配置集群监控器 Monitor
查看监控器仲裁
ceph status 命令,检查 MON 仲裁状态
bash
[root@ceph1 ~]# ceph status | grep mon
mon: 3 daemons, quorum ceph1.zhu.cloud,ceph2,ceph3 (age 11m)ceph mon stat 命令,检查 MON 仲裁状态。
bash
[root@ceph1 ceph]# ceph mon stat
e3: 3 mons at {ceph1.zhu.cloud=
[v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0],
ceph2=[v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0],
ceph3=[v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0]} removed_ranks: {},
election epoch 16,
leader 0 ceph1.zhu.cloud, quorum 0,1,2 ceph1.zhu.cloud,ceph2,ceph3ceph quorum_status -f json-pretty 命令,友好的 json 格式输出 MON 仲裁状态。
bash
[root@ceph1 ~]# ceph quorum_status -f json-pretty
{
"election_epoch": 16,
"quorum": [
0,
1,
2
],
"quorum_names": [
"ceph1.zhu.cloud",
"ceph2",
"ceph3"
],
"quorum_leader_name": "ceph1.zhu.cloud",
"quorum_age": 869,
"features": {
"quorum_con": "4540138314316775423",
"quorum_mon": [
"kraken",
"luminous",
"mimic",
"osdmap-prune",
"nautilus",
"octopus",
"pacific",
"elector-pinging"
]
},
"monmap": {
"epoch": 3,
"fsid": "2faf683a-7cbf-11f0-b5ba-000c29e0ad0e",
...
...
...分析监控器映射
Ceph 集群映射包含:
MON 映射
OSD 映射
PG 映射
MDS 映射
CRUSH 映射
MON 映射包含:
- 集群 fsid(文件系统 ID),fsid 是一种自动生成的唯一标识符 (UUID),用于标识 Ceph 集群。
- 各个 MON 节点通信的名称、IP 地址和网络端口。
- 映射版本信息
bash
##查看当前的 MON 映射
[root@ceph1 ~]# ceph mon dump
epoch 3
fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e #集群fsid
last_changed 2025-08-19T05:51:46.573105+0000
created 2025-08-19T05:41:50.650957+0000
min_mon_release 16 (pacific)
election_strategy: 1
0: [v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0] mon.ceph1.laogao.cloud
1: [v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0] mon.ceph2
2: [v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0] mon.ceph3
dumped monmap epoch 3管理集中配置数据库
MON 节点存储和维护集中配置数据库。数据库文件位于 MON 节点,
默认位置是:
/var/lib/ceph/fsid/mon.fsid/mon.fsid/mon.host/store.db
数据库文件会不断增大,改进措施:
运行 ceph tell mon.$id compact 命令,整合数据库,以提高性能。
bash
[root@ceph1 ~ 18:16:16]# ceph tell mon.ceph1.zhu.cloud compact
compacted rocksdb in 0 seconds将 mon_compact_on_start 配置选项为 TRUE ,以便在每次守护进程启动时压缩数据库。
bash
[root@ceph1 ~ 18:16:55]# ceph config set mon mon_compact_on_start true集群验证
Ceph 默认使用 Cephx 协议进行加密身份验证,同时使用共享密钥进行身份验证。
默认情况下,Ceph 会启用 Cephx。如有必要,可以禁用 Cephx,但不建议这样做,因为这样会减弱集群的安全性。
使用 ceph config set 命令启用或禁用 Cephx 协议。
bash
[root@ceph1 ~ 18:17:29]# ceph config get mon auth_service_required
cephx
[root@ceph1 ~ 18:19:42]# ceph config get mon auth_cluster_required
cephx
[root@ceph1 ~ 18:19:47]# ceph config get mon auth_client_required
cephx, none参数说明:
auth_service_required,客户端与Ceph services之间通信认证。可用值 cephx 和 none 。
auth_cluster_required,Ceph集群守护进程之间通信认证,例如 ceph-mon , ceph-mgr 。可用值
cephx 和 none 。
auth_client_required,客户端与Ceph集群之间通信认证。可用值 cephx 和 none
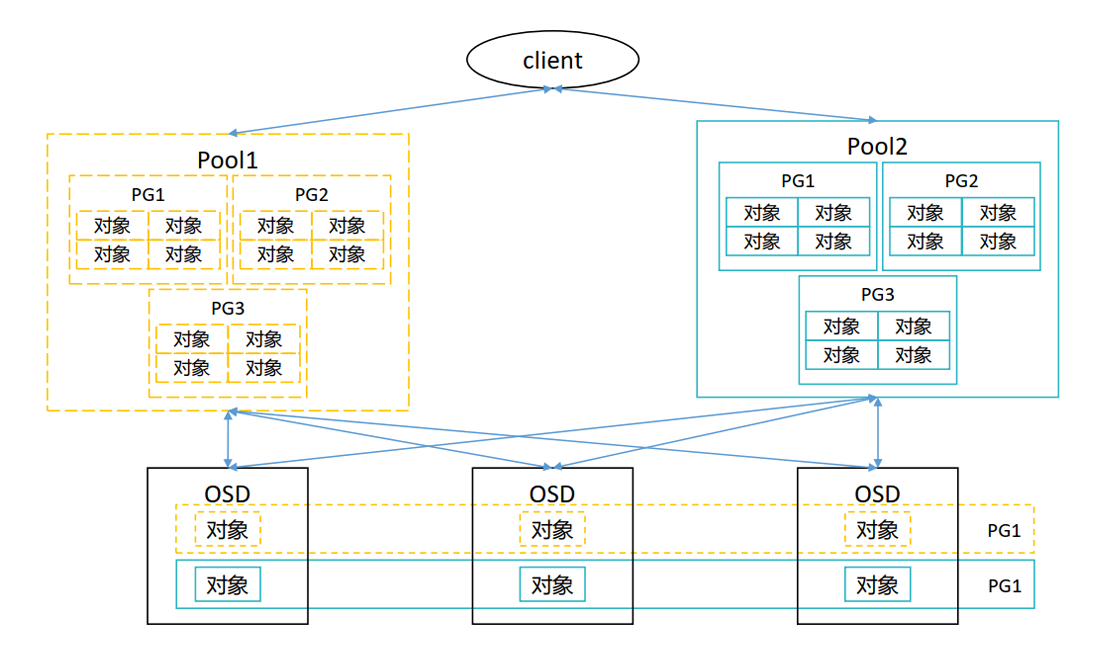
池管理
Ceph 数据组织结构
POOL
池是 Ceph 存储集群的逻辑分区,用于在通用名称标签下存储对象。 Ceph 为每个池分配特定数量放置
组 (PG),用于对对象进行分组以进行存储。
每个池具有以下可调整属性:
池 ID
池名称
PG 数量
CRUSH 规则,用于确定此池的 PG 映射
保护类型(复本或擦除编码)
与保护类型相关的参数
影响集群行为的各种标志
Place Group
PG 全称为Placement group, 是构成pool的子集, 也是一系列对象的集合。一个PG仅能属于一个
Pool。
PG的计算公式为:
Ceph集群PG 总数 = (OSD 数 * 100) / 最大副本数
单个资源池PG总数 = (OSD 数 * 100) / 最大副本数 / 池数
映射对象到OSD
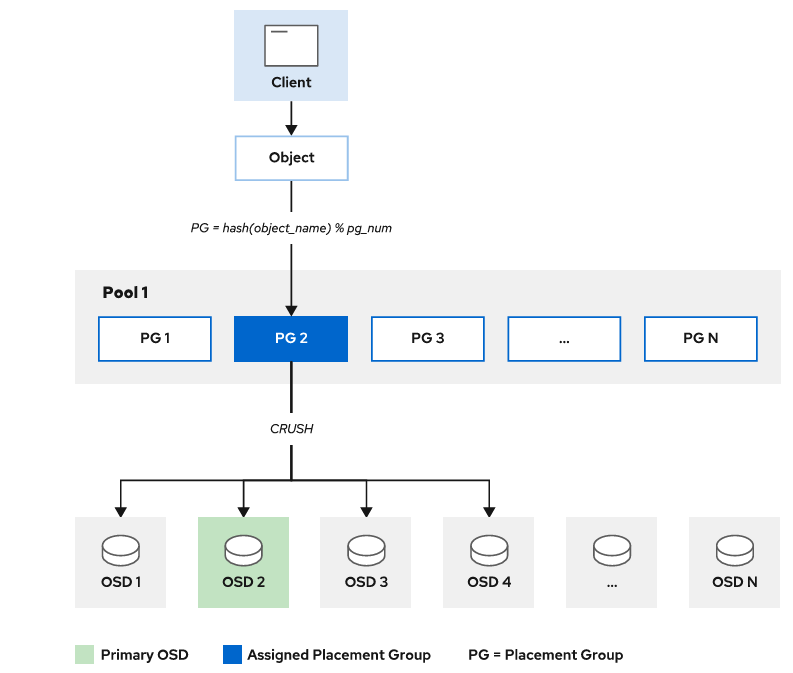
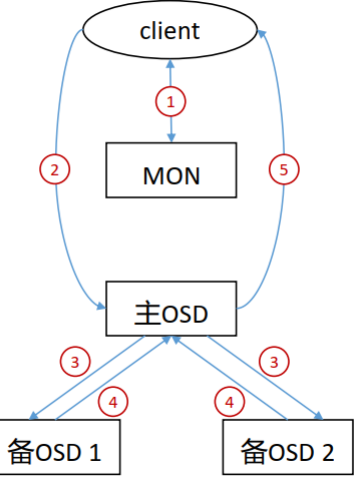
客户端访问ceph流程
- 客户端向MON集群发起连接请求。
- 客户端和MON建立连接后,它将索引最新版本的cluster map,从而获取到MON、 OSD和MDS的信息,但不包括对象的存储位置。
- client根据CRUSH算法计算出对象对应的PG和OSD。
- client根据上步中计算得出主OSD的位置,然后和其进行通信,完成对象的读写。
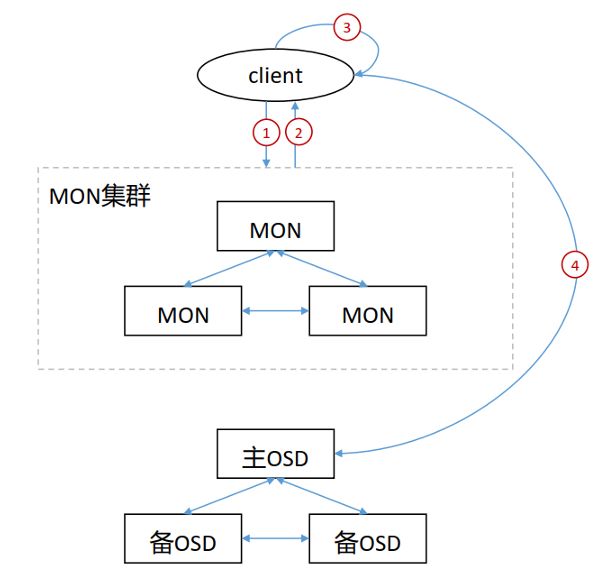
Ceph 数据读取流程
- 客户端通过MON获取到cluster map。
- client通过cluster map获取到主OSD节点信息,并向其发送读取请求。
- 主OSD将client请求的数据返回给client。
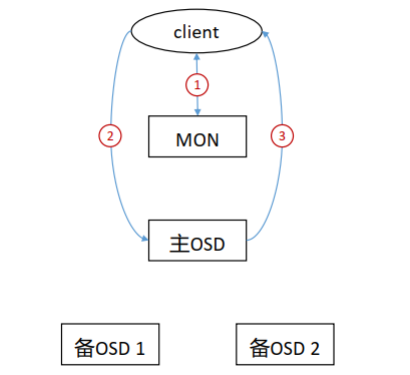
Ceph 数据写入流程
- 客户端通过 MON 获取到 cluster map。
- 客户端通过cluster map获取到主OSD节点信息,并向其发送写入请求。
- 主OSD收到写入请求后,将数据写入,并向两个备OSD发起数据写入指令。
- 两个备OSD将数据写入后返回确认到主OSD。
- 主OSD收到所有备OSD写入完成后的确认后,向客户端返回写入完成的确认
数据保护
Ceph 存储支持:复本池和纠删码池。
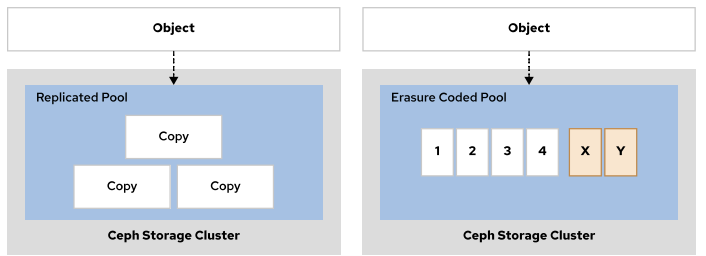
replicated pool(复本池),通过将各个对象复本到多个 OSD 来发挥作用。此池类型会创建多个
对象复本,需要较多存储空间,但其通过冗余提高了读取操作的可用性。
Erasure code pool(纠删代码池),需要较少的存储空间和网络带宽,但因为要进行奇偶校验计
算,所以会占用较多的 CPU处理时间。
池类型选择:
对于不需要频繁访问且不需要低延迟的数据,推荐使用纠删代码池。
对于需要频繁访问并且要具备快速读取性能的数据,推荐使用复本池。
创建池
创建复本池
bash
[root@ceph1 ~]# ceph osd pool create pool_web 32 32 replicated
pool 'pool_web' created
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web
pool_web,指定新池的名称。
第一个32,指定池的放置组 (PG) 总数。
第二个32,指定池的有效放置组数量。将它设置为与 pg_num 相等。该值可省略。
replicated,指定池的类型为复本池;如果命令中未包含此参数,这是默认值。创建纠删代码池
纠删代码池的工作方式:
1.每个对象的数据分割为 k 个数据区块,计算出 m 个编码区块。
2.对象存储在总共 k + m 个 OSD 中。
3.编码区块大小与数据区块大小相同。
纠删代码池有效容量百分比:k / (k+m)。
支持以下 k+m 值,其对应的可用与原始比为:
4+2(比率为 1:1.5)
8+3(比率为 1:1.375)
8+4(比率为 1:1.5)
bash
[root@ceph1 ~]# ceph osd pool create pool_era 32 32 erasure
pool 'pool_era' created
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web
pool_era
##查看默认纠删代码配置
[root@ceph1 ~]# ceph osd erasure-code-profile ls
default
[root@ceph1 ~]# ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
technique=reed_sol_van管理纠删代码配置文件
bash
[root@ceph1 ~]# ceph osd erasure-code-profile set ceph k=4 m=2列出现有的就删代码配置文件
bash
[root@ceph1 ~]# ceph osd erasure-code-profile ls
ceph
default查看现有配置文件的详细信息
bash
[root@ceph1 ~]# ceph osd erasure-code-profile get ceph
crush-device-class=
crush-failure-domain=host
crush-root=default
jerasure-per-chunk-alignment=false
k=4
m=2
plugin=jerasure
technique=reed_sol_van
w=8删除现有的配置文件
bash
[root@ceph1 ~]# ceph osd erasure-code-profile rm ceph
[root@ceph1 ~]# ceph osd erasure-code-profile ls
default查看 池 状态
bash
[root@ceph1 ~]# ceph osd pool ls
device_health_metrics
pool_web
pool_era使用 ceph osd pool ls detail 命令,可以列出池清单和池的详细配置。
bash
[root@ceph1 ~]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0
object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 31 flags
hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr_devicehealth
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins
pg_num 32 pgp_num 32 autoscale_mode on last_change 34 flags hashpspool
stripe_width 0
pool 3 'pool_era' erasure profile default size 4 min_size 3 crush_rule 1
object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 41 flags
hashpspool stripe_width 8192使用 ceph osd lspools 命令,也可以列出池清单。
bash
[root@ceph1 ~]# ceph osd lspools
1 device_health_metrics
2 pool_web
3 pool_era使用 ceph osd pool stats 命令,可以列出池状态信息,池被哪些客户端使用。
bash
[root@ceph1 ~]# ceph osd pool stats
pool device_health_metrics id 1
nothing is going on
pool pool_web id 2
nothing is going on
pool pool_era id 3
nothing is going on使用 ceph df 命令,可以查看池容量使用信息。
bash
[root@ceph1 ~ 16:47:23]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.43
TOTAL 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.43
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 56 GiB
pool_era 3 32 0 B 0 0 B 0 84 GiB
images_pool 4 32 2.8 MiB 14 8.4 MiB 0 56 GiB管理 池
使用 ceph osd pool application 命令
bash
[root@ceph1 ~]# ceph osd pool application <tab><tab>
disable enable get rm set
# 启用池的类型为rbd
[root@ceph1 ~]# ceph osd pool application enable pool_web rbd
enabled application 'rbd' on pool 'pool_web'
[root@ceph1 ~]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins
pg_num 32 pgp_num 32 autoscale_mode on last_change 44 flags hashpspool
stripe_width 0 `application rbd` <------ #看这的变化
# 使用set子命令,设置池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application set pool_web rbd app1 apache
set application 'rbd' key 'app1' to 'apache' on pool 'pool_web'
# 这里添加的设置,app1=apache仅供参考,没有实际意义。
# 使用get子命令,查看池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application get pool_web
{
"rbd": {
"app1": "apache"
}
}
# 使用rm子命令,删除池的应用类型详细配置
[root@ceph1 ~]# ceph osd pool application rm pool_web rbd app1
removed application 'rbd' key 'app1' on pool 'pool_web'
[root@ceph1 ~]# ceph osd pool application get pool_web
{
"rbd": {}
}
# 禁用池的类型
[root@ceph1 ~]# ceph osd pool application disable pool_web rbd --yes-i-reallymean-it
disable application 'rbd' on pool 'pool_web'
[root@ceph1 ~]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins
pg_num 32 pgp_num 32 autoscale_mode on last_change 47 flags hashpspool
stripe_width 0管理 池 配额
使用 ceph osd pool get-quota 命令
bash
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A当存储对象达到限额是,整个池会无法使用
bash
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_objects 100000
set-quota max_objects = 100000 for pool pool_web
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_bytes 10G
set-quota max_bytes = 10737418240 for pool pool_web
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: 100k objects (current num objects: 0 objects)
max bytes : 10 GiB (current num bytes: 0 bytes)当池使用量达到池配额时,操作将被阻止。用户可通过将该值设置为 0 来删除配额。
bash
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_objects 0
set-quota max_objects = 0 for pool pool_web
[root@ceph1 ~]# ceph osd pool set-quota pool_web max_bytes 0
set-quota max_bytes = 0 for pool pool_web
[root@ceph1 ~]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A管理 池 配置
查看池配置
使用 ceph osd pool get 命令,查看池配置。
bash
# 查看池所有配置
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 3 #副本数3
min_size: 2
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false
# 查看池特定配置
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: false
# 备用命令
[root@ceph1 ~]# ceph osd pool get pool_web all | grep nodelete
nodelete: false设置池配置
使用 ceph osd pool set 命令,可以修改池配置选项
bash
# 设置池不可删除
[root@ceph1 ~]# ceph osd pool set pool_web nodelete true
set pool 2 nodelete to true
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: true
# 将 nodelete 重新设置为 FALSE,即可允许删除池
root@ceph1 ~]# ceph osd pool set pool_web nodelete false
set pool 2 nodelete to false
[root@ceph1 ~]# ceph osd pool get pool_web nodelete
nodelete: false管理 池 复本数
bash
[root@ceph1 ~]# ceph osd pool set pool_web size 2
set pool 2 size to 2 #2 size to 2???没变,别闹这里说的时pool2 的size 变成2,
pool2是谁??
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 2 #这里确实从之前的3变成了2
min_size: 1
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false池的默认复本数量由 osd_pool_default_size 配置参数定义,默认值为 3。
bash
[root@ceph1 ~]# ceph config get mon osd_pool_default_size
3使用以下命令定义创建新池的默认复本数量。
bash
[root@ceph1 ~]# ceph config set mon osd_pool_default_size 2
[root@ceph1 ~]# ceph config get mon osd_pool_default_size
2管理 池 PG 数
bash
[root@ceph1 ~]# ceph osd pool set pool_web pg_num 64
set pool 2 pg_num to 64
[root@ceph1 ~]# ceph osd pool get pool_web all
size: 2
min_size: 1
pg_num: 64 #确实PG变为了64
pgp_num: 64
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false管理 池 中对象
上传对象到池中
bash
[root@ceph1 ~]# echo laogao1 > hosts1
[root@ceph1 ~]# rados -p pool_web put hosts hosts1 #将host1文件上传到webapp池取名
为hosts
[root@ceph1 ~]# rados -p pool_web ls
hosts查看池中对象状态
bash
[root@ceph1 ~]# rados -p pool_web stat hosts
pool_web/hosts mtime 2025-08-21T09:52:43.000000+0800, size 8查看池中对象存储在哪里
bash
[root@ceph1 ~]# ceph osd map pool_web hosts
[root@ceph1 ~]# ceph osd metadata osd.4
[root@ceph1 ~]# ceph pg dump pgs_brief检索对象到本地
bash
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
laogao1追加池中对象
bash
[root@ceph1 ~]# echo laogao2 >> hosts2
[root@ceph1 ~]# rados append -p pool_web hosts hosts2
[root@ceph1 ~]# rados get hosts newhosts -p pool_web
[root@ceph1 ~]# cat newhosts
laogao1
laogao2删除池中对象
bash
[root@ceph1 ~]# rados put passwd /etc/passwd -p pool_web
[root@ceph1 ~]# rados ls -p pool_web
passwd
hosts
[root@ceph1 ~]# rados rm passwd -p pool_web
[root@ceph1 ~]# rados ls -p pool_web
hosts管理 池 快照
创建快照
使用 ceph osd pool mksnap 命令,创建池快照
bash
[root@ceph1 ~]# ceph osd pool mksnap pool_web snap1 #给池pool_web创建快照snap1
created pool pool_web snap snap1
[root@ceph1 ~]# ceph osd pool ls detail
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins
pg_num 64 pgp_num 64 autoscale_mode off last_change 68 lfor 0/0/60 flags
hashpspool,pool_snaps stripe_width 0
snap 1 'snap1' 2025-08-21T02:05:02.662386+0000 #多了snap1
[root@ceph1 ~]# rados -p pool_web lssnap
1 snap1 2025.09.29 14:38:50
1 snaps删除快照
使用 ceph osd pool rmsnap 命令,删除池快照。
bash
[root@ceph1 ~]# ceph osd pool rmsnap pool_web snap1
removed pool pool_web snap snap1
[root@ceph1 ~]# ceph osd pool ls detail
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins
pg_num 64 pgp_num 64 autoscale_mode off last_change 69 lfor 0/0/60 flags
hashpspool,pool_snaps stripe_width 0
[root@ceph1 ~]# rados -p pool_web lssnap
0 snaps管理 池 快照中对象
对池某个快照中对象操作需要使用-s选项指定快照名称。
bash
[root@ceph1 ~]# ceph osd pool mksnap pool_web snap1 #给池pool_web拍摄快照snap1
created pool pool_web snap snap1
[root@ceph1 ~]# rados -p pool_web listsnaps hosts
hosts:
cloneid snaps size overlap
head - 16
#拍摄快照后,上传新的内容到hosts中
[root@ceph1 ~]# echo laogao3 > hosts3
[root@ceph1 ~]# rados -p pool_web put hosts hosts3
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
laogao3
# 查看快照中对象
[root@ceph1 ~]# rados ls -p pool_web -s snap1
selected snap 3 'snap1'
hosts
# 获取快照中对象
[root@ceph1 ~]# rados -p pool_web -s snap1 get hosts hosts-from-snap1
selected snap 3 'snap1'
[root@ceph1 ~]# cat hosts-from-snap1 #发现即使hosts文件拍摄快照后变了,从快照获取
的依然没变
laogao1
laogao2
# 恢复对象内容为指定快照时内容
[root@ceph1 ~]# rados -p pool_web rollback hosts snap1
rolled back pool pool_web to snapshot snap1
[root@ceph1 ~]# rados -p pool_web get hosts newhosts
[root@ceph1 ~]# cat newhosts
laogao1
laogao2快照是只读文件系统,无法上传和删除快照中对象。
bash
[root@ceph1 ~]# rados put -p pool_web -s snap1 passwd /etc/passwd
selected snap 3 'snap1'
error putting pool_web/passwd: (30) Read-only file system
[root@ceph1 ~]# rados ls -p pool_web -s snap1
selected snap 3 'snap1'
hosts
[root@ceph1 ~]# rados rm -p pool_web -s snap1 hosts
selected snap 3 'snap1'
error removing pool_web>hosts: (30) Read-only file system管理 池 命名空间
bash
[root@ceph1 ~]# rados put -p pool_web -N myns1 hostname1 /etc/hostname
[root@ceph1 ~]# rados ls -p pool_web
hosts
[root@ceph1 ~]# rados ls -p pool_web -N myns1 #上传的hsotname1在namespace
myns1中
hostname1
[root@ceph1 ~]# rados put -p pool_web -N myns2 hostname2 /etc/hostname
[root@ceph1 ~]# rados ls -p pool_web -N myns2
hostname2
[root@ceph1 ~]# rados ls -p pool_web --all
myns1 hostname1
hosts
myns2 hostname2
[root@ceph1 ~]# rados ls -p pool_web --all --format=json-pretty
[
{
"namespace": "myns1",
"name": "hostname1"
},
{
"namespace": "",
"name": "hosts"
},
{
"namespace": "myns2",
"name": "hostname2"
}
]重命名池
使用 ceph osd pool rename 命令,重命名池
bash
[root@ceph1 ~]# ceph osd pool rename pool_web pool_apache
pool 'pool_web' renamed to 'pool_apache'删除池
使用 ceph osd pool delete 命令,删除池。
bash
[root@ceph1 ~]# ceph osd pool rm pool_apache
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool
pool_apache. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the
pool name *twice*, followed by --yes-i-really-really-mean-it.
#根据提示需要将pool name输入两次,跟上参数--yes-i-really-really-mean-it
[root@ceph1 ~]# ceph osd pool rm pool_apache pool_apache --yes-i-really-reallymean-it
Error EPERM: pool deletion is disabled; you must first set the
mon_allow_pool_delete config option to true before you can destroy a pool
#提示需要先将mon_allow_pool_delete选项配置为true才能删除pool