作者:武卓
过去一年,多模态大模型的发展速度越来越快。开发者不再只满足于让模型"会聊天",而是希望模型能够看懂图片、理解复杂指令、完成视觉问答、辅助代码生成,甚至成为智能体应用中的核心大脑。
Qwen3.5 与 Qwen3.6 的出现,正是这一趋势下非常值得关注的新进展。
这两个系列模型进一步强化了原生多模态能力,在图像理解、复杂推理、代码生成、智能体任务和长上下文处理等场景中都展现出更强的潜力。尤其是 Qwen3.6-35B-A3B 这样的 MoE 模型,在保持 35B 级别模型容量的同时,每次推理只激活约 3B 参数,让大模型在能力与推理效率之间获得了更好的平衡。
对开发者来说,这意味着什么?
意味着我们可以开始尝试把更强的多模态大模型部署到本地设备上,而不只是依赖云端 API;意味着 AI PC、边缘设备、本地工作站将有机会承载越来越多真实可用的 GenAI 应用;也意味着开发者可以在数据隐私、低延迟、本地可控和成本优化之间找到新的平衡点。
现在,OpenVINO™ 2026.2 进一步增加了对 Qwen3.5 与 Qwen3.6 模型的支持,让这些新一代 Qwen 模型能够更方便地在 Intel CPU、GPU 等硬件上完成优化、部署和推理。
本文将围绕 OpenVINO notebooks 中的 vlm-chatbot 示例,带大家以 Qwen3.6-35B-A3B 为例,看看如何完成模型下载、OpenVINO™ 格式转换、INT4 压缩优化,并基于 OpenVINO GenAI API 将模型真正运行起来。
为什么 Qwen3.5 / Qwen3.6 值得开发者关注?
如果说早期的大语言模型主要解决"文本理解与生成",那么 Qwen3.5 / Qwen3.6 更进一步,把多模态能力作为模型能力的一部分来构建。
它们的价值主要体现在三个方面。
第一,是更强的原生多模态能力。模型不只是简单地把视觉编码器接到语言模型上,而是面向图文理解、视觉问答、复杂推理和多模态交互进行了更系统的能力增强。对于开发者来说,这类模型可以更自然地用于图片理解助手、文档分析、视觉客服、工业检测解释、教育问答、个人知识助理等场景。
第二,是更高效的模型结构。以 Qwen3.6-35B-A3B 为例,它采用 MoE 架构,模型总参数约 35B,但每次推理只激活约 3B 参数。这种设计让模型在保持较大容量的同时,尽可能降低单次推理的计算成本。
第三,是更适合智能体应用。随着 tool calling、多步推理、视觉理解、代码生成和本地执行能力逐渐融合,开发者越来越需要一个既能"理解任务",又能"调用工具",还能"结合视觉信息完成判断"的模型底座。Qwen3.5 / Qwen3.6 正好适合这类 agentic AI 应用的探索。
而 OpenVINO 2026.2 的价值,就是让这些模型不仅"能用",而且更适合在 Intel 平台上本地部署、优化运行和集成到真实应用中。
OpenVINO 2026.2:让 Qwen3.5 / Qwen3.6 更容易跑在本地
OpenVINO 一直关注的核心问题是:如何让 AI 模型更高效地运行在真实硬件上。
对于开发者来说,从 Hugging Face 上拿到一个模型,只是第一步。真正要把模型做进应用,还需要解决很多实际问题:
模型如何转换为高效推理格式?
如何降低显存和内存占用?
如何在 CPU / GPU 上稳定运行?
如何支持 streaming 输出?
如何快速搭建一个可交互 demo?
如何进一步封装成自己的本地智能体或 AI PC skill?
这正是 OpenVINO notebooks 中 vlm-chatbot 示例(https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/vlm-chatbot )想解决的问题。
这个 notebook 展示了一个完整的 VLM chatbot 工作流:先安装依赖,然后选择模型和压缩精度,再通过 Optimum Intel 将模型导出为 OpenVINO IR 格式,并利用 NNCF 完成 INT8 或 INT4 权重量化压缩,最后用 OpenVINO GenAI 的 VLMPipeline 运行图文推理,并通过 Gradio 搭建交互式界面。
下面我们就以 Qwen3.6-35B-A3B 为例,走一遍核心流程。
第一步:准备运行环境
打开一个终端窗口,使用如下命令创建一个虚拟环境:
python -m venv ov-qwen36激活虚拟环境 (Windows操作系统):
ov-qwen36\Scripts\activate激活虚拟环境 (Linux / macOS操作系统):
source ov-qwen36/bin/activate然后安装 OpenVINO 2026.2、OpenVINO GenAI、Optimum Intel、NNCF 以及 VLM 推理所需依赖:
pip install -U openvino openvino-tokenizers openvino-genaipip install -U "git+https://github.com/huggingface/optimum-intel.git"pip install -U nncf torch accelerate datasets gradio huggingface-hubpip install -U opencv-python-headless einops timm sentencepiece qwen-vl-utils transformers_stream_generator需要特别注意:Qwen3.5 / Qwen3.6 相关模型需要匹配更新版本的 Transformers。Notebook 中为这两个系列提供了单独选项:
pip install --no-deps "transformers==5.2"如果你是在 notebook 中运行,可以按照 notebook 的交互控件选择 Qwen3.5 / Qwen3.6 对应的 Transformers 版本。
第二步:选择模型和压缩精度
在 vlm-chatbot notebook 中,你可以通过交互控件选择模型、语言、目标设备和压缩精度。
这里我们以Qwen/Qwen3.6-35B-A3B作为示例模型。
由于这是一个 35B 级别的多模态大模型,如果直接使用原始 BF16 / FP16 权重,对本地设备的显存和内存压力会非常大。因此,在 AI PC 或本地工作站上部署时,推荐使用 INT4 权重量化。
OpenVINO notebook 中提供了多种压缩选项:
FP16INT8INT4INT4 AWQINT4 NPU-friendly对于 Qwen3.6-35B-A3B 这类大模型,我们推荐优先尝试 INT4。它可以显著降低模型体积和显存占用,同时保持可接受的生成质量,非常适合在本地设备上进行 demo、原型验证和开发者体验展示。
第三步:下载并导出 OpenVINO™ IR 模型
如果 Hugging Face 或者魔搭社区上已经提供了预转换的 OpenVINO 模型,可以直接使用 notebook 中的 "Use preconverted models" 选项,跳过本地转换过程。
如果希望自己完整复现模型优化流程,可以使用 Optimum CLI 将模型导出为 OpenVINO IR 格式,并在导出过程中完成 INT4 权重量化。
示例命令如下:
optimum-cli export openvino \--model Qwen/Qwen3.6-35B-A3B \--task image-text-to-text \--trust-remote-code \ --weight-format int4 \--group-size 128 \--ratio 1.0 \ov_models/qwen3.6-35b-a3b-int4这里的关键参数包括:
--model指定 Hugging Face 模型 ID。
--task image-text-to-text指定这是一个图像到文本 / 图文对话任务。
--weight-format int4在导出过程中对模型权重进行 INT4 压缩。
--group-size 128控制量化分组大小,通常可以在模型大小、推理性能和精度之间取得较好平衡。
--ratio 1.0表示尽可能对线性层使用 INT4 权重量化。
需要提醒的是,35B 级别模型的转换本身会消耗较多系统内存和时间。如果只是想快速体验,建议优先使用已经转换好的 OpenVINO INT4 模型;如果你希望验证完整优化流程,再选择本地导出。
第四步:选择推理设备
OpenVINO 可以自动检测可用设备,并允许你选择 CPU、GPU 等目标设备。
对于 Qwen3.6-35B-A3B INT4 这样的模型,如果你的机器配备了 Intel GPU,建议优先尝试:
device = "GPU"如果想先验证模型是否能正确加载和运行,也可以使用:
device = "CPU"不过对于 35B 级别模型来说,GPU 通常能带来更好的交互体验,尤其是在需要 streaming 输出、图文理解和连续对话时。
第五步:使用 OpenVINO GenAI 创建 VLM 推理管线
OpenVINO GenAI 提供了更高层的生成式 AI API,可以让开发者不用手动处理复杂的 tokenization、模型调用和 generation loop。
对于 VLM 模型,可以直接使用 VLMPipeline:
import openvino_genai as ov_genaiimport openvino as ovimport numpy as npfrom PIL import Imageimport sysimport time model_dir = "ov_models/qwen3.6-35b-a3b-int4"device = "GPU" load_start = time.time()pipe = ov_genai.VLMPipeline(model_dir, device)print(f"Model loaded in {time.time() - load_start:.2f}s") cfg = ov_genai.GenerationConfig()cfg.max_new_tokens = 256 def streamer(subword): print(subword, end="", flush=True) sys.stdout.flush() return False image_path = "demo.jpg"image_tensor = ov.Tensor(np.array(Image.open(image_path).convert("RGB"))) prompt = "请用中文描述这张图片,并总结其中最重要的信息。" print("Generating...")gen_start = time.time() pipe.generate( prompt, image=image_tensor, generation_config=cfg, streamer=streamer,) print(f"\n\nInference time: {time.time() - gen_start:.2f}s")这段代码完成了几个关键动作:
首先,从 OpenVINO IR 模型目录加载 Qwen3.6-35B-A3B INT4 模型。
然后,创建 OpenVINO GenAI 的 VLMPipeline。
接着,将图片转换为 OpenVINO Tensor。
最后,调用 pipe.generate() 完成图文理解,并通过 streamer 实时输出生成结果。
这也是 notebook 中最值得大家关注的部分:模型一旦被转换和优化为 OpenVINO 格式,后续推理代码就非常简洁,适合继续集成到自己的 Gradio demo、桌面应用、Web 服务、本地智能体或 AI PC skill 中。
第六步:搭建 Gradio Chatbot Demo
完成基础推理后,就可以进一步用 Gradio 搭建交互式界面。
Notebook 已经提供了 Gradio helper,支持图片上传、文本输入和模型输出展示。你可以基于它快速构建一个本地多模态聊天机器人。
一个典型的 demo 体验可以是:
上传一张图片。
输入一个问题,例如:"请分析这张图片中的主要对象,并判断它可能适合什么应用场景。"
模型在本地完成图像理解和中文回答。
你还以继续追问,让模型基于同一张图片进行多轮分析。
以下是在32GB 内存的 Intel® Core™ Ultra X7 358H笔记本电脑上运行 Qwen3.6-35B-A3B模型的效果。
这对于开发者来说非常重要。因为它说明,大模型本地部署并不一定意味着必须准备高端服务器,也不一定必须依赖云端 GPU。通过 OpenVINO 的模型转换、权重量化和 Intel 平台优化,你可以在本地 AI PC 上完成越来越多真实可用的 GenAI 应用探索。
当然,在 Windows 系统上运行时,有一个关键设置需要提前完成:
请打开 Intel 提供的 "Intel Graphics Software",推荐大家手动将 GPU 可用显存调整到 24GB 或以上,如下图所示。
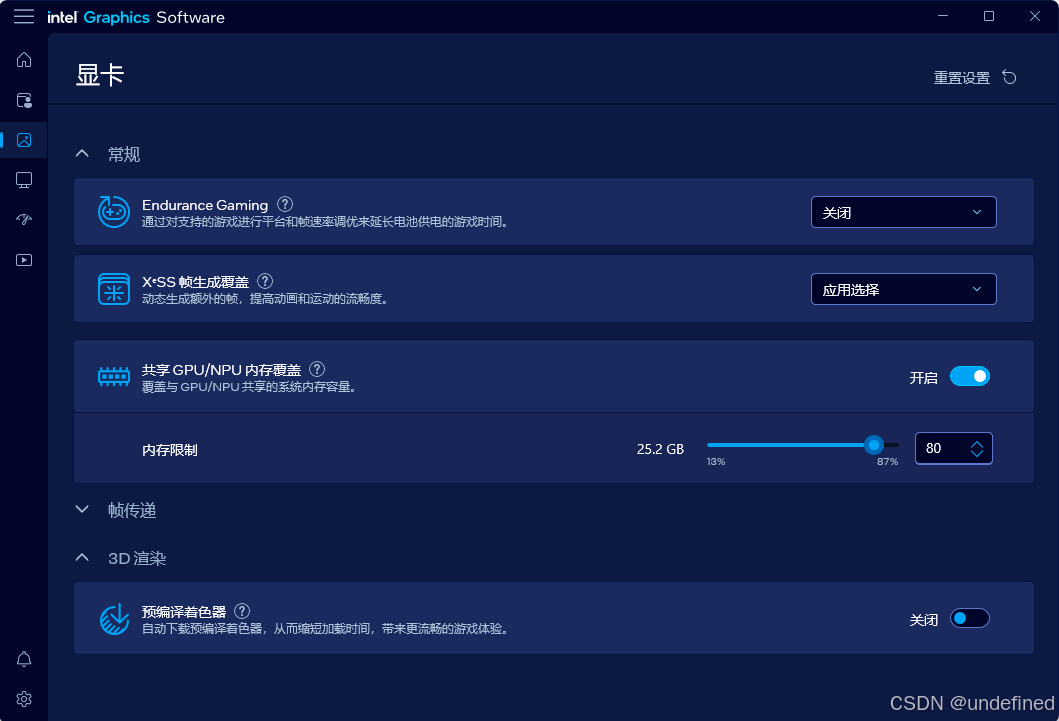
对于 Qwen3.6-35B-A3B INT4 这样的大模型,这一步非常关键。如果 GPU 可用显存设置过低,模型加载和推理过程中可能会出现显存不足、频繁换页或者交互体验不流畅的问题。将 GPU 显存调整到 24GB 及以上后,可以获得更加稳定和流畅的推理体验。
开发者可以基于这个示例继续做什么?
完成这个 notebook 后,你可以继续做很多扩展。
你可以把它封装成一个本地图片理解助手,用于识别截图、海报、产品图、工业图像或文档图片。
你可以把它接入自己的 Agent 框架,让 Qwen3.6 作为多模态理解模块,为智能体提供视觉输入能力。
你可以将 Gradio demo 改造成 Web API,让前端应用、桌面应用或企业内部工具调用本地模型。
你也可以进一步结合 OpenVINO Model Server,把模型服务化,提供更标准的部署接口。
如果你正在构建 AI PC skill,还可以把这个多模态能力封装成一个可被智能体调用的本地 skill。例如:图片信息提取、截图理解、商品图分析、文档页面解释、视觉问答等。
从 notebook 到 demo,再从 demo 到应用,这正是 OpenVINO™ 对开发者最直接的价值。
小结
Qwen3.5 和 Qwen3.6 代表了新一代多模态大模型的发展方向:更强的原生视觉语言能力,更适合智能体应用,更高效的模型结构,以及更广泛的本地部署潜力。
OpenVINO™ 2026.2 对这两个系列模型的新增支持,让开发者可以更方便地将它们部署到 Intel 平台上。借助 Optimum Intel、NNCF 和 OpenVINO GenAI API,开发者可以完成从模型下载、OpenVINO IR 转换、INT4 压缩,到本地图文推理和 Gradio demo 的完整流程。
更重要的是,我们已经可以在 32GB 内存的本地AI PC上运行经过 OpenVINO INT4 优化的 Qwen3.6-35B-A3B。对于 AI PC 开发者来说,这不是一个"未来才会发生"的方向,而是现在就可以上手验证的能力。
现在就动手试试
如果你正在关注多模态大模型、本地智能体、AI PC 应用,或者希望把大模型能力部署到更靠近用户的数据和设备侧,那么现在就是尝试 OpenVINO + Qwen3.5 / Qwen3.6 的最佳时机。
打开 OpenVINO notebooks,运行 vlm-chatbot 示例。
选择 Qwen3.6-35B-A3B。
导出 INT4 OpenVINO 模型。
在你的 Intel AI PC 上跑起第一个本地多模态大模型 demo。
不要只是阅读模型发布信息。
不要只是观看别人跑 demo。
把模型下载下来,把 notebook 跑起来,把你的第一个本地 Qwen3.6 多模态应用做出来。
OpenVINO™ 已经把路径铺好,接下来就看你能用它创造什么。