1、如何设计测试用例*
测试按照测试方法可分为白盒测试、黑盒测试、灰盒测试。
白盒测试 :通过检查软件内部的逻辑结构,对软件中的逻辑路径进行覆盖测试,在程序不同地方设立检查点,检查程序的状态,以确定实际运行的状态与预期状态是否一致。常用的测试方法有语句覆盖 (每个语句至少执行一次)、判定覆盖 (判定语句需要测试为真的情况,还要测试为假的情况)、条件覆盖(在多个条件的组合下,每个条件都要测试为真/为假的情况)
黑盒测试 :在完全不考虑程序逻辑和内部结构的情况下,检查系统功能是否按照需求规格说明书的规定正常使用,是否能适当地接收输入数据而输出正确的结果,满足规范需求。只注重软件的功能。常用的测试方法有等价类划分 (根据需求将输入划分为若干个等价类,从等价类中选一个作为测试用例,如果此用例通过,则所代表的等价类通过)、边界值分析 (边界值有效,则次边界值无效;反之亦反)、场景法 、判定表法 、正交法 、错误猜测法
灰盒测试:多用于集成测试阶段,关注输入输出的正确性,关注程序的内部情况
2、三次握手的具体过程,为什么是三次*
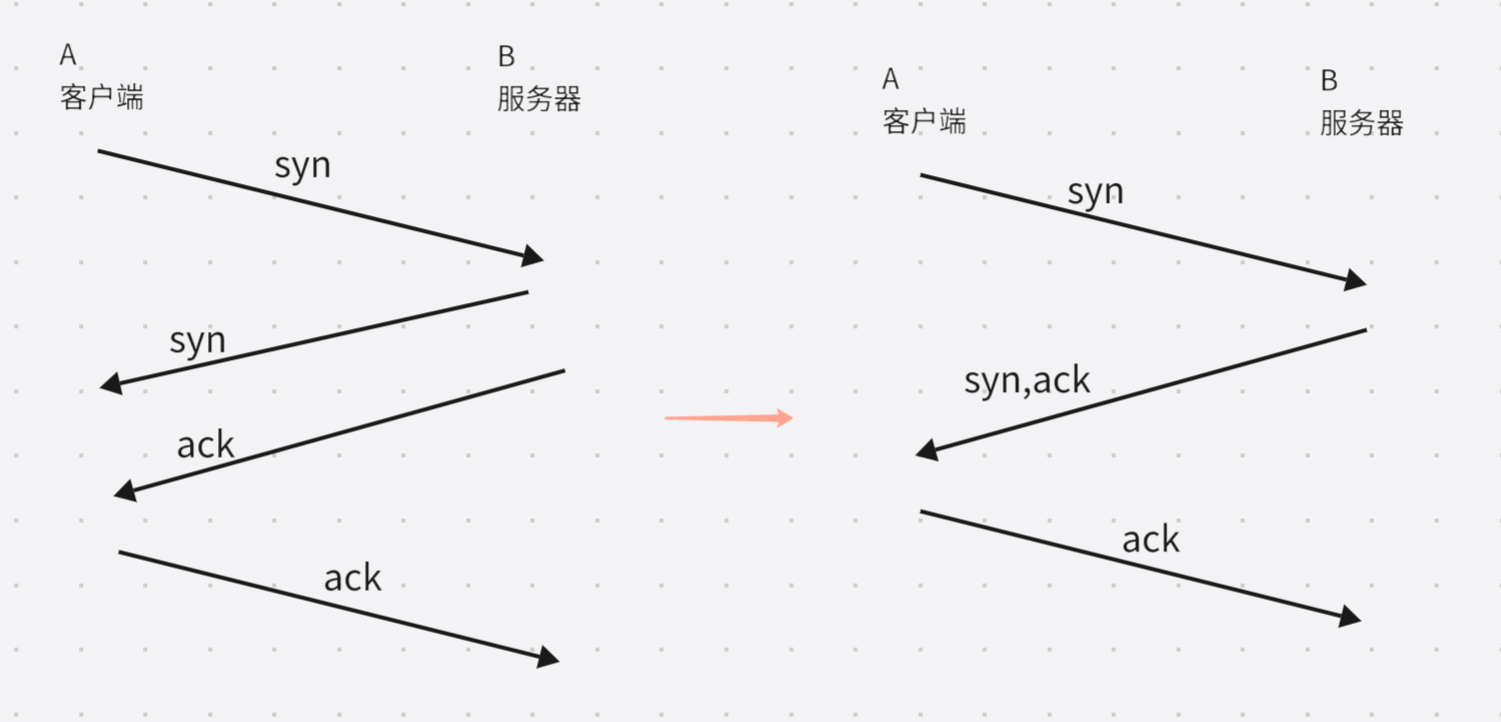
具体过程:
(1)客户端向服务端发送syn报文,表示请求建立连接。
(2)服务端收到syn后,回复syn+ack报文,表示同意连接。
(3)客户端收到服务器的syn+ack后,回复ack报文,连接建立成功。
意义:
(1)初步验证通信链路是否畅通(可靠传输的前提)
(2)确认通信双方各自的发送能力和接收能力是否正常
(3)让通信双方在通信之前,对通信过程中需要用到的一些关键参数进行协商(TCP通信时起始序号是通过三次握手协商确定的,并不从1开始,每次建立连接,TCP的起始序号都不同)
三次握手一定是三次:中间两次的akc,syn都是在内核中,由操作系统负责的时机都是在syn后,此时同一时刻可以合并
3、Redis数据类型,各类型的应用场景*
|--------|----------------|-----------------------|--------------------|
| 数据类型 | 特性 | 应用场景 | 编码方式 |
| String | 最基础,键值存储,二进制安全 | 缓存、计数器、分布式锁、session共享 | raw、int、embstr |
| hash | 字段-值映射表,适合存储对象 | 用户信息、商品详情、购物车 | hashtable、ziplist |
| list | 有序双向链表 | 消息队列、最近联系人列表、时间轴 | linkedlist、ziplist |
| set | 无序集合,自动去重 | 共同好友、标签系统、抽奖去重 | hashtable、intset |
| zset | 有序集合,按score排列 | 排行榜、带权重的任务队列、延迟队列 | skiplist、ziplist |
4、GET、POST*
没有本质区别,使用习惯上有区别。
|---------|------------------------------|----------------------|
| 区别 | GET | POST |
| 语义 | 从服务器拿数据 | 往服务器提交数据 |
| 传递数据的方式 | 通常通过query String把自定义的数据交给服务器 | 通常通过body把自定义的数据交给服务器 |
| 幂等性 | 对应的请求通常设计成幂等的 | 对应的请求对于幂等性无要求 |
幂等性:稳定性,如不同人在浏览器上搜索同一个东西的结果通常不同(不幂等)
5、TCP、UDP*
|-----|-----|-------|-------|-----|
| TCP | 有连接 | 可靠传输 | 面向字节流 | 全双工 |
| UDP | 无连接 | 不可靠传输 | 面向数据流 | 半双工 |
6、死锁*
定义:两个或多个线程在执行过程中,因互相持有对方需要的资源而无限等待的现象。
产生死锁的必要条件:
(1)锁互斥(资源只能被一个线程同时占用)
(2)锁不可被抢占(已分配的资源只能由线程自己释放)
(3)请求和保持(线程维持已有资源的同时请求新资源)
(4)循环等待(存在线程循环等待资源的链)
解决方案:(1)避免锁嵌套(2)约定加锁顺序
7、线程池*
定义:把线程提前从系统中申请好,放到一个地方,后面需要使用线程的时候直接到那里取,用完之后也重新还到那个地方。(从线程池里取线程比从系统中申请更高效:从系统穿件就是调用系统api,由系统内核执行一系列逻辑来完成整个过程;直接从线程池中取,整个过程都是纯用户态代码,过程更可控高效。通常认为纯用户态操作比经过系统内核的操作更高效。)
ThreadPoolExcutor核心参数
|-------------------------------------|--------------------|
| 参数 | 含义 |
| int corePoolSize | 核心线程数(始终存在于线程池内部) |
| int maximumPoolSize | 最大线程数(繁忙时创建,空闲时释放) |
| long KeepAliveTime | 非核心线程空闲的最长时间 |
| TimeUnit unit | 时间类型 |
| BlockingQueue<Runnable> workQueue | 工作队列 |
| ThreadFactory threadFactory | 线程工厂 |
| RejectedExcutionHandler handler | 拒绝策略 |
执行流程:
提交任务------判断核心线程是否满------判断阻塞队列是否满------判断最大线程是否满------触发拒绝策略
拒绝策略:
(1)添加任务时,直接抛出异常
(2)线程池拒绝执行,由调用submit的线程负责执行
(3)把任务队列中最老的任务踢掉,执行新增加的任务
(4)把任务队列中最新的任务踢掉,执行新增加的任务
8、内存垃圾回收*
垃圾回收就是内存回收(以对象为维度进行回收,也可以说是回收对象)
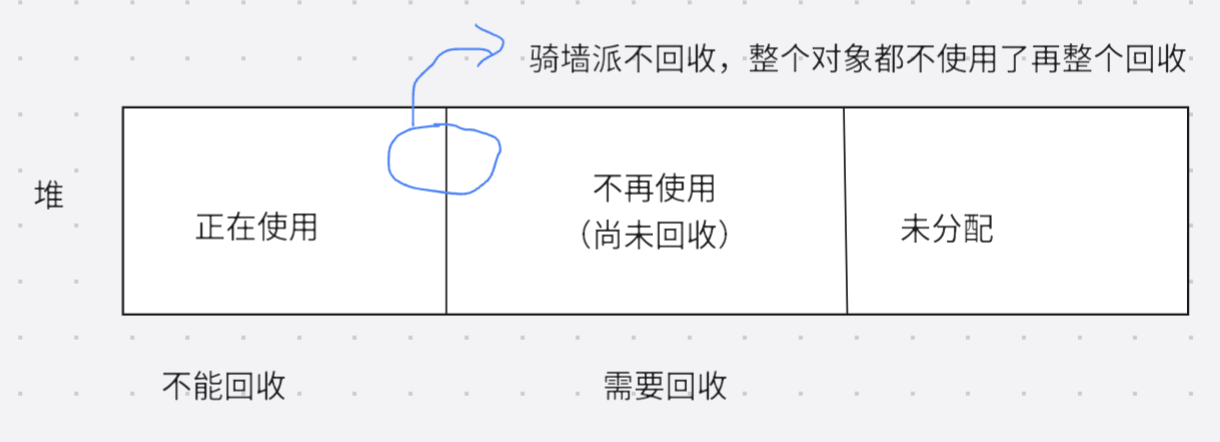
JVM垃圾回收过程
(1)找出谁是垃圾(不再使用的对象)
①引用计数:给每个对象分配一个计数器,衡量有多少个引用。计数器计算引用数(增加一个对象,计数器+1;减少一个对象,计数器-1),计数器为0时,对象就是垃圾。
②可达性分析:JVM中有一种周期性线程,扫描代码中的所有对象,判断某个对象是否可达(能被访问),对应的不可达(不可访问)对象就是垃圾。
(2)释放垃圾的内存空间
①标记-清除:直接对内存中对应的对象进行释放(会引入碎片问题,后续申请内存可能失败)
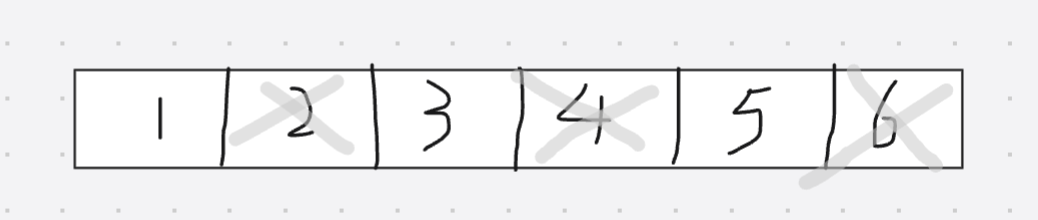
②复制算法:将空间一分为二,只使用其中一半,把不是垃圾的对象拷贝到另一侧,同寝室确保拷贝对象是连续的,然后把另一半空间释放(内存利用率低,若存活下来的对象比较多,复制成本比较大)
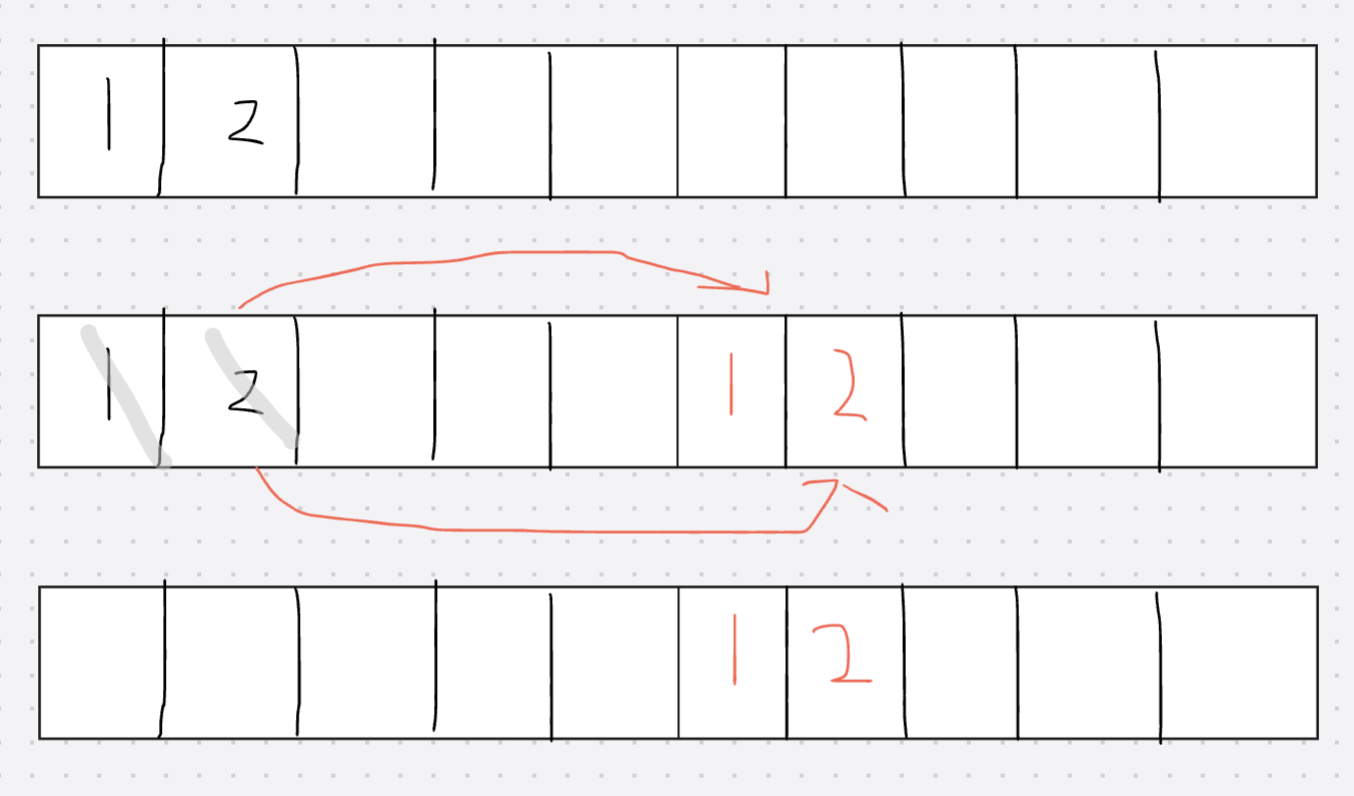
③标记整理:类似于顺序表删除中间元素(效率较低)
*真正机制------分代回收:新生代用复制算法,老年代用标记-清除/标记-整理算法,元空间仅在类卸载、常量池清理时触发回收。
9、SQL*
| 分类 | 命令 | 作用 |
|---|---|---|
| DQL | SELECT |
数据查询 |
| DML | INSERT、UPDATE、DELETE |
数据增删改 |
| DDL | CREATE、ALTER、DROP |
数据结构定义 |
| DCL | GRANT、REVOKE |
权限控制 |
| TCL | COMMIT、ROLLBACK |
事务控制 |
|---|----------------------------------------------------------------------------------|
| 增 | insert into 表名 values(值,值,值),(值,值,值),...... |
| 删 | delete from 表名 where 条件 |
| 查 | select 字段 from 表名 where 条件 order by 字段 limit n; select 字段 from 表1 join 表2 on 条件; |
| 改 | uodate 表名 set 列名=指,列名=值...... where 条件 |
10、分布式消息队列Redis
11、websocket、http
| 维度 | HTTP | WebSocket |
|---|---|---|
| 通信模式 | 单向请求-响应 | 全双工双向通信 |
| 连接方式 | 短连接,每次请求需重建(HTTP/1.x) | 长连接,保持持久 |
| 头部开销 | 每次请求都携带HTTP头 | 仅握手时携带,后续极少 |
| 实时性 | 较低(需轮询) | 高 |
| 应用场景 | 页面加载、REST API | 在线聊天、实时游戏、推送 |
12、Linux常用命令
| 分类 | 常用命令 | 作用 |
|---|---|---|
| 文件/目录 | ls -al、cd、pwd、cp、mv、rm -rf |
浏览、切换、复制、移动、删除 |
| 查看文件内容 | cat、more、less、head -n、tail -f |
查看完整/分页/前几行/实时日志 |
| 权限管理 | chmod、chown |
修改权限和所有者 |
| 进程管理 | ps aux、top、kill -9、killall |
查看进程、监控、终止进程 |
| 网络 | netstat -anp、ss、ping |
端口监听、网络连通测试 |
| 文本处理 | grep、awk、sed |
搜索、过滤、替换 |
| 压缩解压 | tar -czvf、tar -xzvf |
打包压缩/解压 |
| 查看日志 | tail -f、less、grep |
实时跟踪过滤日志 |
13、软件测试流程*
需求分析------测试计划------测试设计------测试执行------测试评估------上线------运行维护
14、标准的测试用例要满足什么
| 标准 | 说明 |
|---|---|
| 完整性 | 包含编号、标题、前置条件、测试步骤、测试数据、预期结果、实际结果、优先级等核心要素 |
| 可追溯性 | 每个用例必须关联具体需求ID或用户故事编号 |
| 明确性/可执行性 | 描述清晰无歧义,步骤不熟悉业务的人也能执行 |
| 代表性 | 覆盖有效/无效等价类、边界值、典型业务场景 |
| 简洁性 | 无冗余步骤,每个用例聚焦单一检查点,建议不超过3-5个验证点 |
| 可维护性 | 易于修改和更新,遵循统一的命名规范 |
| 覆盖率 | 满足定义的功能/代码覆盖率要求 |
15、Java JVM底层原理*
(1)内存区域划分:程序计数器、堆、栈(Java虚拟机栈、本地方法栈)、元数据区
(2)类加载 :使用双亲委派模型(类加载器收到类加载请求时,先委派给父加载器加载,只有父加载器无法加载时才自己加载,保障核心类库安全)
过程 :加载 (代码中先找到类名,然后进一步找到对应的.class文件,打开并读取内容)------验证 (验证读到的.class文件的数据名是否正确合法)------准备 (分配内存空间,根据刚才读到的内容,确定类对象需要的内存空间并申请,把内存空间中所有内容初始化为0)------解析 (主要针对类中的字符串常量进行处理)------初始化(执行静态成员的初始化。若当前加载的类还有父类,且父类未被加载,则此环节也去触发针对父类的加载)
(3)垃圾回收机制:见8
16、Linux如何杀掉所有的Java进程
bash
# 方法1:killall(最简单)
killall -9 java
# 方法2:ps + kill
ps -ef | grep java | grep -v grep | awk '{print $2}' | xargs kill -9
# 方法3:pkill
pkill -9 java
# 方法4:配合pgrep -9 参数表示强制终止(SIGKILL),谨慎使用
kill -9 `pgrep java`17、http、https
| 维度 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,不安全 | SSL/TLS加密,安全 |
| 端口 | 80 | 443 |
| 证书 | 无需证书 | 需CA机构颁发的SSL证书 |
| URL前缀 | http:// |
https:// |
| 协议层 | 应用层 | SSL/TLS层之上封装HTTP |
| 连接方式 | TCP直连 | SSL握手+TCP |
| 缓存效率 | 较高 | 较低(加密影响) |
核心区别:http明文传输,https密文传输
18、Python装饰器
定义:装饰器本质上是一个接受函数作为参数、返回新函数的函数,可以在不修改原函数代码的前提下增加额外功能。
核心原理:闭包 + 函数包装------内层函数可以使用外层函数的变量。
常见应用场景:日志记录、权限校验、性能计时、缓存、事务管理
python
def decorator(func):
def wrapper(*args, **kwargs):
# 执行前的扩展逻辑
print("Before function")
result = func(*args, **kwargs)
# 执行后的扩展逻辑
print("After function")
return result
return wrapper
@decorator
def say_hello():
print("Hello")19、python with
定义 :with 语句是 try/finally 的替代方案,专门用于简化资源管理(文件操作、锁、数据库连接等),确保资源在使用后被正确释放。
工作原理:
-
执行上下文管理器的
__enter__()方法(进入代码块前) -
执行
with代码块 -
无论是否异常,都会执行
__exit__()方法(离开时),用于清理资源
实现上下文管理器的方式:
-
定义类,实现
__enter__和__exit__方法 -
使用
contextlib.contextmanager装饰器
20、try...except/finally如何工作
核心规则:
-
先执行
try块中的代码,若无异常,跳过except继续执行 -
若
try块抛出异常,跳转到匹配的except块处理 -
finally块无论是否发生异常都会被强制执行 ,即使try或except中有return,finally仍会执行后再返回 -
try至少搭配except或finally中的一个
python
try:
# 可能抛出异常的代码
except SomeException as e:
# 捕获并处理特定异常
finally:
# 无论是否发生异常,一定会执行21、浏览器输入URL的全过程
网络请求阶段:
-
URL解析:提取协议、域名、端口、路径等
-
DNS解析:将域名解析为IP地址(优先查询浏览器缓存→系统Hosts→递归DNS→迭代DNS)
-
建立TCP连接:三次握手
-
发送HTTP请求:构建并发送请求报文
-
服务器处理:处理请求并返回响应
浏览器渲染阶段 :
-
解析HTML :构建DOM树
-
解析CSS :构建CSSOM树
-
合并渲染树 :DOM + CSSOM → Render Tree
-
布局 :计算元素位置和大小
-
绘制:将渲染树转换为屏幕像素
22、进程与线程*
(1)进程包含线程,一个进程内可以有一个或多个线程,不能没有
(2)进程是系统资源分配的基本单位;线程是调度执行的基本单位
(3)同一个进程的线程之间共用一份系统资源,尤其是内存资源(代码中定义的变量/对象)编程中多个线程可共用同一份变量
(4)线程是当下实现并发编程的主流方式,通过多线程可以充分利用多核CPU
(5)多个线程之间可能会相互影响,导致线程安全问题;一个线程抛出异常可能使其他线程发生问题
(6)多个进程之间一般不会相互影响,一个进程崩溃不会影响到其他进程(进程的隔离性)
| 维度 | 进程 | 线程 |
|---|---|---|
| 定义 | 操作系统进行资源分配的基本单位 | 调度执行的基本单位 |
| 资源拥有 | 有独立地址空间和资源 | 共享所属进程的资源 |
| 内存隔离 | 进程间内存相互隔离 | 线程间共享内存,有独立栈 |
| 创建/销毁/切换开销 | 大 | 小 |
| 通信方式 | 需IPC(管道、共享内存等) | 共享内存直接通信 |
| 容错性 | 一个进程崩溃不影响其他进程 | 一个线程崩溃可能导致进程崩溃 |
联系:一个程序至少有一个进程,一个进程至少有一个线程。每个进程包含独立的堆和方法区,线程共享该进程的资源。
23、进程通信方式
| 通信方式 | 特点 | 适用场景 |
|---|---|---|
| 管道(Pipe) | 半双工,单向,仅限父子/兄弟进程 | 简单数据传输 |
| 命名管道(FIFO) | 可双向,无亲缘关系进程也可使用 | 任意进程间通信 |
| 信号(Signal) | 异步事件通知 | 进程控制、异常通知 |
| 消息队列 | 结构化消息,按类型读取 | 异步、解耦的数据交换 |
| 共享内存 | 最快IPC,多进程映射同一物理内存 | 大量数据高速交换 |
| 信号量 | 进程间同步互斥 | 控制多进程对共享资源的访问 |
| Socket | 支持跨主机通信 | 网络通信 |
24、数据库事务特性*
事务:把要执行的SQL打包成一个整体,这个整体在执行过程中要么全部执行要么一个都不执行(出错时撤销SQL,进行还原)
特性:
(1)原子性:事务中所有操作要么全部成功要么全部回滚
(2)一致性:事务执行前后,数据库中的数据都是合法状态,不会出现非法的临时结果的状态
(3)持久性:事务执行完后会修改硬盘上的数据,持久生效
(4)隔离性:描述多个事务并发执行时,相互产生的影响是怎样的(并发事务间相互隔离)
服务器同时执行多个事务就是并发执行,若这些事务恰好针对同一张表进行增删改查,可能引入问题:(1)脏读 :事务A、B并发执行,A对某个表的数据进行修改,A执行过程中B读取这个表的数据,B读完之后A修改表中的数据,导致B读取的数据不是最终的正确数据,而是临时数据;(2)不可重复读 :一个事务多次读取的结果不一样。事务ABC,A执行一个修改操作,执行完毕后提交数据,B读取刚才A提交的数据,B读取过程中C对刚才A修改的数据进行二次修改,此时后续B再读取表的数据,和第一次读到的结果不同;可以通过给读操作加锁解决此问题;(3)幻读:不可重复读的特殊情况。事务AB,A在读取数据时,B增/删了一些其他数据,在A视角,多次读取的数据内容虽然一样,但结果集不同;可以通过串行化解决此问题
25、SQL的索引*
概念:索引相当于在数据库中构建一个特殊的"目录"(一系列特定的数据结构),通过这样的数据结构加快查询速度,尽可能避免针对表数据的遍历操作。
代价:(1)消耗额外的存储空间(2)可能影响增删的效率
操作:
|------|----------------------------|
| 查看索引 | show index from 表名 |
| 创建索引 | create index 索引名 on 表名(列名) |
| 删除索引 | drop index 索引名 on 表名 |
背后的数据结构:B+树
26、如何优化SQL索引查询
| 优化原则 | 具体建议 |
|---|---|
| 遵循最左前缀 | 复合索引(a,b,c)能优化 WHERE a=... 和 a=... AND b=...,但无法优化 WHERE b=... |
| 避免索引失效操作 | 避免对索引列使用函数、计算(WHERE YEAR(date)=2024)、类型转换、以%开头的LIKE |
避免使用SELECT * |
只查询需要的字段,最好使用覆盖索引 |
使用EXPLAIN分析 |
分析SQL执行计划,关注type(const>ref>range>index>ALL)和Extra(Using index表示覆盖索引) |
注意NOT IN和!= |
这些条件通常无法利用索引 |
| 合理控制索引数量 | 索引不是越多越好,会拖慢INSERT/UPDATE/DELETE性能 |
避免OR |
OR可能导致索引失效,可用UNION替代或使用IN |
27、spring的生态
| 模块 | 主要功能 |
|---|---|
| Spring Framework | IoC容器、AOP、数据访问支持、Web MVC等基础能力 |
| Spring Boot | 自动配置、起步依赖、简化Spring应用开发 |
| Spring MVC | 基于MVC模式的Web开发框架 |
| Spring Cloud | 微服务架构下的服务注册发现、配置中心、网关等组件 |
| Spring Data | 统一的数据访问抽象,支持JPA、MongoDB、Redis等 |
| Spring Security | 身份认证和授权框架 |
| Spring Batch | 批处理框架 |
| Spring Integration | 企业应用集成框架 |
28、常用的注解
| 分类 | 注解 | 作用 |
|---|---|---|
| Bean声明 | @Component、@Service、@Repository、@Controller |
将类注册为Spring容器管理的Bean |
| 依赖注入 | @Autowired、@Resource、@Qualifier |
自动装配依赖 |
| 配置类 | @Configuration、@Bean |
声明配置类和方法级别的Bean |
| Spring Boot | @SpringBootApplication |
启动类核心注解(= @Configuration+@EnableAutoConfiguration+@ComponentScan) |
| Web层 | @RestController、@RequestMapping、@GetMapping、@PostMapping、@PathVariable、@RequestBody |
REST API开发 |
| 事务管理 | @Transactional |
声明式事务 |
| AOP | @Aspect、@Before、@After、@Around |
面向切面编程 |
29、URL发送到后端的过程
URL从浏览器请求发送到后端处理再到响应的完整流程:
客户端:
浏览器解析URL → DNS解析域名 → TCP三次握手 → 构建HTTP请求报文(含请求行、请求头、请求体)→ 发送到服务器
服务器端 :
服务器接收请求 → 解包HTTP报文 → 根据URL路径路由到对应处理器 → 执行业务逻辑(调用Service、数据库操作等)→ 构建HTTP响应报文 → 返回给客户端 → TCP四次挥手
主流框架(如Spring MVC)内部流程 :
DispatcherServlet接收请求 → HandlerMapping找到合适的Controller → HandlerAdapter执行 → Controller处理后返回ModelAndView → ViewResolver解析视图 → 返回响应。
30、为什么http依赖于Tcp
层次原因:TCP属于传输层,HTTP属于应用层。按照TCP/IP协议栈的分层设计,每一层都构建在下一层的基础之上,应用层协议必须依赖传输层协议完成实际的网络数据传输。
可靠性需求 :HTTP传输数据(如网页、图片、API响应)要求数据完整、顺序正确且不丢失。TCP提供面向连接的、可靠的、有序的字节流服务------自动处理丢包重传、拥塞控制、顺序保证等复杂问题,而HTTP本身不处理这些底层细节。
实践配合:HTTP请求发送前必须先通过TCP三次握手建立连接,数据在连接上进行可靠传输,传输完成后通过TCP四次挥手断开连接。
UDP虽然更快但不可靠,不适合承载需要保证数据完整性的HTTP应用场景。