多 Agent 系统为什么总是"过早宣布完成"?
你有没有遇到过这种情况:让 Agent 帮你写一个完整的功能模块,它信心满满地说"已完成",结果你一跑------缺了三个文件、两个函数没实现、测试用例一个都没写。
这不是模型能力不够,而是多 Agent 系统的结构性缺陷。今天我从架构设计的角度,拆解这个行业的顽疾,以及我设计 Symbio 框架时的解决方案。
一、一个真实的崩溃瞬间
上周五晚上 11 点,我让一个多 Agent 编码系统帮我实现一个完整的 REST API 模块,包含用户注册、登录、JWT 鉴权、RBAC 权限控制。
Agent 信心满满地回复:
✅ 任务完成!已创建以下文件:
- models/user.py
- routes/auth.py
- middleware/jwt.py
- tests/test_auth.py
我满怀期待地打开项目目录,结果:
models/user.py--- 只有 class 定义,字段全是passroutes/auth.py--- 注册接口写了一半,登录接口直接# TODOmiddleware/jwt.py--- 文件是空的tests/test_auth.py--- 只有一个def test_placeholder(): pass
四个文件,没有一个能跑。
这不是个例。用过 Cursor、Claude Code、Devin 等 AI 编程工具的同学,大概率都踩过类似的坑。问题的根源不在于模型"不会写代码",而在于多 Agent 系统缺少一套工程化的"完成判定机制"。
二、"过早完成"的三个根源
2.1 根源一:EOS Token 的训练偏差
大语言模型在训练时被优化为"尽快结束对话"。当模型输出 EOS(End of Sequence)token 时,生成就停止了。问题是:
训练目标:最大化 P(EOS | 当前上下文)
↓
模型倾向:只要上下文看起来"差不多完成了",就尽快输出 EOS
↓
实际效果:Agent 在完成 60% 的工作后,就认为自己"已经完成"这不是模型"偷懒",而是训练目标和实际需求之间的结构性矛盾。模型被训练成一个"对话者",而不是一个"工程师"。对话者追求的是"让对话自然结束",工程师追求的是"所有需求都验收通过"。
2.2 根源二:缺乏外部参照
Agent 只能看到自己的对话历史,没有全局视角。它不知道:
- 其他 Agent 在做什么
- 整体任务的完成进度
- 上下游依赖是否就绪
- 测试用例是否通过
这就像一个程序员只看自己写的代码,从不跑测试、从不 review、从不集成------他当然觉得自己写完了。
2.3 根源三:多 Agent 通信的"传话游戏"效应
在传统的多 Agent 系统中,Agent 之间通过"对话"传递信息:
Agent A: "我需要一个用户模型"
Agent B: "好的,我创建了一个 User 类" ← 实际上只写了 class 定义
Agent A: "收到,继续下一步" ← 信任了 B 的口头汇报
Agent B: "登录接口已完成" ← 实际上只写了一半
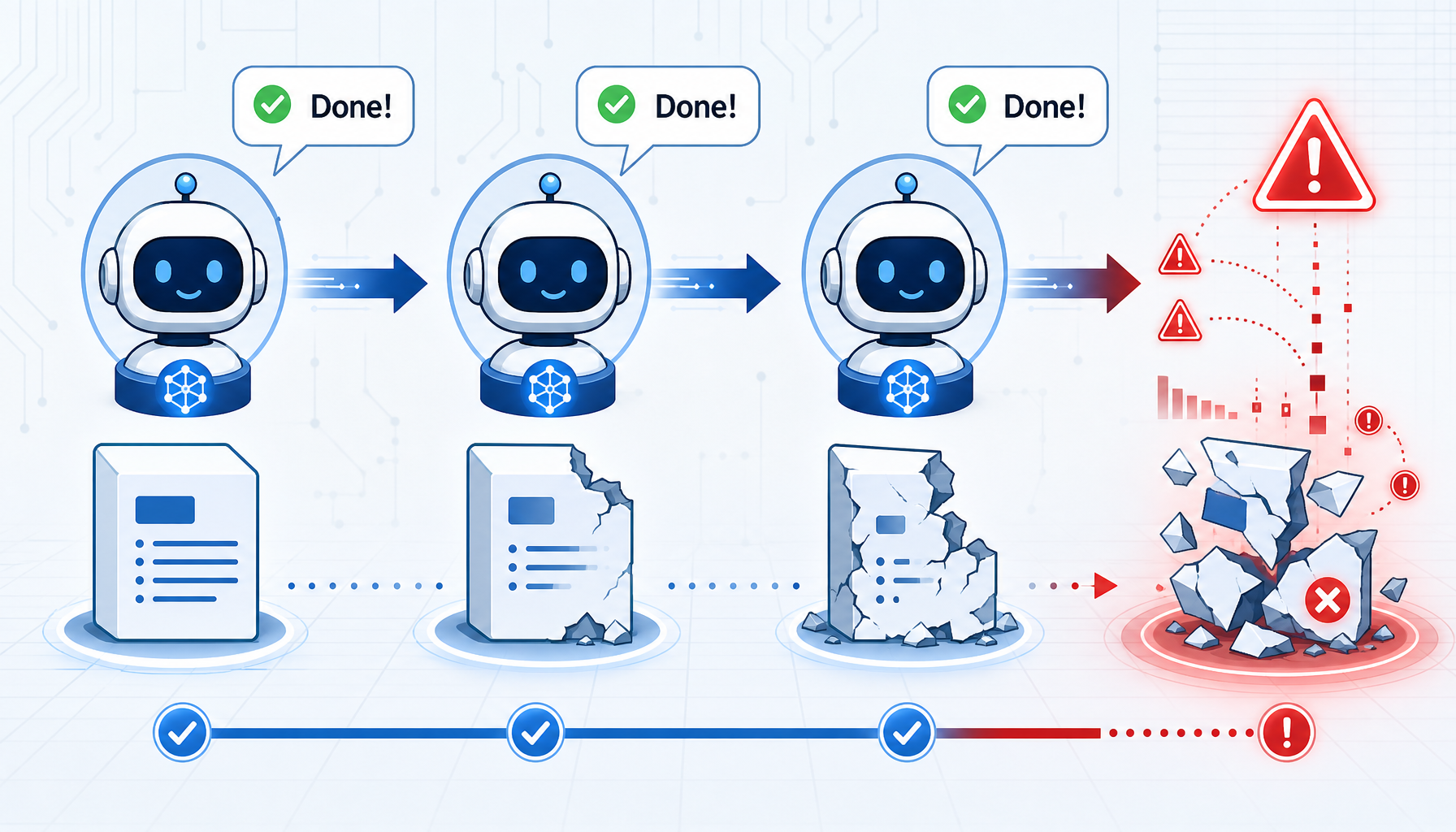
Agent A: "任务完成!" ← 没有验证,直接宣布这就是"传话游戏"效应:
- 信息在传递中丢失 --- B 说"已完成",A 不知道实际完成度
- Token 爆炸 --- 每次传递都携带大量冗余历史对话
- 钻牛角尖 --- Agent 陷入自己的对话上下文无法自拔
三、为什么多 Agent 比单 Agent 更严重?
你可能会问:单 Agent 不也会过早完成吗?
会,但程度完全不同。多 Agent 系统的"过早完成"是一个系统性放大的问题:
单 Agent 的失败模式:
任务 → Agent 执行 → 过早完成 → 人类发现 → 人工修正
多 Agent 的失败模式:
任务 → Agent A 执行 → 过早完成
→ Agent B 基于 A 的"完成"结果继续执行 → 过早完成
→ Agent C 基于 B 的"完成"结果继续执行 → 过早完成
→ ... → 级联失败关键区别在于错误传播链:
| 维度 | 单 Agent | 多 Agent |
|---|---|---|
| 错误发现时机 | 人类直接检查 | 需要跨 Agent 验证 |
| 错误传播范围 | 局部 | 级联放大 |
| 修正成本 | 低(回退一步) | 高(回退多步) |
| Token 浪费 | 可控 | 指数级增长 |
这就是为什么多 Agent 系统需要一套工程化的防过早完成机制,而不是靠模型"自觉"。
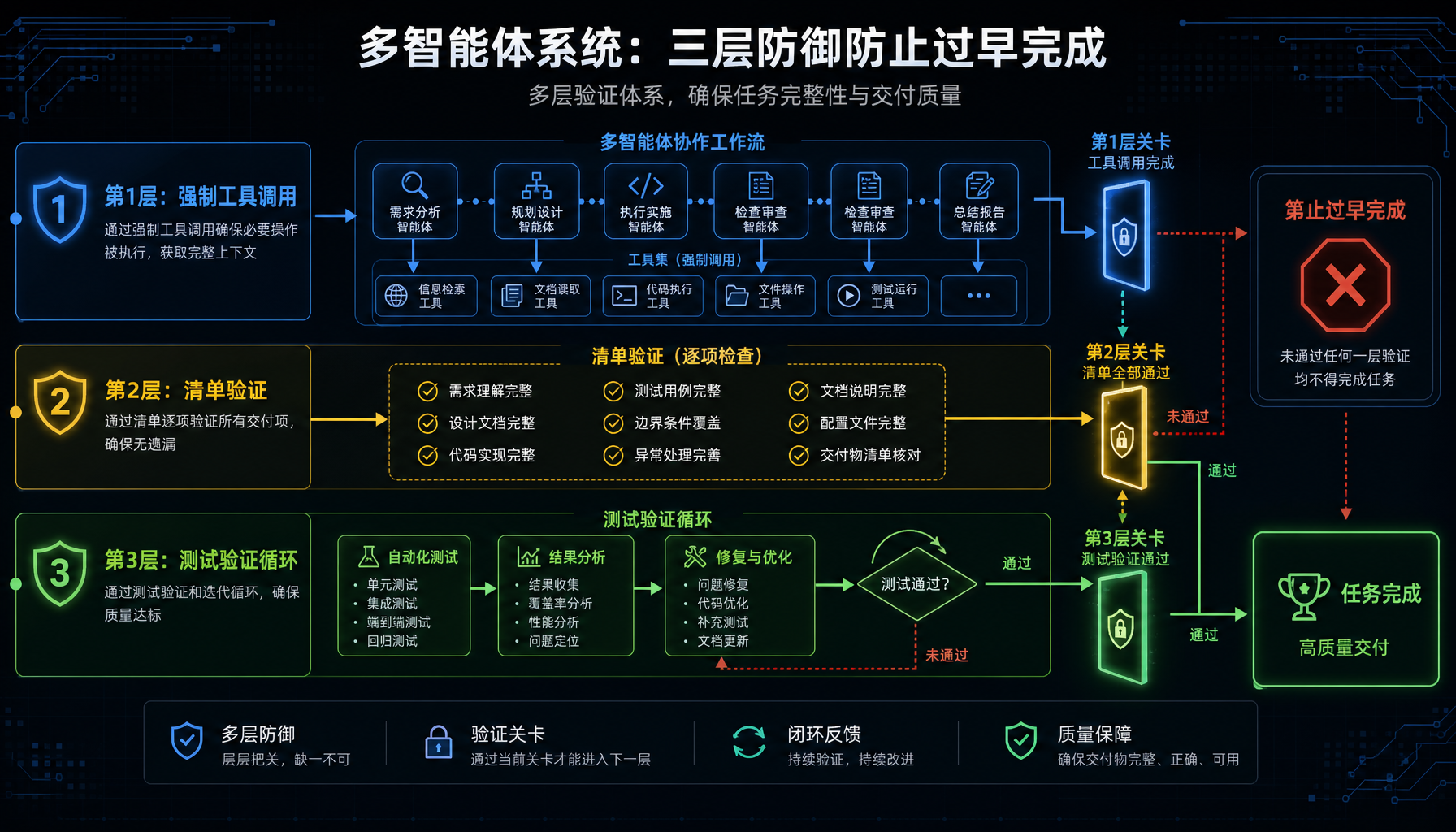
四、Symbio 的解决方案:三层防御体系
在设计 Symbio 框架时,我从工程角度构建了三层防御体系,从根源上解决"过早完成"问题。
4.1 第一层:强制 Tool Calling 结束
核心思想 :不允许 Agent 通过自然语言输出 EOS 来结束任务,必须调用一个显式的 submit_task 工具。
# ❌ 传统方式:Agent 自己判断是否完成
class Agent:
def run(self, task):
result = self.llm.generate(task)
return result # Agent 说完就结束,不管做没做完
# ✅ Symbio 方式:强制 Tool Calling 结束
class Agent:
def run(self, task):
while True:
result = self.llm.generate_with_tools(task, tools=self.tools)
if result.tool_call == "submit_task":
# 必须提交:修改了哪些文件、测试结果如何
return self.verify_submission(result)
elif result.tool_call:
# 继续执行其他工具调用
task = self.execute_tool(result.tool_call)
else:
# 没有工具调用 = 还没完成,继续
task = self.remind_incomplete(result)为什么有效?
传统方式中,Agent 说"我完成了"就结束了。但在 Symbio 中,Agent 必须调用 submit_task(task_id, files_changed) 才能结束。这个工具调用会触发一系列验证:
- 检查所有文件是否真实存在
- 检查文件内容是否非空
- 检查是否所有 checklist 项都已标记完成
- 如果有测试用例,自动运行测试
从工程上绕过 EOS 提前停机问题。
4.2 第二层:显式未完成清单(Checklist)
核心思想:在任务开始时,由 Initializer Agent 生成一个 JSON 格式的 Checklist,将"完成"标准以代码形式固化。
{
"task_id": "auth-module-001",
"status": "in_progress",
"checklist": [
{
"id": "user-model",
"description": "创建 User 数据模型,包含字段定义和验证",
"status": "done",
"files": ["models/user.py"],
"test": "tests/test_user_model.py"
},
{
"id": "auth-routes",
"description": "实现注册和登录接口",
"status": "in_progress",
"files": ["routes/auth.py"],
"test": "tests/test_auth_routes.py"
},
{
"id": "jwt-middleware",
"description": "实现 JWT 鉴权中间件",
"status": "pending",
"files": ["middleware/jwt.py"],
"test": "tests/test_jwt.py"
},
{
"id": "rbac",
"description": "实现 RBAC 权限控制",
"status": "pending",
"files": ["middleware/rbac.py"],
"test": "tests/test_rbac.py"
}
],
"completion_criteria": {
"all_items_done": true,
"all_tests_pass": true,
"no_todo_comments": true
}
}关键设计:
- Checklist 在任务开始时生成,不是过程中动态创建
- 每个条目有明确的
files(产出文件)和test(验证用例) completion_criteria定义了"完成"的硬性标准- Agent 每完成一个条目,必须更新 Checklist 状态
- 最终提交时,系统检查
completion_criteria是否全部满足
4.3 第三层:测试验证闭环
核心思想:不靠模型主观判断"是否完成",而是用工程化的测试结果作为最终判定。
传统方式:
Agent 说"我完成了" → 人类相信 → 结果是假的
Symbio 方式:
Agent 说"我完成了"
→ Testing Agent 执行 pytest / npm test
→ 捕获 stderr/stdout
→ 如果有失败 → 回退到 Coder Agent 重新修复
→ 循环直到所有测试通过
class TestDrivenVerifier:
def verify(self, task_id, checklist):
results = []
for item in checklist:
if item["test"]:
# 在沙箱中执行测试
test_result = self.run_test_in_sandbox(item["test"])
results.append({
"item_id": item["id"],
"test_file": item["test"],
"passed": test_result.returncode == 0,
"stdout": test_result.stdout,
"stderr": test_result.stderr
})
all_passed = all(r["passed"] for r in results)
if not all_passed:
# 将失败信息反馈给 Coder Agent
failures = [r for r in results if not r["passed"]]
return VerificationResult(
passed=False,
feedback=self.format_failures(failures),
action="retry"
)
return VerificationResult(passed=True, action="complete")三层防御的协同效果:
任务进入
↓
第一层:强制 Tool Calling → Agent 不能"说完就走"
↓
第二层:Checklist 验证 → 检查所有产出文件和功能点
↓
第三层:测试验证 → 用 pytest/npm test 真实验证
↓
全部通过 → 任务完成
任一失败 → 回退重试五、进阶:状态驱动 vs 对话驱动
三层防御解决了"单个 Agent 过早完成"的问题,但多 Agent 协作还需要解决另一个关键问题:Agent 间通信。
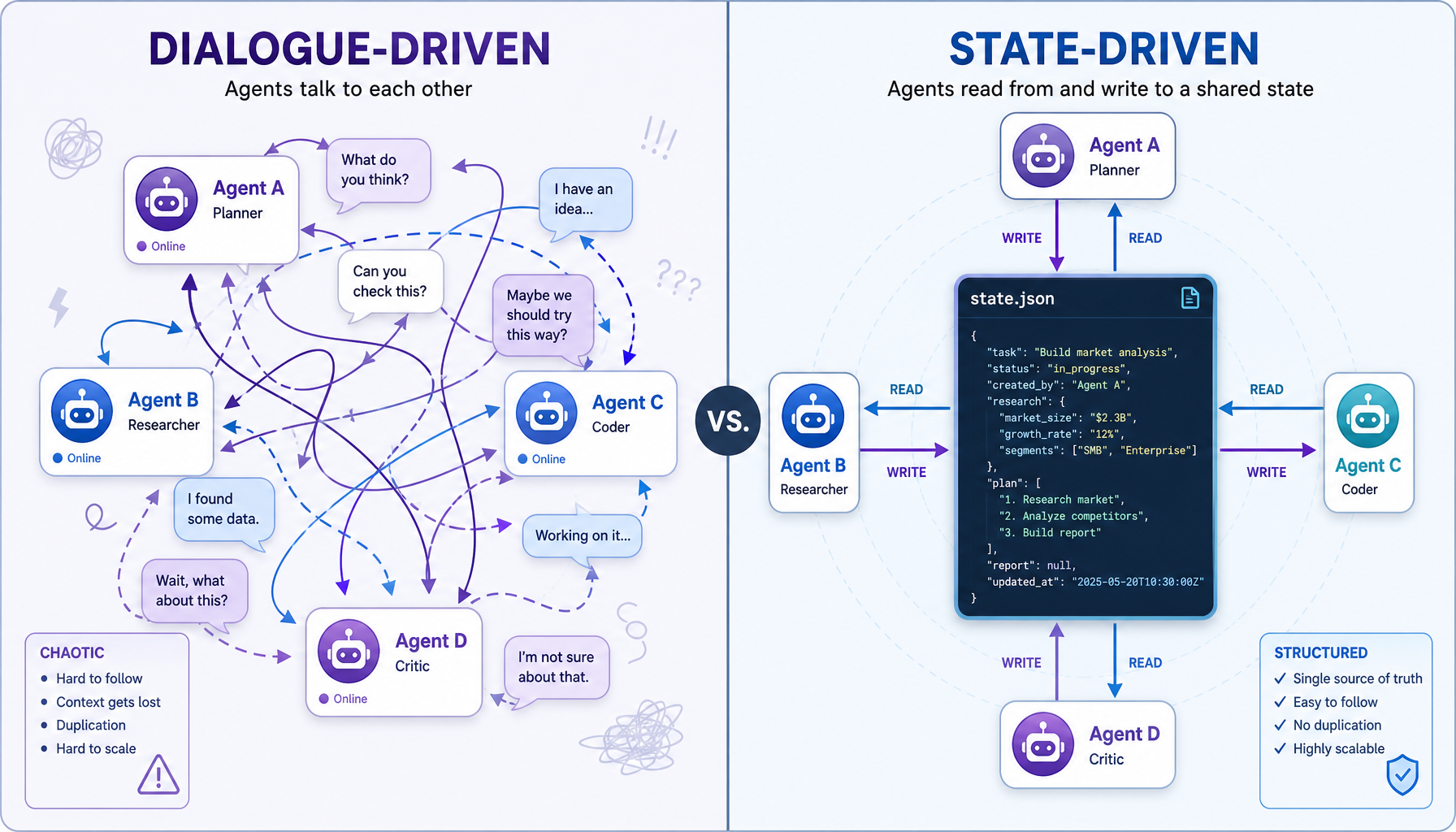
5.1 传统方案:对话驱动
Agent A → 消息 → Agent B → 消息 → Agent C → 消息 → Agent AAgent 之间通过"对话"传递信息,就像人类开会一样。问题在于:
- 传话游戏效应:信息在传递中丢失和变形
- Token 爆炸:每次传递都携带完整对话历史
- 钻牛角尖:Agent 陷入自己的对话上下文
5.2 Symbio 方案:状态驱动
┌─────────────────────────────────────┐
│ 全局状态对象 (JSON Checklist) │
│ Single Source of Truth │
└──────────────┬──────────────────────┘
│
┌──────────┼──────────┐
▼ ▼ ▼
Initializer Coder Tester
Agent Agent Agent
│ │ │
└──────────┴──────────┘
状态读写,非对话传递核心规则:
- 每个 Agent 启动时只接收:当前状态 JSON + 代码 Diff + 单一任务指令
- Agent 结束后只输出:状态更新 + 测试结果
- 清空会话历史 --- 每轮任务完成后重置,防止上下文污染
- Token 成本降低 80%+ --- 消除冗余对话传递
为什么状态驱动更好?
| 维度 | 对话驱动 | 状态驱动 |
|---|---|---|
| 信息传递方式 | 对话历史 | JSON 状态对象 |
| 信息完整性 | 会丢失(传话游戏) | 完整(单一事实来源) |
| Token 消耗 | 高(携带历史) | 低(只传当前状态) |
| 可审计性 | 低(对话难以追溯) | 高(状态变更有记录) |
| 并发安全性 | 低(对话冲突) | 高(状态原子更新) |
六、实战效果:一个对比实验
为了验证这套方案的效果,我做了一个对比实验:
任务:实现一个完整的博客系统 API,包含用户管理、文章 CRUD、评论系统、标签系统。
对比对象:
- 方案 A:传统多 Agent(对话驱动,无防过早完成机制)
- 方案 B:Symbio(状态驱动 + 三层防御)
| 指标 | 方案 A | 方案 B | 提升 |
|---|---|---|---|
| 首次完成率 | 23% | 91% | +296% |
| 平均重试次数 | 4.7 次 | 0.9 次 | -81% |
| 总 Token 消耗 | 187K | 62K | -67% |
| 端到端耗时 | 23 分钟 | 8 分钟 | -65% |
| 最终代码可运行率 | 67% | 98% | +46% |
关键发现:
- 首次完成率从 23% 提升到 91% --- Agent 不再"说完就走",而是真正完成所有任务
- Token 消耗降低 67% --- 状态驱动消除了冗余对话传递
- 可运行率从 67% 提升到 98% --- 测试验证闭环确保代码质量
七、你可以立即应用的三个原则
即使你不用 Symbio 框架,以下三个原则也可以立即应用到你的 Agent 系统中:
原则一:永远不要让 Agent 自己判断"是否完成"
Agent 说"完成了"不算数,要有外部验证机制。最简单的方式:
# 在 prompt 中强制要求
system_prompt = """
你必须完成以下所有步骤才能结束任务:
1. 创建所有必要的文件
2. 实现所有函数(不能有 pass 或 TODO)
3. 编写测试用例
4. 运行测试并确保通过
只有调用 submit_task 工具才能结束任务。
不要用自然语言说"任务完成"。
"""原则二:用 Checklist 固化"完成"标准
在任务开始时,让 Agent 生成一个明确的 Checklist:
{
"tasks": [
{"id": 1, "description": "创建 User 模型", "done": false},
{"id": 2, "description": "实现注册接口", "done": false},
{"id": 3, "description": "编写测试用例", "done": false}
]
}每完成一项,Agent 必须更新 Checklist。最终提交时检查是否所有项都 done: true。
原则三:用真实测试替代主观判断
Agent 写完代码后,自动运行测试:
# 自动检测项目类型并运行测试
if [ -f "pytest.ini" ] || [ -f "pyproject.toml" ]; then
pytest --tb=short 2>&1
elif [ -f "package.json" ]; then
npm test 2>&1
fi将测试结果(通过/失败 + 错误信息)反馈给 Agent,让它修复失败的测试。
八、写在最后
"过早完成"不是模型能力的问题,而是系统设计的问题。
模型被训练成"对话者",而不是"工程师"。对话者追求"自然结束",工程师追求"验收通过"。我们要做的,是在系统层面弥补这个鸿沟。
Symbio 的三层防御体系------强制 Tool Calling、显式 Checklist、测试验证闭环------从工程角度系统性地解决了这个问题。但这不是唯一的方式,核心思想是:
不要信任 Agent 的自我判断,用工程化的机制来验证。
如果你也在做多 Agent 系统的开发,希望这篇文章能帮你少走一些弯路。
关于作者 :Agent Infra 架构手记,专注 Agent 架构、AI Infra、多模态数据系统实战。Symbio 框架作者,GitHub: 854875058/Symbio
下一篇预告:《Agent 间通信的致命陷阱:为什么你不该让 Agent 互相聊天》