构建有效 AI Agent:图解工程实践版
基于 Anthropic Engineering 文章 Building effective agents 整理。
0. 决策地图:先选模式,再看细节

核心心法:先用最简单方案解决问题;只有评估数据证明不够,再升级到工作流或自主 Agent。
按顺序问自己四个问题:
- 单次调用够不够? ------ 提示词 + 上下文示例 + 检索片段先跑通基线。
- 任务步骤能否写死? ------ 步骤可预判就上 Workflow,不必引入动态规划。
- 是否需要动态规划? ------ 真正路径不可预知时才考虑 Agent。
- 风险边界是否可控? ------ 沙箱、停止条件、人工审批必须先就位。
得到的三条路径,对应本文后续章节:
|-----------------------|-----------------------|----|
| 路径 | 适用场景 | 详见 |
| A. 先做增强型 LLM | 单/少次调用,叠加检索、工具、记忆即可解决 | §2 |
| B. 固定任务用 Workflow | 步骤可预先编排,流程稳定可复用 | §3 |
| C. 开放任务用 Agent | 路径不可预知,需要动态规划与反馈循环 | §4 |
判断标准:不要因为"能做成 Agent"就做 Agent;只有当复杂度带来的收益超过成本和风险时,才值得升级。
关键词速记:简单优先 · 按需升级 · 模式可组合 · 工具接口工程化 · 评估驱动迭代。
1. Workflow 和 Agent 的本质区别
|----------|-----------------|------------------------|
| 类型 | 谁控制流程 | 适合场景 |
| Workflow | 开发者预先编排路径 | 步骤清楚、分支可预判、需要稳定输出 |
| Agent | LLM 动态决定步骤和工具使用 | 开放任务、步骤不可预知、需要持续根据反馈调整 |
简单说:Workflow 是"人写好流程,模型执行其中一部分";Agent 是"给模型目标和工具,让模型自己推进任务"。
Agentic system 会提升复杂任务表现,但代价是更高成本、更长延迟、更难调试和更大的错误累积风险。复杂度必须由评估结果证明,而不是由技术偏好决定。
2. 路径 A:增强型 LLM(一切的基础单元)
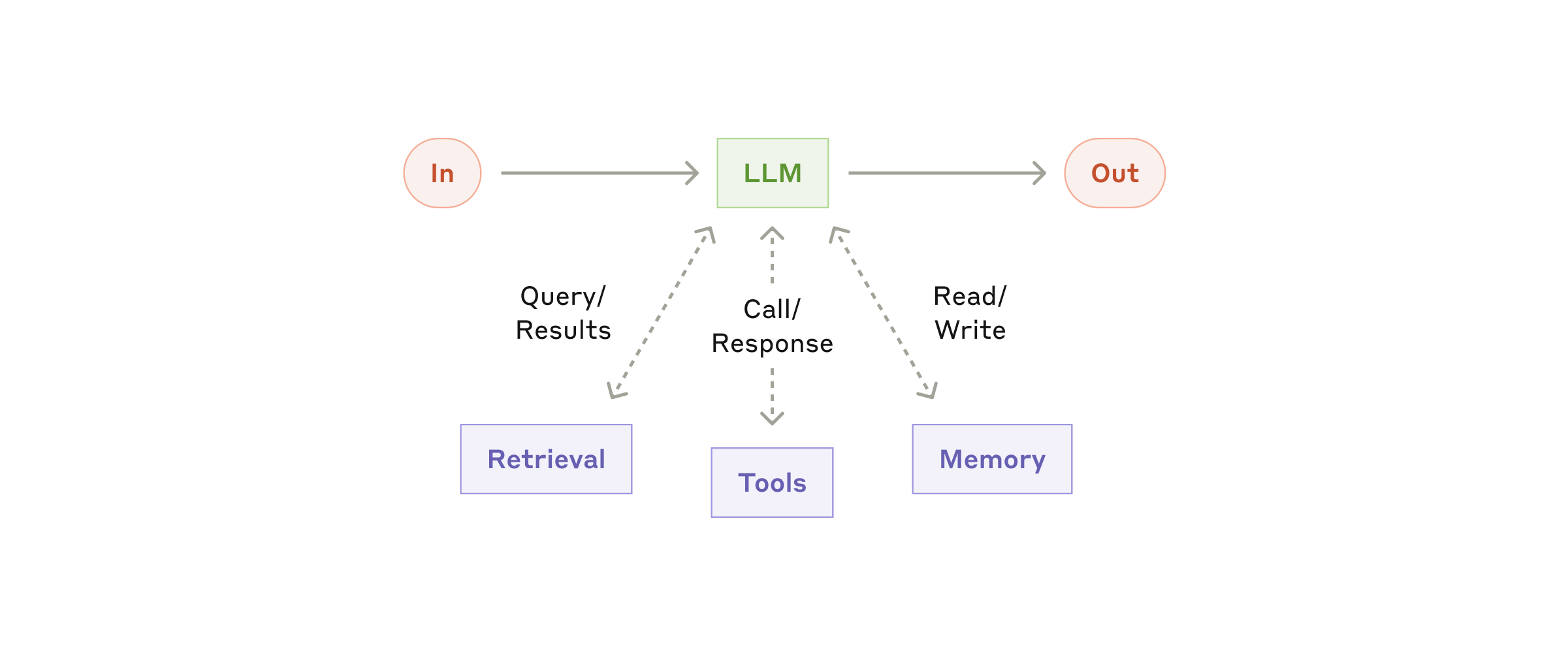
增强型 LLM 是所有 Agentic system 的底座,通常包含三类能力:
- Retrieval:查询外部知识、业务文档或搜索结果。
- Tools:调用 API、数据库、代码执行、文件系统等工具。
- Memory:保留跨轮任务状态、偏好或历史信息。
关键不是"工具越多越好",而是工具接口要清楚、权限要可控、错误要可追踪。
升级判断:用成功率、成本、延迟、可解释性这些指标判断是否需要进入路径 B 或路径 C,避免凭感觉堆复杂度。
3. 路径 B:常见 Workflow 模式
适用前提:任务能拆成相对固定的步骤,开发者愿意为稳定性把流程写死。下面五种模式可单独使用,也可以组合。

3.1 Prompt Chaining:提示词链
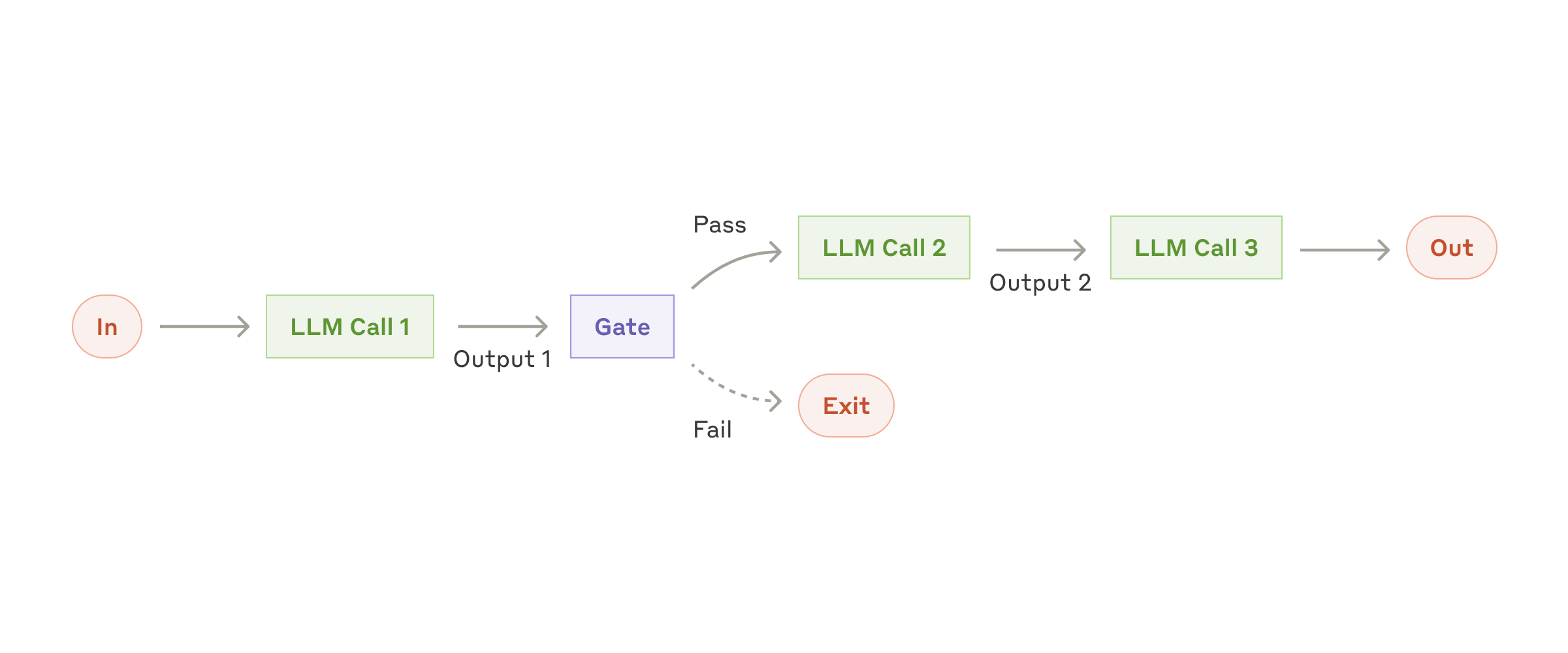
把复杂任务拆成固定步骤,每一步只处理一个更小的问题,中间可以加校验。
适合:先生成大纲再写正文、先提取结构化信息再生成报告、先写文案再翻译。
注意:它是用延迟换准确率;如果步骤无法固定,就不适合。
3.2 Routing:路由
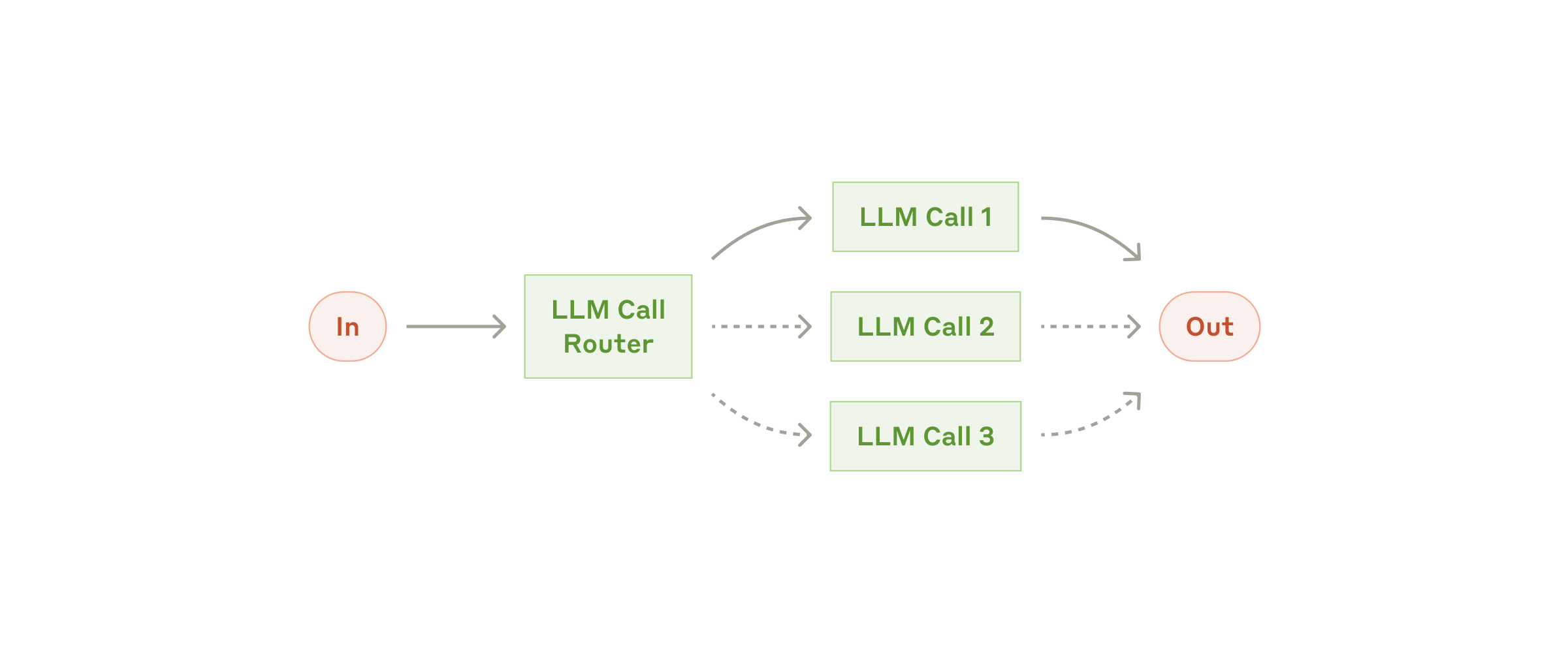
先识别输入类型,再分发到不同模型、提示词、工具或业务流程。
适合:客服分流、复杂问题升级到更强模型、不同业务线走不同知识库。
注意:路由准确性是关键;分类错了,后续流程很容易被带偏。
3.3 Parallelization:并行化
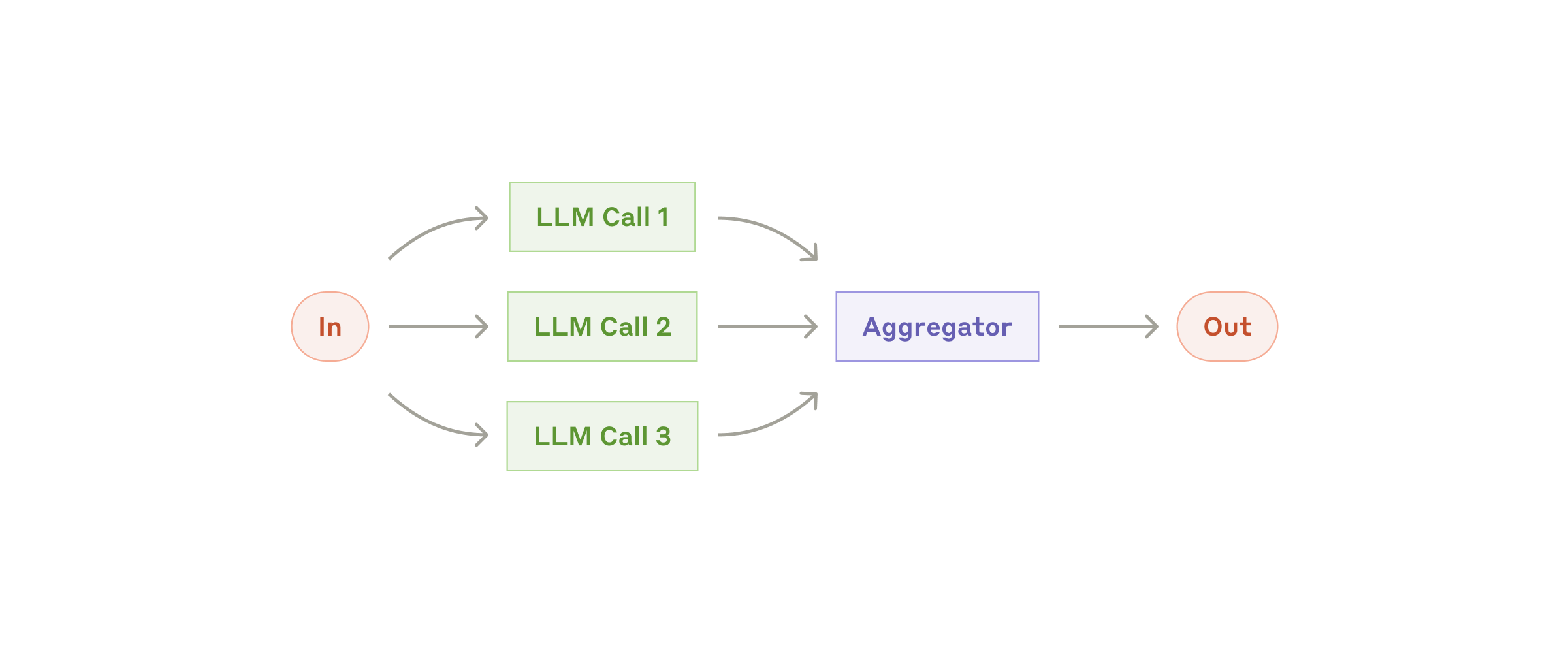
多个 LLM 调用并行执行,再由程序聚合结果。
适合:多维度评估、安全审查、多视角投票、互不依赖的子任务。
注意:必须有清晰的聚合规则,否则只是把复杂度推迟到最后。
3.4 Orchestrator-Workers:编排者与执行者
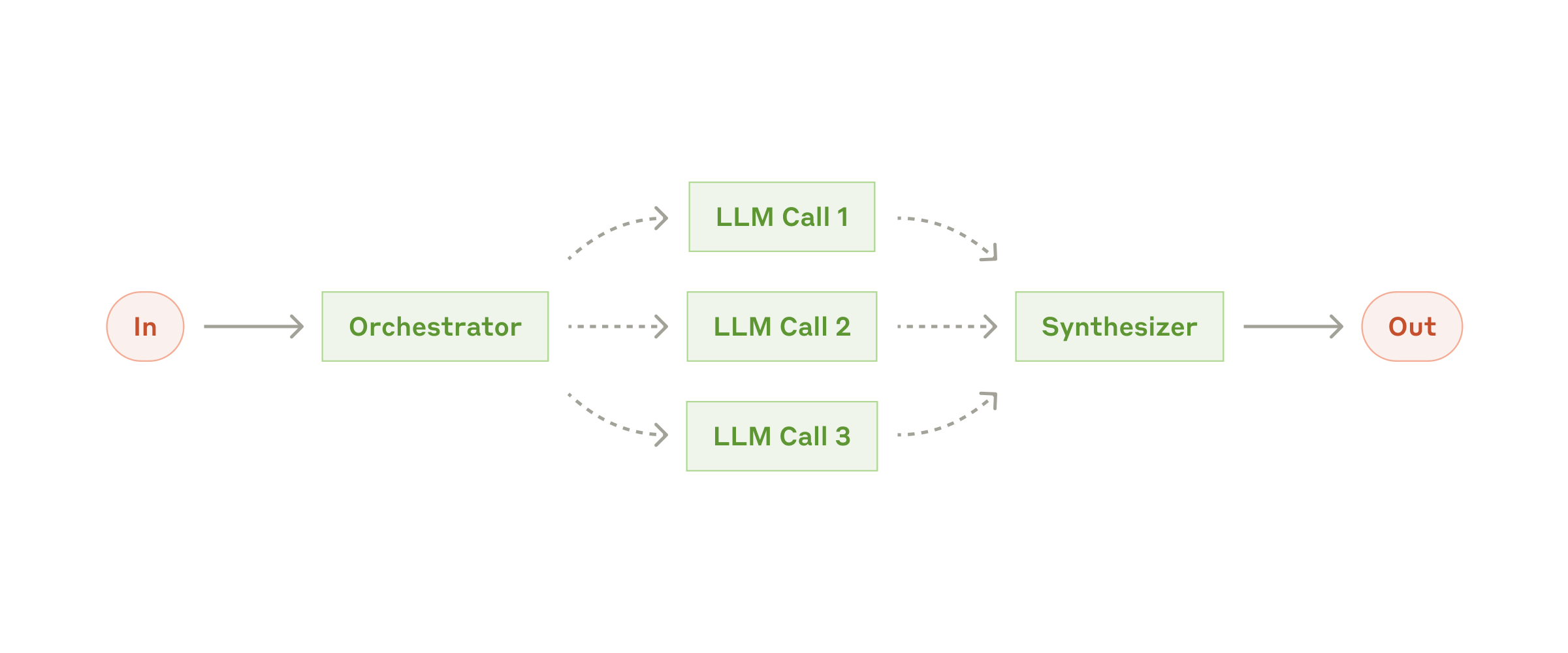
中心 LLM 动态拆解任务,分配给多个 worker,再综合结果。
适合:代码修改、复杂搜索、多来源分析。
和并行化的区别:并行化的子任务通常预先定义;这里的子任务由编排者动态决定。
3.5 Evaluator-Optimizer:评估器与优化器
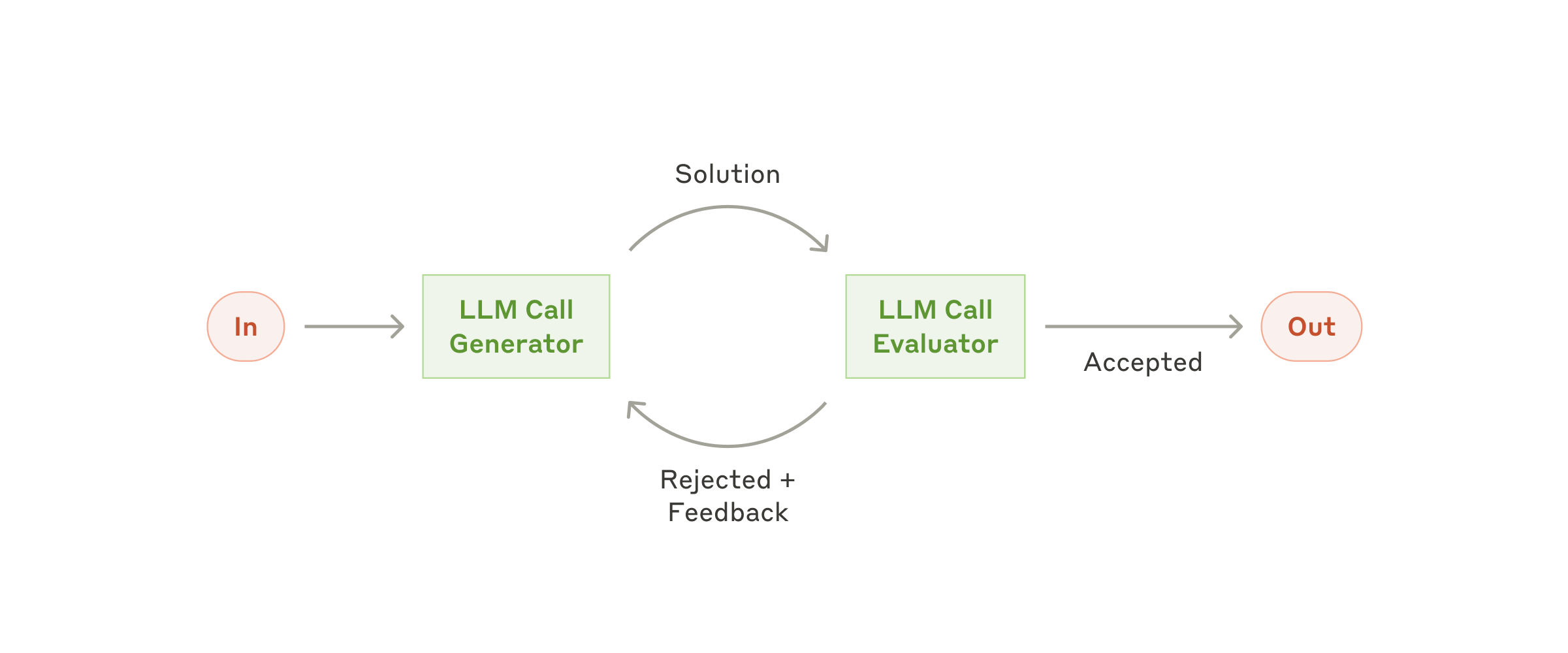
一个 LLM 负责生成,另一个 LLM 负责评价和反馈,形成迭代闭环。
适合:写作、翻译、代码生成、搜索总结等可迭代优化任务。
注意:必须有明确评价标准和停止条件,否则容易变成成本黑洞。
4. 路径 C:自主 Agent
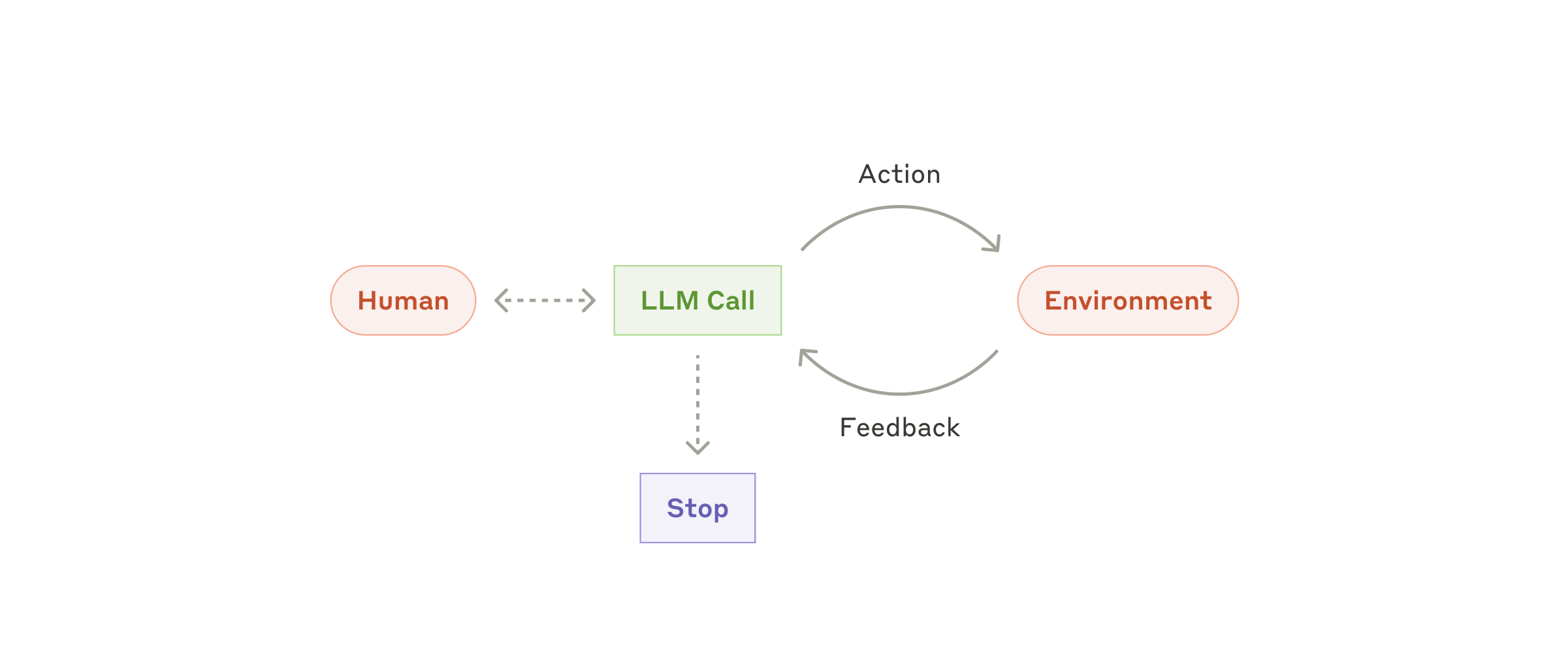
Agent 适合任务路径无法预先写死的场景。它会在"计划 → 调工具 → 看反馈 → 调整计划"的循环中推进任务。
4.1 何时值得上 Agent
适合:
- 步骤数量和执行路径不可预测。
- 需要连续使用工具和环境反馈。
- 成功标准清楚,能通过测试、日志、用户确认或业务结果验证。
4.2 上线必须具备的护栏
- 沙箱和最小权限。
- 最大迭代次数、超时和停止条件。
- 轨迹日志和人工检查点。
4.3 案例:编码 Agent
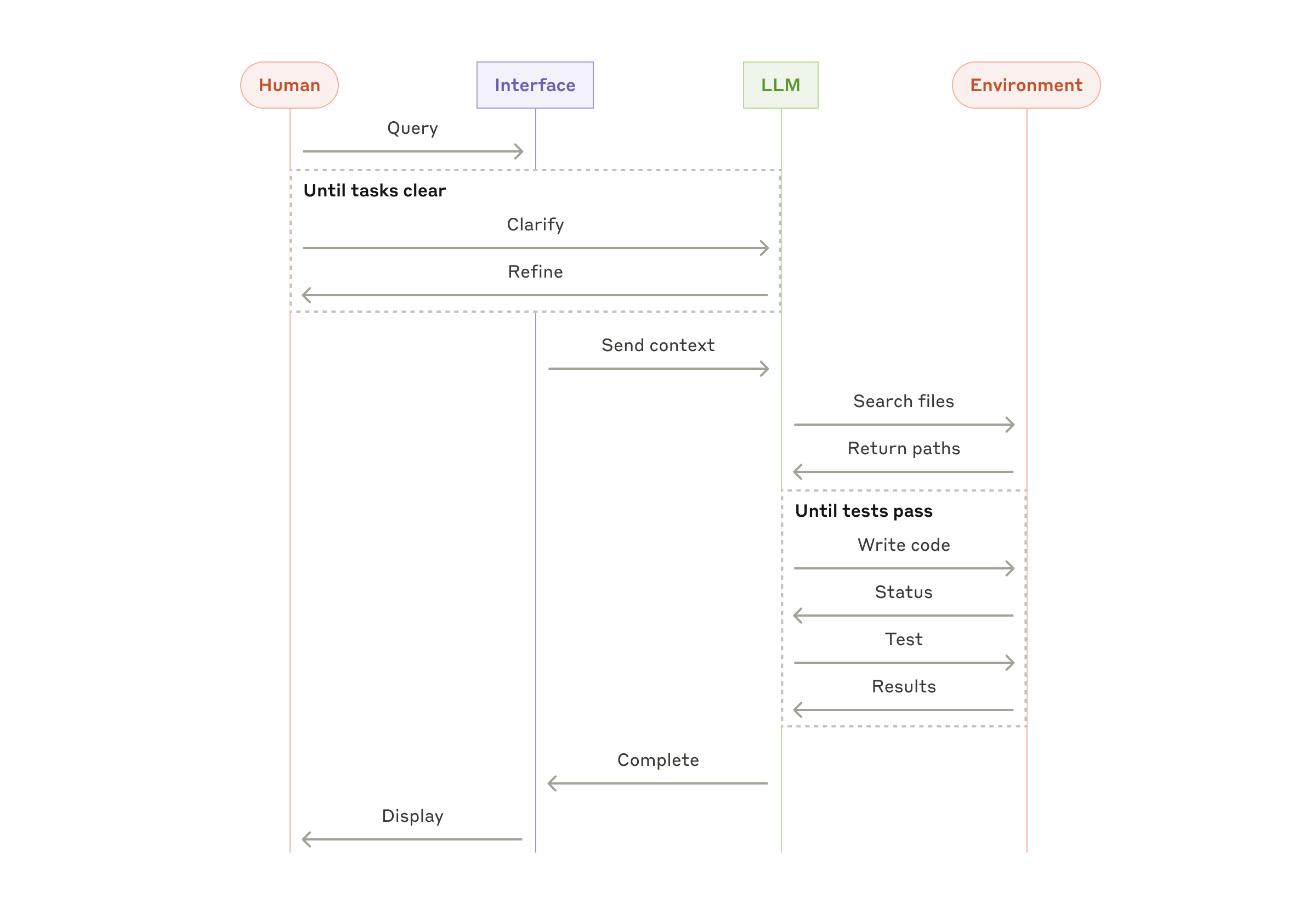
编码 Agent 容易落地,是因为反馈闭环明确:文件变更、测试结果、类型检查、diff 和 code review 都能帮助模型修正下一步。
但自动测试只能验证一部分正确性,最终仍需要人工审查架构一致性、可维护性和边界条件。
5. 工程化要点
5.1 框架使用建议
框架能降低上手成本,但也会遮住真实 Prompt、模型响应和工具调用,导致调试困难。
建议:
- 先用 LLM API 做最小可行路径。
- 把 Prompt、工具调用和评估指标跑稳定。
- 再考虑把重复模式沉淀成框架或接入现成框架。
5.2 工具接口设计:Agent 成败的关键
很多 Agent 问题不是模型不够强,而是工具太难用。
好的工具接口应该做到:
- 工具名和参数名清楚,不让模型猜。
- 描述包含用途、边界、示例和常见错误。
- 返回可行动的错误信息。
- 用结构约束避免误用,例如枚举值、必填字段、绝对路径、权限范围。
可以把工具说明当成写给初级工程师的 API 文档。如果人看了都要猜,模型更容易猜错。
6. 落地检查清单
- 单次 LLM 调用是否已经足够?
- 是否能通过检索、上下文示例或工具调用解决?
- 是否有清晰评估指标:成功率、延迟、成本、误报率、漏报率?
- 任务步骤是否能预先写死?如果能,优先 Workflow。
- 是否真的需要模型动态规划?
- 工具权限是否最小化?
- 是否有最大迭代次数、超时和停止条件?
- 高风险动作是否有人审或显式确认?
7. 最终原则
不要为了"做 Agent"而做 Agent。有效系统通常从简单方案开始,用评估发现瓶颈,再逐步增加复杂度。
生产级 Agent 最重要的不是"更自主",而是:可观测、可控制、可调试、可评估。