大家好,我是HLAIA光子。
计网是面试里绕不开的一关。OSI 七层模型、TCP/IP 四层模型、HTTPS 握手过程、REST 和 RPC 的区别,这几个问题面试官翻来覆去地问。但大多数人的理解停留在"背答案"的层面,换个问法就答不上来。
OSI 七层与 TCP/IP 四层
为什么分层
网络通信的复杂度是爆炸级的。从你敲下回车到网页渲染出来,中间经历了 DNS 查询、TCP 三次握手、TLS 加密协商、HTTP 请求、IP 路由、以太网帧封装、光纤上的光信号传输......任何一环出问题都可能打不开网页。
如果把这些功能全部塞进一个"大而全"的协议里,任何一个小的改动都会牵一发而动全身。分层的核心思想很简单:每一层只管自己的事,层和层之间通过标准接口交互,各自独立演进。
说人话就是:你写 HTTP 应用的时候不需要关心光纤用什么波长传输数据。反过来,光纤设备也不需要理解你传的是 JSON 还是 XML。
OSI 七层模型
OSI 由 ISO 在 1984 年提出,是一个理论参考模型,七层可以看这个图
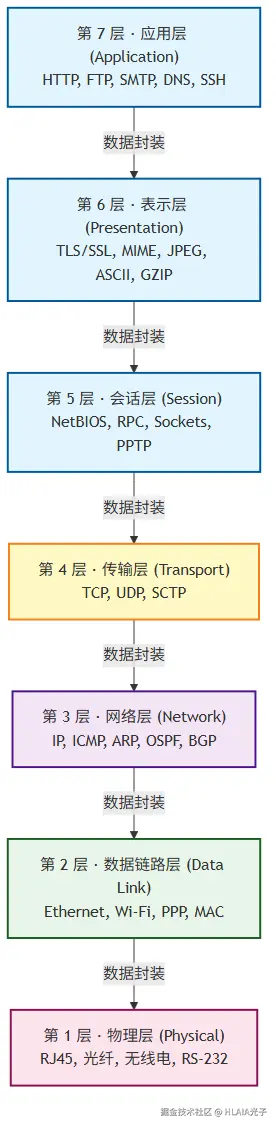
数据封装是 OSI 模型的核心概念。发送方从第七层往下走,每一层给数据加上自己的头部信息,就像套娃一样一层层包起来。接收方从第一层往上走,每层拆掉对应的头部,最终还原出原始数据。
这里有个容易被忽略的点:很多人背了七层的名字,但没意识到第四层也就是传输层,是真正的分水岭。四层以下关心的是"数据怎么到达目的地",四层以上关心的是"数据是什么意思"。这个区别在你排查问题的时候特别有用。
TCP/IP 四层模型
以前有种说法,说TCP/IP 模型是简化版 OSI,其实不是,它是完全不同的出身。OSI 是先有模型再找协议填充,TCP/IP 是先有协议实践再抽象出分层。所以 TCP/IP 模型只有四层:
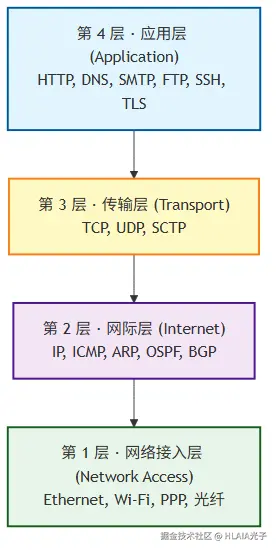
它的应用层把 OSI 的应用层、表示层、会话层合并了;它的网络接入层把 OSI 的数据链路层和物理层合并了。
两者对照关系:
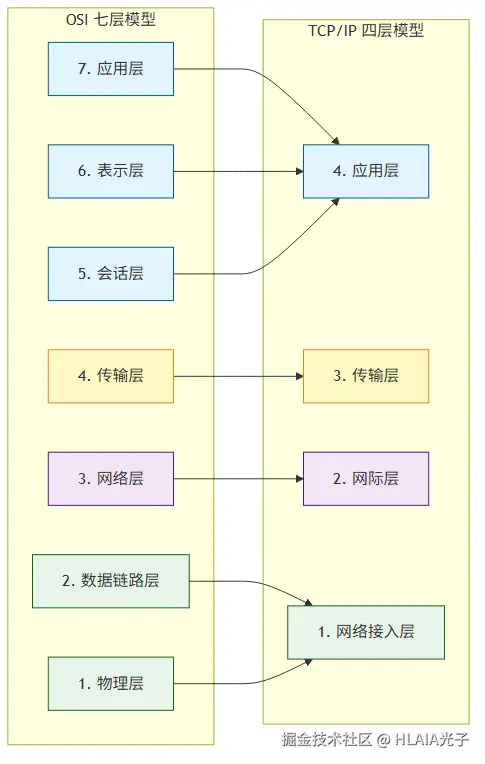
从哪层开始排障
实际工作中网络出问题了,排查的思路就是从底层往上层走:
网络接入层:网线插好了吗?接口是 UP 状态吗? 网际层:IP 地址配对了没?能 ping 通网关吗? 传输层:目标端口开放吗?防火墙有没有拦截? 应用层:服务在跑吗?DNS 解析对了吗?证书过期了没?
这个排查习惯能省掉大量无效排查的时间。
HTTP 与 HTTPS
HTTP 的硬伤
HTTP 协议有三个先天缺陷,而且是致命的:明文传输 ,任何人都能窃听报文内容;无完整性校验 ,中间人可以篡改数据;无身份验证,中间人可以冒充服务器。
在咖啡店的公共 WiFi 下用 HTTP 访问网站,你的密码、Token、浏览记录对同网络的所有人来说都是透明的,用 Wireshark 抓个包就能看到。
HTTPS 怎么修的
HTTPS 就是在 HTTP 和 TCP 之间插了一个 TLS 层,用三套机制分别修补了这三个漏洞:
混合加密解决窃听问题。非对称加密用来安全地交换一把临时会话密钥,之后的通信都用对称加密。混合的原因是:非对称加密很慢,对称加密很快。用非对称加密传密钥只跑一次,之后的数据传输全走对称加密。
消息认证码解决篡改问题。接收方收到数据后验证 MAC 值,如果数据在传输中被改过,校验立刻失败。
数字证书解决身份伪造问题。CA 机构用自己的私钥给网站信息签名,浏览器用内置的 CA 公钥验签。签名匹配就说明这个网站确实是它声称的那个人。
现在说的"SSL 证书"其实用的是 TLS 协议。SSL 早就被废弃了,但这个名字实在太好记了,业界改不了口。
TLS 握手到底发生了什么
这是面试高频题,很多人能说出"四次握手"但讲不清楚每次握手里具体传了什么。我们来看 TLS 1.2 的完整流程:
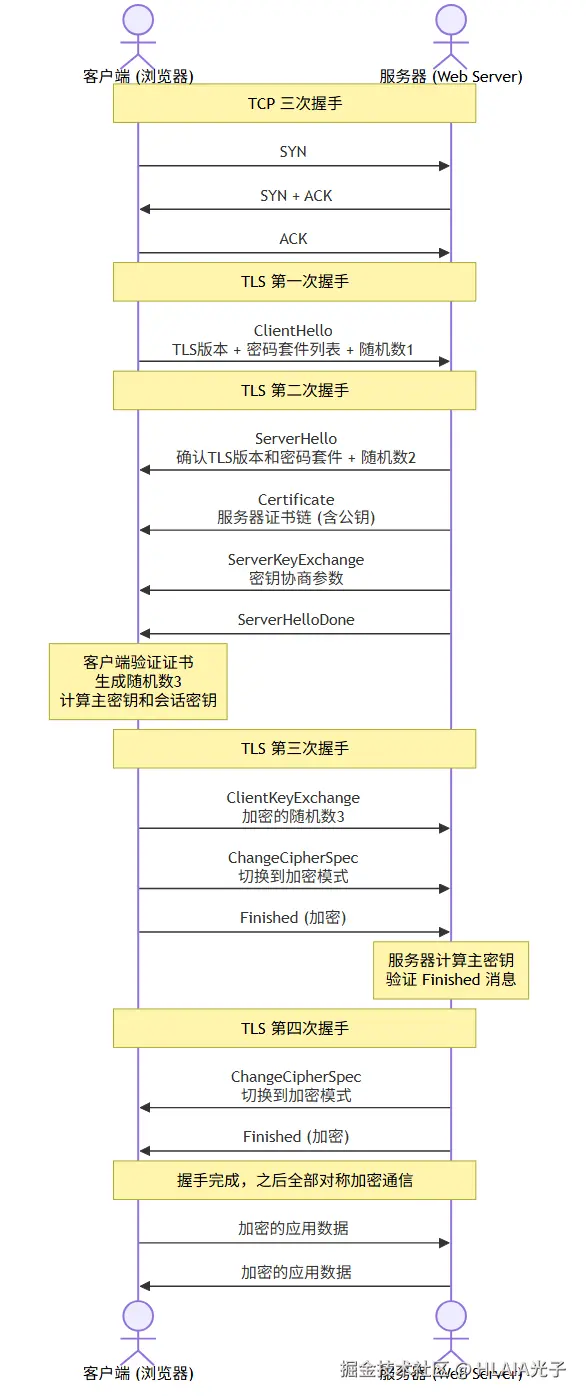
第一次握手:客户端发 ClientHello,带上 TLS 版本、支持的密码套件列表、以及一个随机数。
第二次握手:服务器回 ServerHello 确认版本和密码套件,再发自己的证书链,再发密钥协商参数,最后告诉客户端"我说完了"。
第三次握手:客户端验证证书没问题后,生成第三个随机数用服务器公钥加密发过去。然后双方各自用这三个随机数算出同一把主密钥,再拆分成四把会话密钥。
第四次握手:双方互相发 Finished 消息确认密钥没问题。
之后的所有通信都用对称加密。这就是 HTTPS 的完整握手过程。
三个随机数的设计
三个随机数的设计,不是为了凑数。客户端生成一个,服务器生成一个,客户端再生成一个用服务器公钥加密传过去,三者共同参与最终主密钥的计算。
这套机制的核心目的是防止重放攻击:即使攻击者录制了握手的全部报文,重新发送时因为随机数不同,生成的密钥完全不同,解密失败。
TLS 1.3 的改进
TLS 1.3 在 2018 年发布,做了挺大的简化。
握手从 2-RTT 砍到了 1-RTT;加密起点提前到了 ServerHello 之后;只支持 ECDHE 密钥交换,强制前向保密;密码套件从数百种砍到仅 5 种。
前向保密的意思是,即使服务器的私钥未来某天被泄露了,历史的通信记录也无法被解密。因为每次会话的密钥是临时协商的,和服务器私钥没有直接依赖关系。这个特性在数据合规越来越严格的今天是刚需。
HTTP 与 RPC
两种设计哲学
HTTP 的 RESTful 风格和 RPC 代表了两种完全不同的世界观,
REST 把世界看成资源的集合。URL 是资源的地址,HTTP Method 是对资源的操作。核心问题是"我对哪个资源做什么操作"。
RPC 把世界看成函数的集合。像调用本地函数一样调用远程函数,网络细节全部透明。核心问题是"我要调用哪个函数,传什么参数"。
举个例子。查一个用户的信息:
REST 的思路是:GET /users/123。名词是 user,动词是 GET。
RPC 的思路是:getUser(123)。这就是函数了。
两种思路没有绝对的对错,但它们的适用场景还是有所差别。
gRPC 为什么快
gRPC 是 Google 开源的 RPC 框架,底层用了 HTTP/2 加 Protocol Buffers 序列化。
JSON 是文本,要逐字符解析,字段名在每个请求里重复传输。Protobuf 是二进制,字段名用数字编号代替,解析速度快 5 到 8 倍,序列化后的体积也比 JSON 小 60% 到 80%。
gRPC 还原生支持四种通信模式:一问一答的 Unary、服务端流式推送、客户端流式上传、以及双向流。这些在 HTTP/1.1 下要么做不了,要么需要 WebSocket 额外支持。
更关键的是契约。gRPC 的 .proto 文件编译后生成客户端和服务端代码,接口定义即文档,编译期就能检查类型安全。REST 的 Swagger 文档是人写的,人和代码之间的同步是松散的。
什么时候用哪个
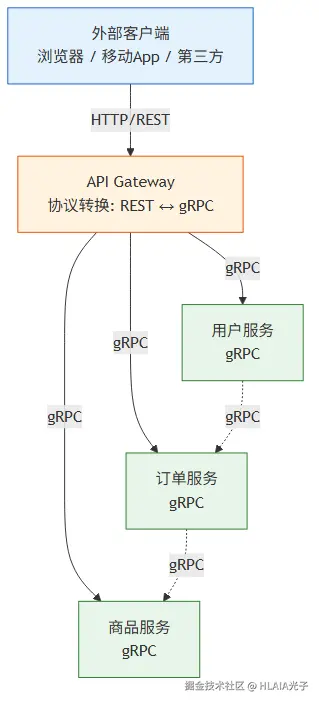
这不是非此即彼的选择,业界主流做法是混合架构(没错又是混合...这个世界是一个巨大的杂交水稻):
对外暴露的 API 用 HTTP/REST。浏览器原生支持,curl 和 Postman 就能调试,所有防火墙和代理都兼容。第三方开发者不需要装任何额外的工具链。
内部微服务之间用 gRPC。速度快、契约强、流式传输原生支持。内部服务不需要考虑浏览器兼容,网络环境可控。
中间加一层 API Gateway 做协议转换。外部请求通过 HTTP 进来,Gateway 转成 gRPC 发给内部服务,响应再转回 HTTP 返回客户端。
有一点容易混淆:OpenAPI 描述的 URL 模板模式,概念上其实更接近 RPC 而不是真正的 REST。客户端清楚地知道"我要调哪个操作、填什么参数"。真正的 REST 客户端是通过服务器返回的超媒体链接来导航的,不需要提前知道 URL 结构。不过实践中纯粹的 REST 很少见,OpenAPI 风格是最主流的。
写在最后
学计网最大的误区就是把它当文科来背,七层叫什么名字、TLS 分几步握手、REST 五个约束是什么,背得滚瓜烂熟一问"为什么这么设计"就哑了。
理解设计动机比记住名词重要得多。OSI 为什么要分层,HTTPS 为什么用三个随机数,RPC 为什么比 HTTP 快。把这些问题想通,面试的时候不管对方怎么换问法你都能接住。
实际工作中这些知识也用得上。排查线上问题的时候,你能快速判断是网络层的连通性出问题、传输层的端口被防火墙挡了、还是应用层的协议不兼容。
如果你觉得这篇文章有帮助,点赞关注,点点赞~