前面文章中,我们提到 ES因操作系统内存不足而被OOM的故事,但OS本身并没有那么简单粗暴,在OOM之前,其实它还动用了很多方法。
https://blog.csdn.net/Hehuyi_In/article/details/161494113?spm=1001.2014.3001.5501
在这篇文章中我们会继续学习------OOM的实质是"内核穷尽所有手段,仍无法凑齐申请方需要的内存量"。
一、 整体概览
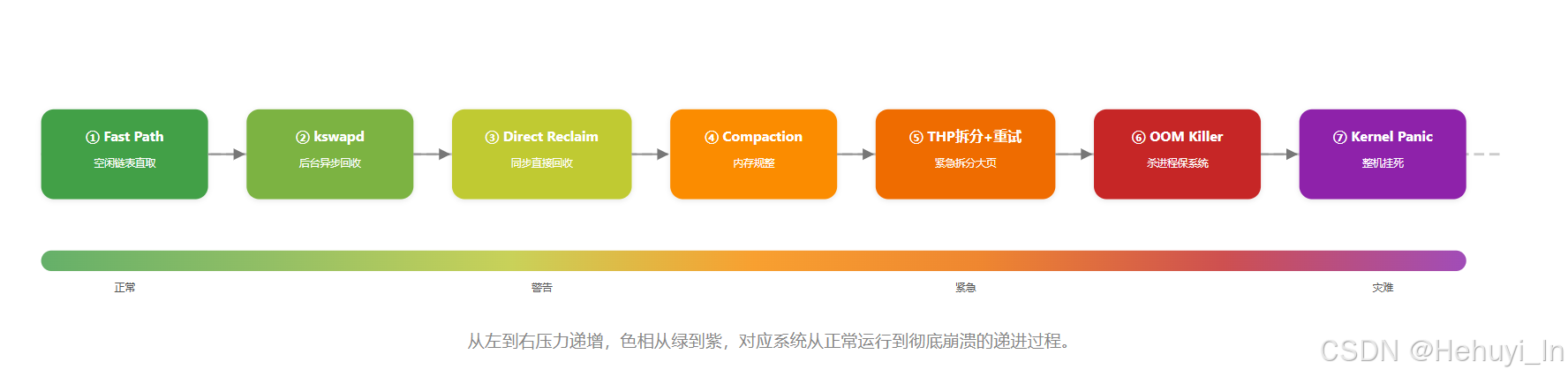
1. 七层防线
从进程申请内存,到最极端的整机挂死,实际上Linux是七层递进防线:
内存申请 → 快速路径 → 异步回收 → 直接回收 → 碎片规整 → 大页拆分 → 杀进程 → 系统崩溃
运维的核心任务是让系统永远不要走到最后三层,理解每一层的"为什么"和"不做什么",才能真正驾驭生产环境的内存行为。
2. 预备知识:内存水位线(Watermark)
究竟Linux如何判断内存够与不够,什么时候应该用哪种方式回收?基于Watermark
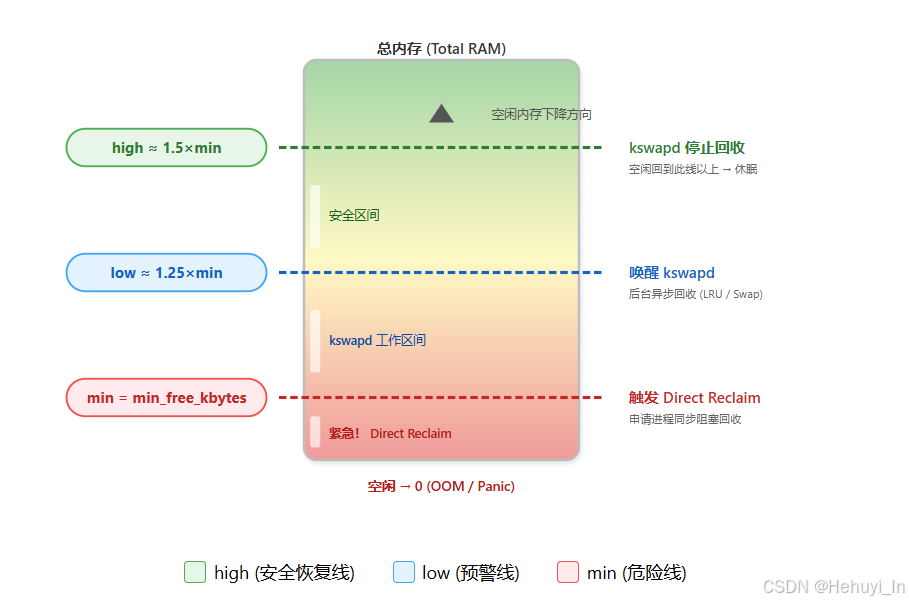
每个内存 Zone 有三条水位线:
• min = min_free_kbytes (内核参数,可通过 sysctl vm.min_free_kbytes 查看/设置)
• low ≈ 1.25 × min (即 5/4 倍,由 watermark_scale_factor 微调)
• high ≈ 1.5 × min(即 3/2 倍,用于 kswapd 休眠恢复线)
行为总结:
- 空闲低于
low→ 唤醒 kswapd 异步回收 - 低于
min→ 进程同步阻塞进行 Direct Reclaim
因此你应该可以想到,min_free_kbytes设置太大太小都是有问题的:
- 太大:内核天天觉得自己内存不足,有事没事触发回收,浪费可用内存的同时增加了系统负担
- 太小:意识到该回收已经来不及,kswapd来不及工作就触发了直接回收,甚至触发OOM
好的下面我们正式来看每一步是做什么的
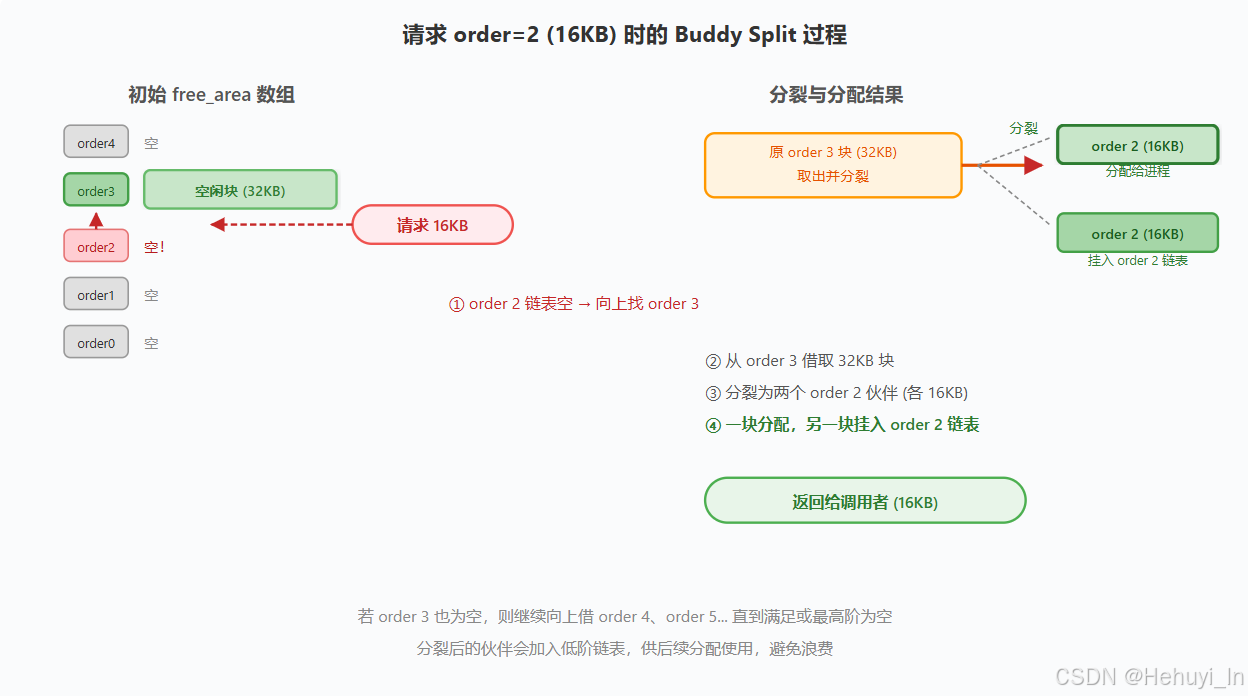
二、 Fast Path --- 空闲链表直取
触发条件: 空闲内存高于low水位线,且Buddy System有空闲页,即可直接摘取。
核心机制: 在目标 free_area[order] 链表摘取一个连续页块,若无则向更高 order 借一大块并分裂(buddy split),一半分配,一半挂入低阶链表。时间复杂度 O(1),延迟 ~100ns。
cat /proc/buddyinfo Node 0, zone DMA 1 1 1 1 1 1 1 1 1 2 2 Node 0, zone DMA32 5528 3979 3210 1625 1111 678 225 132 29 12 1 Node 0, zone Normal 10388 5540 2822 2098 1509 681 356 172 78 28 10
**用户感知:**此路径无任何卡顿。若系统始终走 Fast Path,说明内存充裕,应用响应稳定。
三、 kswapd --- 后台异步回收
异步回收不阻塞申请进程,它的存在将内存回收压力从进程直接回收转移到了后台,是 Linux 内存管理的第一道防线。
触发条件: 空闲内存降至 low 水位以下。
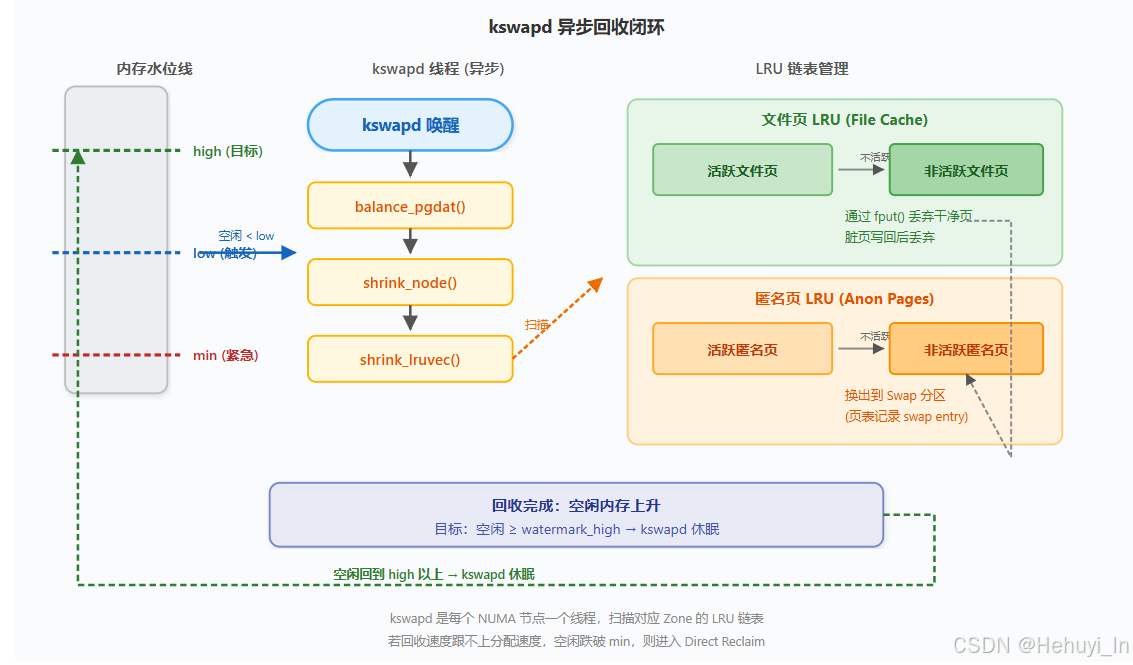
核心机制:
① 触发: 空闲内存降至 low 水位以下,内核唤醒 kswapd 守护线程(每个 Zone 一个)。
② 扫描: kswapd 调用 balance_pgdat() → shrink_node() → shrink_lruvec(),依次扫描文件页和匿名页的 LRU 链表。
③ 回收: 对于非活跃文件页,直接丢弃(干净页)或写回后丢弃;对于非活跃匿名页,换出到 Swap 分区。
④ 目标: 回收直到空闲内存恢复到 high 水位以上,kswapd 自动休眠。
**用户感知:**正常情况下用户无感。但如果 kswapd 长期 100% CPU,说明内存压力持续,应用可能会观察到分配延迟增加。
查看 kswapd 活动
top -H -p $(pgrep -f kswapd)
监控扫描与回收
grep -E "pgscan|pgsteal" /proc/vmstat
相关参数:
vm.swappiness 控制回收匿名页的倾向。
- 0或1:数据库建议调低至 1,尽可能回收文件缓存
- 60:默认,平衡值
- 100:优先回收匿名页(内存不足时多swap)
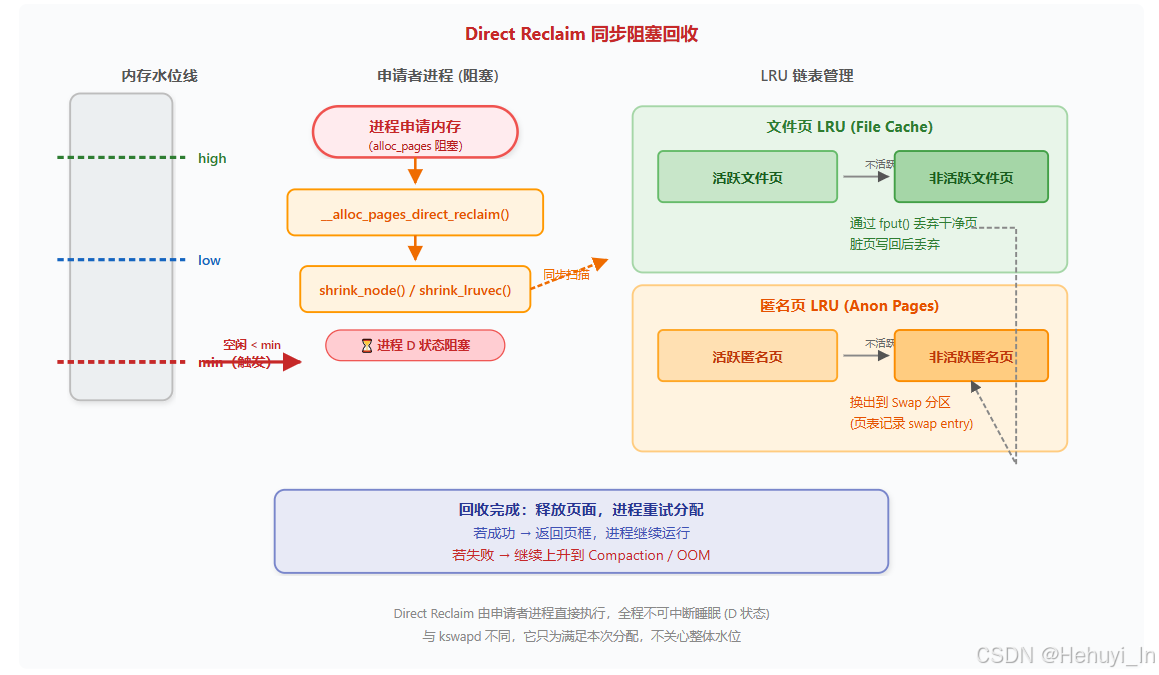
四、 Direct Reclaim --- 同步直接回收
申请进程被迫亲自执行回收(所谓"直接"),Direct Reclaim 是同步 且阻塞的,是系统性能急剧下降的起点。其哲学是"谁需要谁回收",避免死锁和优先级反转,代价是当前进程的响应延迟。
触发条件: 空闲内存跌破 min 水位,kswapd 来不及回收。
核心机制:
① 触发: 空闲内存跌破 min 水位,kswapd 来不及回收,申请进程直接调用 __alloc_pages_direct_reclaim()。
② 执行: 进程亲自扫描 LRU 链表,回收文件页(丢弃干净页或写回脏页)和匿名页(换出到 Swap)。
③ 阻塞: 整个回收过程同步进行,进程处于 D 状态,延迟可达毫秒到秒级。
④ **结果:**回收完成后重试分配,若成功则返回页框继续运行;若失败则继续上升到 Compaction、THP 拆分或 OOM Killer。与 kswapd 不同,它只为满足自己需求分配,不关心整体水位。
用户感知: 进程处于 D 状态,应用请求延迟飙升,从毫秒到秒级不等,是性能急剧下降的起点。
如何观察 grep allocstall /proc/vmstat # 查看 Direct Reclaim 停滞次数 sar -B 1 10 # 观察直接回收扫描(pgscand)
加大 vm.min_free_kbytes 可有效减少 Direct Reclaim,但会牺牲一部分可用内存(留作应急)。
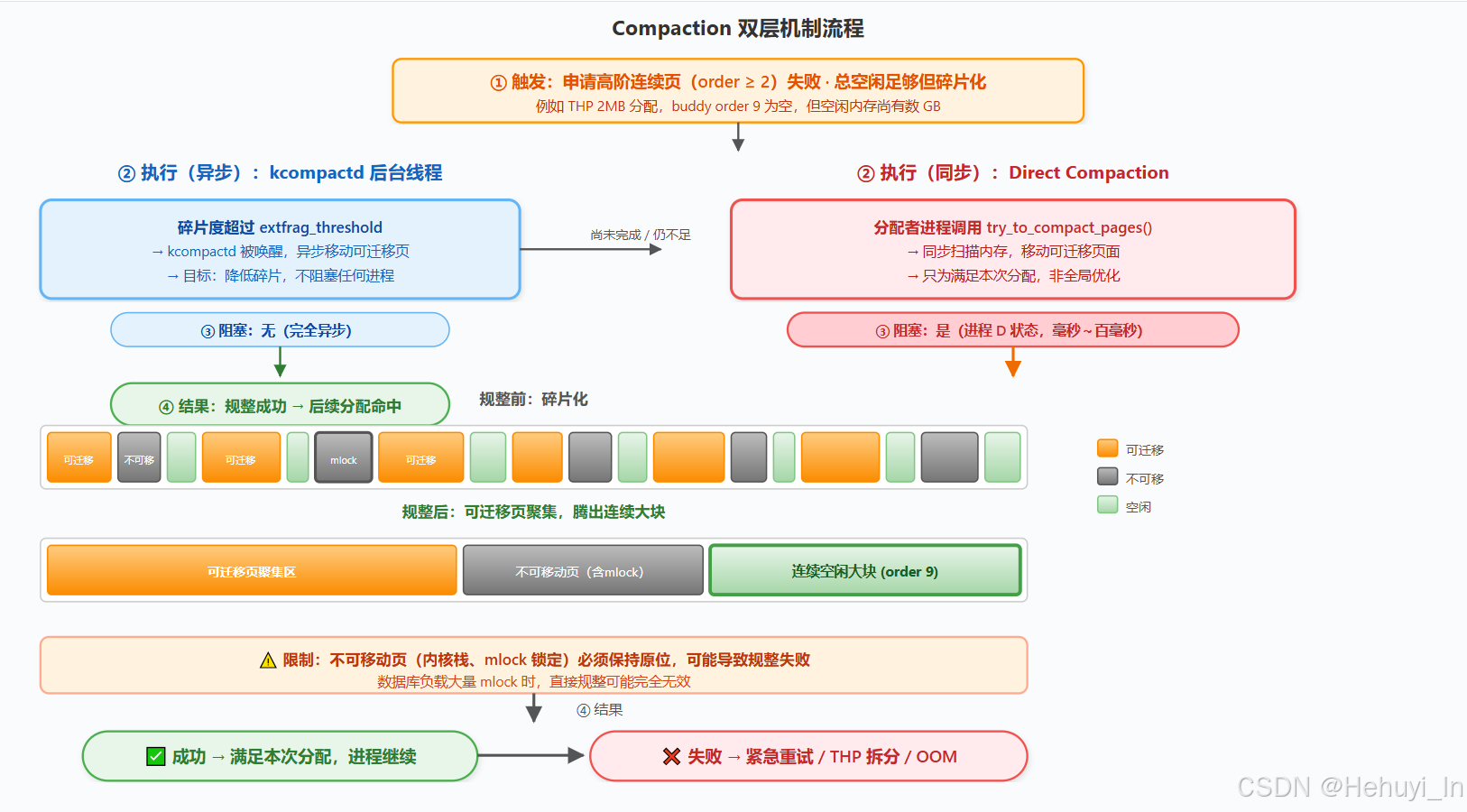
五、 Compaction --- 内存规整
Compaction 是内核应对物理内存外部碎片的主要手段,通过移动可迁移页面来创造连续空间,本质是用 CPU 时间换取内存连续性。不可移动页(内核栈、mlock)是规整失败的主因。
类似内存回收,它也分为异步规整和直接规整,一旦触发直接规整,同样阻塞申请进程。
数据库中大量 mlock 的共享内存可能导致规整无效,此时应关闭透明大页或使用大页。
1. 异步规整**(kcompactd)**
① 触发: 内核线程定期检查内存碎片度,当碎片指数超过 extfrag_threshold 时自动唤醒。
② 执行: 扫描内存区域,将可迁移页面(匿名页、文件缓存)向一端移动,腾出连续空闲区域,目标是将碎片降到阈值以下。
③ 阻塞: 完全异步执行,不阻塞任何应用进程,类似 kswapd。
④ **结果:**成功则全局碎片水平下降,后续高阶分配命中率提升;未能形成足够连续块时,仍需直接规整兜底。
2. 直接规整(Direct Compaction):
① 触发: 进程急需高阶连续页,且后台规整未完成或不足以形成连续块。
② 执行: 进程在分配路径上调用 try_to_compact_pages(),申请进程亲自扫描并移动可迁移页面,只为满足本次分配。
③ 阻塞: 进程进入D 状态,直至规整完成或失败,延迟通常毫秒~百毫秒级别。
④ **结果:**成功则获得连续大块,进程继续运行;失败则进入下一步------THP 拆分或 OOM Killer。
**用户感知:**与内存异步、同步回收类似,但相对而言,规整比回收较轻量级。
相关命令 echo 1 > /proc/sys/vm/compact_memory # 手动触发规整 grep compact /proc/vmstat # 查看成功率
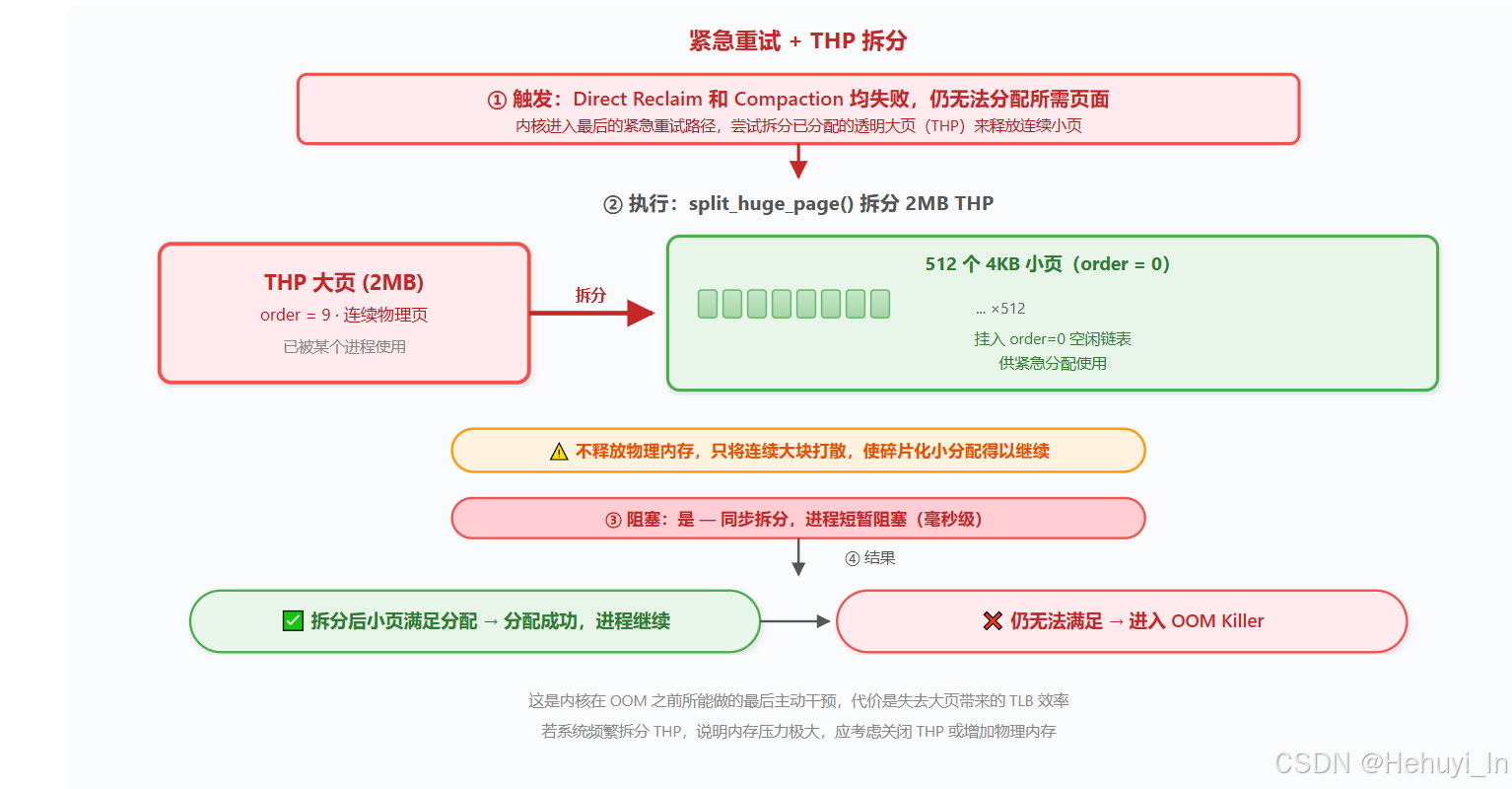
六、 最后的挣扎 ------ THP 拆分
THP 拆分并不释放物理内存,只是自动将连续大块打散成小页(即所谓的透明,不需要用户来操作拆分)。这样做虽能解燃眉之急,但会永久失去该大页的效率优势,属于内核在 OOM 前最后的挣扎。若系统频繁触发 THP 拆分,说明内存碎片化严重且压力极大,应考虑关闭 THP 或增加物理内存。
实际上为了避免这步,传统数据库一般都关闭透明大页,早死早超生,作为了解即可。
① 触发: 当直接回收及规整均无法满足本次分配时,内核进入紧急重试路径,检查是否存在已分配的透明大页(THP)可以拆分。
② 执行: 如有,内核调用 split_huge_page(),将一个 2MB 的透明大页分裂为 512 个独立的 4KB 小页,这些小页被挂入 Buddy System 的 order=0 空闲链表。
③ 阻塞: 拆分过程是同步的,申请者进程会短暂阻塞(通常毫秒级),等待拆分完成。
④ **结果:**若拆分后的小页能满足本次分配,则分配成功;否则,内核将不得不进入 OOM Killer 选择牺牲进程。
相关命令
查看拆分次数
grep thp_split /proc/vmstat
若持续发生,评估是否关闭 THP
echo never > /sys/kernel/mm/transparent_hugepage/enabled
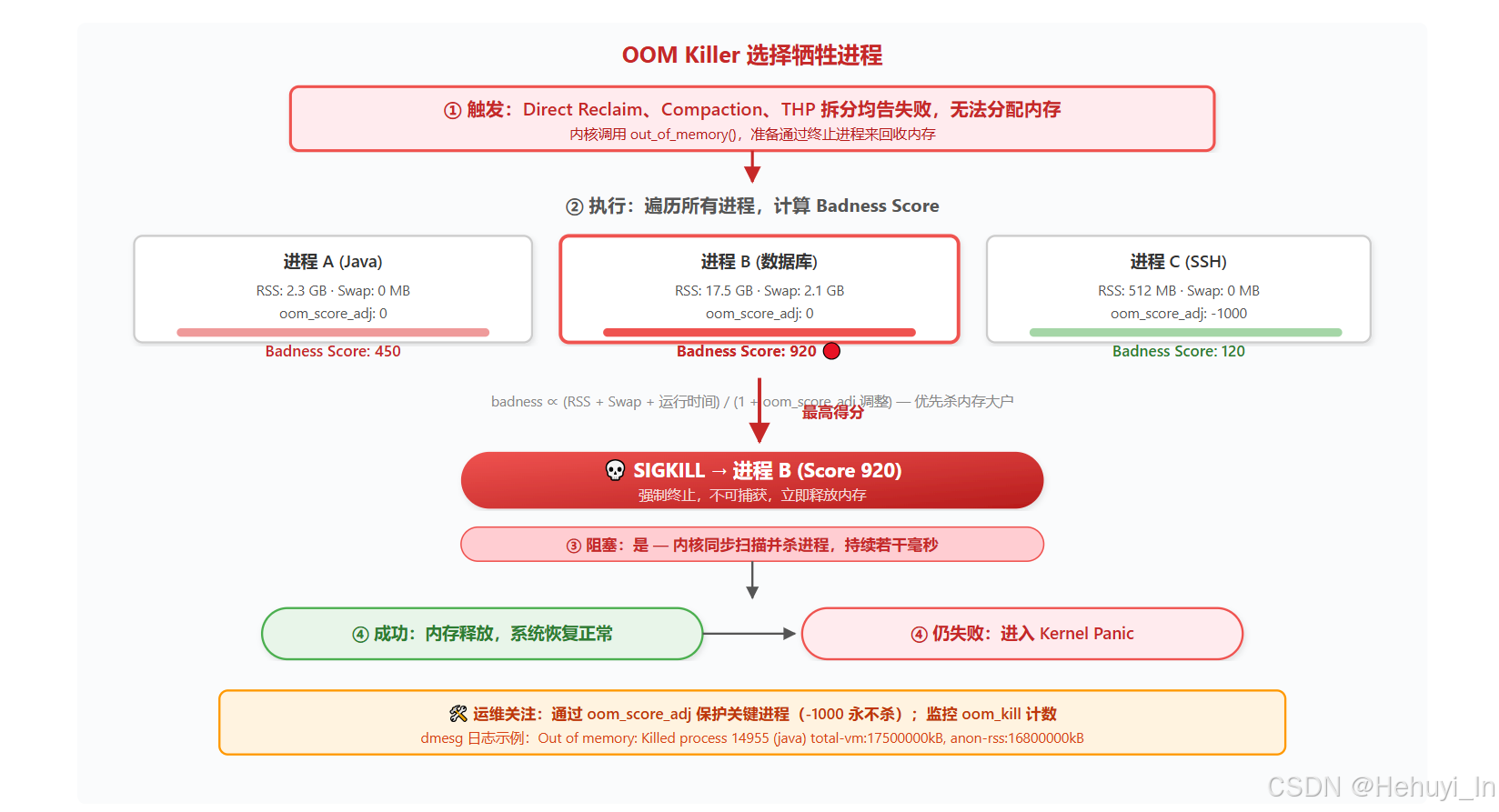
七、 拿得多死得快 ------ OOM Killer
OOM Killer 是内核的终极手段,遵循"拿得多死得快"原则------RSS 越大、Swap 使用越多,被选中的概率越高。通过 /proc/[pid]/oom_score_adj(范围 -1000 到 1000)可人为调整进程被杀优先级,为关键服务设置负值保护。OOM 并非总内存不足的证明,而是内核穷尽所有手段后仍然凑不齐所需页面的无奈之举。
① 触发: 所有回收手段(kswapd、Direct Reclaim、Compaction、THP 拆分)均无法满足本次分配,内核调用 out_of_memory()。
② 执行: 内核遍历所有进程,计算每个进程的 Badness Score ,综合考虑 RSS、Swap 占用、运行时长、oom_score_adj 等因素。得分最高者被选中。
③ 阻塞: OOM Killer 过程同步执行,当前申请者进程会阻塞,直到选中进程被杀死并释放内存。
④ **结果:**成功释放内存后,系统恢复运行;若仍无法满足分配,则进入 Kernel Panic。
**用户感知:**被选中的进程突然消失,服务中断。系统日志会打印详细报告,包括被杀进程的 PID、RSS、评分等。
相关参数
查看 OOM 历史
dmesg | grep -i "out of memory"
保护关键进程(永不杀)
echo -1000 > /proc/PID/oom_score_adj
可以配置
vm.panic_on_oom=0避免 OOM 时直接崩溃。
八、 无可救药 ------ Kernel Panic
Kernel Panic 是 Linux 最后的防线,遵循"数据一致性优先于可用性"的原则------宁可挂死也不可带病运行导致数据损坏。
① 触发: OOM Killer 执行后仍无法满足内存分配,或内核内存管理子系统自身出现严重异常(如内核内存泄漏、slab 耗尽、关键数据结构损坏)。
② 执行: 内核调用 panic() 函数,停止所有 CPU,在控制台和日志中打印崩溃信息(包含寄存器、栈回溯),然后进入无限循环等待硬件重启。
③ 阻塞: 系统完全挂死,不再处理任何中断或请求,所有服务不可用。
④ 结果: 若配置了 kernel.panic=30,系统在 30 秒后自动重启;若有硬件 watchdog,也可触发强制重启,否则只能手动断电。

**用户感知:**整机完全不可用,所有服务中断。这是最极端的场景。
建议配置
kernel.panic自动重启和kdump收集崩溃转储,以便事后分析根因。panic 后自动重启
sysctl kernel.panic=30
永久生效
echo "kernel.panic=30" >> /etc/sysctl.conf
九、灵魂拷问:内核设计者的抉择
1. 为什么内核宁愿kill进程甚至整机挂死,也不拒绝内存分配?
简单说:不是内核"不想拒绝",而是内核"无法安全地拒绝",同时"拒绝的代价比杀进程更大"。
① 时序错位:malloc 的承诺与物理页的延迟
用户程序调用
malloc()申请的是虚拟地址空间 ,不是物理内存。只有当 CPU 首次写入这块虚拟地址时,才会触发缺页中断 ,内核此时才调用alloc_pages()分配物理页。这意味着:从
malloc返回成功到真正分配物理内存之间,存在巨大的时间窗口。当缺页发生时,内核已经无法向调用者返回 NULL 了------因为调用者根本没有在等待一个返回值,它只是在执行一条普通的mov指令。内核如果此时选择"拒绝",唯一能做的事情是向当前进程发送 SIGSEGV(段错误),这会导致进程非预期崩溃,而且完全没有上下文来优雅处理。
② 用户程序不会检查 NULL
即便内核想办法让
malloc返回 NULL(比如关闭 overcommit,设置vm.overcommit_memory=2),绝大多数应用程序也不会检查malloc的返回值 。从几十年的软件工程实践来看,程序员普遍假设小内存分配不会失败,或者检查失败后只会调用abort()。与其让进程带着未初始化的指针继续运行,最终在某处产生更难排查的崩溃、数据损坏或安全漏洞,不如让内核主动选择一个进程,干净利落地杀掉。OOM Killer 的日志至少能告诉你谁被杀、为什么,而随机的段错误则几乎没有可追溯性。
③ 乐观分配与兜底惩罚的设计哲学
Linux 内核采用的是**"乐观分配 + 兜底惩罚"**策略,背后是两种效率权衡:
乐观分配(overcommit):允许进程申请远超物理内存容量的虚拟内存。这在现实中是合理的------大部分进程申请的堆内存并不会完全使用,fork 出的子进程大多立即 exec。乐观分配让系统可以运行更多进程、更充分地利用内存,避免了宝贵的物理内存闲置。
兜底惩罚(OOM Killer) :当乐观分配玩脱了,物理内存真的耗尽时,内核不会默默"降级"为返回 NULL,而是主动介入,选择一个最占内存的进程终止。这是一种**"牺牲个体,保存整体"**的降级策略,比起让整个系统随机的进程崩溃,杀伤范围更可控。
更进一步,如果 OOM Killer 也无法挽回(比如内核自身内存泄漏,或所有用户进程都是关键进程无法杀死),内核选择 Panic 挂死,遵循的是**"数据一致性优先于可用性"**的原则:宁可停机,也不能让一个已经内存紊乱的系统继续写入磁盘、产生不可逆的数据损坏。
2. 为什么 min_free_kbytes 用绝对值而不用比例?
是为了在小内存和大内存系统上都能有可预测的底线行为;内核后续引入 watermark_scale_factor 作为比例补充,让管理员可以在绝对值基础上灵活调节回收灵敏度,而不是彻底推翻绝对值体系。
① 直接原因:历史惯性与行为可预测性
Linux 内核的
min_free_kbytes从最初实现时就采用了绝对值(KB 为单位),原因很朴素:
早期内存很小:2.4/2.6 早期时代,服务器内存通常是 512MB~4GB。绝对值(如 16MB、32MB)直观且够用,不需要比例。
绝对值行为稳定 :如果改成比例(如"总内存的 1%"),那么同一个系统在热插拔内存或内存容量变化时,
min_free_kbytes会随之改变,可能导致不可预期的行为波动。绝对值一旦设定,管理员心里有数,不会因为内存变化而"悄悄"改变系统的回收行为。紧急预留的性质决定 :
min_free_kbytes的本质是"为极端紧急情况预留的最后一道物理内存防线"。这道防线的宽度取决于系统需要处理的最坏情况------例如同时多个进程触发 Direct Reclaim 时,需要多少原子操作内存------而不是总内存的百分比。
② 绝对值的问题:大内存机器反而预留不足
绝对值的设计在小内存时代没问题,但在大内存时代暴露了缺陷。
内核的默认计算公式大致为:
min_free_kbytes ≈ sqrt(总内存) × 16(实际更复杂,与 Zone 数量和内存位宽有关)。这意味着:
总内存 默认 min_free_kbytes 占总内存比例 4 GB ~88 MB ~2.2% 16 GB ~176 MB ~1.1% 64 GB ~352 MB ~0.55% 256 GB ~704 MB ~0.28% 1 TB ~1408 MB ~0.14% 内存越大,
min_free_kbytes占比反而越小。 这是根函数(sqrt)的特性导致的。对于 256GB 甚至 1TB 的大内存机器,几百 MB 的紧急预留是远远不够的。一旦内存碎片化或突发大量分配,这点预留很快被击穿,Direct Reclaim 和 OOM 频繁发生。这就是为什么很多运维会在高内存服务器上手动调大
min_free_kbytes到数 GB。
③ 内核的补救:watermark_scale_factor
内核开发者早就意识到绝对值不够灵活,因此在 4.6 版本(2016 年)引入了
watermark_scale_factor参数(默认值 10,范围 10~1000,对应 0.1%~10% 的比例因子)。它在min_free_kbytes的绝对值基础上,按比例拉宽 low 和 high 水位线之间的距离。公式如下:
low = min + (max - min) × watermark_scale_factor / 10000 high = min + (max - min) × watermark_scale_factor × 2 / 10000其中
max是 Zone 的总内存。也就是说,watermark_scale_factor越大,三条线之间的距离越远:
kswapd 唤醒更早(low 离 min 更远),有更多时间在后台回收;
但可用内存也会略微减少。
最终,内核选择了**"绝对值基准 + 比例因子微调"** 的混合方案:
min_free_kbytes作为绝对底线,watermark_scale_factor作为灵敏度调节旋钮。
3. 为什么 Direct Reclaim 让申请方"亲自下场",而不排队等 kswapd?
异步回收可能来不及,且可能存在死锁或优先级反转风险。让申请者自己回收是同步保证分配成功的最直接方式。
① kswapd 不可靠:异步回收无法提供确定性保证
kswapd是一个后台内核线程,它的行为是尽力而为的:
回收速度不确定:kswapd 的扫描和回收速度受限于 CPU 调度、磁盘 I/O 和 LRU 链表的长度。当系统突发大量内存申请时(例如多个进程同时启动或批量数据加载),kswapd 的回收速度可能远远跟不上分配需求。
没有强保证 :kswapd 的目标是让空闲内存恢复到
watermark_high,但它并不承诺某一次具体的分配一定成功。如果把所有希望都寄托在 kswapd 上,就相当于将"是否能分配成功"变成了一件随机事件。因此,内核不能假设 kswapd 总能准时交付内存。必须有一个同步的兜底机制来保证分配最终能够成功。
② 死锁风险:回收路径本身也需要内存
这是最关键的技术原因。内存回收过程(无论是 kswapd 还是 Direct Reclaim)在执行时,内核自身可能需要分配一些临时内存 ,如果所有内存分配都依赖 kswapd 来回收,而 kswapd 在回收过程中又需要分配内存,那么一旦 kswapd 卡在这些临时分配上,就形成了**"等自己回收"**的死锁。
Linux 的解法是:让申请者进程在 Direct Reclaim 路径上亲自执行回收。这样,当前进程可以一边回收、一边满足自己的临时内存需求。即使回收过程需要分配一些内存,这些分配也可以由当前进程自己完成(继续递归回收),从而打破死锁循环。
③ 避免全局拥塞和优先级反转
如果所有内存申请都在
kswapd上排队,会导致:
全局同步瓶颈:所有分配者都必须等待同一个(或少数几个)后台线程,系统吞吐量会急剧下降,尤其是在多核系统上。
优先级反转:一个低优先级的进程可能因为少量内存需求而阻塞高优先级进程,因为都在等待 kswapd 回收。而 Direct Reclaim 让高优先级进程可以直接执行回收并立即获得内存,避免了无关的低优先级进程影响关键任务。
时间不可控:进程无法预测 kswapd 何时完成工作,对于需要低延迟响应的应用(如数据库、交易系统)来说,这种不确定性是不可接受的。
Direct Reclaim 的本质是**"谁要谁回收"**,相当于将回收工作分布式地交给各个申请者并行完成,既能充分利用多核,又能让急需内存的进程得到更快的响应。
十、速查表
| 步骤 | 机制 | 触发条件 | 阻塞 | 延迟 | 关键监控指标 |
|---|---|---|---|---|---|
| ① Fast Path | Buddy System | 空闲充足 | 否 | ~100ns | /proc/buddyinfo |
| ② kswapd | 异步 LRU 回收 | 空闲 < low | 否 | ms~s | pgscan_kswapd |
| ③ Direct Reclaim | 同步直接回收 | 空闲 < min | 是 | ms~s | allocstall |
| ④ Compaction | 内存规整 | 需连续大块 | 可能 | ms~百ms | compact_stall |
| ⑤ THP拆分 | 拆分大页 | 多次重试失败 | 是 | ms | thp_split_page |
| ⑥ OOM Killer | 杀进程 | 所有回收失败 | 是 | s级 | oom_kill 计数 |
| ⑦ Panic | 系统崩溃 | OOM后仍失败 | - | ∞ | kdump |