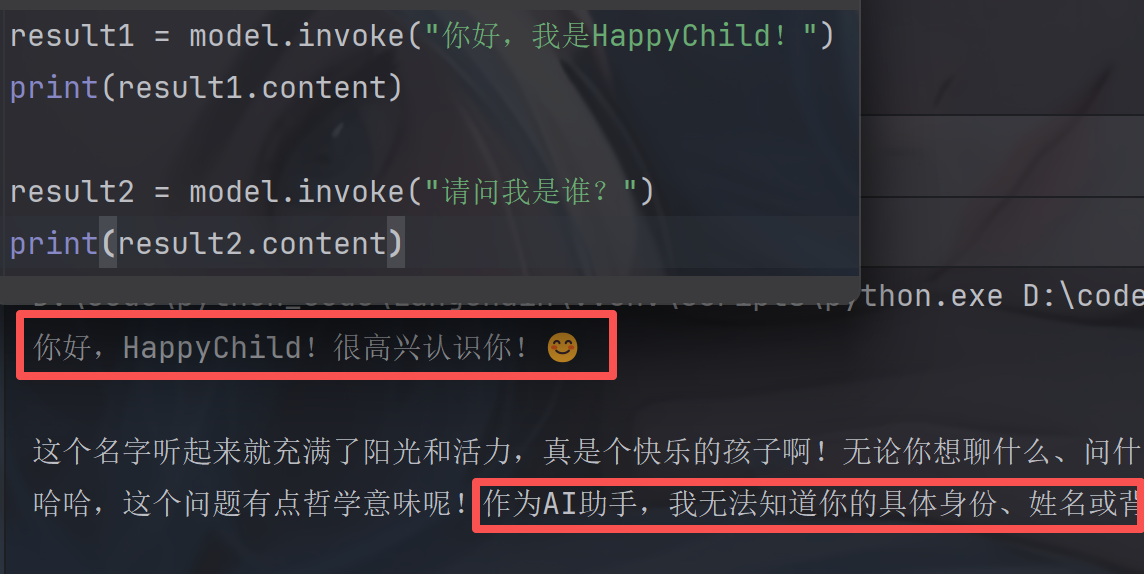
1.原生LLM消息结构
消息结构一般都是由角色和内容组成,以及因 LLM 的不同⽽不同的附加元数据。
•
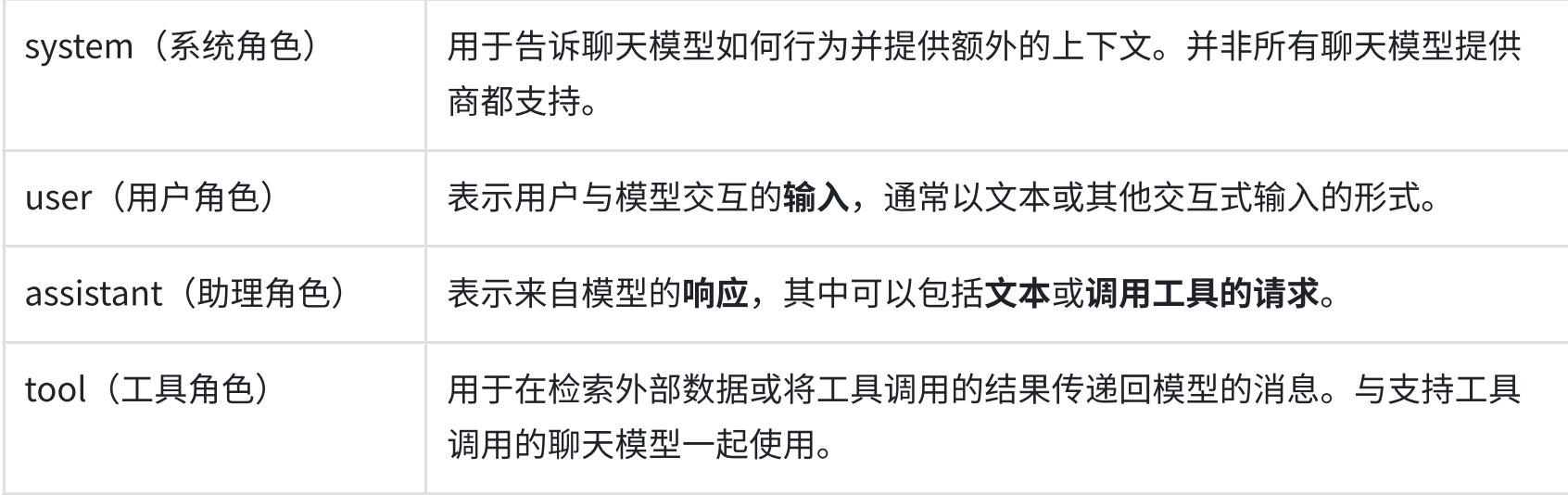
消息⻆⾊ (Role):⽤来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。
•
消息内容 (Content):表⽰多模态数据 (例如,图像、⾳频、视频)的消息⽂本或字典列表的内容。内容的具体格式可能因底层不同的 LLM ⽽异。⽬前,⼤多数模型都⽀持⽂本作为主要内容类型,对多模态数据的⽀持仍然有限。
•
消息其他元数据 (Additional metadata)
2.LangChain消息结构
LangChain 提供了⼀种统⼀的消息格式,可以跨聊天模型使⽤,允许⽤⼾使⽤不同的聊天模型,⽽⽆需担⼼每个模型提供商使⽤的消息格式的具体细节。
比如LangChain使用init_chat_model选择不同的模型,最后还是利用统一的格式进行消息传参:
pythonopenai_model = init_chat_model("gpt-4o-mini", model_provider="openai") anthropic_model = init_chat_model("claude-3-5-sonnet-latest", model_provider="anthropic") deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek") google_genai_model = init_chat_model("gemini-2.5-flash", model_provider="google_genai") model = init_chat_model(...) messages = [ SystemMessage("你是一位擅长写七言绝句的诗人,能根据用户输入的主题生成优雅有韵律的诗!"), HumanMessage("帮我写首关于星空的诗。") ]LangChain常见的消息格式类型:
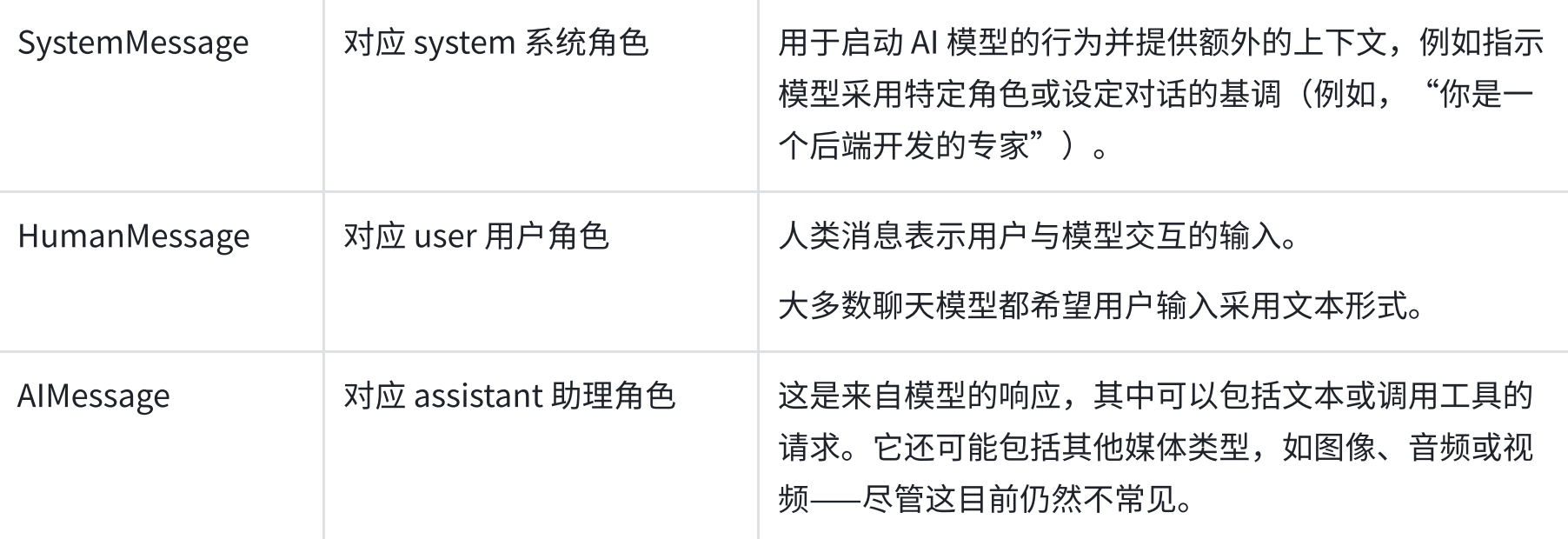

BaseMessage
上面展示的消息类型我们之前的文章都提到过,它们都是 LangChain BaseMessage 的⼦类,全部是作为 LangChain 聊天模型的输⼊和输出
参数如下:
•
content :消息的字符串内容。
•
additional_kwargs :与消息关联的其他有效负载数据。对于来⾃ AI 的消息,可能包括模
型提供程序编码的⼯具调⽤。
•
response_metadata :响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
•
type :消息的类型。必须是消息类型唯⼀的字符串。此字段的⽬的是在对消息进⾏反序列化时⽅便地识别消息类型。
•
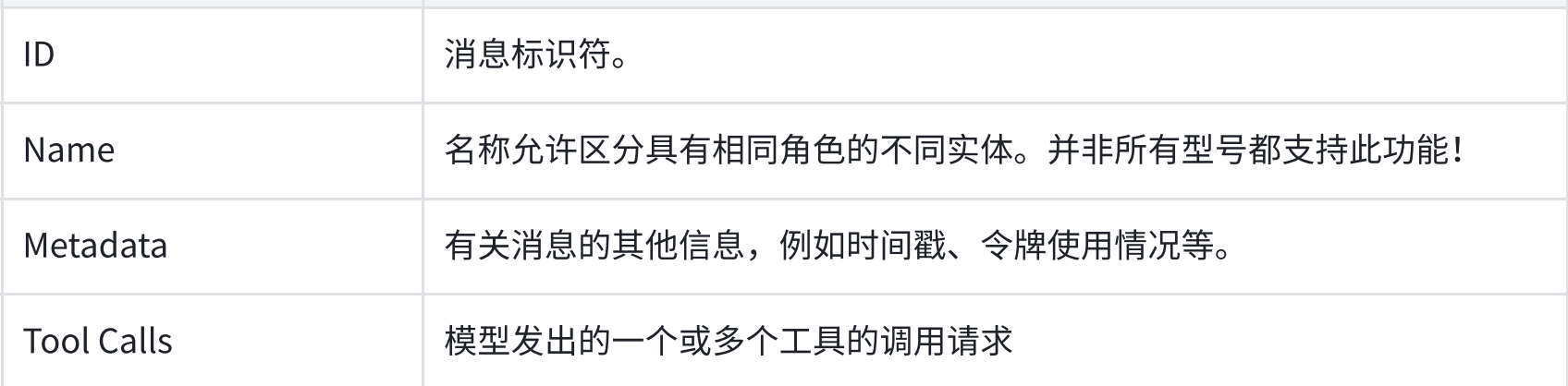
name :消息名称,为消息提供⼀个⼈类可读的名称。该字段的使⽤是可选的,是否使⽤它取决于模型实现。
•
id :消息的可选唯⼀标识符。理想情况下,这应该由创建消息的提供者/模型提供。
内置⽅法:
pretty_print() **→**None :打印消息的漂亮表⽰。
pretty_repr(html: bool = False) **→**str :获得消息的漂亮表⽰。
(1)请求:是否将消息格式化为 HTML。如果为 True,则消息将使⽤ HTML 标记进⾏格式化。默认值为 False。
(2)响应:这是消息的漂亮表⽰。
text() **→**str :获取消息的⽂本内容。
3.历史消息缓存
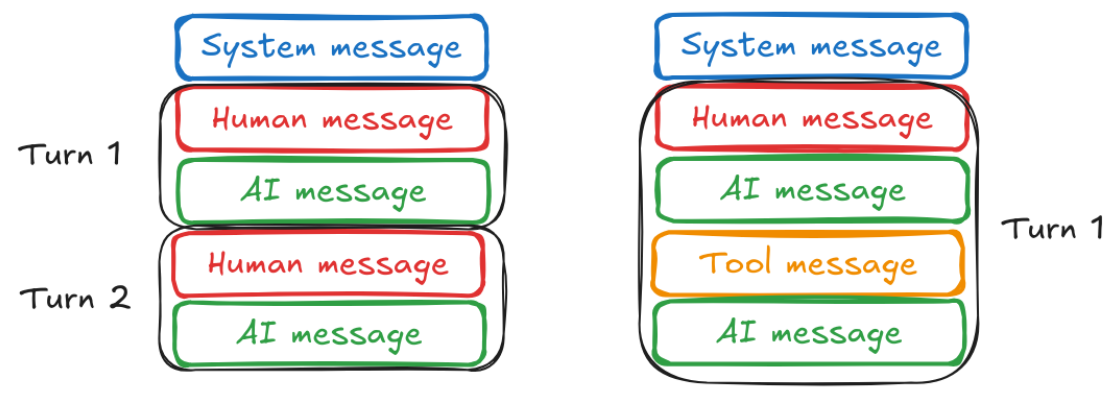
我们使用大模型进行对话时,大多数都是设置对话上下⽂的系统消息开始。接下来是包含⽤⼾输⼊的⽤⼾消息,然后是包含模型响应的助⼿消息
当我们采用通用的对话方式时,LLM不会记忆上下文信息,自动就是单论对话。这种对话无法让LLM记录历史信息。
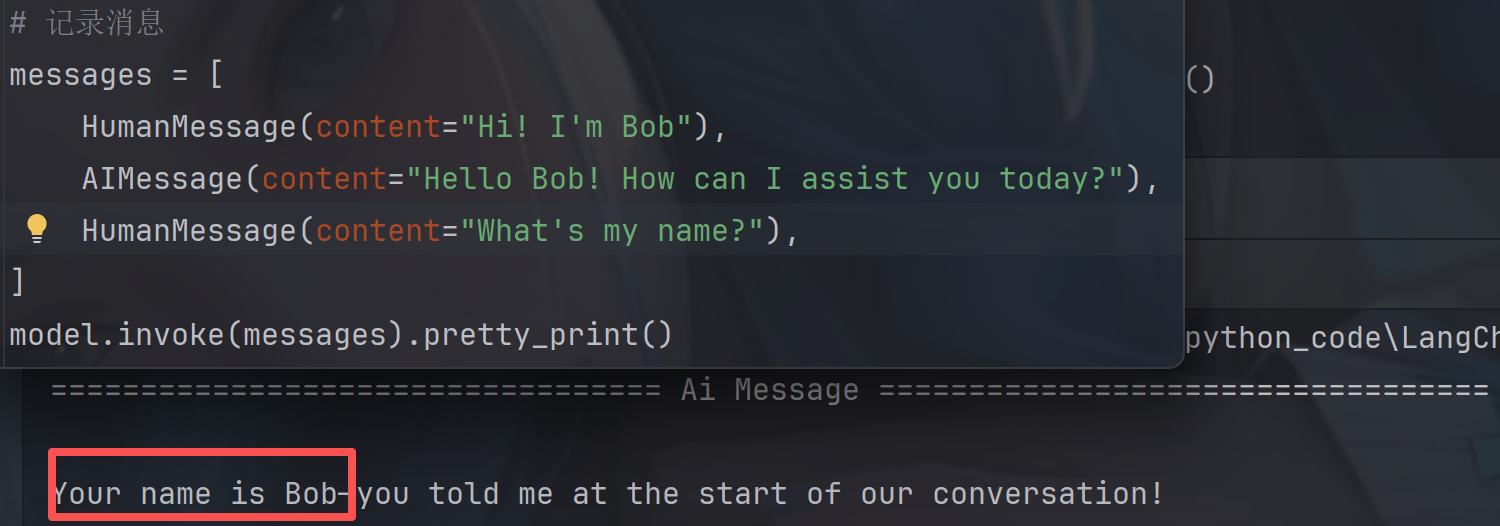
我们可以使用手动维护LLM传来的AImessages来记录上下文:
但当信息一多,手动维护消息列表就不现实了,所以在LangChain老版本中使⽤ RunnableWithMessageHistory 消息历史类来包装另⼀个 Runnable 并为其管理聊天消息历史 记录。它将跟踪模型的输⼊和输出,并将其存储在某个数据存储中。未来的交互将加载这些消息,并 将其作为输⼊的⼀部分传递给链。
注:从 LangChain 的 v0.3 版本开始,官⽅建议 LangChain ⽤⼾不要使⽤
RunnableWithMessageHistory ,⽽是利⽤ LangGraph 持久性 来完成
pythonimport os from langchain_openai import ChatOpenAI from langchain_core.messages import HumanMessage, AIMessage from langchain_core.chat_history import BaseChatMessageHistory,InMemoryChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory # 定义⼤模型 model = ChatOpenAI( model = "deepseek-v4-flash", api_key=os.getenv("DEEPSEEK_API_KEY"), base_url=os.getenv("DEEPSEEK_BASE_URL"), ) store = {} # 接受⼀个 session_id 并返回⼀个消息历史对象。 # 这个 session_id ⽤于区分不同的对话,并应作为配置的⼀部分在调⽤新链时传⼊ def get_session_history(session_id: str) -> BaseChatMessageHistory: if session_id not in store: # InMemoryChatMessageHistory() 将消息存储在内存列表中。 store[session_id] = InMemoryChatMessageHistory() return store[session_id] # 包装model,管理聊天消息历史记录 with_message_history = RunnableWithMessageHistory(model, get_session_history) config = {"configurable": {"session_id": "1"}} with_message_history.invoke( [HumanMessage(content="Hi! I'm Bob")], config=config, ).pretty_print() with_message_history.invoke( [HumanMessage(content="What's my name?")], config=config, ).pretty_print()

4.管理消息
对于任意一款模型而言,留存信息都有一个固定的上下文窗口,包含输入和输出的所有token总数。当我们的输入token总数上升,输出就没有空间了无法再执行任务了。所以我们要合理管理消息,对消息进行curd操作。
4.1消息裁剪trim_messages()
LangChain中trim_messages 可⽤于将聊天历史记录的⼤⼩减⼩为指定的令牌计数或指定的消息计数。
用下面代码进行演示:
python
import os
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
response = model.invoke(messages)
print(response)
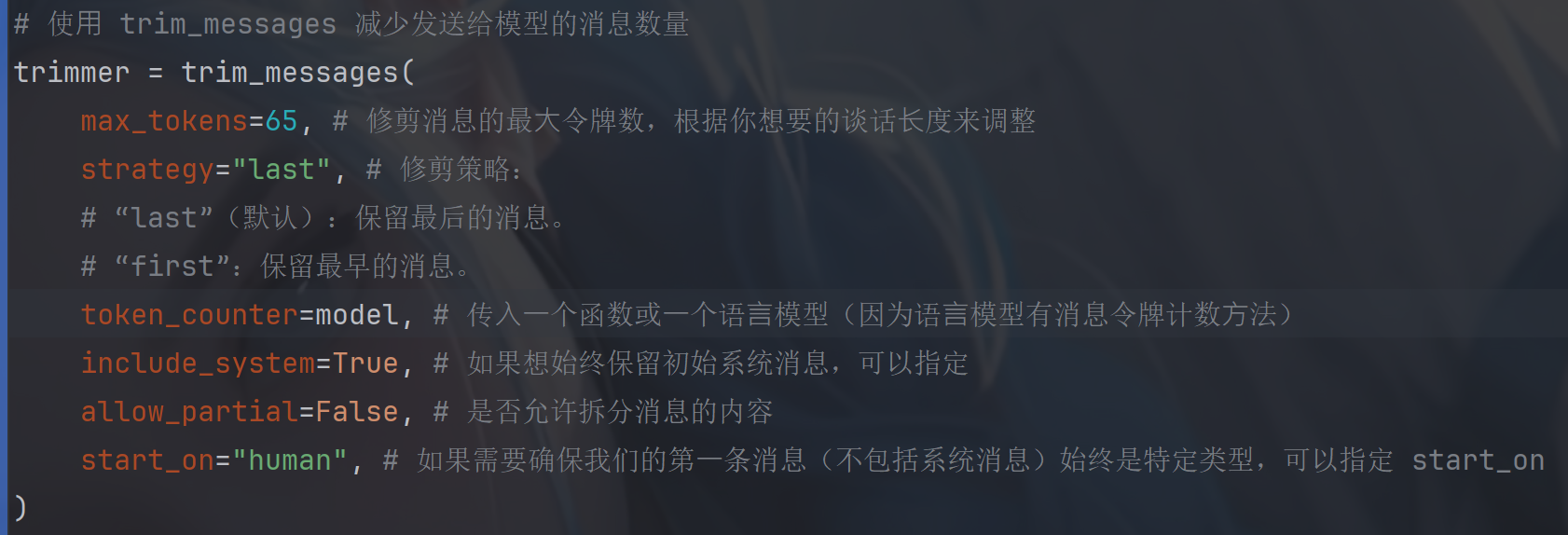
进行裁剪:
trim_messages()参数:
注意:DeepSeek 模型不支持 get_num_tokens_from_messages() 方法,所以再trim_messages()无法使用deepseek
python
model = ChatOpenAI(model="gpt-5.5")
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 使⽤ trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=65, # 修剪消息的最⼤令牌数,根据你想要的谈话⻓度来调整
strategy="last", # 修剪策略:
# "last"(默认):保留最后的消息。
# "first":保留最早的消息。
token_counter=model, # 传⼊⼀个函数或⼀个语⾔模型(因为语⾔模型有消息令牌计数⽅法)
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
# response = model.invoke(messages)
# print(response)
chain = trimmer | model #先裁剪消息后传给model
print(chain.invoke(messages))
python
结果:
usage_metadata={
'input_tokens': 60,
'output_tokens': 16,
'total_tokens': 76,
'input_token_details': {
'audio': 0, 'cache_read': 0
},
'output_token_details': {
'audio': 0,
'reasoning': 0
}
}除了基于 token 的修剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这 种情况下, max_tokens 将控制最⼤消息数。
python
# 使⽤ trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=11, # 最⼤消息数
strategy="last", # 修剪策略:
# "last"(默认):保留最后的消息。可获取消息列表中的最后⼀个 max_tokens
# "first":保留最早的消息。
token_counter=len, # 根据消息数裁剪
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第⼀条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)4.2消息筛选filter_messages()
当消息过多时我们可以进行过滤保留我们想要的消息,LangChain提供了filter_messages()供我们使用。
使用形式:
python
filter_messages(messages, i/enclude_types=[HumanMessage, ...],i/exclude_ids=["3",...],...)
python
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
# 历史消息记录
messages = [
SystemMessage("你是⼀个聊天助⼿", id="1"),
HumanMessage("⽰例输⼊", id="2"),
AIMessage("⽰例输出", id="3"),
HumanMessage("真实输⼊", id="4"),
AIMessage("真实输出", id="5"),
]
print(filter_messages(messages, include_types="human"))
# 注意写法等价于:
# print(filter_messages(include_types="human").invoke(messages))
print(filter_messages(messages, include_types=[HumanMessage, AIMessage],exclude_ids=["3"]))
4.3消息合并merge_message_runs()
对于用户输入的同类型的不同消息我们可以利用merge_message_runs进行合并。
python
# 消息合并
model = ChatOpenAI(
model = "deepseek-v4-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL"),
)
# 历史消息记录
messages = [
SystemMessage("你是⼀个聊天助⼿。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使⽤ LangChain?"),
HumanMessage("为什么要使⽤ LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage("不过别担⼼,它不会"分散"你的注意⼒!"),
HumanMessage("选择LangChain还是LangGraph?"),
]
merged = merge_message_runs(messages)
# 打印合并后的每个消息
print("\n".join([repr(x) for x in merged]))