文章目录
- 概述
- ReAct:推理与行动的闭环
- Self-Reflection:用自我评估提升输出质量
- [MCP Tool Use:基于 MCP 的轻量级工具集成](#MCP Tool Use:基于 MCP 的轻量级工具集成)
- [CodeAct:用可执行代码替代僵硬 JSON](#CodeAct:用可执行代码替代僵硬 JSON)
- [Multi-Agent Workflow:协作式问题解决](#Multi-Agent Workflow:协作式问题解决)
- [Agentic RAG:检索增强的智能化演进](#Agentic RAG:检索增强的智能化演进)
- 架构对比与组合建议
- 实战落地建议与结语
- 补充资料
-
-
- [一、ReAct:推理 × 行动 的核心思想](#一、ReAct:推理 × 行动 的核心思想)
- [二、Agent、Tool 与 MCP(模型如何"用工具")](#二、Agent、Tool 与 MCP(模型如何“用工具”))
- 三、Multi-Agent:一个模型不够,那就一群
- [四、Agentic RAG:RAG 进入"会思考"阶段](#四、Agentic RAG:RAG 进入“会思考”阶段)
- [五、反思(Reflection):Agent 为什么能变聪明](#五、反思(Reflection):Agent 为什么能变聪明)
- 六、学术论文(可作为博客的理论支柱)
- 七、工程与实践补充
- 八、趋势与案例
-

概述
多模态 AI Agent 的 6 大设计模式,可以组合出当下主流的大模型应用架构:
- 用 ReAct 驱动推理与工具调用,
- 用 Self-Reflection 控制质量,
- 用 MCP 与 CodeAct 扩展工具与执行力,
- 再通过 Multi-Agent 与 Agentic RAG 把复杂任务拆解并接入海量知识源。
接下来我们从工程落地角度,系统梳理这 6 种模式的原理、适用场景与实践建议。
核心问题:如何把一个"只会对话的大模型",演化成"能自己思考、调用工具、协作与检索"的智能体系统,并在真实业务中可控、可维护、可扩展。
以"从单体智能,到可协作的智能系统"为主线,依次介绍:ReAct、Self-Reflection、MCP Tool Use、CodeAct、Multi-Agent Workflow、Agentic RAG 六种模式,并穿插工程实践建议。
ReAct:推理与行动的闭环
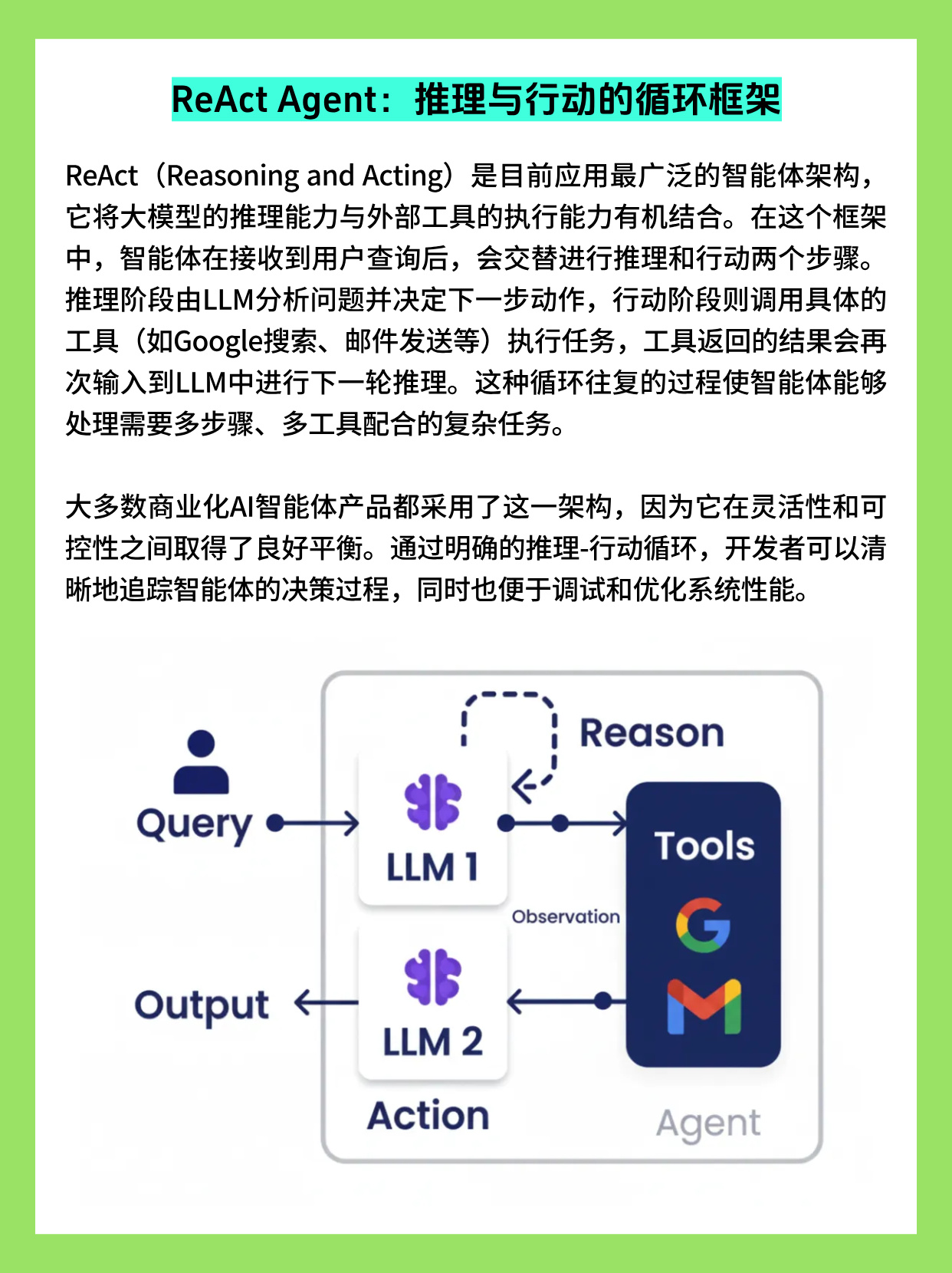
ReAct(Reasoning + Acting)是一种让大模型在"思考"与"使用工具"之间交替迭代的通用范式:每一步先输出推理思路,再选择行动(调用搜索、数据库、API 等),再根据反馈继续推理。
研究表明,这种"Thought → Action → Observation"的循环能显著提升复杂推理与决策任务上的表现,并且使推理轨迹对人类更可解释、可诊断。
在工程实践中,可以按以下方式落地 ReAct:
- 把 Agent 设计成一个循环:模型读入当前对话历史与工具观测结果,生成下一步"思考 + 工具调用";一旦模型认为可以给出最终答案,就结束循环并返回结果。
- 工具层抽象为统一接口(如
search(query)、db_query(sql)),由中间件执行真实调用并返回结构化 Observation,避免模型直接拼接底层 API 细节。
注意控制:
- 设置最大循环轮数与令牌上限,防止"过度思考"导致成本失控。
- 对 Thought 部分做审计与日志记录,为后续调试与安全审查提供依据。
Self-Reflection:用自我评估提升输出质量
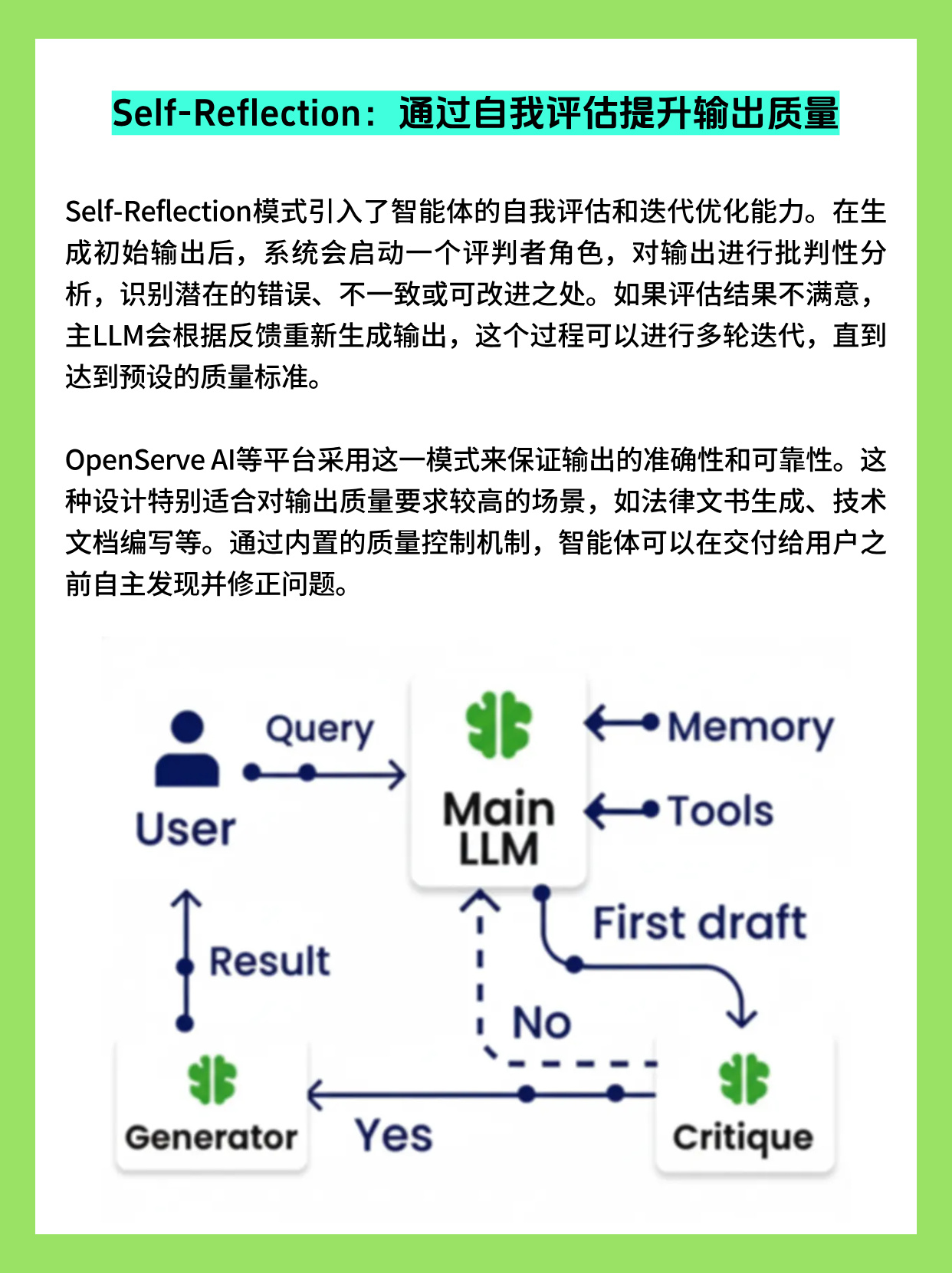
Self-Reflection 模式在主任务链路之外,引入一个"自我审稿"的环节,让模型对自己的中间结果进行评价与修正,从而显著提升答案的正确性、一致性与安全性。
最新研究与工程经验显示,引入反思与批判步骤后,在数学推理、代码生成、知识问答等任务上的正确率都有明显提升,并能减少有害或偏见输出。
一种典型实现是"三段式 Agent":
- 主 LLM 先根据用户请求与工具结果生成 "First Draft";
- 反思 LLM(可与主模型相同或更小)阅读草稿,给出错误分析与修改建议;
- 主 LLM 依据评语重写答案,必要时可以多轮迭代,直到通过质量门槛或达到轮数上限。
工程要点:
- 反思提示中明确质量标准:事实准确性、逻辑一致性、代码可执行、安全合规等,避免空泛评价。
- 对高风险场景(法律、医疗、金融)可以强制启用 Self-Reflection,并结合规则/检索进一步校验结论。
MCP Tool Use:基于 MCP 的轻量级工具集成
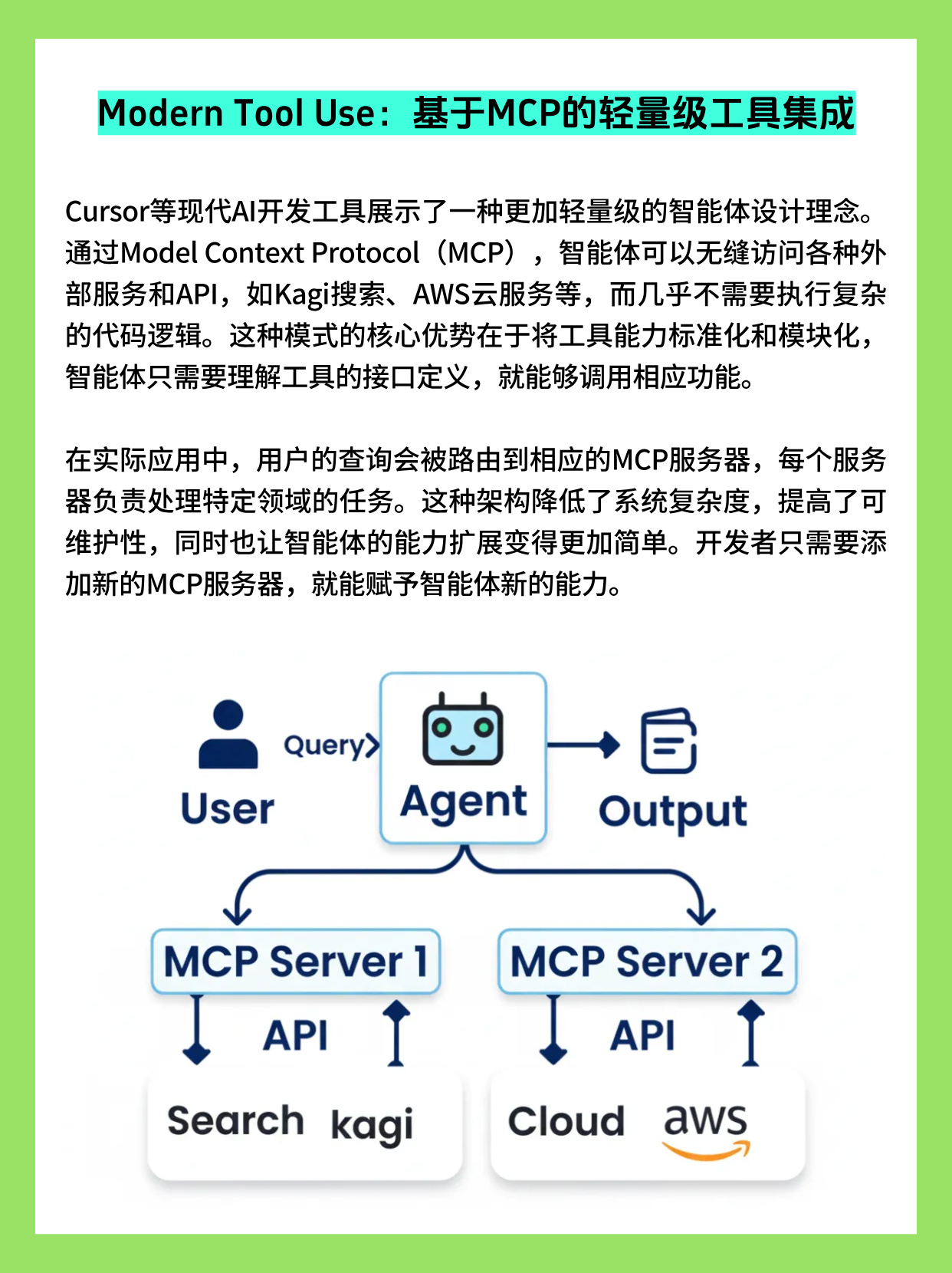
随着 Agent 场景爆发,工具生态迅速膨胀,如何低成本、安全地把各种 API 暴露给模型调用,成为系统设计的关键问题。
Model Context Protocol(MCP)提供了一个通用协议层,让"工具服务器"通过统一的接口向 LLM 客户端暴露可调用的函数(Tools),支持动态发现、热更新与跨语言实现。
工程实践中的优势主要体现在:
- 标准化:每个 MCP Server 声明自己提供的工具清单与参数模式,客户端可以在运行时列出工具、加载文档并生成合适的 Tool Call 提示。
- 解耦与扩展:Agent 只感知 MCP 抽象,而不依赖具体云厂商或第三方 API;新增一个能力往往只需部署新的 MCP Server 并在配置中启用即可。
落地建议:
- 将"搜索""内部业务系统""云计算任务"等能力分别做成独立 MCP Server,由统一的 Agent 编排调用,便于权限隔离与团队协作开发。
- 在网关层增加审计与速率限制,对 MCP 调用进行计量和安全控制。
CodeAct:用可执行代码替代僵硬 JSON
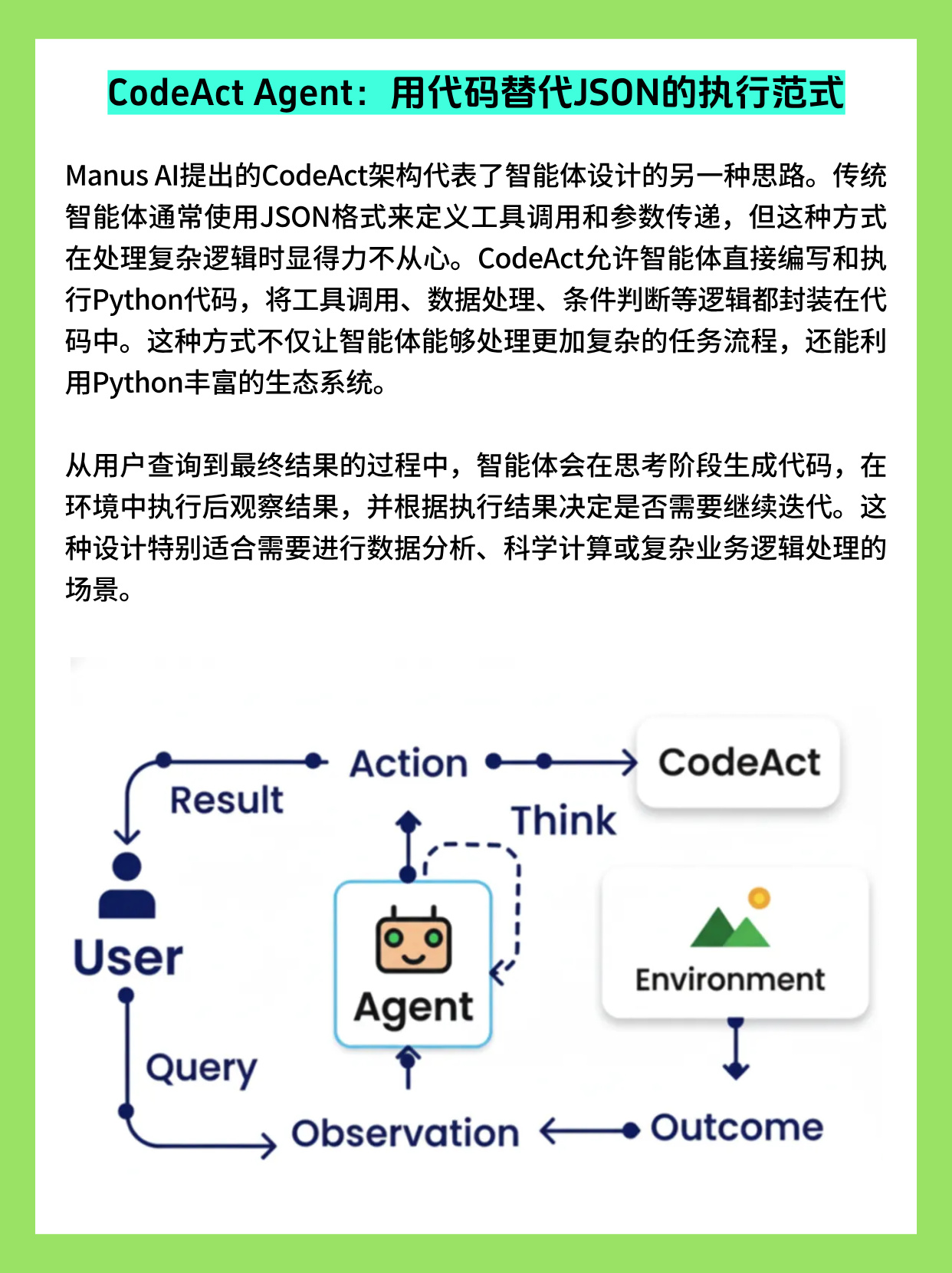
传统 Agent 通常让模型输出 JSON 指令,如 { "tool": "search", "args": {...} },对复杂流程(多步运算、条件分支、循环)则显得笨重且难以维护。
CodeAct 思路是:让模型直接生成可执行代码(典型是 Python),把工具调用、数据处理、控制流全部写进脚本,由运行环境执行后再把结果反馈给模型或用户。
实际系统(如 Manus AI)中,CodeAct 具有几方面优势:
- 灵活组合多工具:一次代码执行即可调用多个 API,完成清洗、分析、可视化等完整流水线。
- 充分利用生态:直接调用 Python 生态中的数据分析、机器学习、异步 IO 等库,而无需在 Agent 层重复造轮子。
工程侧需重点关注安全与资源隔离:
- 在受限沙箱中运行代码,限制网络访问、文件系统、运行时间与内存占用,防止越权与 DoS。
- 记录并审计生成代码,对高敏操作引入人工审核或基于规则的静态分析。
Multi-Agent Workflow:协作式问题解决
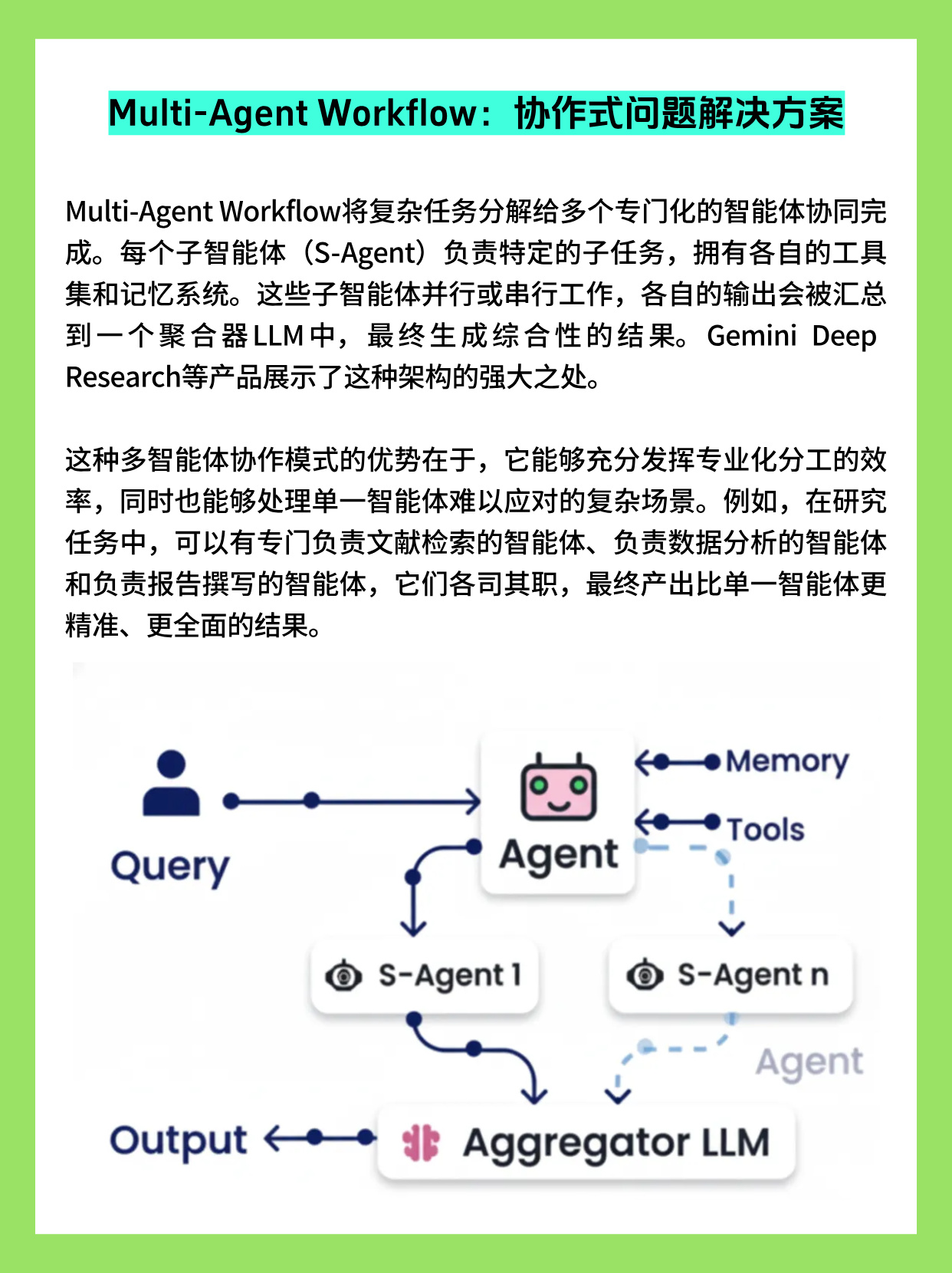
单一 Agent 难以同时在检索、推理、数据分析、写作等所有方面都做到"最优",多 Agent 协作(Multi-Agent Workflow)于是成为更可扩展的架构选择。
该模式将复杂任务拆解为多个专职子 Agent(S-Agent),例如"文献检索 Agent""数据分析 Agent""报告撰写 Agent",由一个聚合/编排 LLM 负责解释用户需求、调用合适子 Agent 并整合结果。
典型优势包括:
- 专业化与模块化:每个子 Agent 可以使用不同模型、Prompt 与工具栈,如用代码能力更强的模型负责数据处理,用长上下文模型负责文档综述。
- 可扩展性:新增能力时只需增加新 Agent,再在编排层配置触发条件即可,无需重写整个系统提示与逻辑。
简单的工程实现方式是"Agent-as-Tools"模式:
- 在编排 Agent 中,把每个子 Agent 暴露成一个"工具";当模型决定调用某个子 Agent 时,本质上是一次 Tool Call,由后端把用户子任务转发给对应 Agent 并收集结果。
- 调试多 Agent 系统时,可先在人为设计的简单任务图(DAG)上验证,再逐步交给模型自主规划调用顺序。
Agentic RAG:检索增强的智能化演进
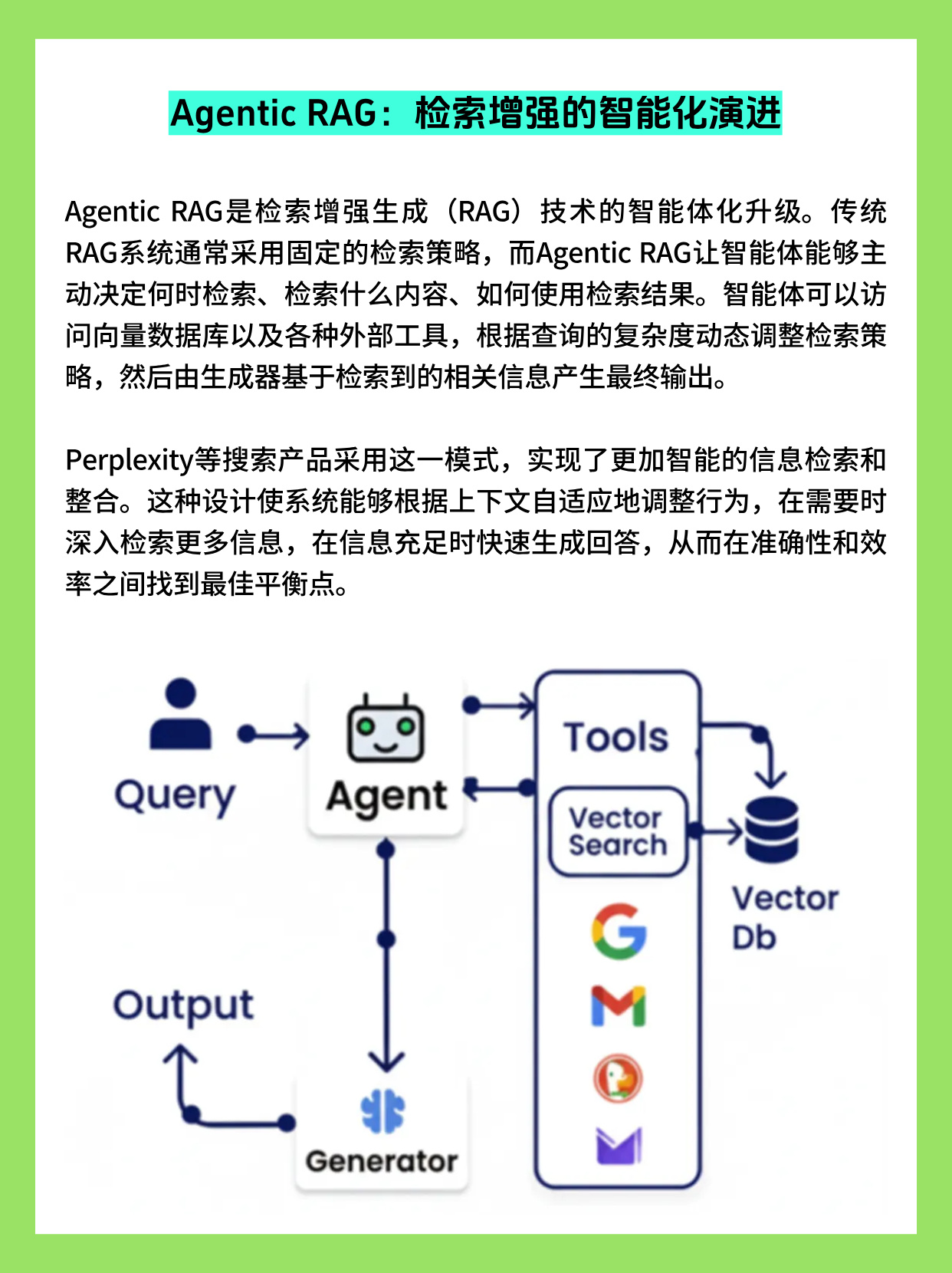
经典 RAG 往往只是在回答问题前做一次固定检索:构造 Query → 检索向量库 → 把若干文档拼接进 Prompt → 生成答案。
Agentic RAG 让"检索策略"本身也交由 Agent 负责决策:是否需要检索、检索多少轮、选择哪些数据源、什么时候停止继续查找,并在多轮检索结果之间进行综合与反思。
当前多家搜索与问答产品已经采用这种模式,以在"准确性"和"响应速度"之间找到更优平衡:
- 对简单问题,Agent 判断一次检索就足够,从而快速返回答案。
- 对复杂、多跳或歧义问题,Agent 会主动做多轮检索,跨向量库与外部搜索引擎,甚至调用结构化工具(如内部 API)补充关键事实。
工程侧的关键设计:
- 将"检索"抽象成工具家族:如
vector_search_corpus_A、web_search,sql_knowledge_base等,统一接入 Agent 调度。 - 结合 Self-Reflection,让模型在汇总检索结果后,先检查答案是否覆盖关键信息与证据,再决定是否追加检索。
架构对比与组合建议
在真实系统中,这 6 种模式通常不是"二选一",而是按任务与约束进行组合。下面的表格给出一个工程视角的对比与搭配思路。
| 模式 | 核心作用 | 典型场景 | 与其他模式的常见组合 |
|---|---|---|---|
| ReAct | 推理与工具调用闭环,解决多步任务 | 复杂问答、代码调试、运维自动化 | 与 MCP Tool Use 结合标准化工具调用;与 Agentic RAG 结合做智能检索决策。125 |
| Self-Reflection | 自我评估与重写,提升质量与安全 | 法律、技术写作、高风险输出 | 作为 ReAct、Agentic RAG 的后置质量闸门,对最终答案做批判与修正。71213 |
| MCP Tool Use | 统一的工具协议层,便于扩展与治理 | IDE 插件、企业内部平台、跨云工具集 | 提供底座能力,被 ReAct、Multi-Agent、CodeAct 等上层模式共同使用。21415 |
| CodeAct | 通过可执行代码完成复杂流程 | 数据分析、脚本自动化、ETL | 作为某些子 Agent 的"行动层",由 ReAct 或 Multi-Agent 调用执行。4163 |
| Multi-Agent Workflow | 多 Agent 分工协作与编排 | 研究助手、企业知识工作流 | 顶层由编排 Agent 采用 ReAct + Agentic RAG;底层子 Agent 可能用 CodeAct、MCP 等实现能力。3175 |
| Agentic RAG | 智能化检索策略与信息整合 | 搜索问答、企业知识库、数据洞察 | 与 MCP 结合访问多数据源;与 Self-Reflection 结合校验检索是否充分。1852 |
在系统设计时可以遵循:
- 先选"决策/推理层":大多数应用可以从 ReAct + Agentic RAG 起步。
- 再选"执行层":简单任务用 MCP 工具即可,复杂数据处理则引入 CodeAct。
- 对任务复杂度高或跨多领域的场景,引入 Multi-Agent Workflow 做分工;对质量门槛高的输出,加上 Self-Reflection 闸门。
实战落地建议与结语
工程团队在从"LLM 应用"走向"Agent 系统"时,可以按以下步骤推进:
- 从一个小而精的 ReAct Agent 开始,引入 1--2 个关键工具(如搜索、数据库),并加上基础日志与超时/轮数限制。
- 当需要调用的外部系统增多时,逐步迁移到 MCP 方案,避免在应用里硬编码各类 API。
- 针对数据分析、自动化脚本等场景,引入 CodeAct 作为"专家子 Agent",由编排层适时调用。
- 面对跨检索、推理、写作的复杂知识任务,用 Multi-Agent Workflow + Agentic RAG 组合,并给最终答案添加 Self-Reflection 校验。
通过这六种设计模式的合理组合,可以把大模型从"聊天工具"演化为"可协作、可扩展、可治理的智能工作伙伴",在搜索、办公自动化、研发辅助、数据分析等场景中构建真正可用的 AI Agent 系统。
补充资料
一、ReAct:推理 × 行动 的核心思想
1. ReAct Prompting(官方指南)
https://www.promptingguide.ai/techniques/react
系统介绍 ReAct(Reason + Act)提示范式:让模型在"思考---调用工具---再思考"的循环中完成复杂任务。
9. ReAct: Synergizing Reasoning and Acting in Language Models(Google Research)
https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models/
ReAct 的原始思想来源,解释为什么"只推理"或"只行动"都不够。
20. ReAct-LM 项目主页
ReAct 学术与工程实践的集中展示,含论文、示例与扩展工作。
二、Agent、Tool 与 MCP(模型如何"用工具")
2. Model Context Protocol(MCP)--- Tools 概念说明
https://modelcontextprotocol.info/docs/concepts/tools/
解释 MCP 中 Tool 的标准定义方式,是"模型调用外部能力"的协议级抽象。
14. LangChain MCP(Python 实现)
https://docs.langchain.com/oss/python/langchain/mcp
LangChain 对 MCP 的落地实现,适合理解工程视角下的 Tool 接入。
15. MCP Server Tools 规范(2025-06)
https://modelcontextprotocol.io/specification/2025-06-18/server/tools
MCP 的最新工具接口规范,适合写"协议级"或"生态级"分析文章引用。
三、Multi-Agent:一个模型不够,那就一群
3. What is Multi-Agent AI(V7 Labs)
https://www.v7labs.com/blog/multi-agent-ai
通俗但不浅的多智能体系统介绍,适合博客中作为"概念引入"。
17. Agents-as-Tools Pattern(AWS Dev.to)
https://dev.to/aws/build-multi-agent-systems-using-the-agents-as-tools-pattern-jce
把 Agent 当成 Tool 使用的设计模式,非常工程化。
四、Agentic RAG:RAG 进入"会思考"阶段
5. Understanding Agentic RAG(Arize)
https://arize.com/blog/understanding-agentic-rag/
清晰解释 Agentic RAG 与传统 RAG 的本质区别。
18. Agentic RAG(AI21 Glossary)
https://www.ai21.com/glossary/foundational-llm/agentic-rag/
偏定义与概念澄清,适合作为术语解释引用。
五、反思(Reflection):Agent 为什么能变聪明
12. Self-Reflection in Language Models(Galileo AI)
https://galileo.ai/blog/self-reflection-in-language-models
介绍"自我反思"如何提升模型决策质量。
13. Reflection Agents(LangChain 官方博客)
https://blog.langchain.com/reflection-agents/
反思型 Agent 的工程实践案例,和 ReAct 非常搭。
11. HuggingFace Agents Course:Thoughts & Reasoning
https://huggingface.co/learn/agents-course/en/unit1/thoughts
从教学角度解释"Thought / Action / Observation"结构。
六、学术论文(可作为博客的理论支柱)
7. Agentic Reasoning with Tools(arXiv:2405.06682)
https://arxiv.org/abs/2405.06682
系统讨论 Agent + Tool 的推理结构,偏理论但很扎实。
8. ReAct: Reasoning and Acting in Language Models(arXiv:2210.03629)
https://arxiv.org/abs/2210.03629
ReAct 原始论文,经典必读。
七、工程与实践补充
4. ReAct Prompt 示例 Gist
https://gist.github.com/renschni/4fbc70b31bad8dd57f3370239dccd58f
可直接复用的 ReAct Prompt 示例,适合"实战篇"。
6. What is a ReAct Agent(IBM Think)
https://www.ibm.com/think/topics/react-agent
企业视角解读 ReAct Agent,语言稳健,适合对管理层友好的博客。
10. ReAct Framework(APXML Agentic LLM Course)
把 ReAct 放进更大的 Agent 架构与记忆体系中。
八、趋势与案例
16. What is Manus AI Agent(Thunderbit)
https://thunderbit.com/blog/what-is-manus-ai-agent
一个具体 Agent 产品的拆解,适合落地案例分析。
19. 今日头条:Agent 相关文章
https://www.toutiao.com/w/1850385655091211/
中文社区视角,适合补充国内讨论语境。
21. CodeAct 相关讨论(LinkedIn)
CodeAct 思路的实践讨论,连接 ReAct 与代码执行型 Agent。
