走到这里,"光流"这条几何提取路线已经被推进了两步:AVDC(第 13 篇)证明了"动作能从光流几何地算出来",Im2Flow2Act(第 14 篇)把光流搬进潜在空间直接生成、还把它立成了"跨域通用接口"。但这两者都卡在同一个天花板上------它们用的都是二维光流。
二维光流只能描述物体在画面平面里"上下左右"怎么挪,却天生看不见两样东西:深度方向的位移(物体离你远了还是近了) ,和旋转(物体转了多少角度)。Im2Flow2Act 的倒水任务老是失败,根子就在这------倒水靠的是茶壶绕轴的旋转和壶嘴的高度对准,恰恰都是二维光流的盲区。
3DFlowAction("3D Flow → Action",从三维光流到动作;arXiv 2025)的破局思路直截了当:既然二维不够,那就升到三维。 它训了一个"3D 流世界模型",让视频扩散直接生成稠密的三维光流场,把旋转和深度位移这些平面流摸不到的运动分量,全都捕捉进来。
一、要解决什么问题:动作空间各不相同,二维光流又丢了关键信息
3DFlowAction 想同时解开两个结。
第一个结:跨本体的"动作空间"互不相通。 现有机器人数据集,每一个都把动作记录在各自的动作空间里------这台机械臂用关节角、那台用末端位姿、夹爪开合的定义也各异。结果是:一个数据集训出来的策略,几乎没法直接喂给另一台机器人。数据散落各处,却拼不到一块儿。
那有没有一种"动作表征",是和具体机器人无关、人和各种机器人都通用的?论文给出的洞察是:
"理解物体在三维空间中应该如何移动,是指导动作的关键线索;而这条线索对具身无关,人和不同机器人都适用。"
换句话说------别再纠结"机器人的关节该怎么转"了,先想清楚"物体该怎么动"。 物体的三维运动,就是那个跨本体的通用语。这个思路和 Im2Flow2Act 一脉相承,只是把"物体怎么动"从二维升级到了三维。
第二个结:二维光流信息不足。 前面已经讲过,平面光流捕捉不到旋转和深度位移。这里举个具体例子体会一下:想象一个茶壶正对着相机慢慢倾倒。在二维画面里,壶身的轮廓几乎没怎么"平移",光流看上去微乎其微------可实际上茶壶正绕着一根轴大幅旋转、壶嘴也在朝相机方向(深度方向)逼近。这两样最关键的运动,二维光流统统"看不见",因为它只记录画面平面上的左右上下位移。再比如把一支笔笔尖朝下插进笔筒,笔主要是沿深度方向往下走、还伴随手腕的旋转------同样落在二维光流的盲区里。
而真实操作里,"绕轴旋转""沿深度方向推拉"恰恰是大量任务(倒水、插笔、挂杯子)的核心。要让"物体怎么动"这条线索真正管用,它必须是三维的。
两个结合在一起,3DFlowAction 的目标就清楚了:用三维物体光流作为跨本体的通用动作接口,并造一个能生成它的世界模型。
二、核心思想与直觉:先学会"想象物体的三维运动",再据此约束出动作
一句话概括 3DFlowAction:
训一个"3D 流世界模型 "------给定初始 RGB-D 画面和语言指令,用视频扩散生成物体表面点的三维运动轨迹(带深度、带旋转);再把这段三维流当作"约束",用一个优化器反解出机器人该执行的一连串动作。整个表征对具身无关,所以无需针对硬件重新训练。
它属于级联式 WAM 里"基于像素空间、几何式动作提取 "这一支,是 AVDC、Im2Flow2Act 的直系后继,核心升级就两个字:升维。
它和前两者最关键的区别:
- 相对 AVDC :AVDC 是"生成 RGB 视频→现成工具算二维光流→解 SE(3)";3DFlowAction 直接生成三维光流,且做了闭环规划与验证。
- 相对 Im2Flow2Act:Im2Flow2Act 生成的是二维物体光流,丢了深度和旋转;3DFlowAction 生成的流多了一个深度通道,旋转和远近位移都拿得到------这正是为了治 Im2Flow2Act 倒水失败那种病。
三、方法详解:3D 流世界模型 + 闭环验证 + 优化反解动作
整套系统可拆成"造数据 → 训世界模型 → 验证规划 → 反解动作"四块。
3.1 三维光流长什么样
先看表征。一段三维光流被记作 ℱ ∈ ℝ^(T×H×W×4),即在 T 个时刻、H×W 的网格上,每个点用四个通道描述:
- 前两个通道:该点在图像里的二维 (x, y) 坐标;
- 第三个通道:深度(这是相比二维光流新增的关键维度);
- 第四个通道:可见性(这个点此刻是否被遮挡)。
多出来的"深度通道",就是它能捕捉远近位移、并配合二维坐标还原旋转的物理基础。
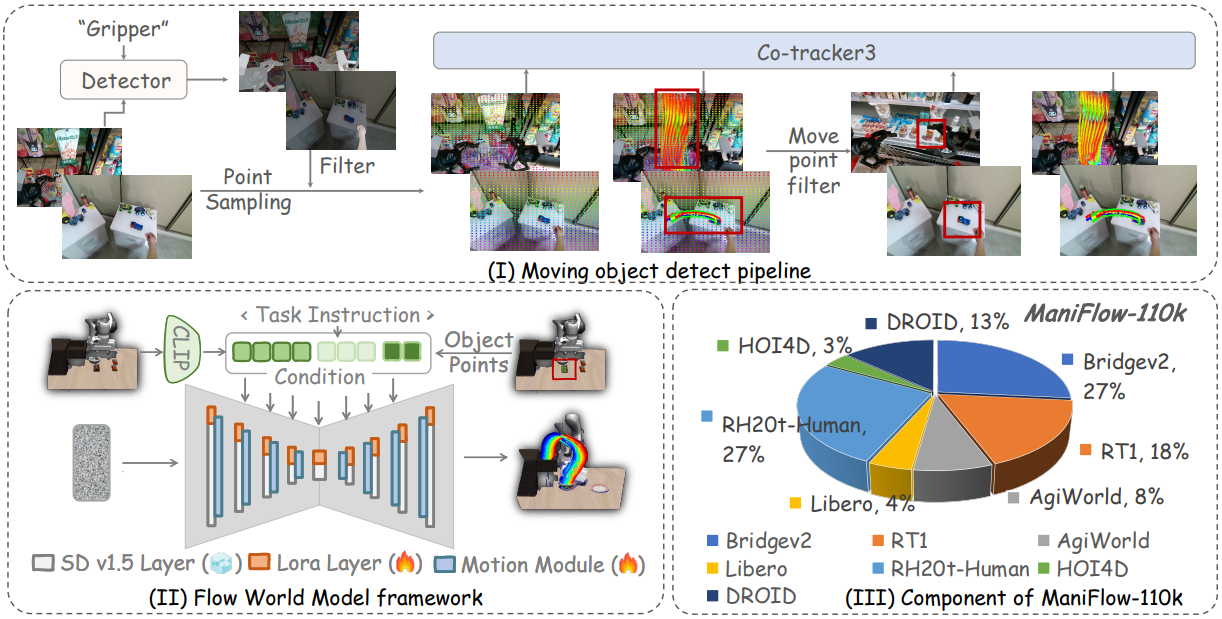
3.2 ManiFlow-110k:用"自动检测运动物体"的流水线造数据
要训世界模型,先得有大量"三维光流"样本。可现成数据集里没有这种标注,于是论文造了一个自动化流水线 ,把普通机器人视频"升维"成三维光流,得到了 ManiFlow-110k(11 万条三维光流数据)。流水线四步走:
- Grounding-SAM2 从首帧分割出夹爪的掩码(目的是把"夹爪/具身"的运动从物体运动里剔除,只留物体光流------这个"只追物体不追具身"的原则,和 Im2Flow2Act 一致);
- Co-tracker3 在视频里追踪点,找出那些发生了显著移动的点(即被操作的物体上的点);
- DepthAnythingV2 预测每一帧的深度;
- 用深度把二维光流投影成三维。
数据来源是 BridgeV2、DROID、RH20T 等多个开源数据集。论文报告,在 BridgeV2 验证集上,"运动物体自动检测"的准确率超过 80%。这套流水线的意义在于:它让我们不需要任何额外人工标注,就能把海量现成机器人视频转化成三维光流训练数据。
3.3 3D 流世界模型------视频扩散生成三维运动
先说它在干嘛。 给定初始的 RGB-D 观测和一句任务指令,它要"想象"出物体接下来该怎么在三维空间里运动,生成出那段三维光流。
再说怎么实现。 底座依旧是 AnimateDiff(给 Stable Diffusion 注入时间运动模块的视频扩散模型)。但这里有个很重要的技术抉择:
- 不走 VAE 压缩。Im2Flow2Act 是把流压进 Stable Diffusion 的潜在空间再扩散的;但 3DFlowAction 发现,"Stable Diffusion 的图像 VAE 没法有效编码深度信息"------硬压会把宝贵的深度细节糊掉。所以它放弃了对流的 VAE 压缩,以保住深度的精度。
- 训练方式:在 Stable Diffusion 主干上插 LoRA 层(轻量微调),时间运动模块则从零训练。
- 条件注入:初始 RGB 观测经 CLIP 编码 + 任务指令 + 初始点的正弦位置编码,一起作为生成条件。
训完之后,这个世界模型就内化了"操作的物理规律"------它知道倒水时茶壶该怎么转、开抽屉时把手该怎么沿深度方向移动。
3.4 流引导渲染 + GPT-4o 验证------给规划上一道"质检"
光生成了流还不够,怎么知道这段"想象"靠不靠谱?3DFlowAction 加了一道闭环验证:
- 估计变换:用 SVD(奇异值分解,一种从一组点对解出最优刚体变换的经典方法)从"首帧的流点 P₁"和"末帧的流点 P₂"之间解出变换矩阵 T;
- 流引导渲染:把物体点云用 T 变换、再重投影回二维,渲染出"预测的最终状态"长什么样;
- GPT-4o 质检:把任务描述 + 这张渲染出的预测图一起喂给 GPT-4o,让它判断"预测的流是否真的符合任务要求"。
这道验证让系统具备了闭环规划能力------能应对干扰、确保规划过程的可靠性。如果 GPT-4o 觉得想象得不对,就可以重新规划。
3.5 把三维流变成动作------流约束的优化
最后一步,把三维流翻译成机器人动作。这里 3DFlowAction 用的不是学出来的策略(像 Im2Flow2Act),也不是闭式几何(像 AVDC),而是优化:
- 约束怎么定 :用最远点采样(farthest-point sampling)从流里挑出 N 个关键点,目标是找到一组末端执行器位姿,使得"机器人带着物体走"之后,物体关键点的实际位置和"预测流里该到的位置"之间的欧氏距离最小。即把预测的三维流当作硬约束。
- 怎么解:用 SciPy 的 Dual Annealing(双重退火,全局搜索)+ SLSQP(序列二次规划,局部精修)求解 SE(3) 末端位姿,配合逆运动学和碰撞检测。每次迭代约 1 秒。
注意这套优化器输出的是一连串(a chunk)机器人动作。因为约束是"物体的三维运动"(与本体无关),优化时再叠加具体机器人的逆运动学和碰撞约束,所以同一套流可以驱动不同的机器人------这就是它"无需硬件特定训练"的实现机理。
3.6 组件一览
| 组件 | 角色 | 关键技术 |
|---|---|---|
| ManiFlow-110k 流水线 | 自动造三维光流数据 | Grounding-SAM2 + Co-tracker3 + DepthAnythingV2 |
| 3D 流世界模型 | 想象物体三维运动 | AnimateDiff(不走 VAE,保深度)+ LoRA |
| 流引导渲染 + GPT-4o | 验证规划、闭环 | SVD 解变换 + 重投影 + VLM 质检 |
| 流约束优化器 | 三维流 → 机器人动作 | Dual Annealing + SLSQP + IK + 碰撞检测 |
核心公式与逻辑梳理
把 3DFlowAction 的"造数据 → 训世界模型 → 验证 → 反解动作"四块串成形式化链条:
- 表征:把"物体运动"刻画成稠密的三维光流张量,多出一个深度通道。
- 想象:3D 流世界模型从 RGB-D 观测 + 指令出发,生成整段三维光流。
- 质检:SVD 解出首末两帧间的刚体变换,重投影渲染一张"预测终态图"喂 GPT-4o 判定靠不靠谱。
- 反解:把三维流当硬约束,用 Dual Annealing + SLSQP 求一连串末端位姿(叠加 IK 与碰撞检测)。
- 跨本体:约束在物体侧、求解在机器人侧,换台机器只换 IK,世界模型原封不动。
下面拎出四条关键式子。
(1) 三维光流的张量定义
F∈RT×H×W×4\mathcal{F} \in \mathbb{R}^{T \times H \times W \times 4}F∈RT×H×W×4
符号说明 :TTT 是时间帧数;H×WH \times WH×W 是物体表面的关键点网格;每个点用 4 个通道描述------第 1、2 通道是该点在图像里的 (x,y)(x, y)(x,y) 坐标,第 3 通道是深度 ddd(相对相机的距离),第 4 通道是可见性。
这条式子在做什么 :它就是 Im2Flow2Act"3 通道 (u, v, vis)"基础上加了一个"深度"。看上去只是多加一维,物理含义却完全不同------有了 ddd,"绕轴旋转""沿深度方向推拉"这些纯平面光流看不见的运动分量都被显式编码进表征里。也因为深度信息不能容忍 VAE 那种"为节省算力而模糊掉细节"的压缩,论文专门指出:这里不走 VAE,直接在高维表征上做扩散------升维换来精度,代价是更大的训练/推理开销。
(2) 3D 流世界模型的扩散训练目标(标准噪声预测)
Ldiff=EF,ε,t ∥ε−εθ(Ft, t∣I0,D0,txt)∥2\mathcal{L}{\text{diff}} = \mathbb{E}{\mathcal{F}, \varepsilon, t}\!\left\\left\\\| \\varepsilon - \\varepsilon_\\theta(\\mathcal{F}_t,\\ t \\mid I_0, D_0, \\text{txt}) \\right\\\|\^2\\rightLdiff=EF,ε,t∥ε−εθ(Ft, t∣I0,D0,txt)∥2
符号说明 :Ft\mathcal{F}tFt 是干净三维流 F\mathcal{F}F 加噪到第 ttt 步的中间态;ε∼N(0,I)\varepsilon \sim \mathcal{N}(0, I)ε∼N(0,I) 是采样的高斯噪声;εθ\varepsilon\thetaεθ 是基于 AnimateDiff 主干的去噪网络(Stable Diffusion 主干插 LoRA + 从零训练的时间运动模块);条件由首帧 RGB I0I_0I0 与深度 D0D_0D0 经 CLIP 编码、再加上指令 txt\text{txt}txt 与初始点的正弦位置编码一起注入。
这条式子在做什么 :和 AVDC、Im2Flow2Act 是同一类扩散去噪目标,区别只在生成对象------这里学的不是 RGB 视频、也不是二维流图像,而是带深度的三维流张量 。在 ManiFlow-110k(11 万条自动构造的三维流)上跑完,世界模型就内化了"倒水时壶嘴该往哪转""开抽屉时该沿深度方向匀速"这种物理常识。消融实验里去掉 ManiFlow-110k 预训练直接掉 40%,可见这条 Ldiff\mathcal{L}_{\text{diff}}Ldiff 的训练规模就是物理先验的来源。
(3) SVD 解物体首末两帧间的刚体变换
T=SVD(P2, P1)T = \text{SVD}(P_2,\ P_1)T=SVD(P2, P1)
符号说明 :P1∈RN×3P_1 \in \mathbb{R}^{N \times 3}P1∈RN×3 是世界模型生成的"首帧物体三维点集",P2∈RN×3P_2 \in \mathbb{R}^{N \times 3}P2∈RN×3 是同一组点在末帧的位置;T∈SE(3)T \in SE(3)T∈SE(3) 是把 P1P_1P1 旋转 + 平移到 P2P_2P2 最贴合的刚体变换;SVD\text{SVD}SVD 是 Kabsch--Umeyama 求解器(去中心化后对点积协方差做奇异值分解、再拼出旋转矩阵)的简记。
这条式子在做什么 :它从生成的三维流里抽出"物体最终到了哪儿"这条干净的高层信息。这一变换不是为了直接做动作,而是为了给规划上一道闭环质检 ------把 TTT 作用到物体三维模型上、重投影成一张图,再问 GPT-4o:"这个终态符合 '把杯子挂到挂架上' 这句指令吗?"如果 VLM 摇头,就触发重规划。这道闭环让纯生成式规划具备了"自纠错"的能力。
(4) 三维流约束的动作优化(核心目标)
f(t)(kinitial)=mina∈SE(3)∑i=1N∥kinitiali−kpredi(t)∥22f^{(t)}(\mathbf{k}{\text{initial}}) = \min{a \in SE(3)} \sum_{i=1}^{N} \big\| \mathbf{k}{\text{initial}}^{i} - \mathbf{k}{\text{pred}}^{i}(t) \big\|_2^2f(t)(kinitial)=a∈SE(3)mini=1∑N kinitiali−kpredi(t) 22
符号说明 :kinitiali\mathbf{k}{\text{initial}}^{i}kinitiali 是用最远点采样从物体上挑出的第 iii 个关键点的初始三维位置(共 NNN 个);kpredi(t)\mathbf{k}{\text{pred}}^{i}(t)kpredi(t) 是世界模型预测出的、该点在第 ttt 帧本该到达的位置;a∈SE(3)a \in SE(3)a∈SE(3) 是要求解的末端执行器位姿(实际上还要满足逆运动学可达 + 碰撞约束,论文用 Dual Annealing 做全局搜索 + SLSQP 做局部精修,每次迭代约 1 秒)。
这条式子在做什么 :它把上游的三维流当作硬约束 ------优化器只问一个问题:"我把末端摆到什么位姿,机器人带着物体走之后,物体上这 NNN 个关键点能尽可能贴近世界模型告诉我的目标位置?"这种"约束在物体侧、求解在机器人侧"的拆解,正是它"跨本体不需要重训"的形式化体现:物体的目标位置 kpred\mathbf{k}_{\text{pred}}kpred 与机器人形态无关,换台机器只需换一遍 aaa 所属的 IK 与碰撞模型,世界模型完全不动。
和 Im2Flow2Act 的"学一个光流条件策略"比,这里走的是"硬约束 + 数值优化"的路子;和 AVDC 的"一次性 SE(3) 闭式解"比,这里允许更复杂的多目标约束(IK、碰撞、可达性都能并进来)。三者一字排开,恰好对应几何式动作提取的三种典型口味------闭式几何、学习策略、约束优化。
四、实验怎么做·结果说明了什么
3DFlowAction 在四个真机任务上验证,平台是 Dobot XTrainer(配 Femto Bolt 深度相机)和 Franka Emika。四个任务都精心选过,专门考察二维流的盲区:
- 倒茶:茶壶要保持水平、壶嘴对准杯口(考旋转 + 对位);
- 插笔:笔要竖直、伴随复杂旋转(考旋转);
- 挂杯子:把手对准挂架(考精确三维对位);
- 开抽屉:避免拽歪、防止卡住(考深度方向直线运动)。
4.1 对比视频生成/几何提取类方法(每任务 10 次)
| 方法 | 倒茶 | 插笔 | 挂杯 | 开抽屉 | 总成功率 |
|---|---|---|---|---|---|
| AVDC | 1/10 | 2/10 | 0/10 | 5/10 | 20.0% |
| ReKep | 2/10 | 1/10 | 3/10 | 2/10 | 20.0% |
| Im2Flow2Act | 2/10 | 2/10 | 0/10 | 6/10 | 25.0% |
| 3DFlowAction | 6/10 | 7/10 | 5/10 | 10/10 | 70.0% |
这张表是全文最有说服力的证据。注意挂杯 和插笔 这两个最吃旋转/三维对位的任务:AVDC 和 Im2Flow2Act 在挂杯上双双挂零 (0/10),而 3DFlowAction 做到 5/10、7/10。这直接印证了核心论点------升到三维,才补得上旋转和深度这两块致命盲区。 整体上 70% 对 20--25%,是数量级的差距。
4.2 对比模仿学习方法
| 方法 | 倒茶 | 插笔 | 挂杯 | 开抽屉 | 总成功率 |
|---|---|---|---|---|---|
| PI0(π₀,强模仿学习基线) | 5/10 | 5/10 | 4/10 | 6/10 | 50.0% |
| Im2Flow2Act | 4/10 | 2/10 | 0/10 | 5/10 | 27.5% |
| 3DFlowAction | 6/10 | 7/10 | 5/10 | 10/10 | 70.0% |
即便对上 π₀ 这种强模仿学习策略(50%),3DFlowAction 仍以 70% 领先------而且它的卖点是"无需为每台硬件单独训练"。
4.3 跨本体与泛化
- 跨本体(不重新训练):在 Franka 上 67.5%、在 XTrainer 上 70.0%------同一套三维流世界模型,换台机器人几乎不掉点,坐实了"无需硬件特定训练"。
- 零样本泛化(换物体/换背景) :
- 换物体:55.0%(AVDC 仅 15.0%、π₀ 40.0%);
- 换背景:50.0%(AVDC 0%、π₀ 32.5%)。
泛化这块拉开的差距同样明显------这得益于"三维物体运动"这个表征对外观变化天然不敏感。
4.4 关键消融
- 关掉闭环规划(去掉 GPT-4o 验证那一环):平均成功率掉约 20%------说明"质检 + 重规划"对可靠性很重要。
- 关掉大规模预训练(不在 ManiFlow-110k 上预训):平均掉约 40%------说明那 11 万条三维流数据喂出来的"物理规律先验"是性能的大头。
另外,论文披露训练只需每个任务约 30 段人类演示视频(无动作标注),采集约 10 分钟------数据成本极低。
五、亮点与为什么重要
- 把光流从 2D 提升到 3D:这是它最核心的贡献,直接补上了平面光流看不见旋转和深度的致命缺陷。挂杯、插笔从"接近零"到"过半成功",就是这一升维的直接红利。
- "3D 流世界模型"这一构造:让视频扩散去生成三维运动,并通过 ManiFlow-110k 把海量现成机器人视频自动转成三维流训练数据------既给了世界模型物理先验,又没增加人工标注负担。
- 三维物体流作为跨本体通用动作接口:同一套世界模型,无需硬件特定训练就能驱动 Franka 和 XTrainer(67.5%/70%),真正做到跨本体。
- 闭环 + VLM 质检:用 GPT-4o 验证"想象的流是否符合任务",给纯生成式规划加了一道可靠性保险。
- 数据极省:每任务约 30 段无标注人类视频、10 分钟采集,却在最难的几个任务上反超强模仿学习基线。
它把"级联式 WAM → 像素空间 → 几何式动作提取 → 光流路线"这条线推到了一个新高度:当中间表征从二维升到三维,几何式动作提取的能力上限被显著抬高了。
六、局限与未解
论文坦承了主要短板:
- 形变物体是软肋:"三维光流在建模柔性物体运动时面临挑战,因为严重遮挡和复杂运动";而且物体的非刚性形变会导致下游优化器解不出有效动作------本质上,"流约束优化"假设物体近似刚体,遇到布料、绳子这类会失灵。
- 依赖深度感知质量:三维流的深度通道依赖深度相机/深度估计,深度不准会直接拖累三维流的精度。
- 优化有耗时:每次迭代约 1 秒的优化求解,相比端到端策略的实时推理仍有延迟。
- 生成质量决定上限:和所有级联式方法一样,世界模型若"想象"得不合理,下游优化得再好也是错的(虽然 GPT-4o 验证缓解了一部分)。
- 深度通道带来的训练代价:为保住深度精度而放弃 VAE 压缩,意味着世界模型要在更高维的表征上做扩散,训练与生成的开销都比 Im2Flow2Act 那种"压进潜在空间"的做法更大------这是"升维"换来的精度提升所付出的另一面成本。
七、在 WAM 谱系中的位置
3DFlowAction 是几何式级联 WAM"光流路线"的集大成者,处在这条线的最前沿:
- 承上 :它是 AVDC(第 13 篇)→ Im2Flow2Act(第 14 篇)→ 3DFlowAction 这条"光流升级链"的第三棒。
- 相对 AVDC:从"生成 RGB 视频再算二维光流、解一次 SE(3)",升级为"直接生成三维光流 + 闭环验证 + 优化反解";
- 相对 Im2Flow2Act:直接把它的二维物体光流升到三维,专门治好了它倒水、插笔栽在"深度/旋转盲区"上的病(实验里 Im2Flow2Act 正是主要对比对象)。
- 横向对照(相对 Dreamitate,第 15 篇):两者都在补"二维光流的深度短板",但路子不同------Dreamitate 靠"立体视频 + 跟踪一个刚体工具的 6DoF 位姿"拿到三维信息;3DFlowAction 靠"生成物体表面稠密点的三维流"。前者偏刚体工具、单物体;后者偏稠密、通用物体运动。
- 启下 :再往前一步就是 NovaFlow、Dream2Flow ------它们把这条路推向零训练:直接用预训练视频生成大模型,配深度估计和点追踪推导出三维物体级光流,连世界模型都不用自己训。
放在整个 WAM 大图景里,3DFlowAction 给"几何式动作提取"这一思路提供了一个有力的注脚:只要把"物体该怎么动"这条线索刻画得足够完整(升到三维),机器人就能在跨本体、强泛化、低数据成本的前提下,把"想象"可靠地变成"行动"------而这一切,依然不需要为每台机器人单独学一遍动作。
八、参考
- 论文 :Hongpeng Zhi, Piao Chen, Siyuan Zhou, Yichao Dong, Qiang Wu, Lin Han, Mingkui Tan. 3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model.
- 发表:arXiv 预印本,2025.
- arXiv:https://arxiv.org/abs/2506.06199
注:本文为基于该论文的学习性解读,所有方法、数据集与数值均来自论文公开信息,方法名称保留英文原名以便检索。