大家好,我是一名大一计算机学生,方向是全栈开发。这篇文章记录了我最近的学习笔记------从 JavaScript 的 var/let/const 底层机制,到用 Python 调用大模型 API 完成一个 AI 应用。希望能给同样在入门路上的同学一些参考。
一、为什么从 JS 底层开始?
很多人学前端上来就撸 React/Vue,但我觉得理解语言底层才能真正走远。JavaScript 作为一门"一周赶工出来的浏览器副产品"( Brendan Eich 1995 年只用了 10 天),它有一些与生俱来的"瑕疵"。如果不把这些坑搞明白,后面写业务代码就是踩雷。
这篇文章的核心内容围绕 var / let / const 展开,但这不仅仅是三个关键字的区别------它牵连出:
- 作用域链
- 变量提升(Hoisting)
- 暂时性死区(TDZ)
- for + setTimeout 经典面试题
- 栈内存与堆内存
二、var 的问题到底在哪?
2.1 没有块级作用域
js
var age = 100;
if (age > 12) {
var dog = age * 7; // 在块内用 var 声明
console.log(dog); // 700
}
console.log(dog); // 700 ------ 块外也能访问!var 声明的变量,只在函数体内有局部作用域 ,在 {} 代码块中是不管的。这会导致变量泄漏到外层,污染全局。
这也是为什么早期 JS 项目要用 立即执行函数(IIFE) 来模拟块级作用域------因为没有 let 的年代,只有函数能隔离变量。
2.2 变量提升(Hoisting)------ 最反直觉的坑
js
console.log(pizza); // undefined ------ 不报错!
var pizza = 'Deep Dish';这段代码不会报错,而是打印 undefined。原因是 JS 引擎在执行代码前有一个编译阶段:
javascript
编译阶段:创建执行上下文 → pizza 被赋值为 undefined
执行阶段:console.log(pizza) → undefined
pizza = 'Deep Dish' → 赋值你的代码书写顺序 ≠ 实际执行顺序 ,这种不一致是很多 bug 的根源。所以 ES6 引入 let 和 const 来终结这个问题。
💡 面试常考:var 有变量提升,let/const 没有------准确说其实也有(在编译阶段同样被创建),但你不能在声明前访问它,这就是 暂时性死区(TDZ)。
三、let & const 的正确打开方式
3.1 let:支持块级作用域
js
{
const name = 'DeepSeek';
console.log(name); // 'DeepSeek'
}
console.log(name); // ReferenceError: name is not defined{} 形成了一个独立的块级作用域,变量在花括号外面直接"消失"了,变量查找遵循冒泡规则:
javascript
当前作用域 → 外层作用域 → ... → 全局作用域 → 找不到 → ReferenceError3.2 const:常量还是"常量引用"?
这是很多初学者踩坑的地方------const 修饰的是引用,不是值:
js
// 简单数据类型:值不可变
const key = 'abc123';
key = 'ABC123'; // ❌ TypeError: Assignment to constant variable
// 复杂数据类型:引用不变,但内容可以改
const person = {
name: '李玉刚',
age: 18
};
person.age++; // ✅ 没问题!
console.log(person); // { name: '李玉刚', age: 19 }
person = '111'; // ❌ TypeError: Assignment to constant variable原理 :JavaScript 中,简单类型值存在栈内存 ,复杂类型值存在堆内存 ,变量存的是堆地址的引用。const 锁定的是栈里的那根"指针",不让你指向别的东西,但堆里的内容是可变的。
| 类型 | const 行为 |
|---|---|
| number / string / boolean | 值不可改 |
| object / array | 引用不可改,内容可改 |
3.3 let 声明和赋值可以分开,const 不行
js
let a; // ✅ 先声明,值是 undefined
a = 51; // ✅ 后赋值
const item; // ❌ SyntaxError: Missing initializer in const declaration这条规则简单但重要:const 声明时必须初始化。
四、一道面试题搞懂 for + setTimeout
这是面试高频题,也是理解 var vs let 最直观的场景:
js
// 版本一:var
for (var i = 0; i < 10; i++) {
setTimeout(function () {
console.log(`This number is ${i}`);
}, 1000);
}
// 输出:10 10 10 10 10 10 10 10 10 10为什么全是 10?
var不认块级作用域 → for 循环只有一个全局的isetTimeout是异步的,在同步的 for 循环结束后才执行- 此时
i已经变成了 10
js
// 版本二:let
for (let i = 0; i < 10; i++) {
setTimeout(function () {
console.log(`This number is ${i}`);
}, 1000);
}
// 输出:0 1 2 3 4 5 6 7 8 9为什么 let 就对了?
let支持块级作用域 → 每次迭代都创建了一个独立的i- 10 个
setTimeout各自闭包捕获的是自己那一轮的i
面试官期待的答案结构:
- 先指出
var没有块级作用域,循环结束i是 10- 说明
setTimeout异步执行,回调执行时i已经是 10- 解释
let在每次迭代创建独立绑定- 补充:如果用
var,可以通过 IIFE 或setTimeout的第三个参数来传值
五、推门入 AI:从 Jupyter Notebook 到第一个大模型应用
5.1 从 ModelScope 和 HuggingFace 说起
学 AI 避不开两个名字:海外的 HuggingFace 和国内的 ModelScope(魔搭)。

HuggingFace 2016 年成立,被称作「AI 界 GitHub」------它不是一个模型,而是一个开源社区 。上面汇聚了海量预训练模型和数据集,覆盖 NLP、CV、多模态,同时提供了 Transformers 这类让开发者直接调用的工具库。ModelScope 是阿里出品的国内对标平台,理念相同:让模型可复用、可发布、可协作。
这俩平台教会我一个关键认知:站在巨人肩膀上,不是一句鸡汤。 你不需要从零训练一个模型,社区里已经有成千上万个现成的预训练模型,你的工作是用代码把它们「用起来」------这就是调 API、写 Prompt、做应用层的意义。
5.2 Jupyter Notebook:实验型编程的最佳拍档
NLP 实验、数值运算、算法验证------这些场景有一个共同点:你需要边写边看结果。
传统 IDE 的「写完 → 编译 → 运行 → 看输出」循环太慢了。Jupyter Notebook 的设计哲学完全不同:随时编写,随时运行。
python
# 在 Notebook 里,每个 cell 都是一个独立的实验单元
# 你可以改一行,立刻看输出,不需要重新跑整个文件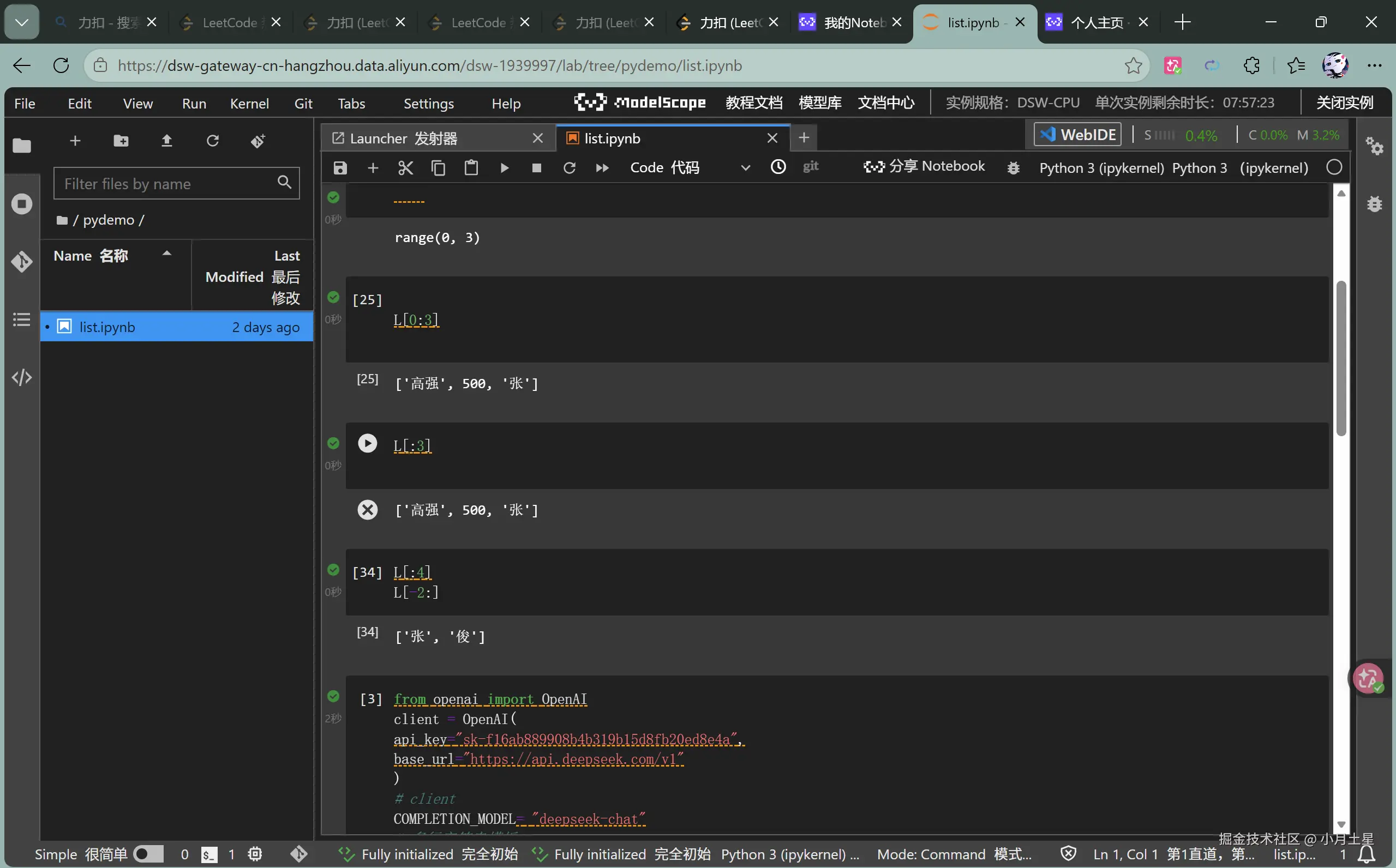
python
# Python 列表切片 ------ 优雅到令人发指
L = ['高强', 500, '张', '俊']
L[:3] # ['高强', 500, '张']
L[-2:] # ['张', '俊']🧩 和 JS 数组的思维差异 :Python 的
list是一个"可变序列容器",可以塞不同类型的元素,操作偏数学切片思维。JS 数组是稀疏的、有length自动维护、原型链上挂了一堆方法。两种语言思维切换,在全栈路上不是负担------你会开始关注**"这个语言为什么这样设计"**,而不是"这个语法怎么背"。
接触过 JS 的数组方法再来看 Python 切片,会觉得 Python 对数据的操作确实简洁。不同语言的思维切换,也是全栈路上的必修课。
5.2 调用 DeepSeek API 生成商品文案
python
from openai import OpenAI
client = OpenAI(
api_key="sk-xxxxxxxx", # 替换为你的 key
base_url="https://api.deepseek.com/v1"
)
COMPLETION_MODEL = "deepseek-chat"
prompt = """
Consideration product : 工厂现货PVC充气青蛙夜市地摊热卖
充气玩具发光蛙儿童水上玩具
1. Compose human readable product title used on Amazon
in English within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties
called title, selling_points and price_range.
"""
def get_response(prompt):
response = client.chat.completions.create(
model=COMPLETION_MODEL,
messages=[
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
print(get_response(prompt))API 返回结果:
json
{
"title": "Inflatable PVC Light-Up Frog Toy for Pool, Beach, Night Market Fun",
"selling_points": [
"Built-in LED lights make the frog glow brightly at night...",
"Made from durable, non-toxic PVC material...",
"Designed for versatile water fun...",
"Eco-friendly rechargeable or battery-operated design...",
"Eye-catching frog shape with bright colors..."
],
"price_range": "$8.99 -- $14.99"
}5.3 这段代码教会我的事
- Promp Engineering 是核心能力:同样的模型,喂不同的 Prompt,输出质量天差地别。想清楚你要什么格式、什么语气、什么场景,比调参数更重要。
- JSON 输出是关键规范:让模型返回结构化数据,这样代码可以自动化处理,而不是拿到一堆自然语言还要手动解析。
- AI 只是工具,你才是决策者:模型生成的文案和定价只能参考,最终还是要结合真实市场数据做决策。
六、我的学习路线总结
技术路线图
大一阶段我的几个核心感悟:
| 感悟 | 说明 |
|---|---|
| 先深后广 | 把一个知识点(如 var/let/const)彻底搞懂,比泛泛看 10 个教程有用 |
| 写代码 > 看视频 | 抄一遍代码,加自己的注释,调 BUG,这个过程不可替代 |
| 笔记要有观点 | 不是照搬文档,而是记录"为什么这么设计""坑在哪里" |
| 全栈不是全会 | 全栈的核心是打通前后端+AI 的链路,而不是每项技术都精通 |
| AI 是杠杆 | 大一会用 AI 工具,相当于进了加速通道,但基础原理仍然是地基 |
七、写在最后
这不是偶然的。
2026 年入门编程,和五年前最大的不同是:AI 不再是选修课,而是必修课。 你不需要成为算法研究员,但你必须知道怎么调用大模型、怎么写 prompt、怎么把 AI 能力嵌入到你的应用里。
作为一个刚上路的大一学生,我知道未来还有很长的路要走------从 JS 底层到 Node.js 服务端,从 Python 脚本到真正的 AI 应用落地,中间隔着无数个 Debug 的深夜。
但学编程最有趣的地方就在于:你每搞懂一个底层原理,就好像点亮了技能树上的一盏灯,原本黑暗的地图慢慢变得清晰起来。