很多随机算法并不是靠"运气好"工作,而是靠候选空间里存在大量可用证据。只要证据足够密集,随机抽样就不再像碰运气,而更像一种低成本的搜索策略。
对于某个输入 xx,如果额外给出一段信息 ww,我们就能比直接求解更高效地验证某个结论。在计算复杂性中,这类辅助信息通常被称为 witness,也可以理解为"证人"或"证据"。算法不一定知道 witness 分布在哪里,也不一定能直接构造 witness;但它必须能够高效检查一个候选者是否为 witness。只要 witness 在候选集合里足够多,随机抽一个候选者就有不错的概率命中。
素数测试是这个思想的经典例子。我们想判断一个正整数 nn 是素数还是合数。直接分解 nn 目前没有已知的经典多项式时间算法,但证明"nn 是合数"有时可以很容易:只要找到一个合适的 witness。
素数测试问题
给定整数 nn,最直接的素数测试是试除法:从 22 一直试到 nn,只要发现某个 ii 整除 nn,就知道 nn 是合数。
kotlin
is_prime(n):
i = 2
while i <= sqrt(n):
if n mod i == 0:
return false
i = i + 1
return true从数值大小看,这个算法的复杂度是 O(n)O(n),似乎还能接受;但在这个问题的背景下,输入的规模一般不是输入的数字 nn,而是 nn 的位数。若输入长度记为 ll,那么大约有 l=lognl=logn。试除到 nn 等价于试到 2l/22l/2 量级。所以,这是一个指数时间算法。
因此,高效的素数测试真正关心的是能否在 lognlogn 的多项式时间内完成。这就要求我们不能逐个检查可能因子,而要寻找更便宜的证据。
什么样的 witness 才有用
谁能证明"nn 是合数"?一个自然的 witness 是 nn 的非平凡因子。若存在 aa 满足 1<a<n1<a<n 且 a∣na∣n,那么 aa 可以直接证明 nn 是合数。检查它也很快,只需要计算 nmodanmoda。
问题在于,因子作为 witness 太稀疏。假设 n=pqn=pq,其中 pp 和 qq 是两个很大的素数。候选集合可以取 2,...,n−12,...,n−1,大小接近 nn,但真正能整除 nn 的候选者可能只有很少几个。随机抽一个数,命中因子的概率非常低。
这说明 witness 的定义不能只满足"可验证",还要满足"数量多"。一个适合随机算法的 witness 定义通常要满足三个条件:它能高效证明目标结论;任意候选者是否为 witness 可以高效检查;在候选集合中,witness 的比例不能太低,最好有常数级下界。
如果候选集合为 CC,witness 集合为 W⊆CW⊆C,我们希望存在常数 α>0α>0,使得 ∣W∣/∣C∣≥α∣W∣/∣C∣≥α。这样随机抽取一个候选者,命中 witness 的概率至少是 αα。
换句话说,随机算法并不害怕不知道 witness 在哪里;它害怕的是 witness 太少。只要证据足够多,随机性就能把"寻找证据"的成本降下来。
Fermat 测试:从素数的必要条件出发
而确实有这样一个数学定理可以帮上忙。Fermat 小定理给了一个更好的方向。它的内容是:若 nn 是素数,并且 a≢0(modn)a≡0(modn),则有
an−1≡1(modn)an−1≡1(modn)
这给出了一个反向证据:如果我们找到某个 aa,使得 an−1≢1(modn)an−1≡1(modn),那么 nn 一定不是素数。这样的 aa 就可以作为 nn 为合数的 witness。
于是可以写出一个简单的测试:
kotlin
fermat_test(n, a):
if pow_mod(a, n - 1, n) != 1:
return composite
else:
return probably_prime这里的 pow_mod 不是先算出巨大的 an−1an−1 再取模,而是在每一步乘法后取模,即使用快速模幂完成计算。因为指数 n−1n−1 有 O(logn)O(logn) 位,可以在 O(logn)O(logn) 次模乘内完成,这已经是输入长度的多项式时间。
实际实现中,通常还会先计算 gcd(a,n)gcd(a,n)。如果 1<gcd(a,n)<n1<gcd(a,n)<n,那么我们已经找到了 nn 的一个非平凡因子,可以立即判定 nn 是合数。
固定取 a=2a=2 可以得到一个非常便宜的测试:
kotlin
if pow_mod(2, n - 1, n) == 1:
return probably_prime
else:
return composite如果返回 composite,结果是确定的;如果返回 probably_prime,则不一定正确。因为存在合数 nn 也满足 2n−1≡1(modn)2n−1≡1(modn),这类数被称为以 22 为底的 Fermat 伪素数。
这时随机选择 aa 可以减少对单个底数的依赖:
kotlin
a = random integer in [2, n - 2]
if pow_mod(a, n - 1, n) == 1:
return probably_prime
else:
return composite但仍然不够理想。有些合数会对大量底数通过 Fermat 条件。问题不是模幂计算不够快,而是 witness 的定义还不够强。
Fermat 测试看的是终点:an−1an−1 是否等于 11。如果只看终点,有些合数确实能伪装得很好。Miller-Rabin 测试的改进之处在于,它不只看终点,还检查通向这个终点的平方链是否像素数模数下那样"合法"。
Miller-Rabin:更强的合数证人
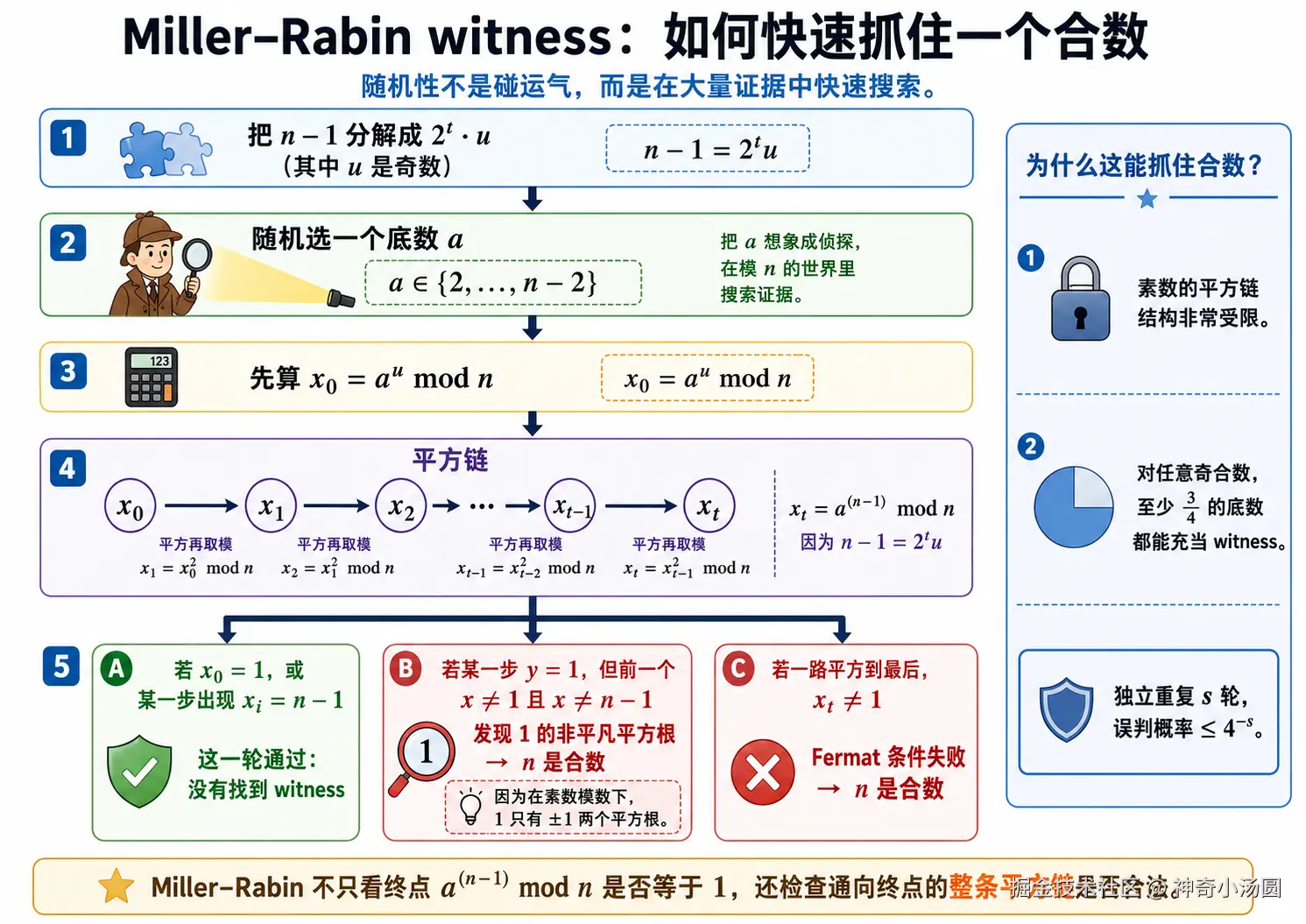
Miller-Rabin 测试对 Fermat 条件做了加强,将得到 an−1modnan−1modn 的过程分解。
对于奇数 n≥5n≥5,将 n−1n−1 提出 22 因子,写成
n−1=2tun−1=2tu
其中 uu 是奇数。然后随机选择一个候选底数 aa,先计算 x0=aumodnx0=aumodn,然后不断平方:
xi=xi−12modnxi=xi−12modn
可以推出,最终的 xt=an−1modnxt=an−1modn。最终的结果和费马素数的判定是一致的,但是在原基础上,我们增加了对中间结果的判断。如果 nn 是素数,那么这条平方链必须满足一些非常受限的结构。Miller-Rabin 的 witness 检查正是利用这些结构。
kotlin
witness(a, n):
write n - 1 = 2^t * u, where u is odd
x = pow_mod(a, u, n)
repeat t times:
y = x * x mod n
if y == 1 and x != 1 and x != n - 1:
return true
x = y
if x != 1:
return true
return falsewitness(a, n) 返回 true 表示 aa 成功证明了 nn 是合数。
这里有两类失败模式。第一类是 Fermat 条件本身失败:最终得到的 an−1modnan−1modn 不是 11,那么 nn 必然是合数。第二类更微妙:在平方链中出现了 11 的非平凡平方根。
这是因为质数的一些特殊性质,对于素数模数,11 的平方根只能是 ±1±1(也就是 11 和 n−1n−1 )。出现其他平方根,说明模数一定不是素数。这一点可以从 (x−1)(x+1)≡0(modn)(x−1)(x+1)≡0(modn) 看出来。若 nn 是素数,则乘积为 00 意味着至少一个因子为 00,于是 x≡1x≡1 或 x≡−1x≡−1。只有合数模数下才可能出现更复杂的零因子现象。
因此,如果在迭代过程中,某一步有 y≡1(modn)y≡1(modn),而对应的 xx 既不是 11 也不是 n−1n−1,那么 nn 一定不是质数。
错误概率指数下降
这样一来,Miller-Rabin 的完整算法很短:
kotlin
miller_rabin(n, s):
if n < 2:
return composite
if n == 2 or n == 3:
return prime
if n mod 2 == 0:
return composite
repeat s times:
a = random integer in [2, n - 2]
if witness(a, n):
return composite
return probably_prime这个算法有单侧错误。若它返回 composite,一定正确,因为已经找到了合数 witness。若它返回 probably_prime,则表示在 ss 次随机尝试中都没有找到 witness。
更准确地说,若 nn 是素数,任何合法底数都不会让 Miller-Rabin 返回 composite。错误只可能发生在另一侧:nn 实际上是合数,但随机选择的底数都没有暴露它的合数性。
对于任意奇合数 nn,可以证明,多四分之一的底数会让合数通过 Miller-Rabin 测试。也就是说,至少四分之三的候选底数可以作为合数 witness。因此,如果 nn 实际上是合数,一次随机测试没有命中 witness 的概率至多为 1/41/4。
独立重复 ss 次时,全部失败的概率至多是
P(error)≤(14)s=4−sP(error)≤(41)s=4−s
这就是 witnesses 的力量。算法并不需要知道 witness 分布在哪里,也不需要显式构造它们;只要 witness 在候选集合里足够密集,随机抽样就足以给出很强的概率保证。
实际使用中,s=40s=40 已经让错误概率小到可以忽略。若应用场景需要更强保证,可以继续增加 ss,代价只是线性增加测试轮数。
常用的底数选取和已知伪素数
在实际应用中,当需要完全确定地判断一个不超过某个上限的整数是否为素数时,可以放弃随机抽样,转而使用一组固定且经过验证的底数。此时 Miller-Rabin 测试退化为确定性算法,因为对于该范围内的所有合数,至少其中一个底数能充当 witness。
常见确定性底数集合
| 最大整数范围 | 底数集合 | 说明 |
|---|---|---|
| 2152302898747 | 2, 3, 5, 7, 11 | 常见于 32 位整数场景 |
| 3474749660383 | 2, 3, 5, 7, 11, 13 | |
| 264264 | 2, 325, 9375, 28178, 450775, 9780504, 1795265022 | 经过充分验证的 7 个底数集合 |
| 21282128 | 2, 3, 5, 7, 11, 13, 17 | 未严格证明但实践中几乎总是可靠 |
| 3317044064679887385961981 | 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37 | 由 J. Sorenson 和 J. Webster 验证的一组底数,覆盖极大范围 |
已知的强伪素数(Strong Pseudoprime)
即便使用了 Miller-Rabin,某些合数仍能针对一组特定底数"伪装"成素数。这些数被称为强伪素数。
- 以 2 为底的强伪素数:最小的是 2,047=23×892,047=23×89。也就是说,Miller-Rabin 测试若只用 a=2a=2,会把 2047 判为素数。
- 以 2 和 3 为底的强伪素数:最小的是 1,373,653=829×1,6571,373,653=829×1,657。
- 同时以 2、3、5、7 为底的强伪素数:已知最小的是 3,215,031,751=151×751×28,3513,215,031,751=151×751×28,351。
总的来说,Miller-Rabin 之所以能从"概率算法"走向"工程上可信任的实用工具",正是基于一个根本事实:合数的 witness 在底数空间中占据压倒性多数(至少 75%)。只需少量随机抽样,就能以指数速度衰减的误差概率获得正确判定。
这些例子表明了为何不能依赖少数几个固定底数做广泛范围的素数测试。对于超出上述表格范围的整数,仍然应该使用随机底数,保证高概率正确。
确定性素数测试
长期以来,一个自然问题是:这些 witness 是否只是"随机上很多",还是存在某种可被确定性利用的结构?2002 年,AKS 素数测试给出了确定性多项式时间算法,证明素数判定确实属于 P。这在理论上非常重要,因为它不依赖随机抽样,也不再输出 probably_prime,而是确实有多项式时间准确判定是否是素数的方法。
不过,理论复杂度和工程表现是两回事。AKS 的历史意义不等于它在常规应用中优于 Miller-Rabin。实际系统里,Miller-Rabin 仍然常用,因为它实现简单、速度快,并且错误概率可以通过重复测试降到极低。对于许多固定字长整数,还可以选择一组已知底数,使 Miller-Rabin 在该范围内变成确定性测试。
同时,Abundance of Witnesses 给出的不是某个特定算法技巧,而是一种设计算法的角度:如果直接求解困难,就寻找一种容易验证且大量存在的证据。素数测试里,因子是证据,但太少;Fermat witness 更便宜,但不够强;Miller-Rabin witness 把"证据密度"和"验证效率"平衡到了一个适合随机算法的位置。随机性在这里不是替代证明,而是用来快速找到证明。