nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇把一条 prompt 一次 prefill,产出了第一个 token。但生成远不止一个 token:拿到第一个 token 后,引擎进入 decode ------每一步、每条序列只把上一步刚产出的那一个 token 喂进模型,算出下一个,如此循环。
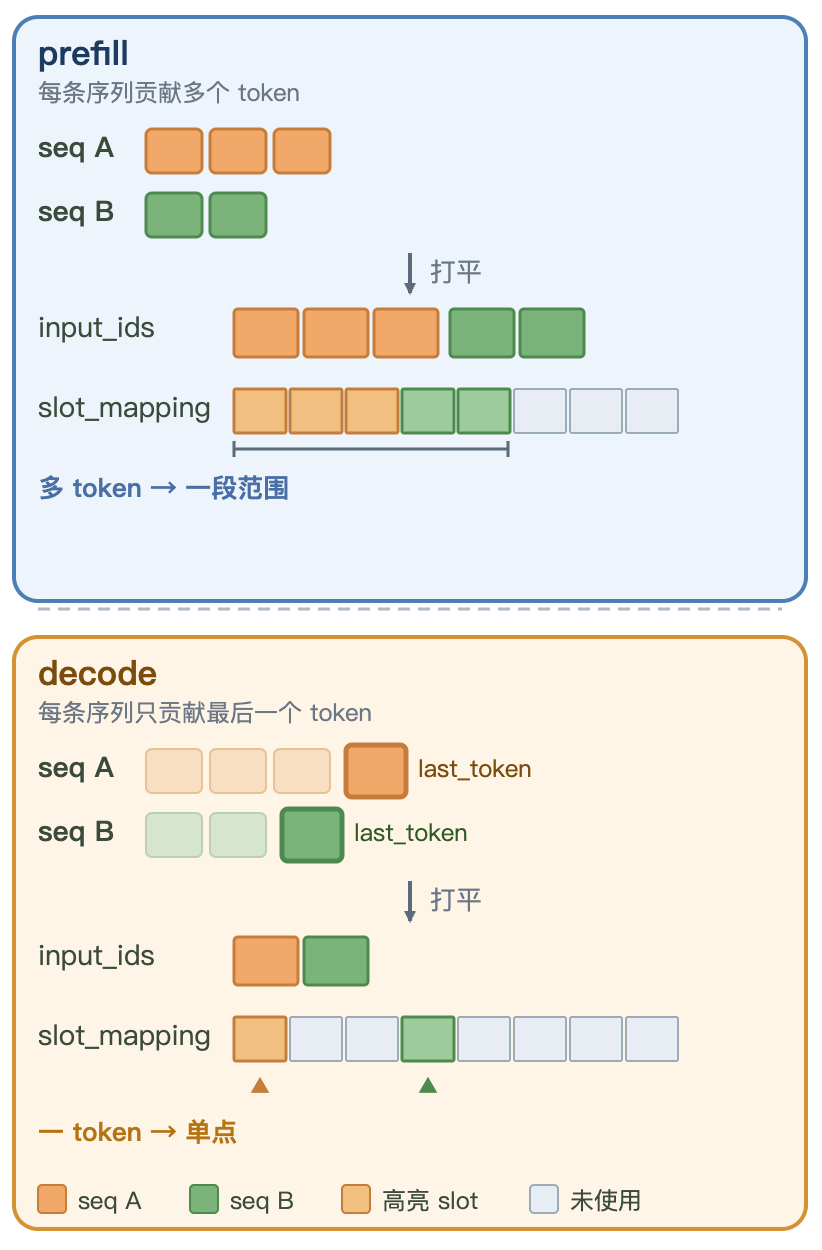
prefill 一次吞下整段 prompt(多个 token 并行算),decode 每步每条只算一个 token。这一个 token 怎么铺成张量、K/V 写到 cache 的哪里、注意力又怎么读到前面所有历史,就是本篇要解决的。
2. 总览
decode 与 prefill 是 ModelRunner 里两条不同的 prepare 路径。两者最根本的差异在于每条序列贡献几个新 token:prefill 贡献整段 prompt(多个),decode 只贡献上一步那一个。token 数的不同,直接决定了张量的形状。
| 张量 | prefill | decode |
|---|---|---|
input_ids |
各序列新 token 打平(变长) | 每条一个 last_token |
positions |
range(start, end) |
len(seq) - 1(单点) |
cu_seqlens_q/k |
有(切变长 batch) | 无 |
context_lens |
无 | len(seq)(每条总长) |
slot_mapping |
逐块算出的一段范围 | 单点 |
block_tables |
仅前缀复用时 | 每一步都用 |
3. prepare_decode
把「每条序列上一步产出的那一个 token」铺成模型输入张量和 Context。
python
import torch
from nanovllm.engine.sequence import Sequence
from nanovllm.utils.context import set_context
# 导入第 11 章实现的ModelRunner
from topic11_model_runner import ModelRunner
def prepare_decode(self, seqs: list[Sequence]):
input_ids = []
positions = []
slot_mapping = [] # 每条新 token 写到哪个物理 slot(单点)
context_lens = [] # 每条要回看的 K/V 总长
for seq in seqs:
# decode:每条只取上一步产出的那一个 token
input_ids.append(seq.last_token)
# 它的位置 = 序列长度 - 1(接在历史末尾)
positions.append(len(seq) - 1)
# 注意力要回看的 K/V 总长 = 整条序列长度
context_lens.append(len(seq))
# 单点 slot:末块物理块号 × 块大小(末块起始 slot)
# + 末块内 token 数 - 1(新 token 的 0-based 下标)
slot = (seq.block_table[-1] * self.block_size
+ seq.last_block_num_tokens - 1)
slot_mapping.append(slot)
# CPU list → pinned 张量 → 异步拷 GPU(同 prepare_prefill)
# pin_memory 页锁定省一次中转拷贝,non_blocking 异步入队不阻塞 CPU
def to_cuda(x, dtype):
t = torch.tensor(x, dtype=dtype, pin_memory=True)
return t.cuda(non_blocking=True)
input_ids = to_cuda(input_ids, torch.int64)
positions = to_cuda(positions, torch.int64)
slot_mapping = to_cuda(slot_mapping, torch.int32)
context_lens = to_cuda(context_lens, torch.int32)
# 保存历史 K/V 的访问地址
block_tables = self.prepare_block_tables(seqs)
# 写进 Context:is_prefill=False,cu_seqlens 全缺省(→ L10)
set_context(
False, slot_mapping=slot_mapping,
context_lens=context_lens, block_tables=block_tables,
)
return input_ids, positions
ModelRunner.prepare_decode = prepare_decodeslot_mapping
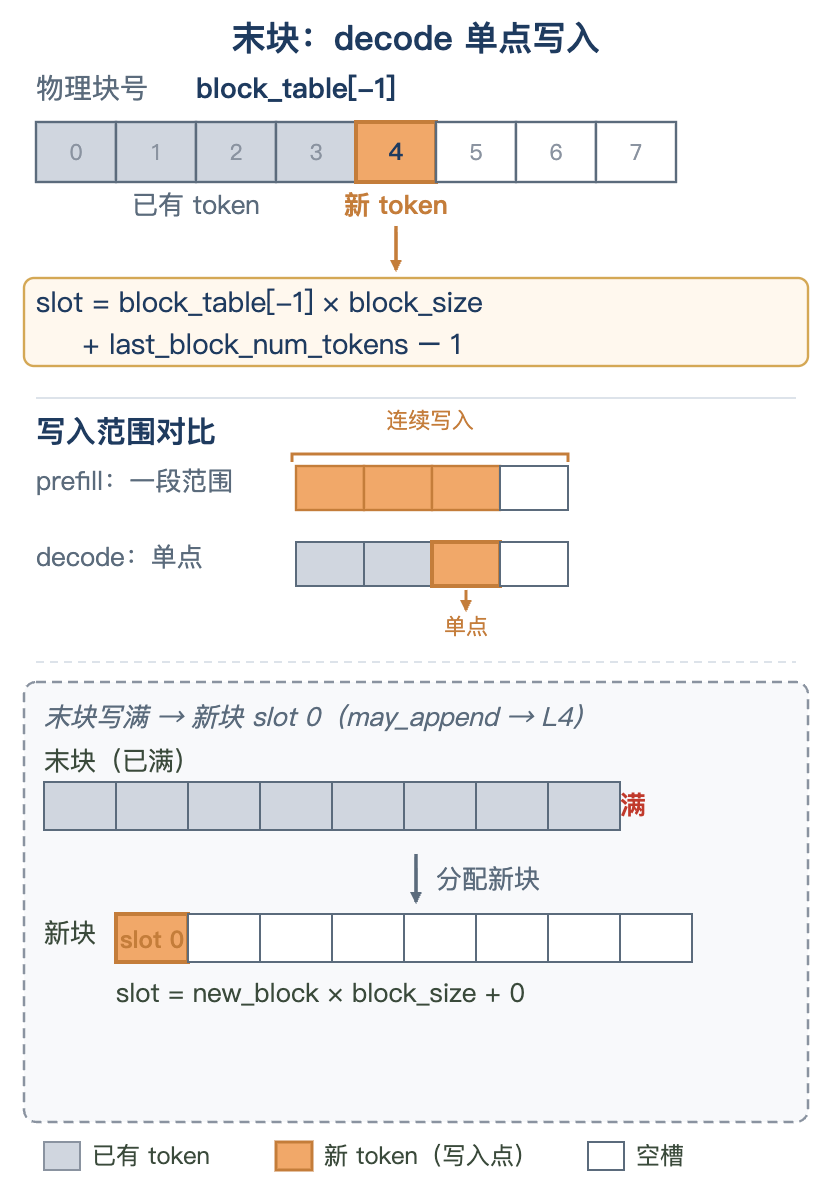
decode 每条序列只算一个新 token,所以只有这一个 token 的 K/V 要写进 cache------slot_mapping 自然只有一个值,不像 prefill 要逐块算出一段范围。
这个 slot 由如下代码算出:
slot = seq.block_table[-1] * block_size + seq.last_block_num_tokens - 1
四段含义:
block_table[-1]:序列最后一个逻辑块对应的物理块号。* block_size:每块占block_size个 slot,块号乘以它,得到该物理块的起始 slot 下标。last_block_num_tokens:末块里现有的 token 数(含刚 append 的新 token),即num_tokens - (num_blocks - 1) * block_size。- 1:新 token 在末块内的 0-based 下标------也就是它的物理 slot。
末块若已写满,会先分配一个新块,单点就落到新块的 slot 0(块的分配由 BlockManager 负责,见 L4)。
context_lens 与 block_tables
decode 的 query 只有一个 token,但它要 attend 到前面所有 历史 K/V------而这些 K/V 全在分页 cache 里,散落在各个物理块,不在本批张量中。计算 attention 的时候,通过 context_lens、block_tables 查找历史 K/V:
context_lens[i] = len(seq):第 i 条序列要回看的 K/V 总长。block_tables:每条序列「逻辑块 → 物理块」的清单。
打个比方:context_lens 像「往回看多少字」,block_tables 像「这些字分别存在哪几间储物柜」。
所以 decode 必须要 block_tables;而 prefill 只在命中前缀缓存(cu_seqlens_k[-1] > cu_seqlens_q[-1])时才需要------没有前缀时 K/V 当场算出就在批里(L11 讲过)。
注意力据此走 flash_attn_with_kvcache:query 是单个新 token,K/V 全来自 cache(kernel 细节在后续章节讲解)。
4. 集成验证
在 L11 prefill 产出第一个 token 的基础上,把它 append 回序列,执行 decode、打印铺出的张量,并续写一小段文本。
python
import torch.distributed as dist
from modelscope import snapshot_download
from transformers import AutoTokenizer
from nanovllm.config import Config
from nanovllm.utils.context import get_context, reset_context
from nanovllm.sampling_params import SamplingParams
# 单卡环境准备(同 L11)
torch.cuda.set_device(0)
if not dist.is_initialized():
dist.init_process_group("nccl", "tcp://localhost:2334", world_size=1, rank=0)
model_path = snapshot_download("Qwen/Qwen3-0.6B")
config = Config(model_path, enforce_eager=True, max_model_len=4096)
runner = ModelRunner(config)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# prompt → token ids(chat template)
msgs = [{"role": "user", "content": "你是谁"}]
text = tokenizer.apply_chat_template(
msgs, tokenize=False, add_generation_prompt=True, enable_thinking=False,
)
prompt_ids = tokenizer(text).input_ids
# 造一条 Sequence,先跑 prefill 拿到第一个 token
seq = Sequence(prompt_ids, SamplingParams(temperature=0.6))
seq.num_scheduled_tokens = len(seq)
seq.block_table = list(range(seq.num_blocks))
first_token = runner.run([seq], is_prefill=True)[0]
seq.append_token(first_token) # 把第一个 token 接回序列
print("prompt tokens :", len(prompt_ids))
print("first token :", first_token, "->", tokenizer.decode([first_token]))
print("seq length now:", len(seq))Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
2026-05-29 15:10:37,892 - modelscope - INFO - Target directory already exists, skipping creation.
prompt tokens : 14
first token : 104198 -> 我是
seq length now: 15
python
# 看一眼 prepare_decode 铺出来的张量
input_ids, positions = runner.prepare_decode([seq])
ctx = get_context()
print("input_ids :", input_ids.tolist()) # [last_token],每条一个
print("positions :", positions.tolist()) # [len-1]
print("context_lens:", ctx.context_lens.tolist()) # [len]
print("slot_mapping:", ctx.slot_mapping.tolist())
print("block_tables:", ctx.block_tables.tolist())
reset_context()input_ids : [104198]
positions : [14]
context_lens: [15]
slot_mapping: [14]
block_tables: [[0]]
python
# 循环 decode,续写一小段(每步把新 token 接回序列)
for _ in range(30):
token = runner.run([seq], is_prefill=False)[0]
if token == tokenizer.eos_token_id:
break
seq.append_token(token)
# 解码出 prompt 之后续写的部分
print("completion:", tokenizer.decode(seq.completion_token_ids))completion: 我是你的AI助手,我将随时为您提供帮助和支持。如果您有任何问题或需要帮助,请随时告诉我!全流程展示:
prepare-decode
5. 小结
prepare_decode 把 decode step 铺成张量:每条只取 last_token,positions / context_lens 记录 seq 长度,block_tables 存储历史 KV 的地址。
prefill 与 decode 两条 prepare 路径补齐后,ModelRunner 的「Sequence ↔ 张量」功能就完整了。下一篇从 Qwen3 的整体架构开始,逐层拆解 model forward 实现。