Wolverine:杀不死的 Android 进程保活方案
引言
在 Android 生态中,进程保活一直是推送、即时通讯、音乐播放、后台数据同步等场景下的核心技术挑战。随着 Android 系统对后台进程管控日趋严格(从 Doze 模式到各厂商的激进杀后台策略),传统保活方案逐渐失效。本文将深入剖析一种利用 Linux 内核 flock 文件锁 机制实现进程死亡感知与自动拉起的保活方案------Wolverine(金刚狼)。该方案经实测可在华为、三星、小米、ViVO 等主流机型的 Android 5-12 系统上实现保活,在手动强杀和 force-stop 场景下均可生效。
为什么需要进程保活?
对于即时通讯应用,进程死亡意味着无法及时接收消息,影响用户体验;对于音乐播放器,进程被杀死会导致音乐中断;对于后台数据同步服务,进程保活是确保数据完整性和实时性的基础。然而,Android 系统从设计之初就强调资源管理和用户体验,对后台进程的限制越来越严格,这使得保活技术成为开发者与系统之间一场持续的"攻防战"。
Wolverine 方案的独特价值
与以往依赖 Android Framework API 或系统漏洞的方案不同,Wolverine 从 Linux 内核层面寻找突破口,利用 flock 文件锁的进程死亡自动释放特性,构建了一套近乎实时的进程死亡感知与拉起机制。它不仅绕过了高版本 Android 对广播、Service 等组件的限制,还通过参数预计算和 Native 守护进程,将拉起延迟压缩到微秒级,从而在系统 force-stop 的间隙中成功"复活"进程。下文将详细拆解其技术原理、架构设计与关键实现。
回顾 Android 保活与 Google 的对抗历史,涌现了多种方案,每一代都在系统升级中被逐步封堵:
- 监听 SCREEN_ON/OFF 广播:通过系统广播感知屏幕状态并拉起进程,Android 8.0 后隐式广播被限制
- 一像素透明 Activity:在锁屏时启动 1px 的透明 Activity 提升进程优先级,被各厂商定向封杀
- 双进程互相监听拉起:两个 Service 互相绑定,一方死亡另一方拉起,系统可同时杀死同一应用的所有进程
- 前台通知+播放静默音乐:保持前台 Service 状态,但严重耗电且用户可感知
- 各厂商推送 SDK 整合:根据 ROM 类型选用对应厂商推送通道,依赖厂商配合
- APP 矩阵互拉:只要联盟中一个 APP 存活就能唤醒其他 APP,被系统关联杀机制击破
这些方案要么在高版本系统上失效,要么存在严重的副作用。Wolverine 从 Linux 内核层面出发,找到了一条全新的技术路径。
核心思想:文件锁作为进程存活的"心跳"
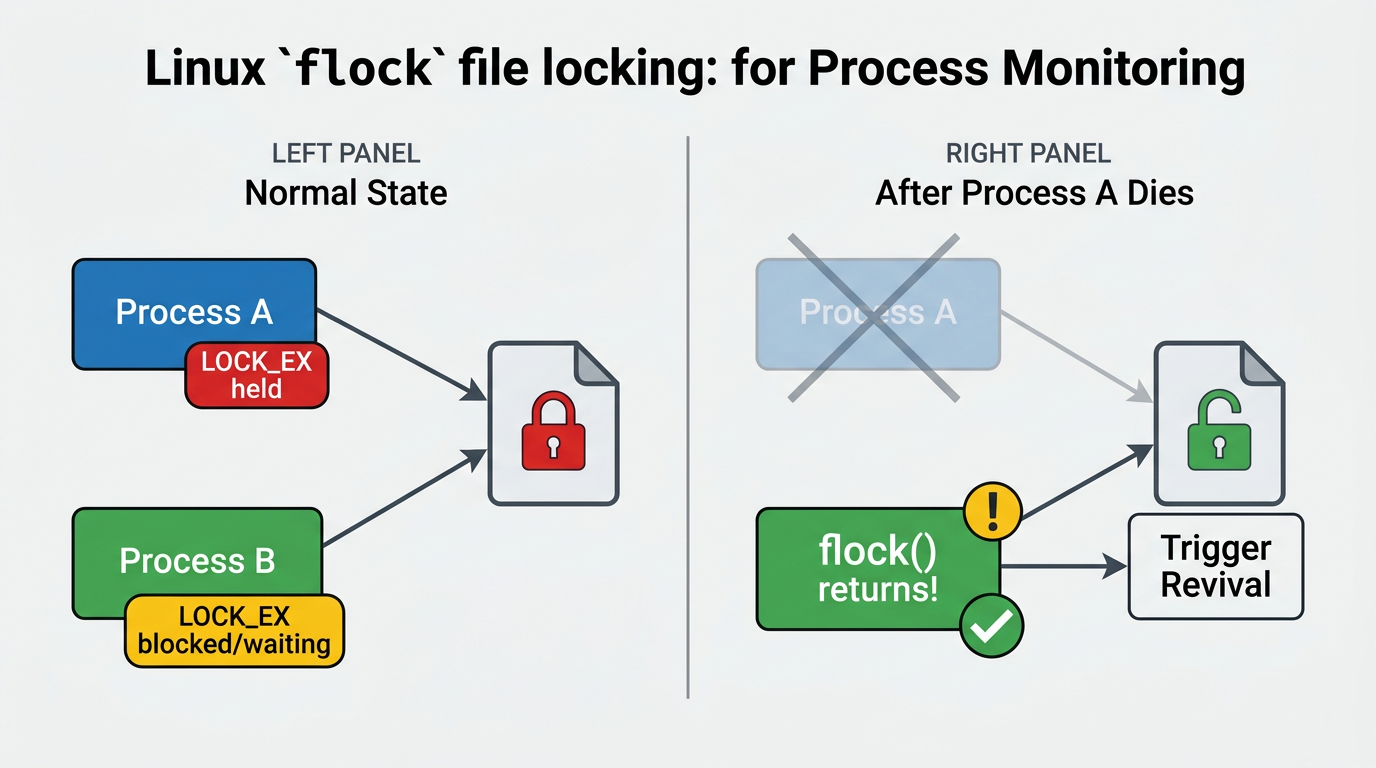
Linux 内核提供的 flock() 系统调用具备一个关键特性:当持有文件锁的进程被杀死时,内核会自动释放该进程持有的所有文件锁 。这一语义天然构成了一种跨进程的"死亡通知"机制------进程 A 持有锁文件 X 的排他锁,进程 B 阻塞在对锁文件 X 的加锁请求上;一旦进程 A 死亡,锁被释放,进程 B 的 flock() 调用立即返回成功,从而得知进程 A 已经不存在了。
flock 的关键语义如下:
int flock(int fd, int operation);
LOCK_SH - 共享锁,多进程可同时持有
LOCK_EX - 排他锁,同一时刻仅一个进程可持有
LOCK_UN - 释放锁
LOCK_NB - 非阻塞模式(通过 OR 组合使用)
注:同一文件不可同时持有共享锁和排他锁与传统的轮询检测(如定时检查 /proc/pid)相比,文件锁方案具备几个显著优势:零延迟感知(内核级通知)、极低的 CPU 和电池消耗(阻塞等待不消耗 CPU 时间片)、以及对应用层透明(不依赖任何 Android Framework API)。
整体架构
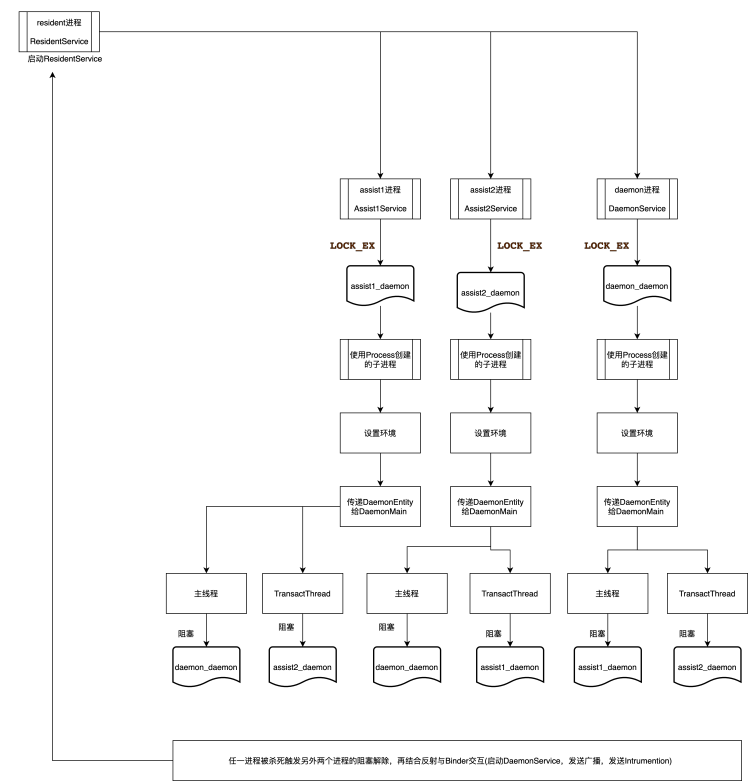
Wolverine 的架构设计围绕多进程互相监控、交叉持锁展开。整体总结:系统运行 3 个保活进程加上 1 个主进程(目标进程),共 4 个进程协同工作。3 个保活进程中,每个进程对其他 2 个进程对应的文件执行 flock,同时预先准备好恢复参数(通过反射获取 ActivityManagerNative 代理、填充好 Parcel 数据),并对自身进程对应的文件进行轮询 flock。若其中一个进程被杀死,另外 2 个进程立即感知到锁释放,并使用之前预先准备好的参数与 AMS 通信拉起服务。
┌─────────────────────────────────────────────────────┐
│ 宿主应用主进程 │
│ WolverineKeepAlive.attachBaseContext() │
│ ↓ │
│ WolverineKeepAliveHelper.lockFiles() │
│ ↓ │
│ LockThread → app_process 启动守护进程 │
└─────────────────────────────────────────────────────┘
↕ flock 互锁 ↕ flock 互锁
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ :channel │ │ :assist1 │ │ :assist2 │
│ DaemonSvc │ │ AssistSvc1 │ │ AssistSvc2 │
│ 持锁+监听 │ │ 持锁+监听 │ │ 持锁+监听 │
└──────────────┘ └──────────────┘ └──────────────┘
↕ flock 互锁 ↕ flock 互锁
┌─────────────────────────────────────────────────────┐
│ Native 守护进程 (app_process 启动) │
│ DaemonMain.main() → waitFileLock() │
│ 锁释放 → Binder transact 拉起服务 │
└─────────────────────────────────────────────────────┘为什么能从系统手下"偷得一丝生存机会"
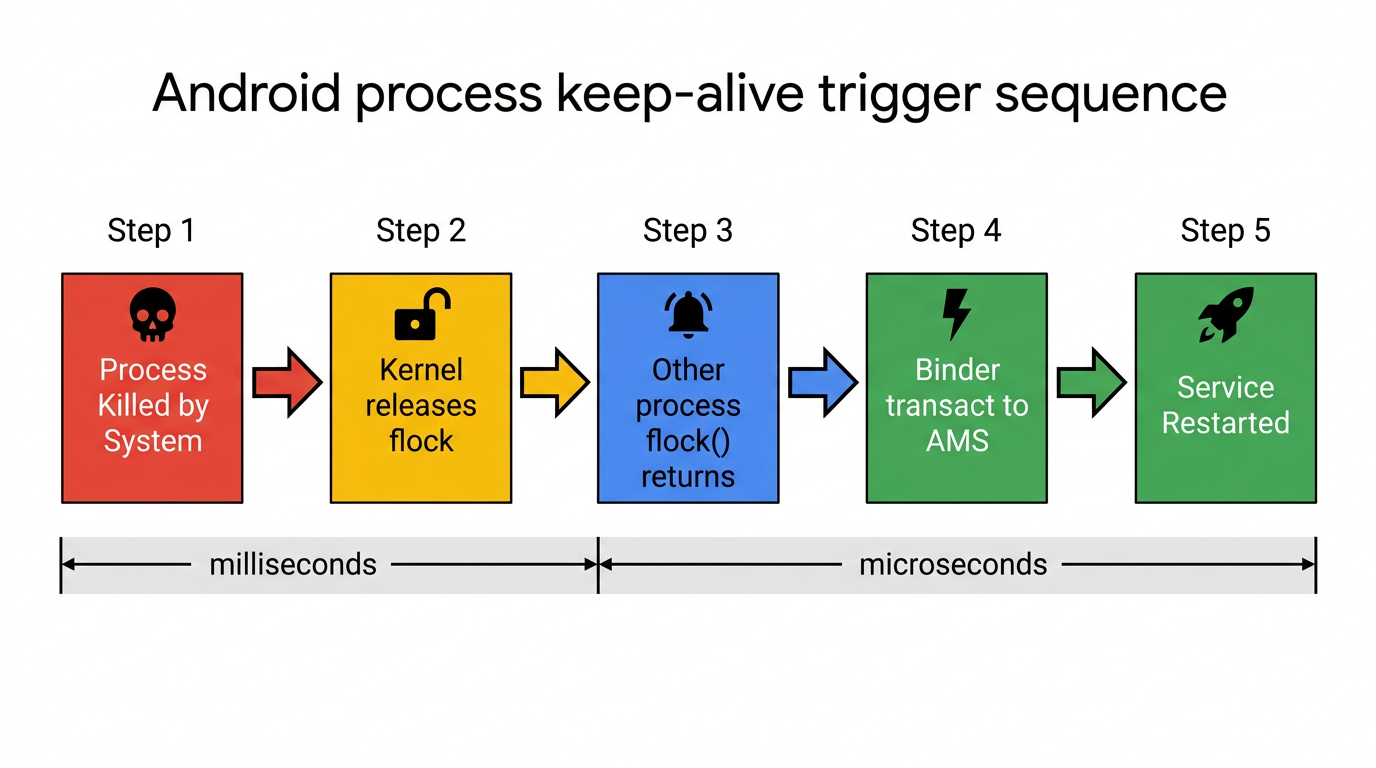
这是理解整个方案最关键的一点:由于 AMS 代理以及 Parcel 参数在进程启动时就已经准备完毕,当检测到目标进程死亡后,拉起操作的全部开销仅仅是一次 Binder IPC 通信。这个时间窗口极短(微秒级),而系统 force-stop 的进程遍历和逐个 kill 操作是有时间间隔的(毫秒级)。正是这个数量级的差异,让 Wolverine 能够在系统杀死一个进程后、杀死下一个进程之前,完成新进程的拉起。
关键实现细节
类继承结构
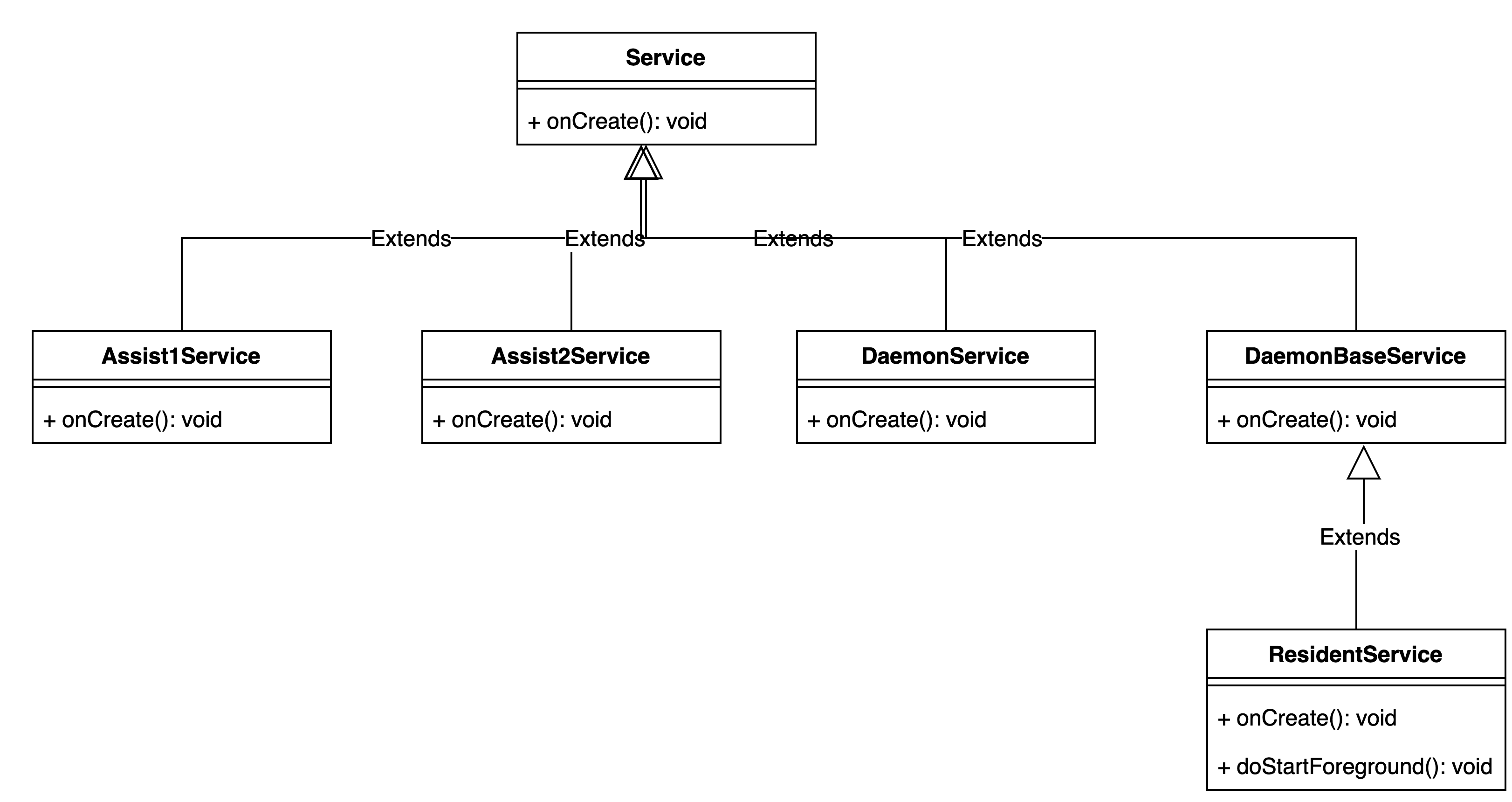
如上图所示,Wolverine 的 Service 层采用统一的继承结构:AssistService1、AssistService2、DaemonService 均直接继承自 Android 的 Service 基类,各自运行在独立进程中负责保活监控;DaemonBaseService 也继承自 Service,是用户目标 Service(如 ResidentService)的抽象父类,用户的业务 Service 通过继承它即可获得保活能力。
1. Native 层:flock 文件锁操作(wolverine.cpp)
文件锁逻辑通过 JNI 暴露给 Java 层,核心有两个函数:
lock_file ------ 获取排他锁,表示"我还活着":
c
int lock_file(const char *lock_file_path) {
int fd = open(lock_file_path, O_RDONLY);
if (fd == -1) {
fd = open(lock_file_path, O_CREAT, S_IRUSR);
}
int ret = flock(fd, LOCK_EX); // 获取排他锁
return ret != -1;
}进程启动时调用此函数对自己的锁文件加排他锁(LOCK_EX)。由于排他锁是进程级别的,只要进程存活,其他进程对同一文件的 flock(LOCK_EX) 请求就会阻塞。
wait_lock_file ------ 监控其他进程的存活状态:
c
int wait_lock_file(const char *lock_file_path) {
int fd = open(lock_file_path, O_RDONLY);
if (fd == -1) {
fd = open(lock_file_path, O_CREAT, S_IRUSR);
}
int lockRet;
while (true) {
lockRet = flock(fd, LOCK_EX | LOCK_NB); // 非阻塞尝试
if (lockRet == -1) break; // 加锁失败说明对方已持锁(活着)
flock(fd, LOCK_UN); // 加锁成功说明对方还没启动,释放后等待
sleep(1);
}
// 到这里说明对方已经持有锁了,现在切换到阻塞模式等待对方死亡
return flock(fd, LOCK_EX) != -1; // 阻塞等待锁释放(对方死亡)
}这段逻辑的巧妙之处在于分两阶段工作:第一阶段用非阻塞模式(LOCK_NB)轮询确认目标进程已经持有了锁(即目标进程已启动完成),第二阶段切换到阻塞模式等待锁释放(即目标进程死亡)。一旦 flock(fd, LOCK_EX) 返回成功,就意味着目标进程已被杀死,此时立即触发拉起流程。
2. 守护进程的启动方式(LockThread.java)
Wolverine 并没有使用常规的 Service 或 fork 子进程来创建守护进程,而是直接通过 shell 调用 app_process 命令启动一个独立的 Java 进程:
java
// 设置 CLASSPATH 为宿主 APK 路径
arrayList.add("export CLASSPATH=$CLASSPATH:" + publicSourceDir);
// 设置动态链接库路径,包含 native so 目录
arrayList.add("export LD_LIBRARY_PATH=/system/lib64/:/vendor/lib64/:" + nativeLibraryDir);
// 通过 app_process 启动 DaemonMain 类
arrayList.add("app_process / com.alibaba.wolverine.component.DaemonMain <params> --application --nice-name=m_d_daemon_<suffix> &");app_process 是 Android 系统中 Zygote 的底层工具,通常用于启动系统服务。通过它直接启动 Java 类意味着:该进程不在 AMS(Activity Manager Service)的管辖范围内,不属于任何应用的进程组,系统的 force-stop 无法直接关联到它。配合 setsid() 调用(通过 JNI 的 nativeSetSid),守护进程彻底脱离父进程的会话组,成为独立的进程组 leader。
3. 参数预计算:争分夺秒的关键优化
DaemonMain 的 run() 方法在启动后立即执行以下预计算步骤:
java
private void run() {
// 步骤1:通过反射获取AMS的Binder代理
this.setBinder();
// 步骤2:预先构造所有Parcel数据(Service/Broadcast/Instrumentation)
this.fillAllParcel();
// 步骤3:脱离会话组
nativeSetSid();
// 步骤4:阻塞等待锁释放(目标进程死亡)
waitFileLock(lockFilePath);
// 步骤5:锁释放,立即发起预备好的Binder事务
this.startService();
this.sendBroadcast();
this.startInstrumentation();
}注意步骤 1-3 是在目标进程存活期间就完成的"预热"操作。当步骤 4 的阻塞等待被唤醒时,步骤 5 只需要执行已经组装好的 Binder transact 调用------这就是整个方案能跑赢系统 kill 流程的核心原因。
4. 进程复活:原始 Binder 事务
由于守护进程不在 Android Framework 的标准环境中运行,无法使用 Context.startService() 等 API。Wolverine 采用了直接构造 Parcel 数据并通过 Binder 事务与 AMS 通信的方式:
java
// 通过反射获取 AMS 的 Binder 引用
Class<?> cls = Class.forName("android.app.ActivityManagerNative");
Object ams = cls.getMethod("getDefault").invoke(cls);
Field mRemote = ams.getClass().getDeclaredField("mRemote");
mRemote.setAccessible(true);
IBinder binder = (IBinder) mRemote.get(ams);
// 手动构造 startService 的 Parcel(在预计算阶段完成)
Parcel serviceParcel = Parcel.obtain();
serviceParcel.writeInterfaceToken("android.app.IActivityManager");
// ... 写入 Intent 及其他必要字段
// 检测到进程死亡后,直接发起预备好的 Binder 事务
binder.transact(serviceCode, serviceParcel, null, FLAG_ONEWAY);BinderManager 类通过反射获取 TRANSACTION_startService、TRANSACTION_broadcastIntent、TRANSACTION_startInstrumentation 的事务码,使得守护进程能够在没有 Context 的情况下直接与 AMS 通信。
5. 三重拉起策略
当检测到目标进程死亡后,守护进程并行执行三种拉起操作:
- startService:通过 Binder 事务向 AMS 发送启动 DaemonService 的请求
- sendBroadcast:发送广播到 DaemonReceiver,作为备用拉起路径
- startInstrumentation:启动 DaemonInstrumentation 组件
Instrumentation 作为 Android 系统中的测试框架组件,其启动不受常规后台限制约束。DaemonInstrumentation 的 onCreate 中会进一步触发 DaemonService.startService(),形成多路冗余拉起。且 TransactToBinderThread 内部类为每个锁文件分配独立线程监控,确保多路检测并行进行。
6. 锁文件的分配与互锁矩阵
系统中存在三个守护角色:channel、assist1、assist2。锁文件命名规则为 <processName>_daemon,存放在应用的 filesDir 目录下。互锁关系如下:
| 进程 | 持有锁文件 | 监控锁文件 |
|---|---|---|
| :channel | channel_daemon | assist1_daemon, assist2_daemon |
| :assist1 | assist1_daemon | channel_daemon, assist2_daemon |
| :assist2 | assist2_daemon | channel_daemon, assist1_daemon |
每个进程同时启动一个 Native 守护进程,该守护进程监控与自己不同的锁文件。这意味着任何一个进程被杀死,其他两个进程以及对应的 Native 守护进程都会感知到并触发拉起。只有当所有进程在同一时刻被同时杀死时,保活才会失效------这也是该方案唯一的已知弱点。
为什么 force-stop 难以彻底杀死
Android 的 force-stop 流程通常是:遍历应用的所有进程并逐一 kill。但这个过程并非原子操作------当系统 kill 第一个进程时,第二个进程的 waitFileLock() 已经检测到锁释放并触发拉起;而通过 app_process 启动的 Native 守护进程由于不在应用的进程记录中,force-stop 甚至根本不知道它的存在。这就形成了一种"你杀我一个,我立马启动一个新的"的竞态条件,使得实际存活率极高。
系统层面可以从两种思路应对:在 force-stop 期间不允许启动新进程,或者先收集所有相关进程再统一 kill(如有必要可先发送 SIGSTOP 暂停所有进程,再逐一发送 SIGKILL)。部分国产 ROM 的"一键加速"已经采用了类似策略。
双开关设计:SDK 开关与业务开关
Wolverine 设计了双开关机制来控制保活行为:
java
// SDK开关:在 Application.attachBaseContext() 中设置
WolverineKeepAlive.attachBaseContext(base, daemonServiceEntity, true);
// 业务开关:可在任意时机动态控制
WolverineKeepAlive.enableBusiness(base, true);这一设计的原因在于:保活 SDK 的初始化时机极早(必须在 Application 创建之前),但业务上控制保活的时机无法预测(如用户登录后启动保活、登出后关闭保活)。双开关共同为 true 时保活才真正生效,既满足了早期初始化的技术要求,又保留了业务层面的灵活控制。
数据流转与序列化
守护进程通过 app_process 启动时需要传递配置信息(Intent、锁文件路径等)。由于命令行参数只能传递字符串,Wolverine 将整个 DaemonEntity 对象通过 Parcel 序列化后进行 Base64 编码,作为命令行参数传入。守护进程的 main() 方法中再反序列化恢复为对象:
java
// 序列化:DaemonEntity → Parcel → byte[] → Base64 String
public String toString() {
Parcel parcel = Parcel.obtain();
this.writeToParcel(parcel, 0);
return Base64.encodeToString(parcel.marshall(), Base64.NO_WRAP);
}
// 反序列化:Base64 String → byte[] → Parcel → DaemonEntity
public static DaemonEntity createFromStr(String str) {
byte[] data = Base64.decode(str, Base64.NO_WRAP);
Parcel parcel = Parcel.obtain();
parcel.unmarshall(data, 0, data.length);
parcel.setDataPosition(0);
return CREATOR.createFromParcel(parcel);
}版本适配
代码中针对不同 Android 版本做了多处适配:
- API 23+ (Android 6.0) :保活功能仅在此版本以上启用(
VERSION.SDK_INT > 23) - API 26+ (Android 8.0) :Binder 事务的 Parcel 写入格式变化(新增
writeInt(1)字段),对应 Android O 中 AMS 接口的变更 - 64位/32位 :根据
nativeLibraryDir路径是否包含 "64" 来选择app_process或app_process32,并相应设置LD_LIBRARY_PATH
技术总结与局限
Wolverine 方案的核心优势可以归纳为三点:一是利用 Linux 内核 flock 语义实现零延迟的进程死亡感知,二是通过参数预计算将拉起耗时压缩到仅一次 Binder IPC 通信,三是多进程冗余互保形成的高可靠性网络。
但该方案也存在明确的局限:一是需要额外 3 个保活进程,对系统资源有一定消耗;二是若系统能够原子化地同时杀死所有相关进程(如先 SIGSTOP 后 SIGKILL),则保活失效;三是直接操作 Binder 和反射系统 API 的做法在 Android 高版本(特别是 hidden API 限制加强后)可能面临兼容性风险。S2 版本规划将 Java 反射替换为 Native ioctl 直接与 Binder 驱动交互,以解决性能和兼容性问题。
从安全治理的角度看,这类保活技术虽然满足了部分应用的功能需求,但也给用户的设备续航和系统资源管理带来了负担,各主流 ROM 厂商也在持续强化相应的防御措施。技术工作者在了解此类方案的同时,也应当在功能需求与用户体验之间做出审慎权衡。