目录
前面在文章ollama+qwen2.5vl:7b多模态做图片和文件分析-CSDN博客
中介绍了多模态大模型,通过调用ollama接口解读文件和图片。
这里我们开始做Agent,就是根据提示词操作电脑软件。
效果
先给效果,我还是用多模态大模型,做一个网页,然后给出提示词:"Edge 浏览器搜索最新热点新闻",然后就能自动打开浏览器了,并且自动搜索了相关内容。
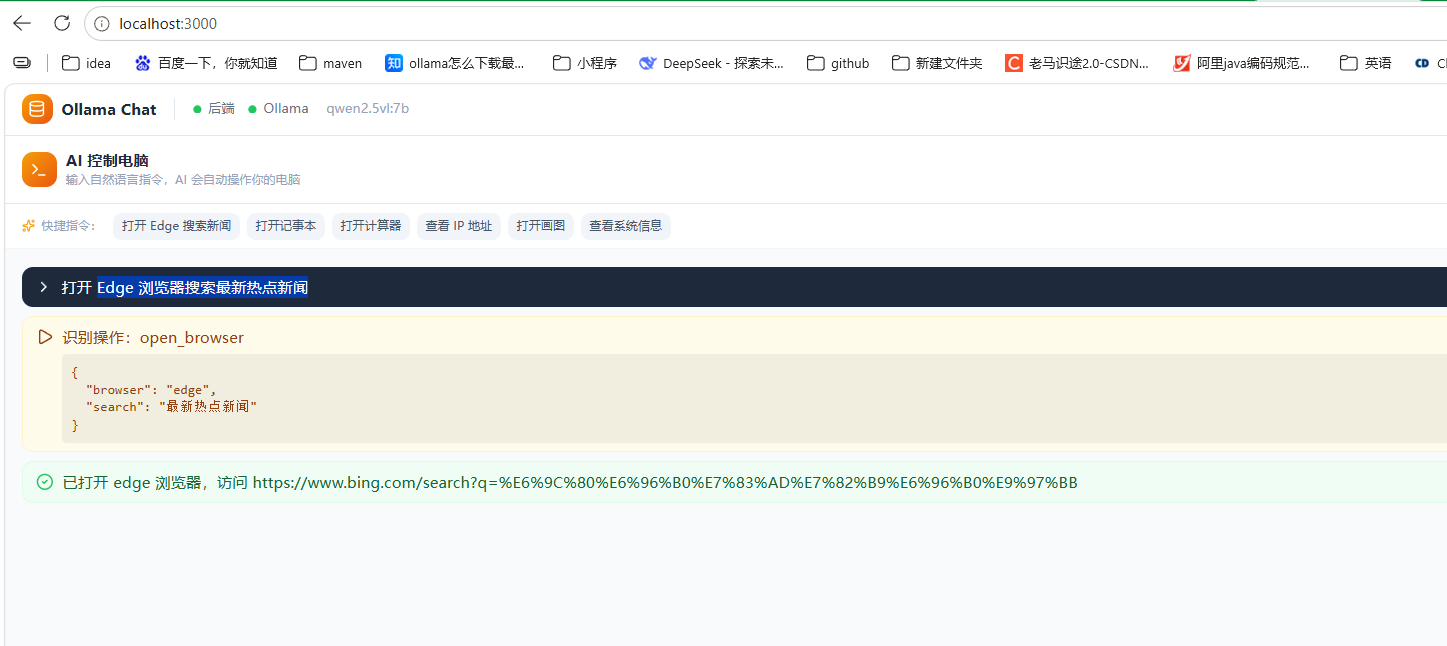
编写agent
代码地址:见文章底部
下载后,npm install npm run build npm start 就能打开浏览器了。然后右上角有个控制电脑,AI就能操作电脑了。
关键代码:基于前面的文章学习,这里最关键的就是新增了一个server/services/agent.js
看接口入口:在server/index.js文件中:
// POST /api/agent/execute - 执行自然语言指令
'POST /api/agent/execute': async (req, res) => {
const body = await parseBody(req);
const { command } = body;
if (!command) {
return json(res, 400, { error: '指令不能为空' });
}
try {
const result = await agent.execute(command);
json(res, 200, result);
} catch (error) {
json(res, 500, { success: false, message: `执行失败:${error.message}` });
}
},然后进入到agent.js,给输入的句子加上系统提示词,这点很重要,我们要去大模型必须给我们返回固定的格式,方便我们解析固定的操作软件。
// ========== 2. 意图识别 ==========
/**
* 构建系统提示词,告诉 AI 如何解析指令
*/
function buildSystemPrompt() {
const toolDescriptions = Object.entries(TOOLS).map(([name, tool]) => {
const paramDesc = Object.entries(tool.parameters || {})
.map(([key, desc]) => ` - ${key}: ${desc}`)
.join('\n');
return `- ${name}: ${tool.description}\n${paramDesc}`;
}).join('\n\n');
return `你是一个电脑助手,负责将用户的自然语言指令转化为结构化的操作。
## 可用操作
${toolDescriptions}
## 输出格式
你必须以 JSON 格式输出,不要输出其他任何内容:
{
"action": "操作名称(从上面的列表中选择)",
"parameters": {
"参数名": "参数值"
}
}
## 规则
1. action 必须从可用操作列表中选择
2. parameters 必须包含该操作所需的所有必填参数
3. 如果用户只是闲聊,没有操作意图,使用 action: "chat"
4. 只输出 JSON,不要有任何解释、注释或 markdown 标记
5. 如果用户说的不明确,尽量选择最合理的操作`;
}然后调用大模型,解析返回结果中的固定action字段,和描述字段。如果解析不了,就用聊天对话兜底。
/**
* 解析用户指令,返回结构化操作
* @param {string} userInput - 用户输入的自然语言
*/
async function parseIntent(userInput) {
const schema = JSON.stringify({
action: 'string, 操作名称',
parameters: 'object, 参数键值对'
}, null, 2);
const systemPrompt = buildSystemPrompt();
const response = await ollama.chat(userInput, [], systemPrompt);
// 尝试从 AI 回复中提取 JSON
let jsonStr = response.trim();
console.log("大模型回复内容: ", jsonStr)
// 去掉 markdown 代码块标记
if (jsonStr.startsWith('```json')) {
jsonStr = jsonStr.replace(/```json\n?/, '').replace(/\n?```/, '').trim();
} else if (jsonStr.startsWith('```')) {
jsonStr = jsonStr.replace(/```\n?/, '').replace(/\n?```/, '').trim();
}
// 尝试找 JSON 花括号包裹的内容
const jsonMatch = jsonStr.match(/\{[\s\S]*\}/);
if (jsonMatch) {
jsonStr = jsonMatch[0];
}
try {
const parsed = JSON.parse(jsonStr);
// 验证 action 是否在白名单中
if (!TOOLS[parsed.action]) {
throw new Error(`未知的操作类型:${parsed.action}`);
}
return {
action: parsed.action,
parameters: parsed.parameters || {},
raw: response
};
} catch (e) {
console.error('JSON 解析失败:', e.message);
console.error('AI 原始回复:', response);
// 降级:当作聊天处理
return {
action: 'chat',
parameters: { reply: '抱歉,我没理解您的指令,能再说清楚一点吗?' },
raw: response,
parseError: e.message
};
}
}然后添加一个Tool枚举工具类。去匹配我们解析的action行为,比如说action=open_browser\open_app\open_file等,
比如说打开浏览器:
/**
* 打开浏览器并访问指定 URL
*/
open_browser: {
description: '打开浏览器(Edge/Chrome)并访问指定网址或搜索内容',
parameters: {
url: '要访问的完整网址,如 https://www.bing.com',
search: '搜索关键词(与 url 二选一)',
browser: '浏览器类型:edge 或 chrome,默认 edge'
},
async execute(params) {
const browser = params.browser || 'edge';
let targetUrl = params.url;
// 如果提供了搜索关键词,构造搜索 URL
if (params.search && !targetUrl) {
const encoded = encodeURIComponent(params.search);
targetUrl = `https://www.bing.com/search?q=${encoded}`;
}
if (!targetUrl) {
throw new Error('缺少 url 或 search 参数');
}
// Windows 命令
// 主要是execAsync函数,挺牛的,通过命令告诉操作系统,启动浏览器。
if (browser === 'chrome') {
await execAsync(`start chrome "${targetUrl}"`);
} else {
await execAsync(`start msedge "${targetUrl}"`);
}
return { success: true, message: `已打开 ${browser} 浏览器,访问 ${targetUrl}` };
}
},这里面有个很重要的函数execAsync 可以直接通知windows操作系统打开对应的app. 并且访问对应的地址。
这些就差不多了。
然后我们看运行的日志,这里是一整段:
[Agent] 收到指令: 打开记事本
[Agent] 正在解析意图...
工具描述,toolDescriptions= - open_browser: 打开浏览器(Edge/Chrome)并访问指定网址或搜索内容
- url: 要访问的完整网址,如 https://www.bing.com
- search: 搜索关键词(与 url 二选一)
- browser: 浏览器类型:edge 或 chrome,默认 edge
- open_app: 打开本地已安装的应用程序,如 notepad、calc、cmd 等
- app: 应用名称或路径,如 notepad、calc、mspaint、cmd、explorer
- args: 传递给应用的参数(可选)
- open_file: 用系统默认程序打开文件,或在资源管理器中打开文件夹
- path: 文件或文件夹的完整路径
- folder: 是否以文件夹模式打开(true 则在资源管理器中打开所在目录)
- run_command: 执行系统命令(仅限安全命令,如 dir、echo、ping 等)
- command: 要执行的命令字符串
- cwd: 工作目录(可选)
- sys_info: 获取系统信息,如 IP 地址、磁盘空间、内存使用等
- type: 信息类型:ip、disk、memory、cpu、all,默认 all
- chat: 当用户只是聊天、询问信息,不需要操作电脑时使用
- reply: 给用户的回复内容
-----------------------------------------------------------------------
大模型回复内容: {
"action": "open_app",
"parameters": {
"app": "notepad"
}
}
-------------------------------------------------------------------
[Agent] 解析结果: {
"action": "open_app",
"parameters": {
"app": "notepad"
},
"raw": "{\n \"action\": \"open_app\",\n \"parameters\": {\n \"app\": \"notepad\"\n }\n}"
}
--------------------------------------------------------------------------
[Agent] 执行操作: open_app { app: 'notepad' }比如说这里我要打开notepad。 看看给的提示词中,关于我要打开的工具的描述:
-
open_app: 打开本地已安装的应用程序,如 notepad、calc、cmd 等
-
app: 应用名称或路径,如 notepad、calc、mspaint、cmd、explorer
-
args: 传递给应用的参数(可选)
这里提示词给的大模型的限定参数就很好。输出时的结果就很准确。
workFlow工作流
这里简单延申下工作流的使用,上面知识单纯的打开一个工具,那么如果我们还要接连做几个动作怎么办?其中还有循环判断,存库操作,把这些连起来就是工作流了。
这里简单延申下,打开notepad后再输入两行文字。
效果
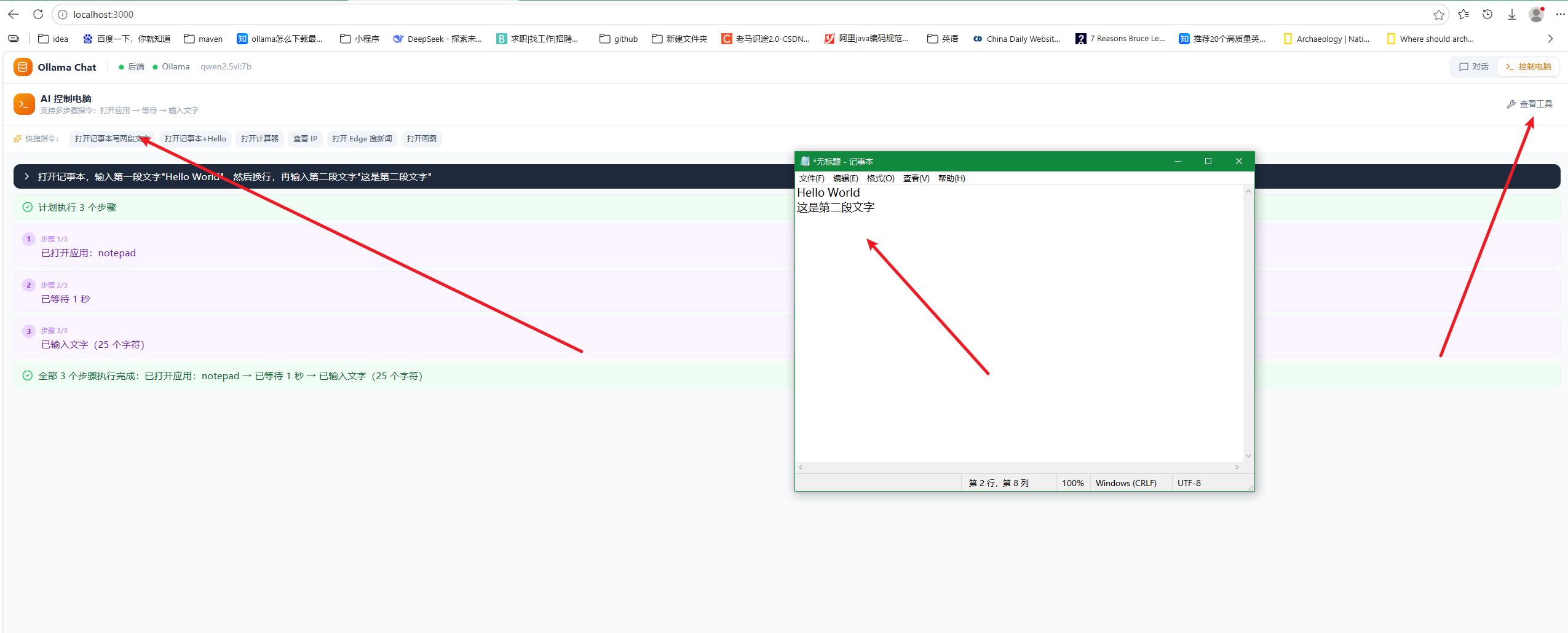
这里主要是再agent.js文件上加了三个函数,
|-----------------|-------------------------------|
| type_text | 模拟键盘输入文字(基于 Windows SendKeys) |
| wait | 等待指定秒数(给应用启动时间) |
| click | 模拟鼠标点击屏幕位置 |
/**
* 模拟键盘输入文字(Windows SendKeys)
*
* 特殊键标记:
* {ENTER} = 回车 {TAB} = 制表 {SPACE} = 空格
* {BACKSPACE} = 退格 {DELETE} = 删除键
* {UP} {DOWN} {LEFT} {RIGHT} = 方向键
* {HOME} {END} = 行首/行尾 {PGUP} {PGDN} = 翻页
* {F1}~{F12} = 功能键
* {CTRL+A} = 全选 {CTRL+C} = 复制 {CTRL+V} = 粘贴
* {CTRL+S} = 保存 {ALT+F4} = 关闭窗口
* {SHIFT+HOME} = 选中到行首 {SHIFT+END} = 选中到行尾
* { } = 左右花括号需要用 {{ 和 }} 表示
*/
type_text: {
description: '在**当前活动窗口**中模拟键盘输入文字。支持特殊键如 {ENTER} 换行、{TAB} 制表、{CTRL+A} 全选等。常用于打开记事本后自动输入内容。',
parameters: {
text: '要输入的文字内容,支持 {ENTER} {TAB} {CTRL+A} 等特殊键',
delay: '每个字符之间的延迟毫秒数(默认 10ms,太快可能丢失字符)',
window_title: '目标窗口标题关键字(可选,用于先激活窗口)',
pre_wait: '输入前等待的秒数(给窗口聚焦时间),默认 0.5 秒'
},
async execute(params) {
let text = params.text || '';
const preWait = parseFloat(params.pre_wait) || 0.5;
const windowTitle = params.window_title;
if (!text) throw new Error('缺少 text 参数');
// 等待窗口聚焦
if (preWait > 0) await sleep(preWait * 1000);
// 如果需要激活特定窗口
if (windowTitle) {
try {
await runPowerShell(`
Add-Type -AssemblyName System.Windows.Forms
$proc = Get-Process | Where-Object { $_.MainWindowTitle -like "*${windowTitle}*" } | Select-Object -First 1
if ($proc) {
[System.Windows.Forms.SendKeys]::SendWait("%") # Alt 键唤醒窗口
Start-Sleep -Milliseconds 200
}`);
} catch (e) {
console.log('[type_text] 窗口激活失败,继续尝试:', e.message);
}
}
// SendKeys 中的特殊字符需要转义
// {} 用于特殊键,所以字面量的花括号需要转义为 {{ }}
let sendKeysText = text
// 先转义实际的花括号(用户想输入 { 和 })
.replace(/\{/g, '{{')
.replace(/\}/g, '}}')
// 恢复 SendKeys 特殊键标记(把 {{ENTER}} 变回 {ENTER})
// 先还原双重转义后的特殊键
;
// 上面把 {ENTER} 变成了 {{ENTER}},需要还原
// 但 {{ 是字面量 {,所以 {ENTER} → {{ENTER}} 后需要把特殊键还原
// 用正则匹配常见的 SendKeys 标记并还原
const specialKeys = ['ENTER','TAB','SPACE','BACKSPACE','DELETE','HOME','END','PGUP','PGDN',
'UP','DOWN','LEFT','RIGHT','F1','F2','F3','F4','F5','F6','F7','F8','F9','F10','F11','F12',
'CTRL+A','CTRL+C','CTRL+V','CTRL+X','CTRL+S','CTRL+Z','ALT+F4',
'SHIFT+HOME','SHIFT+END'];
// 把 {{ENTER}} 还原为 {ENTER}
for (const key of specialKeys) {
sendKeysText = sendKeysText.split(`{{${key}}}`).join(`{${key}}`);
}
// 用 -EncodedCommand 方式执行 PowerShell,彻底避开引号转义
await runPowerShell(`
Add-Type -AssemblyName System.Windows.Forms
Start-Sleep -Milliseconds 500
[System.Windows.Forms.SendKeys]::SendWait("${sendKeysText}")
`);
return { success: true, message: `已输入文字(${text.length} 个字符)`, input: text.substring(0, 50) + (text.length > 50 ? '...' : '') };
}
},
/**
* 模拟鼠标点击
*/
click: {
description: '在屏幕指定位置模拟鼠标点击,或点击指定窗口的某个位置',
parameters: {
x: '屏幕 X 坐标(像素)',
y: '屏幕 Y 坐标(像素)',
button: '鼠标按钮:left、right、middle,默认 left',
double: '是否双击,默认 false',
window_title: '目标窗口标题(可选,用于相对坐标)'
},
async execute(params) {
const x = parseInt(params.x) || 0;
const y = parseInt(params.y) || 0;
const button = params.button || 'left';
const isDouble = params.double === 'true' || params.double === true;
// 用 PowerShell 移动鼠标并点击
const psScript = `
Add-Type -AssemblyName System.Windows.Forms
[System.Windows.Forms.Cursor]::Position = New-Object System.Drawing.Point(${x}, ${y})
Start-Sleep -Milliseconds 200
$mouse = [System.Windows.Forms.MouseButtons]::${button === 'right' ? 'Right' : button === 'middle' ? 'Middle' : 'Left'}
`;
await execAsync(`powershell -Command "${psScript.replace(/\n/g, '; ').replace(/"/g, '\"')}"`, { timeout: 10000 });
return { success: true, message: `已${isDouble ? '双击' : '点击'} (${x}, ${y})` };
}
},
/**
* 等待一段时间
*/
wait: {
description: '等待指定秒数,用于给应用启动、页面加载留出时间',
parameters: {
seconds: '等待秒数(默认 2)',
reason: '等待原因(可选,用于日志)'
},
async execute(params) {
const seconds = parseFloat(params.seconds) || 2;
const reason = params.reason || '';
await sleep(seconds * 1000);
return { success: true, message: `已等待 ${seconds} 秒${reason ? '(' + reason + ')' : ''}` };
}
},也就是,分成了三个步骤,一个是打开app,然后等一下,再写入内容。
那怎么区分这三个步骤呢?怎么拿到这三个步骤呢?
毫无疑问都是大模型返回给我们的格式化结构数据。
那怎么拿到这个格式化结构数据呢,就需要修改我们的提示词了。提示词给出AI需要返回的多步骤指令。
// ========== 2. 意图识别 ==========
function buildSystemPrompt() {
const toolDescriptions = Object.entries(TOOLS).map(([name, tool]) => {
const paramDesc = Object.entries(tool.parameters || {})
.map(([key, desc]) => ` - ${key}: ${desc}`).join('\\n');
return `- ${name}: ${tool.description}\\n${paramDesc}`;
}).join('\\n\\n');
return `你是一个电脑助手,负责将用户的自然语言指令转化为电脑操作。
## 可用操作
${toolDescriptions}
## 输出格式
用户指令可能包含**多个步骤**(如"打开记事本输入两段文字"),你必须用 steps 数组:
### 单步指令
{"action": "操作名称", "parameters": {"参数名": "参数值"}}
### 多步指令( steps 数组按顺序执行)
{"steps": [
{"action": "open_app", "parameters": {"app": "notepad", "wait": "2"}},
{"action": "wait", "parameters": {"seconds": "1", "reason": "等待记事本窗口出现"}},
{"action": "type_text", "parameters": {"text": "第一段文字内容{ENTER}{ENTER}第二段文字内容"}}
]}
## 规则
1. 支持多步骤时优先用 steps 数组,按正确顺序排列
2. 用 type_text 输入文字前,必须先 open_app 打开应用,并加 wait 等待窗口出现
3. {ENTER} 表示回车换行,{TAB} 表示制表符
4. 只输出 JSON,不要任何解释或 markdown 标记
5. 如果用户只是闲聊,用 action: "chat"`;
}
/**
* 解析用户指令
*/
async function parseIntent(userInput) {
const systemPrompt = buildSystemPrompt();
console.log("组装的系统提示词:", systemPrompt)
const response = await ollama.chat(userInput, [], systemPrompt);
console.log("大模型回复内容: ", response)
// 提取 JSON
let jsonStr = response.trim();
if (jsonStr.startsWith('\\`\\`\\`json')) {
jsonStr = jsonStr.replace(/\\`\\`\\`json\\n?/, '').replace(/\\n?\\`\\`\\`/, '').trim();
} else if (jsonStr.startsWith('\\`\\`\\`')) {
jsonStr = jsonStr.replace(/\\`\\`\\`\\n?/, '').replace(/\\n?\\`\\`\\`/, '').trim();
}
const jsonMatch = jsonStr.match(/\\{[\\s\\S]*\\}/);
if (jsonMatch) jsonStr = jsonMatch[0];
try {
const parsed = JSON.parse(jsonStr);
// 处理多步骤
if (parsed.steps && Array.isArray(parsed.steps)) {
// 验证每个步骤
for (const step of parsed.steps) {
if (!TOOLS[step.action]) throw new Error(`未知操作:${step.action}`);
}
return { steps: parsed.steps, raw: response, isMultiStep: true };
}
// 处理单步
if (!TOOLS[parsed.action]) throw new Error(`未知操作:${parsed.action}`);
return {
steps: [{ action: parsed.action, parameters: parsed.parameters || {} }],
raw: response,
isMultiStep: false
};
} catch (e) {
console.error('JSON 解析失败:', e.message);
console.error('AI 原始回复:', response);
return {
steps: [{ action: 'chat', parameters: { reply: '抱歉没理解,能再说清楚一点吗?' } }],
raw: response,
parseError: e.message
};
}
}运行日志:
[Agent] 收到指令: 打开记事本,输入第一段文字"Hello World",然后换行,再输入第二段文字"这是第二段文字"
组装的系统提示词: 你是一个电脑助手,负责将用户的自然语言指令转化为电脑操作。
## 可用操作
- open_browser: 打开浏览器(Edge/Chrome)并访问指定网址或搜索内容\n - url: 要访问的完整网址\n - search: 搜索关键词(与 url 二选一)\n - browser: 浏览器类型:edge 或 chrome,默认 edge\n\n- open_app: 打开本地应用程序,如 notepad、calc、mspaint、cmd 等\n - app: 应用名称或路径,如 notepad、calc、mspaint、cmd、explorer\n - args: 传递给应用的参数(可选)\n - wait: 启动后等待的秒数(给窗口留出时间),默认 1 秒\n\n- type_text: 在**当前活动窗口**中模拟键盘输入文字。支持特殊键如 {ENTER} 换行、{TAB} 制表、{CTRL+A} 全选等。常用于打开记事本后自动输入内容。\n - text: 要输入的文字内容,支持 {ENTER} {TAB} {CTRL+A} 等特殊键\n - delay: 每个字符之间的延迟毫秒数(默认 10ms,太快可能丢失字符)\n - window_title: 目标窗口标题关键字(可选,用于先激活窗口)\n - pre_wait: 输入前等待的秒数(给窗口聚焦时间),默认 0.5 秒\n\n- click: 在屏幕指定位置模拟鼠标点击,或点击指定窗口的某个位置\n - x: 屏幕 X 坐标(像素)\n - y: 屏幕 Y 坐标(像素)\n - button: 鼠标按钮:left、right、middle,默认 left\n - double: 是否双击,默认 false\n - window_title: 目标窗口标题(可选,用于相对坐标)\n\n- wait: 等待指定秒数,用于给应用启动、页面加载留出时间\n - seconds: 等待秒数(默认 2)\n - reason: 等待原因(可选,用于日志)\n\n- run_command: 执行系统命令(仅限安全命令)\n - command: 要执行的命令字符串\n - cwd: 工作目录(可选)\n\n- sys_info: 获取系统信息\n - type: 信息类型:ip、disk、memory、cpu、all,默认 all\n\n- chat: 当用户只是聊天,不需要操作电脑时使用\n - reply: 给用户的回复内容
## 输出格式
用户指令可能包含**多个步骤**(如"打开记事本输入两段文字"),你必须用 steps 数组:
### 单步指令
{"action": "操作名称", "parameters": {"参数名": "参数值"}}
### 多步指令( steps 数组按顺序执行)
{"steps": [
{"action": "open_app", "parameters": {"app": "notepad", "wait": "2"}},
{"action": "wait", "parameters": {"seconds": "1", "reason": "等待记事本窗口出现"}},
{"action": "type_text", "parameters": {"text": "第一段文字内容{ENTER}{ENTER}第二段文字内容"}}
]}
## 规则
1. 支持多步骤时优先用 steps 数组,按正确顺序排列
2. 用 type_text 输入文字前,必须先 open_app 打开应用,并加 wait 等待窗口出现
3. {ENTER} 表示回车换行,{TAB} 表示制表符
4. 只输出 JSON,不要任何解释或 markdown 标记
5. 如果用户只是闲聊,用 action: "chat"
大模型回复内容: {"steps": [{"action": "open_app", "parameters": {"app": "notepad"}}, {"action": "wait", "parameters": {"seconds": "1"}}, {"action": "type_text", "parameters": {"text": "Hello World{ENTER}这是第二段文字", "delay": "10"}}]}
[Agent] 解析出 3 个步骤: [
{
"action": "open_app",
"parameters": {
"app": "notepad"
}
},
{
"action": "wait",
"parameters": {
"seconds": "1"
}
},
{
"action": "type_text",
"parameters": {
"text": "Hello World{ENTER}这是第二段文字",
"delay": "10"
}
}
]
[Agent] 执行步骤 1/3: open_app
[Agent] 执行步骤 2/3: wait
[Agent] 执行步骤 3/3: type_text结束。
目前阶段还是通过模拟键盘数据来操作电脑软件的,代码实现上很麻烦,细节很多,很容易出问题。而且不同的软件操作的方式也不通用。因此最后肯定都是要向AI机器人的方向发展的。就像人一样坐在电脑面前通过视觉操作电脑。
代码地址:
https://download.csdn.net/download/csdnliuxin123524/92925807
npm install
npm run build
npm start
就能运行了。
最后记录了一个去除依赖包 压缩项目的命令:
remove-item -recurse node_modules