本文整理自 2026 年 5 月 14 日 Create2026 百度 AI 开发者大会 - 具身智能专场,百度智能云主任架构师应茹的同名主题演讲。

云上的具身智能研发正在分成两大方向,第一类是操控类模型,主要服务于叠衣服、拆快递等长程的精细操作任务;第二类是运动控制类策略,面向平衡控制与敏捷反应,服务于武术、舞蹈等高难度全身协同运动。
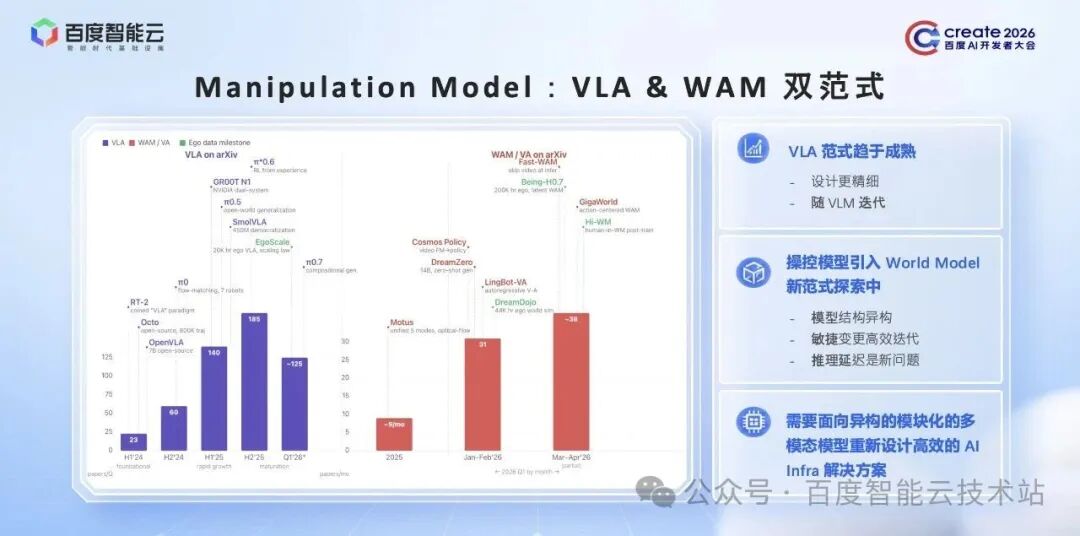
首先看操控类模型。当前研究仍以 VLA(视觉-语言-动作)为主干范式,大体从两个层面推进。
一是 VLA 自身的架构演进,常见架构分为双系统分层与单体两类:双系统分层架构中,上层由大规模 VLM 构建「通用大脑」(如大于 200B 的 MoE 结构),承担高层语义推理与长程任务拆解,下层由高频策略完成实时动作映射;单体结构的 VLM backbone 通常控制在 10B 以内,端到端输出动作。
二是 VLA 引入世界模型(WM,World Model)的路线,覆盖合成数据引擎、视频-动作联合建模(WAM,World Action Model)等多种形态,旨在让模型显式建模动作对环境状态的改变,使策略不仅能感知当前世界,还能在内部预演动作交互后的状态演化,从而在长程任务与跨本体迁移上获得更强的泛化能力。从公开学术成果的统计趋势来看,
两条路线目前都在快速推进。VLA 经过 2025 年集中的研发和成果的爆发,其架构与设计范式逐步形成共识。
站在 AI Infra 视角,当下 VLA 范式对 Infra 的核心诉求是最新 VLM backbone 的高效的后训练支持。
引入 WM 的路线,在最近 4 到 5 个月内出现了的云端大规模世界模型训练需求。行业内正积极探索 VLA 模型如何引入世界模型 WM,既有将世界模型作为 VLA 的外挂模块生成未来帧,也有将世界模型直接引入 VLA 进行混合训练,整体处于快速试错与范式探索阶段。这一过程中,AI Infra 需要提供一套能够兼顾灵活性和效率的训练框架。
额外值得注意的是,引入世界模型之后,由于其 Diffusion 结构特性,在推理部署阶段会带来显著的延迟,制约高频闭环控制,这也需要 AI Infra 针对性地设计高效的解决方案。
在运动控制策略领域,近期一个显著的行业趋势是:研发需求正逐步从本地向云端迁移。这一转变背后的深层原因,可以从技术演进的脉络中找到解答。
如下图左侧所示,当前主流的运动策略训练范式主要表现为单类动作对应独立策略。这种模式需要为不同动作单独设计奖励函数(Reward Function),导致其难以实现规模化扩展(Scaling)。此外,该范式下单个策略所需的算力资源较少,通常仅依赖 1-2 台机器。
然而,行业目前正加速向统一策略与规模化扩展(Scaling)转变。在此,我们总结了两个标志性的发展线索:
-
学术与开源界的突破(NVIDIA SONIC): 该项工作利用海量的人类动捕数据生成密集的训练信号,成功取代了传统的手工设计奖励函数。在这一全新范式下,运动控制策略的参数量从 1M 成功扩展(Scale)至 40M,最终打造出一个统一的全身控制策略。
-
工业界的落地(Figure AI 「System 0」): 工业界头部企业 Figure AI 在发布 Helix 02 时,首次提出了「System 0」概念。作为底层的统一控制策略,System 0 彻底替代了以往独立、割裂的动作控制范式。
无论是开源学术界还是工业界,其技术演进思路已高度趋同:即利用统一的全身控制底座,全面替代传统碎片化的控制策略。随着策略训练规模扩大,以 SONIC 为例,其典型训练规模已达 128 卡。
研发面临的挑战从单机管理跃升为数十台机器的分布式调度与部署,全面上云已成为行业的必然选择。在此背景下,一套面向运动控制策略研发的全流程工作流(Workflow),已成为决定策略迭代效率的关键基础设施。

为精准匹配操作类模型与运动控制类策略的研发需求,百度百舸构建了一套全流程具身智能 Workflow ,以底层高性能计算、存储系统、机间高速互联网络为基础,覆盖具身智能研发的典型环节,实现从数据准备 - 开发训练 - 仿真 - 推理环节的全链路赋能。
-
首先是数据准备环节,百度百舸预置了简智无本体数据集、智源双臂机器人真机数据集等热门开源数据集。同时集成了开源数据集高频使用的数据格式转换算子,以及运动控制策略动捕数据所需的重定向算子。以及运动控制策略动捕数据所需的重定向算子。当前,我们也正在准备 Egocentric data 所需的数据清洗和标注的常用算子。
-
数据准备完成后,可以通过分布式存储挂载至开发训练集群,方便地开始训练,我们在这里会提供通用的训练加速套件。
-
训练的阶段性 Checkpoint 产生时,可以使用百舸预置的各类主流仿真环境和任务集,进行效果评估,这里也会涉及到推理,如我们刚才所提到的世界模型会有推理瓶颈,我们针对其 Diffusion 结构、VAE Encoder 结构也提供了专门的加速方案。

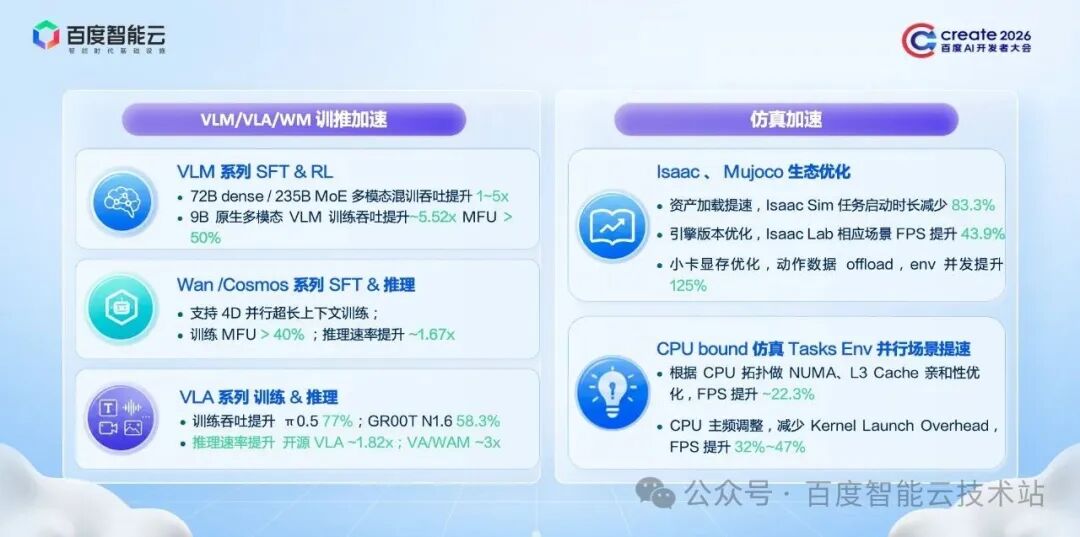
在操控类模型训练环节中,不同技术路线对应不同的模型结构与参数量,这对分布式训练提出多样化需求。比如大小脑分层的双层 VLA 设计,「大脑」部分通常达到非常大的规模量级,从云上视角来看,这属于大于 200B 的 MoE 分布式训练,百度百舸积累了大量此类模型后训练优化的基础设施经验,高效支撑大规模训练需求。
在尝试快速引入世界模型的过程中,我们发现行业内普遍存在模型结构高度模块化、且结构频繁迭代的问题。若采用天然兼容 Hugging Face 的开源框架,则多机分布式训练的加速效果不佳;如果选用加速效果极致的框架,通常无法灵活修改模型结构。针对这一痛点,百度百舸面向各类灵活的开源框架提供加速套件,帮助研发人员在训练效率与模型灵活性之间找到平衡点。
另外,我们注意到,当前阶段,单体 VLA 或引入世界模型的 WAM 的参数量大约是 5B 到 20B 的量级,我们将这类模型定义为中型尺寸模型。这类模型的训练需要的算力是什么样的?是算力越大越好吗?
近期 DeepSeek V4 技术报告中有一个非常有意思的论点:卡间或机器间每 GB 互联带宽所能支撑的模型算力存在一个合理值。引申来看,如果模型尺寸没有达到这个算力值,超配的带宽就是浪费。对于20B 量级以下的 VLA 或 WAM 模型,盲目堆砌最高端的硬件配置,不仅不会带来等比例的性能提升,反而会造成显存、带宽、算力等多个维度的资源错配,推高研发成本。这正是我们近期重点推进的工作之一。
我们详细评测了此类中型尺寸模型所需的算力、显存带宽以及多机之间的互联带宽,针对这类模型,在当前的算力供应背景下,我们提供了一套高性价比的服务器算力配置,同时配套提供多机训练加速套件,让用户能够获得理想的多机加速比,也为这个阶段的具身模型研发提供更多的配置选择。

另一个是运动控制策略,我们观察到运动控制策略正朝着统一化、Scaling 的方向快速发展。针对这一趋势,百度百舸在云上提供了集成 NVIDIA 开源的 WBC-AGILE 框架,它是一套覆盖资产准备、调试、训练、评估等环节的运动控制策略研发流水线。
基于这套流水线,百度百舸重点开展了两方面优化工作:
-
首先,基于 Scaling 的需求,我们针对性优化了多机之间的通信效率,确保多机训练的高效推进;
-
运动控制策略的训练通常基于小卡开展,而小卡的核心痛点是显存资源珍贵且紧张,我们会针对特定的场景,对显存里的部分内容 offload 到 Host 的内存,释放出更多显存空间,这些空闲显存可用于开启更多仿真环境的并行数。从而让用户在使用相同卡数量的情况下,获得更大的训练吞吐量,提升训练效率。
同时,百度百舸也在积极跟进开源学术领域的最新进展。例如,几周前 SONIC 将其训练配方开源后,百度百舸第一时间集成,支持用户一键 scale 到 128 张卡上,尝试复现 SONIC 的训练效果。
此外,上海交通大学穆尧老师实验室研发的 CLOT 全身控制策略训练方案,百度百舸也第一时间集成,进一步丰富了研发工具矩阵。

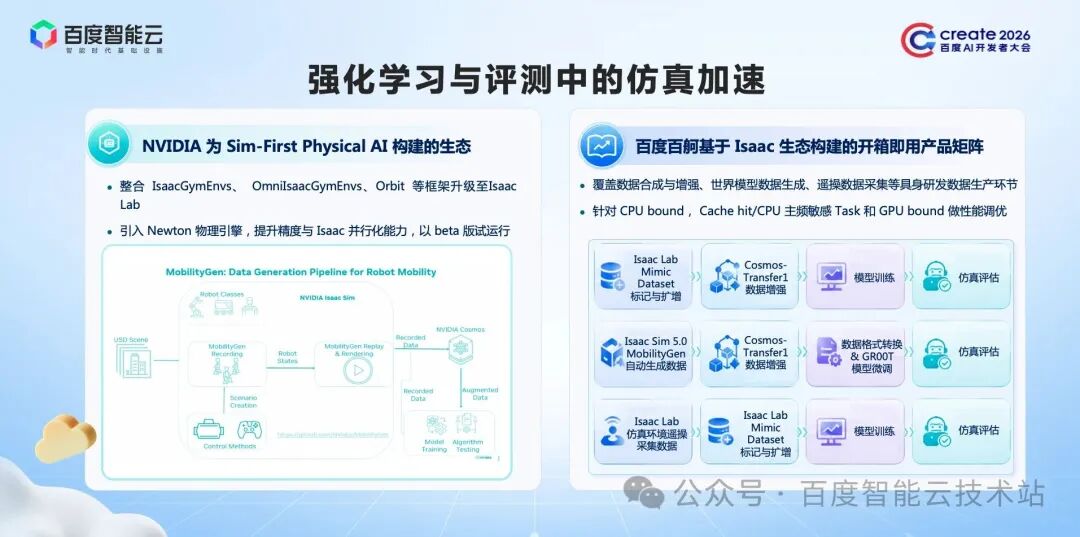
在我们的研发流水线中,仿真环境是强化学习及模型测评过程中的关键环节。
以英伟达仿真生态为例,它具有高度模块化的特点,由多个模块组合而成。但用户在具身智能场景中使用时,需手动完成多个模块的串联,且模块间存在版本兼容性问题。即便部署成功,版本不兼容也会导致性能衰退。
对此,百度百舸为用户常用场景的提供了模块组合的镜像,实现仿真环境开箱即用,大幅降低使用门槛。
同时,我们在研究中发现,仿真环境的引擎源于 CPU 时代,这意味着大量仿真任务未能完全卸载至 GPU,属于 CPU 算力敏感型任务。针对此类场景,我们对 CPU 拓扑进行了细致的调优,让这类仿真任务能够在 CPU 上实现高速运转。
另外,我们也在跟进 NVIDIA 对于仿真引擎的研发迭代,比如我们发现部分场景下,升级 Newton 物理引擎代替原有的 Phyx 引擎,RL 吞吐会有接近 50%的提升。我们也会大家持续跟进这样的进展,及时把业界新的高效的能力,集成到百舸。
在支撑具身智能行业发展的这段时间里,百度百舸已积累了大量技术优化成果,用户可通过百度百舸的通用加速套件或 Docker 镜像,一键享受相关加速效果。额外需要说明的是, VLA 引入世界模型后,在推理部署环节可能会出现推理延迟瓶颈。
近几周,我们重点针对开源领域具有影响力的 WAM 模型开展工程化加速工作,取得了较为理想的效果,将其推理延迟降低至原有水平的 1/4。这一实践也带给我们深刻思考:我们在行业中看到了大量的算法创新,而工程优化同样具有重要价值。我们希望与更多企业开展深度合作,将算法创新与工程优化深度融合,共同推动行业发展。
百度百舸依托底层高性能计算、自研昆仑芯、超节点等核心资源,深度服务于具身智能全流程研发工作。目前,百度智能云已通过百度百舸,服务于北京、上海创新中心等具身智能「国家队」,同时也为产业链内超过 30 家具身智能头部企业提供支撑。未来,我们希望与更多企业开展深度合作,为企业在创新背景下抢占发展先机提供核心能力支撑。