AgentOps 是什么?Agent 可观测性从零到一
Agent 不是"调一次 API 就完事"的应用------它在多轮思考、工具调用、甚至自我纠错中完成一个任务。这种复杂性让可观测性从"锦上添花"变成了"保命刚需"。
一、引言
2025 年被称为"Agent 元年"。从 coding agent、客服 agent 到 browser-use agent,AI 应用正在从"单次问答"进化到"多步自主执行"。但 Agent 带来了全新的工程挑战------一个用户请求可能触发:
- 5 次 LLM 调用(思考、规划、执行、校验、总结)
- 3 次工具调用(搜索文档、查询数据库、执行代码)
- 2 次内部循环(结果不符合预期 → 重试)
当用户说"你的 Agent 回答错了",你该怎么排查?是 Prompt 的问题?是检索到的上下文有问题?还是工具调用返回了错误结果?传统的日志系统完全无法应对这种复杂度。
读完这篇文章,你将理解:
- AgentOps 与 LLMOps 的核心区别
- Agent 场景独有的可观测性维度
- 主流方案的能力对比和选型建议
- 如何从零搭建 Agent 可观测性体系
二、为什么 Agent 需要专门的可观测性?
2.1 Agent 的"多跳推理"让故障定位变得困难
这是传统 LLM 应用的调用链:
用户请求 → [RAG 检索] → LLM 调用 → 返回结果这是 Agent 的调用链:
用户请求
├→ LLM 思考(规划子任务)
├→ 工具调用 1:搜索知识库
│ └→ 结果校验 → 不理想,换关键词重新搜索
├→ 工具调用 2:查询数据库
├→ LLM 综合信息,生成回答
└→ LLM 自检 → 发现遗漏 → 补充工具调用 3 → 最终回答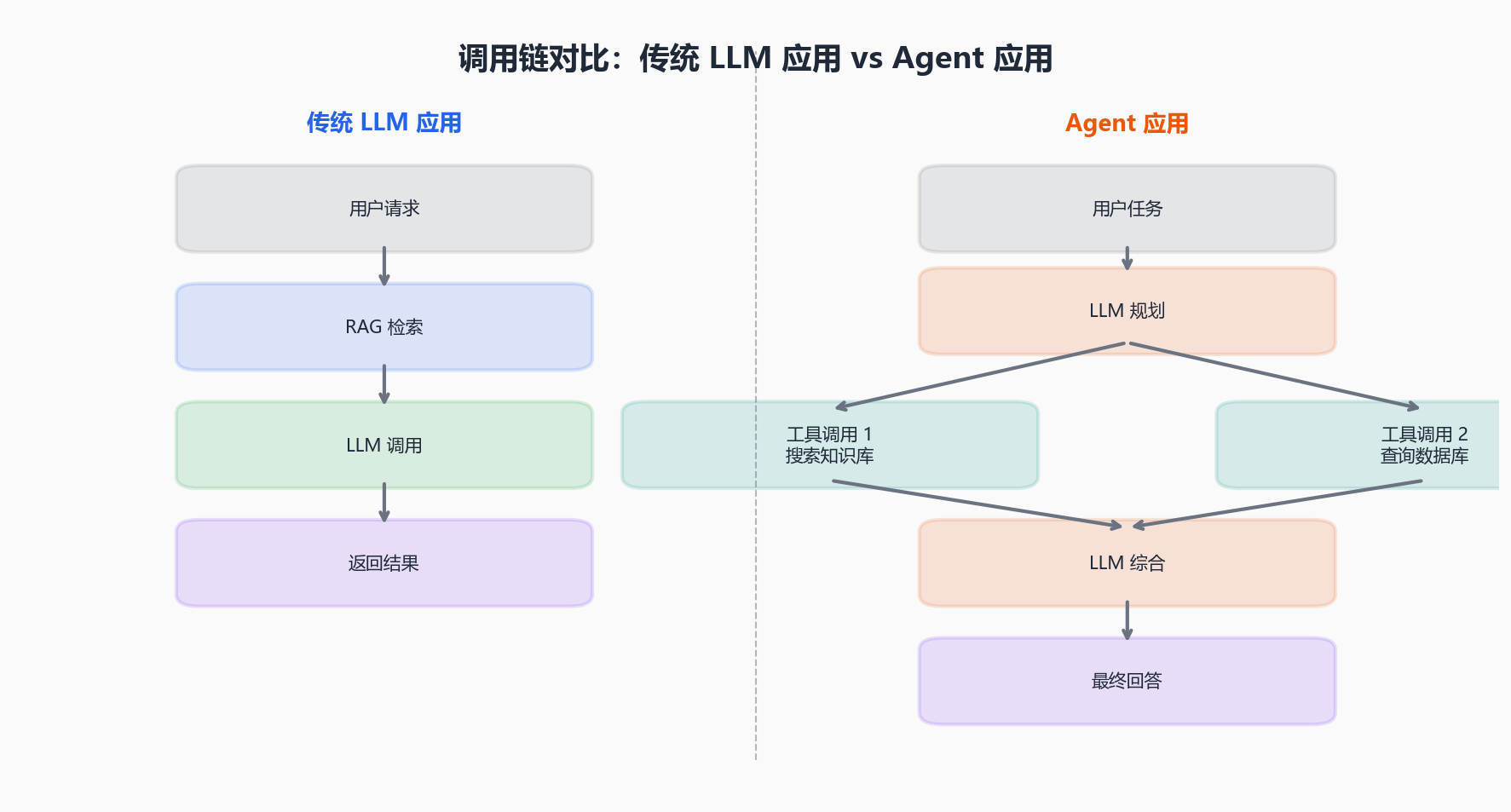
一个请求可能产生 10-20 个子步骤,任何一个环节出错都会传递到最终结果。你需要的不是"某次 LLM 调用的日志",而是整棵执行树的完整回放。
2.2 新出现的可观测维度
Agent 带来了一些传统后端监控完全不覆盖的维度:
| 新维度 | 说明 | 为什么重要 |
|---|---|---|
| 决策 Trace | Agent 每一步的"思考 → 行动 → 观察"循环 | 理解 Agent 为什么做了某个选择 |
| 工具调用链 | 调了哪个工具、参数是什么、返回值是什么 | 定位工具集成问题 |
| 重试与循环 | Agent 自我纠错的次数和原因 | 发现 Prompt 设计缺陷 |
| 任务成功率 | 多步任务的整体完成率(非单次调用成功率) | Agent 评估的核心指标 |
| Token 放大效应 | 一个用户请求实际触发了多少 LLM 调用和 Token | 成本控制 |
三、AgentOps 的核心能力拆解
3.1 Trace & Span:不只是"调用链",而是"决策树"
分布式追踪(Distributed Tracing)的概念在微服务领域已经成熟,但 Agent 的 Trace 需要承载更多信息:
传统 Span :service=user-service, operation=GET /users, duration=23ms
Agent Span:
span:
type: "llm.think"
input: "用户想订一张从北京到上海的机票..."
output: "我需要先查航班信息,再确认用户偏好..."
model: "claude-sonnet-4-6"
token_usage: {prompt: 342, completion: 156}
duration_ms: 2340
metadata:
step_in_plan: "gather_info"
parent_span: "task_book_flight"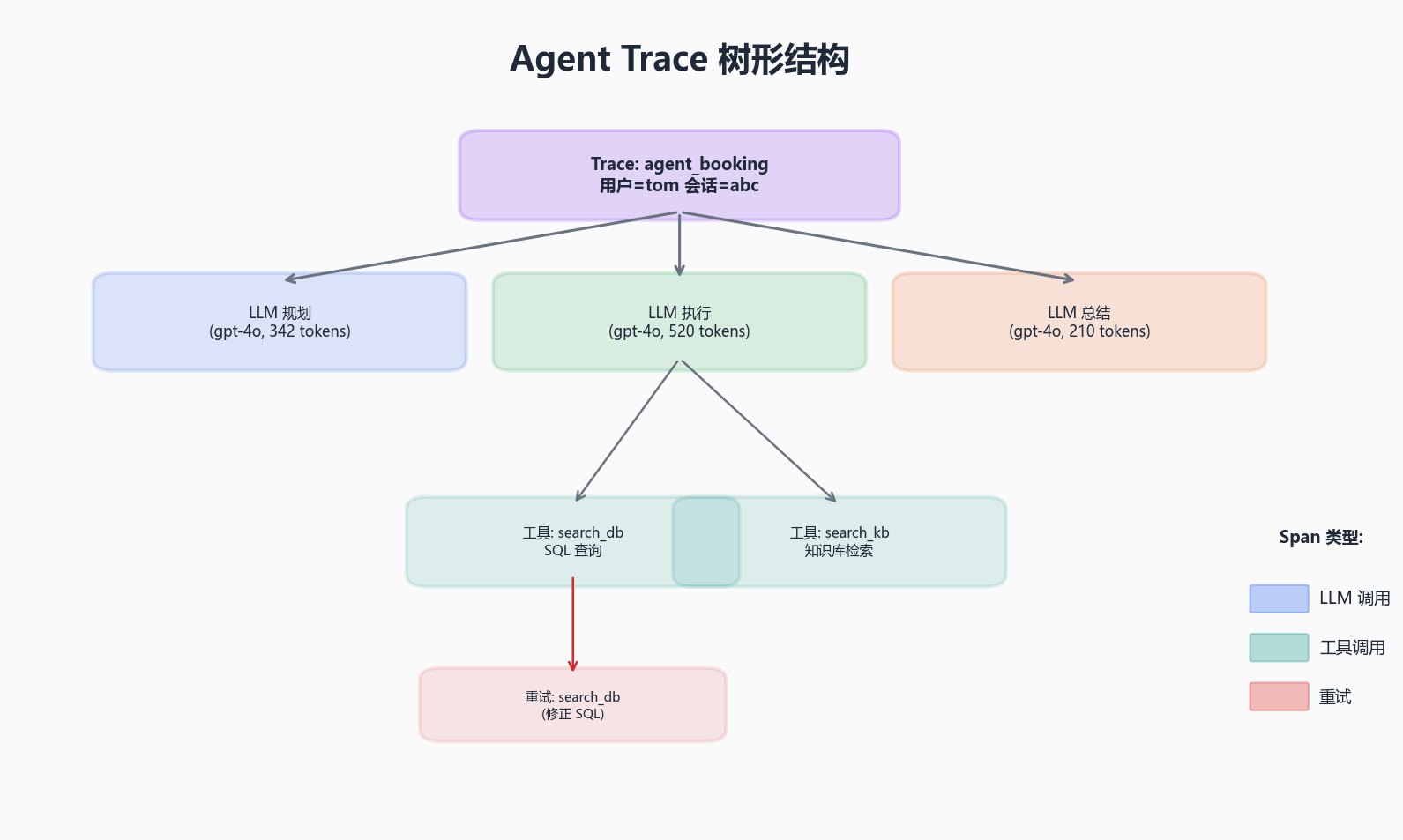
关键设计原则:
- 每个 LLM 调用和工具调用都是独立 Span
- Span 之间构成树状结构,根 Span 代表用户请求
- 需要记录 IO 内容(至少摘要),方便事后回放分析
3.2 决策回放:排查问题的终极武器
Agent 最让人头疼的场景是:同样的输入,有时对有时错。为什么?因为温度参数、检索结果、API 返回值的微小差异都会让 Agent "走上不同的路"。
决策回放(Decision Replay)能力让你能:
- 以时间线形式回看 Agent 的每一步
- 看到每一步的输入、输出、耗时、模型参数
- 对比"成功路径"和"失败路径"的分叉点
python
# 伪代码:用 LangFuse 获取一次 Trace 并分析
from langfuse import Langfuse
langfuse = Langfuse()
# 获取某次用户投诉的 Trace
trace = langfuse.get_trace(trace_id="trace_abc123")
print(f"任务: {trace.name}")
print(f"总步数: {len(trace.observations)}")
print(f"总 Token: {trace.usage.total}")
print(f"总耗时: {trace.duration}ms")
for obs in trace.observations:
print(f" [{obs.type}] {obs.name} | "
f"耗时={obs.duration_ms}ms | "
f"Token={obs.usage.total if obs.usage else 0}")3.3 工具调用可观测性:Agent 的"手"不能是黑盒
Agent 通过工具(Tool/Function Call)与外部世界交互。工具的可靠性直接影响 Agent 的可靠性。
每个工具调用需要记录:
json
{
"tool_name": "search_knowledge_base",
"input": {"query": "Python GIL 是什么", "top_k": 5},
"output": {
"documents": [...],
"count": 3,
"elapsed_ms": 234
},
"status": "success",
"error": null
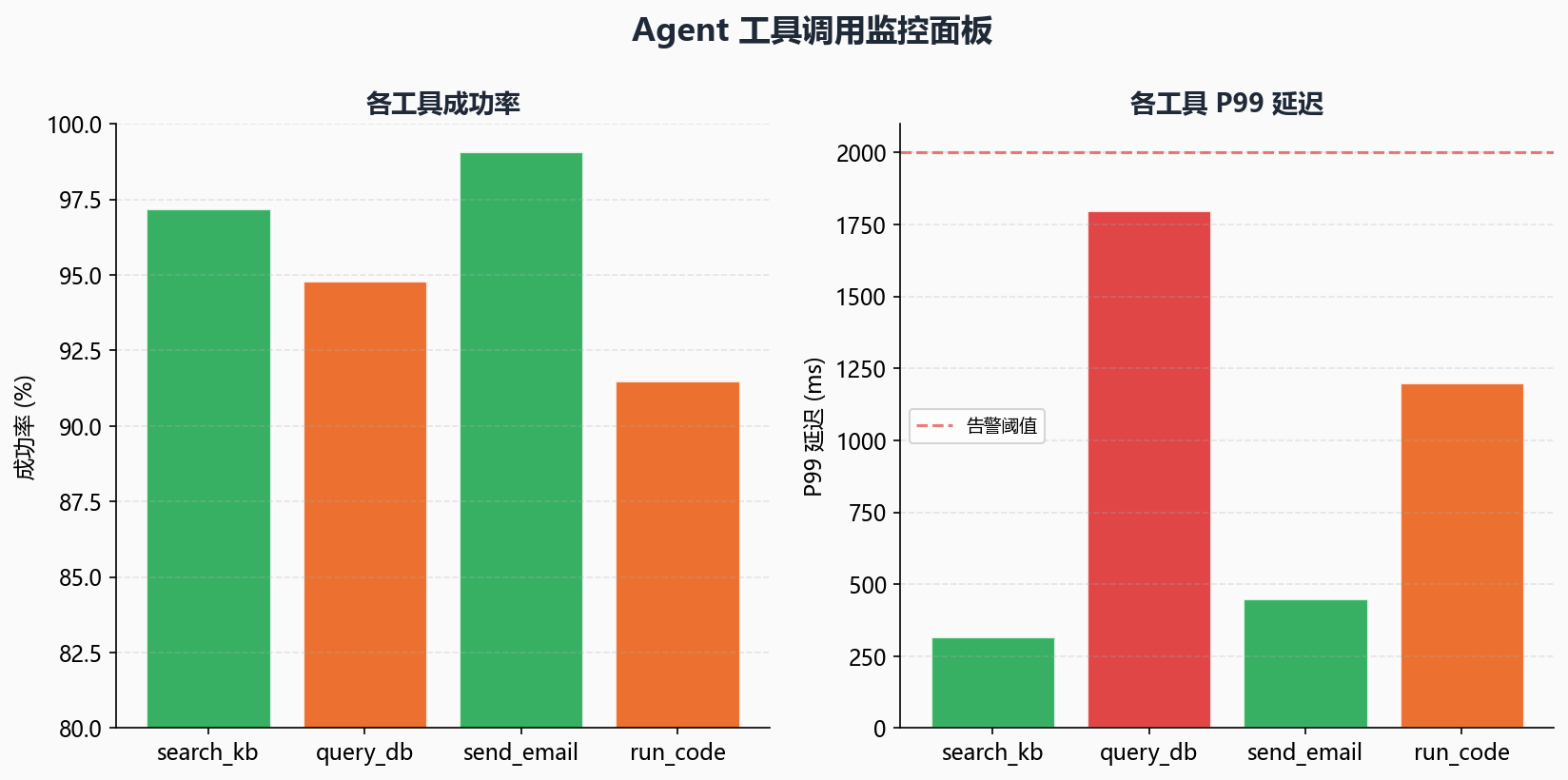
}工具层面的关键指标:
| 指标 | 计算方式 | 告警阈值建议 |
|---|---|---|
| 工具调用成功率 | success / total | < 95% |
| 工具调用 P99 延迟 | 排序取 P99 | > 2000ms |
| 空结果率(搜索类工具) | empty_result / total | > 30% |
| 工具调用次数分布 | 按工具名分组统计 | 异常尖峰 |
3.4 成本归因:Agent 是"烧钱机器"还是"物有所值"?
单个 LLM 调用的成本大概在 0.001-0.01,看起来不贵。但一个 Agent 任务可能调用 10+ 次 LLM,每次的上下文又越来越长(RAG 检索结果被拼入后续 Prompt),导致成本非线性增长。
成本归因需要回答:
- 哪个用户/租户花的 Token 最多?
- 哪种类型的任务平均成本最高?
- Agent 的多轮循环中,哪一轮最"烧钱"?
python
# 成本归因示例
def calculate_session_cost(trace):
total_cost = 0
cost_breakdown = {}
for obs in trace.observations:
if obs.type == "generation" and obs.usage:
model = obs.model
input_cost = (obs.usage.prompt_tokens / 1_000_000) * PRICING[model].input
output_cost = (obs.usage.completion_tokens / 1_000_000) * PRICING[model].output
cost = input_cost + output_cost
total_cost += cost
cost_breakdown[obs.name] = cost_breakdown.get(obs.name, 0) + cost
return total_cost, cost_breakdown四、主流 AgentOps 方案对比
| 方案 | 类型 | 核心优势 | 短板 | 适合场景 |
|---|---|---|---|---|
| LangFuse | 开源/商业 | 全栈(Trace + 评测 + Prompt 管理 + 成本),LangChain/OpenAI 原生集成 | 自部署需要基础设施 | 中小团队首选 |
| LangSmith | 商业 | LangChain 深度集成,Hub 社区共享 Prompt | 非 LangChain 栈集成成本高 | 重度 LangChain 用户 |
| Arize Phoenix | 开源 | 质量评估和漂移检测能力强 | Trace 功能相对弱 | 侧重质量监控的团队 |
| Weights & Biases | 商业 | 训练+评估一条龙,实验追踪成熟 | Agent 场景的支持较新 | 同时做微调和 Agent 的团队 |
| 自研方案 | 自建 | 完全定制,数据不外传 | 研发成本高,长期维护负担 | 大厂/强合规需求 |
选型建议
- 2-5 人团队、做 Agent 原型:LangFuse Cloud(免费额度够用)
- 10-50 人团队、Agent 在产品中:LangFuse 自部署 + Phoenix 做质量
- 50+ 人、多个 Agent 产品线:LangSmith(商业支持)+ 自研部分组件
- 强合规/私有化:LangFuse 自部署 + 定制开发
五、从零搭建 Agent 可观测性(最小可行版本)
第 1 步:集成 Trace SDK(30 分钟)
python
from langfuse import Langfuse
from langfuse.decorators import observe, langfuse_context
# 初始化
langfuse = Langfuse(
public_key="pk-...",
secret_key="sk-...",
)
@observe(as_type="generation")
def call_llm(messages, model="gpt-4o"):
# 你的 LLM 调用逻辑
response = openai_client.chat.completions.create(...)
# 自动记录 Token 使用
langfuse_context.update_current_observation(
usage={
"input": response.usage.prompt_tokens,
"output": response.usage.completion_tokens
},
model=model
)
return response
@observe()
def agent_loop(user_request):
# Agent 主循环
plan = call_llm(...) # 自动嵌套为子 Span
tool_result = execute_tool(...)
final_answer = call_llm(...)
return final_answer
第 2 步:建立质量评估(1 小时)
python
from langfuse import Langfuse
langfuse = Langfuse()
# 在 Trace 上打分
trace = langfuse.trace(
name="agent_booking",
user_id="user_123"
)
# 对最终回答评分
trace.score(
name="user_satisfaction",
value=4, # 1-5 分
comment="订票成功但耗时较长"
)
trace.score(
name="task_success",
value=1, # 0 或 1
comment="正确完成了机票预订"
)第 3 步:配置告警(30 分钟)
LangFuse 支持 Webhook 和 Prometheus 集成,至少配置这几个告警:
- 任务成功率 < 80%:Agent 可能出问题
- P95 延迟 > 30s:某些任务卡住了
- 单次任务 Token > 50K:可能出现了无限循环
- 工具调用错误率 > 5%:外部依赖有问题
六、实战案例:一次 Agent 线上故障的排查回放
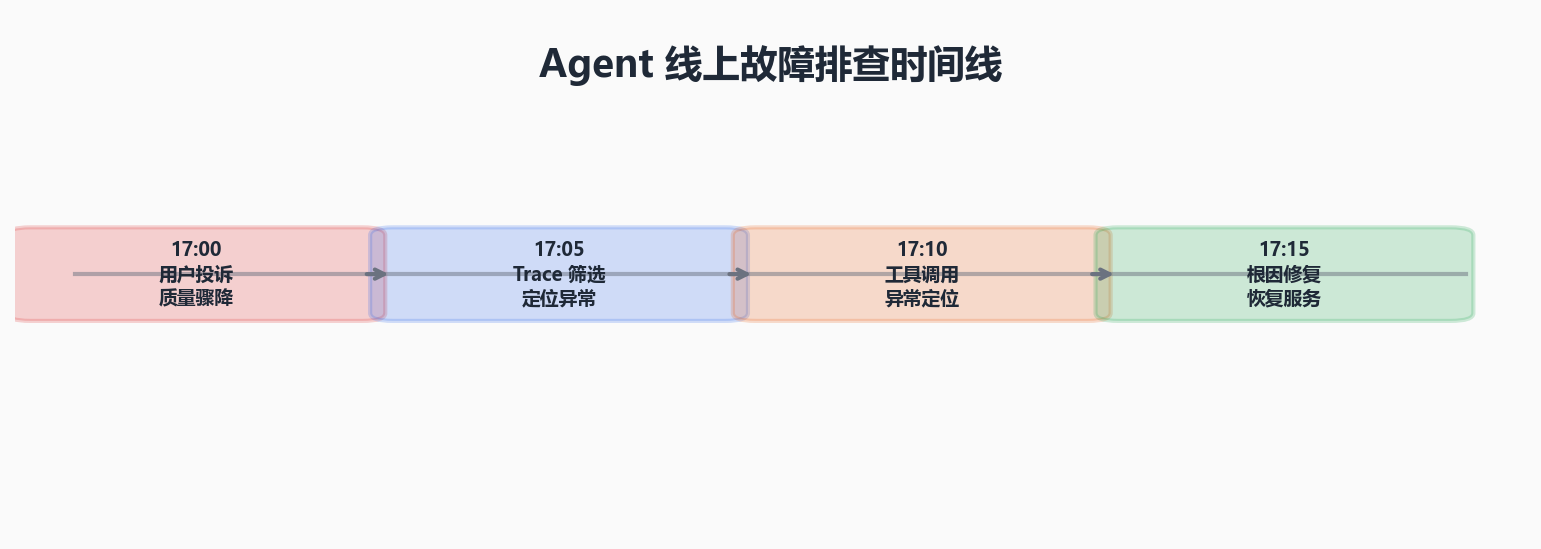
某团队的知识库问答 Agent 在周四突然出现质量骤降。通过 LangFuse Trace 排查过程:
- 定位问题 Trace:筛选用户点踩的会话,找到 5 个代表性 Trace
- 回放对比:将这些 Trace 与前一天的成功 Trace 对比
- 找到分叉点:发现"搜索知识库"工具返回的空结果率从 3% 飙升到 35%
- 根因:周三晚上知识库的向量索引重建任务失败,导致大量文档检索不到
- 修复:重建索引,30 分钟后恢复正常
没有 Agent 可观测性,这个过程可能需要一整个下午------而你有了 Trace,只用了 15 分钟。
七、总结
- Agent 的可观测性不是可选项:多跳推理 + 工具调用 + 自我纠错 = 必须要有 Trace 和回放
- AgentOps 是 LLMOps 的超集:多出了决策回放、工具调用链、任务成功率等关键维度
- 最小起步选 LangFuse:开源、全栈、集成简单,30 分钟就能看到第一棵 Trace 树
- 成本归因要趁早:Agent 的 Token 放大效应会让成本 "安静地" 增长,等你发现已经晚了
- 评估和可观测是一体的:没有自动评估的可观测只是一堆漂亮图表------在生产中,它们必须一起工作
AgentOps 还处在非常早期的阶段。LangFuse、LangSmith、Arize 每个月都在发布 Agent 相关的新功能。建议持续关注这些项目的 Changelog,Agent 的可观测性标准还在被定义中。