AI时代下,如何做原子代码拆分
在AI时代的冲击下,我们生成代码速度上升,加速了我们软件演化的进程。AI不会根据公司的当前阶段选择合适的架构,也不会随着公司的成长调整合适的架构。AI想彻底成为或者取代一个软件架构师从目前来看几乎是不可能的。 而且在一些雇佣不起架构师的小公司,因为生成代码速度上升,整个公司也不进行AI代码生成的监测,所以如果我们不关注我们项目的架构,我们的代码会变成"上帝代码"!随后在效率提升的表面,员工加班给AI擦屁股,最后公司破产! 如果你觉得,我说的这些未来AI都可以解决,那我们拭目以待,除非AI真的不是基于概率推理,而是拥有自己的思想!
什么是好代码
看过Clean Architecture的都知道,便于扩展、便于修改、便于维护、任务边界明确的代码才是好代码。 我们举例子来说明这个问题。
后端
后端一般是如下架构
- controller 请求相关
- service 服务相关
- dao 数据库 相关
如下图:
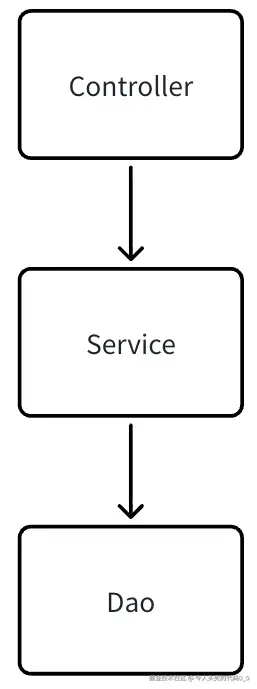 图1.1
图1.1
有没有后端的同学想过为什么是这个架构,读到这里,可以先闭上眼睛想一想。
好了,我来讲一下为什么这个做,我也只是讲一讲自己的理解,有什么不足还请大家指出。
首先我们来观察一下图1.1,想一想每次迭代需求 哪些是频繁变更的?哪些是不频繁变更的? 如果是新需求那基本上是完全新增。 如果是修改已有需求则service变更、修改数据库则dao变更。 如果直接依赖的话,controller变更谁都不会影响,service 变更影响controller,dao变更影响service、controller. 所以进行如下优化!
查看如下图:
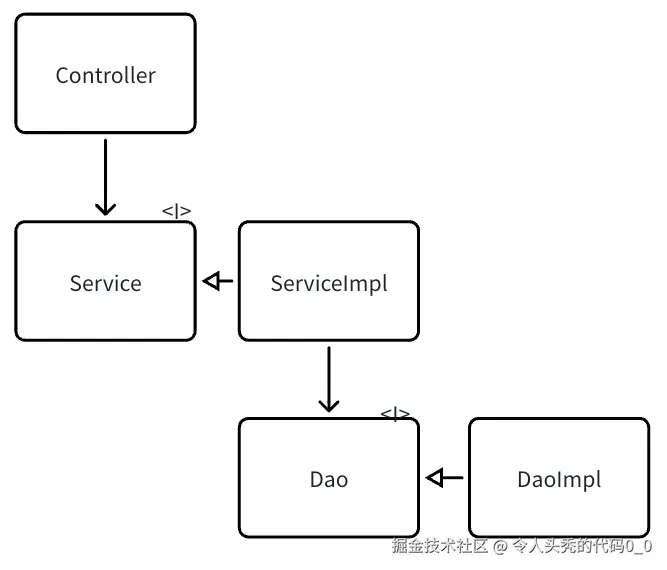
我们称后端的某一个业务逻辑的controller、service、dao为一个业务的原子代码,包括对controller、service、dao测试相关的代码。 测试驱动开发中、测试相关的代码可以使用AI去写。当然你也可以全部让AI写这个原子代码。
因为controller不频繁变更,却指向频繁变更的service会导致修改service,controller也需要频繁修改。所以需要一个稳定的接口层解耦。 当然如何设计接口层也是有一定难度的。 而dao也有可能随着业务的变更而变更,比如文本文件升级为mysql,mysql升级为oracle 我们使用依赖倒置原则将其进行解耦。 变更需求时controller变更谁都不会影响,service 变更不会影响controller,dao变更不会影响service、controller. 只需要修改对应实现,其他组件不需要修改,可插拔
还有一个优点:
- 代码复用
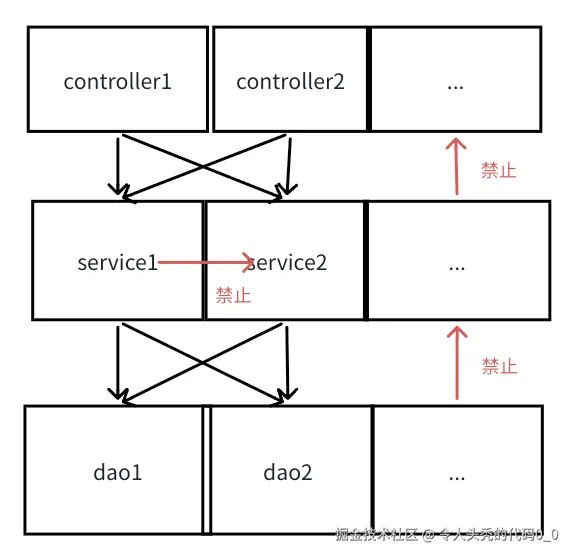
不同controller可以复用相同service,相同controller可以复用不同service,不同service可以复用相同dao,相同service可以复用不同dao,提高代码复用性。 只能是controller->service->dao. 但是每层的service是不可以互相引用的。改动一个service,其他的service不受影响 不可盲目复用,如果需求变更频率不一致,需要将复用的service、dao进行拆分。
前端
我们以react native为例进行分析,写react的同学看过来,到底前端有没有类似的架构,赶紧思考一下。 这考验你对于react的理解,理解完成react之后,你才能总结出有利于react的Clean Architecture. 前端在AI的冲击下,让我们减少了对前端的思考。什么样的Clean Architecture适合react呢?快想,想10分钟,想不出来否则你真的会被AI替代:)
前端响应式编程,什么样的代码是bad?什么样的代码是good?
我们先来分析一下
ts
function HelloWorld() {
const [count, setCount] = useState(0)
const handlePress1: () => void = () => {
setCount(count + 1)
}
const handlePress2: () => void = () => {
setCount(c => c + 1)
}
return (
<>
<Text onPress={handlePress1}>Hello, World! count: {count}</Text>
</>
)
}handlePress1是一个闭包函数,会将count拷贝一份放在handlePress1函数内部,然后使用快照的值+1更新count handlePress2是一个函数式更新,c的值是最新的state的值。 这些handle函数之间去操作state,这个操作看似正确、简单,实则降低了代码的可维护性。 在简单场景,我们尚且感觉能够hold住,但在复杂业务场景这些都是十分麻烦的,使得组件变成了上帝组件,赚的钱够植解决上帝组件掉的头发么:)。 查看如下图所示:
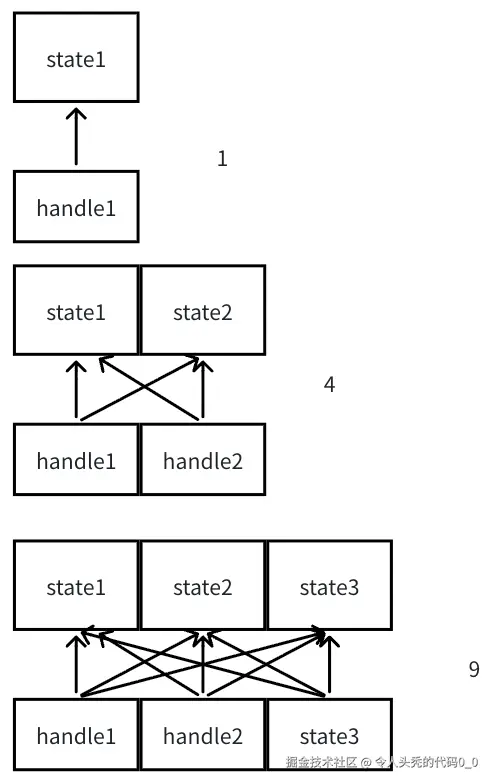
状态和ui刷新是相关的,状态越多、handle越多ui刷新次数越多,这个可以指数级别的增长! 随着业务的增加与业务的复杂度上升,状态控制变得非常棘手,难以维护。感受过这个恐惧的前端同学,请评论出来诉苦:) 而且还有state的两种写法闭包更新和函数式更新,导致变得更加复杂。
而且因为状态的复杂性,导致这个组件的复用性为0,因为它状态之间的耦合性严重,而且变得非常脆弱,改动一点点代码,必然会引出bug。
为了解决这个问题,我们需要限制状态的更新。为此我想了一个架构,是否经得住考验还有待大佬们商榷。如下图所示:
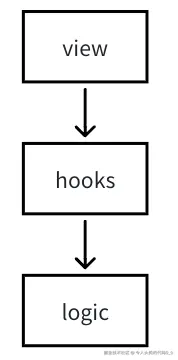
view: 里面没有任何handle逻辑,只有props
hooks: 是自定义hooks, 里面没有任何逻辑
logic: 所有无状态逻辑都被封装在这里,即将原来的所有handle函数放在这里,必须要有两个要求:
- 每个函数都是纯函数
- 状态无关,纯逻辑
- 逻辑函数之间无调用依赖关系
我以一个例子来说明:
counterLogic.ts
ts
export const INITIAL_COUNT = 0;
export const MIN_COUNT = 0;
/**
* @author zsh
* @param count count
* @returns the incremented count
*/
export function increment(count: number): number {
return count + 1;
}
/**
* @author zsh
* @param count count
* @returns the decremented count
*/
export function decrement(count: number): number {
return Math.max(MIN_COUNT, count - 1);
}
/**
* @author zsh
* @returns the reset count
*/
export function reset(): number {
return INITIAL_COUNT;
}
/**
* @author zsh
* @param count count
* @returns true if the count is even, false otherwise
*/
export function isEven(count: number): boolean {
return count % 2 === 0;
}每一个函数都必须是纯函数,react 自身也是如此要求的。
useCounter.ts
自定义hooks必须以use开头。
ts
import { useCallback, useState } from 'react';
import {
INITIAL_COUNT,
decrement,
increment,
reset,
} from './counterLogic';
export type CounterApi = {
count: number;
increment: () => void;
decrement: () => void;
reset: () => void;
};
export function useCounter(initial: number = INITIAL_COUNT): CounterApi {
const [count, setCount] = useState(initial);
return {
count,
increment: useCallback(() => setCount(increment), []), //
decrement: useCallback(() => setCount(decrement), []),
reset: useCallback(() => setCount(reset()), []),
};
}CounterView.tsx
tsx
import { StyleSheet, Text, View } from 'react-native';
export type CounterViewProps = {
count: number;
onIncrement: () => void;
onDecrement: () => void;
onReset: () => void;
};
/**
* @author zsh
* style也可以作为props
*/
export function CounterView({
count,
onIncrement,
onDecrement,
onReset,
}: CounterViewProps) {
return (
<View style={styles.container}>
<Text testID="count" style={styles.count}>
Count: {count}
</Text>
<View style={styles.row}>
<Text testID="dec" style={styles.btn} onPress={onDecrement}>
-
</Text>
<Text testID="inc" style={styles.btn} onPress={onIncrement}>
+
</Text>
</View>
<Text testID="reset" style={styles.reset} onPress={onReset}>
reset
</Text>
</View>
);
}
const styles = StyleSheet.create({
container: { flex: 1, alignItems: 'center', justifyContent: 'center' },
count: { fontSize: 24, marginBottom: 16 },
row: { flexDirection: 'row', gap: 24 },
btn: { fontSize: 32, paddingHorizontal: 16 },
reset: { marginTop: 16, color: '#888' },
});这个组件非常干净没有任何逻辑,复用性非常高。 这也是一个标准组件的封装。
思考:想一想网络请求应该放在哪里?
使用 Counter.tsx
tsx
import { CounterView } from './CounterView';
import { useCounter } from './useCounter';
export function Counter() {
const { count, increment, decrement, reset } = useCounter();
return (
<CounterView
count={count}
onIncrement={increment}
onDecrement={decrement}
onReset={reset}
/>
);
}剩下的测试用例让AI写。
优势
- 对state的修改集中到hooks
- 数据流向确定,事件从view流向logic,数据从logic流向view
- 易于调试、测试 这样封装我们将逻辑、状态、ui进行了解耦分离。提高了代码复用性、可读性、可维护性。 我们看到改变任何logic、hooks、view都不会互相影响。原因是:
- view被props限制
- hooks被type限制
看useCounter.ts的代码,状态的变更被约束在了hooks的type,不会有指数级状态变更。
如下图所示:
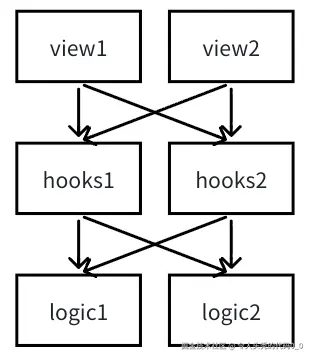
这种架构只会使我们的业务足够灵活,因为是排列组合! 我们可以将不同业务、不同变更频率的代码进行拆分。 通用的话可以放心大胆地使用不同的hooks、logic。 不通用的话就各自使用自己的hooks、logic。相信各位都有自己的见解。
我们称前端的某一个业务逻辑的logic、hooks、view为一个业务的原子代码,包括对logic、hooks、view测试相关的代码。 测试驱动开发中、测试相关的代码可以使用AI去写。当然你也可以全部让AI写这个原子代码。 不管多复杂的业务,让AI按照这个模式写,它总能实现! 不要再使用什么单例的什么Manager,将所有的业务放在Manager会导致如下:
- 占用内存(级联效应,影响引用这个非常垃圾的核心单例Manager的对象的生命周期,造成内存泄露)
- 业务量上来,代码量猛涨
- 赶工期将不合理逻辑移入Manager
- 循环引用view -> manager -> view
- 包含状态
- 混入全局状态管理(redux)
- // TODO 请大佬补充
最终导致成为上帝Manager 不是开发跑,就是公司完蛋破产,不知道AI能不能兜住这个上帝Manager
Android
我是搞Android的,IOS我不懂,我就不研究了。 Android的灵活性远没有后端和前端那么高。Android原生的灵活性是非常差的。迭代个几年,如果没有架构师参与的话,那Android的业务迭代速度会直线下降。通常需要(组件化、插件化、热更新)。 所以Android是非常复杂的。当然本话题不需要考虑整体架构。我们谈的仅是业务层面的架构。 因为android如此的复杂,所以很早就有人想办法解决这个问题了。
演进:
MVC -> MVP -> MVVM -> MVI
能把上面每一个说明白,说对的人真的很少,因为他是一种思想,每个人的水平不一样、理解不一样、经验不一样,每个人都持有自己的观点,尚没有达成如后端架构那样的共识!
但是通常我们一般会参考google,因为人家开发了android系统,绝对对android app架构的理解非常之深。 链接如下:
- 单activity(多activity的app已经过时了)
- 一个app多个设备运行
- 适配横竖屏(禁忌等比放大)
- 每个compose组件彼此独立,互不耦合
如下图所示:
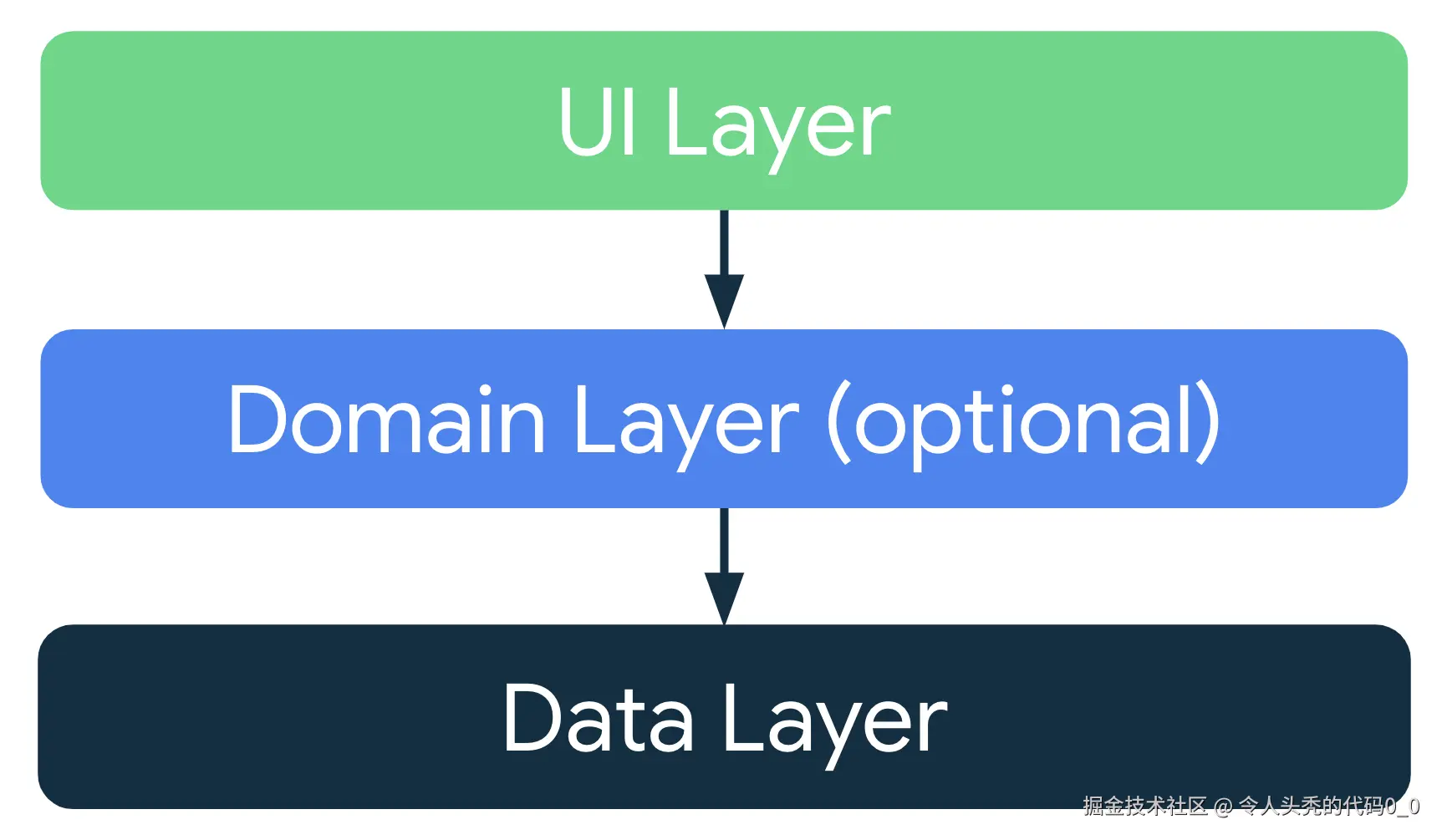
上图转为android环境即为:
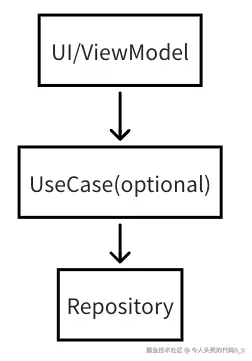
在现代Android开发中
- UI即为Compose。ViewModel中存储状态State.
- UseCase即为获取数据之后的业务处理,此类即用即创建,主线程安全(主线程直接调用安全),与环境无关可以移植其他平台,可以进行协程切换,便于测试
- Repository即为获取数据的那一层,一般以业务对象(新闻、电影、用户等)划分,主线程安全(主线程直接调用安全),里面包含大量处理数据源的逻辑
- DataSource:包含cache(datastore,建议在compose环境不要使用mmkv)、network(okhttp3)、database(sqlite3)
非常简单清晰,不愧是Google.
注意:
- 每个类使用最小生命周期,即用即创建,用完销毁,禁止引用全局的applicationContext,或者Activity造成内存泄露,因为现在都是单Activity应用。
- 将依赖进行构造函数注入,不要set注入,Kotlin不是Java那种随便的语言
- 按照业务和变更频率拆分组件。
原子化代码
一个业务的UI/ViewModel->UseCase->Repository->DataSource就是Android业务的原子化代码。适合TDD测试驱动开发,单元测试让AI写即可。
QA
为什么AI时代下Clean Architecture变得非常重要?
- 因为符合Clean Architecture的代码才能进行原子化拆分
- 可以进行TDD测试驱动开发(AI生成)
- 每次AI完成原子化任务我们code review、理解代码的压力变得很低
- 消耗token量低
- AI写的代码质量会非常高
- TODO 大佬们补充来!