消失于无形:针对 SAM2 的跨提示通用对抗攻击

摘要
近期研究揭示了图像分割基础模型 SAM 对对抗性示例的脆弱性。其后续模型 SAM2 由于在视频分割中强大的泛化能力而备受关注。然而,其鲁棒性尚未得到探索,并且现有针对 SAM 的攻击能否直接迁移到 SAM2 上仍不清楚。在本文中,我们首先分析了现有攻击在 SAM 和 SAM2 之间的性能差距,并指出了由其架构差异引起的两个关键挑战:来自提示的方向性引导和跨连续帧的语义纠缠。为了解决这些问题,我们提出了 UAP-SAM2,这是第一个由双重语义偏差驱动的针对 SAM2 的跨提示通用对抗攻击。为了实现跨提示的可迁移性,我们首先设计了一种目标扫描策略,将每一帧划分为 k 个区域,每个区域随机分配一个提示,以减少优化过程中对提示的依赖。为了提升有效性,我们设计了一个双重语义偏差框架,通过扭曲当前帧内的语义并破坏连续帧之间的语义一致性来优化 UAP。在六个数据集、两个分割任务上的大量实验证明了所提方法对 SAM2 的有效性。对比结果表明,UAP-SAM2 以显著优势超越了最先进的攻击方法。我们的代码可在以下网址获得:https://github.com/CGCL-codes/UAP-SAM2。
1 引言
深度学习的最新进展催生了具有强大泛化能力的大型分割基础模型 4, 16, 33, 40, 43,能够从未见过的图像中分割物体。其中,分割一切模型(SAM)4 可以通过利用提示(例如点或框)来精确定位目标物体,输出无类别掩码。尽管其分割能力强大,但 SAM 仅限于图像。因此,最近提出了 SAM2 28,它集成了一种记忆机制来存储先前帧的特征,将 SAM 扩展到通用视频分割。给定一个提示(通常在第一帧上),SAM2 可以连续跟踪并分割后续帧中的目标物体 11, 32, 49。
深度神经网络(DNN)以易受对抗性示例攻击而闻名 34, 35, 46,微小的不可察觉的扰动会导致错误的预测。近期研究表明,此类扰动可以显著削弱 SAM 分割目标物体的能力。Attack-SAM 42 应用 PGD 23 为每张图像生成样本特定扰动。DarkSAM 48 引入了一种空间-频率通用攻击框架,制作了能泛化到不同图像的通用对抗扰动(UAP)30, 44, 45。鉴于基于 SAM 的模型对提示的敏感性,近期工作 14, 21, 48 也设计了具有跨提示可迁移性的对抗性示例。然而,尽管这些方法对 SAM 有效,SAM2 针对这些攻击的鲁棒性仍未得到探索。
受现有视频攻击 36, 37 的启发,我们研究了为 SAM 设计的现有攻击是否可以直接迁移到 SAM2。我们在 YouTube 41 和 MOSE 6 数据集上评估了包括 PGD 23、Attack-SAM 42(A-SAM)、S-RA 29、UAD 22 和 DarkSAM 48 在内的几种代表性方法,设置 ϵ=10/255\epsilon = 10 / 255ϵ=10/255。如图 1 所示,现有攻击能有效欺骗 SAM,但无法欺骗 SAM2。例如,DarkSAM 在两个数据集上将 SAM 的平均分割性能相对于其原始性能降低了 98.25%98.25\%98.25%,而仅导致 SAM2 下降 22.26%22.26\%22.26%。这些结果突显了将攻击从 SAM 直接迁移到 SAM2 的困难。
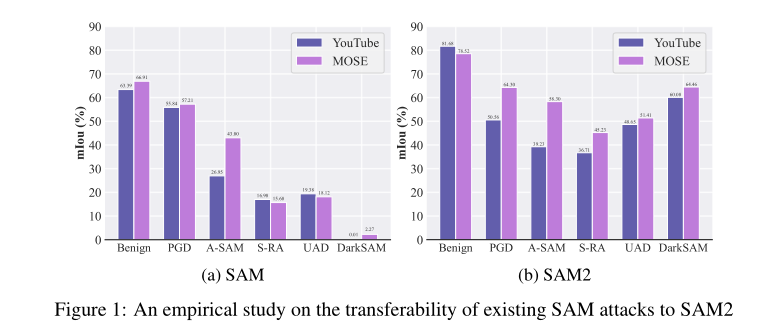
鉴于 SAM 和 SAM2 之间共享的设计理念,我们在第 3.1 节进行了全面分析,以揭示其性能差距的根本原因。为了实现跨帧的一致且准确的分割,SAM2 将用户提供的提示存储为持久的、视频特定的表示。它还维护一个记忆库,缓存来自先前某些帧的语义特征。在推理过程中,SAM2 联合利用提示和记忆库来指导每一帧的分割,并在整个序列中重复此过程。我们在第 3.1 节中的发现突显了现有攻击失败的两个关键因素:(1)来自提示的方向性引导,以及(2)跨连续帧的语义纠缠。为了有效攻击 SAM2,我们建立了两个关键目标。首先,扰动必须能够泛化到不同的提示,以保持攻击有效性。其次,由于视频包含大量帧,我们的目标是制作一个 UAP,而不是适用于不同视频中任何帧的样本特定扰动。
在本文中,我们提出了 UAP-SAM2,这是第一个由双重语义偏差驱动的针对 SAM2 的跨提示通用对抗攻击。它生成了一个能够跨视频、帧和提示泛化的 UAP,有效阻止 SAM2 分割目标物体,使其"消失于无形"。针对第一个目标,我们首先设计了一种目标扫描策略,将每一帧划分为 mmm 个区域,每个区域随机分配一个提示,以减少优化过程中对提示的依赖。此外,我们没有直接攻击依赖提示的掩码,而是破坏了图像编码器产生的语义特征,以提高跨提示的可迁移性。针对第二个目标,我们设计了一个双重语义偏差框架,通过扭曲当前帧内的语义并破坏连续帧之间的语义一致性来优化 UAP。具体来说,我们设计了一种语义混淆攻击,通过向语义空间注入噪声来阻碍 SAM2 对目标物体的理解;一种特征偏移攻击,以最大化对抗帧与良性帧之间的语义距离;以及一种记忆错位攻击,通过破坏时间对齐来放大帧间语义不一致性。
我们对 UAP-SAM2 及其样本特定变体 UAP-SAM2* 在涵盖视频和图像分割任务的六个数据集上进行了全面评估。对比实验表明,我们的方法在针对 SAM2 的攻击中显著优于 SOTA 攻击。此外,我们还验证了 UAP-SAM2 在 Sam2long 7 上的可迁移性,Sam2long 是一种增强了 SAM2 长视频能力的变体。我们的方法在防御研究中也表现出鲁棒性,即使在常见的模型剪枝和数据预处理防御下也能保持有效性。
总之,我们的贡献如下:
- 我们提出了第一个针对 SAM2 的跨提示通用对抗攻击,揭示了视频分割基础模型的脆弱性。通过设计 UAP,我们的方法能持续误导 SAM2 在视频、帧和提示下的分割。
- 我们设计了一个全新的双重语义偏差框架,通过扭曲当前帧内的语义并破坏连续帧之间的语义一致性来优化 UAP。
- 我们在两个分割任务的六个数据集上进行了大量实验,证明了所提方法对 SAM2 的有效性。对比结果表明,UAP-SAM2 以显著优势超越了 SOTA 攻击。
2 预备知识
给定一个输入帧序列 X={xi}i=1N\mathcal{X} = \{x_{i}\}{i = 1}^{N}X={xi}i=1N 和提示 P={pi}i=1L\mathcal{P} = \{p{i}\}{i = 1}^{L}P={pi}i=1L,SAM2 fθ(⋅)f{\theta}(\cdot)fθ(⋅) 预测每一帧 xix_ixi 的分割掩码 V={yi}i=1N\mathcal{V} = \{y_{i}\}{i = 1}^{N}V={yi}i=1N。对于一帧 xix_ixi,坐标 (m,n)(m,n)(m,n) 处的像素记为 ximnx_i^{mn}ximn,如果其对应的掩码值 yimny_i^{mn}yimn 超过预定义的零阈值,则认为该像素属于掩码区域。SAM2 由一个图像编码器 Eimg\mathcal{E}{\mathrm{img}}Eimg 组成,它将每一帧 xix_ixi 编码为特征嵌入 Fi=Eimg(xi)F_i = \mathcal{E}{\mathrm{img}}(x_i)Fi=Eimg(xi);一个提示编码器 Eprompt\mathcal{E}{\mathrm{prompt}}Eprompt 处理输入提示 pip_ipi 并产生相应的嵌入 Qi=Eprompt(pi)Q_i = \mathcal{E}{\mathrm{prompt}}(p_i)Qi=Eprompt(pi);一个记忆库 Mi\mathcal{M}{i}Mi 存储帧 xix_ixi 之前的过去 KKK 个嵌入 EiE_iEi。一个记忆注意力模块 A\mathcal{A}A 整合 Fi,MiF_i, M_iFi,Mi 和 QiQ_iQi 以生成增强的表示。最后,一个掩码解码器 D\mathcal{D}D 接收该表示并预测分割掩码 yiy_iyi。我们可以将上述过程简化为:
V=fθ(X,P)(1) \mathcal{V} = f_{\theta}(\mathcal{X},\mathcal{P}) \tag{1} V=fθ(X,P)(1)
遵循 42, 48,我们假设攻击者能够获取开源的 SAM2,并可以从互联网收集公开可用的数据集来制作对抗性示例。攻击者的目标是制作一个针对每一帧的对抗性扰动 δ\deltaδ,使得 SAM2 无法在不同提示下准确定位目标物体,即一次跨提示通用对抗攻击。此外,δ\deltaδ 应足够小,并由预定义的扰动幅度 ϵ\epsilonϵ 的 lpl_plp 范数约束。接下来,我们正式定义这种类型的攻击。
定义 2.1 (针对 SAM2 的跨提示通用对抗攻击) 。对于一个输入帧序列 X\mathcal{X}X,我们为每一帧 xi∈Xx_i \in \mathcal{X}xi∈X 生成一个 UAP δ\deltaδ,以使其在不同提示 P\mathcal{P}P 下的预测掩码偏离其真实掩码 yiy_iyi。该问题可表述为:
minδExi∼X∀pi∈P, IoU(fθ(xi+δ,pi),yi),s.t. ∥δ∥p≤ϵ(2) \min_{\delta}\mathbb{E}{x_i\sim \mathcal{X}}\left\\forall p_i\\in \\mathcal{P},\\ IoU(f_{\\theta}(x_i + \\delta, p_i), y_i)\\right, \quad \text{s.t.} \ \left\Vert \delta \right\Vert{p}\leq \epsilon \tag{2} δminExi∼X∀pi∈P, IoU(fθ(xi+δ,pi),yi),s.t. ∥δ∥p≤ϵ(2)
在本文中,我们在视频和图像分割任务上评估 UAP-SAM2,主要关注 UAP。为了与现有工作公平比较,我们还将我们提出的方法改编为样本特定形式 UAP-SAM2*,而不修改损失函数。
3 方法论
3.1 观察与设计理念
受图 1 所示现有攻击下 SAM 与 SAM2 之间显著性能差距的启发,我们通过考察它们的架构差异来探究根本原因。然后,我们希望根据我们的发现为新兴的 SAM2 设计一种有效的 UAP。
观察 I:对第一帧的攻击无法迁移到后续帧。 第一个设计差异在于提示策略。与为每一帧提供样本级提示的 SAM 不同,SAM2 仅在第一帧提供初始提示,该提示随后被存储并复用于分割后续帧。现有的视频攻击 37 表明,图像级扰动可以迁移到视频,因此一个自然的想法是仅攻击第一帧并观察对后续帧的影响。我们在 YouTube 数据集上对第一帧应用 DarkSAM 作为一次攻击,以评估其对 SAM2 的有效性。在第一帧上生成对抗性扰动后,我们将它们添加到所有后续帧中,并评估攻击的影响。我们将扰动预算从 10/255 逐渐增加到 32/255,以研究攻击强度的影响。如图 2 (a) 所示,即使在最高预算 32/255 下,DarkSAM 仍然无法显著降低分割性能。这可能归因于提示的方向性引导以及 SAM2 增强的鲁棒性(可能源于其先进的架构和多样化的训练数据)。此外,无法破坏第一帧的扰动通常也无法有效迁移到后续帧。

启示 I. 尽管攻击第一帧可以在一定程度上误导 SAM2 在整个视频序列中的行为,但其效果有限。这促使我们研究其他设计差异以提高攻击效力。
观察 II:对过去和当前帧的联合建模阻碍了针对特定帧的攻击。 根据 28,除了使用来自第一帧的固定提示外,SAM2 还维护一个记忆库,存储过去 kkk 帧的语义特征。一个记忆注意力模块整合这些特征以指导当前帧的分割。我们将这种同时使用历史上下文和当前帧特征的方式称为双重引导机制。
为了评估其影响,我们向从 YouTube 数据集中随机选取的中间帧注入对抗性噪声。然后,我们可视化图像编码器从先前帧提取并存储在记忆库中的特征。如图 2 (b) 的第 1 行和第 2 行所示,仅攻击单帧并不会显著降低 SAM2 的分割准确性,原因是跨连续帧的语义纠缠。然而,第 3 行和第 4 行显示,扰动过去帧的特征以破坏记忆库会显著损害当前帧的分割性能。为了探究这种双重引导机制的脆弱性,我们考察了两个互补的视角:当前帧中的语义错位和相邻帧间的语义不连续性。
为了探究这种双重引导机制的脆弱性,我们考察了两个互补的视角:当前帧中的语义错位和相邻帧间的语义不连续性。
我们通过将输出掩码阈值化为前景和背景来分割每一帧。我们专注于迫使 SAM2 将前景物体误解为背景,同时增强背景显著性以混淆当前帧的特征。图 2 已经表明,由于记忆模块的影响,单帧攻击是不够的。因此,我们扩展了攻击,通过注入跨连续帧的 UAP 来放大帧间语义差距。从图 3 可以看出,这导致当前帧与相邻帧以及第一帧之间的相似性逐渐下降。我们将这一发现称为雪崩效应现象。
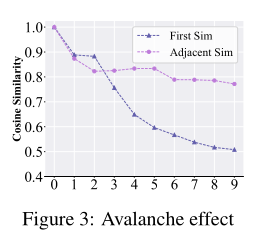
启示 II. 在基于记忆的引导存在的情况下,仅攻击单帧是无效的。相反,同时破坏当前语义和跨帧的时间一致性会在引导和分割之间产生更强的错配,从而削弱 SAM2 对视频内容的理解。
3.2 UAP-SAM2:完整的图示
基于第 3.1 节中概述的设计理念,我们从两个角度构建我们的攻击:(i)当前帧内的语义扭曲,以及(ii)跨连续帧的语义不连续性。对于当前帧,我们通过联合引入语义混淆和特征偏移来增强攻击有效性。为了减少我们的方法对特定提示的依赖,我们设计了一种目标扫描策略,在优化过程中选择随机提示。具体来说,我们将每个视频帧均匀划分为 mmm 个区域,并为每个区域随机生成一个提示。此外,我们的优化主要针对图像编码器的输出特征,其输入仅为图像。
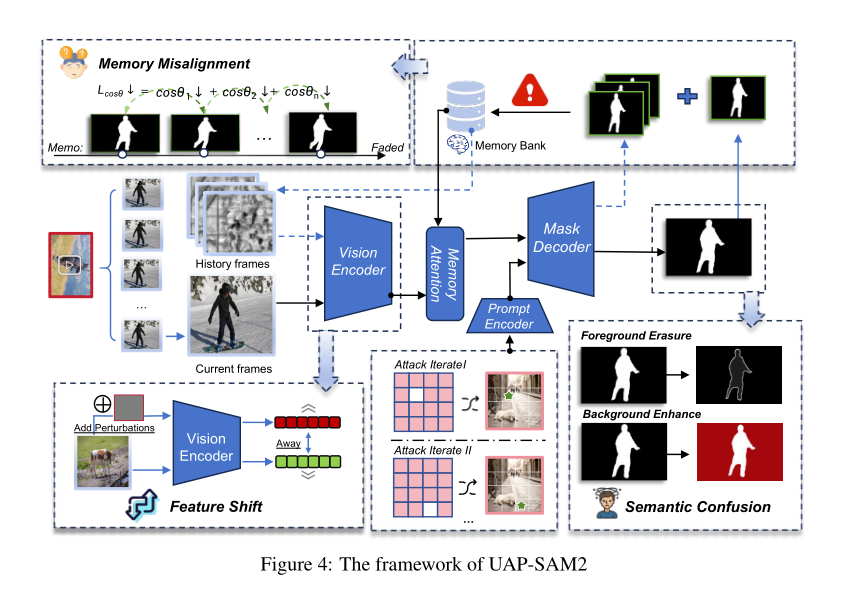
在本节中,我们介绍 UAP-SAM2,这是一种新颖的由双重语义偏差驱动的针对 SAM2 的跨提示通用对抗攻击。如图 4 所示,UAP-SAM2 流程实现了记忆错位攻击 Jma\mathcal{J}{ma}Jma 以破坏时间引导,特征偏移攻击 Jfa\mathcal{J}{fa}Jfa 以扭曲局部表示,以及语义混淆攻击 Jsa\mathcal{J}_{sa}Jsa 以混淆物体级语义。UAP-SAM2 的整体优化目标如下:
Jtotal=Jsa+Jfa+Jma(3) \mathcal{J}{total} = \mathcal{J}{sa} + \mathcal{J}{fa} + \mathcal{J}{ma} \tag{3} Jtotal=Jsa+Jfa+Jma(3)
语义混淆攻击。 我们应用一个二值掩码 m+m_+m+ 来分离每一帧中的物体和背景。与先前针对 SAM 的攻击 48 类似,我们旨在通过优化前景区域使其类似背景来误导模型。同时,我们进一步将决策边界附近的前景像素推向背景类别,同时强化原本被识别为背景的像素以保持其分类。通过将 UAP 添加到目标帧 xix_ixi,我们得到对抗帧 x~i\tilde{x}_ix~i。该目标可形式化为:
Jsa=1N∑i=1N{(fθ(x\~i,P)⋅m+−y−)2+((1−fθ(x\~i,P))⋅m−−y−)2}(4) \mathcal{J}{sa} = \frac{1}{N}\sum{i = 1}^{N}\left\{\left(f_{\\theta}(\\tilde{x}_i,\\mathcal{P})\\cdot m_+ - y_-)\\right^2 +\left\\left((1 - f_{\\theta}(\\tilde{x}_i,\\mathcal{P})\\right)\\cdot m_- - y_-)\\right^2\right\} \tag{4} Jsa=N1i=1∑N{(fθ(x\~i,P)⋅m+−y−)2+((1−fθ(x\~i,P))⋅m−−y−)2}(4)
其中 y−y_{- }y− 是一个与帧形状匹配的掩码,在与目标物体对应的区域包含阈值(例如 -1),其他地方为 0。m−m_{- }m− 表示每一帧背景区域的二值掩码,它是突出前景的掩码的反面。
为了进一步有效混淆前景和背景,我们使用二元交叉熵(BCE)损失函数,将接近零的 logits 视为模型对其分类置信度低。相反,logits 的绝对值越大(无论是正还是负),模型对其预测的置信度越高。为了增强攻击的有效性,我们提高像素位置的整体置信度,自然加强了在决策边界附近(即 logits 接近 0)的像素上的更新,从而将其 logits 推向背景,实现更强的混淆效果。因此,我们将语义混淆攻击 Jsa\mathcal{J}_{sa}Jsa 定义如下:
Jsa=1N∑i=1NBCE(fθ(x\~i,P)⋅m+,y−)+BCE((1−fθ(x\~i,P))⋅m−,y−)(5) \mathcal{J}{sa} = \frac{1}{N}\sum{i = 1}^{N}\left\\mathrm{BCE}\\left(f_{\\theta}(\\tilde{x}_i,\\mathcal{P})\\cdot m_{+},y_{-}\\right) + \\mathrm{BCE}\\left(\\left(1 - f_{\\theta}(\\tilde{x}_i,\\mathcal{P})\\right)\\cdot m_{-},y_{-}\\right)\\right \tag{5} Jsa=N1i=1∑NBCE(fθ(x\~i,P)⋅m+,y−)+BCE((1−fθ(x\~i,P))⋅m−,y−)(5)
特征偏移攻击。 我们优化 UAP 以最小化由 SAM2 图像编码器提取的扰动帧和良性帧特征之间的相似度。我们将此形式化为:
Jfa=−1N∑i=1Ncos(Eimg(x~i),Eimg(xi))(6) \mathcal{J}{fa} = -\frac{1}{N}\sum{i = 1}^{N}\cos \left(\mathcal{E}_{\mathrm{img}}(\tilde{x}i),\mathcal{E}{\mathrm{img}}(x_i)\right) \tag{6} Jfa=−N1i=1∑Ncos(Eimg(x~i),Eimg(xi))(6)
为了进一步增加对抗帧和良性帧之间的特征差异,我们采用对比学习 2 方法。我们首先对目标帧应用 ρ\rhoρ 次随机增强 T(⋅)\mathcal{T}(\cdot)T(⋅),并通过 ei=1ρ∑j=1pEimg(T(xi))e_i = \frac{1}{\rho}\sum_{j = 1}^{p}\mathcal{E}{\mathrm{img}}(\mathcal{T}(x{i}))ei=ρ1∑j=1pEimg(T(xi)) 将它们的特征聚合成一个原型。然后,我们将对抗帧 x~i\tilde{x}{i}x~i 和原始帧的原型 eie_iei 视为负对,同时从其他视频中随机采样帧作为正对。通过最大化 x~i\tilde{x}{i}x~i 和 eie_iei 之间的距离并最小化正样本之间的距离,我们有效地将对抗特征从其原始语义中推开。因此,我们可以得到 Jfa\mathcal{J}_{fa}Jfa。
Jfa=−1N∑i=1Nlogexp(cos(Eimg(x~i),ei))/τ∑k=1N1k≠iexp(cos(Eimg(x~i),Eimg(xk)))/τ(7) \mathcal{J}{fa} = -\frac{1}{N}\sum{i = 1}^{N}\log \frac{\exp\left(\cos\left(\mathcal{E}{\mathrm{img}}(\tilde{x}i),e_i\right)\right) / \tau}{\sum{k = 1}^{N}\mathbf{1}{k\neq i}\exp\left(\cos\left(\mathcal{E}_{\mathrm{img}}(\tilde{x}i),\mathcal{E}{\mathrm{img}}(x_k)\right)\right) / \tau} \tag{7} Jfa=−N1i=1∑Nlog∑k=1N1k=iexp(cos(Eimg(x~i),Eimg(xk)))/τexp(cos(Eimg(x~i),ei))/τ(7)
其中 1k≠i\mathbf{1}_{k\neq i}1k=i 是指示函数,τ\tauτ 表示温度参数。
记忆错位攻击。 从第二帧开始,我们通过最大化连续对抗帧之间的特征差异来破坏 SAM2 中的记忆库。通过逐步增加当前对抗帧与前一帧之间的语义差异,我们引发了图 3 所示的雪崩效应。此过程表述为:
Jma=−1N∑i=1Ncos(Eimg(x~i+1),Eimg(x~i))(8) \mathcal{J}{ma} = -\frac{1}{N}\sum{i = 1}^{N}\cos \left(\mathcal{E}{\mathrm{img}}(\tilde{x}{i + 1}),\mathcal{E}_{\mathrm{img}}(\tilde{x}_i)\right) \tag{8} Jma=−N1i=1∑Ncos(Eimg(x~i+1),Eimg(x~i))(8)
4 实验
4.1 实验设置
数据集和模型。 我们在三个公共视频分割数据集上评估我们的攻击:YouTube-VOS2018 (YouTube) 8、DAVIS 2017 (DAVIS) 26 和 MOSE 6,用于视频分割任务。为了进一步研究 UAP-SAM2 在图像分割任务上的表现,我们通过从原始视频数据集中随机采样帧来构建相应的基于图像的数据集,分别记为 YouTube*、DAVIS* 和 MOSE*。我们将视频中的所有帧调整为统一的尺寸 3×1024×10243\times1024\times10243×1024×1024。我们使用官方仓库中预训练的 SAM2-T、SAM2-S 和 SAM2.1-T 作为目标模型。为了进一步验证可迁移性,我们将在 Sam2long 7 上进行评估,该模型增强了 SAM2 在长视频任务中的能力。更多细节见附录 B。
攻击设置。 我们将通用对抗攻击 UAP-SAM2 的扰动边界 ϵ\epsilonϵ 设置为 10/255,将样本特定变体攻击 UAP-SAM2* 的扰动边界设置为 8/255,使用批量大小为 1,训练 10 个周期。我们使用固定的随机种子 30 进行所有实验以确保可重复性。我们默认使用点提示进行评估。
评估指标。 遵循 42, 48,我们使用平均交并比(mIoU)指标来评估 UAP-SAM2 的有效性。mIoU 是分割任务中广泛使用的指标 4, 24, 28,用于衡量预测掩码与真实掩码之间的平均重叠度。较低的 mIoU 值表示更好的攻击性能。
4.2 攻击性能
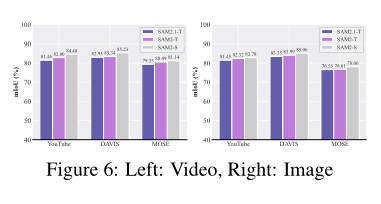
为了全面评估 UAP-SAM2 的有效性,我们在涵盖视频和图像分割任务的六个数据集(YouTube、DAVIS、MOSE、YouTube*、DAVIS* 和 MOSE*)上进行了实验。我们评估了三种模型变体:SAM2-T、SAM2-S 和 SAM2.1-T。为清晰起见,我们在全文中将数据集(包括其相应的变体数据集)记为 D1−D3\mathcal{D}_1 - \mathcal{D}_3D1−D3,将模型记为 M1−M3\mathcal{M}_1 - \mathcal{M}_3M1−M3。我们在 72 种不同设置下评估了我们攻击的样本特定变体和通用变体。对于每种设置,我们使用点提示和框提示生成对抗性示例,并报告点提示评估下的性能。作为参考,图 6 显示了 SAM2 在良性样本上的分割准确性。在图像和视频分割任务的六个数据集中,SAM2 的平均 mIoU 超过 76%76\%76%,展示了强大的分割能力和泛化性。表 1 显示,UAP-SAM2 生成的对抗性示例持续且显著地降低了 SAM2 的性能,并具有跨提示可迁移性。值得注意的是,在 DAVIS 数据集上使用点提示时,UAP-SAM2 及其变体 UAP-SAM2* 分别将 SAM2 的 mIoU 降低了超过 45.79%45.79\%45.79% 和 54.77%54.77\%54.77%。如表 1 所示,无论使用点提示还是框提示,我们的方法在视频分割上的攻击性能始终优于图像分割。这进一步验证了其在破坏连续帧间语义一致性方面的有效性。
我们在 72 种不同设置下评估了我们攻击的样本特定变体和通用变体。对于每种设置,我们使用点提示和框提示生成对抗性示例,并报告点提示评估下的性能。作为参考,图 6 显示了 SAM2 在良性样本上的分割准确性。在图像和视频分割任务的六个数据集中,SAM2 的平均 mIoU 超过 76%76\%76%,展示了强大的分割能力和泛化性。表 1 显示,UAP-SAM2 生成的对抗性示例持续且显著地降低了 SAM2 的性能,并具有跨提示可迁移性。值得注意的是,在 DAVIS 数据集上使用点提示时,UAP-SAM2 及其变体 UAP-SAM2* 分别将 SAM2 的 mIoU 降低了超过 45.79%45.79\%45.79% 和 54.77%54.77\%54.77%。如表 1 所示,无论使用点提示还是框提示,我们的方法在视频分割上的攻击性能始终优于图像分割。这进一步验证了其在破坏连续帧间语义一致性方面的有效性。
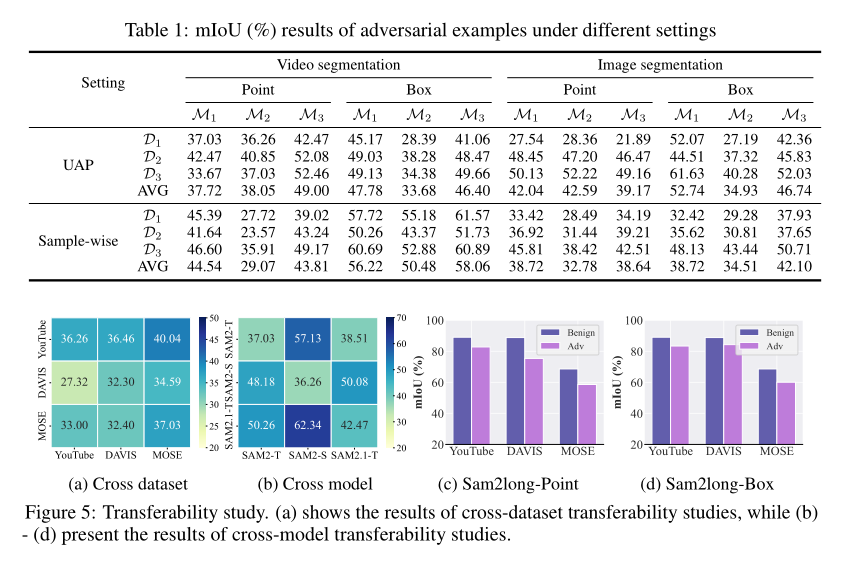
我们进一步评估了我们的方法在不同数据集和模型间的可迁移性。图 5 (a) 和图 5 (b) 报告了 UAP-SAM2 在迁移设置下的性能,其中每一行对应于从同一源生成的对抗性示例。结果展示了跨数据集和跨模型的强可迁移性。此外,图 5 © 和图 5 (d) 显示了在 SAM2-T 上制作并迁移到 Sam2long 7 的 UAP 在点提示和框提示下的攻击性能,证实了我们的方法对 SAM2 变体同样有效。
4.3 对比研究
鉴于缺乏专门针对 SAM2 的对抗性攻击,我们通过将 UAP-SAM2 与最新的针对 SAM 的攻击(如 Attack-SAM 42、S-RA 29、UAD 22 和 DarkSAM 48)进行全面比较来评估我们的方法。我们进一步将 UAP-SAM2 与最初为分类、图像分割和视频分割任务设计的代表性对抗性攻击方法(包括 UAPGD 5、SegPGD 10 和 VOSPGD 13)进行比较。为确保公平比较,我们将所有基线方法改编为通用对抗攻击框架,并应用与 UAP-SAM2 相同的优化设置。为了评估这些方法的跨提示泛化能力,我们统一采用随机提示(即训练和测试期间使用的提示不同)进行方法优化以生成对抗性示例。我们选择 SAM2-T 作为目标模型,并在六个数据集上的图像和视频分割任务上评估所有方法的性能。如表 2 所示,UAP-SAM2 在三个数据集的视频分割任务上优于所有现有攻击。对于图像分割,我们的方法也超越了大多数基线。上述结果可归因于我们的方法中对视频特征的专门设计。
4.4 消融研究
在本节中,我们研究了不同因素对 UAP-SAM2 攻击性能的影响。我们使用 SAM2-T 和 SAM2-S 作为目标模型,使用 DAVIS 作为数据集。
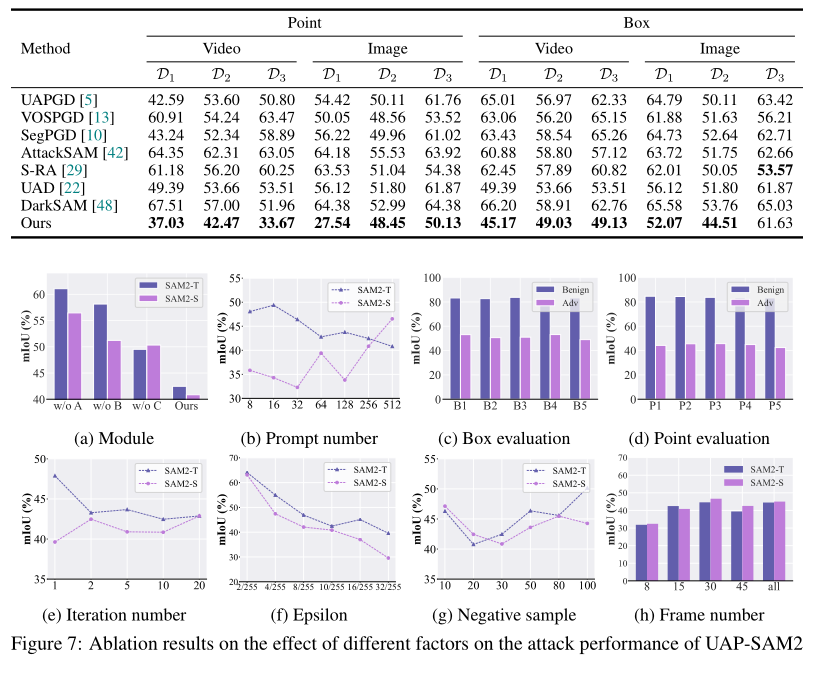
模块的影响。 我们进行消融研究以评估各个组件对 UAP-SAM2 攻击有效性的贡献。为清晰起见,我们将 Lsa\mathcal{L}{sa}Lsa、Lfa\mathcal{L}{fa}Lfa 和 Lma\mathcal{L}_{ma}Lma 分别记为 A、B 和 C。如图 7 (a) 所示,没有一个消融变体超过完整模型,这突显了每个模块在实现最佳攻击性能中的重要性。
提示数量的影响。 我们研究了所提出的目标扫描策略中分割区域的数量 mmm 如何影响 UAP-SAM2 的攻击性能。我们将区域计数从 8 变化到 512,并在图 7 (b) 中报告结果。当 m=256m = 256m=256 时,攻击在两种设置下都达到最佳性能,我们将其作为默认配置。
评估模式的影响。 我们研究了不同的评估提示设置如何影响 UAP-SAM2 的攻击性能。具体来说,我们使用五个随机采样的框提示(B1 - B5)和五个点提示(P1 - P5)评估了在 SAM2-T 上生成的扰动。如图 7 © - (d) 所示,UAP-SAM2 在不同的提示配置下持续保持强大的性能,证明了我们方法的鲁棒性。
迭代次数的影响。 我们研究了迭代次数对 UAP-SAM2 攻击性能的影响。我们进行了从 1 到 20 次不同迭代次数的实验。图 7 (e) 所示的结果表明,当迭代次数达到 10 后,攻击性能趋于稳定。因此,我们将其设置为实验的默认配置。
ϵ\epsilonϵ 的影响。 我们在图 7 (f) 中评估了 UAP-SAM2 在 ϵ\epsilonϵ 从 2/2552/2552/255 到 32/25532/25532/255 范围内的性能。随着 ϵ\epsilonϵ 的增加,攻击性能相应增强。值得注意的是,即使在 4/2554/2554/255 的设置下,我们的方法仍然保持高攻击效力,平均 mIoU 下降超过 33.08%33.08\%33.08%。
负样本数量的影响。 我们在图 7 (g) 中探索了改变负样本数量(从 10 到 100)对 UAP-SAM2 性能的影响。考虑到计算效率和攻击有效性,我们将 30 设置为默认测试值。
测试帧数量的影响。 我们研究了每个视频中选择的帧数对 UAP-SAM2 性能的影响。如图 7 (h) 所示,使用 15 帧的结果与使用所有帧的结果相当。因此,出于效率考虑,我们将 15 帧设置为实验的默认配置。
5 防御研究
由于目前没有专门针对 SAM2 的对抗性防御,我们通过两种常见的防御策略来探索 UAP-SAM2 的鲁棒性:模型剪枝 50 和数据预处理 27。
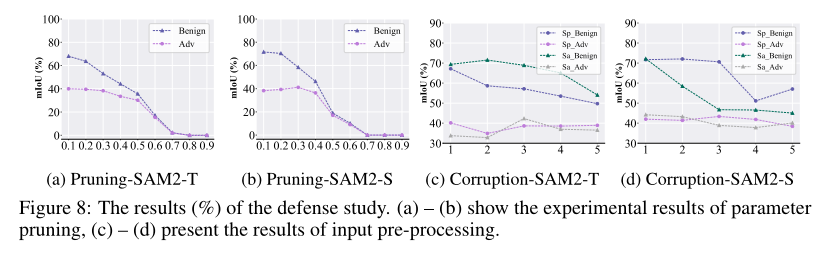
模型剪枝是一种广泛使用的压缩技术,通过移除冗余参数来简化网络复杂度,从而可能降低对扰动的敏感性。我们在 DAVIS 上评估了不同剪枝率(从 0 到 0.9)下的攻击性能。如图 8 (a) - (b) 所示,随着剪枝率的增加,良性样本的 mIoU 持续下降,而对抗性示例的 mIoU 保持相对稳定。值得注意的是,即使剪枝率达到 0.4,良性样本的性能显著下降,而对抗性示例的 mIoU 几乎不受影响。这些结果表明,模型剪枝对 UAP-SAM2 提供的鲁棒性有限。
数据预处理通过向图像引入诸如遮挡或模糊等失真来抑制对抗性噪声的影响。我们分别在严重程度从 0 到 5 的情况下应用飞溅(sp_)和饱和(sa_)损坏,以评估此策略在 DAVIS 上的有效性。如图 8 © - (d) 所示,增加损坏强度导致良性样本 mIoU 持续下降,而对抗性 mIoU 基本不受影响。这些发现表明,即使面临基于输入损坏的预处理防御,我们的方法仍然有效。
6 相关工作
6.1 分割一切模型
分割一切模型(SAM)17 因其强大的泛化能力在图像分割领域取得了显著成功。SAM2 28 是最新的改进版本,通过记忆机制应用于图像和视频分割任务,将 SAM 扩展到通用视频分割。用户只需在第一帧上提供一个提示,SAM2 就能在后续帧中实时执行目标定位和分割。基于其强大的泛化能力,最近的研究 1, 3, 7, 15, 19, 32, 39, 49 开发了特定任务的 SAM 变体,以更好地解决各种下游应用。SAM2 已迅速应用于各种下游任务,如医学视频分割 49、3D 分割 11 和伪装物体检测 32。
6.2 针对 SAM 的对抗性攻击
最近的研究 12, 20, 21, 29, 38, 42, 48 揭示了 SAM 易受对抗性示例攻击 9, 23, 25, 47, 18, 31, 44,这些示例通过添加难以察觉的扰动来诱导错误预测。现有的针对 SAM 的对抗性攻击分为两类:样本特定攻击(为每个输入定制扰动)和通用攻击(创建适用于许多图像的单一扰动)。Attack-SAM 42 是第一个采用 PGD 23 来操纵图像-提示对的预测掩码的方法。UAD 22 通过模拟空间变形来优化对抗性噪声,从而破坏图像编码器的特征表示,实现了无提示攻击,进一步扩展了这一方向。与此同时,DarkSAM 48 引入了第一个针对 SAM 的通用对抗攻击。它设计了一个混合空间-频率框架,阻止图像中的物体被分割,并提出了一个阴影目标策略以提高跨提示的可迁移性。其他研究 20, 29 则关注于欺骗 SAM 无法分割图像中特定物体的局部攻击。尽管这些方法对 SAM 有效,但由于图像和视频之间的模态差异以及 SAM2 的架构新颖性,它们无法直接应用于 SAM2。
7 结论、局限性与更广泛影响
在本文中,我们研究了现有攻击针对 SAM 和 SAM2 的性能差距,并将其归因于两个关键挑战:来自提示的方向性引导和跨连续帧的语义纠缠。为此,我们提出了 UAP-SAM2,这是第一个由双重语义偏差驱动的针对 SAM2 的跨提示通用对抗攻击。我们设计了一种目标扫描策略并直接扰动图像编码器的输出特征,以增强跨提示可迁移性。为了进一步提高攻击有效性,我们联合利用了语义混淆和特征偏差。我们在两个分割任务的六个数据集上进行了大量实验,证明了所提方法对 SAM2 的有效性。
虽然我们的工作侧重于基于提示的视频分割模型,但一个潜在的局限性是 UAP-SAM2 可能无法直接泛化到传统分割模型,因为它们的输出不是无标签掩码。尽管基于 SAM 的模型越来越受欢迎,但为 SAM2 制作的对抗性示例如何迁移到其他分割框架尚不清楚。随着这些模型越来越多地被应用于自动驾驶和医学成像等安全关键型应用,理解它们的脆弱性是未来研究的一个重要方向。
致谢
本工作得到湖北省重大计划项目(编号 2023BAA024)和国家自然科学基金项目(批准号 62372196 和 62202186)的资助。Yufei Song 是通讯作者。
参考文献
(参考文献 1-50 从略,内容同原始文件)
NeurIPS 论文清单
(清单内容从略,内容同原始文件)
A 附录
(附录内容从略)
B 实验设置
在本节中,我们提供实验设置的详细信息。对于视频分割,我们随机选择 100 个视频,并从每个视频中采样 15 个连续帧进行评估。对于图像分割,我们随机选择 50 个视频,并均匀采样总共 500 帧。
B.1 数据集
DAVIS 2017: DAVIS 2017 26 是一个广泛用于视频目标分割任务的标准数据集。其训练集包含 60 个视频,测试集包含 30 个视频。每个视频提供像素级的目标(人类、动物、物体)分割标注,即每一帧给出目标的精确边界。它专为视频中的目标分割和跟踪任务而设计,特别适用于多目标跟踪和分割研究。
YouTube-VOS2018: YouTube-VOS2018 8 是一个基于 YouTube 平台视频内容设计的大规模数据集,用于视频目标分割任务,特别是在长视频序列中实现精确的目标分割。该数据集提供了大规模、密集标注的视频序列。训练集包含 3,883 个视频,涉及 40 个不同的目标类别,测试集包含 1,474 个视频,涉及 20 个不同的目标类别。
MOSE: MOSE 6 是一个基于 YouTube 平台视频内容设计的大规模数据集,用于视频目标分割任务,特别是在长视频序列中实现精确的目标分割。该数据集提供了大规模、密集标注的视频序列。训练集包含 3,883 个视频,涉及 40 个不同的目标类别,测试集包含 1,474 个视频,涉及 20 个不同的目标类别。
B.2 评估指标
我们选择平均交并比(mIoU)作为评估分割准确性的指标。mIoU 是语义分割任务中常用的评估方法,用于衡量模型在不同类别上的性能。它通过计算每个类别的交并比(IoU)并对所有类别的 IoU 取平均来获得最终评估结果。具体来说,IoU 是预测区域与真实区域的交集面积与两者并集面积的比率。每个类别的 IoU 计算公式为:
IoU=预测区域∩真实区域预测区域∪真实区域 \mathrm{IoU} = \frac{\mathrm{预测区域} \cap \mathrm{真实区域}}{\mathrm{预测区域} \cup \mathrm{真实区域}} IoU=预测区域∪真实区域预测区域∩真实区域
mIoU 是所有类别 IoU 的平均值,反映了模型在分割任务中的整体性能。更高的 mIoU 表示在各类别上具有更好的分割性能,特别是在类别不平衡或细粒度分割任务中。
C 补充对比研究
与第 4.3 节一致,我们将 UAP-SAM2* 与一系列 SOTA 对抗性攻击进行比较,包括 Attack-SAM 42、S-RA 29、UAD 22、DarkSAM 48、PGD 23、SegPGD 10 和 VOSPGD 13。为确保公平比较,所有基线方法都被改编为样本特定对抗攻击框架,并在与 UAP-SAM2* 相同的设置下进行优化。为了评估这些方法的跨提示泛化能力,我们统一采用随机提示(即训练和测试期间使用的提示不同)进行方法优化以生成对抗性示例。我们选择 SAM2-T 作为目标模型,并在六个数据集上的图像和视频分割任务上评估所有方法。如表 A1 所示,UAP-SAM2* 在三个数据集的图像和视频分割任务上普遍优于所有现有攻击方法,只有一个例外。在 UAP 和样本特定对抗攻击框架下的可视化比较分别在图 A3 和图 A4 中提供。
D 多点评估研究
我们深入研究了多提示评估设置对我们提出的攻击方法有效性的影响。具体来说,我们选择 SAM2-T 作为目标模型,并考察输入提示数量的变化如何影响对抗性示例上的分割性能。如图 A2 所示,我们展示了 SAM2 在不同提示点数量下的分割输出的定性可视化。我们的观察表明,增加提示数量为模型提供了更多关于目标物体的空间信息,这可以稍微减轻对抗性扰动的影响。尽管如此,UAP-SAM2 仍然表现出强大的攻击性能,即使在密集提示条件下,也能持续破坏 SAM2 生成连贯且语义有意义的分割的能力。这些结果突显了我们的方法在不同提示配置下的鲁棒性和普遍有效性。
E 稳定性分析
考虑到随机种子设置对训练和测试图像选择的潜在影响,我们详细分析了不同随机种子如何影响 UAP-SAM2 的性能。虽然我们在所有主要实验中默认采用随机种子 30 以确保一致性,但我们进一步通过在多个随机种子设置下评估我们的方法来探索其鲁棒性。具体来说,我们选择了五个随机种子,并在三个基准数据集(DAVIS、YouTube 和 MOSE)上使用 SAM2-T 作为目标模型进行通用对抗攻击。如图 A1 所示,误差线反映了不同种子下攻击性能的方差。数据集上持续的小波动证实了 UAP-SAM2 提供稳定可靠的结果,显示出对种子初始化变化的强鲁棒性。