上一篇 NovaFlow 走的是"借现成视频模型、零训练"的轻量路线。这一篇的 LV-P(Large Video Planner,大型视频规划器)反其道而行------它自己从头训了一个 140 亿参数的视频基础模型,立志把"视频"做成机器人决策的"母语",再从模型想象出的视频里重建出人手的三维姿态,映射成机器人末端执行器的轨迹。
它依然属于「级联式 WAM → 像素空间 → 几何式动作提取 」一族:先想象视频,再几何地提取动作。但它最值得讲的,是一个让"想象的视频在时间上更连贯、更可控"的训练技巧------扩散强迫(Diffusion Forcing)。这一篇我们就把这套大基座 + 扩散强迫 + 人手重建的组合拳讲透。
一、要解决什么问题:机器人基础模型,到底该用什么"母语"
这两年构建"机器人基础模型"主流是把一个多模态大语言模型(MLLM)改装一下,让它在输出文字之外也能输出动作------这就是 VLA(视觉-语言-动作模型)的思路。它的潜台词是:语言是智能的主干,动作只是挂在语言模型后面的一个小尾巴。
LV-P 的作者提出了一个不同的判断:对机器人这种"活在物理世界、要和时空打交道"的智能体来说,真正贴合它本质的"母语"也许不是语言,而是视频。
为什么?因为一段视频天然地编码了"状态如何随时间演化"的时空序列------画面里物体怎么动、手怎么伸过去、东西怎么被推走,本身就是一串连续的"状态-动作"轨迹。这和机器人要做的事情(在时间上连续地改变世界状态)是同构的。而语言是高度压缩、离散、抽象的,把物理动作硬塞进"下一个词预测"的框架里,多少有点削足适履。
于是 LV-P 旗帜鲜明地主张:用大规模视频预训练作为构建机器人基础模型的"主模态"。 让模型先在海量视频上学会"想象世界会怎么演化",再把这份想象翻译成动作。
但这条路有两个绕不开的难题:
- 怎么训出一个又通用又能"按需想象"的视频基座? 它既要能"看一张图脑补一段视频"(从头规划),也要能"接着一段已有视频往下续"(在执行中滚动规划)。
- 想象出的是人在操作的视频,可机器人不是人。 怎么把视频里"人手怎么动"翻译成"机器人末端执行器怎么动"?这又是那个老问题------本体鸿沟(embodiment gap)。
二、核心思想与直觉:一个会"看图脑补"也会"续写视频"的 14B 大脑
LV-P 的核心可以拆成两句话:
第一,训练一个 14B 的潜空间视频扩散大模型,用"扩散强迫"让它既能从单帧规划、也能续接视频,且时序连贯、可控。
第二,从它想象出的视频里用现成工具重建人手的 4D 轨迹,再几何地映射成机器人末端执行器的指令。
先说一个直觉性的比喻,理解第一句里最关键的"扩散强迫"。
普通的视频生成模型像一个"一口气写完全篇"的作家------所有帧同时从纯噪声里去噪生成,要么全是"已知的过去",要么全是"要生成的未来",泾渭分明。这带来一个问题:如果你想让它"已知前几帧、续写后几帧",往往得专门改架构、加模块。 而且"过去"和"未来"被同等对待,模型不容易学会"越靠近现在越确定、越往未来越发散"这种符合直觉的时间结构。
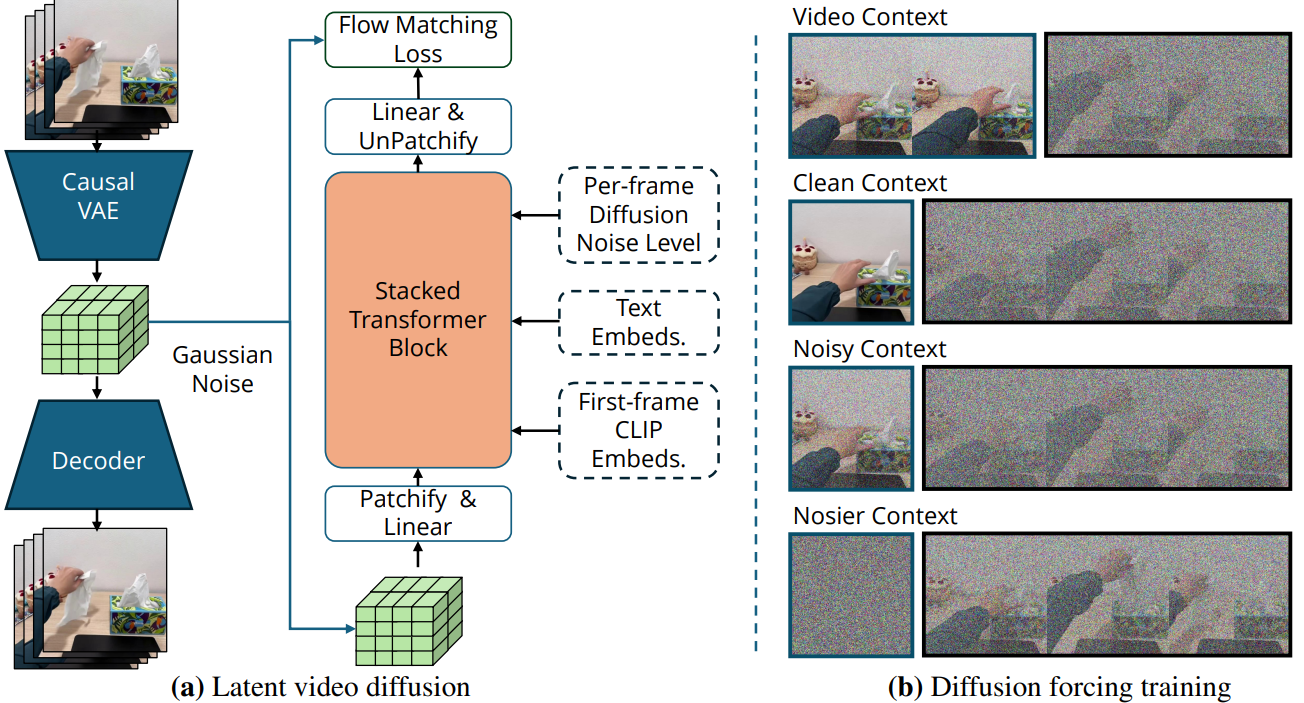
扩散强迫 换了个玩法:它给视频的不同片段独立地施加不同强度的噪声 ------把"历史"片段加很少的噪声(因为它接近确定、是给定的条件),把"未来"片段加很重的噪声(因为它要从模糊中被生成出来)。再配合因果掩码(不让未来的信息泄漏回过去)。
这样一来,同一个模型、同一套权重,就能统一处理"图生视频"和"视频生视频"两种任务:想从一张图开始规划?把历史长度设成 0;想接着已有画面续写?把已有画面当低噪历史喂进去。无需任何架构改动,靠的只是"给不同 token 喂不同的噪声强度"。
它在 WAM 谱系里的定位也因此清晰:它和 NovaFlow 同属"级联---像素---几何",但 NovaFlow 是白嫖 别人的视频模型,LV-P 是自建一个面向机器人规划的视频基座,并在训练机制(扩散强迫)和数据配方(人+机混合的百万级数据)上做了深度定制。
三、方法详解:从 14B 基座到机器人轨迹
3.1 骨架:基于 Wan 2.1 的 14B 扩散 Transformer
LV-P 以 Wan 2.1 的图生视频 14B 权重 为起点,做"继续预训练"。它本质是一个在潜空间 里工作的扩散 Transformer(DiT 变体),论文称之为 Diffusion Forcing Transformer。
为什么要在潜空间而不是像素空间工作?因为原始视频太"大"了,直接生成像素又慢又费显存。LV-P 用一个时序因果 3D VAE先把视频压缩:
- 压缩比是 8×8×4(空间各压 8 倍、时间压 4 倍),压成 16 通道的潜表示;
- 输入形状 1+T, 3, H, W 的视频,被编码成 1+⌈T/4⌉, 16, ⌈H/8⌉, ⌈H/8⌉ 的潜张量;
- 最终生成 3 秒、48 帧、16 fps 的视频,对应 49 帧的潜片段,分辨率 832×480。
这里"时序因果"很重要:它保证压缩时"当前帧只依赖过去、不偷看未来",这和扩散强迫的因果设定是配套的。
3.2 训练机制:扩散强迫的具体实现
这是全文的技术核心,拆开看其实很清爽:
- 历史片段长度:从 {0, 1, 2, ..., 6} 个潜帧里随机采样。也就是说训练时模型见过"完全没历史(从头生成)"到"有 6 个潜帧历史(续写)"的各种情况,所以推理时这两种能力都具备。
- 噪声策略 :历史片段有 50% 的概率被设成零噪声(当作完全确定的、干净的条件),另外 50% 的概率加一点中等噪声(这是为了让模型对"历史本身也可能有噪声/不完美"更鲁棒)。
- 逐帧独立噪声:未来片段的每一帧可以挂不同的噪声等级,给 DiT 的不同 token 喂不同的噪声嵌入即可。
- 架构精简 :相比原始 Wan 2.1,LV-P 去掉了它的 mask 通道和 guidance 通道------因为扩散强迫已经用"噪声等级"这一个机制统一表达了"哪些是条件、哪些要生成",那些额外通道就冗余了。
一句话:扩散强迫把"图生视频/视频生视频/不同条件长度"这些原本要分别处理的情况,统一成了"给每帧设一个噪声等级"这一件事。 优雅,且省掉了专门的交叉注意力条件模块。
3.3 推理:历史引导(History Guidance)
训练好之后怎么用?规划时,模型以"当前场景观测"为低噪历史、以任务文字为条件,去噪生成未来视频。
LV-P 在这里做了一个巧妙的扩展------历史引导(history guidance) 。我们熟悉的"无分类器引导(CFG)"是用来增强"文字条件"的影响力;LV-P 把同样的思想用到了帧级别 :在采样时,把"有历史条件"和"无历史条件"两种预测做差并放大,从而增强历史画面对生成结果的牵引力,让续写出来的视频和当前场景贴合得更紧。它最多支持 24 帧的上下文,并能通过**自回归式滚动(iterative rollout)**把多段视频接起来,完成多阶段长任务的规划。
3.4 数据配方:LVP-1M(140 万片段,人 + 机混合)
视频基座的能力,七分靠数据。LV-P 精心配了一个 140 万片段 的数据集 LVP-1M,把"机器人数据"和"人类视频"混在一起:
| 来源 | 类别 | 规模 |
|---|---|---|
| AgiBot-World | 机器人 | 863k |
| DROID | 机器人 | 192k |
| Language-Tables | 机器人 | 71k |
| Bridge | 机器人 | 25k |
| Panda-70M(过滤后) | 人类 | 196k |
| Something-Something | 人类 | 93k |
| Ego4D | 人类 | 39k |
| Epic-Kitchens | 人类 | 7k |
合计约 120 万机器人 + 40 万人类片段。配套有一套讲究的清洗流程:
- 时间对齐到"人的速度":不管原视频帧率多少,都归一化到约 3 秒,让人和机器人的动作"语速"统一。
- 质量过滤:用光流剔除相机大幅晃动的片段(去掉运动最剧烈的前 30%)、检查画面里能否看到操作主体、保留高质量专家轨迹。
- 动作中心的重新打标 :用 Gemini Flash 给每段视频生成 2--5 条侧重"运动而非静态外观"的描述(共约 410 万条标注),让文字条件更聚焦于"在做什么动作"。
训练规模上:继续预训练 6 万步、批大小 128、约 2000 亿 token,在 128 块 H100 上跑了约 14 天;之后还在 Ego4D / Epic-Kitchens / Panda 的"低相机运动"子集上微调 1 万步。
3.5 从想象视频到机器人动作:人手 4D 重建 + 重定向
模型想象出的是"人手在操作"的视频。怎么变成机器人指令?这一步是纯几何/优化,分几小步:
(1) 重建人手位姿 :用 HaMeR 逐帧从画面里恢复人手的 MANO 网格顶点和手腕朝向(一个 SO(3) 旋转)。
(2) 4D 对齐(解决单目尺度模糊) :单目重建有个老毛病------不知道手离相机多远的"绝对尺度",且容易漂移。LV-P 用 MegaSAM 估计深度图、相机内参和外参,把手腕像素按深度反投影到三维,再用因果 Savitzky-Golay 滤波做时间平滑。这样手的轨迹既有了真实尺度、又不抖。(消融显示,光用 HaMeR 会漂移,加上 MegaSAM 对齐后轨迹明显更稳。)
(3) 手指/夹爪重定向:
- 灵巧手:用 Dex-Retargeting,把人手关键点通过优化求解成机器人手的关节角;
- 平行夹爪:用 GraspNet 预测抓取位姿,并用"手部运动的启发式规则"判断"何时该闭合抓取"。
(4) 真机执行 :相机坐标系与机器人坐标系用一个固定旋转对齐;用 cuRobo 做逆运动学,从手腕位姿解出机械臂轨迹;最后以 15 Hz(Franka)或 5 Hz(G1 人形 + Inspire 手)同步控制手臂和手。
把这条"动作翻译"链路串起来:HaMeR 重建手 → MegaSAM 校准 4D 尺度 → Dex-Retargeting/GraspNet 定手指 → cuRobo 解逆运动学 → 真机执行。
核心公式与逻辑梳理
LV-P 的方法链条比一般"零训练"路线更深,但拆开看其实就五个清晰节拍:
- VAE 压缩:用时序因果 3D VAE 把 RGB 视频压到潜空间(8×8×4 压缩比),让扩散过程在小张量上跑。
- 加噪 :训练时给每一帧潜表示独立 采样一个噪声等级------历史帧给小(或零)噪声,未来帧给大噪声,这就是"扩散强迫(Diffusion Forcing)"。
- 去噪学习:14B Transformer 在文字与历史条件下学会"把噪声还原成干净潜帧"。
- 历史引导采样:推理时把"有历史"和"无历史"的预测做差并放大,让续写更贴现场。
- 几何提取:HaMeR 重建人手 → MegaSAM 校 4D 尺度 → 重定向到机器人 → cuRobo 解 IK 下发真机。
下面给出最能体现这套机制的几条式子。
(1) 扩散强迫的训练目标
LV-P 基于 Flow Matching 范式。先在干净潜表示 z0z_0z0 上独立采样每帧的噪声等级 ktk_tkt、构造加噪样本,再回归"前进方向":
zkt,t=(1−kt) z0,t+kt εt,εt∼N(0,I)z_{k_t,t} = (1-k_t)\,z_{0,t} + k_t\,\varepsilon_t, \quad \varepsilon_t \sim \mathcal{N}(0, I)zkt,t=(1−kt)z0,t+ktεt,εt∼N(0,I)
LDF(θ)=Ez0,ε,{kt}∑t=1T∥fθ(zkt,t,c,kt,t)−(εt−z0,t)∥22\mathcal{L}{\text{DF}}(\theta) = \mathbb{E}{z_0, \varepsilon, \{k_t\}}\bigg\\sum_{t=1}\^{T}\\Big\\\| f_\\theta\\big(z_{k_t,t}, c, k_t, t\\big) - (\\varepsilon_t - z_{0,t}) \\Big\\\|_{2}\^{2}\\biggLDF(θ)=Ez0,ε,{kt}t=1∑T fθ(zkt,t,c,kt,t)−(εt−z0,t) 22
符号说明 :z0,tz_{0,t}z0,t 是第 ttt 帧"干净"的潜表示;εt\varepsilon_tεt 是独立采样的标准高斯噪声;kt∈0,1k_t\in0,1kt∈0,1 是每帧独立 的噪声等级(历史帧 50% 概率被设为 kt=0k_t=0kt=0、其余采小值,未来帧采任意值);ccc 是文字条件嵌入;fθf_\thetafθ 是 DiT 网络;E\mathbb{E}E 是对所有随机量求期望。
这条式子在做什么 :普通的视频扩散对所有帧用同一个噪声等级 ------"过去"和"未来"一锅煮,要做"已知前几帧、续写后几帧"就得另外加结构。扩散强迫把噪声等级变成逐帧可调的参数 :历史帧 ktk_tkt 趋近 0(几乎干净,被当作条件),未来帧 ktk_tkt 偏大(需要从噪声里被生成)。同一套权重就此同时学会"图生视频(历史长度=0)""视频生视频(历史长度>0)"以及一切中间情况,架构上不需要 mask 通道、不需要专门的条件分支。这是 LV-P 最干净的技术贡献。
(2) 历史引导(帧级 CFG)
把无分类器引导从"文字条件"推广到"历史条件",采样时的得分函数写成:
s^(zk∣xhist,c)=s(zk∣∅,∅)+(1+whist)s(zk∣xhist,c)−s(zk∣∅,c)+wtexts(zk∣∅,c)−s(zk∣∅,∅)\hat{s}(z_k\mid x_{\text{hist}}, c) = s(z_k\mid \varnothing, \varnothing) + (1+w_{\text{hist}})\bigs(z_k\\mid x_{\\text{hist}}, c) - s(z_k\\mid \\varnothing, c)\\big + w_{\text{text}}\bigs(z_k\\mid \\varnothing, c) - s(z_k\\mid \\varnothing, \\varnothing)\\bigs^(zk∣xhist,c)=s(zk∣∅,∅)+(1+whist)s(zk∣xhist,c)−s(zk∣∅,c)+wtexts(zk∣∅,c)−s(zk∣∅,∅)
符号说明 :s(⋅)s(\cdot)s(⋅) 表示去噪网络在某种条件下给出的"分数"(梯度方向);xhistx_{\text{hist}}xhist 是已观察到的历史帧、ccc 是文字条件、∅\varnothing∅ 表示"丢弃此条件";whistw_{\text{hist}}whist、wtextw_{\text{text}}wtext 是两个引导强度。
这条式子在做什么 :把"有历史 vs. 无历史"和"有文字 vs. 无文字"两类对比拆成两个可独立放大的方向。whistw_{\text{hist}}whist 越大,模型生成的未来就被当前画面"拉得越紧",避免脑补到"另一个世界"。这正好对应"机器人滚动规划时希望续写紧贴现场"的实际需求。
(3) 4D 人手尺度对齐(MegaSAM + 因果平滑)
单目 HaMeR 给出的手腕只有"像素坐标 + 相对深度",存在尺度漂移。LV-P 先用 MegaSAM 估出每帧深度 dtd_tdt、相机内参 KKK 与外参 Ttw←cT_t^{w\leftarrow c}Ttw←c,把手腕像素 utu_tut 反投影到世界坐标,再做因果 Savitzky-Golay 平滑:
ptw=Ttw←c K−1 ut⊤, 1⊤⋅dt,p~tw=∑i=−w0βi⋅pt+iwp_t^{w} = T_t^{w\leftarrow c}\,K^{-1}\,\bigu_t\^\\top,\\,1\\big^\top \cdot d_t, \qquad \tilde{p}t^{w} = \sum{i=-w}^{0} \beta_i \cdot p_{t+i}^{w}ptw=Ttw←cK−1ut⊤,1⊤⋅dt,p~tw=i=−w∑0βi⋅pt+iw
符号说明 :utu_tut 是 HaMeR 输出的手腕像素坐标,K−1K^{-1}K−1 是相机内参的逆(用来把像素抬到归一化相机坐标),dtd_tdt 是该点的度量深度,Ttw←cT_t^{w\leftarrow c}Ttw←c 是从相机坐标系到世界坐标系的位姿变换;后一项里 βi\beta_iβi 是 Savitzky-Golay 滤波器系数(窗长 www,只看过去帧,所以叫"因果")。
这条式子在做什么:把"二维像素 + 单目深度"几何上正确地变成"世界坐标系里的米单位手腕轨迹",再用一个只看过去、不看未来的低阶多项式滤波抹掉抖动。这一步保证了下游用 Dex-Retargeting/cuRobo 解出来的机器人轨迹既物理合理、又时间平滑------也是消融实验里"光靠 HaMeR 会漂、加了 MegaSAM 才稳"的数学根源。
(4) 灵巧手重定向的优化目标
把人手关键点映射成机器人手关节角时,Dex-Retargeting 解一个最小二乘:
q∗=argminq ∑j∥ϕj(q)−p~jhuman∥2+λ ∥q−qref∥2s.t. qmin≤q≤qmaxq^{*} = \operatorname*{argmin}{q}\;\sum{j}\big\|\phi_j(q) - \tilde{p}j^{\text{human}}\big\|^{2} + \lambda\,\|q - q{\text{ref}}\|^{2} \quad \text{s.t.}\;q_{\min}\le q\le q_{\max}q∗=qargminj∑ ϕj(q)−p~jhuman 2+λ∥q−qref∥2s.t.qmin≤q≤qmax
符号说明 :qqq 是机器人手关节角向量;ϕj(q)\phi_j(q)ϕj(q) 是机器人手第 jjj 个对应点(指尖/指节)在 qqq 下的正向运动学位置;p~jhuman\tilde{p}j^{\text{human}}p~jhuman 是人手对应关键点(已对齐到机器人手坐标系);qrefq{\text{ref}}qref 是参考姿态(防止过度扭曲);λ\lambdaλ 平衡两项。
这条式子在做什么 :第一项要求"机器人手指尖落点尽量贴近人手指尖落点"------这是任务相关的拟合项;第二项是软约束,防止解出来的姿态怪异;硬约束 qmin≤q≤qmaxq_{\min}\le q\le q_{\max}qmin≤q≤qmax 强制不越关节限位。一个标准的约束最小二乘就完成了"人手 → Inspire 灵巧手"的本体跨越。这也解释了为什么平行夹爪任务普遍弱一些:人手有 20+ 个自由度,硬压到 1 个自由度的夹爪上,第一项的拟合误差天然就大。
四、实验怎么做·结果说明了什么
机器人本体 :覆盖两种差异极大的形态------Franka 机械臂(平行夹爪)和 G1 人形机器人(配 Inspire 灵巧手)。能同时驱动夹爪和灵巧手,本身就是对"视频基座 + 重定向"路线通用性的有力证明。
真机任务与结果(成功次数/试验次数):
- Franka + 平行夹爪:抓物体 5/10、把 A 放进 B 3/10、开抽屉 2/10、按按钮 4/10。
- G1 人形 + 灵巧手:擦桌子 8/10、扫球 5/5、按按钮 4/5、开盒子 2/10、开门 6/10、舀豆子 3/5、撕胶带 2/5。
与 VLA 基线的对比 最能说明问题:π0 在大多数夹爪任务上 0/10,OpenVLA 在所有平行夹爪任务上 0/10 ,而且这两个 VLA 基线根本不兼容灵巧手。LV-P 在多阶段、灵巧操作任务上的表现,把"视频主模态"路线相对"语言主模态 VLA"的优势摆了出来------尤其是在灵巧手这种 VLA 难以覆盖的本体上。
第三方"野外"评测(100 个由第三方挑选的任务)更见泛化力:
- 接触正确率:平均 87.3%,best@4 达 100%;
- 任务完成率:平均 59.3%,best@4 达 82%;
- 完美完成率:平均 44.0%,best@4 达 71%。
在最难的 Level 3 上,LV-P(39.3%/76%)显著超过直接用 Wan 2.1(39.3%/76% 处的对比项)、Cosmos-Predict 2(7.5%/24%)、Hunyuan(13.5%/42%)等通用视频模型------这说明针对机器人规划做继续预训练 + 扩散强迫 + 人机混合数据,确实让基座比"原始通用视频模型"更会"想象可执行的未来"。
五、亮点与为什么重要
- 范式上的旗帜 :明确主张"视频是机器人决策的主模态",而非把动作当语言模型的尾巴。这是对主流 VLA 路线的一次有力补充乃至挑战。
- 扩散强迫做条件统一 :用"逐帧独立噪声 + 因果掩码"这一个机制,不改架构就统一了图生视频与视频生视频、支持任意历史长度,还能自回归滚动做长程规划。这是本文最干净利落的技术贡献。
- 历史引导:把无分类器引导从"文字条件"推广到"帧级历史条件",让续写视频更贴合现场。
- 人机混合的百万级数据配方:用"时间对齐到人速 + 动作中心打标 + 相机运动过滤"把异构的机器人/人类视频揉到一起预训练,给社区提供了可借鉴的数据工程范式。
- 覆盖灵巧手:在 π0、OpenVLA 等 VLA 完全无法处理的灵巧手任务上跑出了成功率,拓宽了"视频→动作"路线的适用边界。
六、局限与未解
作者坦承几处短板:
- 速度:单张 A100 上生成一段视频要"好几分钟",离实时控制差得远。
- 开环不够用 :对灵巧操作这类需要实时纠错的任务,开环执行(想一次做到底)明显不足,需要闭环。
- 误差传导:人手重建和 4D 重建的误差会一路传到重定向,源头错了下游就跟着错。
- 夹爪迁移有损:把人手(多自由度)的运动压缩到平行夹爪(自由度少得多)上,本质是"有损压缩",信息丢失会拖累平行夹爪任务的成功率(这也解释了为什么夹爪任务的数字普遍不如部分灵巧手任务)。
七、在 WAM 谱系中的位置
LV-P 和上一篇的 NovaFlow 是"级联---像素---几何"路线里一对有趣的对照:
| NovaFlow(17) | LV-P(18) | |
|---|---|---|
| 视频模型 | 白嫖现成(Wan/Veo) | 自训 14B 基座 |
| 训练成本 | 零训练 | 128×H100 训 14 天 |
| 中间表征 | 物体 3D 流 | 人手 4D 轨迹 |
| 落地方式 | Kabsch/PhysTwin 解析+物理 | HaMeR+重定向+IK |
| 特色技术 | 校准的 3D 点流 | 扩散强迫 + 历史引导 |
可以看到,两者都用"想象视频 + 几何提取",但一个把宝押在"借力 + 表征设计",一个押在"自建基座 + 训练机制"。 LV-P 与系列里 LAPA、villa-X(学习潜在动作)、VPP(潜空间规划)等也有呼应------它们共同探索"如何让视频/潜空间的预测更好地服务下游控制"。
紧接着的 19 篇 Dream2Flow 会把"从生成视频提取 3D 物体流"这件事推向更开放的世界、更多物体类型;而 20 篇 4DGen 则更激进------干脆让世界模型直接生成自带几何的"4D 视频",省掉后处理估深度这一步。三篇连起来读,正好看清"级联---像素---几何"这一支在 2025 年的多线演进。
八、参考
- 论文:Large Video Planner Enables Generalizable Robot Control
- 机构:哈佛大学 Kempner Institute 等
- 年份:2025(arXiv 预印本)
- arXiv:https://arxiv.org/abs/2512.15840
注:本文为基于该论文公开信息的学习性解读,方法、数据与数字以原论文为准;个别成功率为论文所报数值,精确数据请查阅原文。