读完 17 篇 NovaFlow(零训练、用 3D 流驱动)和 18 篇 LV-P(自建 14B 视频基座),这一篇的 Dream2Flow 像是把它们的优点又拢到了一起:它沿用 NovaFlow 那种"借现成视频模型 + 3D 物体流中间表征"的零样本思路 ,但目标更野心------要在开放世界(open-world)里、对刚性、铰接、可形变、颗粒状四大类物体都能用同一套框架搞定,只靠一句话和一张图。
它同样坐落在「级联式 WAM → 像素空间 → 几何式动作提取」这一支。这一篇我们重点讲清楚:它和 NovaFlow 到底像在哪、不同在哪,以及它为"开放世界操作"做了哪些专门的设计。
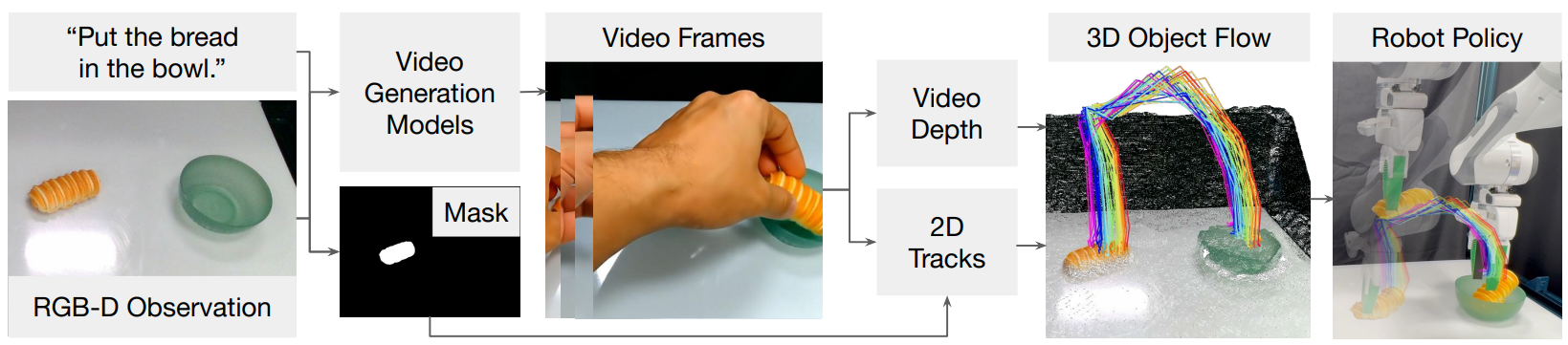
一、要解决什么问题:视频模型很会"做梦",可机器人不会"圆梦"
今天的图生视频大模型有个让人惊艳的能力:你给它一张当前场景图、加一句"把面包放进碗里",它就能"做梦"般地生成一段合理的视频------面包被一只手拿起来、移过去、放进碗里。这段梦里,物体的运动几乎总是物理上合理的,因为模型在海量互联网视频里见过无数类似场景。
但这里有个根本性的错位:
视频里完成任务的是"人手",而真正要去执行的是"机器人"。视频模型擅长生成"物体该怎么动",却没法直接告诉机器人"你的关节该怎么转"。
这就是反复出现的本体鸿沟(embodiment gap)------梦里是人的身体,现实里是机器人的身体,两者对不上。再加上开放世界里物体五花八门(有硬的、有带关节的、有软的、还有沙子米粒这种颗粒状的),想用一套统一的方法把"梦"翻译成"动作",就更难了。
Dream2Flow 要回答的就是:怎么把视频模型做的这个"梦",稳健地、跨物体类型地、在开放世界里翻译成机器人能执行的低层指令?
二、核心思想与直觉:把"物体怎么动"从"谁来动"里剥离出来
Dream2Flow 的核心 idea 和 NovaFlow 一脉相承,但表述得更点题:
用"3D 物体流(3D object flow)"作中间表征,把"状态如何改变"(物体怎么动)和"由谁来实现这个改变"(人手还是机器人)彻底分开。
打个比方:你要描述一支舞,可以用两种方式。一种是描述"舞者的肌肉和关节怎么发力"------这高度依赖具体是谁在跳;另一种是描述"舞者身体的关键点在空间里画出的轨迹"------这与是谁无关,换个人照着轨迹也能跳出同一支舞。3D 物体流就是后一种描述:它只记录"场景里物体上的点,在三维空间中沿时间画出的轨迹",完全不提"是人手还是机器人促成了这些运动"。
这一剥离带来两个直接好处:
- 跨越本体鸿沟:因为流里没有任何"执行者"的信息,所以视频里是人手在动没关系------我只取物体的运动,再交给机器人去复现。
- 零样本、对物体类型不挑食:流是点级轨迹,不假设物体是刚体、不需要物体 CAD 模型,因此刚性、铰接、可形变、颗粒状物体都能用同一种表征来描述,再分类型落地。
作者特别强调,3D 物体流比"只跟踪物体 6D 位姿"的方法更通用、更耐用------位姿跟踪隐含"物体是刚体"的假设,遇到绳子、布料、沙堆就失灵了;而点级的流天然能描述形变和散开。这正是 Dream2Flow 想覆盖"开放世界全物体类型"的底气所在。
它和 NovaFlow(17 篇)的关系,可以理解为同一思路在"开放世界 + 物体类型广度"维度上的推进:都用现成视频模型、都用 3D 物体流、都零样本,但 Dream2Flow 把物体类型扩到了"颗粒状",并在不同类型的动作落地策略上做了更细的分工。
为什么偏偏是"3D 物体流",而不是别的中间表征
要体会这一选择的分量,不妨把候选的几种"中间语言"摆在一起比一比。从视频里提取动作,业界大致试过三条路:
- 直接学一个动作翻译网络(逆动力学,IDM) :看着前后两帧画面,回归出"中间该执行什么动作"。问题是它得针对机器人本体训练,换个机器人就得重学,且容易把"人手"的动作硬学进去,本体鸿沟没真正解决。
- 2D 光流 :记录画面上每个像素往哪个方向移动。它的硬伤是没有深度------当物体朝着或背着相机方向运动时,画面上几乎看不出位移,光流就"瞎了";而且二维信息无法直接换算成三维世界里的位移距离。
- 物体 6D 位姿跟踪 :跟踪整个物体的平移+旋转。它隐含一个强假设------物体是刚体。一旦遇到绳子、布、一堆沙子,"整体位姿"这个概念本身就不成立了。
3D 物体流恰好同时绕开了这三个坑 :它带深度(解决 2D 光流的盲区)、不假设刚体(解决位姿跟踪的局限)、不含执行者信息(解决 IDM 的本体鸿沟)。它把"物体运动"描述到点级别------每个点各自有自己的三维轨迹,所以无论物体是整体平移、还是局部形变、还是干脆散成一片颗粒,它都能如实记录。这正是 Dream2Flow 敢于宣称覆盖"开放世界全物体类型"的根本原因。
三、方法详解:从"做梦"到"圆梦"的开放世界流水线
整条流水线分三大段:生成梦境 → 把梦提炼成 3D 物体流 → 按物体类型把流翻译成动作。
3.1 第一段:用现成的图生视频模型生成任务视频
输入是一张初始 RGB 图 + 一句任务指令。Dream2Flow 把它喂给一个现成的、可替换的图生视频模型来"做梦"。
值得注意的是,它不锁定单一模型,而是把视频生成器当成"可插拔组件",并实测了多家:
- Veo 3:在真实世界任务上表现最好;
- Wan 2.1:在仿真任务上效果最优;
- 还对比了 Kling 2.1 / Kling 2.6、Sora 2 等。
这种"框架与具体视频模型解耦"的设计很务实------视频大模型迭代飞快,今天最强的明年可能就被超越,把它做成可替换组件,框架就能持续吃到底座进步的红利。
3.2 第二段:用视觉基础模型把梦提炼成 3D 物体流
视频是平面像素,要变成 3D 流,得靠一组视觉基础模型协同把"哪些是目标物体、它们离相机多远、每个点往哪飘"都搞清楚:
- 物体分割 :Grounding DINO (按文字找到目标物体)+ SAM 2(精确分割出来)。
- 点跟踪 :CoTracker3 与 SpatialTrackerV2(在画面上追踪关键点的轨迹)。
- 深度估计:视频深度估计模型,逐帧给出每个像素的深度。
把这些拼起来,流程是:分割出相关物体 → 逐帧估深度 → 跟踪 2D 关键点 → 借助深度把 2D 轨迹抬升成"度量一致(metrically consistent)"的 3D 轨迹 。最终产物就是目标物体上一簇点在三维空间中随时间演化的轨迹------3D 物体流。这里"度量一致"很关键:它意味着流的尺度对应真实物理尺寸,机器人才能照着它走对距离。
3.3 第三段:把流翻译成动作------按物体类型分而治之
拿到流之后,Dream2Flow 把"操作"重新表述为一个**物体轨迹跟踪(object trajectory tracking)**问题:机器人要做的,就是想办法让真实物体沿着流规定的轨迹运动。针对不同物体类型,落地手段不同:
(A) 刚性物体的抓取操作 :用数据驱动的抓取选择 ------调用 AnyGrasp (生成候选抓取位姿)等,结合从视频里恢复的手部信息(HaMeR)确定怎么抓;抓住后,物体被夹爪带着按"刚体变换"运动,于是末端执行器的位姿规划就由"物体该怎么动"反解出来。
(B) 非抓取式(non-prehensile)操作 (如推、扫这类不抓起来的动作):用一个学习式的、基于粒子的动力学模型 ------以 Point Transformer V3 为骨架,预测"我这么推,物体的粒子会怎么动",再去逼近流给出的目标。这对推 T 形块、扫面条这种"不抓、靠推/拨"的任务很关键。
© 铰接物体 (带关节,如开门、开烤箱、开抽屉):用强化学习配合"基于流的奖励"------把"物体上的点是否到达了流指定的位置"作为奖励信号,让策略学会施加正确的力把关节打开。
(D) 颗粒/可形变物体(沙、米、布等):同样落在"流作为跟踪目标"的范式里,由动力学模型/优化去逼近流目标。
一句话概括这一段的设计哲学:"物体怎么动"由流统一描述,"怎么让它这么动"则按物体物理性质(能不能抓、是否刚性、有没有关节)选用抓取+刚体变换、粒子动力学、或强化学习等不同工具。
为什么不能用一种方法通吃?因为"让物体沿轨迹运动"这件事,对不同物体的物理意义完全不同 。对一个刚性的易拉罐,你只要抓住它、按流走就行,运动学是确定的、可解析的;对一堆要被推开的面条,你根本抓不住,只能靠"推/拨",而推力作用下颗粒会怎么散开是个复杂的接触动力学问题,得用学习式的粒子模型去预测;对一扇门,你既要找到把手、又要施加恰当的力矩让它绕铰链转动,这种"带约束的发力"用强化学习去试错最自然。流给出了统一的"目标"(物体该到哪),但"如何施力去达成目标"必须尊重各类物体的物理特性。 这种"统一表征 + 分类执行"的设计,是 Dream2Flow 能在开放世界里覆盖广泛物体的工程关键。
值得一提的是,正因为流里不含任何"是谁在动"的信息 ,本体鸿沟在这一步被悄悄抹平了:视频里是人手把面包放进碗,提取出来的却只是"面包这簇点的三维轨迹";机器人拿到的是这条轨迹,至于用平行夹爪还是灵巧手去复现,与"梦里那只手长什么样"毫无关系。解耦的妙处,正在于把一个跨本体的难题,转化成了一个"让真实物体走对轨迹"的纯几何/控制问题。
把三段串成一张表:
| 阶段 | 做什么 | 用到的组件 |
|---|---|---|
| 1 做梦 | 图+指令→任务视频 | 可插拔 I2V:Veo 3(真实最佳)/ Wan 2.1(仿真最佳)等 |
| 2 提流 | 视频→度量一致的 3D 物体流 | Grounding DINO + SAM 2、CoTracker3 + SpatialTrackerV2、视频深度 |
| 3 圆梦 | 流→机器人动作(按物体类型) | AnyGrasp/HaMeR(刚体抓取)、Point Transformer V3(非抓取动力学)、RL(铰接) |
核心公式与逻辑梳理
把整条流水线写成"输入到动作"的算法逻辑链,只有六步:
- 做梦 :图生视频模型 G\mathcal{G}G 接收一张初始图 I0I_0I0 和指令 ℓ\ellℓ,吐出 TTT 帧 RGB 视频 {It}\{I_t\}{It}。
- 分割 :Grounding DINO + SAM 2 输出目标物体的二值掩码 MMM。
- 深度 :视频深度模型给出每帧深度图 ZtZ_tZt。
- 抬升 3D :把 2D 跟踪轨迹按深度反投影到世界系,得到度量一致的 3D 物体流 P1:T\mathcal{P}_{1:T}P1:T。
- 轨迹跟踪 :把操作建模为"让真实物体走对 P1:T\mathcal{P}_{1:T}P1:T"的优化或控制问题。
- 分类落地:刚体走抓取+几何反解,非抓取走粒子动力学,铰接走 RL,软体/颗粒走流跟踪。
下面用公式把最关键的几环钉牢。
(1) 度量一致的 3D 物体流
用掩码 MMM 选出目标物体上的像素 uuu,再借深度 ZtZ_tZt 与投影 Π\PiΠ 抬升到世界系:
P1:T={ Π−1(uti, Zt(uti)) ∣ uti∈M, i=1,...,n, t=1,...,T } ∈ RT×n×3\mathcal{P}_{1:T} = \big\{\,\Pi^{-1}(u_t^i,\,Z_t(u_t^i))\,\big|\, u_t^i \in M,\; i=1,\dots,n,\; t=1,\dots,T\,\big\}\;\in\;\mathbb{R}^{T\times n\times 3}P1:T={Π−1(uti,Zt(uti)) uti∈M,i=1,...,n,t=1,...,T}∈RT×n×3
符号说明 :utiu_t^iuti 是第 iii 个被 CoTracker3 跟踪到的 2D 像素在第 ttt 帧的位置;Zt(uti)Z_t(u_t^i)Zt(uti) 是该像素在该帧的度量深度;Π−1\Pi^{-1}Π−1 是相机投影的逆(结合内参与外参,把"像素 + 深度"反算回三维世界坐标);MMM 限定只取目标物体上的点;最终 P\mathcal{P}P 是一个 T×n×3T\times n\times 3T×n×3 的张量。
这条式子在做什么 :把"画面上一堆 2D 轨迹"抬升成"世界系里一堆带物理尺度的 3D 轨迹"。这一抬升直接绕开了 2D 光流的两大硬伤------朝相机方向的运动看不见、米单位换算不出来。而只保留掩码内的点这一动作,让流变成了"纯粹物体描述、不含人手/机器人"------本体鸿沟在数学上就此被切开。
(2) 操作 = 物体轨迹跟踪(任务目标)
把整个操作问题写成一个动作序列的优化:
minu1:T∈U ∑t=1Tλtask⋅∑i=1n∥x\^tobj\[i−Pti∥22⏟物体轨迹跟踪+λctrl⋅Cctrl(x^t,ut)]\min_{u_{1:T}\in \mathcal{U}}\; \sum_{t=1}^{T}\Big\\lambda_{\\text{task}}\\cdot\\underbrace{\\sum_{i=1}\^{n}\\big\\\|\\hat{x}_{t}\^{\\text{obj}}\[i - \mathcal{P}ti\big\|{2}^{2}}{\text{物体轨迹跟踪}} + \lambda{\text{ctrl}}\cdot \mathcal{C}_{\text{ctrl}}(\hat{x}_t, u_t)\Big]u1:T∈Umint=1∑Tλtask⋅物体轨迹跟踪 i=1∑n x\^tobj\[i−Pti 22+λctrl⋅Cctrl(x^t,ut)]
符号说明 :utu_tut 是第 ttt 步动作(机器人指令),U\mathcal{U}U 是合法动作集合;x^tobji\hat{x}_{t}^{\text{obj}}ix^tobji 是在动作下预测得到的物体上第 iii 个点的位置;Pti\mathcal{P}tiPti 是流给出的目标位置;Cctrl\mathcal{C}{\text{ctrl}}Cctrl 是控制代价(如关节加速度、能量),λ\lambdaλ 们是权重。
这条式子在做什么 :把"操作"这件事抽象成"让真实物体走对预先想象的 3D 轨迹"------任务项要求物体上的点贴着流走,控制项压住"动作幅度过大"。整个目标里没有任何"执行者"的字眼------所以同一条流既能驱动 Franka 平行夹爪、也能驱动灵巧手,体现的就是 Dream2Flow 反复强调的"状态与执行者解耦"。
(3) 粒子动力学模型(非抓取式操作)
像扫面条、推 T 形块这种没法抓的任务,用基于 Point Transformer V3 的粒子动力学预测器学一个状态转移:
Δx^t+1=gϕ(x~t, ut),x~t∈RN×14\Delta\hat{x}{t+1} = g{\phi}\big(\tilde{x}_t,\, u_t\big),\qquad \tilde{x}_t \in \mathbb{R}^{N\times 14}Δx^t+1=gϕ(x~t,ut),x~t∈RN×14
Ldyn(ϕ)=E ∥ gϕ(x\~t,ut)−(xt+1−xt)∥22 \mathcal{L}_{\text{dyn}}(\phi) = \mathbb{E}\Big\\,\\big\\\|\\,g_{\\phi}(\\tilde{x}_t, u_t) - (x_{t+1} - x_t)\\big\\\|_{2}\^{2}\\,\\BigLdyn(ϕ)=E gϕ(x\~t,ut)−(xt+1−xt) 22
符号说明 :x~t\tilde{x}tx~t 是 NNN 个粒子的特征张量(每个粒子拼了位置、RGB、法向、推力参数,共 14 维);gϕg\phigϕ 是 Point Transformer V3 骨架的预测器;Δx^t+1\Delta\hat{x}_{t+1}Δx^t+1 是它预测的下一时刻位置增量;ϕ\phiϕ 是网络参数。
这条式子在做什么 :刚体可以解析地反求(Kabsch 那一套),但散开的面条、被推的 T 形块没法用"整体平移+旋转"描述,必须靠学习式动力学预测器来回答"我这么推,粒子会往哪散"。把动力学学好之后,把它代入式 (2) 的任务项内做 MPC/优化,就能反求出动作。这一步是 Dream2Flow 比 NovaFlow 多覆盖一类"颗粒物体"的关键。
(4) 铰接物体的 RL 奖励(流距离换算成进度)
对开抽屉/开门这种带关节、需要试错施力的任务,Dream2Flow 直接把流变成 RL 奖励:
t∗=argmint 1n∑i=1n∥x^τobji−Pti∥2,rflow=w⋅t∗Tt^{*} = \operatorname*{argmin}{t}\;\frac{1}{n}\sum{i=1}^{n}\big\|\hat{x}{\tau}^{\text{obj}}i - \mathcal{P}{t}i\big\|{2}, \qquad r{\text{flow}} = w\cdot\frac{t^{*}}{T}t∗=targminn1i=1∑n x^τobji−Pti 2,rflow=w⋅Tt∗
符号说明 :x^τobj\hat{x}_\tau^{\text{obj}}x^τobj 是当前真实仿真步 τ\tauτ 下物体的状态;Pt\mathcal{P}_tPt 是流在第 ttt 个想象帧上的目标;t∗t^*t∗ 是"当前真实状态最接近流序列中哪一个目标帧"的索引;TTT 是流总长;www 是缩放常数。
这条式子在做什么 :把"当前物体距离流上的哪一站最近"换算成一个介于 0 到 1 的"进度奖励"------物体越往任务终点推进,t∗/Tt^*/Tt∗/T 就越大。RL 智能体只要按这个奖励施力探索,自然学会"逐步把抽屉拉开"。用流当奖励信号这一步,让原本需要专门工程化奖励函数的铰接物体操作变成了"读图、对齐、跟着流走"的统一范式------这是 Dream2Flow 把流的用途从"目标"扩展到"奖励"的精彩之处。
四、实验怎么做·结果说明了什么
任务(共 8 个,刻意覆盖四大物体类型):Push-T(推 T 形块)、把面包放进碗、开烤箱、盖碗、拉椅子、开抽屉、扫面条、回收易拉罐。这套任务组合本身就是在展示"开放世界、全物体类型"的卖点------既有刚性抓取(面包、易拉罐),也有铰接(烤箱、抽屉),还有非抓取推扫(Push-T、扫面条)。
真机结果 :在 60 次真实世界试验中,整条流水线的逐级表现是------
- 视频生成成功:48 次
- 流提取成功:44 次
- 机器人执行成功:40 次
- 整体成功率约 67%(40/60)
这个"漏斗式"的数字非常有信息量:它把失败明明白白地归因到了三个环节,让人一眼看出每一级各损失了多少 ------从 60 到 48(视频环节掉了 12),48 到 44(流提取掉 4),44 到 40(执行掉 4)。可见最大的损耗发生在最上游的视频生成,这和 NovaFlow"视频模型是智力上限"的结论一致。
对比基线 :主要对比了 AVDC (稠密 2D 光流派)和 RIGVid (从视频估刚体位姿变换派)。Dream2Flow 报告其成功率"高于或持平"这些基线------核心论点是:3D 物体流这种点级表征,比"2D 光流"(缺深度)和"刚体位姿"(限刚体)更通用、更稳健,所以能覆盖更多物体类型、在开放世界里更耐用。(论文同时给出仿真与真机实验佐证这一点。)
五、亮点与为什么重要
- 把"3D 物体流"这一表征的价值讲透并推广到开放世界:明确论证了它相对 2D 光流(无深度)和 6D 位姿(限刚体)的双重优势,并用刚性/铰接/可形变/颗粒四类任务证明其通用性。
- 状态与执行者彻底解耦:用"物体流不含执行者信息"这一点干净地跨过本体鸿沟,做到零样本、免演示。
- 视频模型可插拔:框架不绑定特定生成器,能持续吃到视频大模型进步的红利;还顺手对比了 Veo 3 / Wan 2.1 / Kling / Sora 2 在该任务上的优劣(真实场景 Veo 3 最佳、仿真 Wan 2.1 最佳)。
- 按物体类型的多策略落地:刚体抓取用 AnyGrasp+刚体变换、非抓取用 Point Transformer V3 粒子动力学、铰接用基于流的 RL------一套表征、多套执行,覆盖面广。
- 透明的失败分析:用 60 次试验的"漏斗"清楚定位瓶颈在视频生成,方法论上很诚实,也给后人指了优化方向。
六、局限与未解
作者的失败分析点出三类主要瓶颈:
- 视频生成的硬伤:物体"变形/穿模(morphing)"、幻觉(生成了不该有的内容)。这是整条链路最大的损耗源,也是系统智力的天花板。
- 跟踪失败:遇到遮挡、或物体发生剧烈旋转时,点跟踪会失准。
- 抓取选择不匹配:抓取逻辑选错抓法,导致抓不稳或抓错位置。
可以看出,和 NovaFlow 类似,Dream2Flow 的瓶颈也呈"两头"分布------上游被视频模型质量锁死,下游受限于跟踪与抓取的鲁棒性 。另外,论文公开信息中未把 NovaFlow、Im2Flow2Act、ReKep、VoxPoser 等作为直接对比基线(主要对比 AVDC 与 RIGVid),因此与最相近的 NovaFlow 之间缺乏直接的同协议横评------这也是读者在比较两者时需要留意的地方。
七、在 WAM 谱系中的位置
Dream2Flow 与 NovaFlow(17 篇)是"级联---像素---几何---物体流"这条细分支上血缘最近的一对:
| NovaFlow(17) | Dream2Flow(19) | |
|---|---|---|
| 中间表征 | 校准的 3D 点流 | 度量一致的 3D 物体流 |
| 视频模型 | Wan / Veo | 可插拔(Veo3/Wan2.1/Kling/Sora2) |
| 物体类型 | 刚性/铰接/可形变 | 刚性/铰接/可形变/颗粒 |
| 跟踪 | TAPIP3D | CoTracker3 + SpatialTrackerV2 |
| 落地 | Kabsch / PhysTwin+MPC | AnyGrasp+刚体 / Point Transformer V3 / RL |
| 机构 | 布朗/RAI | 斯坦福 |
它和上游的 AVDC、Im2Flow2Act、3DFlowAction(光流派)以及 RIGVid、Dreamitate(位姿派)共同构成了"几何式动作提取"的家族谱系------而 Dream2Flow 的贡献,是把这条路推向了更开放的世界和更全的物体类型,并在工程上把视频生成器做成了可热插拔的组件。
读到这里,17--19 三篇都在"想象 2D 视频 → 后处理估深度 → 提取流"的套路里打转。下一篇 20 的 4DGen 会跳出这个套路:它让世界模型直接生成自带 3D 几何的"4D 视频"(RGB + 点图序列),从源头省掉"事后估深度"这道容易出错的工序------这正是对本篇"上游被视频质量锁死、深度靠后处理"这一痛点的另一种回应。
八、参考
- 论文:Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
- 作者:Karthik Dharmarajan、Wenlong Huang、Jiajun Wu、Li Fei-Fei、Ruohan Zhang
- 机构:斯坦福大学
- 会议/年份:ICRA 2026(arXiv 预印本,2025)
- arXiv:https://arxiv.org/abs/2512.24766
- 项目主页:https://dream2flow.github.io/
注:本文为基于该论文公开信息的学习性解读,方法、组件与数字以原论文为准;部分细节据其公开页面整理,精确数据请查阅原文。