
那么我们继续来讲一下持久化可以实现的第二个应用能力 ------ 人机交互。对于人机交互这个概念,在课程前期已经和大家多次提及,相信大家都已经不陌生了。那到底什么是人机交互?我们结合具体场景来解释。
人机交互(Human-in-the-loop)
假设我们要开发一套 AI 系统,这套系统主要包含两大功能:第一是生成文章,第二是发布文章。基于这个需求,我们先来思考如何设计 LangGraph 的节点。首先第一个节点必然是生成文章节点 ,该节点执行完成后,输出的内容就是完整文章,而这篇文章会被存入全局状态state当中。紧随其后的第二个节点就是发表文章节点,它会接收上一个节点输出的文章,再执行发布操作。
这里能体现出节点之间相互独立的特点:生成文章节点只需要调用大语言模型完成内容创作,发表文章节点则可以借助工具来实现发布。举个例子,假如后端有一个文章服务service,服务会对外提供各类接口,我们就可以在发表节点中绑定对应工具,通过工具调用服务接口完成文章发布。关于 LangGraph 工具的编写,之前已经带着大家手动实现过,工具本质就是函数,函数如何调用接口这里就不再赘述,大家理解这套工作模式即可。
按照这个设计,整个工作流的正常执行逻辑就很清晰了:输入文章主题,系统自动生成文章,再完成发布,流程就此结束。这是标准的 Graph 执行流程,但我们需要思考一个实际问题:如何保证 AI 生成的文章质量合格?

可能有人会想到,可以把单一的生成文章节点拆分成多个子节点,比如先生成大纲、再根据大纲撰写正文、最后进行内容润色,依靠拆分任务的方式提升文章内容的准确性。但这种方式只能尽可能优化结果,无法做到百分百保证内容合格。那么有没有其他解决办法?
我们可以在原有自动执行的工作流基础上,新增一条人工参与的流程。当工作流执行到文章生成节点、产出文章内容后,我们让整个工作流暂时停止执行 ,由人工介入流程。人工可以获取到已生成的文章,进行审核校验。
这里分为两种情况:
-
第一种,人工审核通过,就恢复工作流,继续执行后续的发表节点;
-
第二种,人工审核不通过,我们可以手动修改文章内容,得到合格版本后,再恢复工作流执行发布操作。
在这个过程中,工作流暂停时,我们可以从执行流程中取出文章内容供人工审核;恢复流程时,又能将审核结果、修改后的文章重新写入工作流。这种人工介入的方式,能够大幅提升 AI 系统输出结果的准确性与整体鲁棒性。
**更多类似场景:**AI 自动发送邮件前,弹出确认窗口,人工确认后再执行发送,取消则终止流程;
简单总结:在 AI 自动执行的流程中插入 "暂停" 环节,等待人类输入指令或内容后,再继续执行流程,这就是人机交互功能。这项功能在各类 AI 应用中使用非常广泛,比如常用的 Cursor 等 AI 开发工具、IDE 的 AI 插件,当插件需要在终端执行命令时,都会弹出确认提示,由人工判断是否执行命令,这也是典型的人机交互。
核心概念:中断(Interrupts)
讲完人机交互的概念,我们接着学习核心概念 ------中断。 在 LangGraph 中,人机交互和中断本质指向同一能力,只是叫法不同。中断是 LangGraph 基于底层持久化能力封装而来的应用层能力。大家要理清层级关系:持久化是最底层基础能力,LangGraph 依托持久化封装出中断接口,而我们最终实现的人机交互功能,又是基于中断能力开发的。
我们可以用打游戏来类比理解中断:玩游戏遇到关卡无法通关时,我们会先暂停游戏、进行存档,接着查阅攻略,准备就绪后读取存档、继续游戏。这和中断的逻辑完全一致:正常工作流就好比游戏运行,中断就是暂停并保存当前状态,人工处理对应查阅攻略,最后恢复流程就是读取存档继续运行。
- 用户可以在游戏过程中主动按下 "存档键";
- 此时会将游戏当前状态等信息进行存档,保存下来;(实现游戏过程的中断)
- 当我们攻略后想继续游戏时,就可以读取存档继续玩。(恢复游戏继续)
**放到 LangGraph 中解释:**中断允许工作流在指定节点暂停运行,等待外部传入数据或指令后,再继续往下执行。所以学习人机交互,核心就是掌握中断的使用方式。
中断如何实现?
接下来我们拆解中断的完整执行链路,以及它和持久化的关联。想要在工作流中实现暂停与恢复,核心依靠两个关键内容:
- 通过调用 interrupt() 方法中断执行流程,依靠持久化能力,保存当前状态。
- 外部用户通过发送 Command 对象,使得工作流恢复执行流程。
interrupt()方法可以传入参数,当工作流触发暂停时,这个参数里的数据会传递给外部 ,也就是我们前面案例中,把生成的文章展示给人工审核;而Command对象是恢复流程的核心,我们可以在Command中写入人工的决策、修改后的内容等数据,这些数据会被传回工作流内部。
交互流程如下图所示:
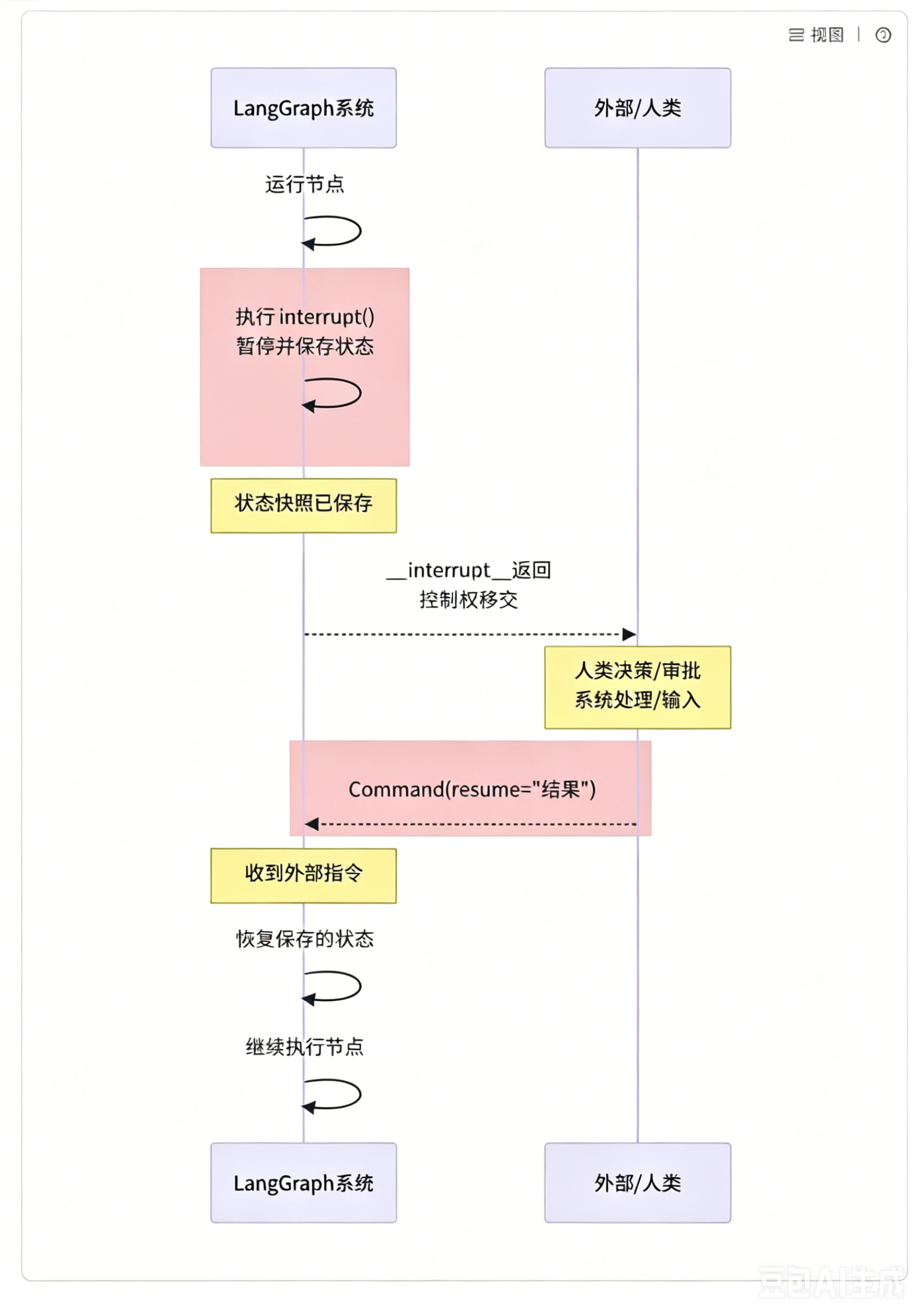
结合系统与人工两条时间线,完整流程如下:LangGraph 系统正常运行并执行节点,当代码调用interrupt()后,工作流暂停。此时系统会借助底层持久化能力,保存当前工作流的状态快照(checkpoint),状态快照保存完成后,系统将执行控制权移交到外部。
外部的人工拿到数据后,完成审核、修改、决策等操作,处理完毕后,向系统发送Command指令。LangGraph 接收到指令,读取之前保存的状态快照,恢复工作流执行,整个流程继续向后推进。不难看出,中断功能完全依托于线程级持久化、状态快照存储这套底层机制。
interrupt() 是一个暂停点 + 等待输入点。被调用时,LangGraph 保存当前状态快照(含代码位置和变量),然后暂停执行。外部通过 Command(resume=...) 传入数据后,系统加载快照,将传入数据作为 interrupt() 的返回值,然后从暂停点继续执行。
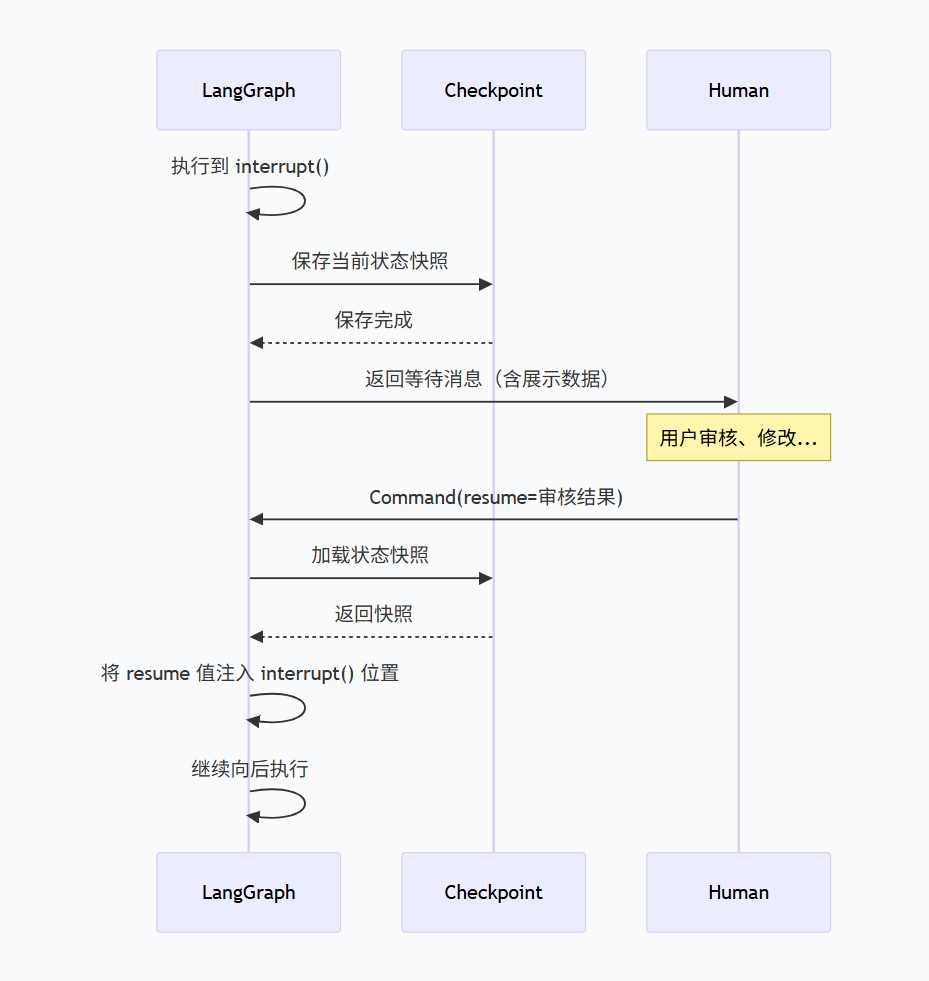

不过不要被误导,我们要始终记得,持久化(保存的 checkpoint)确实不会因 Command 而被修改或删除。
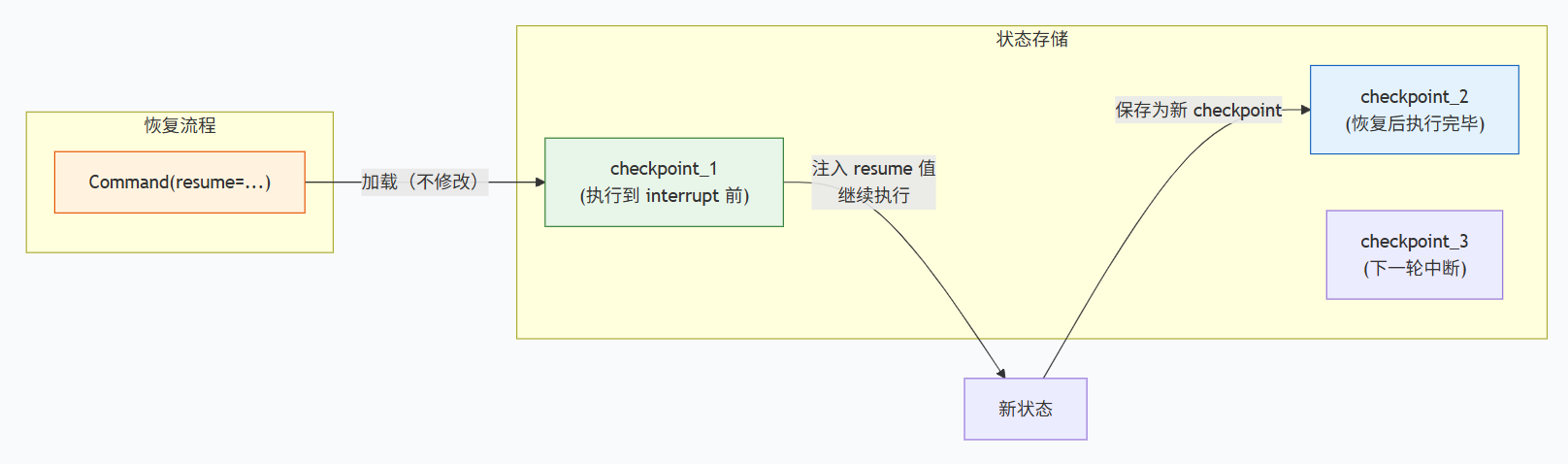
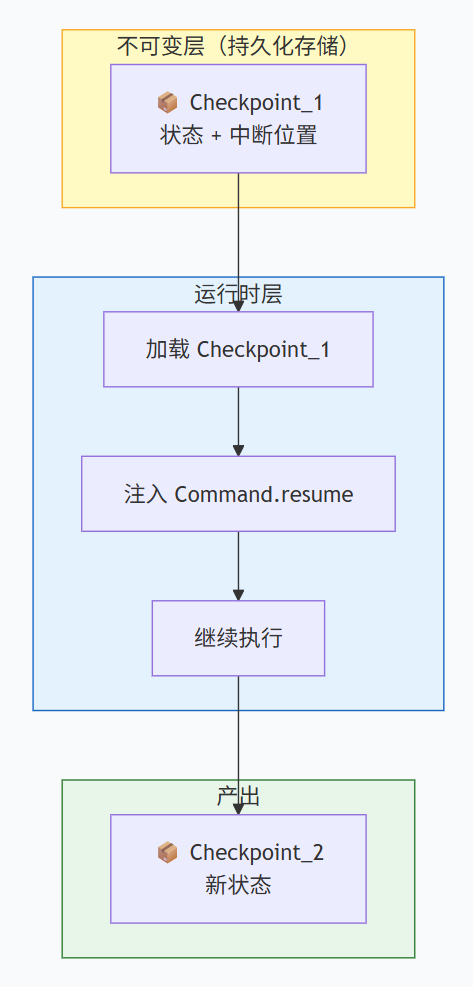
所以,"恢复的本质,不是修改历史快照,而是在不可变的旧快照之上,叠加一层 Command 注入值,形成一个临时的'遮蔽层',程序基于这个叠加后的视图继续执行。"这就和"写时拷贝"很相似!
理论讲解完成,接下来我们结合代码实操,演示中断的具体用法。首先我们需要定义状态、节点、图结构,再完成编译与调用。
首先自定义状态,状态中包含输入和输出字段;接着编写业务节点,在节点内部调用interrupt()方法实现暂停。
这里重点说明interrupt() **的参数与返回值:**方法的入参是传递给外部的数据,可以是字符串、字典等可序列化类型,但不能传递函数、类实例、数据库连接这类复杂对象;而它的返回值,就是外部通过Command传回工作流的数据。
我们举一个简单示例:interrupt("结束还是继续?"),暂停时会把这段提示语展示给外部;外部传入yes或no,这个结果就会作为interrupt()的返回值,我们可以根据返回值编写分支逻辑:收到yes就正常输出内容、继续执行,收到no则终止工作流。
完成节点编写后,开始构建StateGraph图结构,添加节点与边。这里有一个硬性要求:编译图的时候,必须指定checkpointer持久化存储器 。因为中断依赖持久化能力,不配置存储器,就无法保存状态快照,中断功能也会直接失效,示例中我们使用内存型存储器InMemorySaver。
图编译完成后,执行调用逻辑也有要点:调用invoke()方法时,必须传入config配置,并在配置中指定thread_id(线程 ID)。thread_id的作用是标记当前工作流会话,系统会根据这个 ID,将状态快照保存到对应会话下,后续恢复流程时,也依靠这个 ID 读取快照。
python
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class State(TypedDict):
input: str
output: str
def hello_node(state: State):
# 主动喊"停",并传递提示信息
human = interrupt("暂停,是否继续?") # 第一次运行会停在这里
if human == "yes":
return {"output": "你好,我是你的贴心助手!"}
else:
return {"output": "拜拜"}
builder = StateGraph(State)
builder.add_node("hello", hello_node)
builder.add_edge(START, "hello")
builder.add_edge("hello", END)
# 必须指定 checkpointer,以在每个步骤后保存图状态
graph = builder.compile(checkpointer=InMemorySaver())
# 必须使用 thread_id 运行 Graph,相当于告诉系统读哪个"存档"。
config = {"configurable": {"thread_id": "human_1"}}
# 步骤1:启动,触发暂停
first = graph.invoke({"input": "hi"}, config=config)
print(first) # 看到提示:interrupt
# 步骤2:恢复,把答案发回去
second = graph.invoke(Command(resume="no"), config=config)
print(second)第一次调用invoke(),传入初始内容,工作流运行至interrupt()处触发暂停。此时执行结果中会携带__interrupt__字段,里面就是我们通过interrupt()传出的提示信息,前端、控制台等外部载体,都可以读取该字段展示内容,实现交互弹窗、文字提示等效果。
第二次调用invoke()实现流程恢复,这一次不再传入普通状态数据,而是直接传入Command对象,并在Command中写入恢复数据(比如yes),同时沿用和第一次相同的config与thread_id。系统接收到Command后,读取对应会话的状态快照,恢复节点执行,interrupt()会接收Command传回的数据,节点内的分支逻辑开始生效,最终输出结果,整个流程执行完毕。
python
{'input': 'hi', '__interrupt__': [Interrupt(value='结束还是继续?', id='5b7f545fceaa4dbccbc6a101e8394f05')]}
{'input': 'hi', 'output': '拜拜'}代码关键点:
-
编译图时:必须指定
checkpointer,以在每个步骤后保存图状态。 -
调用
interrupt()时:表示主动喊 "停!",并传递提示信息。 -
使用
invoke/stream恢复执行,需使用Command(resume=...)语法,其中resume表示传回 AI 的响应值 -
必须使用
thread_id运行 Graph,相当于告诉系统读哪个存档。
因此实现了中断,便是实现了人机交互模式。
通过代码演示,我们掌握了interrupt()和Command的基础搭配用法。但中断的使用存在明确的规则与限制,大家在编码时必须严格遵守,接下来我们逐一讲解四大核心规则。
中断的黄金法则(规则和限制)
只能传序列化的简单数据
第一条规则:interrupt()仅支持传递可序列化的简单数据
函数、类实例、数据库连接等复杂对象无法被序列化,绝对不能作为interrupt()的参数。合法的数据类型包括字符串、数字、布尔值、简单字典、普通列表等。如果传递无法序列化的对象,会直接导致功能报错。
正面示例✅:
python
# 示例1:传递可序列化的简单类型
def node_a(state: State):
name = interrupt("What's your name?")
count = interrupt(42)
approved = interrupt(True)
return {"name": name, "count": count, "approved": approved}
python
# 示例2:传递带有简单值的字典
def node_a(state: State):
response = interrupt({
"question": "Enter user details",
"fields": ["name", "email", "age"],
"current_values": state.get("user", {})
})
return {"user": response}反面示例❌:
python
# 示例1:传递函数实现中断(函数不能被序列化)
def validate_input(value):
return len(value) > 0
def node_a(state: State):
response = interrupt({
"question": "What's your name?",
"validator": validate_input
})
return {"name": response}
python
# 示例2:传递类实例实现中断(实例不能被序列化)
class DataProcessor:
def __init__(self, config):
self.config = config
def node_a(state: State):
processor = DataProcessor({"mode": "strict"})
response = interrupt({
"question": "Enter data to process",
"processor": processor
})
return {"result": response}不应该将 interrupt() 调用包裹在 try/except 代码块中
第二条规则:不要将interrupt()调用包裹在通用的try/except异常捕获代码块中
错误做法是: 如果将 interrupt() 调用包裹在通用的 try/except Exception 或 try/except(空)代码块中,你编写的代码会提前捕获这个特殊异常。这会导致运行时系统无法感知到中断,从而使 interrupt() 功能失效。
反面示例❌:
def node_a(state: State):
try:
interrupt("What's your name?")
except Exception as e:
print(e)
return state根本原因是:
interrupt()实现暂停的底层原理,是主动抛出一个 LangGraph 专属的特殊异常,依靠这个异常触发状态保存、流程暂停、控制权移交等操作。这个异常需要由 LangGraph 运行时系统捕获处理。
如果我们使用try/except Exception捕获所有异常,就会提前拦截这个专属异常,LangGraph 无法感知到中断指令,最终导致中断功能彻底失效。 对应的正确写法有两种:
正确做法:
-
分离逻辑 :将
interrupt()调用与可能引发其他异常的代码分开。先调用interrupt(),然后再处理可能出错的操作。 -
精确捕获 :在
try/except块中只捕获你预期会发生的、非常具体的异常类型(例如NetworkException)。这样,interrupt()抛出的特殊异常就不会被你的代码捕获,而能顺利传递给运行时系统。
正面示例✅:
python
# 示例1:先中断,再处理
def node_a(state: State):
name = interrupt("What's your name?")
try:
fetch_data()
except Exception as e:
print(e)
return state
python
# 示例2:捕捉特定的异常类型
def node_a(state: State):
try:
name = interrupt("What's your name?")
fetch_data()
except NetworkException as e:
print(e)
return state这部分是一个重要的警告,旨在避免开发者因使用常规的错误处理模式而导致 interrupt() 机制失效。其核心是必须让 interrupt() 抛出的特殊异常能够 "逃逸" 出你编写的节点函数,以便被 LangGraph 运行时正确处理。
中断前的动作要 "幂等"
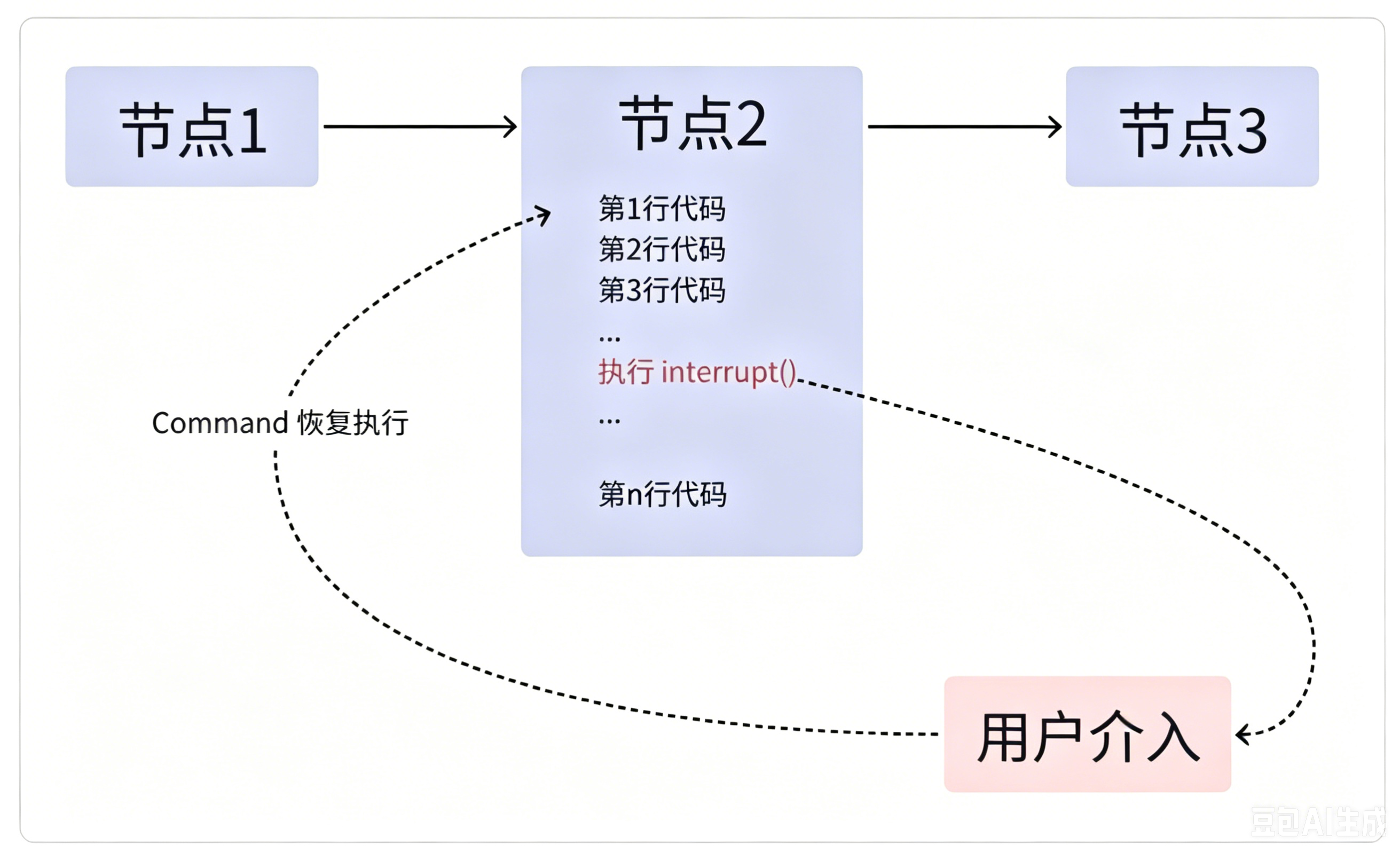
第三条规则:interrupt()执行之前的代码逻辑,必须保证幂等性
首先明确一个底层特性:当我们通过Command恢复工作流时,触发中断的整个节点会从头重新执行 ,而不是从interrupt()这一行代码继续执行。这就意味着,interrupt()之前的代码,会被重复运行多次。【非常重要!】
幂等性指: 一个操作无论执行一次还是多次,最终产生的效果和数据结果完全一致。如果在interrupt()之前编写非幂等的副作用操作,比如数据库新增数据、向日志列表追加内容等,节点重复执行时,就会重复新增、重复追加,造成数据冗余、数据错乱。
针对这个问题,有三种解决方案:
-
第一,使用幂等操作,比如数据库更新操作,多次更新同一条数据,结果不会发生变化;
-
第二,将带有副作用的代码,写在interrupt()调用之后,节点重复执行也不会触发多次操作;
-
第三,拆分节点,把有副作用的逻辑独立成新节点,中断逻辑单独放在一个节点中,彻底规避重复执行带来的问题。
幂等性:一个操作无论执行一次还是多次,产生的效果都相同。
正面示例✅:
python
# 示例1:使用幂等操作(更新或插入操作,多次执行结果一致)
def node_a(state: State):
db.upsert_user(
user_id=state["user_id"],
status="pending_approval"
)
approved = interrupt("Approve this change?")
return {"approved": approved}
python
# 示例2:将副作用放在中断之后(先中断,获得批准后再执行副作用)
def node_a(state: State):
approved = interrupt("Approve this change?")
if approved:
db.create_audit_log(
user_id=state["user_id"],
action="approved"
)
return {"approved": approved}
python
# 示例3:将副作用分离到独立节点(仅在获得批准后执行一次)
def approval_node(state: State):
approved = interrupt("Approve this change?")
return {"approved": approved}
def notification_node(state: State):
if state["approved"]:
send_notification(user_id=state["user_id"], status="approved")
return state反面示例❌:
python
# 示例1:在中断前创建新记录(每次恢复都会创建新的审计记录)
def node_a(state: State):
audit_id = db.create_audit_log({
"user_id": state["user_id"],
"action": "pending_approval",
"timestamp": datetime.now()
})
approved = interrupt("Approve this change?")
return {"approved": approved, "audit_id": audit_id}
python
# 示例2:在中断前追加到列表(每次恢复都会重复追加相同条目)
def node_a(state: State):
db.append_to_history(
state["user_id"],
"action_requested",
approved
)
approved = interrupt("Approve this change?")
return {"approved": approved}这一规则的核心是:确保在 interrupt() 调用之前执行的所有操作都是幂等的,或者将非幂等操作移到 interrupt() 调用之后。这是为了避免因节点重新执行而导致的重复副作用,确保系统的数据一致性和预期行为。
中断顺序固定
第四条规则:同一节点内多个interrupt()的调用顺序必须固定
LangGraph 会维护一个索引列表,按顺序记录节点内每一个interrupt()的执行与恢复状态。节点恢复执行时,会根据这个索引,依次跳过已处理完成的中断。
如果通过if条件判断、动态遍历列表等方式,让interrupt()的执行数量、执行顺序发生变化,索引列表就会匹配错乱,系统无法判断哪些中断已处理、哪些待处理,最终引发程序异常。
因此禁止使用条件判断、动态循环来控制interrupt()的执行,必须保证每一次运行节点时,interrupt()的调用顺序、调用数量完全一致。
也就是说:在同一节点中使用多个 interrupt() 调用时需要注意的顺序和索引匹配规则。LangGraph 使用严格的顺序从头开始恢复:
- 恢复执行从头开始:节点恢复时会从头重新运行,而不是从中断的精确行继续。
- 恢复执行顺序匹配 :为每个执行任务维护一个恢复值列表。遇到
interrupt()时,按顺序从这个列表中取对应的值。 - 顺序必须一致:中断调用的顺序在每次执行中必须完全相同。
正面示例✅:
python
# 中断调用顺序固定
def node_a(state: State):
name = interrupt("What's your name?") # 索引0
age = interrupt("What's your age?") # 索引1
city = interrupt("What's your city?") # 索引2
return {"name": name, "age": age, "city": city}反面示例❌:
python
# 示例1:条件性跳过中断(第一次索引可能跳过,恢复时可能不连续,导致索引错乱)
def node_a(state: State):
name = interrupt("What's your name?") # 索引0
if state.get("needs_age"):
age = interrupt("What's your age?") # 索引1(有时存在)
city = interrupt("What's your city?") # 索引1或2(不确定)
python
# 示例2:基于非确定性数据的循环中断(中断数量随动态列表变化)
def node_a(state: State):
results = []
for item in state.get("dynamic_list", []): # 列表可能在不同执行中变化
result = interrupt(f"Approve {item}?") # 中断数量不确定
results.append(result)以上就是使用中断功能的四大核心规则,这些都是编码时必须遵守的硬性规范。
总结:以上我们首先理解了人机交互的概念,它是在 AI 自动流程中加入人工暂停与介入的能力;而在 LangGraph 中,该能力依靠中断 实现,中断基于底层持久化、状态快照机制运行;核心用法就是用interrupt()暂停流程、向外传递数据,用Command恢复流程、向内回传数据;最后我们详细讲解了中断使用时的四大规则与限制,结合正反案例说明了编码规范。以上就是关于 LangGraph 中断与人机交互功能的全部内容。
人机交互的应用场景
那么我们继续来看一下将来如果我们要自己去实现一些智能应用的时候,有哪些场景会使用到人机交互,或者说有哪些场景会使用到我们之前讲过的中断功能。
使用中断来实现需要人工介入的交互式工作流有四种常见模式:
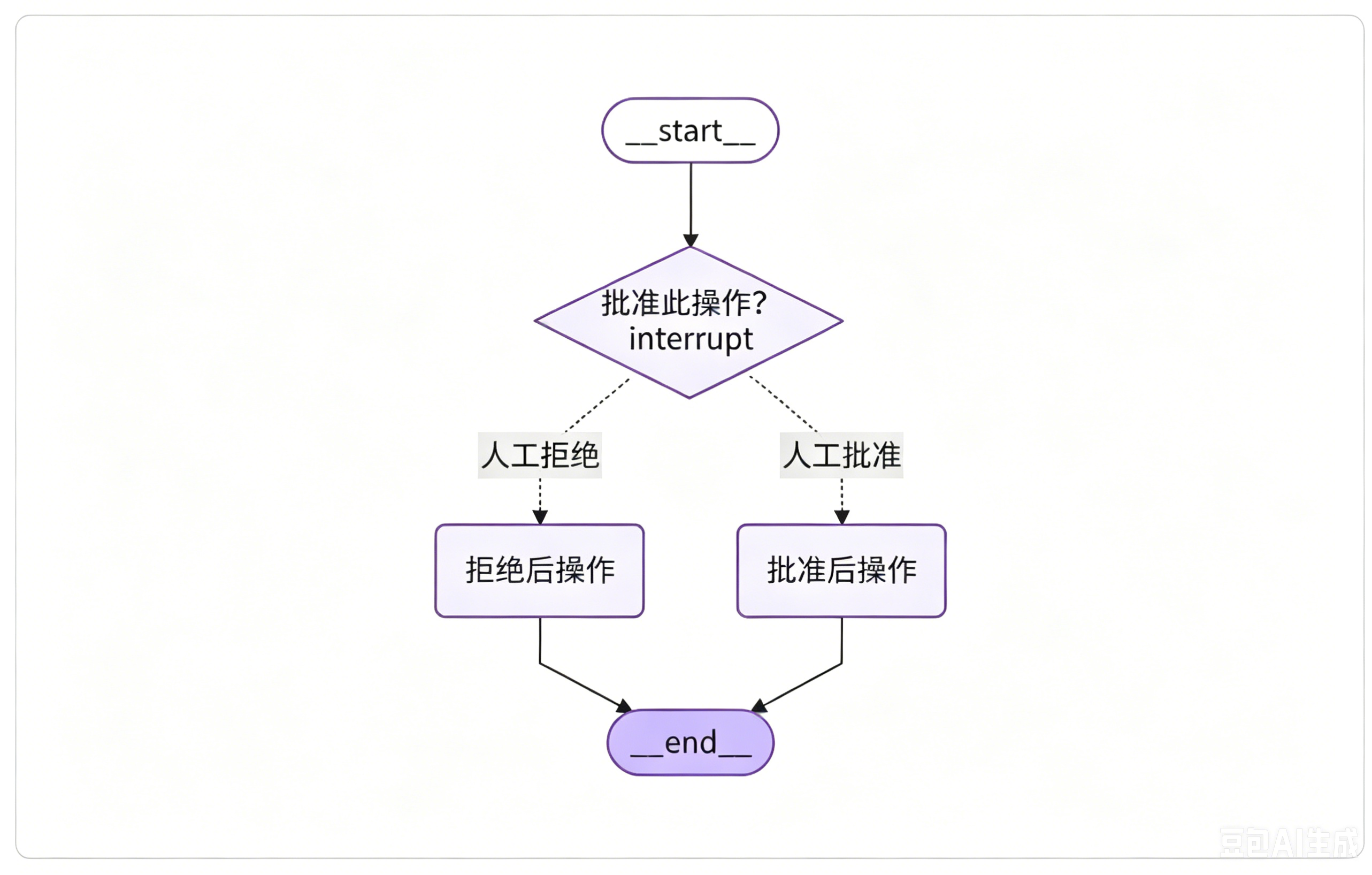
第一种叫审批与拒绝。**那审批与拒绝是什么意思呢?**就是在我们执行关键操作的时候,先暂停流程,暂停完之后等待人工审核,选择批准还是拒绝。我们会根据返回的批准或者拒绝指令,让流程路由到不同的分支上,这也是我们最早给大家举的例子。
就好比发送邮件前,点击确认就代表批准发送邮件,点击取消就代表不批准发送邮件,这就是第一种批准与拒绝的场景。
这类场景的常规流程大概是: 流程运行到指定节点后设置中断,人工如果同意就返回yes,拒绝就返回no。系统会根据审批结果,将流程分流到对应的后续处理环节,拒绝就执行拒绝对应的逻辑,批准就执行批准对应的相关节点。
第二种常见模式是审查与编辑状态。也就是在工作流运行的过程中暂停流程,允许人工审查并且修改当前工作流内的状态。就拿之前生成文章的例子来说,大语言模型完成文章生成后,我们触发中断,人工可以查看生成的内容,如果发现段落存在问题,就直接对段落进行修改。
**这类场景的常规流程大概是:**最开始只有文章主题或者大纲,系统根据主题生成完整文章,生成完毕后触发中断。中断之后,系统会把文章内容传递给外部人工,人工完成查看、编辑操作后,再将修改好的文章回传到工作流中,完成状态更新。这就是审查和编辑状态,也是我们之前讲到的人工编辑文章的交互方式。
第三个场景是在工具中中断。我们在开发应用时会编写各类工具,工作流运行过程中也会调用这些工具。而在工具正式执行之前,我们可以借助中断功能让人工介入。人工可以检查工具的调用参数是否正确,也可以直接修改调用参数,甚至能够直接取消本次工具调用。有了人机交互和中断能力,以上这些操作都可以实现。
第四个场景是验证人工输入。我之前举过办理银行卡的例子,大家可以回忆一下。去银行办卡,需要用户提供手机号和身份证。如果用户只出示了手机、报了手机号,缺少身份证,柜台工作人员就会要求用户补交证件。这个过程就相当于人工再次参与到工作流中,把身份证相关信息重新输入到流程里。
以上四种,就是人机交互,也就是中断功能在 AI 应用中的典型使用场景。接下来我们会逐一通过代码实现这几个场景,让大家直观了解中断在实际 AI 项目中的具体用法。
中断的核心作用,就是赋予了工作流暂停执行、等待外部输入的能力。依托这项能力,我们可以实现丰富的应用功能:完成各类审批操作、查看并编辑流程状态、由人工决定是否调用工具以及修改工具参数、循环校验用户输入内容。接下来我们从第一个场景 ------ 批准与拒绝开始实现。
批准或拒绝(Approve or reject)
批准与拒绝是中断功能里使用频率最高的场景,像金融交易、数据库修改、接口调用这类关键操作前,基本都会暂停流程,等待人工审批。就像我们手机转账时,页面会弹出确认窗口,展示转账金额等信息,点击确定代表批准转账,交易执行成功;点击取消代表拒绝转账,本次交易终止。
**接下来我们开始编写代码实现该场景。**首先规划整体结构:第一个节点专门用来实现中断、发起审批;第二个节点模拟审批通过后的业务操作;第三个节点模拟拒绝审批后的业务操作,节点内部仅做简单打印,方便查看运行效果。
首先定义状态结构。状态中需要包含两类信息,第一类是操作详情,用来描述当前要执行的动作,比如金融转账,方便人工知晓审批内容;第二类是审批状态,记录当前流程处于等待、批准还是拒绝状态。后续代码运行时,我们会对这两个状态字段进行赋值和传递。
python
class ApprovalState(TypedDict):
action_details: str # 操作详情(如"转账30000元")
status: Optional[Literal["等待", "批准", "拒绝"]] # 审批状态初始化状态时,我们后续可以设定具体操作,例如转账3000元,同时将审批状态默认设置为等待。当人工完成审批后,再把状态更新为批准或者拒绝。
状态定义完成后,开始编写节点逻辑。第一个节点为审批节点,在这个节点中直接调用interrupt方法实现流程暂停。之前我们大多传递字符串作为中断参数,这次我们传递字典类型的数据。字典内包含两个内容,一是审批提问是否批准此操作,二是操作详情,同时补充提示信息请输入,批准或拒绝。
python
# 审批节点(只负责中断和返回决策,不做路由)
def approval_node(state: ApprovalState):
# 中断执行,将审批请求传递给调用者(字典格式)
decision = interrupt({
"question": "批准此操作?",
"details": state["action_details"],
"提示信息": "请输入 批准 或 拒绝"
})
# 根据决策结果修改状态
state["approved"] = decision
# 返回更新后的状态(路由由条件边负责)
return state流程触发中断后,外部人工输入批准或者拒绝,这个结果会作为interrupt方法的返回值被节点接收。我们拿到该决策结果后,就可以根据结果修改状态,再配合后续节点完成不同逻辑。
接着编写两个分支节点:批准节点和取消节点,节点内部仅做打印输出,模拟对应的业务逻辑即可。
python
def proceed_node(state: ApprovalState):
return {"status": "批准"}
def cancel_node(state: ApprovalState):
return {"status": "拒绝"}节点编写完成后,开始搭建StateGraph图结构,依次把审批节点、批准节点、取消节点添加到图中。编译图的时候必须配置持久化存储器,这里我们使用内存型存储器 InMemorySaver,这是使用中断功能的必要条件。
添加节点之后需要配置连线。首先配置基础连线,从START入口指向审批节点。由于后续流程需要根据审批结果分流,这里要用到条件边 。我们编写判断函数,读取状态中的审批字段,如果状态为批准,就路由到批准节点;反之则路由到取消节点。将判断函数和节点映射关系配置到条件边中,依靠人工审批结果决定流程走向。
最后配置收尾连线,将批准节点、取消节点都指向END结束节点,代表无论审批结果如何,执行完对应逻辑后流程终止。整个图结构到此搭建完成。
python
# 条件边函数:根据状态中的 approved 决定下一个节点
def route_after_approval(state: ApprovalState) -> Literal["proceed", "cancel"]:
if state["approved"]:
return "proceed"
else:
return "cancel"
# 构建图
builder = StateGraph(ApprovalState)
# 添加节点
builder.add_node("approval", approval_node)
builder.add_node("proceed", proceed_node)
builder.add_node("cancel", cancel_node)
# 添加边
builder.add_edge(START, "approval")
builder.add_conditional_edges("approval", route_after_approval) # 条件边
builder.add_edge("proceed", END)
builder.add_edge("cancel", END)
# 编译图(需要持久化支持中断)
memory = InMemorySaver()
graph = builder.compile(checkpointer=memory)运行代码测试,第一次调用invoke执行流程,这里一定要传入config配置并指定thread_id,使用线程级持久化存储时,该配置必不可少。程序运行后会触发中断,返回中断字典,里面包含审批问题、转账操作详情以及输入提示,和我们的设计一致。
随后进行第二次调用恢复流程,此时不再传入普通状态数据,而是传入Command对象,在其中填写审批结果,比如取消。代码会执行取消节点的逻辑并打印内容,同时更新最终状态为取消。
python
[Interrupt(value={'question': '批准此操作?', 'details': '转账30000元', '提示信息': '请输入 批准 或 拒绝'}, id='c587d5d033f7fcde7fe76c8a753d9a85')]
批准从运行结果能看出这套写法的核心逻辑:接收人工返回的审批状态,借助条件边做逻辑判断,进而执行不同的后续流程。这是 LangGraph 中实现分支流程的常规写法。
除此之外,LangGraph 还提供了另一种实现方式。上面的写法是在节点内更新审批状态,再依靠条件边跳转节点;而第二种写法,可以直接在审批节点中根据决策结果,通过返回Command对象搭配goto参数,直接指定下一个要执行的节点,不再需要额外配置条件边。
具体实现逻辑: 在审批节点拿到人工的决策结果后,通过if判断结果是批准还是取消,分别定义对应的目标节点名称。最终return Command(goto=目标节点名),让流程直接跳转到指定节点。
这种写法下,状态不再在审批节点中统一修改,而是放到对应的分支节点内更新:批准节点中将状态改为批准,取消节点中将状态改为取消。
python
# 审批节点
def approval_node(state: ApprovalState) -> Command[Literal["proceed", "cancel"]]:
# 中断执行,将审批请求传递给调用者(字典格式)
decision = interrupt({
"question": "批准此操作?",
"details": state["action_details"],
"提示信息": "请输入 批准 或 拒绝"
})
# 根据决策结果更新状态
state["approved"] = decision
# 恢复后路由到适当的节点
return Command(goto="proceed" if decision else "cancel")图结构搭建时,只需要配置START到审批节点的基础连线即可,无需再配置条件边。再次运行代码测试,分别传入取消和批准,流程都能正常跳转到对应节点执行,功能完全正常。
两种写法各有特点:依靠条件边的写法,在搭建图结构时就能直观看到整个流程的走向,可读性更强;通过Command搭配goto跳转节点的写法,可以省去条件边的代码,代码整体更加简洁,但需要阅读节点内部逻辑,才能理清流程分支。两种方式 LangGraph 都支持,大家可以根据实际开发场景和个人习惯自行选择。
具体代码如下
python
from typing import Literal, Optional, TypedDict
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
class ApprovalState(TypedDict):
action_details: str # 操作详情(如"转账30000元")
status: Optional[Literal["等待", "批准", "拒绝"]] # 审批状态
# 审批节点
def approval_node(state: ApprovalState) -> Command[Literal["proceed", "cancel"]]:
# 中断执行,将审批请求传递给调用者(字典格式)
decision = interrupt({
"question": "批准此操作?",
"details": state["action_details"],
"提示信息": "请输入 批准 或 拒绝"
})
# 根据决策结果更新状态
state["approved"] = decision
# 恢复后路由到适当的节点
return Command(goto="proceed" if decision == "批准" else "cancel")
def proceed_node(state: ApprovalState):
return {"status": "批准"}
def cancel_node(state: ApprovalState):
return {"status": "拒绝"}
# 构建图
builder = StateGraph(ApprovalState)
builder.add_node("approval", approval_node)
builder.add_node("proceed", proceed_node)
builder.add_node("cancel", cancel_node)
builder.add_edge(START, "approval")
builder.add_edge("proceed", END)
builder.add_edge("cancel", END)
graph = builder.compile(checkpointer=MemorySaver())
# 运行图(首次调用会触发中断)
config = {"configurable": {"thread_id": "123"}}
initial = graph.invoke(
{"action_details": "转账30000元", "status": "等待"},
config=config
)
print(initial["__interrupt__"]) # -> [Interrupt(value={'question': ..., 'details': ...})]
# 用决策恢复执行:True路由到proceed,False路由到cancel
resumed = graph.invoke(Command(resume="批准"), config=config)
print(resumed["status"]) # -> "批准"实现方式总结:
在节点中使用 interrupt() 函数暂停执行。传入一个包含审批问题、操作详情等信息的 JSON 可序列化对象,该对象会显示在调用结果 result["interrupt"] 中。
当图被暂停后,外部系统(如 UI 界面)可以根据 interrupt 中的信息向用户展示审批请求。
人工做出决定(批准或拒绝)后,通过再次调用图并传入 Command(resume=...) 来恢复执行。
恢复时,传入 Command(resume=True) 表示批准,传入 Command(resume=False) 表示拒绝。
节点代码会接收这个 resume 值作为 interrupt() 函数的返回值,然后根据该值,使用 Command(goto=...) 将流程路由到不同的后续节点(例如 "proceed" 节点或 "cancel" 节点)。
Command(goto=...)表示要导航到的下一个节点的名称
到这里,关于人机交互第一个应用场景 ------ 审批与拒绝的代码实现和两种写法,就全部讲解完毕了。
查看和编辑状态(Review and edit state)
这一场景和刚才的批准或拒绝只有细微区别。批准或拒绝,是工作流恢复后,根据传回的信息执行不同的后续操作;而查看和编辑状态,额外增加了人工修改状态 的能力。具体逻辑是这样的:触发interrupt中断时,系统会把待审核的文章这类数据发送给外部人工。人工查看后,如果判定内容不合格,就直接对文章进行修改,修改完成后,再通过Command对象,把编辑好的完整文章回传给工作流。
当编辑后的内容传入工作流、流程恢复执行后,节点需要做的核心操作,就是将新的、合格的文章重新写入state状态中,之后再继续执行发表等后续流程。
该场景表示在流程执行过程中,使用中断功能让人进行审查和编辑状态内容。
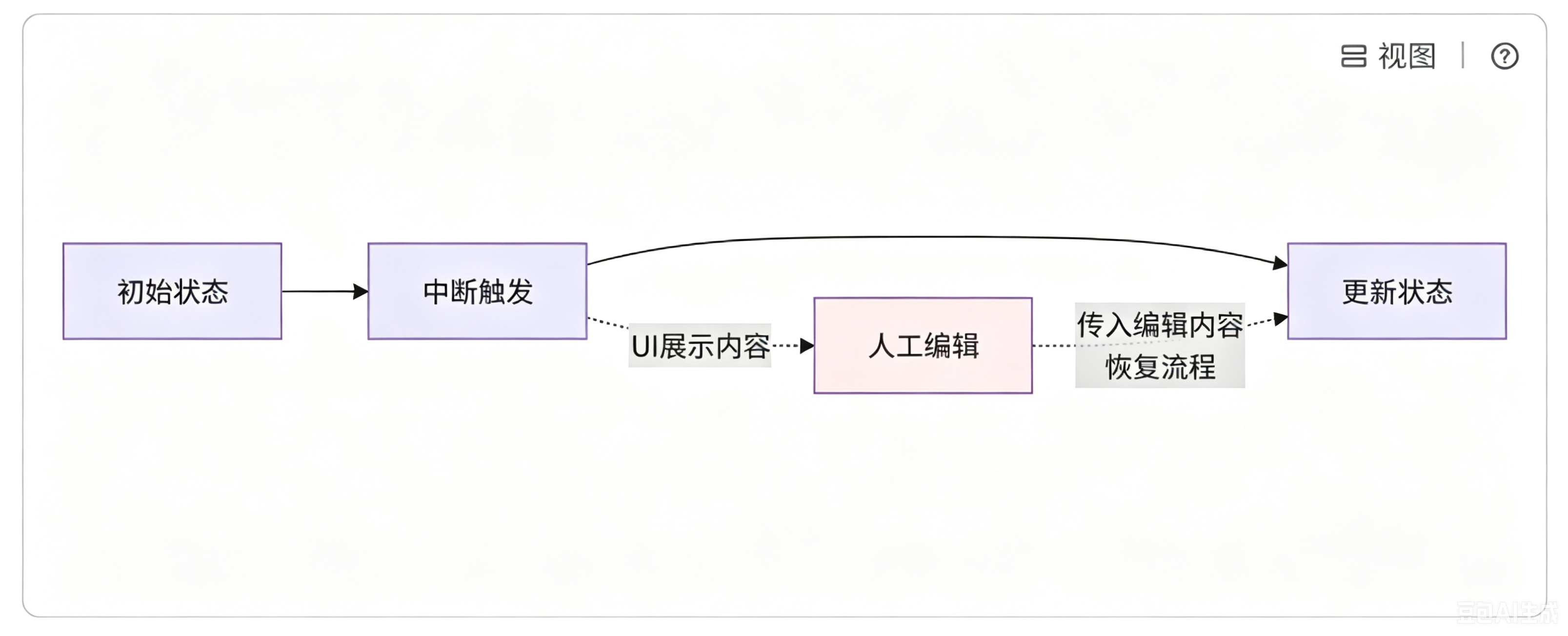
触发中断后,人工获取系统传出的数据并进行编辑;编辑完成,将新内容回传恢复工作流,节点再把更新后的内容同步到状态里。这个场景最典型的案例,就是我们反复提到的人工审核文章,接下来我们就编写代码,模拟人工审核 AI 文档内容的完整流程。
我们新建代码区域,首先定义状态。使用TypedDict来声明状态结构,状态内部只设置一个text字段,用来存放文章内容。AI 生成的文章会存入text,中断时把该字段内容传给人工审核,人工编辑完成后,再将新内容重新赋值给状态中的text。
python
class ReviewState(TypedDict):
generated_text: str状态定义完成后,开始编写节点,将节点命名为review_node。这个节点的核心功能就是触发中断,让审核人员编辑已生成的内容。我们在节点内直接调用interrupt方法,传入一个字典作为参数:字典里设置提示文案查看、编辑内容,再通过content键取出state中的text,把原始文章内容传递给外部。
python
def review_node(state: ReviewState):
# 请求审阅者编辑生成的内容
updated = interrupt({
"instruction": "查看并编辑此内容",
"content": state["generated_text"],
})
return {"generated_text": updated}外部人工编辑完成后,会通过Command对象回传新内容,这部分内容会作为interrupt的返回值,我们用变量update接收。最后直接return {"generated_text": update},把人工编辑后的内容更新到全局状态中。到这里,实现查看与编辑状态的核心节点就编写完成了,逻辑就是接收外部的编辑结果,并完成状态更新。
接下来搭建StateGraph图结构。首先绑定我们定义好的状态,添加review节点,配置基础连线:从START入口指向review节点,再由review节点指向END结束节点。
编译图的时候,必须配置checkpointer持久化存储器 ,这里使用InMemorySaver内存存储,编译完成后得到可运行的图实例。
python
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
class ReviewState(TypedDict):
generated_text: str
def review_node(state: ReviewState):
# 请求审阅者编辑生成的内容
updated = interrupt({
"instruction": "查看并编辑此内容",
"content": state["generated_text"],
})
return {"generated_text": updated}
# 构建图
builder = StateGraph(ReviewState)
builder.add_node("review", review_node)
builder.add_edge(START, "review")
builder.add_edge("review", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "42"}}
initial = graph.invoke({"generated_text": "初稿"}, config=config)
print(initial["__interrupt__"]) # -> [Interrupt(value={'instruction': ..., 'content': ...})]
# 用审阅者编辑后的文本恢复执行
final_state = graph.invoke(
Command(resume="审稿后的改进稿"),
config=config,
)
print(final_state["generated_text"]) # -> "审稿后的改进稿"随后调用invoke执行工作流。第一次调用时,传入初始状态数据,给text赋值为待审核文章,同时必须配置config并指定thread_id线程编号,这是线程级持久化的必要配置。
第一次执行会触发中断,执行结果中会包含__interrupt__字段,里面存放着我们传出的提示信息与原始文章内容。我们打印该字段下的value,就能在控制台看到查看、编辑内容以及待审核文章这段文本。
人工完成审核与编辑后,进行第二次调用恢复流程。本次不再传入原始状态,而是传入Command对象,在resume中填写编辑后的内容,例如编辑后的文章,同时沿用和第一次相同的config配置。流程恢复后,节点会自动用新内容更新状态,最后打印最终状态,可以看到text字段已经替换为人工编辑后的文本。
以上就是结合代码,对查看和编辑状态场景的完整演示。该场景广泛应用于各类内容审核工作,哪怕是一篇文章拆分出多个段落,也可以逐段进行人工审核。
除了文章审核,下面列举了更多拓展场景,底层逻辑完全一致,只是业务内容不同。
第一类:人工审查、修改大语言模型生成的文本与数据。比如 AI 生成营销文案后,交由营销专家审核优化。调用interrupt时,除了传递文案内容,还可以附加平台标识,例如platform: "douyin",明确适配的发布渠道,人工编辑完成后回传新文案即可。
人工审查和修改 LLM 生成的内容(如文本、数据)
python
# 生成营销文案后让营销专家审核
interrupt({
"instruction": "为社交媒体优化营销文案",
"content": "...", # 待审核文案
"platform": "douyin"
})第二类:提取结构化数据后,交由专业人员校验修正。比如提取产品规格信息,在中断参数中注明需要校验的字段["尺寸", "重量", "材料"],工作人员核对、修正数据后回传内容。
在继续执行前纠正错误、添加信息或进行微调
python
# 提取结构化数据后让专家验证
interrupt({
"instruction": "验证和纠正提取的产品规格",
"content": "...", # 提取的规格
"required_fields": ["尺寸", "重量", "材料"]
})第三类:代码审核场景。AI 生成Python代码后,交由开发人员审查代码效率与规范性,中断参数中标记language: "Python",开发人员查看代码、修改问题后再回传。
适用于需要质量控制或专业审核的自动化流程
python
# 生成代码后让开发人员审查
interrupt({
"instruction": "查看生成的Python函数的效率和最佳实践",
"content": "...", # 待审核代码
"language": "Python"
})注意恢复时传入的内容会完全替换原始内容。如果需要部分编辑,可以在中断载荷中标记可编辑部分。
我们还可以自定义交互协议,丰富判断逻辑。举个例子:让interrupt的返回值接收一个字典,字典包含success和content两个字段。 当success: true,代表审核通过,无需修改内容,节点就不做状态更新,保留原始文本; 当success: false,代表审核不通过,节点就取出字典中content里的新内容,覆盖原有状态文本。
按照这套自定义协议编写代码后,就能区分 "审核通过" 和 "审核驳回并修改" 两种情况,灵活性更高。
总的来说,查看和编辑状态的核心能力,就是支持人工读取、修改工作流中的状态数据,再将新内容同步回流程。在各类 AI 应用里,内容质检、人工修正类需求,基本都会用到这一功能。
到这里,第二个人机交互应用场景就讲解完毕了。
在工具中中断(Interrupts in tools)
接下来我们看第 3 种人机交互的应用场景,也就是在工具中使用中断。
在此之前,我们使用中断功能,基本都是在工作流的节点内部进行编写。而LangGraph还支持直接在自定义的tool工具函数里使用中断,不再局限于节点层面。借助这个特性,我们就能在工具被调用、正式执行之前,加入人工审查和人工干预的环节。
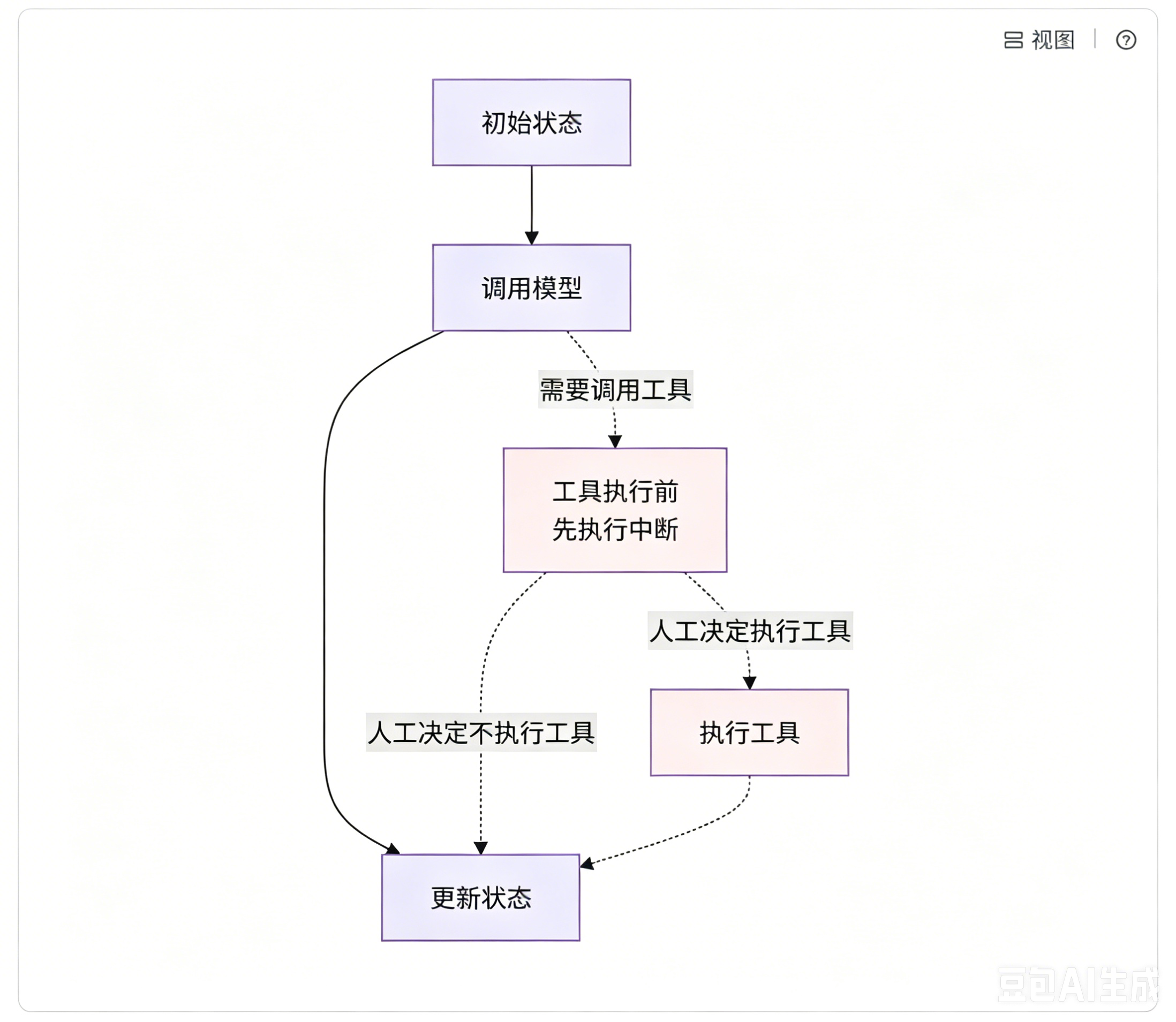
流程启动后会进入第一个节点,这个节点会调用大模型,并且该大模型提前绑定了对应的工具。大模型接收到问题后,会根据需求判断是否需要调用绑定的工具。按照常规流程,一旦判定需要调用工具,程序就会直接执行工具逻辑。但如果我们在工具函数内部 加入interrupt中断,整个流程就会发生变化:哪怕大模型已经确定要调用工具,流程依然会暂停,交由人工来判定是否真的要执行这次工具调用。
**人工拥有最终决定权:**可以选择允许工具正常执行;也可以直接拒绝,终止本次工具调用。除此之外,我们还能对工具的调用参数进行修改,这和之前 "查看和编辑状态" 场景里修改内容的逻辑类似。简单来说,大模型和工作流只负责发起调用请求,工具最终能否执行、参数是否调整,全部由人工把控。
关键特点如下:
- 中断逻辑内置于工具,而非图的节点中。
- 工具变得 "智能",知道何时需要人工批准。
- 工具可以在任何图中使用,自动具备中断能力。
这种使用方式有很明显的优势。我们之前学过两种调用工具的形式:一是将工具封装成独立节点调用,二是在普通节点的函数内部直接调用工具。而把中断写在工具内部后,这个工具就具备了通用性,在整个工作流的任意位置被调用时,都会自动触发人工审核逻辑。相当于给工具加装了一道 "统一开关",无论工作流里哪个环节发起调用,人工都可以统一管控,决定工具是否执行。
光讲解概念大家可能理解得不够透彻,接下来我们编写代码,搭建完整工作流,实操演示这个场景。本次我们模拟发送邮件的业务场景:在邮件正式发出前,人工核对收件人、邮件主题、正文内容,确认无误再发送;也可以修改邮件信息,或是直接取消发送。
首先梳理整体流程结构。我们编写一个节点,节点内部会调用绑定了邮件工具的大模型。**核心的邮件发送逻辑,单独封装成一个工具函数,中断逻辑就写在这个工具函数当中。**流程启动后,传入一条表示 "发送邮件" 的HumanMessage初始化状态。大模型识别到需求后,会返回携带工具调用指令的消息。随后程序执行对应的工具,进入工具函数内部触发中断,等待人工操作。人工完成审核、修改参数或取消操作后,流程恢复,根据人工的指令执行对应逻辑,最终整个工作流结束。
下面开始逐部分编写代码。首先定义状态,因为本次是对话交互场景,消息流转是核心,我们直接使用LangGraph内置的消息状态MessagesState即可,无需额外自定义状态结构。
第一步,定义邮件发送工具。使用@tool装饰器声明这是工具函数,函数设置三个入参:to代表收件人、subject代表邮件主题、body代表邮件正文。工具的作用是模拟发送邮件,我们并不会真实调用邮件服务,仅通过字符串返回结果做演示。
python
@tool
def send_email(to: str, subject: str, body: str):
"""发送电子邮件给收件人"""
# 在发送前暂停
response = interrupt({
"action": "发送邮件",
"to": to,
"subject": subject,
"body": body,
"message": "同意发送这封邮件吗?",
})
if response.get("action") == "同意":
final_to = response.get("to", to)
final_subject = response.get("subject", subject)
final_body = response.get("body", body)
# 实际发送邮件(此处为示例,仅打印)
email_info = f"收件人: {final_to} 主题: {final_subject} 正文: {final_body}"
print(f"[发送邮件] {email_info}")
return email_info
return "用户取消邮件"在工具函数的最前端,先调用interrupt触发中断。我们向外部传递一个字典,包含操作类型action、收件人to、主题subject、正文body,同时附上提示语同意发送这封邮件吗?。外部人工的操作结果,会作为interrupt的返回值,我们用变量接收这部分数据。
这里我们自定义一套交互协议: 人工通过返回字典里的action字段表达意图。如果填写不同意 ,代表取消本次邮件发送;如果填写同意 ,则允许发送,同时还可以选择性传入新的to、subject、body,实现参数修改。
拿到中断的返回结果后,先做逻辑判断。如果action为不同意 ,直接返回字符串用户取消发送邮件,终止本次工具执行。 如果是同意发送,就解析参数:优先使用人工新传入的收件人、主题、正文;若人工没有修改参数,就沿用工具原本接收到的入参。最后拼接邮件信息并打印,模拟邮件发送成功,同时返回对应的结果字符串。到这里,带中断功能的邮件工具就编写完成了。
第二步,编写工作流的核心节点。这个节点需要完成两件事:调用绑定工具的大模型、解析模型返回结果并执行工具。 首先初始化大模型,并通过bind_tools绑定我们刚刚编写的邮件工具。接着调用模型,传入系统提示词与状态中的对话消息,系统提示词用于告知模型可以调用邮件发送工具。
python
# 使用绑定工具的模型
model_with_tools = init_chat_model("gpt-4o-mini", temperature=0).bind_tools([send_email])
# 这里的 dict 仅仅是继承的用法
def llm_call(state: dict):
"""LLM 决定是否调用工具"""
messages = model_with_tools.invoke(
[SystemMessage(content="你支持调用工具进行邮件发送。")]
+ state["messages"]
)
# 直接调用工具(为了演示效果)
if messages.tool_calls:
tool_call = messages.tool_calls[0]
tool_result = send_email.invoke(tool_call["args"])
return {"messages": [
ToolMessage(content=tool_result, tool_call_id=tool_call["id"])
]}
return {"messages": [messages]}模型执行完毕后会返回消息对象,我们判断消息中是否存在工具调用指令tool_calls。如果存在,说明模型判定需要调用工具:取出第一条工具调用的参数,手动执行工具的invoke方法,得到工具运行结果。之后按照消息格式规范,构造ToolMessage,填入工具返回内容与对应的调用 ID。 如果消息中没有工具调用指令,就直接将模型返回的消息作为结果传出。最终把消息更新到状态中,完成当前节点的逻辑。
第三步,搭建并编译图结构。创建StateGraph并绑定消息状态,把刚刚编写的节点加入图中。配置基础连线:从入口START指向该节点,节点执行完成后指向END结束节点。 编译图时,必须配置持久化存储器,这里依旧使用InMemorySaver内存存储,编译完成后得到可运行的图实例。同时定义config配置项,设置唯一的thread_id,这是中断功能正常运行的必要条件。
python
import operator
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
from langchain.tools import tool
from langchain_core.messages import AnyMessage, SystemMessage, ToolMessage, HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import interrupt, Command
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
@tool
def send_email(to: str, subject: str, body: str):
"""发送电子邮件给收件人"""
# 在发送前暂停
response = interrupt({
"action": "发送邮件",
"to": to,
"subject": subject,
"body": body,
"message": "同意发送这封邮件吗?",
})
if response.get("action") == "同意":
final_to = response.get("to", to)
final_subject = response.get("subject", subject)
final_body = response.get("body", body)
# 实际发送邮件(此处为示例,仅打印)
email_info = f"收件人: {final_to} 主题: {final_subject} 正文: {final_body}"
print(f"[发送邮件] {email_info}")
return email_info
return "用户取消邮件"
# 使用绑定工具的模型
model_with_tools = init_chat_model("gpt-4o-mini", temperature=0).bind_tools([send_email])
# 这里的 dict 仅仅是继承的用法
def llm_call(state: dict):
"""LLM 决定是否调用工具"""
messages = model_with_tools.invoke(
[SystemMessage(content="你支持调用工具进行邮件发送。")]
+ state["messages"]
)
# 直接调用工具(为了演示效果)
if messages.tool_calls:
tool_call = messages.tool_calls[0]
tool_result = send_email.invoke(tool_call["args"])
return {"messages": [
ToolMessage(content=tool_result, tool_call_id=tool_call["id"])
]}
return {"messages": [messages]}
builder = StateGraph(MessagesState)
builder.add_node("llm_call", llm_call)
builder.add_edge(START, "llm_call")
builder.add_edge("llm_call", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "email-workflow"}}
initial = graph.invoke({
"messages": [HumanMessage(content="发送电子邮件至 alice@example.com,主题是:请假,内容是:理由如下...")]
}, config=config)
print(initial["__interrupt__"]) # -> [Interrupt(value={'action': ..., ...})]
# 用批准和可选编辑的参数恢复
resumed = graph.invoke(
Command(resume={
"action": "同意",
"subject": "病假"
}),
config=config
)
print(resumed["messages"][-1]) # -> 工具调用结果接下来开始调用执行,分多种场景测试效果。 第一次调用,传入初始的HumanMessage,内容为指定收件人、邮件主题 "请假" 以及正文。程序运行后会触发中断,控制台打印出中断携带的全部信息,包含操作类型、原始收件人、主题、正文和审核提示,说明流程成功停在了工具内部。
第一种测试场景:人工选择同意 ,不修改任何参数。调用Command恢复流程,resume中传入{"action": "同意"}。流程恢复后,工具沿用原始参数模拟发送邮件,控制台打印出完整的邮件信息,最终状态里的ToolMessage也同步显示发送成功的结果。
第二种测试场景:人工选择同意 ,同时修改邮件主题。恢复流程时,除了action为同意,额外传入新的主题请病假。运行后可以看到,最终发送的邮件主题已经被替换为修改后的内容,收件人和正文保持不变,参数修改功能生效。
第三种测试场景:人工选择不同意 ,取消发送。恢复流程时传入{"action": "不同意"},工具直接返回用户取消发送邮件,不会执行邮件发送逻辑。
通过多组测试可以验证:将中断写在工具内部后,相当于给工具设置了统一管控开关。无论工作流中哪个环节调用这个工具,都会触发人工审核,工具能否执行、参数是否调整,全部由人工决定。
以上就是第三个人机交互场景 ------在工具中使用中断的全部内容。
验证人工输入(Validating human input)
接下来我们看最后一种人机交互的应用场景:验证人工输入。
我们结合实际案例来讲解。假设我们开发了一个对话式智能体,一边是用户,一边是 AI。用户向 AI 发起请求:帮我注册一款 APP 账号。按照常规流程,智能助手会直接执行注册操作。但这款 APP 注册时,要求用户提供手机号、姓名、年龄等信息。如果工作流执行过程中检测到资料缺失,就会触发交互弹窗。
弹窗会提示用户补充信息,界面上配有手机号、姓名对应的输入框,以及确定按钮。用户填写信息并点击确定后,系统会继续执行注册流程。如果用户填写的手机号格式错误,后台校验不通过,就会再次弹出提示框,要求用户重新输入,直到所有信息校验合格,最终完成账号注册。
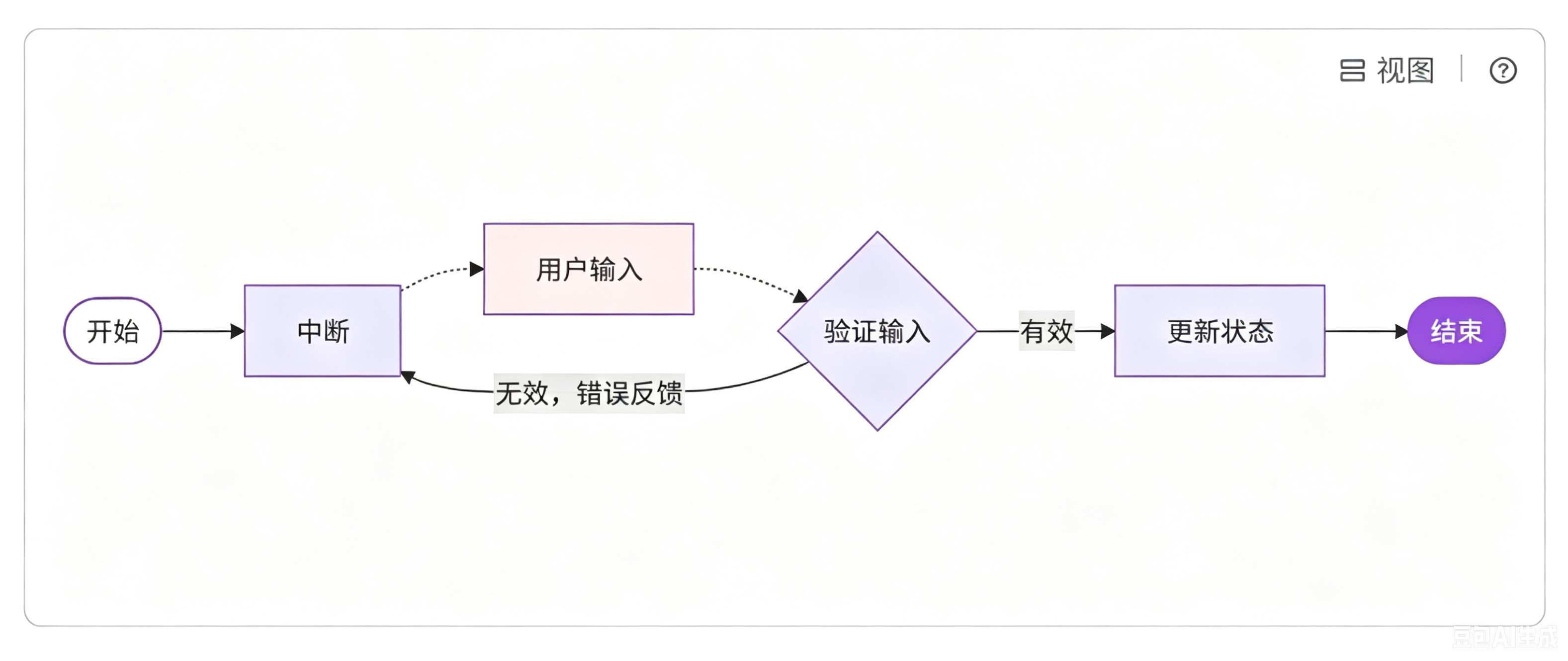
对应到工作流逻辑中: 整个流程的核心任务是根据用户提供的手机号、姓名等信息完成 APP 注册。当检测到信息缺失或内容无效时,就调用中断 暂停流程,弹出输入提示等待用户填写内容。用户提交信息后,系统自动开展校验:数据有效则继续执行后续流程;数据无效,就再次触发中断,引导用户重新输入。这就是循环输入、循环验证的逻辑,该过程会一直重复,直到用户输入合法内容为止。
接下来我们通过代码实现这套逻辑。新建代码文件,首先定义状态结构体。本次案例简化需求,仅以年龄输入验证 为例,状态中只设置age字段,用于存储用户填写的年龄,初始化时将其置为空值。
python
class FormState(TypedDict):
age: int | None状态定义完成后,开始编写节点函数,将节点命名为get_age_node。这个节点的功能是循环获取用户输入的年龄,并完成合法性校验。我们在节点内部调用interrupt触发中断,首次展示的提示语为:请输入年龄。中断的返回值就是用户填写的内容,我们用变量接收。
python
def get_age_node(state: FormState):
prompt = "你多大了?"
while True:
answer = interrupt(prompt) # 有效载荷出现在 result["__interrupt__"] 中
if isinstance(answer, int) and answer > 0:
return {"age": answer}
# 每次验证失败后,提示信息会更新
prompt = f"'{answer}' 不是一个有效的年龄。请输入正数。"年龄的校验规则设定为:必须是整数,且数值大于 0。代码中通过isinstance判断数据类型,同时判断数值大小。如果输入内容符合规则,直接return将合法年龄更新到状态中,流程继续向下执行。
如果输入内容校验失败,就需要重复引导用户输入。这里我们使用while死循环实现循环逻辑。同时定义一个提示字符串变量,首次使用默认提示语;校验失败后,更新提示内容,明确告知用户错误原因以及正确输入要求:请输入一个有效的年龄,需要大于 0 岁且是一个整数。更新后的提示语会随下一次中断传递给用户,让用户清楚问题所在。
节点逻辑编写完成后,开始搭建StateGraph图结构。绑定刚刚定义的状态,添加get_age_node节点,配置基础连线:从START入口指向该节点,节点执行完毕后指向END结束节点。
编译图的时候,必须配置持久化存储器,这里使用InMemorySaver内存存储。编译完成后得到可运行的图实例。调用invoke执行工作流,同时配置config并指定thread_id线程编号,这是中断功能正常运行的必要配置,初始状态中age赋值为空。
python
from typing import TypedDict
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command, interrupt
class FormState(TypedDict):
age: int | None
def get_age_node(state: FormState):
prompt = "你多大了?"
while True:
answer = interrupt(prompt) # 有效载荷出现在 result["__interrupt__"] 中
if isinstance(answer, int) and answer > 0:
return {"age": answer}
# 每次验证失败后,提示信息会更新
prompt = f"'{answer}' 不是一个有效的年龄。请输入正数。"
# 构建图
builder = StateGraph(FormState)
builder.add_node(get_age_node)
builder.add_edge(START, "get_age_node")
builder.add_edge("get_age_node", END)
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "form-1"}}
# 首次调用: 显示初始提示
first = graph.invoke({"age": None}, config=config)
print(first["__interrupt__"]) # -> [Interrupt(value='你多大了?', ...)]
# 提供无效数据: 节点重新提示
retry = graph.invoke(Command(resume="三十"), config=config)
print(retry["__interrupt__"]) # -> [Interrupt(value="'三十' 不是一个有效的年龄...", ...)]
# 提供有效数据: 循环退出,状态更新
final = graph.invoke(Command(resume=30), config=config)
print(final["age"]) # -> 30第一次调用流程会触发中断,我们打印__interrupt__中的内容,控制台会输出初始提示请输入年龄,此时流程暂停,等待用户输入。
我们分场景进行测试。第一次测试,传入字符串格式的内容模拟无效输入。流程恢复后会再次触发中断,控制台展示更新后的错误提示,提醒用户输入规范。
第二次测试,传入合法的数字,例如18。本次校验通过,循环终止,节点将合法年龄更新到状态中,流程直接走到结束节点。打印最终状态,可以看到age字段成功赋值为18,功能符合预期。
本案例中我们仅做了简单的年龄校验,基于这套逻辑,还可以拓展出更复杂的校验规则。比如手机号校验,要求必须是 11 位纯数字;身份证号、邮箱等信息,也都可以按照对应的格式规则编写校验逻辑,底层依旧使用 "中断 + 循环" 的实现方式。
验证人工输入这个场景,应用范围非常广泛。最典型的就是各类平台的用户注册流程,除此之外,线上工单创建、线上表单信息采集等所有需要收集并校验用户信息的场景,都可以使用该方案实现。
到这里,人机交互对应的四种应用场景就全部讲解完毕了。通过案例和代码实操,相信大家已经掌握了LangGraph里中断功能的使用方式,也理解了中断的应用价值。现如今绝大多数智能应用,都会涉及人机交互能力,所以我们不仅要熟悉各类业务场景,更要牢记中断功能的使用规则与限制,这样才能在实际开发中灵活、规范地运用这项能力。