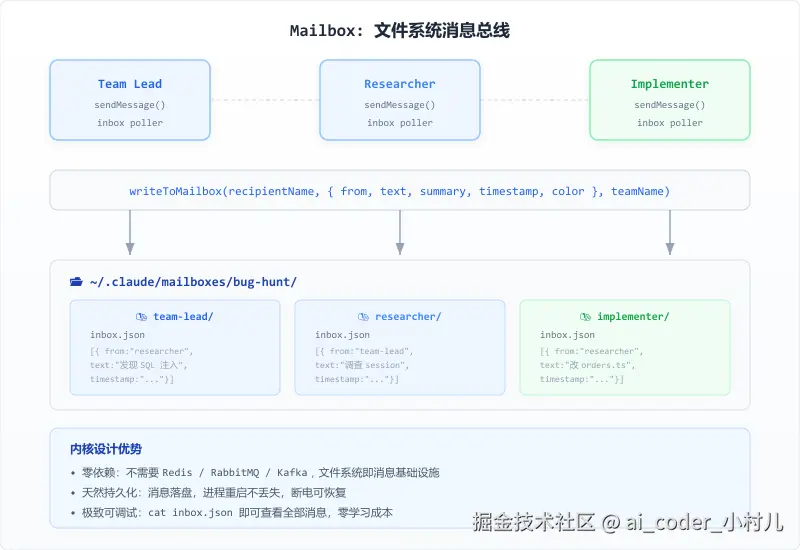
Mailbox:用文件系统做消息总线
Mailbox 是消息系统中设计密度最高的组件------它用文件系统替代了消息队列。不需要 Redis、不需要 RabbitMQ。文件系统自带分布式系统里最难解决的三个属性:天然并发写入(操作系统管)、天然持久化(不删就在)、天然可调试(cat 就能看)。对于 Agent Teams 这种团队规模最多几十人的实验性功能,引入消息中间件是过度设计。
广播实现同样克制------遍历 config.json 成员列表,跳过自己,逐个写邮箱。没有 pub-sub,没有 fanout。设计者判断广播是低频操作,"为低频操作保持简单"本身就是一个有效的工程决策。
消息怎么流转的讲完了。但通信的前提是------团队本身得先"存在"。这个"存在"在代码和磁盘上究竟长什么样?
三、团队是建在磁盘上的
Agent Teams 在源码里是通过 TeamCreateTool 创建的。但理解它的最好方式不是读工具调用流程,而是看它最终在磁盘上留下的东西:
bash
~/.claude/
├── teams/{team-name}/
│ └── config.json ← 团队的花名册
├── tasks/{team-name}/ ← 共享任务列表
└── mailboxes/{team-name}/ ← 消息邮箱
├── team-lead/inbox.json
├── researcher/inbox.json
└── implementer/inbox.jsonconfig.json 是整个团队的共享真相来源。打开它能看到:团队名、创建者、每个队员的名字/ID/模型/工作目录、谁正在干活(isActive)、Leader 批了哪些免审批路径(teamAllowedPaths)。
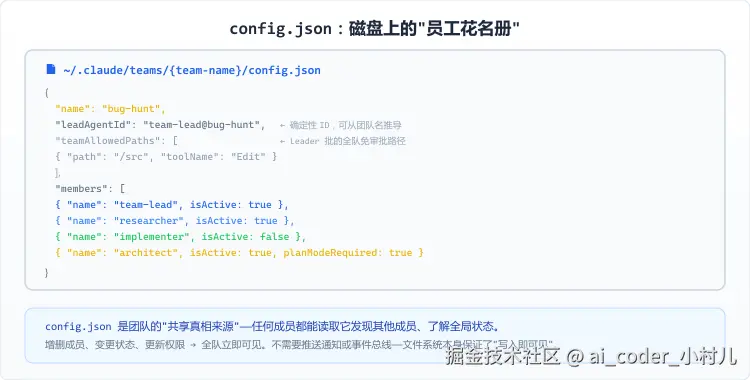
几个值得关注的源码设计:
Leader 的 ID 是确定性的。 格式为 team-lead@团队名,不是随机 UUID。知道团队名就能推导出 Leader 的身份,不需要中心化注册表或服务发现。
Leader 刻意不是"teammate"。 源码里 isTeammate() 对 Leader 返回 false------Leader 不用轮询邮箱、不用响应关机请求、不用在停止时发空闲通知。代码层面做了角色隔离。
一个 Leader 只能管一个团队。 不是技术做不到,是刻意为之的约束------每个会话只有一个 teamContext,多团队会导致消息路由状态爆炸。
团队建好了,消息能流转了。但一个团队不可能永远活着------怎么优雅地结束它?
四、优雅关闭:关机是一个协议握手
Agent Teams 的关闭不是 kill------是一个两阶段提交协议。
第一阶段:请求。 Leader 判断任务完成后,给每个 Teammate 发 shutdown_request,附带唯一 requestId。
第二阶段:响应。 队友收到后有两个选择:
- 批准------发
shutdown_response(approve: true)。in-process 模式下 abort 自己的 AbortController,tmux 模式下调用gracefulShutdown(0)(退出码 0 表示正常主动退出)。 - 拒绝------必须附带理由。源码里明确校验:
approve: false但没有reason→ 直接返回错误。没有理由的拒绝是沉默,Leader 无法区分"队友卡住了"和"队友还在干活"。
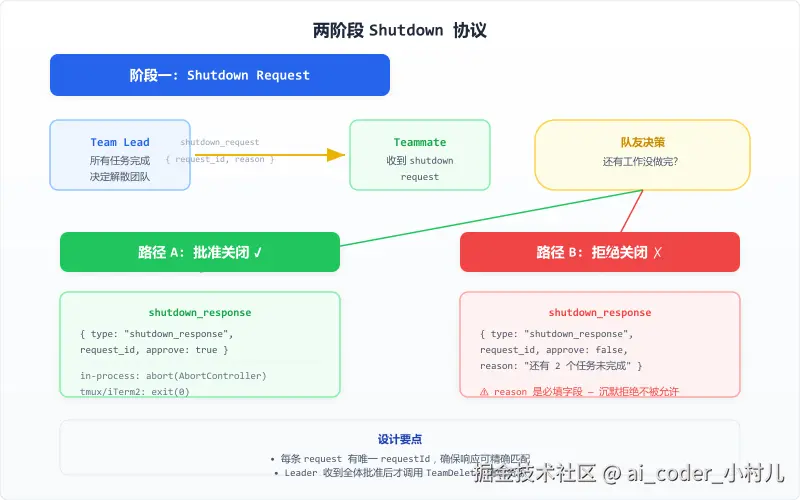
只有所有 Teammate 都批准了,Leader 才调用 TeamDelete 清理资源。有一个人拒绝,Leader 就等。
队友离开时不拖累全局
每个 Teammate 启动时注册一个 Stop Hook。停止时自动做两件事:在 config.json 里把 isActive 标为 false;给 Leader 发一条空闲通知。Hook 有 10 秒超时,执行不阻塞 Stop 流程------一个组件的退出不应该依赖另一个组件的可用性。
协议层面的机制讲完了。现在看这些机制在实际终端里怎么用。
五、在 Claude Code CLI 中实际使用
本节假设你已启用 Agent Teams。如果还没启用,往回翻到文章开头,那里有启用步骤。
启用
在 ~/.claude/settings.json 或项目的 .claude/settings.json 中添加:
json
{ "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1" } }重启 Claude Code。确认生效的方式:终端输入"创建一个 agent team 测试",如果 Claude 回复"Agent Teams 未启用"则说明环境变量没生效,检查 settings.json 路径和 JSON 格式。
创建团队
用自然语言告诉 Claude 建团队,说清楚团队名、几个 teammate、各自负责什么:
创建一个 agent team 帮我调查这个 bug。
1 个 teammate 查 session 层,1 个查数据库层,1 个查缓存层。
每个 teammate 只读分析自己的模块,发现疑点后发消息告诉其他 teammate。
最后 Leader 汇总所有发现,给我一份完整调查结论。Claude 内部生成 TeamCreate 工具调用,然后逐个用 Agent 创建 teammate。你看到的是自然语言交互,看不到底层调用。
观察和管理
bash
# 查看团队状态
哪些队友完成了任务?还有谁在工作中?
# 给特定队友发消息
告诉 researcher 我怀疑 middleware/session.js:42 有竞态条件,让它重点看看
# 给所有队友广播
所有人暂停手上的工作,先汇报目前的发现解散团队
让所有 teammate 汇报最终发现,然后解散团队Leader 逐个发 shutdown_request,等所有人批准后清理目录。如果有人拒绝(带理由,如"还有一个文件没看完"),Leader 等待它完成。
常见故障排查
队友没收到消息。 两步确诊:先看 ~/.claude/mailboxes/{team-name}/{teammate-name}/inbox.json 有没有被写入新的消息条目。有消息但 teammate 没反应 → inbox poller 可能没正常工作,重启 teammate。没有消息 → 检查你发的 teammate 名字是否和 config.json 里的一致。
团队跑一半卡住了。 最常见的原因是异步 teammate 被权限弹窗阻塞。后台 teammate 设了 shouldAvoidPermissionPrompts: true,遇到需要确认的操作会被静默拒绝,Agent 不理解"被拒绝"和"操作失败"的区别,反复重试。解决:给异步 teammate 配 permissionMode: 'dontAsk' 加明确 allowedTools,或者让它在前台运行以便处理弹窗。
解散后残留文件。 正常通过 shutdown 协议解散的团队会自动清理。如果是 Ctrl+C 强制退出 Leader,~/.claude/teams/{team-name}/ 和 ~/.claude/tasks/{team-name}/ 可能残留。手动删除这些目录即可。注意先确认所有 teammate 进程已退出。
四条实战建议
-
给 teammate 充足的上下文。 Teammate 不继承 Leader 的对话历史------它在自己的上下文窗口里从零开始。创建时把需要的信息写进 prompt。
-
避免文件冲突。 两个 teammate 改同一个文件会覆盖。拆分任务时确保各自负责不同的文件集。
-
从只读任务开始。 审查、搜索、调研先跑通,再上改代码的任务。
-
不要让团队跑太久没人管。 发现 Leader 在 teammate 完成前自己就开始下一步时,直接说"等你的 teammate 都完成后再继续"。
六、三种值得注意的设计取舍
为什么 Mailbox 用文件系统而不用消息队列? 消息队列更"专业",但引入外部依赖、需要运维、增加调试难度。文件系统是任何系统的默认基础设施,零运维成本。对于一个实验性功能,这个选择务实而非简陋。
为什么 Leader 能直接写代码而 Coordinator 模式不能? Coordinator 认为管和干要分离。Swarm 的 Team Lead 既是队友又是组织者------管也可以干。两种不同的编排哲学,适用于不同的信任模型。
为什么拒绝关机必须有理由? 在分布式系统里,不可观测的状态是最危险的。沉默拒绝让 Leader 无法判断队友状态。强制理由把每次拒绝变成有效通信。
七、已知限制
Agent Teams 存在以下已知限制,生产环境需要评估:
- 不支持 Agent 嵌套。 Teammate 不能再创建自己的子 Agent。多层编排由 Leader 负责。
- Leader 掉线后 teammates 变孤儿。 如果 Leader 进程被 kill,teammate 进程不会自动退出,且失去协调者。需手动清理。
- 不支持跨团队通信。 一个团队的成员不能给另一个团队的成员发消息。
- Token 成本高。 每个 teammate 是独立的 Claude 进程,有独立上下文窗口。多 teammate 场景的 token 消耗是单会话的数倍。
- 是实验性功能。 API 和行为可能在后续版本中变化。
本讲小结
Agent Teams 的核心设计哲学:
- 通信拓扑决定协作上限。 星形适合分治,网状适合涌现。
- 简单基础设施胜过复杂中间件。 Mailbox 用文件系统------判断是"这对当前规模已经足够好"。
- 优雅关闭是分布式系统的试金石。 两阶段协议、拒绝必须有理由、超时不阻塞退出。
| 核心机制 | 一句话理解 |
|---|---|
| 团队创建 | config.json 是磁盘上的"员工花名册" |
| 消息路由 | 根据目标状态自动选最快投递方式 |
| Mailbox | 用文件系统做消息总线 |
| Shutdown 协议 | 两阶段握手,拒绝必须有理由 |
| Stop Hook | 队友退出时自动通知 Leader |
思考题
-
你的项目中是否有"独立调查各模块都正常,合在一起才暴露根因"的级联故障?Agent Teams 的网状通信能带来什么 Sub-agent 做不到的排查效果?
-
Mailbox 用文件系统做消息存储,如果有 10+ 个 teammate 同时给 Leader 发消息,潜在的并发问题是什么?你有什么防护思路?
-
如果把 Agent Teams 的两阶段 shutdown 协议和数据库事务的两阶段提交做对比,它们在"一致性"上的要求有什么本质不同?
本篇实践任务
任务 1:跑一次多视角排查。 找一个有三个以上模块的项目,创建一个 3 人 Agent Team 做代码质量审查。一个查安全,一个查性能,一个查可维护性。对比:如果只用三个 Sub-agent 并行审查,结果有什么不同?
任务 2:测试 shutdown 拒绝机制。 在排查过程中,当 Leader 要解散时,手工给某个 teammate 追加任务,观察它是否会拒绝 shutdown。如果拒绝------它附带理由了吗?Leader 等了多久?
任务 3:对比 token 成本。 同一个中等复杂度任务,分别用 Agent Teams 和 Sub-agent 模式各跑一次。记录 token 消耗,计算倍数。这个倍数在你的场景里值得吗?
下篇预告
第 11 篇:MCP 实战------什么时候该用,什么时候不该用
Agent Teams 讲完,多 Agent 编排主题就完整了。下一篇换赛道------MCP。Anthropic 最近的态度变了:能用 CLI 直接解决的,不一定要走 MCP。理解这个转变背后的工程原因,比学怎么配置 MCP server 更重要。下篇拆解。
AI Coding 系列持续更新。Agent Teams 不是让 AI 做更多事,是让 AI 之间能互相说话------这个通信通道打开之后,能做的事比 Sub-agent 多一个维度。