本文整理自 2026 年 5 月 14 日 Create2026 百度 AI 开发者大会 - AI Infra 专题论坛,百度智能云主任架构师黎世勇的同名主题演讲。

2025年上半年,DeepSeek-R1 的正式发布,不仅为行业带来了优质的开源模型,也为大模型推理及整个 AI Infra 领域带来了重大的机遇与挑战。
具体而言,主要体现在以下三个方面:
-
第一,DeepSeek-R1 采用了先进的 MLA 结构,这一结构大幅降低了大模型对显存的需求,同时提升了计算效能。但与此同时,它也为推理服务系统带来了一定的适配成本,其通信算子、KV 管理等环节均与其他模型存在差异,需要进行针对性适配。
-
第二,DeepSeek-R1 所采用的 MoE 架构能够支撑庞大的模型参数规模,并将激活参数控制在较小范围内,从而显著降低大模型推理过程中的计算量。但同时,MoE 架构会引入专家并行及各类通信开销,因此我们需要结合推理系统的自身特点,针对性优化以抵消这一影响。
-
第三,DeepSeek-R1 率先采用原生 MTP 技术,将业界长期研究的投机推理技术接收率提升至较高水平,有效提升了端到端吞吐效率。但这一新技术的应用,也为框架中其他策略的适配带来了不小的工作量。
面对新模型架构对 AI Infra 带来的新挑战,百度百舸在 2025 年上半年开展了一系列极致优化工作:比如构建大规模 PD 分离系统来提升性能、通过通信系统优化、冗余均衡策略等手段,缓解 MoE 系统带来的各类影响。
很快,百度百舸在典型场景------即输入长度 4K、输出长度 1K 的场景中,取得了不逊色于 DeepSeek 官方的性能与效果。
进入到 2025 年下半年,行业初期普遍预计大模型参数规模将持续膨胀,然而实际情况却是:截至目前,大模型参数规模并未出现大幅增长,例如 Kimi 模型的参数规模约 1T,且多数开源模型均采用了 DeepSeek 的架构。
这引发了行业的思考:大模型对推理服务系统的挑战是否依然存在?
就在此时,行业迎来了另一重要范式变革:2025 年下半年,Agent 技术逐步成熟,能够完成各类多样化任务;今年年初,龙虾 Agent 爆发式走红,进一步点燃了行业热情。广大用户尝试利用龙虾 Agent 处理工作、生活中的各类任务,但很快又发现 Token 消耗速度过快,相关使用成本居高不下。
Agent 时代带来的最大范式变革,在于输入序列长度(即上下文长度)发生了数量级的提升。
-
回顾行业发展历程,早期模型的训练长度相对有限,多为 4K、128K,而当前行业普遍关注 1M 上下文长度;
-
从线上推理服务的实际请求数据来看,Agent 出现后,数据长度也发生了显著变化------ 2025 年上半年我们优化 DeepSeek-R1 时,序列长度仍为 4K 输入、1K 输出,而目前上下文长度平均已达到 40K、60K,部分场景甚至达到 100K。
这种数量级的变化,为 AI Infra 领域带来了新的挑战。其核心体现在以下几个方面:
第一,计算量大幅增加。
Transformer 架构中,Attention 计算量随序列长度平方级增长,即序列长度增长 10 倍,计算量将增长 100 倍。为应对这一问题,去年下半年以来,DeepSeek-V3.2 等先进模型均采用了更优的架构设计,但新架构也带来了新的问题,后文将进一步加以说明。
第二,序列长度增加对 KV Cache 产生显著影响。
序列长度越长,单个请求所需存储的 KV Cache 就越多,这对系统性能构成了巨大挑战。由于 HBM 容量有限,KV Cache 的激增会极大限制并发请求数量,导致并发性能无法提升,进而降低整个基础设施的运行效率,最终造成 Decoder 吞吐大幅衰减。针对这一问题,我们可通过各类 KV Cache 相关技术,将有限的 KV Cache 资源分配给真正需要的请求,从而提升系统并发度。
第三,大量 Token 的缓存压力以及重复 Token 的 KV Cache 命中难题。
我们通过对大量 Agent 相关数据的分析发现,尽管 Agent 场景下序列长度长、Token 消耗大,但其中存在大量重复 Token,重复率高达 60%---90%。这一现象不难理解:Agent 完成任务时,需加载大量固定 Prompt,这些 Prompt 在不同请求中完全一致;同时,用户使用 Agent 完成任务时,往往需要多轮交互,每一轮的输入、输出都会作为下一轮的输入,导致大量 Token 重复出现。
针对这一问题,业界很早就已尝试通过更大规模的 KV Cache 存储系统加以解决,但在此过程中需要攻克两个核心技术难题:一是 HBM 容量有限,无法缓存大量不同请求的 Token;二是实际部署中,请求具有分散性、随机性,导致 KV Cache 难以匹配,无法达到理想的命中率。
为解决上述问题,我们采用了分层池化的 KV Cache 存储系统,通过这一设计提升 KV Cache 命中率,从而降低重复 Token 带来的成本损耗。
第四,Agent 时代对工具调用的准确率提出了更高要求。
Agent 完成任务需调用大量工具,而工具的选择由大模型判断。为确保任务高效、准确完成,工具调用的准确率至关重要------调用错误或不合适的工具,轻则增加 Token 消耗,重则导致任务失败。
我们发现,目前部分开源方案的工具调用准确率尚未达到模型官方公布的水平,核心解决路径是采用约束性解码技术,并对采样策略进行优化。

接下来,我将为大家详细介绍百度百舸针对这些挑战提供的相关技术解决方案。
首先介绍 Prefill 相关优化。
如前所述,DeepSeek-V3.2 及最新的 DeepSeek-V4 等模型,均采用 DSA 架构以优化序列长度增加带来的计算量问题。但即便经过优化,序列长度的数量级提升------从 4K 增至 40K,未来甚至可能达到 400K,导致 Prefill 阶段的首 Token 延迟仍在快速上升。
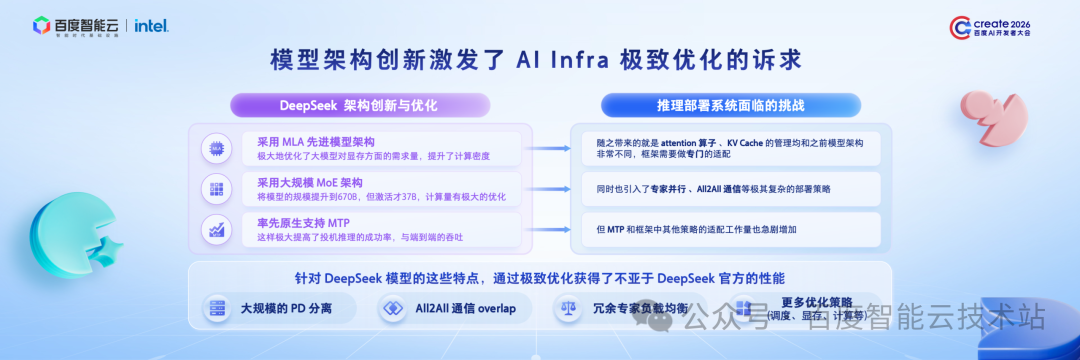
针对这一问题,我们采用序列并行策略,将长序列拆分至不同显卡,由多显卡并行完成 Prefill 计算。
这一策略面临两个核心问题:
-
一是 Attention 计算需遵循因果关系,即后续 Token 的 Attention 计算量明显高于前序 Token,即便采用 DeepSeek-V3.2 等先进架构,在 Indexer(索引器) 模块中这一关系依然存在。若简单将序列拆分至各显卡,会导致负载不均衡。
针对这一问题,我们提出了创新解决方案:将整个序列拆分为 CP 组 显卡数量两倍的切片,在序列前半部分,按顺序将切片分配至各显卡;在序列后半部分,采用逆序分配方式,将计算量较大的后序分片分给已接受较小计算量的前序分片的卡上,从而实现各显卡负载均衡。
-
二是序列拆分至不同显卡后,必然会引入通信问题。传统 CP 实现需经过多轮 send-recv 操作,且实现复杂度较高。
我们观察到,在新的 DSA 结构下,index 数量极少。为消除 CP 通信带来的影响,我们在 Index 处理环节采用 AllGather 方式,通过一次 AllGather 操作,将所有所需 Index 数据同步至每张显卡。这一方式虽会占用少量显存,但大幅降低了通信开销与实现复杂度。
基于上述两项优化,我们实现了完备的 CP 切换机制,确保在长序列场景下,通过显卡扩展仍能获得良好的 TTFT 体验。
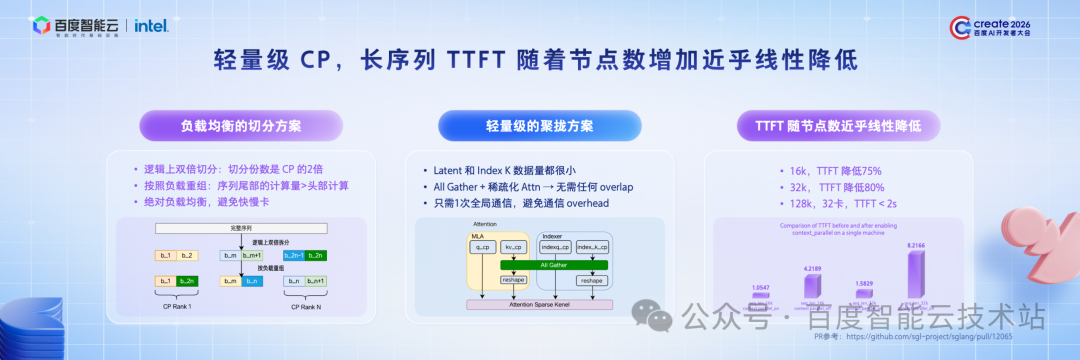
其次,针对输入序列中重复 Token 的情况,我们构建了池化 KV Cache 存储系统。该系统主要解决 HBM 容量不足的问题------除显存外,我们还可利用内存、 SSD 等容量更大的存储介质存储 KV Cache。
但这会带来两个新问题:
-
一是不同级别存储介质的 I/O 性能存在差异;
-
二是请求调度具有随机性,且需遵循负载均衡等策略,导致 KV Cache 可能分散在不同节点,无法达到理论命中率。
针对 I/O 性能差异的问题,我们对 I/O 环节进行了深度优化,采用多设备运行、GDR、UVA 等底层技术,优化显存与内存之间的数据拷贝效率,缓解不同存储介质带来的性能损耗;同时,结合 I/O 数据流实现数据流水线并行技术,显著降低传输过程中的通信开销,将不同存储介质的 I/O 影响降至最低,从而可利用 SSD、内存等介质存储更多 KV Cache。
针对命中率问题,我们引入池化策略:当请求调度至某一节点,如果该节点未缓存所需 KV Cache,但在集群层面存在该 KV Cache 时,我们会将 KV Cache 同步至该节点,以提升命中率。为解决同步过程中的通信开销问题,我们实现了异步预读策略,将通信开销控制在可接受范围。
目前,通过这一设计,集群 KV Cache 命中率已接近 90% 的理论水平。这套完备的分层池化 KV Cache 系统,大幅降低了 Agent 场景下重复 Token 带来的 Prefill 阶段的成本。
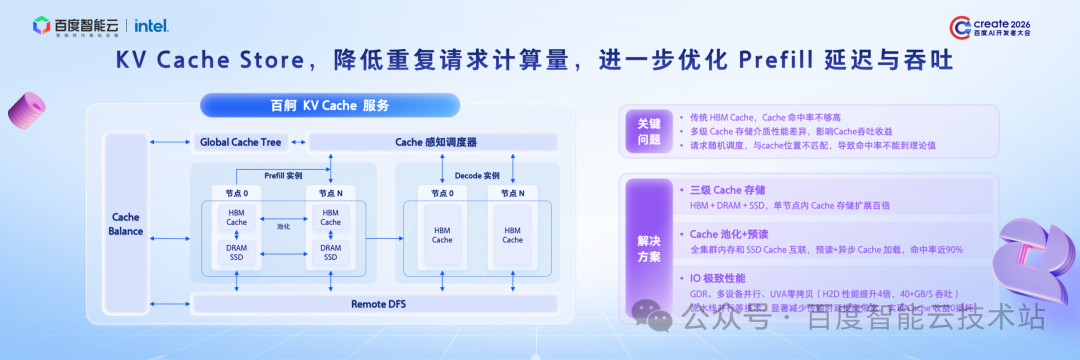
接下来介绍 Decode 相关优化。
Decode 的核心功能是生成大量数据,其面临的核心问题与前文提及的 Prefill 阶段类似:单个请求占用的 KV Cache 资源过多,HBM 仅能存储少量请求的 KV Cache,导致系统并发性能无法提升。
结合 DSA 架构,我们找到了优化方向:DSA 结构的核心计算逻辑是,针对每个 Token,无需与所有 Token 进行计算,仅选取 Top 2K 或 1K 的 Token 进行计算。这一设计为优化提供了空间:我们仅在 HBM 中存储这 2K Token,将全量 KV Cache offload 在内存中,可大幅提升系统并发性能。
这一优化同样面临三个问题,我们针对性提出了解决方案:
-
DSA 架构选取的 Top 2K Token 具有较强的离散性,而 I/O 层面访问离散小块数据的性能较差。针对这个问题,我们借助底层 UVA 机制,实现了一个专门用于传输离散小块数据的算子,使传输效率接近带宽极限。
-
除此之外,我们进一步分析发现:Decode 的每一轮迭代中,单个 Token 选取的最相关 Token 具有较高相似性,下一轮选取的 2K Token 与上一轮存在大量重叠。基于此,我们将大部分 2K Token 在执行后仍保留在显存中,下一轮通过淘汰机制选取新增 Token 即可,这样就进一步降低了需加载的 Token 数据量。
-
采用 Overlap 策略,实现数据传输与计算的并行------加载部分 Token 后即可启动后续计算,无需等待全部 Token 加载完成。
在上述三项技术的协同作用下,Decode 阶段的 Offload 成为可能,系统并发度实现数倍提升,相关成本也随之降低数倍。
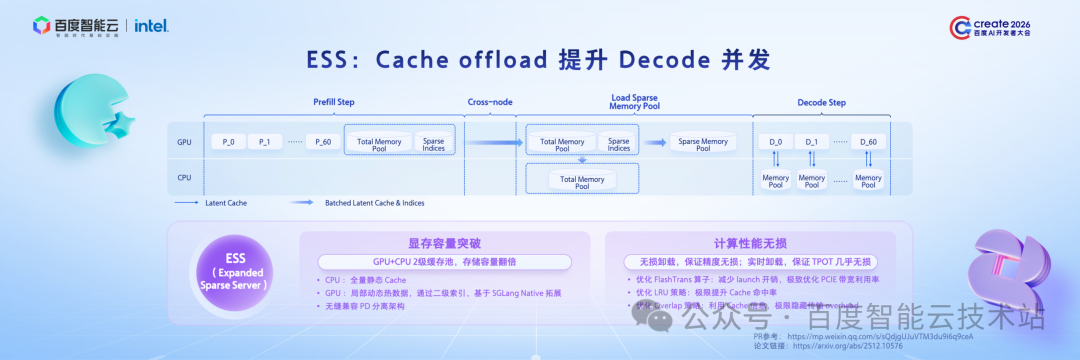
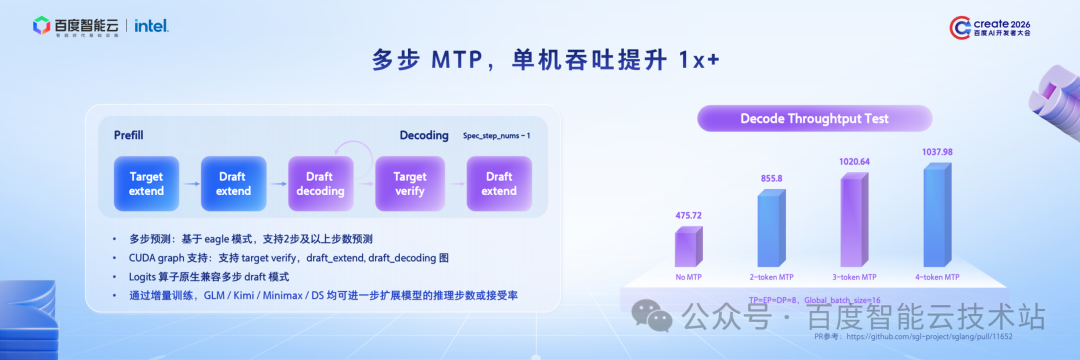
在 Decode 阶段,MTP 技术同样是性能优化的关键。
DeepSeek-V3.2 这一先进模型发布后,我们率先完成了 MTP 适配,并将相关PR贡献至社区,供大家参考。
除适配先进模型的 MTP 外,我们还针对行业痛点进行了进一步探索:一方面,并非所有 Agent 模型都开源了 MTP,例如 Kimi、MiniMax 等;另一方面,即便如 DeepSeek,也仅开源了一层 MTP。而推理过程中,推理步数越多、接收率越高,吞吐性能提升越显著。
基于此,我们通过增量训练的方式实现两大目标:一是为 Kimi、MiniMax 等未开源 MTP 的模型,训练专属 MTP,使其在 Decode 阶段也能享受 MTP 带来的效率提升;二是为 DeepSeek 等已开源 MTP 的模型,训练更多层 MTP(典型为三层),进一步提升接收率,降低推理成本。
通过这两方面的探索,我们进一步降低了推理阶段的 Decode 成本。
除上述系统性优化外,为确保引擎在各类场景下均能实现性能与成本的最优平衡,我们还开展了大量精细化优化工作。例如:
-
彻底消除引擎层面的 Schedule 开销------ GPU 持续高效运行是提升系统效率的关键,而引擎不可避免会产生 Schedule 开销,我们通过异步化、提前 Launch 等技术,将这类开销降至最低。
-
Kimi 及未来各类新模型将逐步原生支持多模态,多模态会包含 VIT 和 LLM 两种结构,二者计算量存在差异。我们通过 EPD 分离,将 VIT 部分与 LLM 部分进一步分离,结合实战经验,可将多模态推理性能提升 2 至 3 倍;
-
通过融合算子、其他引擎优化机制等,进一步挖掘性能潜力。唯有通过这些极致的精细化优化,才能将整个推理阶段的性能与成本优化至最佳状态。

最后,我将简要分享百度百舸在芯片层面的布局。
除提升引擎本身性能外,选择高性价比芯片、降低 Token 成本,也是百度百舸的核心责任。在昆仑芯硬件平台上,为了实现规模化应用并发挥其成本优势,我们重点着眼于以下两个核心问题:
第一,模型适配问题。接触过国产芯片的同仁都清楚,以往国产芯片的模型适配成本较高------国产芯片与 GPU 的工作机制存在差异,需大量修改代码,操作繁琐。针对这一问题,去年我们与 vLLM 社区合作,基于 device-plugin 相关机制开源了 vLLM-Kunlun 项目,旨在实现模型的快速、顺畅适配;借鉴 vLLM-Kunlun 的成功经验,我们也将相关 PR 提交至 SGLang 社区,未来大家也可在 SGLang 社区中获取相应能力。
借助这一机制,在适配国产芯片时,用户仅需实现国产芯片特有能力即可,无需改动 vLLM 主框架代码,模型注册、算子注册等抽象环节均已提前完成。这为国产芯片的普及应用、降低行业成本扫清了重要障碍。
第二,精度与性能优化问题。我们在昆仑芯上投入大量资源优化相关算子,确保其精度与性能均达到 GPU 同等水平。
未来,我们将持续加大投入,推动国产芯片不断完善,不仅在推理引擎层面提升性能,更将为行业提供更多高性价比芯片选择,进一步降低 Token 成本。

百度百舸始终致力于把握大模型发展趋势,无论是早期 DeepSeek 模型架构带来的行业变革,还是当前 Agent 技术引发的上下文长度提升挑战,我们都将提前布局推理引擎与算力技术,为行业提供更优质、更高效的解决方案。
