近期,OpenBMB 团队发布了最新的 VoxCPM2 模型,该模型拥有 2B 参数,支持语音克隆、语音设计和高质量的语音合成,支持英文、中文、日语、韩语、德语、法语等 30 种主流语言。
VoxCPM2 特点
- 支持 30 种语言,无需语言标签,可直接输入支持的任何语言文本
- 支持语音设计,输入自然语言描述,无需参考音频,即可生成新的语音
- 支持语音克隆,可添加风格引导,以控制情感、语速和表现力
- 支持生成 48kHZ 高质量音频
- 完全开源且允许商业使用
由于 VoxCPM2 拥有上述多个核心特点,你可以把它作为 ElevenLabs 的开源替代品。即你可以在本地部署 VoxCPM2 模型,从而减少 TTS 合成的成本。如果你想找其它商业软件的替代品,你可以使用 BestAlternative.dev 网站,该网站收录了几百个主流付费软件的开源替代方案。
VoxCPM2 架构
VoxCPM 采用了一种无分词器、扩散自回归架构,能够在连续的潜在空间中对语音进行建模,而非使用离散的语音单元。
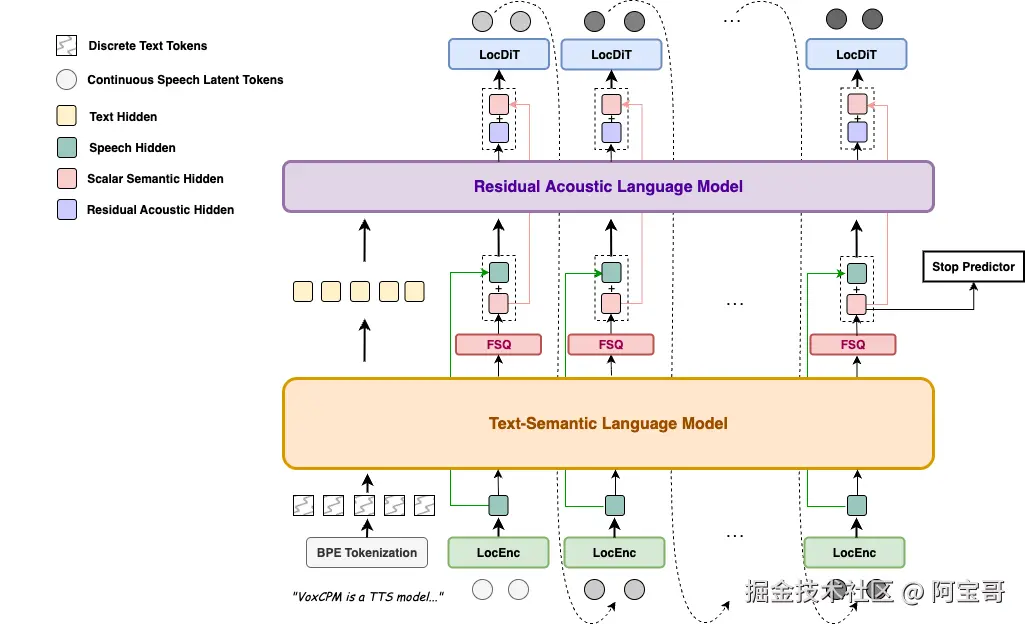
本地部署
VoxCPM2 官方文档已经详细介绍了如何基于 PyTorch 和 CUDA 运行 VoxCPM2 模型,接下来我将介绍在 macOS 下,使用 mlx-audio 在本地部署 VoxCPM2 模型。
1.配置虚拟环境
shell
uv venv .venv
source .venv/bin/activate- 安装 mlx-audio 和 soundfile
shell
uv pip install "git+https://github.com/Blaizzy/mlx-audio" --prerelease=allow
uv pip install soundfile- 下载模型
你可以根据电脑的配置和实际的需求,下载对应的量化模型。
shell
hf download mlx-community/VoxCPM2-4bit --local-dir ./models/VoxCPM2-4bit
# or
hf download mlx-community/VoxCPM2-8bit --local-dir ./models/VoxCPM2-8bit
# or
hf download mlx-community/VoxCPM2-bf16 --local-dir ./models/VoxCPM2-bf16- Zero-shot Generation
python
import numpy as np
from mlx_audio.tts.utils import load
from mlx_audio.audio_io import write as audio_write
MODEL_DIR = "models/VoxCPM2-8bit"
OUTPUT_PATH = "zero_shot.wav"
model = load(MODEL_DIR)
result = next(model.generate("Hello, this is VoxCPM2 on Apple Silicon."))
audio_mx = result.audio
audio_write(
str(OUTPUT_PATH),
np.array(audio_mx),
model.sample_rate,
format="wav",
)需要注意的是,如果待合成的文本中包含括号,需要进行转译处理,不然无法正常合成语音。
- Voice Design
python
import numpy as np
from mlx_audio.tts.utils import load
from mlx_audio.audio_io import write as audio_write
MODEL_DIR = "models/VoxCPM2-8bit"
OUTPUT_PATH = "voice_design.wav"
model = load(MODEL_DIR)
result = next(model.generate(
text="Hello, welcome to VoxCPM2.",
instruct="A young woman, warm and gentle voice",
))
audio_mx = result.audio
audio_write(
str(OUTPUT_PATH),
np.array(audio_mx),
model.sample_rate,
format="wav",
)- Voice Cloning
python
import numpy as np
from mlx_audio.tts.utils import load
from mlx_audio.audio_io import write as audio_write
MODEL_DIR = "models/VoxCPM2-8bit"
OUTPUT_PATH = "voice_cloning.wav"
model = load(MODEL_DIR)
result = next(model.generate(
text="Hello, this is VoxCPM2 on Apple Silicon.",
ref_audio="lisa.wav",
))
audio_mx = result.audio
audio_write(
str(OUTPUT_PATH),
np.array(audio_mx),
model.sample_rate,
format="wav",
)- Ultimate Cloning
针对制作有声读物等长篇内容的场景,为了保证一致性,你需要同时提供参考音频和对应的转录文本。
python
import numpy as np
from mlx_audio.tts.utils import load
from mlx_audio.audio_io import write as audio_write
MODEL_DIR = "models/VoxCPM2-8bit"
OUTPUT_PATH = "ultimate_cloning.wav"
model = load(MODEL_DIR)
result = next(model.generate(
text="2B-parameter multilingual tokenizer-free TTS model with 48kHz studio-quality output. Supports zero-shot generation, voice design, voice cloning, and continuation for long-form speech. 30 languages including English, Chinese, Indonesian, Japanese, Korean, and more.",
prompt_text="VoxCPM2 is a tokenizer-free, diffusion autoregressive Text-to-Speech model",
prompt_audio="lisa.wav",
))
audio_mx = result.audio
audio_write(
str(OUTPUT_PATH),
np.array(audio_mx),
model.sample_rate,
format="wav",
)总结
VoxCPM2 是一个功能强大的 TTS 模型,如果你有语音合成的需求,可以实际评估一下它的功能。如果它不能满足你的需求,你可以再测试一下 Qwen3-TTS,它提供 0.6B 和 1.7B 两种尺寸,支持英文、中文、日语、韩语、德语、法语等 10 种主流语言,也同样支持语音合成、语音设计和语音克隆,只是需要切换不同的模型。