
01 VLA策略的瓶颈,世界模型的机会
ArXiv URL:http://arxiv.org/abs/2605.00080v1
当前机器人学习的主流范式------Vision-Language-Action(VLA)策略,试图将感知、语言理解和控制统一到一个端到端模型中。
但一个核心矛盾越来越明显:纯反应式的VLA策略在长时间序列推理、误差累积和物理环境鲁棒性上表现不佳。
问题不仅仅出在动作预测能力不足,更在于缺乏一种显式的预测结构,让模型能够在行动之前预判世界会如何演变。
这正是世界模型(World Model)重新回到舞台中央的原因。来自ETH Zurich、Harvard、Stanford、UC Berkeley、Oxford等机构的研究者联合发布了一篇大规模综述,系统梳理了世界模型在机器人学习中的角色演变------从辅助预测器,到策略的核心组件,再到可控的学习型仿真器。
核心判断:世界模型正在从"想象未来"的辅助工具,演变为机器人决策闭环的基础设施。
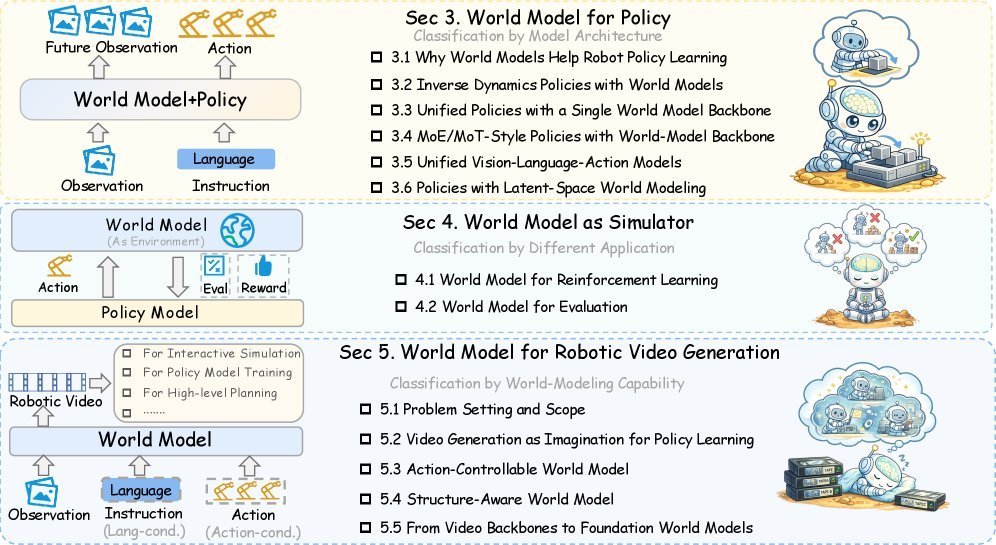
02 什么才算机器人的世界模型
"世界模型"这个词在不同文献里含义差异很大。有人用它指latent dynamics model,有人指视频预测器,有人甚至把大模型内部的隐式预测能力也算进去。
本文综述给出了一个以机器人学习为中心的操作性定义:世界模型是对智能体-环境动态的预测模型,核心形式是状态转移------给定当前状态和动作,预测未来状态序列:
p(xt+1:t+H∣xt,at:t+H−1,l) p(x_{t+1:t+H} \mid x_t, a_{t:t+H-1}, l) p(xt+1:t+H∣xt,at:t+H−1,l)
由于在实际机器人系统中,最常用且最可扩展的"状态"就是视觉观测流,因此综述里讨论的世界模型主要是视觉世界模型,即在图像/视频空间做未来预测。
更关键的是"动作"的概念被拓宽了。低层的电机指令是动作,高层的语言指令也是动作------前者指定"怎么动",后者指定"未来应该变成什么样"。
一个可操作的世界模型需要提供三种核心能力:
-
前瞻:在执行前预判动作后果
-
想象规划:通过想象的rollout比较和筛选行为方案
-
数据放大:合成额外的演示轨迹来增强学习
03 世界模型与策略的四种耦合方式
这篇综述最有结构性的贡献之一,是从架构视角将世界模型与策略的关系划分为清晰的类别。
所有方法的共同出发点是一个联合预测-控制分布:
p(ot+1:t+k,at+1:t+k∣ot,l) p(o_{t+1:t+k}, a_{t+1:t+k} \mid o_t, l) p(ot+1:t+k,at+1:t+k∣ot,l)
从这个分布出发,可以通过不同的边际化得到策略模型、被动世界模型、可控世界模型和逆动力学模型。不同架构的本质区别在于:预测和动作生成之间如何交互。
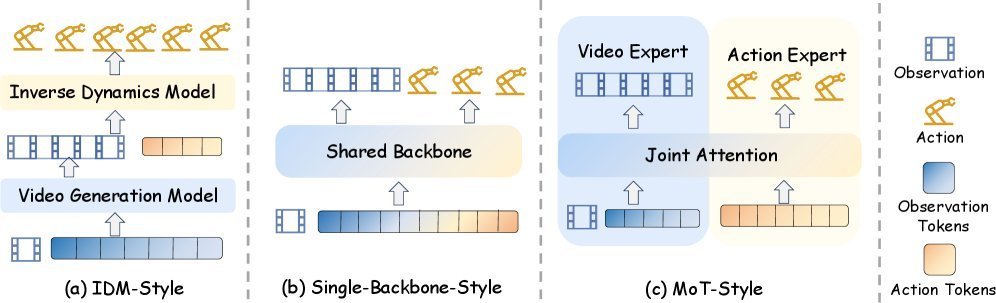
第一类:解耦式逆动力学策略
世界模型先独立生成未来观测序列,然后一个独立的策略模块把预测的未来映射为可执行动作。
模块化带来了可复用性和可解释性,但视觉预测的误差会向下游传播。
第二类:单骨干统一策略
视觉token和动作token在同一个生成骨干中联合处理。
视频生成模型天然具备时序预测的归纳偏置------运动连续性、时序因果性、近似物理动态------这些都是VLM骨干(主要做图文对齐预训练)不容易获得的。
第三类:MoE/MoT风格策略
保留专门的视频预测专家和动作生成专家,通过共享注意力或交叉注意力交互。
动机在于视频预测和动作生成在时间频率、表示尺度和优化需求上差异很大,完全共享参数不一定最优。
这三种范式的演进趋势很清晰:从松散解耦到紧密集成,从先预测再行动到预测与行动在同一生成过程中完成。
04 世界模型作为学习型仿真器
世界模型的另一条演进线路更容易被忽视但同样重要:它们正在成为可控仿真器。
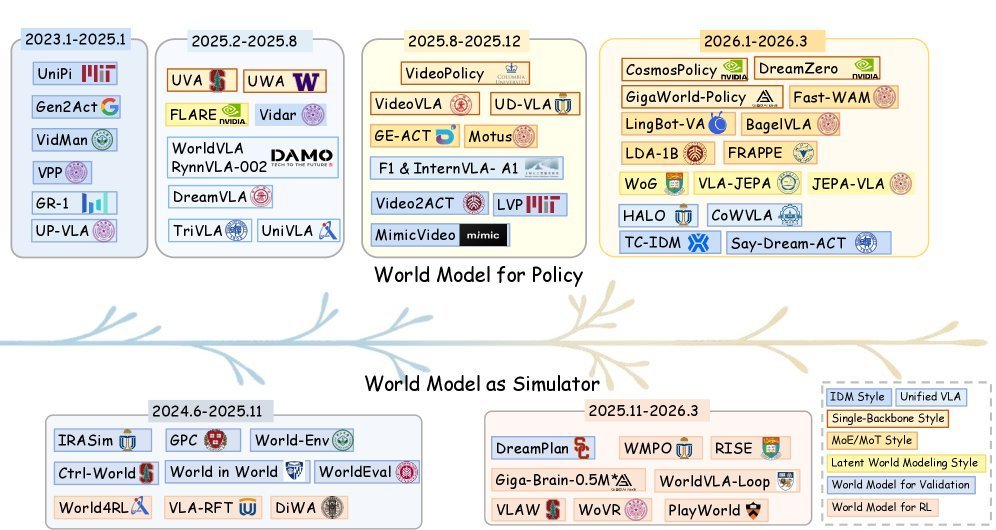
传统的做法是用世界模型做rollout验证------对候选动作序列做想象推演,选择预测结果最好的那个。
新的趋势是把世界模型直接当作强化学习的环境。这意味着什么?策略不再需要在真实物理环境或手工搭建的仿真器中采集数据,而是在世界模型生成的"想象环境"中进行后训练(post-training)。
更激进的方向是策略和世界模型的共演化(co-evolution):策略在世界模型生成的数据上改进,同时策略产生的新轨迹又被用来更新世界模型,形成闭环迭代。
这条路线的关键瓶颈不是生成"看起来合理"的未来,而是生成"与控制一致"的未来。
如果世界模型在关键物理交互上不忠实------比如抓取时的接触力学------策略在想象环境中学到的行为到真实世界就会失败。
05 从视频生成到可控机器人视频
视频生成模型是当前世界模型最主流的实现载体。综述将机器人视频世界模型的发展分为三个阶段。
第一阶段:想象式生成
模型能产出未来视觉序列,但缺乏对动作的精确响应,更多是"给一个语言指令,想象一下大概会怎样"。
第二阶段:可控生成
引入动作条件化,使视频预测能够忠实反映具体的动作序列。
这一步让世界模型真正可用于规划和策略优化。
第三阶段:基础模型规模的结构化生成
借助Wan、Sora等大规模视频基础模型,通过适配(adaptation)将通用视频生成能力迁移到机器人领域,同时加入物理约束、3D结构和多视角一致性。
这个演进的核心挑战在于保真度和可控性之间的权衡。基础模型规模越大,生成的视觉质量越高,但动作条件的精确响应反而更难保证------模型倾向于生成"看起来自然"的视频,而不是"忠实反映该动作"的视频。
06 导航与自动驾驶的世界模型
综述还覆盖了导航和自动驾驶这两个重要的具身智能领域。
在导航场景中,世界模型主要用于预测空间布局和通行性,帮助智能体在未知环境中做规划。
自动驾驶领域对世界模型的需求更为迫切。交通场景中其他参与者的行为高度不确定,纯反应式策略无法处理复杂的博弈和长尾场景。
世界模型在这里的角色既是预测器(预判其他车辆的行为),也是仿真器(生成大量场景用于训练和安全验证)。
两个领域的共同点是:世界模型的价值不仅在于预测准确性本身,更在于预测是否对决策有用。
一个在像素级指标上表现优秀但在关键决策点不忠实的世界模型,实际价值可能很低。
07 评估世界模型有多难
综述系统总结了现有的基准、数据集和评估协议,也揭示了一个根本性问题:目前缺乏统一的评估框架来衡量世界模型对策略性能的实际贡献。
多数工作用视频生成质量指标(FVD、SSIM等)来评价世界模型,但这些指标和下游任务成功率之间的相关性并不稳定。
一个视觉上完美但物理上不一致的预测,在生成指标上得分很高,却可能导致策略灾难性失败。
反之,一个视觉粗糙但动态忠实的预测,可能对策略更有价值。
这意味着世界模型的评估需要从"生成质量"转向"对决策的有用性",但如何量化"有用性"本身就是一个开放问题。
08 边界与展望
回到开头的核心判断:世界模型正在成为机器人学习闭环中的基础设施,而不仅仅是辅助模块。
但本文综述也清楚地展示了当前的边界。视频骨干是否真的比VLM骨干更适合控制,目前还没有定论。解耦式架构和统一式架构谁更实用,取决于具体任务和数据规模。世界模型作为仿真器的可靠性,受限于它在物理交互上的保真度。
这篇综述适合三类读者关注:
正在设计VLA架构的研究者,可以从中获得架构设计的系统参照;做仿真和数据生成的团队,可以了解世界模型作为学习型仿真器的最新进展;以及关注机器人基础模型路线选择的人,可以从中看到预测式和反应式两条路线正在如何融合。