我帮你把HBase笔记 优化精简,保留核心,去掉冗余。让你理解是什么、为什么、怎么用。
📚 HBase 笔记优化版
一、HBase是什么?(一句话)
HBase = 分布式、面向列的 NoSQL 数据库
-
关系型数据库(MySQL):存结构化数据,有固定schema
-
HBase:存半结构化/非结构化数据,列可以动态增加
通俗理解:
text
MySQL:先设计表结构(列固定),再填数据
HBase:先有表,列可以随时加,适合字段经常变的场景二、为什么用HBase?(对比MySQL)
| 维度 | MySQL | HBase |
|---|---|---|
| 数据量 | 亿级就慢 | 百亿级也OK |
| Schema | 固定列,改结构痛苦 | 列动态增加,不用改表 |
| 扩展性 | 垂直扩展(换更好的机器) | 水平扩展(加机器就行) |
| 查询 | 灵活(SQL随便写) | 只能按rowkey查 |
| 事务 | 支持 | 不支持(只有行级) |
结论: 数据量大、列经常变、不需要复杂查询 → 用HBase
三、HBase数据模型(核心概念)
3.1 存储结构对比
text
MySQL:
┌─────┬──────┬─────┐
│ id │ name │ age │
├─────┼──────┼─────┤
│ 1 │ 张三 │ 28 │
└─────┴──────┴─────┘
HBase:
rowkey: 1
└─ info:name = "张三"
└─ info:age = 28
rowkey: 2
└─ info:name = "李四"
└─ info:age = 30
└─ info:gender = "男" ← 动态加的列3.2 核心概念(只记5个)
| 概念 | 类比MySQL | 说明 |
|---|---|---|
| Namespace | Database | 表的分组,自带default和hbase |
| Table | Table | 存数据的表 |
| Rowkey | 主键 | 唯一标识一行,按字典序排序 |
| Column Family | 无 | 列簇 ,必须预先定义(如info) |
| Column Qualifier | 列名 | 列限定符,可动态添加(如name、age) |
| Timestamp | 无 | 时间戳,支持多版本 |
| Cell | 单元格 | 由rowkey+列簇+列限定符+timestamp唯一确定 |
关键理解:
text
HBase存数据格式:
rowkey: 001
└─ info:name = "张三" (timestamp: 1700000000)
└─ info:name = "张小三" (timestamp: 1700000001) ← 同一单元格有多个版本
└─ info:age = "28"四、HBase架构(4个角色)
text
┌─────────────┐
│ Client │
└──────┬──────┘
│
┌──────▼──────┐
│ ZK集群 │ ← 监控、选主、入口
└──────┬──────┘
│
┌──────────┼──────────┐
│ │ │
┌───▼───┐ ┌───▼───┐ ┌───▼───┐
│Master │ │Master │ │ ZK │
│(Active)│ │(Standby)│ │
└───┬───┘ └───────┘ └───────┘
│
┌───▼─────────────────────────┐
│ Region Server │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │Region│ │Region│ │Region│ │
│ └─────┘ └─────┘ └─────┘ │
└─────────────────────────────┘
│
┌────▼────┐
│ HDFS │ ← 最终存储
└─────────┘4.1 四个角色职责(背这个)
| 角色 | 一句话职责 | 类比 |
|---|---|---|
| Region Server | 负责数据的读写(get/put/delete) | 一线员工 |
| Master | 负责表的管理(create/alter/delete) | 部门经理 |
| Zookeeper | 监控Master和RegionServer,存元数据入口 | 监控+电话本 |
| HDFS | 实际存储数据文件 | 文件柜 |
关键点:
-
读写数据不经过Master(直接和Region Server交互)
-
Master挂了不影响读写,只影响表操作
五、启动HBase(完整流程)
5.1 前置条件
bash
# 1. Hadoop必须启动
jps
# 应该看到:NameNode, DataNode, ResourceManager, NodeManager
# 2. Zookeeper必须启动
cd $ZOOKEEPER_HOME
bin/zkServer.sh start
# 验证ZK启动成功
netstat -apn | grep 2181 # 看到LISTEN状态
bin/zkServer.sh status # 看到 standalone 或 leader/follower5.2 清理ZK中的旧HBase信息(重要!)
bash
# 如果之前启动过HBase,需要先清理
zkCli.sh
deleteall /hbase
quit5.3 启动HBase
bash
cd $HBASE_HOME
bin/start-hbase.sh
# 验证启动成功
jps
# 应该看到:
# HMaster
# HRegionServer
# Web界面验证
http://node100:16010六、HBase vs 关系型数据库(面试必问)
| 维度 | 关系型数据库(MySQL) | HBase |
|---|---|---|
| 数据量 | TB级 | PB级 |
| Schema | 固定列,改表要DDL | 列动态添加 |
| 查询 | SQL任意条件 | 只能按rowkey(+过滤器) |
| 事务 | ACID | 只支持行级原子性 |
| 索引 | 支持多种索引 | 只有rowkey索引 |
| 扩展 | 垂直(换机器) | 水平(加机器) |
| 适用 | 业务系统、复杂查询 | 海量数据、简单查询 |
七、面试问答模板
Q1:HBase是什么?
HBase是一个分布式、面向列的NoSQL数据库,基于HDFS存储,适合海量数据、高并发读写场景。
Q2:HBase和MySQL有什么区别?
主要区别:HBase数据量更大(PB级)、列可以动态添加、只能按rowkey查询;MySQL支持复杂SQL、事务、多索引。
Q3:HBase为什么快?
按rowkey字典序存储,查询快
数据直接写MemStore,再刷到HDFS
Region可以分裂,水平扩展
Q4:HBase为什么依赖Zookeeper?
ZK负责:监控RegionServer生死、选主Master、提供元数据入口(知道去哪找数据)
八、启动验证速查表
bash
# 1. 检查Hadoop
jps | grep -E "NameNode|DataNode"
# 2. 检查ZK
zkServer.sh status
# 3. 清理旧数据(首次或出错时)
zkCli.sh <<< "deleteall /hbase"
# 4. 启动HBase
$HBASE_HOME/bin/start-hbase.sh
# 5. 验证
jps | grep -E "HMaster|HRegionServer"
# Web: http://node100:16010📌 总结
text
HBase = 分布式列族数据库
├── 数据模型:Namespace → Table → Rowkey → Column Family → Column
├── 架构:Master(管理) + RegionServer(读写) + ZK(监控) + HDFS(存储)
└── 启动顺序:Hadoop → ZK → 清理 /hbase → HBase记忆口诀:
text
HBase存数据,面向列族来,
Rowkey做主键,列可动态加。
Master管表结构,RegionServer做读写,
ZK负责监控,HDFS最终存。
启动先Hadoop,再启动ZK,
清理/hbase,最后起HBase。不需要精简,老师的笔记已经很精简了,再精简看不懂了。第一天学HBase,之前没接触过。
明白了!既然你是第一天接触HBase ,我把老师的笔记展开解释,用你能理解的方式讲清楚每个概念。
📚 HBase 笔记详解版(第一天友好)
一、HBase是什么?(从MySQL说起)
1.1 你学过的MySQL
sql
-- MySQL要先设计表结构
CREATE TABLE user (
id INT,
name VARCHAR(50),
age INT
);
-- 然后才能插入数据
INSERT INTO user VALUES (1, '张三', 28);MySQL的问题:
-
列是固定的(name、age)
-
如果想加个
gender列,要ALTER TABLE改表结构 -
如果数据量上亿,查询变慢
1.2 HBase的做法
sql
-- HBase建表:只需要声明列簇,不需要具体列
create 'user', 'info'
-- 插入数据:列可以随时加
put 'user', '1', 'info:name', '张三'
put 'user', '1', 'info:age', '28'
put 'user', '1', 'info:gender', '男' -- 新增列,不需要改表结构1.3 一句话总结
| 对比 | MySQL | HBase |
|---|---|---|
| 列是否固定 | 固定,要提前设计 | 动态,随时可以加 |
| 适合数据量 | 千万/亿级 | 百亿/千亿级 |
| 查询方式 | SQL随便查 | 主要靠rowkey查 |
二、NoSQL 是什么意思?
NoSQL = Not Only SQL(不仅仅是SQL)
text
传统数据库:只能存结构化数据(表格形式)
NoSQL数据库:能存结构化、半结构化、非结构化数据
例子:
- 结构化:用户表(id, name, age)
- 半结构化:JSON数据 {name:"张三", age:28}
- 非结构化:图片、视频、日志文本HBase属于: 面向列的NoSQL数据库
三、HBase数据存储逻辑架构(重点理解)
3.1 老师笔记里的这条
{name:zhangsan, age:28}
解释: HBase存数据不是表格形式,而是键值对(KV)形式
text
MySQL视角:
┌─────┬──────────┬─────┐
│ id │ name │ age │
├─────┼──────────┼─────┤
│ 1 │ zhangsan │ 28 │
└─────┴──────────┴─────┘
HBase视角:
rowkey="1" 对应的数据:
"name" → "zhangsan"
"age" → "28"3.2 老师笔记里的"行有行有列"
解释: HBase从逻辑上看,也有行和列,但存储方式是KV
text
逻辑视图(你看着像表格):
┌─────────┬──────────────┬───────────┐
│ rowkey │ info:name │ info:age │
├─────────┼──────────────┼───────────┤
│ 1 │ zhangsan │ 28 │
│ 2 │ lisi │ 30 │
└─────────┴──────────────┴───────────┘
实际存储方式(KV键值对):
rowkey=1, info:name = "zhangsan"
rowkey=1, info:age = "28"
rowkey=2, info:name = "lisi"
rowkey=2, info:age = "30"3.3 老师笔记里的"列簇"
这是HBase最核心的概念!
text
列簇(Column Family)= 列的"分组"
类比理解:
你有一个文件夹(表)
文件夹里有多个分类(列簇)
每个分类下有多个文件(列)
具体例子:
表名:user
列簇1:info(基本信息)
├── name(姓名)
├── age(年龄)
└── gender(性别)
列簇2:contact(联系方式)
├── phone(电话)
├── email(邮箱)
└── address(地址)为什么用列簇?
-
不同列簇可以设置不同属性(如压缩、版本数)
-
不同列簇存储在不同文件,查询时只读需要的列簇
建表时只声明列簇:
bash
# 创建表user,有两个列簇:info 和 contact
create 'user', 'info', 'contact'
# 插入数据时,列可以随便加
put 'user', '1', 'info:name', '张三' # info列簇下的name列
put 'user', '1', 'info:age', '28' # info列簇下的age列
put 'user', '1', 'contact:phone', '13800138000' # contact列簇下的phone列
put 'user', '1', 'contact:email', 'zhang@email.com'四、数据模型(逐条解释)
4.1 Namespace(命名空间)
| 概念 | 类比MySQL | 说明 |
|---|---|---|
| Namespace | Database | 用来分组管理表 |
两个默认的Namespace:
bash
# hbase:系统内置表存放的地方(不要动)
# default:用户默认的命名空间,不指定时存这里
# 例子:在default下建表
create 'user', 'info' # 等同于 create 'default:user', 'info'
# 例子:自定义命名空间
create_namespace 'myapp'
create 'myapp:order', 'info'4.2 Table(表)
-
和MySQL的表类似
-
区别:HBase的表只声明列簇,不声明具体列
bash
# MySQL:CREATE TABLE user (id INT, name VARCHAR, age INT)
# HBase:create 'user', 'info' ← 只声明有个列簇叫info4.3 Row(行)
bash
# 每一行有一个唯一的 rowkey
# rowkey 类似于MySQL的主键
put 'user', 'rowkey_001', 'info:name', '张三'
# ↑
# 这就是rowkey重要特性: rowkey按字典序存储
text
假设有rowkey:1, 10, 100, 2, 20, 200
字典序排序后:1, 10, 100, 2, 20, 200
不是数字顺序!是字符串比较
所以设计rowkey要注意:
- 需要时间排序的,用"20250101_001"格式
- 避免热点,可以用hash分散4.4 Column(列)
text
完整列名 = 列簇:列限定符
例子:
info:name ← 列簇是info,列限定符是name
info:age ← 列簇是info,列限定符是age
contact:phone ← 列簇是contact,列限定符是phone4.5 Timestamp(时间戳)
这个是HBase的特色!
bash
# 同一单元格可以存多个版本
put 'user', '1', 'info:name', '张三' # 版本1(时间戳:1000000)
put 'user', '1', 'info:name', '张小三' # 版本2(时间戳:1000001)
# 查询时,默认返回最新版本
get 'user', '1'
# 返回:info:name = '张小三'
# 可以查询历史版本
get 'user', '1', {COLUMN => 'info:name', VERSIONS => 2}
# 返回两个版本:张小三 和 张三有什么用?
-
记录数据变更历史
-
比如用户修改了地址,可以查历史地址
4.6 Cell(单元格)
text
Cell = rowkey + 列簇 + 列限定符 + timestamp
这四个组合起来,唯一确定一个值
例子:
rowkey='1', info:name, timestamp=1000000 → '张三'
rowkey='1', info:name, timestamp=1000001 → '张小三'
这是两个不同的Cell,存着两个版本的"姓名"五、架构角色(用公司类比)
5.1 四个角色一句话
| 角色 | 一句话 | 公司类比 |
|---|---|---|
| Region Server | 管数据的读写(干活的人) | 一线员工 |
| Master | 管表的创建/删除(不参与读写) | 部门经理 |
| Zookeeper | 监控谁活着谁死了,记录"去哪找数据" | 监控+前台 |
| HDFS | 实际存储数据文件 | 文件柜 |
5.2 详细解释
1. Region Server
-
真正干活的
-
负责
put(写)、get(查)、delete(删) -
一台机器上可以运行多个Region Server
2. Master
-
负责
create(建表)、alter(改表)、delete(删表) -
不参与数据的读写! 所以Master挂了,读写不受影响
-
Master挂了只是不能建表/删表
3. Zookeeper
-
监控Region Server和Master的健康状态
-
记录"元数据入口"(告诉客户端去哪找数据)
-
选主:如果Master挂了,ZK会从备用的选一个出来
4. HDFS
-
HBase本身不存数据,数据最终存在HDFS上
-
HBase只是个"中间层",负责管理数据的索引和缓存
5.3 一次查询的完整流程
text
1. 客户端问ZK:"我要查rowkey=100的数据,找谁?"
2. ZK告诉客户端:"去找Region Server A"
3. 客户端直接连Region Server A查数据
4. Region Server A从自己的MemStore或HDFS读取数据返回
注意:全程不经过Master!六、启动HBase(逐步操作)
6.1 前置条件
bash
# 步骤1:确保Hadoop已启动
jps
# 应该看到:NameNode, DataNode, ResourceManager, NodeManager
# 步骤2:启动Zookeeper
cd $ZOOKEEPER_HOME
bin/zkServer.sh start
# 步骤3:验证Zookeeper启动成功
netstat -apn | grep 2181
# 输出应该有一行包含 LISTEN 状态
bin/zkServer.sh status
# 输出:standalone(单机模式)或 leader/follower(集群模式)6.2 初始化HBase
bash
# 为什么要清理?
# 如果之前启动过HBase,ZK里会有旧数据,需要删掉
# 进入ZK命令行
zkCli.sh
# 删除旧的hbase数据
deleteall /hbase
# 退出
quit6.3 启动HBase
bash
cd $HBASE_HOME
bin/start-hbase.sh
# 等待几秒钟6.4 验证启动
bash
# 方法1:jps看进程
jps
# 应该看到:
# HMaster
# HRegionServer
# 方法2:访问Web界面
# 浏览器打开:http://node100:16010
# 能看到HBase的监控页面,说明启动成功七、你今天需要理解的核心(背这个)
text
┌─────────────────────────────────────────────────────┐
│ HBase核心概念 │
├─────────────────────────────────────────────────────┤
│ 1. NoSQL = Not Only SQL,不止能存表格数据 │
│ 2. 列簇 = 列的"分组",建表时只声明列簇,不声明具体列 │
│ 3. Rowkey = 行键(主键),按字典序排序 │
│ 4. Timestamp = 时间戳,一个单元格可以存多个版本 │
│ 5. Cell = rowkey+列簇+列限定符+timestamp 唯一确定 │
│ 6. Region Server = 负责读写数据 │
│ 7. Master = 负责管理表(建表/删表) │
│ 8. ZK = 监控+元数据入口 │
│ 9. HDFS = 最终存储数据的地方 │
└─────────────────────────────────────────────────────┘八、马上要操作的命令(预习)
启动成功后,你会学到这些:
bash
# 进入HBase命令行
hbase shell
# 建表(只有一个列簇info)
create 'user', 'info'
# 查看所有表
list
# 插入数据
put 'user', '1001', 'info:name', '张三'
put 'user', '1001', 'info:age', '28'
# 查询数据
get 'user', '1001'
# 扫描整张表
scan 'user'
# 删除表(需要先禁用)
disable 'user'
drop 'user'
# 退出
quit列簇还是不太懂
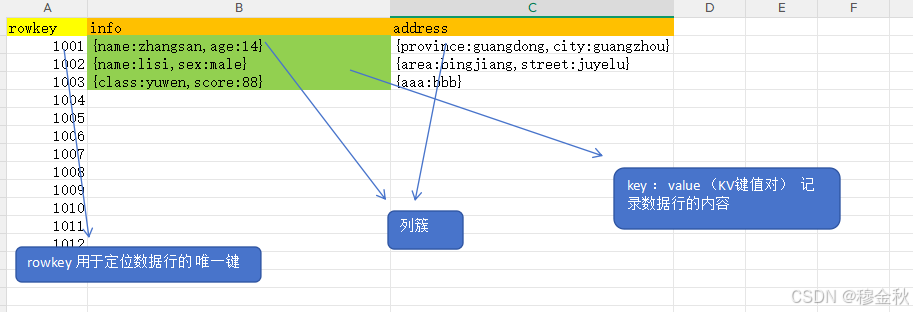
一、先看你这张图(逐行解释)
text
rowkey info address
1001 {name:zhangsan, age:14} {province:guangdong, city:guangzhou}
1002 {name:lisi, sex:male} {area:binjiang, street:juyelu}
1003 {class:yuwen, score:88} {aaa:bbb}你图中表达的意思:
| rowkey | info列簇里的内容 | address列簇里的内容 |
|---|---|---|
| 1001 | name=zhangsan, age=14 | province=guangdong, city=guangzhou |
| 1002 | name=lisi, sex=male | area=binjiang, street=juyelu |
| 1003 | class=yuwen, score=88 | aaa=bbb |
二、列簇到底是什么?(通俗解释)
2.1 一句话定义
列簇 = 列的"分组" = 把相关的列放在一起
2.2 用衣柜类比
text
你的衣柜(表)
├── 上衣区(列簇1)
│ ├── T恤(列)
│ ├── 衬衫(列)
│ └── 外套(列)
└── 裤子区(列簇2)
├── 牛仔裤(列)
├── 西裤(列)
└── 短裤(列)-
列簇 = 分区(上衣区、裤子区)
-
列 = 具体衣服(T恤、衬衫、牛仔裤)
2.3 用你的图解释
text
你的表有两个列簇:
- info(信息类列)
- address(地址类列)
列簇info下面有:
name列、age列、sex列、class列、score列 (这些列可以随时增加)
列簇address下面有:
province列、city列、area列、street列、aaa列三、列簇 vs 列 (重点区分)
3.1 建表时
bash
# HBase建表:只声明列簇,不声明具体列
create 'user', 'info', 'address'
# ↑ ↑
# 列簇1 列簇2
# MySQL建表:要声明所有具体列
CREATE TABLE user (
name VARCHAR(50), # 具体列
age INT, # 具体列
province VARCHAR(50) # 具体列
);3.2 插入数据时
bash
# HBase:列可以随时加,不用提前声明
# 第一行:info下有name和age
put 'user', '1001', 'info:name', 'zhangsan'
put 'user', '1001', 'info:age', '14'
# 第二行:info下有name和sex(和第一行列不同,没问题!)
put 'user', '1002', 'info:name', 'lisi'
put 'user', '1002', 'info:sex', 'male'
# 第三行:info下有class和score(完全不同的列,也没问题!)
put 'user', '1003', 'info:class', 'yuwen'
put 'user', '1003', 'info:score', '88'这就是列簇的核心价值:
-
列簇是固定的(建表时定义好了)
-
列是动态的(每行可以有不同的列)
四、为什么需要列簇?(设计目的)
4.1 性能原因
text
场景:一张表有100个列,但查询时经常只查其中20个
MySQL:每次读整行,100个列都读出来
HBase:只读需要的列簇
如果你把20个常用列放在一个列簇,80个不常用列放在另一个列簇
→ 查询只读第一个列簇,速度快很多4.2 存储属性不同
bash
# 不同列簇可以设置不同的属性
# info列簇:保存100个版本
alter 'user', {NAME => 'info', VERSIONS => 100}
# address列簇:只保存1个版本
alter 'user', {NAME => 'address', VERSIONS => 1}
# info列簇:开启压缩
alter 'user', {NAME => 'info', COMPRESSION => 'SNAPPY'}4.3 权限控制
bash
# 可以控制谁能访问哪个列簇
# info列簇给所有人看
# address列簇只给管理员看五、用你的图理解列簇的"动态性"
text
rowkey info address
1001 {name:zhangsan, age:14} {province:guangdong, city:guangzhou}
1002 {name:lisi, sex:male} {area:binjiang, street:juyelu}
1003 {class:yuwen, score:88} {aaa:bbb}
1004 {} {}注意观察:
-
列簇info:每一行的"列"都不同
-
1001行:有name、age两列
-
1002行:有name、sex两列(没有age)
-
1003行:有class、score两列(没有name)
-
1004行:info列簇下没有任何列
-
-
列簇address:也是每行列不同
-
1001行:province、city
-
1002行:area、street
-
1003行:aaa
-
1004行:空
-
这在MySQL里是不可能的! MySQL每一行的列必须一样。
六、列簇的最佳实践(面试会问)
6.1 列簇不要太多
bash
# 不好的设计:列簇太多
create 'user', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'
# 好的设计:2-3个列簇
create 'user', 'basic_info', 'extra_info', 'address'原因: 每个列簇对应一个物理文件,列簇太多影响性能
6.2 经常一起查的列放在同一个列簇
bash
# 好的设计:经常查姓名+年龄,放在同一列簇
basic_info: name
basic_info: age
basic_info: gender
# 不经常查的大字段,放另一个列簇
extra_info: resume_text
extra_info: portrait_image6.3 列簇名尽量短
bash
# 不好的:列簇名太长
create 'user', 'basic_information'
# 好的:短一点
create 'user', 'info'
# 原因:每个KV都会带上列簇名,太长浪费存储七、记忆口诀
text
列簇是分组,列是组内项
建表定列簇,具体列随时加
每行可不同,灵活又高效
性能优化点,常用放一组八、检查你是否理解了
问题: 下面这张表,应该怎么设计列簇?
text
用户数据:
- 经常查:id, name, age, gender
- 偶尔查:vip_level, register_time, last_login_time
- 很少查:address, phone, email答案:
bash
create 'user',
'basic_info', # id, name, age, gender
'vip_info', # vip_level, register_time, last_login_time
'contact_info' # address, phone, email九、你图中的疑问解答
Q:为什么1003行的info列簇下有class和score?
A:因为列簇info下的列是动态的,每行可以放不同的列。1003行放的是成绩数据,不是用户数据,完全允许。
Q:这样不会乱吗?
A:取决于你的业务设计。通常一张表存一类数据(比如都存用户数据),不会像图里那样混着成绩数据。图只是为了演示"动态列"的特性。
Q:列簇address里的aaa:bbb是什么意思?
A:意思是在address列簇下,有一列叫"aaa",值是"bbb"。a和b只是占位符,代表你可以放任何列名和值。
重要概念理解
一、Table(表)
你的笔记原文:
只需要声明列簇就行,不需要声明具体的列
用你的图解释:
bash
# 建表时:只声明列簇名字
create 'user', 'info', 'address'
# ↑ ↑
# 列簇1 列簇2
# 不需要像MySQL那样:
# CREATE TABLE user (name VARCHAR, age INT, province VARCHAR...)建表后,表的结构是这样的:
text
表名:user
├── 列簇:info (里面能放什么列?不知道,反正留了个位置)
└── 列簇:address (里面能放什么列?不知道,反正留了个位置)插入数据时:
bash
# 列可以随便加,不需要提前告诉HBase
put 'user', '1001', 'info:name', 'zhangsan' # ← 加了一个name列
put 'user', '1001', 'info:age', '14' # ← 加了一个age列
put 'user', '1001', 'address:province', 'guangdong' # ← 加了一个province列这就是"动态数据写入": 列是插入数据时动态产生的,不是建表时固定的。
二、Row(行)
你的笔记原文:
数据行由 rowkey 以及对应的列簇组成,按 rowkey 字典顺序存储
用你的图解释:
text
你的图中的每一行数据:
第1行:rowkey=1001
第2行:rowkey=1002
第3行:rowkey=1003
...
每一行都由两部分组成:
1. rowkey(行的唯一标识)
2. 各个列簇下的数据(info里的内容、address里的内容)什么叫"按字典顺序存储"?
你的rowkey: 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010, 1011, 1012
在HBase里物理存储的顺序:
text
1001 → 1002 → 1003 → 1004 → 1005 → 1006 → 1007 → 1008 → 1009 → 1010 → 1011 → 1012注意: 不是按数字大小,是按字符串比较!
text
举例:rowkey有 1, 10, 100, 2
字符串排序结果:1 → 10 → 100 → 2为什么重要?
-
设计rowkey时,如果想让最近的数据在前面,就要把时间倒序放
-
比如:
20250101_001比20250102_001小,会排在前面
三、Column(列)
你的笔记原文:
主要由 列簇 + 列的限定符 组成
用你的图解释:
text
你的图里:
┌─────────────────────────────────────────────────┐
│ rowkey │ info │ address │
├─────────────────────────────────────────────────┤
│ 1001 │ {name:zhangsan, age:14} │ {province:guangdong, city:guangzhou} │
└─────────────────────────────────────────────────┘
拆解成列:
完整列名1 = info:name (列簇=info,列限定符=name)
完整列名2 = info:age (列簇=info,列限定符=age)
完整列名3 = address:province(列簇=address,列限定符=province)
完整列名4 = address:city (列簇=address,列限定符=city)规律:
text
完整列名 = 列簇名 + ":" + 列限定符
info:name ← 冒号前面是列簇,冒号后面是列名
info:age
address:province
address:city为什么这么设计?
-
不同列簇可以有相同列限定符(不冲突)
-
例如:
info:phone和address:phone是两个不同的列
四、Timestamp(时间戳)
你的笔记原文:
标识数据的不同版本,每条数据写入系统都会自动标记对应时间戳
用你的图解释:
你的图只画了最新数据,实际上HBase存的是这样:
text
rowkey=1001, info:name
├── timestamp=1700000003 → "zhangsan" (最新)
├── timestamp=1700000002 → "zhang" (旧版)
└── timestamp=1700000001 → "zhangwei" (最旧)
rowkey=1001, info:age
└── timestamp=1700000001 → "14" (只有一个版本)实际操作演示:
bash
# 第一次写入
put 'user', '1001', 'info:name', 'zhangwei'
# 系统自动加时间戳:timestamp=1000000
# 第二次写入(修改)
put 'user', '1001', 'info:name', 'zhang'
# 系统自动加时间戳:timestamp=1000001
# 第三次写入(再修改)
put 'user', '1001', 'info:name', 'zhangsan'
# 系统自动加时间戳:timestamp=1000002
# 查询时,默认返回最新的(zhangsan)
get 'user', '1001'
# 查询所有版本,能看到修改历史
get 'user', '1001', {COLUMN => 'info:name', VERSIONS => 3}
# 返回:zhangsan, zhang, zhangwei时间戳的作用:
| 作用 | 说明 |
|---|---|
| 版本管理 | 记录数据修改历史 |
| 自动排序 | 时间戳大的更新,自动排前面 |
| 过期清理 | 可以设置只保留最近3个版本 |
五、Cell(单元格)
你的笔记原文:
由 {rowkey, 列簇, 列限定符, timestamp} 确认数据的唯一单元
用你的图解释:
Cell = 一个格子里的数据
text
你的图中,表面上有很多格子:
┌─────────┬──────────────────────┬─────────────────────────────────┐
│ rowkey │ info │ address │
├─────────┼──────────────────────┼─────────────────────────────────┤
│ 1001 │ {name:zhangsan, age:14} │ {province:guangdong, city:guangzhou} │
└─────────┴──────────────────────┴─────────────────────────────────┘
但每个"格子里"其实是一个KV键值对
实际上的Cell:
┌─────────────┬───────────────┬─────────────┬───────────────┐
│ rowkey │ 列簇:列限定符 │ timestamp │ value │
├─────────────┼───────────────┼─────────────┼───────────────┤
│ 1001 │ info:name │ 1700000003 │ zhangsan │ ← 一个Cell
│ 1001 │ info:age │ 1700000003 │ 14 │ ← 一个Cell
│ 1001 │ address:province│ 1700000003 │ guangdong │ ← 一个Cell
│ 1001 │ address:city │ 1700000003 │ guangzhou │ ← 一个Cell
└─────────────┴───────────────┴─────────────┴───────────────┘为什么要有"Cell"这个概念?
因为HBase里,一个"格子"可能有多个版本!
text
同样是 rowkey=1001, info:name 这个"格子"
实际上有3个Cell(3个版本):
Cell1: {1001, info:name, 1000001, "zhangwei"}
Cell2: {1001, info:name, 1000002, "zhang"}
Cell3: {1001, info:name, 1000003, "zhangsan"}
四个参数组合起来,才能唯一确定一个值!六、用你的图完整串一遍
你的图数据:
text
rowkey=1001
info:name = "zhangsan"
info:age = 14
address:province = "guangdong"
address:city = "guangzhou"在HBase里实际存储的是:
json
[
// 这是一个Cell
{
"rowkey": "1001",
"column": "info:name",
"timestamp": 1700000003,
"value": "zhangsan"
},
// 这是另一个Cell
{
"rowkey": "1001",
"column": "info:age",
"timestamp": 1700000003,
"value": "14"
},
// 这是另一个Cell
{
"rowkey": "1001",
"column": "address:province",
"timestamp": 1700000003,
"value": "guangdong"
},
// 这是另一个Cell
{
"rowkey": "1001",
"column": "address:city",
"timestamp": 1700000003,
"value": "guangzhou"
}
]七、总结对比表
| 概念 | 一句话解释 | 在你的图中对应什么 |
|---|---|---|
| Table | 整张表 | 整张图片 |
| Row | 一行数据 | 图片中的一行(如1001那行) |
| Column | 列簇+列名 | info:name、address:city |
| Timestamp | 数据版本 | 图片没画,每个值背后都有个时间戳 |
| Cell | 一个具体值 | 图中的一个格子,但拆成KV形式 |
八、记忆口诀
text
建表只定列簇名,列可动态后添加
Rowkey唯一标识行,字典顺序来存储
完整列名分两段:列簇冒号列名字
时间戳管版本,一个格子多版本
Rowkey+列+时间戳,唯一确定一个CellHBase 基础命令速查表
一、表操作命令
| 命令 | 语法 | 说明 | 示例 |
|---|---|---|---|
list |
list |
查看所有表 | list |
create |
create '表名', '列簇1', '列簇2'... |
创建表 | create 'user', 'info', 'address' |
describe |
describe '表名' |
查看表结构 | describe 'user' |
exists |
exists '表名' |
判断表是否存在 | exists 'user' |
disable |
disable '表名' |
禁用表(删除表前必须先禁用) | disable 'user' |
is_disabled |
is_disabled '表名' |
判断表是否已禁用 | is_disabled 'user' |
enable |
enable '表名' |
启用表 | enable 'user' |
is_enabled |
is_enabled '表名' |
判断表是否已启用 | is_enabled 'user' |
drop |
drop '表名' |
删除表(必须先disable) | drop 'user' |
alter |
alter '表名', {NAME=>'列簇', 属性=>值} |
修改表结构 | alter 'user', {NAME=>'info', VERSIONS=>5} |
truncate |
truncate '表名' |
清空表数据(保留表结构) | truncate 'user' |
二、数据操作命令(增删改查)
| 命令 | 语法 | 说明 | 示例 |
|---|---|---|---|
put |
put '表名', 'rowkey', '列簇:列名', '值' |
插入/更新一条数据 | put 'user', '1001', 'info:name', 'zhangsan' |
get |
get '表名', 'rowkey' |
查询一行数据 | get 'user', '1001' |
get (指定列) |
get '表名', 'rowkey', '列簇:列名' |
查询指定列 | get 'user', '1001', 'info:name' |
get (多版本) |
get '表名', 'rowkey', {COLUMN=>'列名', VERSIONS=>N} |
查询多个版本 | get 'user', '1001', {COLUMN=>'info:name', VERSIONS=>3} |
scan |
scan '表名' |
扫描整张表 | scan 'user' |
scan (限制条数) |
scan '表名', {LIMIT=>N} |
扫描前N条 | scan 'user', {LIMIT=>10} |
scan (范围) |
scan '表名', {STARTROW=>'起始', ENDROW=>'结束'} |
扫描rowkey范围 | scan 'user', {STARTROW=>'1001', ENDROW=>'1010'} |
delete |
delete '表名', 'rowkey', '列簇:列名' |
删除指定列的最新版本 | delete 'user', '1001', 'info:name' |
delete (指定版本) |
delete '表名', 'rowkey', '列簇:列名', timestamp |
删除指定版本 | delete 'user', '1001', 'info:name', 1700000003 |
deleteall |
deleteall '表名', 'rowkey' |
删除整行数据 | deleteall 'user', '1001' |
incr |
incr '表名', 'rowkey', '列簇:列名', 增量 |
原子性自增 | incr 'user', '1001', 'info:age', 1 |
count |
count '表名' |
统计表行数 | count 'user' |
三、命名空间操作
| 命令 | 语法 | 说明 | 示例 |
|---|---|---|---|
list_namespace |
list_namespace |
查看所有命名空间 | list_namespace |
create_namespace |
create_namespace '命名空间名' |
创建命名空间 | create_namespace 'myapp' |
describe_namespace |
describe_namespace '命名空间名' |
查看命名空间详情 | describe_namespace 'myapp' |
alter_namespace |
alter_namespace '命名空间名', {METHOD=>'set', '属性'=>'值'} |
修改命名空间 | alter_namespace 'myapp', {METHOD=>'set', 'author'=>'admin'} |
drop_namespace |
drop_namespace '命名空间名' |
删除命名空间(必须为空) | drop_namespace 'myapp' |
list_namespace_tables |
list_namespace_tables '命名空间名' |
查看命名空间下的所有表 | list_namespace_tables 'myapp' |
四、工具类命令
| 命令 | 语法 | 说明 | 示例 |
|---|---|---|---|
version |
version |
查看HBase版本 | version |
status |
status |
查看集群状态 | status |
whoami |
whoami |
查看当前用户 | whoami |
quit |
quit |
退出HBase Shell | quit |
help |
help '命令名' |
查看命令帮助 | help 'put' |
五、操作流程模板
建表 → 插入 → 查询 → 删除 完整流程
bash
# 1. 进入HBase Shell
hbase shell
# 2. 建表(要有列簇)
create 'student', 'info', 'score'
# 3. 插入数据
put 'student', '001', 'info:name', '张三'
put 'student', '001', 'info:age', '20'
put 'student', '001', 'score:math', '90'
put 'student', '001', 'score:english', '85'
put 'student', '002', 'info:name', '李四'
put 'student', '002', 'info:age', '22'
put 'student', '002', 'score:math', '78'
# 4. 查询
get 'student', '001' # 查一行
get 'student', '001', 'info:name' # 查某一列
scan 'student' # 查全表
scan 'student', {LIMIT=>10} # 查前10条
# 5. 统计
count 'student'
# 6. 删除
delete 'student', '001', 'score:math' # 删除一列
deleteall 'student', '002' # 删除整行
# 7. 删除表(需要先禁用)
disable 'student'
drop 'student'
# 8. 退出
quit六、常用参数说明
| 参数 | 说明 | 使用场景 |
|---|---|---|
COLUMN |
指定要查询的列 | get 't1', 'r1', {COLUMN=>'cf:col1'} |
VERSIONS |
查询多个版本 | get 't1', 'r1', {COLUMN=>'cf:col1', VERSIONS=>3} |
LIMIT |
限制返回条数 | scan 't1', {LIMIT=>10} |
STARTROW |
起始rowkey | scan 't1', {STARTROW=>'1001'} |
ENDROW |
结束rowkey | scan 't1', {ENDROW=>'2000'} |
TIMESTAMP |
指定时间戳 | put 't1', 'r1', 'cf:col1', 'val', 1234567890 |
七、命令速记口诀
text
表操作:list create describe drop
删表前要disable,enable能恢复
数据操作:put增 get查 scan扫
delete删列 deleteall删行
命名空间:list_namespace查所有
create_namespace建一个
辅助命令:version status whoami
quit退出 help问我看到你在HBase Shell外面执行了
list_namespace命令,这个命令必须在HBase Shell内部执行。
HBase启动成功 - 看到了
running master和running regionserver进入HBase Shell成功 - 看到了
hbase(main):001:0>提示符