从需求到可维护的状态机:3423 行代码的治理经验
今年上半年,我开发了一个售前方案生成 Agent。业务需求很直接:用户输入项目需求,Agent 自动生成方案文档,在关键节点让人确认,支持断点续传。
半个个月后,我面临一个问题:**代码已经 3423 行,但这不是因为写得太乱,而是业务逻辑本身就复杂。** 需求解析、多方案生成、人机确认、断点续传、知识库检索、多格式导出......这些功能挤在一起,即使结构清晰,改一个地方也要在多个文件间跳转。
这不是代码质量的问题,而是**架构的问题**。
这篇文章记录了我如何用 LangGraph 重新设计这个 Agent 的架构。如果你也在构建复杂的 AI Agent,希望这些经验能帮到你。
一、业务全景:Agent 到底要做什么?
1.1 核心流程
售前方案生成不是一个"输入→输出"的简单过程,而是一个**多阶段、多确认、可中断**的复杂流程:
Phase 1: 需求分析
用户输入 → 意图识别 → 项目档案补全 → 方案规划
↘ 信息不足 → 追问用户
Phase 2: 需求确认 + 模板选择
必填字段收集 → 功能点匹配 → 需求确认 → 模板检索/选择
Phase 3: 文档生成(逐章推进)
模板检索 → 大纲生成 → 确认 → 输出格式选择 → 逐章生成 → 确认 → 下一章
↘ 用户反馈 → 基于原文修改
Phase 4: 导出交付
所有章节通过 → 组装方案 → docx/pptx/飞书导出 → 完成
1.2 关键挑战
| 挑战 | 具体表现 | 技术难点 |
|------|---------|---------|
| 多阶段状态 | 需求收集、大纲确认、章节生成... 每个阶段状态不同 | 状态管理、持久化 |
| 人机协作 | 每个关键节点都要等用户确认或修改 | 中断恢复、子图路由 |
| 可中断性 | 用户可能聊到一半离开,明天继续 | Checkpoint、恢复机制 |
| 内容质量 | 生成的内容要有据可查,不能凭空捏造 | RAG、引用追踪 |
| 多方案并行 | 一个项目可能有技术方案+实施方案+运维方案 | 跨方案状态共享 |
1.3 技术选型
| 组件 | 选型 | 核心理由 |
|------|------|---------|
| Agent 框架 | LangGraph | 原生支持状态机、人机确认、Checkpoint |
| 向量检索 | Qdrant | 本地部署简单,支持双 Collection |
| 持久化 | PostgreSQL + JSONB | 团队熟悉,LangGraph Checkpointer 官方支持 |
| LLM | Qwen(主)+ DeepSeek(备) | 国内可用,结构化输出稳定 |
二、架构设计:从混乱到有序的三层结构
2.1 整体架构图
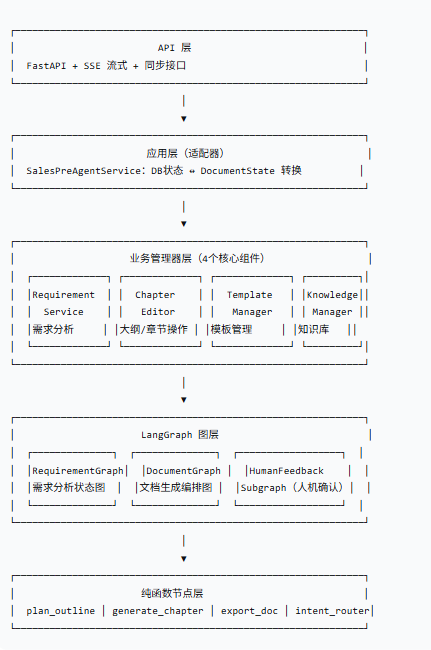
2.2 核心设计原则
在设计这个架构时,我遵循了三个原则:
**原则 1:统一状态,单一事实来源**
所有节点通过 `DocumentState` 通信,不共享 `self.xxx`。新增字段只改一个地方。
**原则 2:节点纯函数化**
每个节点只做一件事,输入输出都是 `DocumentState`。易测试、易修改。
**原则 3:交互逻辑子图化**
人机确认有 6+ 种分支,用子图封装,每个 handler 独立文件。
三、核心实现:三个关键设计决策
决策 1:统一状态模型 `DocumentState`
**问题**:最初状态散落在 9 个 Pydantic 模型 + DB 的 JSONB 列中,加一个字段要改 5 个文件。
**解决方案**:设计统一的 `DocumentState`,作为所有节点的唯一数据契约。
python
class DocumentState(BaseModel):
"""所有节点共享的统一状态"""
# === 会话标识 ===
session_id: str
request_id: str
# === 业务状态 ===
solution_type: str # 方案类型
profile: ProjectProfile # 项目画像
outline_sections: List[str] # 大纲章节列表
chapters: Dict[int, str] # 已生成章节
current_chapter_idx: int # 当前章节索引
# === 控制流 ===
status: SessionStatus # 会话状态枚举
need_human_review: bool # 是否需要人确认
pending_action: Optional[str] # 等待的用户动作
# === 持久化 ===
version: int # 乐观锁版本
updated_at: datetime**关键设计**:
-
所有字段都是可序列化的(Pydantic 自动处理)
-
`status` 枚举明确定义了所有可能的状态
-
`need_human_review` + `pending_action` 实现了"中断等待用户输入"模式
决策 2:人机确认子图化
**问题**:用户交互有 6+ 种类型(确认、修改章节、修改大纲、重新生成、选择模板......),全部写在一个 `_handle_waiting_user_input` 方法里,新增一种类型要改多个分支。
**解决方案**:将人机确认封装成独立子图,每个处理器独立文件。
python
# subgraphs/human_feedback/graph.py
def build_human_feedback_graph():
builder = StateGraph(DocumentState)
# 路由节点:判断用户意图
builder.add_node("router", intent_router_node)
# 处理器节点
builder.add_node("confirm_continue", confirm_continue_handler)
builder.add_node("modify_chapter", modify_chapter_handler)
builder.add_node("modify_outline", modify_outline_handler)
builder.add_node("regenerate_outline", regenerate_outline_handler)
builder.add_node("select_template", select_template_handler)
builder.add_node("fallback", fallback_handler)
# 条件路由
builder.add_conditional_edges(
"router",
lambda state: state.pending_action, # 根据动作类型路由
{
"confirm_continue": "confirm_continue",
"modify_chapter": "modify_chapter",
"modify_outline": "modify_outline",
"regenerate_outline": "regenerate_outline",
"select_template": "select_template",
"other": "fallback",
}
)
return builder.compile()**效果**:
-
新增一种确认类型:新建一个 handler 文件 + 在 router 中加一条映射
-
修改某种确认逻辑:只改对应的 handler,不影响其他
-
每个 handler 可以独立测试
决策 3:双 Graph 协作
**问题**:
需求分析和文档生成是两种不同性质的流程。前者是多轮对话式的信息收集,后者是线性的章节生成。放在一个 Graph 里会让状态爆炸。
**解决方案**:
拆成两个独立的 Graph,由适配器层协调。
python
```python
# RequirementGraph:需求分析专用
# 节点:intent → profile_completion → planner
# 特点:多轮对话、信息补全、追问
# DocumentGraph:文档生成专用
# 节点:plan_outline → generate_chapter → export_doc
# 特点:线性推进、逐章生成、支持修改
```**协作流程**:
python
# 适配器中的状态转换逻辑
class SalesPreAgentService:
async def process(self, user_input: str, request_id: str):
state = self._load_state(request_id)
if state.status == "collecting_requirement":
# 需求分析阶段:使用 RequirementGraph
state = await self.requirement_graph.ainvoke(state)
elif state.status == "generating_document":
# 文档生成阶段:使用 DocumentGraph
state = await self.document_graph.ainvoke(state)
elif state.status == "waiting_confirmation":
# 人机确认阶段:使用 HumanFeedbackSubgraph
state = await self.human_feedback_graph.ainvoke(state)
self._save_state(request_id, state)
return state四、断点续传:让用户可以随时离开
这是 LangGraph + PostgreSQL Checkpointer 最实用的特性。
4.1 实现原理
python
from langgraph.checkpoint.postgres import PostgresSaver
# 初始化 Checkpointer
checkpointer = PostgresSaver(conn_string=DATABASE_URL)
# 编译 Graph 时传入
graph = builder.compile(checkpointer=checkpointer)
# 调用时传入 thread_id(会话标识)
config = {"configurable": {"thread_id": request_id}}
result = await graph.ainvoke(state, config=config)
# 下次调用时,用同样的 thread_id 自动从上次中断处恢复
result = await graph.ainvoke(user_input, config=config)4.2 关键设计:显式的中断点
不是所有地方都需要断点续传。我只在两个场景设置中断:
-
**等待用户输入**(`WAITING_USER_INPUT`):需求信息不足时
-
**等待用户确认**(`WAITING_USER_CONFIRMATION`):大纲/章节生成后
python
# 需要中断时的处理
def plan_outline_node(state: DocumentState):
outline = generate_outline(state)
state.outline_sections = outline
state.status = "WAITING_USER_CONFIRMATION"
state.pending_action = "confirm_outline"
# 返回时自动触发中断,状态被持久化
return state五、效果与经验
5.1 重构后的量化指标
| 指标 | 重构前 | 重构后 |
|------|--------|--------|
| 最长文件行数 | 3423 行 | ~400 行 |
| 新增确认类型耗时 | 2 小时(改 4 个分支) | 20 分钟(新增 1 个 handler) |
| 修改生成逻辑影响范围 | 可能波及路由 | 只改对应节点 |
| 单元测试覆盖 | ~10% | ~60% |
| 新人理解代码时间 | 1 周 | 2 天 |
5.2 最重要的 3 个经验
**经验 1:先统一状态,再谈拆分**
没有清晰的状态定义,拆出来的节点会互相污染。花 1 天设计 `DocumentState`,后续省 10 天。
**经验 2:子图是管理复杂度的核武器**
6+ 种人机确认分支,一个子图全部封装。主 Graph 只看得到 `human_feedback` 这个节点,细节全在内部。
**经验 3:Checkpointer 不仅仅是断点续传**
有了 Checkpointer,你可以:
-
调试:重放任意一次执行过程
-
回滚:回到上一个稳定状态
-
审计:查看完整的执行历史
六、下一步:从可用到可靠
虽然架构已经稳定,但还有一些工作在进行中:
-
**可观测性**:接入 LangSmith,追踪每次调用的 token 消耗和延迟
-
**评估体系**:用 RAGAS 建立 RAG 效果评估,量化每次优化
-
**容器化**:补全 Dockerfile 和 docker-compose,降低部署门槛
-
**成本控制**:实现 token 预算熔断,防止意外超支
## 写在最后
回顾这个项目,最大的感悟是:**AI Agent 的复杂性不在 AI,在 Agent。**
LLM 调用很简单,难的是状态管理、人机协作、断点续传、多流程编排。LangGraph 提供了很好的基础设施,但如何组织代码、如何分层、如何让系统可维护,这些问题框架不会替你回答。
如果你也在做类似的 Agent,希望这篇文章能给你一些启发。欢迎交流讨论。