级联式 WAM 的第一块基石:先用文本条件视频扩散模型"画出"一段执行视频,再用逆动力学模型从画面里"倒推"出动作。
在 WAM(世界动作模型)的家谱里,如果要找一个"开山祖师"级别的工作,UniPi 几乎是绕不开的。它发表在 NeurIPS 2023,标题叫《Learning Universal Policies via Text-Guided Video Generation》(通过文本引导的视频生成学习通用策略)。这个名字已经把它最大胆的主张写在了脸上:机器人的"策略",可以不再是一张"看到什么就做什么"的反应表,而是一段"我接下来要做这件事"的视频。
这篇博客属于 WAM 谱系中"级联式 → 像素空间 → 学习式动作提取"这一支的源头。读懂它,你就握住了后面 VLP、RoboEnvision、This&That 乃至一大票视频驱动机器人工作的总钥匙。
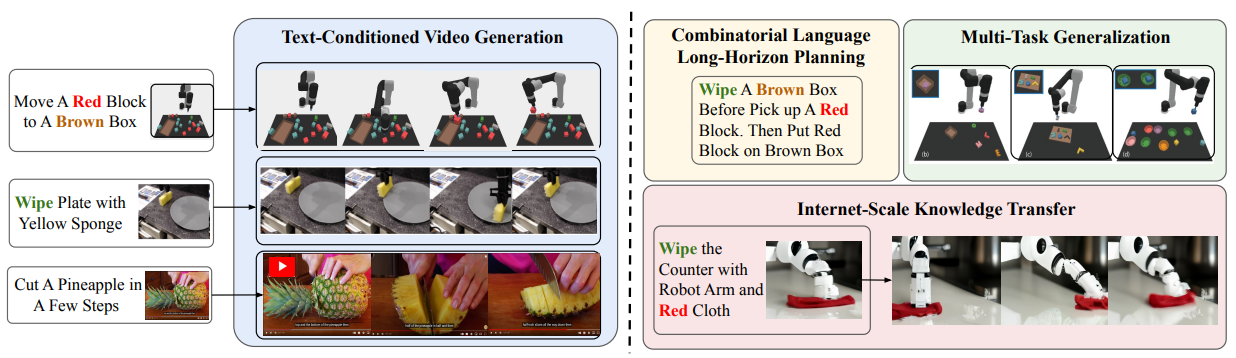
一、要解决什么问题:机器人策略的"三座大山"
先把场景拉到地面。我们想训练一个机器人去完成各种任务:"把红色方块放到蓝色方块右边""把碗收进盒子里"。传统做法是强化学习或模仿学习,把问题建模成一个马尔可夫决策过程(MDP,简单说就是"状态---动作---奖励"循环的数学框架)。这套框架很经典,但每换一个任务、一个环境、一个机器人,你几乎都要重新搭一遍台子,因为它绕不开三座大山:
- 奖励函数要手工设计。 "怎样算把方块摆好了",得有人写一个打分公式。任务一复杂,这公式就难产。
- 状态空间要专门定义。 这个环境用关节角度当状态,那个环境用物体坐标当状态,彼此不通用。
- 每个环境的动作空间还不一样。 七自由度机械臂和移动底盘的"动作"根本不是一回事,学到的策略很难迁移。
结果就是:每个任务一个"专才",训练出来的策略像一次性筷子,换个场景就得扔。
那有没有一种所有任务都能共用的"通用语言" ?UniPi 的回答出人意料地朴素:有,就是视频。
打个比方。你不会写菜谱给一个完全不懂中文的人,但你可以拍一段"怎么炒这盘菜"的视频 给他看------油热了下葱、翻炒、出锅。视频是跨语言、跨厨房的通用媒介。同理,无论机械臂还是移动底盘,无论在厨房还是桌面,"任务怎么完成"都可以用一段 RGB 画面序列 统一地表达出来。UniPi 正是抓住了这一点:图像空间是天然跨环境通用的状态表征,而"任务"可以用一句自然语言来指定,于是奖励函数、状态定义、动作空间这三座大山,被一口气绕了过去。
二、核心思想与直觉:先"想象"出未来,再"读"出动作
UniPi 的核心 idea 一句话就能说清:
把"做决策"重新定义成"做一段文本条件的视频生成"------给定当前看到的画面和一句任务指令,模型先生成一段"未来会怎样演化"的视频,然后再从这段视频里把每一步该执行的动作解读出来。
它把整个流程拆成了两个互相解耦的阶段,这也是它属于**级联式 WAM(Cascaded)**的标志------世界预测和动作生成不是一个模型里搅在一起,而是接力棒式的两棒:
- 第一棒(世界模型 / 规划器) :一个文本条件的视频扩散模型,输入"当前帧 + 任务描述",输出一整段执行视频。这一段视频就是机器人的"计划",是它在脑海里预演出来的"接下来该发生什么"。
- 第二棒(动作提取器) :一个逆动力学模型(IDM,简单说就是"盯着相邻两帧画面,倒推出这中间机器人执行了什么动作"的小网络),把视频里相邻帧之间的视觉变化,翻译成机器人电机能听懂的控制指令。
为什么这么拆?因为这一拆,带来了一个极其优雅的好处------两个阶段可以用完全不同的数据来喂:
- 视频扩散模型只需要看视频就能学,根本不需要动作标注。这意味着它可以吃下海量互联网视频、跨任务的演示视频------这些数据极其丰富。
- 逆动力学模型才需要"画面+动作"的配对数据,但它的活儿很简单(只是看两帧猜动作),所以只需要很少量的带动作标注数据 就够了,而且它与"规划"无关,可以做到与具体任务、具体环境无关(task-agnostic)。
这就把机器人学习里最稀缺、最贵的资源------带动作标注的真机数据 ------的需求量压到了最低,而把最容易获取的资源------无动作标注的视频------的价值榨到了最高。这是 UniPi 留给整个领域最深远的一笔遗产。
为了把这套思路讲得更规整,作者还提出了一个新的问题框架,叫统一预测决策过程(Unified Predictive Decision Process, UPDP) 。它用一个四元组 ⟨𝒳, 𝒞, H, ρ⟩ 取代了传统 MDP:𝒳 是图像观测空间(跨环境通用),𝒞 是文本任务描述(取代奖励函数),H 是有限的时间步长,而 ρ(·|x₀, c) 是一个条件视频生成器 ------给定首帧 x₀ 和任务 c,吐出一段 H 步的图像序列。说白了,UPDP 就是把"求解策略"正式改写成了"求解一个会按指令拍视频的生成器"。
三、方法详解:两个阶段怎么落地
3.1 第一阶段:文本条件视频扩散模型------机器人的"想象引擎"
先补一句直觉再上技术。扩散模型(Diffusion Model)的工作方式,可以想象成一个"从雪花屏里雕刻画面"的过程:先把一段干净视频反复加噪声,加到变成纯雪花点;再训练一个神经网络学会一步步把雪花点"去噪"还原回清晰视频 。生成时,就从纯噪声出发,让网络一点点"雕"出一段全新的视频。UniPi 要的,正是这种"无中生有画视频"的能力------只不过要让它听指令。
具体怎么实现"听指令"和"接着当前画面往下画"?有几个关键设计:
(1)主干是一个 Video U-Net。 U-Net 是图像生成里最常用的"沙漏形"网络(先逐层压缩、再逐层还原)。UniPi 用的是它的视频版,能同时处理空间和时间维度。规模上,仿真任务用的模型约 1.7B 参数。
(2)用 T5-XXL 把文字变成"条件信号"。 任务指令这句话,先经过一个强大的语言编码器 **T5-XXL(约 4.6B 参数的文本模型)**编码成向量,再喂给扩散网络,让它"知道这次要画的是哪件事"。
(3)首帧怎么"接住"?------通道维度拼接 + 时间维度平铺(tiling)。 这是个很巧的小技巧。我们希望生成的视频"从当前这一帧自然地长出来",所以要把当前观测帧作为条件喂进去。UniPi 的做法是:把这张首帧沿时间轴复制成一整段(平铺),再在通道维度上和带噪声的视频拼到一起,让网络在每一个去噪步骤都"看得到起点长什么样"。这样生成的视频就不会跑偏到一个跟初始场景毫不相干的世界里去。
(4)用无分类器引导(Classifier-Free Guidance)增强"听话程度"。 这是扩散模型里一个标准技巧:训练时随机让模型"有时看指令、有时不看指令",生成时把"看指令"和"不看指令"两种预测做一个加权外推,从而放大文本指令的影响力,让画面更紧扣任务。
(5)时间上的"由粗到精"分层生成(hierarchical / 时间超分辨率)。 直接一口气画出一段又长又清晰的视频太难、太慢。UniPi 学了视频生成领域的经验,采用时间超分辨率(temporal super-resolution) :先画一段时间上很稀疏 的关键帧(比如每 8 帧取 1 帧的粗略版,10×48×64),抓住"大致怎么演化";再用一个超分模型在关键帧之间插值出中间帧(每 4 帧取 1 帧,20×48×64),把动作补得连贯流畅。在真机数据上,分辨率还会进一步逐级放大到 32×320×192 这样的高清画面。
这套"先定骨架、再填血肉"的分层思路,后面你会发现是整个 WAM 谱系反复出现的母题------VLP 用它做长程规划,RoboEnvision 干脆把它发扬成"关键帧+插值"的主线。
3.2 第二阶段:逆动力学模型------从画面到电机指令的"翻译官"
视频画好了,机器人却不认识像素,它只认识"关节该转多少度、夹爪该开还是合"。这中间的翻译,就交给逆动力学模型(IDM)。
它的逻辑朴素到近乎"耍赖":给定生成视频里相邻的两帧画面 (xₜ, xₜ₊₁),直接回归出"从前一帧到后一帧机器人执行了什么动作 uₜ"。 之所以叫"逆"动力学,是相对于"正向动力学(给动作预测下一帧)"而言的------它反着来,看结果倒推原因。
架构上它非常轻量:几层 3×3 卷积(带残差连接)提取相邻帧的视觉变化特征,再做空间平均池化,最后接一个 MLP 输出 7 维控制量(对应 7 自由度机械臂)。训练用的就是简单的 MSE 损失(预测动作与真实动作的均方误差)。
这里要再强调一次它的精妙之处:IDM 是和规划完全解耦的 。视频扩散模型负责"想象世界会怎么变",它可以在海量无动作的视频上训练、做到环境无关;IDM 只负责"把视觉变化翻译成动作",它只需要在很少量的带标注数据上训练。在组合泛化实验里,IDM 仅用约 20k 段带动作标注的视频就训练出来了。
核心公式与逻辑梳理
把 UniPi 拆开来看,它的方法链可以浓缩成 5 步:
- 问题改写 :把传统 MDP 换成 UPDP------用图像观测和文本指令直接定义"任务",不再依赖人工奖励函数。
- 首帧条件化:将当前观测帧沿时间轴平铺、与噪声视频在通道维拼接,作为视频扩散模型的固定起点。
- 文本条件去噪:以 T5-XXL 编码的任务指令为条件,反复迭代去噪,把"高斯噪声"雕成"一段执行视频"。
- 分类器自由引导:在采样时把"看指令的预测"和"不看指令的预测"做外推,放大文本对画面的引导力。
- 逆动力学解码:用 IDM 看相邻两帧反推出 7 维控制量,把视频翻译成机器人能执行的动作序列。
公式 1:UPDP 的形式化定义
G=⟨X, C, H, ρ⟩,ρ(⋅∣x0,c): X×C→Δ(XH)\mathcal{G} = \langle \mathcal{X},\ \mathcal{C},\ H,\ \rho \rangle,\qquad \rho(\cdot\mid x_0, c):\ \mathcal{X}\times\mathcal{C}\rightarrow \Delta(\mathcal{X}^H)G=⟨X, C, H, ρ⟩,ρ(⋅∣x0,c): X×C→Δ(XH)
- 符号说明 :X\mathcal{X}X 是图像观测空间(一帧 RGB),C\mathcal{C}C 是文本任务空间(一句指令),HHH 是规划步数上限,ρ\rhoρ 是一个条件视频生成器 ------给定首帧 x0x_0x0 和指令 ccc,输出 HHH 步图像序列的概率分布;Δ(⋅)\Delta(\cdot)Δ(⋅) 表示概率分布的集合。
- 这条式子在做什么:它把"策略学习"重新写成了"按指令拍视频"。原来的 MDP 要靠奖励驱动 trial-and-error,这里直接把"任务"挂在文本上、把"状态"挂在像素上,奖励、状态、动作三座大山在数学层面就被绕开了。
公式 2:扩散前向加噪过程
qk(τk∣τ)=N(τk; αkτ, σk2I),k∈0,1q_k(\tau_k\mid \tau) = \mathcal{N}(\tau_k;\ \alpha_k \tau,\ \sigma_k^2 I),\quad k\in0,1qk(τk∣τ)=N(τk; αkτ, σk2I),k∈0,1
- 符号说明 :τ\tauτ 是干净视频(多帧拼起来的张量),τk\tau_kτk 是加噪到第 kkk 步的"半雪花"视频;αk\alpha_kαk、σk2\sigma_k^2σk2 是预设的噪声调度系数(kkk 越接近 1,画面越接近纯噪声);N(⋅;μ,Σ)\mathcal{N}(\cdot;\mu,\Sigma)N(⋅;μ,Σ) 表示均值 μ\muμ、协方差 Σ\SigmaΣ 的高斯分布。
- 这条式子在做什么 :定义"反复加噪声把视频糊成雪花"的过程。模型训练时就是学这一过程的反演 ------已知 τk\tau_kτk 和 kkk,预测出原视频或者所加噪声。
公式 3:分类器自由引导(Classifier-Free Guidance)
s^(τk,k∣c,x0)=(1+ω) s(τk,k∣c,x0)−ω s(τk,k)\hat{s}(\tau_k, k\mid c, x_0) = (1+\omega)\, s(\tau_k, k\mid c, x_0) - \omega\, s(\tau_k, k)s^(τk,k∣c,x0)=(1+ω)s(τk,k∣c,x0)−ωs(τk,k)
- 符号说明 :s(⋅∣c,x0)s(\cdot\mid c, x_0)s(⋅∣c,x0) 是"看着指令 ccc 和首帧 x0x_0x0 做去噪预测"的网络输出,s(τk,k)s(\tau_k, k)s(τk,k) 则是"不看指令"的预测;ω\omegaω 是引导强度(典型取值 1~5),s^\hat{s}s^ 是最终用来采样的预测。
- 这条式子在做什么 :把"听话"和"不听话"两种预测做差,再把差值放大 ω\omegaω 倍叠回去------相当于沿着"指令带来的方向"额外多走一步,强迫模型更紧扣文本要求。这就是为什么 UniPi 能把抽象指令"红方块在蓝方块右边"画得有模有样。
公式 4:逆动力学模型(IDM)训练目标
LIDM(ϕ)=E(xt,xt+1,ut)∼D ∥fϕ(xt,xt+1)−ut∥22\mathcal{L}{\mathrm{IDM}}(\phi) = \mathbb{E}{(x_t, x_{t+1}, u_t)\sim \mathcal{D}}\ \big\| f_\phi(x_t, x_{t+1}) - u_t \big\|_2^2LIDM(ϕ)=E(xt,xt+1,ut)∼D fϕ(xt,xt+1)−ut 22
- 符号说明 :fϕf_\phifϕ 是参数为 ϕ\phiϕ 的 IDM 网络,输入相邻两帧画面 (xt,xt+1)(x_t, x_{t+1})(xt,xt+1)、输出预测的 7 维控制 u^t\hat u_tu^t;utu_tut 是真实动作标签;D\mathcal{D}D 是带动作标注的演示数据集;E(⋅)∼D\mathbb{E}_{(\cdot)\sim\mathcal{D}}E(⋅)∼D 表示在 D\mathcal{D}D 上取期望;∥⋅∥22\|\cdot\|_2^2∥⋅∥22 是均方误差。
- 这条式子在做什么:简单到几乎"耍赖"------盯着前后两帧画面,直接回归"中间这一手到底拧了几度、夹爪开还是合"。正因为它独立于规划,可以只用极少量带标注数据训练(实验里仅约 20k 段),把昂贵的真机动作数据省到了极致。
四、实验怎么做·结果说明了什么
UniPi 用三组实验回答了三个递进的问题:会不会举一反三 ?能不能跨环境迁移 ?能否搬到真机?
4.1 组合泛化:见过"红配蓝",能不能推广到"绿配黄"
这是 UniPi 最亮眼的一战。环境是一个逼真渲染的桌面场景,指令形如"把 X 放到 Y 的右边",X、Y 是各种颜色的物体。关键考点是:训练时只见过部分颜色搭配,测试时换成没见过的新组合,模型还灵不灵?这考的就是**组合泛化(combinatorial generalization)**能力------把学过的概念像搭积木一样重新组合。
结果可以用"碾压"形容(成功率 %,越高越好):
| 方法 | 见过的摆放 | 见过的关系 | 新摆放 | 新关系 |
|---|---|---|---|---|
| 状态+Transformer 行为克隆 | 19.4 | 8.2 | 11.9 | 3.7 |
| 图像+Transformer 行为克隆 | 9.4 | 11.9 | 9.7 | 7.3 |
| 图像+Trajectory Transformer | 17.4 | 12.8 | 13.2 | 9.1 |
| Diffuser(扩散式规划基线) | 9.0 | 11.2 | 12.5 | 9.6 |
| UniPi(本文) | 59.1 | 53.2 | 60.1 | 46.1 |
读懂这张表:所有传统基线在新组合上都只有个位数到十几的成功率,基本"换个搭配就抓瞎";而 UniPi 在没见过的新摆放上拿到 60.1% ,甚至比自己在"见过"组合上还略高,在新关系上也有 46.1%,是基线的五六倍 。这说明"用语言指定任务+用视频表达计划"这套范式,天然继承了语言和视觉的组合能力------你说一个新搭配,它真能在脑海里把对应的画面想象出来。
4.2 多环境迁移:在 10 个任务上学,到 3 个新任务上考
第二组实验把训练任务扩到 10 个(共 200k 视频),然后在 3 个完全没训练过的新任务上测试迁移。结果(成功率 %):
| 方法 | 摆放碗 | 打包物体 | 打包成对物体 |
|---|---|---|---|
| 状态+Transformer 行为克隆 | 9.8 | 21.7 | 1.3 |
| 图像+Transformer 行为克隆 | 5.3 | 5.7 | 7.8 |
| Diffuser | 14.8 | 15.9 | 10.5 |
| UniPi | 51.6 | 75.5 | 45.7 |
同样是数量级的差距。UniPi 在新任务"打包物体"上做到 75.5%,而最强的基线还在 21.7%。这印证了:视频这个通用媒介,让一个模型学到的技能能在不同任务间共享,而不是每个任务各练各的。
4.3 真机迁移与互联网预训练:先"读万卷书"有没有用
最后一组在真实机器人数据(Bridge 数据集,约 7.2k 段真机视频)上验证。这里作者做了一个对 WAM 全领域都意义重大的对照实验:先在互联网海量数据上预训练(约 1400 万视频-文本对、6000 万图文对、外加 LAION-400M),再微调,到底有没有用?
| 设置 | CLIP 分数↑ | FID↓ | FVD↓ | 任务成功率 |
|---|---|---|---|---|
| 不预训练 | 24.43 | 17.75 | 288.02 | 72.6% |
| 互联网预训练 | 24.54 | 14.54 | 264.66 | 77.1% |
(FID/FVD 衡量生成画面/视频与真实分布的距离,越低越好。)预训练让视频质量(FVD)提升约 8%,任务成功率提升约 6%。结论很关键:互联网视频里蕴含的物理与语义先验,是能"转账"到机器人身上的------这正是后来无数 WAM 工作执着于"复用视频大模型"的最初实证依据。
4.4 消融:每个零件各值多少分
作者还逐个拆掉组件看效果(见过的摆放/关系成功率 %):
| 配置 | 摆放 | 关系 |
|---|---|---|
| 基线(不加任何条件) | 13.2 | 12.4 |
| + 首帧条件 | 52.4 | 34.7 |
| + 首帧时间平铺(保一致性) | 53.2 | 39.4 |
| + 时间分层(超分) | 59.1 | 53.2 |
可以清楚看到:"喂首帧"这一步贡献最大 (一下从 13 跳到 52),这符合直觉------不告诉它从哪儿开始画,它就乱画;而时间分层对"关系类"任务提升尤其明显(39→53),说明把长视频拆成"先粗后细"确实更能画准复杂的空间关系。
五、亮点与为什么重要
把 UniPi 的贡献拎成几条:
- 范式奠基:它第一个系统性地把"序贯决策"重写成"文本条件视频生成 + 逆动力学解码",并用 UPDP 给了形式化。后来"级联式 WAM / 视频策略"这一整支,几乎都是踩着它的肩膀往前走。
- 数据解耦的智慧:把"想象未来"(可用海量无动作视频训练)和"解码动作"(只需少量标注)拆开,从根上缓解了机器人动作数据稀缺的痛点。
- 三大泛化的统一:组合泛化、跨任务迁移、互联网知识迁移------这三件传统 RL/BC 很头疼的事,在"语言+视频"的通用表征下被同时改善。
- 可解释性:机器人的"计划"是一段你能直接看的视频。它打算怎么做,人眼一目了然,这对调试和信任都极有价值。
六、局限与未解
UniPi 作为开山之作,留下的坑也很诚实,且几乎条条都成了后续工作的选题:
- 太慢:生成一段高保真视频可能要花将近一分钟,离实时闭环控制差得远。作者也指出可以靠"渐进式蒸馏"做到约 16 倍加速------这条"提速"线索后来催生了 VPP、DreamZero 等一大批工作。
- 只适合"看得全"的环境 :UniPi 默认环境是完全可观测 的。在部分可观测场景里,视频模型可能会幻觉出并不存在的物体或运动,"想象"得很美却不符合物理。
- 逆动力学的强假设 :IDM 假设"相邻两帧的视觉变化能直接对应一个动作"。对于欠驱动或动力学复杂的系统,这个假设会失效。
- 物理不总靠谱:生成视频里偶尔会出现物体凭空出现、瞬移之类的"穿帮",说明它对真实物理的把握还很粗糙。
这些局限,恰好定义了 WAM 后续要攻的几个主战场:提速、长程、物理一致性、动作可执行性。
七、在 WAM 谱系中的位置
按 WAM 综述的分类法,UniPi 端坐在级联式(Cascaded)→ 基于像素空间的显式规划 → 学习式动作提取这一支的最上游。它确立了"视频扩散当世界模型、IDM 当动作提取器"的两阶段模板,而它的几位"后辈"几乎都在补它的短板:
- VLP(本系列 02):UniPi 一口气生成长视频,长程任务上误差会滚雪球。VLP 引入 VLM 做分层子目标 + 树搜索,把长程规划拆成"走一步、评一步",专治误差累积。
- RoboEnvision(本系列 03):嫌自回归式长视频会累积误差,干脆改成"非自回归"------先生成各子任务的关键帧、再插值合成长视频,正面硬刚 UniPi 的长程短板。
- This&That(本系列 04):UniPi 只用文字当条件,遇到"好几个一样的杯子"会犯迷糊。它加上"this/that 指示语 + 手势坐标"共同条件化,把任务指令的歧义彻底消解。
可以说,UniPi 像是给整个领域开了一张"待办清单",而后面这些工作,都是在认真地一项项打勾。
八、参考
- 论文:《Learning Universal Policies via Text-Guided Video Generation》(UniPi)
- 作者:Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, Pieter Abbeel
- 会议:NeurIPS 2023
- arXiv:https://arxiv.org/abs/2302.00111
注:本文为基于该论文公开信息的学习性解读,方法名、数据集与基准均保留英文原名以便检索;文中数字均取自论文,如需精确复核请对照原文。