lua
> 写在前面,如果对 cs336_assignment1_basics.pdf 理解有疑问的,可以参考 [[assigment1_overview&bpe_basics]] 我对文档的翻译(部分解释细节)
[[assigment1_overview&bpe_basics]] 中层提到过朴素版时间复杂度高,而在 [[train_bpe_naive#测试]] 部分,我们也看到了测试训练时间不符合题目要求。接下来我们的首要任务就是在朴素版的基础上先优化。
## 朴素版详细分析
首先,回顾下朴素版的瓶颈:
每次 merge 操作的逻辑:
1. `count_pairs` : 遍历所有 word 的编码的所有相邻字节对 ->O(N)(N 是总的 token 数)
2. `max()`:查找最高频对
3. `merge_encoding`: 遍历所有 word 的编码执行替换
前面我简单提过,问题就出在第一步------因为每轮合并后,绝大多数 word 的编码是没有变化的,但是我们还是把它们全部重新扫描一遍。
以文档中 bpe_example 为例
```text
low low low low low
lower lower widest widest widest
newest newest newest newest newest newest第一次合并的 (s,t) 影响的 word 数是 3,而我们第二次再统计时还是对所有 word 进行扫描。
优化
经过前面的分析,我们的优化思路就是维护一个全局的 pair_counts,只做增量更新 。 核心思想:不再每轮全部重新统计,而是在合并时只修改受影响的计数。 例如: (A, B) → AB 时,pair_counts 的变化只涉及两边的: ... X A B Y ... → ... X AB Y ...
- 旧的
(X,A)和(B,Y)消失(减掉其计数) - 新的
(X,AB)和(AB,Y)出现,(加上其计数) (A,B)清零
优化的核心思路:
arduino
每轮 merge:
直接从 pair_counts 字典找最大值 ← O(unique pairs)
只扫描【含有 (p0,p1) 的 word】执行替换 ← O(受影响的 word)
对这些 word:旧邻对 -count,新邻对 +count ← 增量更新增量更新的关键是:合并 (p0,p1)→new_id 后,pair_counts 的变化完全由新旧 encoding 的差异决定------旧的 encoding 的相邻字节对减计数,新的 encoding 的相邻对加计数,这样不用分类讨论左右邻居,逻辑不易出 bug。
优化后的实现
python
# 4. BPE training loop
num_merges = vocab_size - size
pair_counts = defaultdict(int, self.count_pairs(word_counts, word_encodings))
for merge_idx in range(num_merges):
if not pair_counts:
print("No more pairs to be merged, quit.")
break
# a. Find the max frequency pair to be merged
merge_pair = max(pair_counts,
key=lambda x: (pair_counts[x], self.vocab[x[0]], self.vocab[x[1]])
)
# b. Merge and update the word encodings
token_id = size
for word in word_encodings:
old_encoding = word_encodings[word]
# skip if the encoding not changed
if not any((old_encoding[i], old_encoding[i+1]) == merge_pair for i in range(len(old_encoding) - 1)):
continue
# update the encoding
new_encoding = self.merge_encoding(old_encoding, merge_pair, token_id)
# update count for pair
cnt = word_counts[word]
for i in range(len(old_encoding) - 1):
pair_counts[(old_encoding[i], old_encoding[i+1])] -= cnt
for i in range(len(new_encoding) - 1):
pair_counts[(new_encoding[i], new_encoding[i+1])] += cnt
# update word encoding
word_encodings[word] = new_encoding
# clear the pairs whose count is no more than 0
del_keys = [k for k, v in pair_counts.items() if v <= 0]
for k in del_keys:
del pair_counts[k]除了手写的一些失误,还遇到了以下几个 bug 1. any() 的使用 我一开始是这样的:
python
for i in range(len(old_encoding) - 1):
if not any((old_encoding[i], old_encoding[i+1]) == merge_pair):
continue测试时就收到了 TypeError 的提示,大概是这样的 'bool' object is not iterable。然后我查询了 any() 的用法
python
def any(iterable):
for element in iterable:
if element:
return True
return Falseany() 接收的参数必须是可迭代对象 (比如列表、生成器),但我传入的是一个布尔值 。 因此,我修改为了让 any() 接收一个生成器对象。
-
清除某些不再存在的字节对的时机 一开始的时候,我在迭代扣除 old_encoding 中的 merge_pair 的频率的时候,就清除
pythonfor i in range(len(old_encoding) - 1): pair_counts[(old_encoding[i], old_encoding[i+1])] -= cnt # clear immediately if pair_counts[(old_encoding[i], old_encoding[i+1])] <= 0: del pair_counts[(old_encoding[i], old_encoding[i+1])]测试时大概是遇到了
KeyError的错误,这种做法存在的问题:当同一个 owrd 的 encoding 中,同一个 pair 可能出现多次。假设两次,如果第一次扣除后归零,立刻清除,第二次扣除时这个 key 就不存在了,就会出现问题。 另外,扣除和加回是分阶段操作的,某个 pair 可能扣除后归零,但如果在同一轮再被加回后又重新出现,相当于提前打断了这个过程。所以,应该等整个 word 的 encoding 的的字节对频率都更新完再判断。
3. pair_counts 没有初始化就使用了(说这个是因为找了半天) 这个问题其实很明显,只是因为测试返回的信息
python
for i in range(len(new_encoding) - 1): > pair_counts[(new_encoding[i], new_encoding[i+1])] += cnt ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ E KeyError: (116, 257) cs336_basics/train_bpe.py:77: KeyError我重新检查了 merge_encoding 的操作和 count_pairs 的统计工作,没什么问题,我往前查看,发现这里的问题了 原因很直接:self.count_pairs 返回的是普通 dict,普通 dict 访问不存在的 Key 回返回 KeyError。 而 defaultdict(int) 访问不存在的 key 时,会自动初始化 int()(也就是 0),然后再执行 += 操作。 所以,将 defaultdict(int) 赋值给 dict(int)
python
pair_counts = defaultdict(int, self.count_pairs(word_counts, word_encodings))也可以先赋值,再使用 update 方法
python
pair_counts = defaultdict(int)
pair_counts.update(self.count_pairs(word_counts, word_encodings))测试
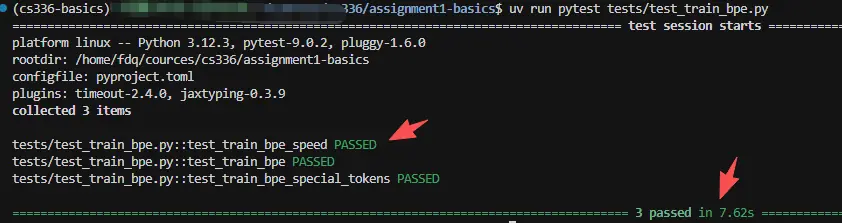 三个测试点都过了,说明相比朴素版,效率提升了。
三个测试点都过了,说明相比朴素版,效率提升了。
Tinystories 数据集上训练
这个题目有两个要求
-
a. vocab size 最大 10,000,确保将 speicial token
"<|endoftext|>"加入到 vocabulary。资源要求:训练时长 ≤ 30 minutes (no GPUs), 占用内存 ≤ 30GB RAM
Tips: 如果要在 2 分钟内完成训练,可以考虑多线程处理 pretokenize。
-
b. "tokenizer 训练过程中哪一部分最耗时?"
按照作业要求,我分了三步实现:
- 编写训练脚本:包含加载训练数据、训练、保存模型、统计时间和内存
- 分析运行时性能 (Profiling):找到瓶颈
- 检查结果:找出最长的 Token
训练脚本
数据
- 检查数据 可以使用 head 先查看下数据:
head -n 5 data/TinyStoriesV2-GPT4-train.txt确认与测试数据类型相同 - 加载数据 为了正确方便读写文件,工程中通常首先获取项目根路径。
python
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))- 获取运行时内存
python
def get_memory_usage_mb():
"""Get current process memory usage in MB"""
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024- 保存模型 训练后的结果 vocabulary 和 merges 规则写入磁盘持久化保存 vocab 是字典结构,保存为
json格式,为了方便人类读,显示为字节串,对于无法显示的,保留repr形式。
merges 是 list 结构,保存为文本文件。 这里也是参考测试文件tests/test_train_bpe.py的保存形式。也使用了tests/test_train_bpe.py中的gpt2_bytes_to_unicode为了简单方便也可以保存为 pickle.
python
# save vocab and merges to disk
from tests.common import gpt2_bytes_to_unicode
def save_vocab_and_merges(vocab, merges, output_dir='results'):
Path(output_dir).mkdir(exist_ok=True, parents=True)
byte_encoder = gpt2_bytes_to_unicode() # {int: str},each bytes map to printable string
# Save vocab:each token's bytes covert to pritntable string
vocab_str = {}
for idx, token_bytes in vocab.items():
vocab_str[idx] = ''.join(byte_encoder[b] for b in token_bytes)
with open(f'{output_dir}/vocab.json', 'w', encoding='utf-8') as f:
json.dump(vocab_str, f, ensure_ascii=False, indent=2)
# Save merges:two tokens are separated by space, and each byte is converted to printable string.
with open(f'{output_dir}/merges.txt', 'w', encoding='utf-8') as f:
for p1, p2 in merges:
t1 = ''.join(byte_encoder[b] for b in p1)
t2 = ''.join(byte_encoder[b] for b in p2)
f.write(f'{t1} {t2}\n')- 训练主函数
python
# main function
# main function
def run_training(input_path, vocab_size, special_tokens, output_dir='results'):
"""Run training"""
# record the initial memory usage before training
print(f'Initial Memory: {get_memory_usage_mb():.2f} MB')
# Initialize the BPE Trainer instance
trainer = train_bpe.BPETrainer()
# start training and record the time and memory usage
start_time = time.time()
print(f'Starting training on {input_path}...')
vocab,merges = trainer.train(input_path, vocab_size, special_tokens)
end_time = time.time()
duration = end_time - start_time
peak_memory = get_memory_usage_mb()
print('-' * 100)
print('Training Complete.')
print(f'Time Taken: {duration:.2f} seconds ({duration/60:.2f} minutes)')
print(f'Final Memory: {peak_memory:.2f} MB')
print('-' * 100)
save_vocab_and_merges(vocab, merges, output_dir)
# Output Statistics information
print("\n=== Statistics (Problem b) ===")
# 1. Longest token
longest_token_bytes = max(vocab.values(), key=len)
try:
longest_token_str = longest_token_bytes.decode('utf-8')
except:
longest_token_str = str(longest_token_bytes)
print(f"Longest Token: {longest_token_str!r}")
print(f"Length in bytes: {len(longest_token_bytes)}")
# 2. Most frequent token (approximate, based on merge priority if we tracked it,
# but here we can just say the last merged token was the most frequent *at that step*)
# The assignment asks for "most frequent token in the dataset"?
# Usually BPE doesn't keep full frequency counts of final vocab unless we re-tokenize.
# We will just print the last merge which represents the most frequent pair remaining.
print(f"Total Merges: {len(merges)}")
print('-' * 100)- 执行训练 在
main中定义参数列表行为,调用训练主函数run_training后终端执行
bash
uv run python ./train_bpe_tinystories.py \
--input_path data/TinyStoriesV2-GPT4-train.txt \
--vocab_size 10000 \
--profile训练&分析
训练结果
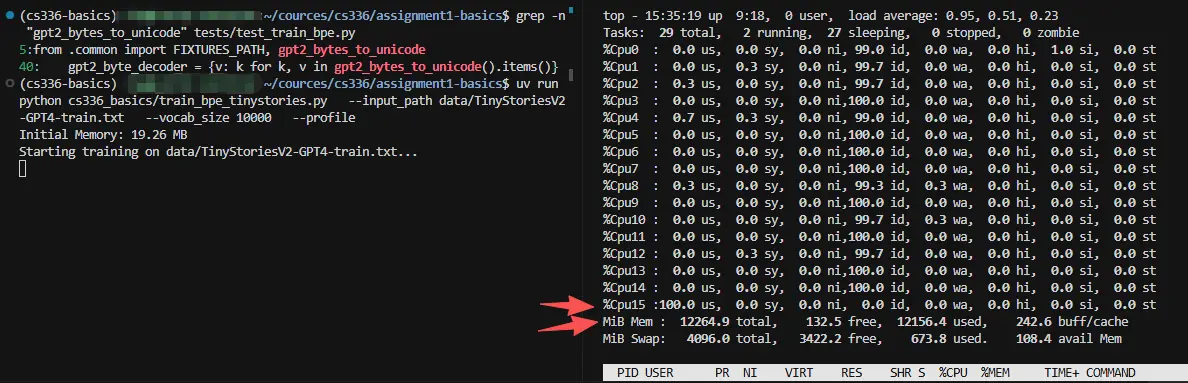
- 训练中 运行时,顺便查看了下 CPU,内存,我略显局促的内存被打满了,确实只有一个 CPU 在跑,符合单线程的预期,后面优化的点就是多线程处理预分词。
- 训练结果
结果分析
-
资源分析 从结果看:
-
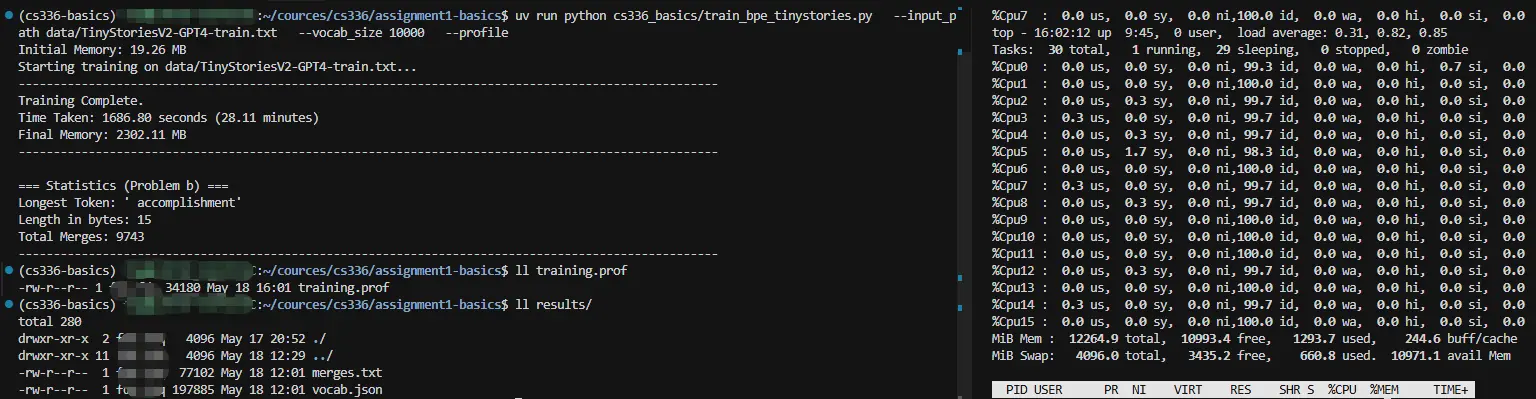
训练花了 28min,内存 2302.11 MB,这与训练数据集大小相符。 用于训练的数据集大小:
bash2.1G data/TinyStoriesV2-GPT4-train.txt 22M data/TinyStoriesV2-GPT4-valid.txt 9.8G data/owt_train.txt 4.3G data/owt_train.txt.gz -
vocabulary 和 merges 已持久化到磁盘
-
性能分析数据已保存到
training.prof
根据上面训练统计信息以及数据集的大小,我的电脑无法支撑在 OpenWebText 数据集上训练的,必须分块加载到内存。既然都分块了,多块并行执行预分词(就像文档提示的优化方向使用多进程)。
性能分析
- 启动 snakeviz 运行 training.prof
- 安装 snakeviz 由 toml 文件可知没有 snakeviz,我们需要单独安装 snakeviz
bash
uv pip install snakeviz- 启动 snakeviz 可视化服务
bash
uv run snakeviz --server training.prof- 浏览器打开 snakeviz 可视化
- 概览:
- 图表:
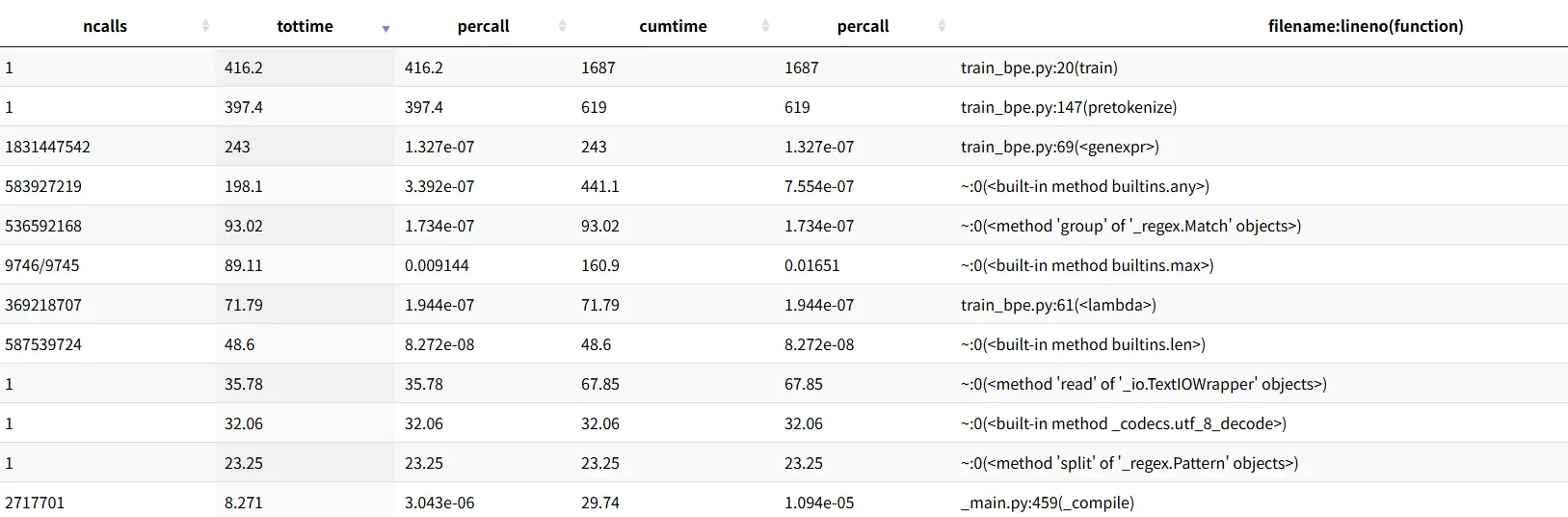
- 打印到终端 如果本地不方便浏览器打开,可以使用 python 内置的 pstats 查看文本报告
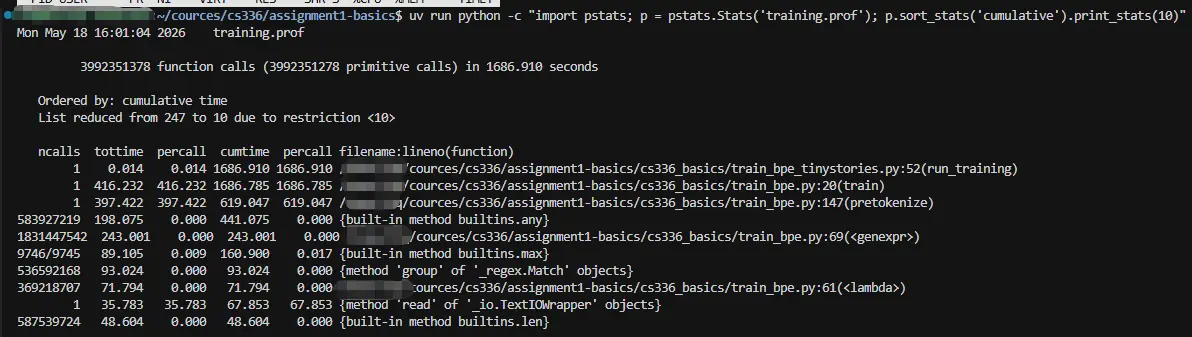
- 瓶颈分析&优化方向
这部分我让 AI 辅助,我把 profile 和代码文件给到 AI 让其分析,给出直观的可视化分析结果,并结合代码说明。
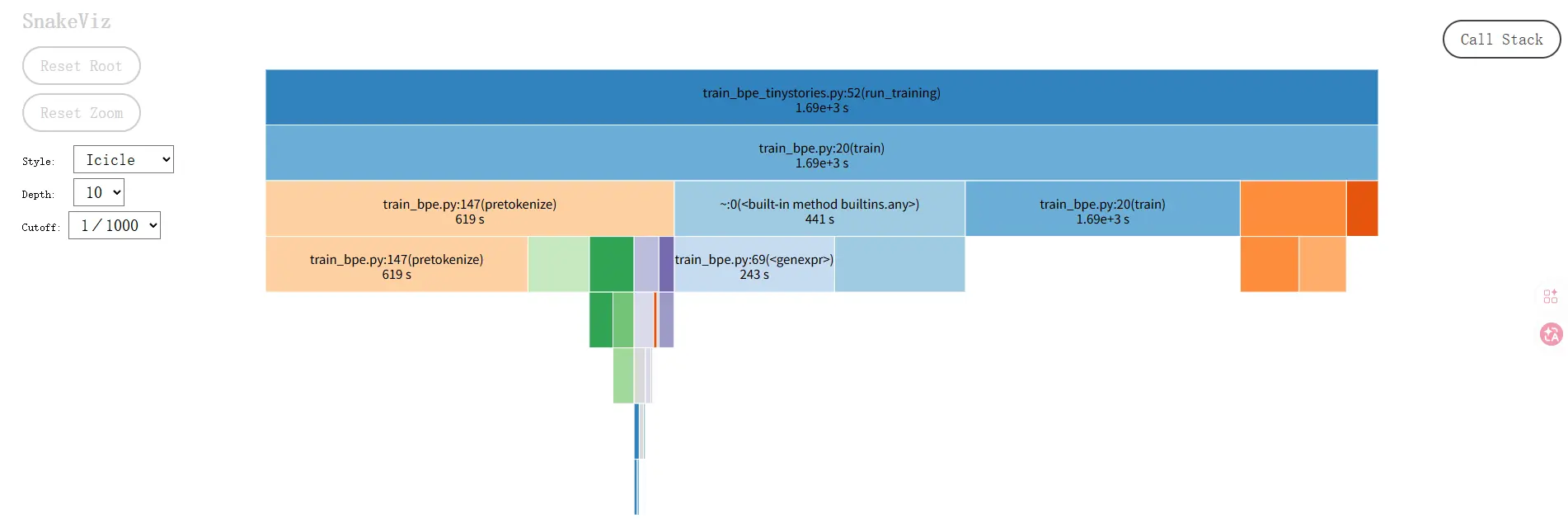
- 时间分布总览
总耗时 1687 秒,分成两大块:
| 函数 | 耗时 | 占比 |
|---|---|---|
pretokenize |
619 秒 | 37% |
train 自身(合并循环) |
416 秒 | 25% |
any + genexpr(快速跳过) |
441 秒 | 26% |
max(选最优 pair) |
161 秒 | 10% |
- 瓶颈 1:pretokenize 占 37%,且有严重的重复编译问题
_compile 被调用了 271 万次 ,耗时 30 秒。原因是你每次调用 re.finditer 时都重新编译正则,而 pretokenize 对每个 chunk 都调用一次 finditer------语料被切成了 271 万个 chunk(即 271 万个文档)。
python
chunks = re.split(escape_special_tokens, text)
...
# 当前:每个 chunk 都触发一次编译检查
for chunk in chunks:
for match in re.finditer(self.pattern, chunk): # 每次都经过编译缓存查找优化方向:提前预编译正则:
python
compiled_pattern = re.compile(self.pattern)同样,切割正则也提前编译
另外读文件耗时 68 秒(read 35s + utf_8_decode 32s),对于 2GB 文件是正常的,无法优化。
- 瓶颈 2:快速跳过逻辑本身成了最大瓶颈,占 26%
这是最反直觉的地方。any 被调用 5.84 亿次 ,genexpr 被调用 18.3 亿次,合计 441 秒。
对应代码里的这一行(69 行):
python
if not any((old_encoding[i], old_encoding[i+1]) == merge_pair
for i in range(len(old_encoding) - 1)):
continue这个 " 快速跳过 " 反而变慢了,原因是:
- 每个 word、每轮合并都要执行这个检查
- genexpr 在 Python 里有较高的调用开销
len()被调用了 5.88 亿次
对于大多数 word,快速跳过确实跳过了后续操作,但检查本身的代价已经比跳过节省的代价更大。
更快的做法是建立索引 :维护一个 pair_to_words 字典,记录每个 pair 出现在哪些 word 里,这样合并时直接查表,完全不用遍历所有 word:
python
# 初始化时建立索引
pair_to_words = defaultdict(set)
for word in word_encodings:
enc = word_encodings[word]
for i in range(len(enc) - 1):
pair_to_words[(enc[i], enc[i+1])].add(word)
# 合并时只处理受影响的 word
for word in pair_to_words[merge_pair]: # 直接拿到受影响的 word,不用遍历全部
...- 瓶颈 3:max() 每轮遍历整个 pair_counts,占 10%
max 被调用 9746 次(每轮一次),每次要遍历整个 pair_counts 字典。随着合并进行,pair_counts 越来越大,每次 max 的代价越来越高。
用堆(heapq) 替代 max,可以把每轮选最优从 O(n) 降到 O(log n):
但堆有一个复杂性:更新计数时需要处理 " 失效条目 "(lazy deletion)。这个改动比 pair_to_words 索引更复杂,建议先做索引优化,再考虑堆优化。
优化方向总结
按收益从高到低:
pair_to_words索引 ------消灭 5.84 亿次any调用,预期节省 400+ 秒- 预编译正则------消灭 271 万次重复编译,预期节省 30 秒
- 堆优化 max------预期节省 100+ 秒,但实现稍复杂
具体优化下篇详细讲解。