目录
1.前言
在c++编程和Linux编程的学习下,我们学习了三高
高并发:系统能同时处理海量请求(像双十一秒杀)。
高可用:系统全年无休,很少宕机(通过冗余、自动故障转移实现)。
高可扩展/高性能/高吞吐:业务量激增时,加机器就能轻松扛住,性能能线性提升。
并发和并行有啥区别?
对比维度 并发 并行 本质 逻辑上同时发生,是一种任务组织方式。 物理上同时发生,是一种执行状态。 形象比喻 一个人(单核)同时玩三个球,快速轮流抛接,看起来三个球都在空中。 三个人(多核)各玩一个球,三个球真正在同一时刻被抛起。 与 CPU 的关系 不一定依赖多核,单核 CPU 通过时间片轮转即可实现,这是"切换的错觉"。 必须依赖多核或多处理器,需要真正的独立计算通道。 CUDA 中的体现 CPU 管理多个异步流,GPU 快速切换线程束(Warp)隐藏访存延迟。 GPU 里成百上千个核心真正同时计算矩阵。
2.背景:并行计算为什么必然出现
我们的计算机从最早的埃尼阿克到现在的各种超算,都是为了应用而产生 的,软件和硬件相互刺激而相互进步,并行计算也是这样产生的,我们最早的计算机肯定不是并行的,但是可以做成多线程的(并发,不是真正的并行),因为当时一个CPU只有一个核,所以不可能一个核同时执行两个计算 ,后来我们的应用逐步要求计算量越来越高,所以单核的计算速度也在逐步上升,后来大规模并行应用产生了,我们迫切的需要能够同时处理很多数据的机器,比如图像处理(GPU主攻 ),以及处理大规模的同时访问的服务器后台(CPU主攻)。
硬件不行了 → 软件跑得太慢,程序员叫苦 → 刺激硬件厂商研发更快的芯片
新硬件出来了 → 计算能力暴涨 → 刺激软件开发者写出更复杂、更强大的程序(比如从文字处理到 4K 视频渲染)
然后新软件又对硬件提出更高要求,如此循环往复。
也就是软件处理的数据越来越多,对计算要求越来越高,对硬件的要求越来越高,单核已经不足以满足,把单核的cpu逼到了物理计算,那此时必然出现了多核、众核
并行计算应该分为两条技术:
硬件:计算机架构
软件:并行程序设计
3.软件视角理解并行性
并行主要分为
指令并行
数据并行
3.1指令并行
- 指令并行 (Task Parallelism):不同的指令或任务同时执行。就像厨房里,一个人切菜,另一个人炒菜,他们干的是不同的事。这多用于支付系统这类高并发服务,每个请求处理逻辑可能不同。
3.2数据并行
- 数据并行 (Data Parallelism) :相同的指令 ,作用在不同的数据上。这是学 CUDA 要处理的核心。就像你要把1000根胡萝卜切丁,你雇了很多人,每个人都只做"切丁"这一个动作,但每人分一根胡萝卜。
CUDA 就是为"数据并行"而生的。你的任务,就是找出计算中那些可以用"同一套操作"处理"大批量数据"的部分。
4.数据划分的两种核心策略
如何把一堆数据,分发给不同的线程去处理
4.1块划分 (Block Partitioning)

做法 :把数据连续地切成大块,每个线程领走一块。
线程1:处理块 1, 2, 3
线程2:处理块 4, 5, 6
线程3:处理块 7, 8, 9
...
优点:像切豆腐,简单直观。每个线程处理的数据在内存里是连续的,访问起来很高效。
缺点 :如果每个块的计算量不一样(比如有的块数据复杂,有的简单),就容易"忙的忙死,闲的闲死",即负载不均衡。
4.2周期划分 (Cyclic Partitioning)

做法 :把数据交错地分给各个线程,像发扑克牌一样。
- 线程1:处理块 1, 6, 11
- 线程2:处理块 2, 7, 12
- 线程3:处理块 3, 8, 13
- ...
你不需要专门找出"1,6,11"是哪个。在周期划分里,这个大块可能是线程1处理,也可能是线程2处理。但因为所有线程分到的大小块比例在统计上是均匀的,所以大家手里的活总量会差不多。
那个倒霉的、分到"1,6,11"这个超大计算块的线程,它也必然同时分到了其他很多"小"块。而那个没分到"1,6,11"的线程,它的篮子里可能装满了各种中等大小和更小的块。
最终的结果就是,大家手里篮子里的总计算量被平衡了,完成时间自然就差不多。它用这种"大杂烩"的方式,完美解决了无法预知单点计算量的问题。
优点:用"概率均匀"对抗"不确定性",负载非常均衡。不管哪个块计算量大,都被平均分到了各个线程上,大家完成时间差不多。
缺点:每个线程访问的数据在内存里是跳跃的、不连续的,可能导致访存效率降低。
没有完美的策略,你的选择直接影响程序最终的运行速度。
要根据你的数据特征 和GPU的内存架构来权衡:
从数据特征看:所有数据块的计算量都差不多吗?还是有的块计算量特别大?
从硬件架构看:GPU 喜欢连续访问内存(块划分更优),但也需要保证所有计算单元都一直在忙(周期划分负载更均衡)。
所以,设计并行程序时,你始终在进行这种权衡,并在理论指导下通过实验去找到那个"最佳划分"。
5.硬件视角理解并行性
软件即兵法谱,我们应该采用哪种策略去划分数据
硬件即兵器谱,我们的计算机架构为了提高并行性是有什么策略
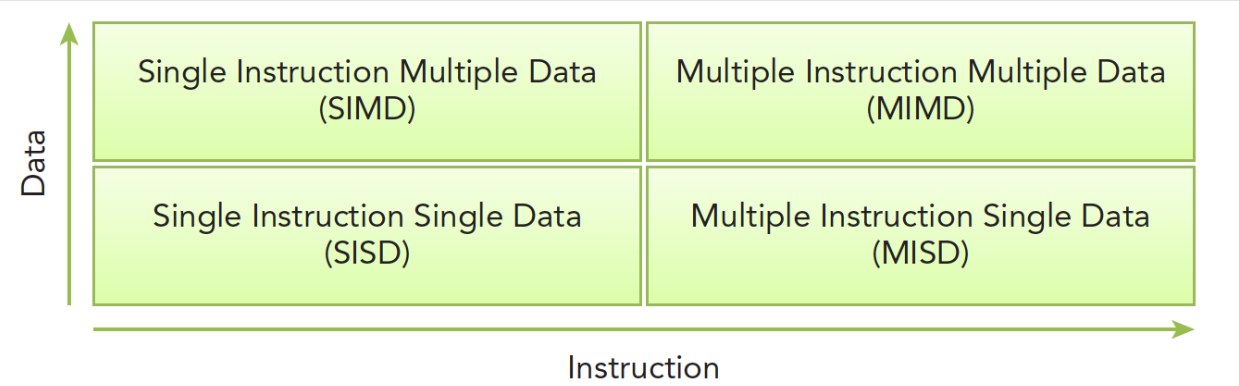
理解所有并行硬件(包括你的 CPU 和 GPU)的基础理论模型。
根据计算机如何处理指令 和数据两条流,将其分成四类。
分类 全称 核心特点与比喻 现实对应 SISD 单指令单数据 传统串行。一个厨子按一张菜谱,一次处理一个食材。 老式单核 CPU(如 386) SIMD 单指令多数据 数据并行 。一个教练喊一声"卧倒!",一排士兵同时卧倒。GPU 的核心就是 SIMD 架构。 GPU、现代 CPU 的向量指令(如 AVX) MISD 多指令单数据 罕见。多位专家从不同角度分析同一份数据,确保结果绝对可靠。 航天飞机飞控系统等极特殊的容错场景 MIMD 多指令多数据 任务并行 。一个大厨房里,有的厨子在炒菜,有的在切菜,各干各的。现代多核 CPU 就是典型的 MIMD。 现代多核 CPU、分布式计算集群
CPU 是一个 MIMD 架构(多核),而它内部的每个核心又都具备 SIMD 指令集(可以同时处理多个数据)
6.优化方向
延迟:是指操作从开始到结束所需要的时间,一般用微秒计算,延迟越低越好。
带宽:是单位时间内处理的数据量,一般用MB/s或者GB/s表示。
吞吐量:是单位时间内成功处理的运算数量,一般用gflops来表示(十亿次浮点计算)
降低延迟、提高带宽、提高吞吐量是所有并行架构的共同目标。
7.内存架构划分:看硬件"怎么组织团队"
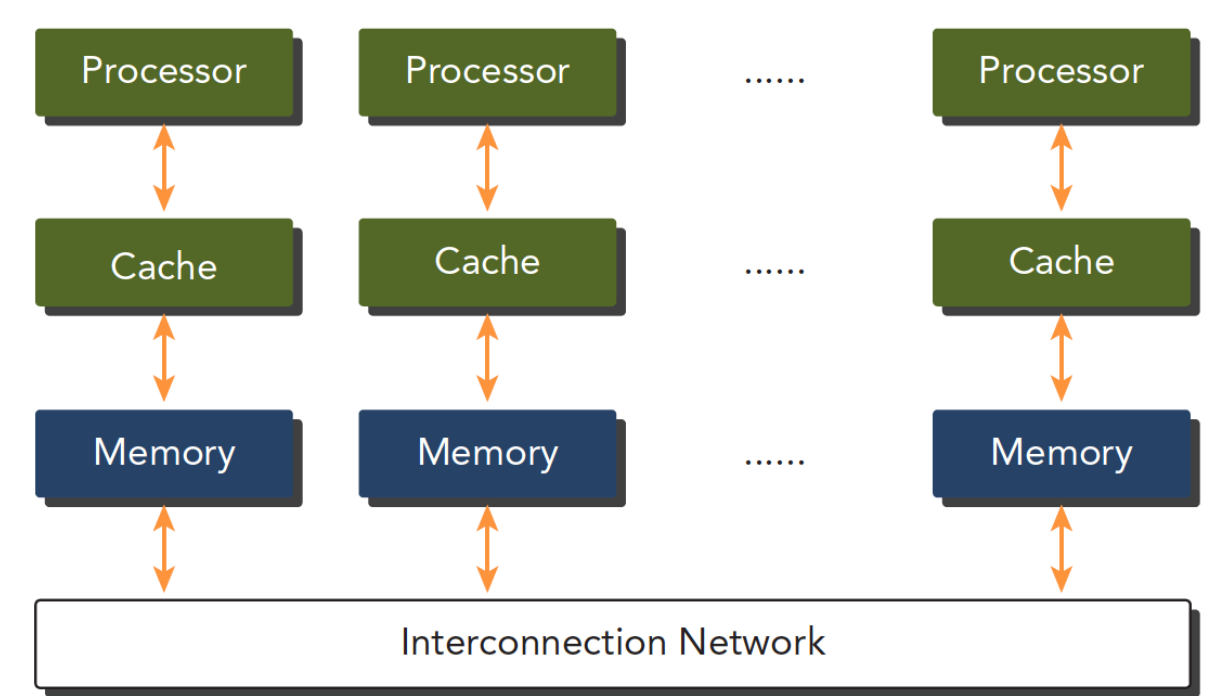
分布式内存系统:
结构:像很多独立的电脑(节点)通过网络连起来,每个节点有自己私有的内存。
特点:规模可以很大(集群),但节点间通信慢,需要程序员显式处理消息传递(如用 MPI)。
地址空间:物理上是分散的。
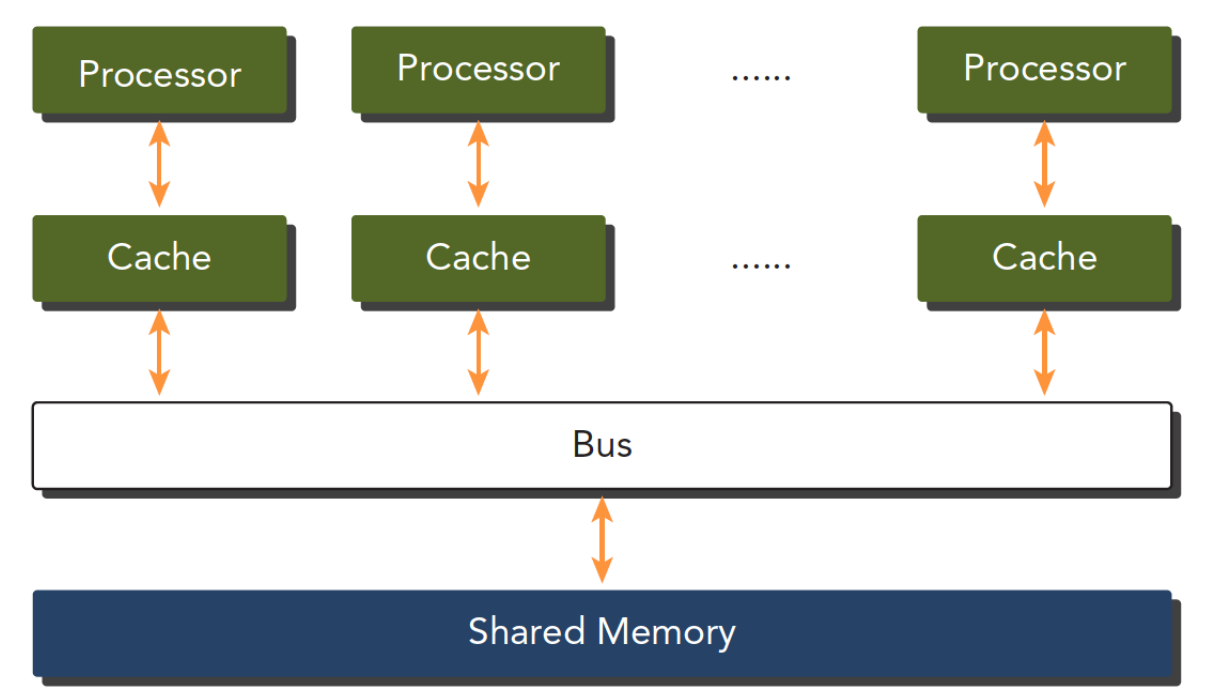
共享内存系统:
结构 :一块主板上的多个处理器(或核心),共享同一块物理内存(我们常说的插在主板上的一条条内存)。
特点:核心间通信非常快,通过共享内存交换数据。
GPU 就是典型的共享内存众核系统:一个 GPU 芯片内部有成百上千个核,它们共享显存。这与多核 CPU 本质上是同一类架构,但核心设计哲学不同。
总结
软件:并行计算部分 :是软件视角,教你如何把一个计算问题,从逻辑上拆解成可以并行的部分。
硬件:计算机架构部分 :是硬件视角,告诉你承载并行计算的物理平台有哪些类别,它们的基本构造和衡量标准是什么。