很多团队做 Flink,都会经历一个很相似的阶段。
一开始,事情其实很顺利。
SQL 能提交,JAR 能发布,任务能启动、停止,出了问题能看日志,有告警,能打 Savepoint。平台从脚本和命令行,变成了一个"像样的系统"。
大家都会有一种感觉:差不多了,可以往生产推了。
但真正到生产环境,事情往往从这里开始变得不一样。
- MySQL / Oracle 说好的整库同步,隔三差五的挂,如何破局?
- 数据同步完了,如何确保一致性?怎么验证?
- Kafka 里几百个 topic,每个 topic 里的 json 大几十个字段,手动建表?
- Paimon 接进来了,表上小文件如何合并,何时过期,湖格式如何治理?
- 任务显示 RUNNING,但 checkpoint 在失败、延迟在升高,这算不算正常?
......
这些问题,不会在 demo 里出现。
但只要系统开始承接真实业务,就一定会出现,而且往往是同时出现。
驾驭 Flink 真正难的,从来不是 "把作业跑起来",而是把一整条数据链路,在生产环境里长期跑稳定。
这些年在客户现场反复被追问的问题,我们把它们一个一个拆开来讲 (限于篇幅,仅作代表性介绍)。
01. 普遍存在的痛点
01. 数据资产入口失控
实时湖仓里的 Catalog,本质是"统一元数据入口"。它把外部数据源、消息流、数仓表、湖表,用 Flink SQL 可以理解的方式组织起来,让数据资产可以被发现、描述、查询和复用。
没有平台级 Catalog,实时数据平台就缺少统一的元数据控制面。每个任务都在重新定义数据资产,每个团队都在维护连接、DDL、字段类型和表结构。短期只是多写几段 SQL,时间一长就会变成元数据漂移、口径不一致、重复建表、调试困难和治理失控。
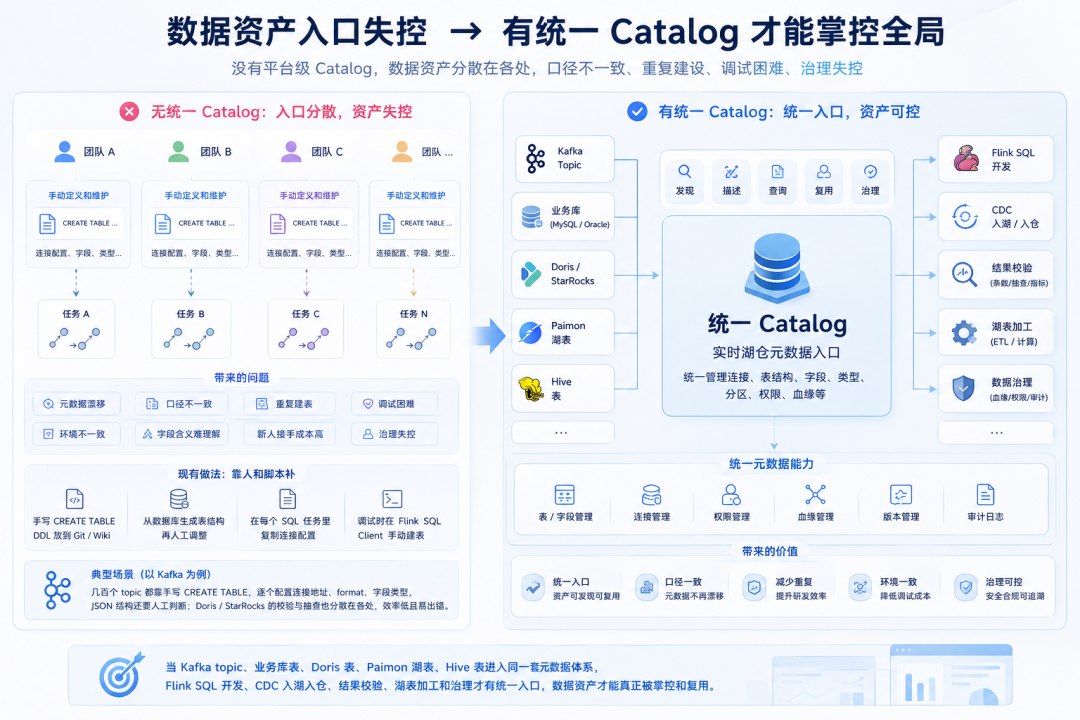
现有做法通常是靠人和脚本补:手写 CREATE TABLE,把 DDL 放到 Git 或 Wiki;从数据库生成表结构;在每个 SQL 任务里复制连接配置;调试时再去 Flink SQL Client 里手动建一遍表。早期能撑住,规模一上来,同一张表在多个任务里有多份 DDL,调试环境和提交环境各有一套表定义,新人接手链路要先翻 SQL、查 Wiki、问字段含义。
Kafka 是最容易感知的例子。几百个 topic 如果都靠手写 CREATE TABLE,每个 topic 都要配置连接地址、format、字段类型,JSON 结构还要人工判断。Doris / StarRocks 也一样,同步完成后的条数校验、明细抽查、指标验证会散落在客户端、SQL Client、脚本和平台页面之间。
到了实时湖仓层面,Catalog 的作用会进一步放大。Kafka topic、业务库表、Doris 表、Paimon 湖表、Hive 表进入同一套元数据体系后,Flink SQL 开发、CDC 入湖入仓、结果校验、湖表加工和治理才有统一入口。
02.CDC 跑通 demo,生产里仍然不敢放手
Flink CDC 已经提供了很好的开源基础。MySQL、Oracle、PostgreSQL 等 source,加上 Doris、Paimon、Kafka、StarRocks 等 sink,可以搭出很多实时同步链路。
企业现场的 CDC 难点,往往出现在 demo 之后,主要有两类。
第一类,是 CDC 链路本身的稳定性很难保障。CDC 要先做历史快照,再接增量日志;要理解上游类型、主键、日志位点、schema 变化;还要把变化转换成下游能接受的写入格式。链路越长,一个细节出问题,最后基本会表现为 "数据没同步" "类型不对" "任务恢复后 schema 对不上"。
比如上游新增字段,下游能不能自动跟上;字段类型映射是否准确;运行中的 CDC 作业加入计算列或调整投影后,从 checkpoint 恢复还能不能一致;schema 自适应是否稳定;字段大小写是否会导致写入失败;Oracle 无主键表能不能稳定同步。这些问题在 demo 里很难暴露,到了几十张、几百张表持续同步的生产环境,才会变成长期稳定性的考验。
第二类,是 CDC 作业缺少可用的平台工具。很多团队作业定义靠 YAML,提交靠命令行,状态看 Flink UI,checkpoint 去集群里找,失败原因查日志,数据是否同步成功再切到 Doris 或 Paimon 里验证。工具都能用,但没有形成统一的 CDC 开发和运维平台。
这会带来几个现实问题:YAML 参数靠人记,写错缩进或字段名要提交后才发现;多库多表规则越写越复杂,没人敢轻易改;作业运行状态和业务同步状态没有统一视图;checkpoint / savepoint 是否可靠,需要人工判断;数据未同步时,开发、运维、DBA 要在多个工具之间排查。
03.Flink SQL 开发调试割裂
做过实时开发的人都知道,整个过程中,最耗费时间和精力的是在开发调试 SQL 上:跑一下、看结果、改一下、再跑。字段类型、join key、窗口水位线、维表 lookup、聚合口径,都要靠不断验证。
现有做法通常有几种:在 IDEA 里嵌 Flink SQL,改一次重启一次;用 Flink SQL Client,手工创建 Catalog、注册表和 UDF;同步到 Doris 后,再切到 Doris 客户端查条数和明细。这些工具都能用,但体验割裂。调试时一个环境,发布时另一个环境;CDC 配置在平台里,验证结果在 Doris 客户端里。
再往深一层看,Flink SQL 查询的最大难点其实是很难做到体验流畅,绝对多数都是磕磕绊绊。一条简单 SQL,背后可能要加载 Kafka、JDBC、Doris、Paimon、Hive、StarRocks 等 connector;要识别 Catalog;要处理 format、UDF、依赖包、ClassLoader、Flink 版本兼容。缺 jar、版本不匹配、Catalog 没识别、connector 初始化失败,用户看到的就是查询跑不起来,或者偶发失败。
开源组件都在,但稳定组合起来并不轻松。很多团队最后形成一套"经验配置":某个 connector 用哪个版本,哪些 jar 放到 lib 目录,哪个 Catalog 要在 SQL Client 里手动创建。这能解决当下问题,却很难支撑多人协作和长期维护。
04. Paimon 接入之后,湖表治理才刚开始
Flink 是实时计算的核心引擎,Paimon 很适合成为 Flink 数据湖的最佳搭档。
原因很直接:Flink 负责持续计算和实时写入,Paimon 负责把变化数据沉淀成湖表。业务库通过 Flink CDC 实时入湖,Flink SQL 继续加工,后续 Spark、Trino、Hive、StarRocks 等引擎读取同一份数据,这是很多团队想要的实时湖仓路径。
Paimon 真正落地后,问题很快会从 "能不能写入湖表",走向 "湖表能不能被持续管理"。
Apache Paimon 提供了很完整的能力:Catalog、主键表、snapshot、tag、branch、time travel、compaction、schema evolution、系统表、各种 Action。单独看都好用,放到企业平台里就会变成治理问题。
首先是 Catalog 管理。Paimon 可以有不同 Catalog 后端、warehouse、文件系统和对象存储参数。HDFS、S3、OSS、OBS、JDBC、REST 环境一多,连接参数、权限、endpoint、warehouse 路径、访问身份就会散落在 SQL、脚本和文档里。
其次是湖表运维。Paimon 表建好后,还会持续产生运维动作:小文件合并、过期 snapshot 清理、tag 保留业务时间点、time travel 回看历史数据、branch 做灰度或修复、系统表定位文件膨胀和写入异常。这些操作如果都靠 SQL Client、命令行、Action jar 和脚本完成,很快会变成少数熟悉 Paimon 的工程师才能维护。
再往深一点,湖格式本身需要一整套治理方案。哪些表需要定期 compaction,哪些 snapshot 可以过期,哪些 tag 要长期保留,哪些分区膨胀异常,哪些表写入延迟升高,权限和审计如何保留,都需要平台层统一管理。Paimon 的关键难点,已经从"Flink 能不能写进去",上升到湖表能不能被集中治理。
05. Flink 作业稳定性保障,远比 "运行中" 复杂
Flink 平台最基础的底盘能力毫无疑问是作业稳定性保障。
很多人第一反应会想到监控指标:checkpoint、背压、延迟、吞吐、TaskManager 重启。这些当然重要,但在它们之前,还有一个更基础的问题:平台显示的作业状态,能不能和真实运行状态一致。
Flink 自身就有十几个状态,不同版本还会有差异。部署在 YARN 上,要叠加 Hadoop YARN 的状态;部署在 Kubernetes 上,又会叠加 Pod、Job、Deployment、Flink Kubernetes Operator 等状态。一个作业从提交到结束,平台看到的可能是 Flink、YARN、K8s、数据库、历史实例状态同时存在。
如果这些状态没有被统一收敛,平台就会出现危险错觉:页面显示 RUNNING,实际作业已经失败;数据库记录还在启动中,YARN 应用已经结束;Pod 重启过几次,平台状态没有更新;用户看到任务正常,数据链路其实已经停止。
这是所有 Flink 平台产品必须守住的基石。状态不准,后面的监控、告警、自动恢复、SLA、故障定位都无从谈起。
状态一致性之外,第二层才是运行健康。作业还在 RUNNING,也不代表链路健康。checkpoint 可能连续失败;TaskManager 可能频繁重启;source 开始堆积;sink 写入变慢;背压和延迟升高。等业务方反馈"数据不对",再去翻日志、查指标,往往已经晚了几个小时。
作业本身的指标和兼容性信号也要暴露出来。不同 connector、Flink 版本、部署模式、资源配置,都会影响稳定性。source 是否持续消费,sink 是否正常写入,checkpoint 耗时是否异常,反压是否集中在某个算子,connector 是否有兼容性 warning,这些信号越早被平台捕捉,越有机会在数据中断前介入。
Flink 作业稳定性保障要同时解决三件事:状态要准,运行要可观测,不稳定信号要尽早暴露。状态决定平台有没有可信事实源,指标决定问题能不能被看见,早期信号决定团队能不能在事故扩大前介入。
02 我们是如何解决的
在聊具体方案之前,先说一点背景。
我们是谁?Apache StreamPark 的创始团队。
Apache StreamPark 做的是流处理开发和作业管理,开源这几年,很多团队用它来管 Flink 和 Spark 作业。这件事我们做了很久,也一直在客户现场和社区里反复看到同一类问题:Catalog 管不起来、CDC 不敢上生产、SQL 开发环境割裂、Paimon 接进来不知道怎么治理、作业状态看不准。
开源能解决一部分。Apache StreamPark 本身的定位,是把作业管好、把开发体验做好。但企业生产环境需要的不止这些。它需要的是一整套方案:Catalog 要统一、CDC 要稳定、SQL 要顺手、湖表要能持续治理、监控要从状态收敛做到早期预警,再加上离线部署、审计、自动恢复这些企业级能力。
这些不是靠单个开源项目能覆盖的,也不是靠社区贡献几个 patch 能补齐的。它需要有人在上面,专门为生产现场做一层完整的、产品化的东西。
所以,基于 StreamPark 多年的技术积累和对 Flink 生态的理解,我们做了 Awestream。
Awestream 完整继承 StreamPark 在 Flink 作业开发、部署和运维上的基础能力,同时围绕 Catalog、Flink CDC、Flink SQL 交互式查询、Paimon 湖仓、全链路监控和企业级交付做了系统增强。
简单说:Apache StreamPark 是流处理开发和作业管理的好底座,Awestream 才是它面向企业实时湖仓生产环境的完整答案。
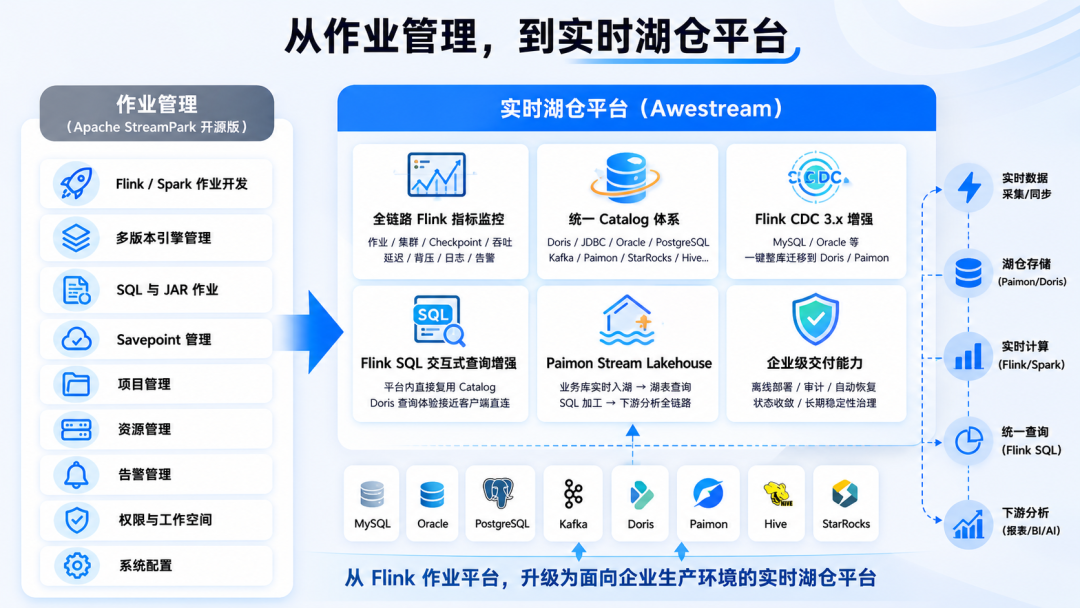
01. Catalog:一次接入,全局复用
Awestream 把 Catalog 放在平台的核心位置,产品层面单独设计了 catalog 管理模块,支持 Kafka、JDBC、Doris、Oracle、PostgreSQL、Paimon、StarRocks、Hive 等数十种数据源和湖仓存储。
以 Kafka Catalog 为例。
过去在 Flink SQL 中使用 Kafka,开发者通常要手写 CREATE TABLE:配置连接地址、topic、format,再把字段一个个写出来。如果有几百个 topic,这件事就会变成几百次重复劳动。
在 Awestream 里,用户创建 Kafka Catalog 时,只需要填写 bootstrap.servers,再配置 topic 纳管规则。规则可以精确匹配某个 topic,也可以按前缀、通配符、模糊匹配或正则方式批量纳管。平台发现 topic 后,会自动把它们映射成 Flink SQL 可使用的表。
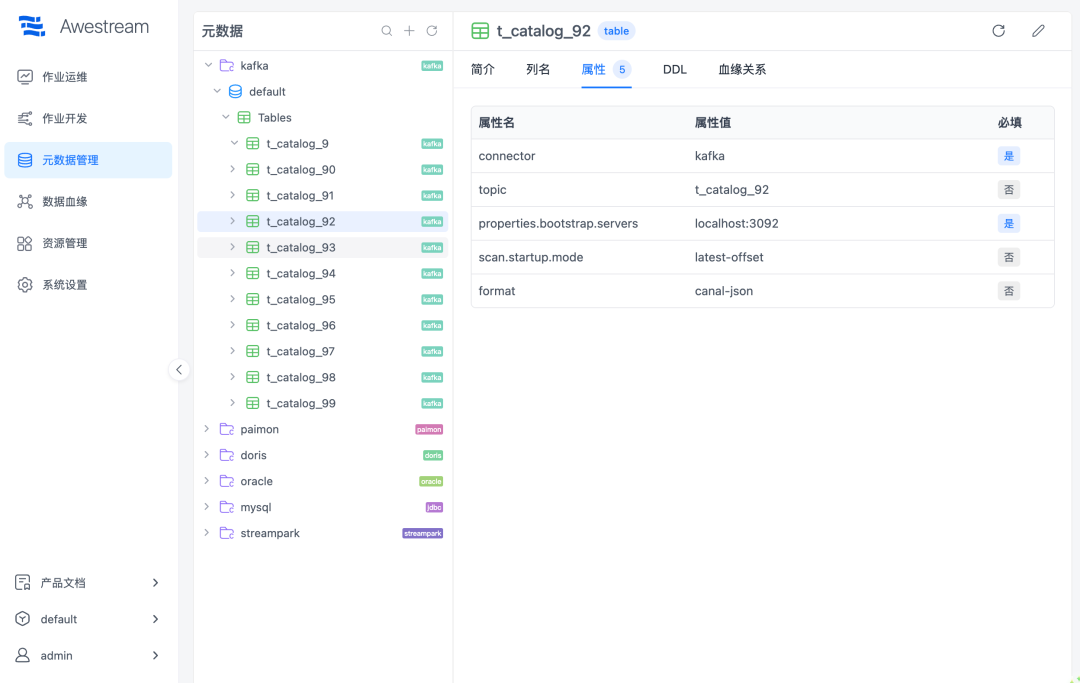
如果 topic 中的数据是 JSON,平台可以采样并解析 JSON 结构,推测字段类型,自动生成表结构。
例如 topic 中写入的是用户积分事件:
{
"user_id":1001,
"user_name":"alice",
"score":98.5,
"event_time":"2026-05-04 10:00:00"
}被 Kafka Catalog 纳管后,平台可以自动映射出类似下面的表:
CREATE TABLE kafka_catalog.default.user_score (
user_id BIGINT,
user_name STRING,
score DECIMAL,
event_time STRING
) WITH (...)后续开发者直接查询即可:
SELECT user_id, user_name, score
FROM kafka_catalog.default.user_score
WHERE score > 90;这个例子放大到几十个、几百个 topic 时,差距会非常明显。开发者不用在每个任务里重复维护 Kafka DDL,平台也能把 topic 统一纳入后续 SQL 开发、查询验证和数据治理。
Doris / StarRocks Catalog 可以用于同步后的条数校验、明细抽查和指标查询。JDBC 类 Catalog 可以接入 MySQL、PostgreSQL、Oracle、Kingbase 等关系型数据库。Paimon / Hive Catalog 可以发现和管理湖表。数据资产进入同一套平台语义后,CDC、SQL 查询、湖仓加工和治理都有了统一入口。
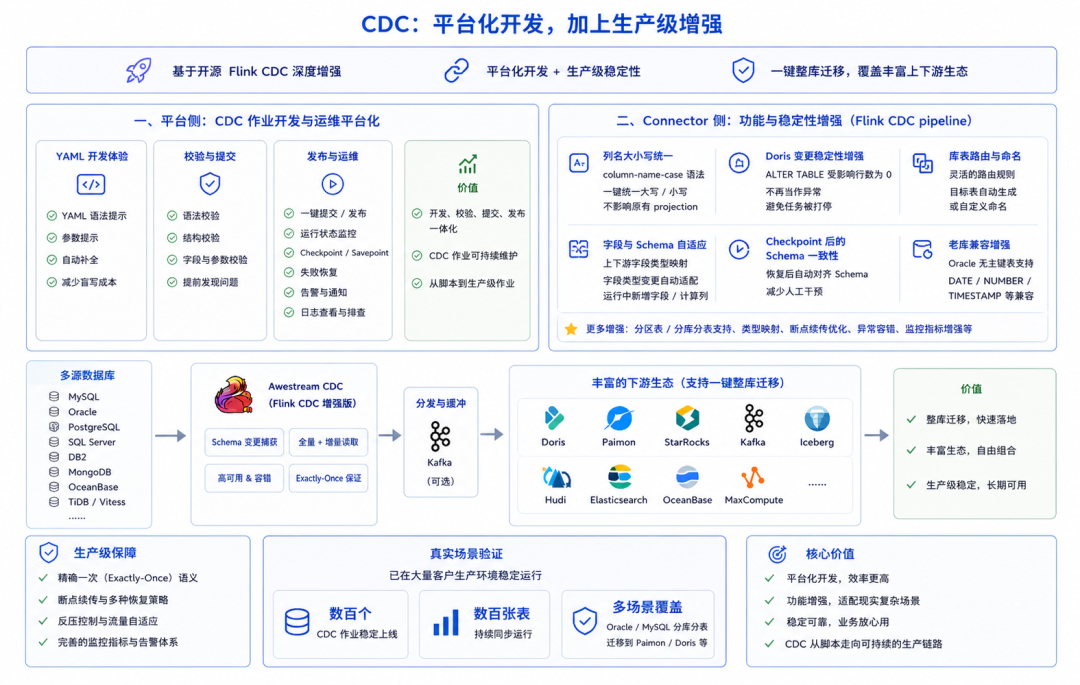
02. Flink CDC:平台化开发,加上生产级增强
Awestream 基于开源 Flink CDC 做了大量增强,支持 MySQL、Oracle 等一键整库迁移到 Doris、Paimon,也可以和 StarRocks、Kafka、Iceberg、Hudi、Elasticsearch、OceanBase、MaxCompute 等下游组合使用。PostgreSQL、SQL Server、DB2、MongoDB、OceanBase、TiDB、Vitess 等 CDC source,也可以纳入同一套链路。
这部分能力正好对应上面两类问题:一类在平台侧,把 CDC 作业开发和运维工具化;一类在 connector 侧,把 CDC 链路的功能和稳定性补强。
第一,平台侧直接支持 Flink CDC YAML 类型作业。
用户可以在平台里编写、保存、校验和提交 CDC YAML。编写过程中,平台提供 YAML 语法提示和参数提示,减少盲写参数的成本;提交前,平台会做语法验证,提前发现缩进、结构、字段名、参数格式等常见问题。
这让 CDC 作业从本地文件和命令行回到平台,开发、校验、提交、发布都在同一个地方完成。任务上线后,平台继续负责运行状态、checkpoint / savepoint、失败恢复、告警和日志排查。对用户来说,CDC 从散落在命令行和配置文件里的同步脚本,变成了可持续维护的生产作业。
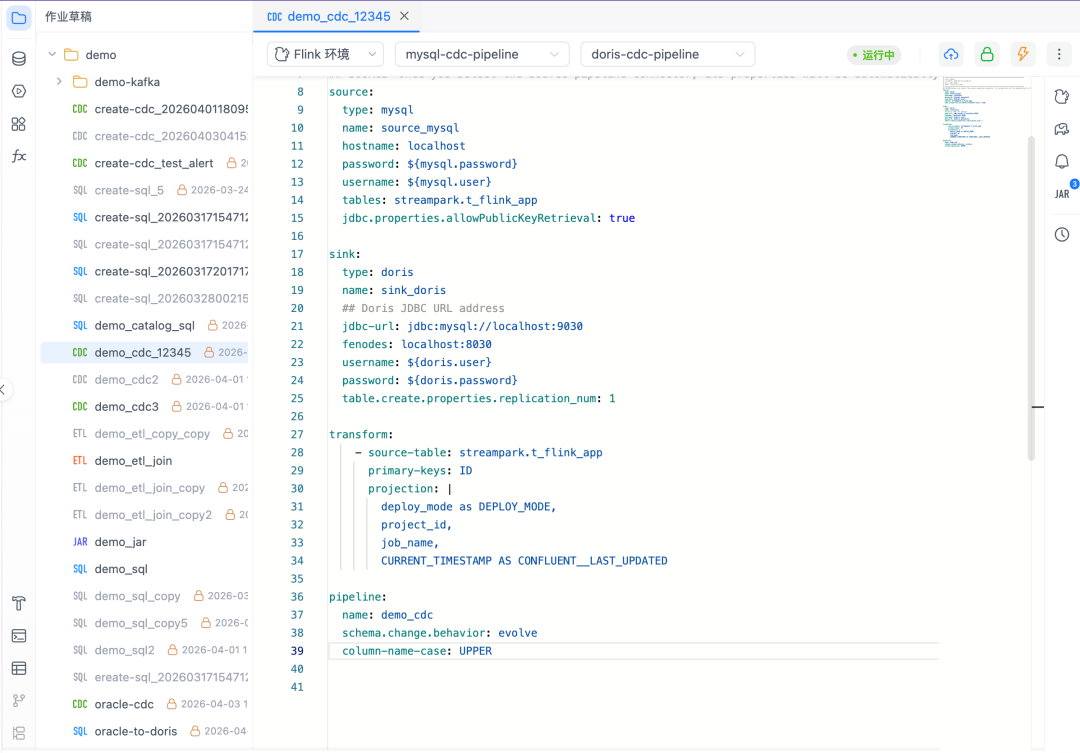
第二,Awestream 在 Flink CDC connector 上做了功能和稳定性增强。
这些增强很多都来自客户的现场反馈。比如在一个客户的项目里,需要把 MySQL 分库分表整库同步到 Doris。源端系统运行多年,各分表结构并不完全统一:同一个字段,有的表是大写,有的表是小写;有些字段类型还有差异;同步过程中还会遇到新增字段、字段类型变化和目标表补列。生产环境很少会按理想规范整整齐齐地摆在那里,CDC 链路必须能适应这些现实。
为了解决字段大小写不一致导致的写入错配,我们和客户一起讨论方案,在 Flink CDC pipeline 中扩展了 column-name-case语法。用户可以在作业层一键将字段统一转为大写或小写,同时不影响原有 projection 逻辑。这样不需要为每张分表单独维护大量字段映射规则,下游 Doris 表也能保持一致的字段口径。
另一个问题出现在 Doris 写入链路。字段类型发生变化后,CDC 会向 Doris 下发 ALTER TABLE 请求,但 Doris 在某些场景下返回受影响条数为 0,原有 connector 会把它当成异常抛出,最终导致同步作业失败。我们沿着链路排查并修复了 Doris connector 的相关处理,让这类字段变更不会轻易把整个 CDC 任务打停。
类似的增强还包括库表路由、目标表命名、上下游字段类型映射、schema 自适应、运行中新增字段和计算列、checkpoint 恢复后的 schema 一致性,以及 Oracle 无主键表、DATE、NUMBER、TIMESTAMP 等老系统常见问题。
这些问题单独看都像细节,到了几十张、几百张表持续同步的生产环境,就会直接影响业务稳定性。实时未来团队多年专精在 Flink 实时计算领域,对 Flink CDC、Doris、Paimon、Kafka、Hive 等生态组件有长期实践和深入理解。团队里既有 Apache StreamPark 创始团队,也有 Flink Committer,遇到这类跨组件、跨版本、跨链路的问题,通常能很快定位根因,并和客户一起把修复方案沉淀成产品能力。目前已有客户从使用 Awestream 开始,稳定上下线并运行几百个 CDC 任务,覆盖 Oracle / MySQL 分库分表迁移到 Paimon / Doris 等场景。CDC 从需要工程师手工守护的同步脚本,变成了可以在平台内持续开发、发布和运维的生产链路。
03. Flink SQL:把 "写、跑、看、改" 放回一个工作台
很多 MySQL 用户熟悉 Navicat 的体验:连接建好,库表就在左侧;点开表能看结构,写一条 SQL 马上出结果;建表、改表、查数、验证数据,都在一个窗口里完成。Awestream 做 Flink SQL 交互式开发,就是冲着这个目标去的,希望把这种顺手的体验带给实时开发者。
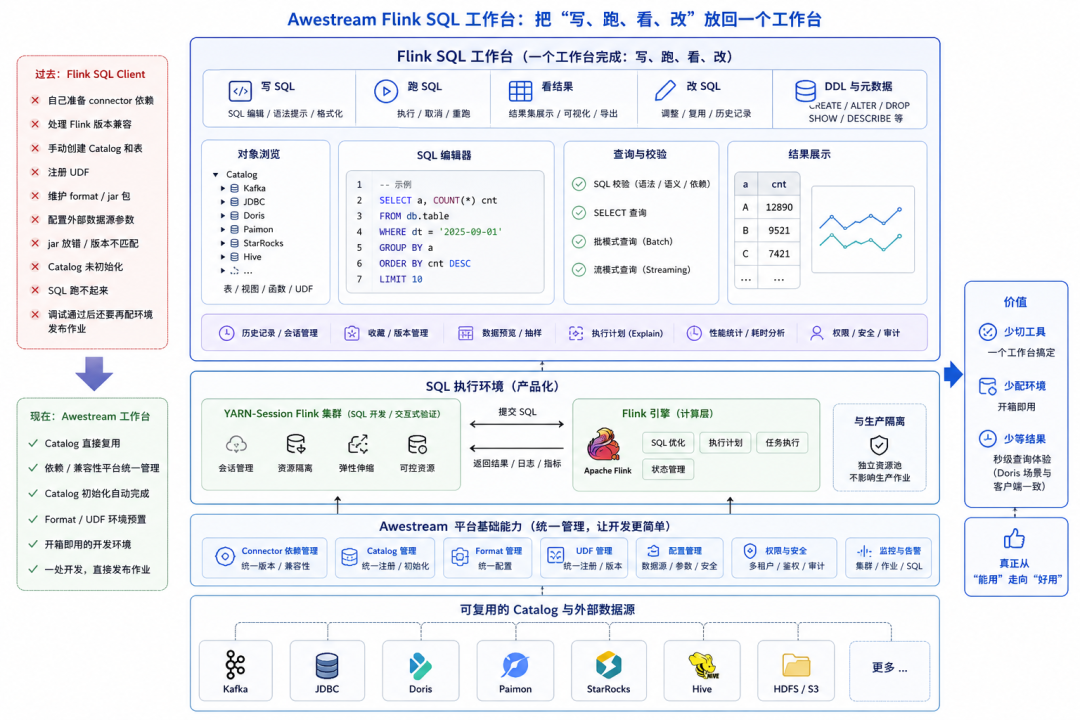
过去使用 Flink SQL Client,能解决问题,但使用成本并不低。开发者要自己准备 connector 依赖,处理 Flink 版本兼容,手动创建 Catalog 和表,注册 UDF,维护 format、jar 包和外部数据源参数。jar 放错、connector 版本不匹配、Catalog 没初始化好,SQL 就可能跑不起来。好不容易在 SQL Client 里调试通过,回到平台发布作业时,还要再配置一遍环境。
Awestream 先把这部分基础工作做掉。平台里的 Kafka、JDBC、Doris、Paimon、StarRocks、Hive 等 Catalog 可以直接复用;connector 依赖、兼容性、Catalog 初始化、format 和 UDF 环境由平台统一管理。用户进入 Flink SQL 工作台时,面对的是一个已经准备好的开发环境,不需要先和依赖、版本、启动参数较劲。
SQL 执行环境也被产品化了。用户可以直接在平台里创建 yarn-session 类型的 Flink 集群,专门用于 SQL 开发查询和交互式验证。调试 SQL 有独立的执行环境,资源可控,也不会和生产作业混在一起。原来"找集群、配命令、起会话"的准备动作,变成了平台上的一次常规操作。
有了这个底座,Flink SQL 才能真正像工作台一样使用。开发者可以直接执行CREATE TABLE、ALTER TABLE、DROP TABLE、SHOW TABLES、SHOW CREATE TABLE、DESCRIBE 等常用 DDL 和元数据语句。表创建成功后会自动保存到对应 Catalog,后续 SQL 开发、查询验证、CDC 校验和湖表加工都能继续复用。
查询同样是完整体验的一部分。Awestream 支持 SQL 校验、SELECT 查询、批模式查询和流模式查询。开发者可以先查几条数据确认字段和类型,也可以验证 join 逻辑、聚合口径、窗口结果,还可以直接查看 Doris、Paimon、JDBC、Kafka 等 Catalog 中的数据。结果出来后马上调整 SQL,再执行一遍,整个 "写、跑、看、改" 的循环保持连续。
我们花了大量精力来打磨查询速度。终于做到了极致的 Flink SQL查询体验,使其速度无限逼近原生客户端。
无论是 MySQL CDC 到 Doris 的 count(*) 全量校验、明细抽查,还是新增字段的条件过滤,现在都无需离开 Awestream。实际验证,Doris/JDBC 模式的查询延迟已与直连客户端 (Doris 查询客户端) 基本持平。对于 Paimon、Kafka 等非 JDBC 数据源,点击查询,SQL 作业秒级提交,在 yarn-session 开发预览集群上瞬时运行。
对 Flink SQL 开发者来说,这种体验带来的价值很直接:少切工具,少配环境,少等结果。建表、看表、改表、查表、验证、批流查询和作业发布都在同一个工作台里完成,Flink SQL 才真正从"能用"走向"好用"。
04. Paimon:让实时数据沉淀为湖仓资产
很多企业已经不满足于把数据从源库同步到目标库。业务库数据通过 Flink CDC 实时进入 Paimon,形成湖仓明细层;再通过 Flink SQL 继续加工,输出到 Doris / StarRocks 支撑分析服务,或者接入 Hive、Trino、Spark 等生态做统一管理。
Awestream 的定位是 Stream Lakehouse 平台,Paimon 是其中很重要的一环。我们对 Paimon 的支持主要放在两个方向:先让湖表接得稳、用得顺,再让湖格式的运维和治理真正进入平台。

第一,是 Paimon Catalog 的完整支持。
Paimon 落地时,Catalog 和存储后端往往是第一道门槛。warehouse 放在哪里,Catalog 后端怎么选,HDFS、S3、OSS、OBS 等对象存储怎么配置,Hadoop 依赖和 Kerberos 权限怎么处理,这些问题如果都交给用户在 SQL、配置文件和集群环境里拼,很容易卡在接入阶段。
Awestream 把这些能力做进平台:用户可以在页面上方便地定义和查看 Paimon Catalog,管理 warehouse、Catalog 后端、文件系统、对象存储、认证参数和访问权限。平台也对 Paimon 与 Hadoop 生态的兼容问题做了适配,包括 Kerberos 权限相关场景。比如有客户需要将 Paimon 数据写入华为云 OBS,平台侧完成了相关存储后端适配后,用户就可以像使用普通湖表一样创建、查看和查询 Paimon 表。
有了 Paimon Catalog,湖表就有了平台级身份,从某个 SQL 脚本里的路径,变成可查看、可引用、可治理的数据资产。开发者可以在平台里查看表定义、字段结构、分区信息和元数据,也可以在 Flink SQL、CDC 入湖、查询验证和后续加工中直接引用这些表。对实时湖仓来说,这一步很关键:湖表先进入统一 Catalog,后续治理才有入口。
第二,是湖格式的运维和治理。
Paimon 表持续写入之后,会自然产生一系列治理动作:小文件需要合并,snapshot 需要管理,tag / branch 要用于保留业务时间点或做灰度,time travel 要能回看历史数据,系统表要能排查文件膨胀、写入异常和元数据问题。这些能力 Paimon 本身已经提供,真正落到企业平台里,关键是让它们变得可操作、可复用、可维护。
Awestream 支持通过 Flink SQL 管理和维护 Paimon 的 tag、branch、snapshot、time travel、系统表和元数据检查。针对一些小表或明确的维护场景,用户可以直接在平台里执行 Paimon SQL 完成 compact,例如:
CALL sys.compact( `table` => 'default.t_paimon_order', order_strategy => 'zorder', order_by => 'car_id');对于更重的湖表运维,平台也提供 Paimon Action 的完整能力,可以通过提交 Jar 任务来执行 compact、snapshot 清理、文件检查等操作。这样一来,Paimon 表从"能写入的数据湖表",进一步变成可以持续查看、维护和治理的湖仓资产。
在实时湖仓链路上,Awestream 将 Flink CDC 入湖、Paimon Catalog 管理、湖表治理、Flink SQL 加工、Doris / StarRocks 服务层输出、平台内 SQL 校验和作业监控串起来。数据进入 Paimon 之后,会继续纳入一套可持续演进的 Streaming Lakehouse 工作流。
05. Flink 作业稳定性:状态收敛、监控告警和自动恢复
Awestream 为 Flink 作业稳定性提供三层保障:
第一层:状态收敛统一判断 Flink、YARN/K8s 及平台作业实例的真实运行状态,避免被旧数据或接口误导。将提交、启动、运行、失败、取消、恢复、结束等过程收敛为一致的状态视图。由此,"运行中""失败"等状态才可信;平台重启后可恢复作业状态,外部 kill 能识别终态,Flink 重启时平台状态不长期滞留。
第二层:运行健康监控全链路监控作业、JM、TM、checkpoint、吞吐、延迟、水位线、背压、重启、资源、日志等指标。集成 Prometheus、Grafana、Alertmanager、Loki,实现采集、日志、告警、看板一体化。
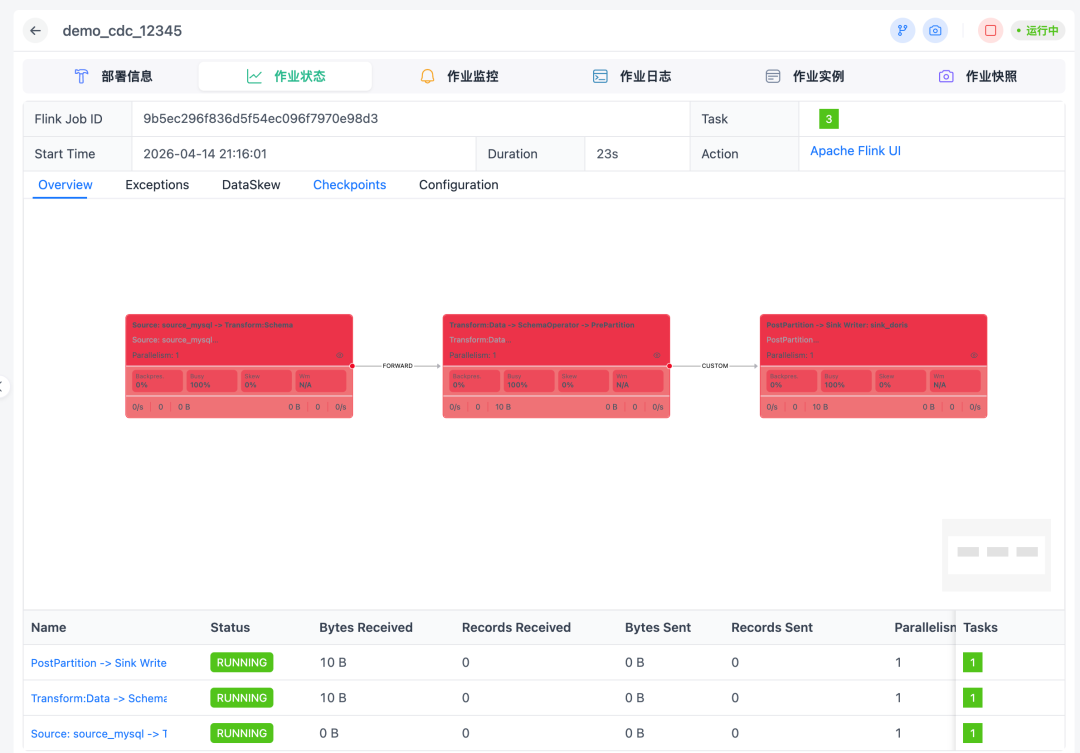
第三层:不稳定信号提前暴露将关键指标、资源状态、checkpoint 质量、重启行为、背压位置、吞吐、connector 异常及兼容性问题暴露到平台视图,让平台感知作业是否变慢、堆积、频繁恢复或即将失败。
状态收敛保真实,指标监控保健康,信号暴露保提前介入。结合 checkpoint/savepoint 恢复、自动重启、告警和日志,使 Flink 作业走向生产稳定。
此外,Awestream 提供商业交付能力:离线部署、审计、自动恢复、平台重启后的状态恢复、长周期资源治理。这对金融、政企、能源、制造等客户,决定产品能否验收和长期使用。
03 写在最后
企业建设实时湖仓,面对的是一整条链路:数据源接入、整库同步、入湖入仓、SQL 开发调试、结果验证、作业发布、监控告警、失败恢复、审计授权和长期运维。
Awestream 就是为这条链路设计的。它基于 Apache StreamPark 的流处理开发和作业管理基础,把统一 Catalog、Flink CDC 整库迁移、Flink SQL 交互式开发、全链路指标监控、Paimon 湖仓支持和企业交付能力,收进同一套平台。
Apache StreamPark 是好底座,开源社区已验证过。但做开源这些年,我们反复看到:企业真正需要的,是把 Catalog、CDC、SQL 开发、湖仓沉淀、生产监控和企业交付串在一起的完整方案。这正是 Awestream 要做的事。
它不是凭空想出来的。它来自一批商业客户真实的生产环境,经过了严苛打磨。走到今天,Awestream 已经成熟、稳定,可以交付。
当前 AI 正在重塑整个技术栈,但无论上层怎么变,实时、准确、可治理的数据底座永远是刚需。AI 时代不是不需要实时湖仓了,而是更需要。
所以我们选择在这个时候把 Awestream 正式推出来。希望它能成为你们在 AI 时代建设实时数据基础设施时,一个靠得住的选择。
如果你正在建设实时数仓、实时湖仓、Flink CDC 入湖入仓,或者评估企业 Flink 平台,欢迎和我们交流。很多坑我们已经在客户现场踩过,也已经在 Awestream 里做成了产品能力。
目前开放免费 PoC 和技术交流通道,你可以直接联系我们安装部署,直接体验 Awestream 的能力。
也欢迎把这篇文章转发给团队里正在"受苦"的同事------ 我们都是从那个时候过来的。

你在用 Flink 时还有哪些痛点?最难受最痛苦的经历是什么?欢迎留言。