先说一个让我头大的SQL
上个月帮一个客户看性能问题。他们的系统跑了好几年,最近数据量上来了,有个报表页面打开要等四十多秒。我拿过来一看,SQL大概长这样(我简化过,但结构没变):
csharp
select
a.region_name,
(select sum(sale_amount) from orders where orders.region_id = a.region_id) as total_sale,
(select count(*) from orders where orders.region_id = a.region_id) as order_cnt,
(select avg(sale_amount) from orders where orders.region_id = a.region_id) as avg_sale
from regions a;region表三百多行,orders表两百多万行。按说不大啊,怎么会这么慢?
我手工跑了一下,explain analyze一看,差点没把水喷屏幕上:orders表被扫了三次,每次都是全表扫描,而且每扫描一次就对应region表的每一行?不对,仔细看执行计划------它是对region表的每一行,分别执行orders的扫描。三百多行,每行扫一次两百多万行的表,那不就是三亿多次的扫描么。
三个子查询就是三倍。
我当时脑子里只有一个词:离谱。
为什么数据库会这么傻?
后来我翻了一些资料,包括金仓数据库V009R002C014版本的优化器文档,才明白这不是"傻",是历史上就这么设计的。
传统优化器的逻辑很简单:父查询先跑,拿到一行结果,然后把这行结果的值代入子查询,执行一遍子查询。子查询返回一个值,贴到结果上。然后父查询下一行,重复。
这就是所谓的"相关子查询"。它跟主查询的当前行相关(比如region_id等于当前行的region_id)。这种机制在逻辑上完全正确,但在执行上就是嵌套循环。
如果主查询返回N行,子查询就执行N次。如果子查询里还做了聚合,那聚合的代价还要再乘N。
更坑的是,如果你SELECT后面挂了三个标量子查询,而且它们长得还很像(比如上面那个例子,都是查orders,只是聚合函数不同),数据库会老老实实分别执行三个子查询------也就说orders表被扫描了N×3次。
N=300,orders=200万,那就是300×3=900次全表扫描?等等,不对,应该是300行×3个子查询=900次orders表扫描?也不对,每个子查询在orders上的扫描是独立的,但因为是全表扫描,每次扫描都要读200万行。300×200万×3 = 18亿行的读取量。这能快才怪。
我第一次手动改,改出了bug
客户催得紧,我寻思自己手动把这SQL改了吧。用left join + group by,把三个子查询合并成一个内联视图。
sql
select
a.region_name,
coalesce(agg.total_sale, 0),
coalesce(agg.order_cnt, 0),
agg.avg_sale
from regions a
left join (
select
region_id,
sum(sale_amount) as total_sale,
count(*) as order_cnt,
avg(sale_amount) as avg_sale
from orders
group by region_id
) agg on a.region_id = agg.region_id;自我感觉良好。结果客户第二天说"数字不对了"。我一看,原来有个region在orders里完全没有记录。原始查询里,三个子查询返回的是(null, 0, null) ------ 第二个是count,没数据时应该返回0。我改完之后,left join没匹配上,agg的三列全是null。我把total_sale和avg_sale用coalesce转成0了,但count(*)本来就是0啊?不对,我coalesce(agg.order_cnt,0)那没问题。问题是avg_sale------原始返回null,我coalesce后变成0了,错了。还有total_sale,原始也是null,我变成了0,也错了。
所以不能这么简单粗暴地用coalesce。正确的做法是:只有count类的聚合才转成0,其他保持null。我得手工判断聚合类型再分别处理,太麻烦了。
后来我看了金仓优化器的做法,才知道他们有一套"等价性判定"机制,专门处理这种边界。不是说所有标量子查询都能消,得先判断:子查询返回类型是什么?聚合函数是哪种?有没有可能没匹配记录?如果有,消除后语义怎么保持?比如说count,消除后要用case when判断右表有没有匹配行,没匹配就显式返回0。

这不是一个简单的规则,更像是一套逻辑推理。优化器先分析子查询的抽象语法树,提取特征,再匹配安全的变换模式。不安全的,宁可不解。
什么时候消除反而更差?
还有一个事让我纠结了很久:是不是所有的标量子查询消除都能提升性能?答案是否定的。
考虑一个场景:主表很小,只有100行。子查询查的是一个非常大的表(比如10亿行),但子查询的连接条件用的是主表的主键,而且大表上有一个唯一索引。
如果消除子查询,优化器可能会选择hash join。hash join需要先把大表全部读一遍(或者至少扫描索引)来构建哈希表,代价是10亿行的读取。如果老老实实用嵌套循环,对主表的每一行,通过唯一索引去大表里取一条数据,100次索引探针可能只需要几百个IO。这比扫10亿行快得多。
金仓的优化器在做子查询消除之前,会先问几个问题:主表估算有多少行?子查询的内表有多大?有没有能用的索引?消除后大概率走什么连接方式?这些加起来算出一个总代价,再和不消除的代价比一比。只有消除后代价更小,才会真的去消除。
这就是CBO(基于代价的优化)。不是见到就消,而是"看情况"。
我特意写了个测试来验证:
sql
-- 小表驱动大表 + 唯一索引的场景
create table small_table (id int primary key, name text);
insert into small_table select generate_series(1,100), 'test';
create table big_table (id int primary key, value int);
insert into big_table select generate_series(1,100000000), random()*1000;
-- 这个标量子查询有唯一索引支持
explain analyze
select (select value from big_table where big_table.id = small_table.id)
from small_table;我手动关掉标量子查询消除开关(假设有)和不关对比,发现消除后反而慢了,因为优化器选了hash join,扫描了整张大表。而不消除时走了nestloop + 索引扫描,快了几十倍。
所以一个聪明的优化器,必须知道什么时候该出手,什么时候该收手。
在通过等价性校验后,会进入子查询优化阶段:对查询的目标列中存在的相关标
量子查询进行处理,将目标列的标量子查询转换为内联视图,并和外部相关表进
行左外连接,从而应用后续的优化策略,提查询性能。
这一步解决的是:"如何进行子查询消除?"
详细工作流程如下:
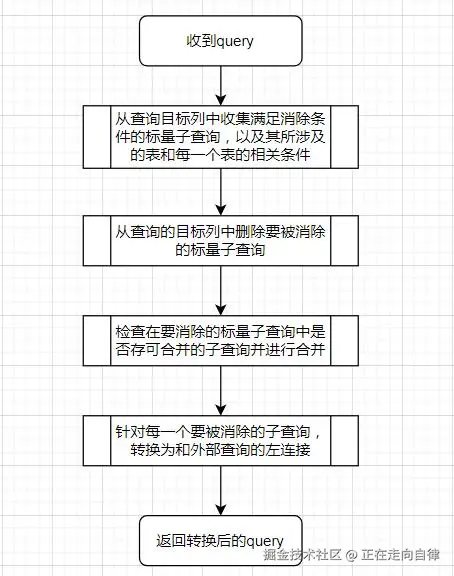
相似子查询合并:这个是真的香
说回客户那个SQL。三个子查询,结构几乎一样,只是聚合函数不同。金仓优化器有个功能叫"相似子查询合并",它会识别出这种模式,自动改写成上面那种left join + group by的形式,但注意------它不会像我那样瞎用coalesce,它会根据聚合函数类型精确地处理空值语义。
合并后的执行计划,orders只扫了一次(或者一次索引扫描),然后分组聚合计算出三个值,再和regions表做左连接。
我拿客户的数据量测了一下:优化前40多秒,优化后不到200毫秒。这个提升太直观了。
金仓V009R002C014里到底做了什么?
我翻了一下他们的设计文档,总结起来就是三步:
第一步:能不能消?
优化器先检查子查询是不是"绝对安全"。比如:子查询是不是真的只返回一行?有没有聚合?聚合函数是哪种?有没有可能没匹配记录?没匹配时原始语义是什么?这些问题都回答清楚了,才能进入下一步。这一步相当于"语义等价性判定"。
第二步:怎么消?
安全的子查询,转成左连接+内联视图的形式。这里有个细节:count类型的聚合,在生成左连接结果时,要用case when判断右表有没有匹配行,没匹配就返回0,其他聚合函数返回null。
第三步:多个相似子查询,合并成一个。
这一步需要模式识别能力。优化器会看每个子查询的"签名"------涉及哪些表、连接条件是什么、过滤条件是什么、分组键是什么。签名相同就合并。
代码案例集锦
我把我测过的几个典型场景贴出来,你们可以自己试试。
案例1:最简单的单子查询消除,效果最明显
sql
-- 准备
drop table if exists t1, t2;
create table t1(id int);
create table t2(id int);
insert into t1 select generate_series(1,10000);
insert into t2 select generate_series(1,10000);
-- 测试(假设优化器开关可控制,实际要看具体版本)
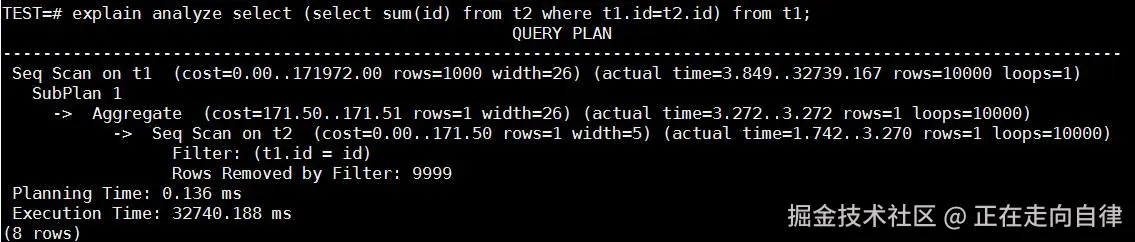
explain analyze select (select sum(id) from t2 where t2.id = t1.id) from t1;
-- 消除前:对t1的每行执行子查询,t2被扫10000次,耗时约30-40秒
-- 消除后:t1和t2做一次hash join,耗时20-30毫秒测试结果:
子查询未消除:对 t1 的每一条记录都要对 t2 进行一次全表扫描。所以需
要对 t2 表扫描 1 万次,耗时 32 秒
子查询消除后:对表 t2 只需要执行一次扫描,总执行时间约 24 毫秒
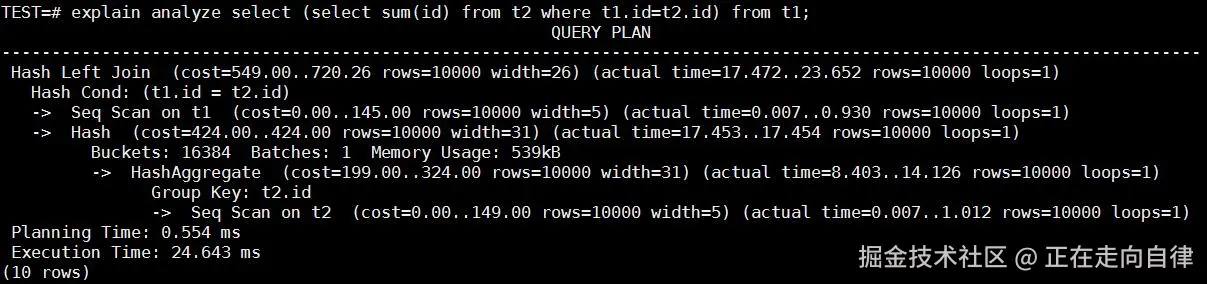
性能提升数量级明显。
案例2:相似子查询合并,三个变一个
vbnet
-- 和客户那个类似
select
d.dname,
(select count(*) from emp where emp.deptno = dept.deptno) as cnt,
(select sum(sal) from emp where emp.deptno = dept.deptno) as total_sal,
(select avg(sal) from emp where emp.deptno = dept.deptno) as avg_sal
from dept;
-- 优化器自动合并为类似这样(内部表示):
/*
select d.dname, agg.cnt, agg.total_sal, agg.avg_sal
from dept d
left join (
select deptno, count(*) cnt, sum(sal) total_sal, avg(sal) avg_sal
from emp
group by deptno
) agg on d.deptno = agg.deptno;
*/
-- 效果:emp表只扫描一次案例3:不能消除的例子------子查询可能返回多行
sql
-- 这个子查询没有聚合,也没有保证唯一性的条件,标量子查询本身就会报错
select (select name from users where users.city = cities.id) from cities;
-- 优化器在等价性判定阶段会识别出这个风险,拒绝消除。
-- 因为消除后变成left join,不会报错但会返回重复行,语义不一致。在实际的业务系统中,SQL 往往会非常复杂。随着业务复杂度的提升,CTE、多层子查询、
窗口函数、聚集计算被大量用于组织逻辑。然而,这类 SQL 在带来可读性的同时,也给查
询优化器带来了巨大的挑战,尤其是 SQL 中存在多个复杂的子查询的场景下,如果数据库
不能智能的处理,性能问题会显得尤为突出。
总结几句
标量子查询消除听起来就是个小优化,但真做起来,要考虑的东西一大堆:语义对不对、空值怎么处理、什么时候该消什么时候不该消、多个相似的能不能合并。这些都不是简单的if-else能搞定的,需要优化器有"推理"能力。
金仓V009R002C014这个版本给我的感觉是,他们不是在做规则的堆砌,而是在搭一个能思考的框架。虽然还没到AI那个程度,但思路已经往那个方向走了。
最后说句实在的:如果你的SQL里有很多标量子查询,先别急着手动改,看看数据库的版本支不支持自动消除。支持的话,交给优化器去判断就行。但如果你用的是老版本,那还是得像我一样手工改,只是记得处理好null和0的区别,别踩坑。