参考大模型基础之评测,本文专注于介绍CLUE、GLUE。
CLUE
官网,The Chinese Language Understanding Evaluation缩写,中文语言理解基准,对标GLUE,开源(GitHub,4.3K Star,544 Fork),论文。
发起于2019年,陆续推出CLUE、FewCLUE、DataCLUE、ZeroCLUE、KgCLUE、SimCLUE等广为引用的测评基准。
评估指标
- 单任务指标:准确率(Accuracy)为主,CMRC/DRCD使用EM(精确匹配)和F1
- 综合评分:所有任务平均分,作为模型综合排名依据
- 分组评分:理解类、推理类、阅读理解类分别给分
局限性
- CLUE设计于2020年,面向预训练语言模型(BERT/RoBERTa时代),大多数任务对现代LLM而言已经接近或超过人类水平(如CMNLI任务,GPT-4已达91%+),区分度极低。
- 任务形式(多选、分类)也不适合评估LLM的生成能力和指令遵循能力。
| 任务名称 | 全称 | 类型 | 训练集大小 | 说明 |
|---|---|---|---|---|
| AFQMC | Ant Financial Question Matching Corpus | 文本相似度 | 34,334 | 蚂蚁金服问题匹配语料,判断两个问题语义是否相同 |
| TNEWS | Toutiao News Classification | 新闻分类 | 53,360 | 今日头条短新闻标题分类,15个类别 |
| IFLYTEK | 科大讯飞App分类 | 文本分类 | 12,133 | App描述长文本分类,119个类别 |
| CMNLI | Chinese Multi-Genre NLI | 自然语言推理 | 391,782 | 中文多类型自然语言推理,含蕴涵/矛盾/中立 |
| OCNLI | Original Chinese Natural Language Inference | 自然语言推理 | 50,000 | 原创中文自然语言推理,避免翻译数据的"翻译腔 |
| C3 | Chinese Multiple Choice Machine Comprehension | 机器阅读理解 | 11,869 | 多项选择阅读理解,对话/混合域 |
| CHID | Chinese Idiom Dataset | 成语填空 | 84,709 | 中文成语(词汇)填空,10个候选项 |
| CMath | Chinese Math Problem | 数学应用题 | 1,000 | 小学数学文字题,需要数值推理 |
| CSL | Chinese Scientific Literature | 关键词识别 | 21,000 | 判断论文关键词是否真实 |
| CMRC2018 | Chinese Machine Reading Comprehension | 抽取式阅读理解 | 10,321 | 从维基百科段落抽取答案片段 |
| DRCD | Delta Reading Comprehension Dataset | 抽取式阅读理解 | 26,936 | 台湾繁体中文阅读理解(CLUE提供简体转换版) |
| ChineseSQuAD | 中文SQuAD | 抽取式阅读理解 | 29,968 | 翻译自SQuAD的中文版 |
FewCLUE
论文,开源(GitHub,518 Star,75 Fork),专门评测模型在少样本(1-shot、4-shot、8-shot)设置下的快速适应能力:
- BUSTM:小布对话语义匹配(阿里小布)
- EPRSTMT:电商评论情感分析
- OCNLI:原创中文自然语言推理
- CSLDCP:中文学科文献分类
- TNEWS':今日头条分类(少样本版)
- IFLYTEK':讯飞App分类(少样本版)
- CLUEWSC2020:中文代词消歧
pCLUE
开源(GitHub,508 Star,60 Fork)基于提示的大规模预训练数据集,用于多任务学习和零样本学习。
包含9个数据集:
- 单分类tnews
- 单分类iflytek
- 自然语言推理ocnli
- 语义匹配afqmc
- 指代消解-cluewsc2020
- 关键词识别-csl
- 阅读理解-自由式c3
- 阅读理解-抽取式cmrc2018
- 阅读理解-成语填空chid
kgCLUE
开源(GitHub,458 Star,61 Fork)。
SimCLUE
开源(GitHub,314 Star,40 Fork)。
提供一个大规模语义数据集;可用于语义理解、语义相似度、召回与排序等检索场景等;作为通用语义数据集,用于训练中文领域基础语义模型。 可用于无监督对比学习、半监督学习、Prompt Learning等构建中文领域效果最好的预训练模型。
DataCLUE
论文,开源(GitHub,144 Star,17 Fork),以数据为中心(Data-centric)的AI,核心问题是如何通过系统化的改造数据(无论是输入或标签)来提高最终效果。传统AI是以模型为中心(Model-centric)的,主要考虑的问题是如何通过改造或优化模型来提高最终效果,通常建立在一个比较固定的数据集上。
基于CLUE,在原始数据集外,通过提供额外的高价值的数据和数据和模型分析报告(增值服务)的形式, 使得融入人类的AI迭代过程(Human-in-the-loop AI pipeline)变得更加高效,并能较大幅度的提升最终效果。
ZeroCLUE
开源(GitHub,59 Star,7 Fork),评测模型在零样本(Zero-shot)设置下的中文NLU能力,无需任何微调。
在GPT-3展示出强大的少样本学习能力之前,NLP模型都需要在具体任务上微调。ZeroCLUE提出一个重要问题:模型在没有见过任何特定任务标注数据的情况下,能做多少?直接催生后来的Prompt-based Learning研究浪潮。
ZeroCLUE复用CLUE的部分任务,但强制要求零样本设置:
- 测试时不提供任何标注样本
- 只允许使用任务描述(Prompt)
- 对比不同Prompt形式下的模型表现
评估能力
中文 NLU 能力
├── 语义理解
│ ├── 文本相似度(AFQMC)
│ ├── 情感分析
│ └── 语义推理(CMNLI/OCNLI)
├── 知识与阅读
│ ├── 机器阅读理解(CMRC2018)
│ ├── 多选阅读理解(C3)
│ └── 词汇理解(CHID)
└── 文本分类
├── 短文本(TNEWS)
└── 长文本(IFLYTEK)其他
SuperCLUE
开源(GitHub,3.3K Star,112 Fork)。
SuperCLUE是大模型时代CLUE的发展和延续,聚焦于通用大模型的多层次、多维度、综合性测评。定位:中文通用大模型综合性测评基准,对标MT-Bench、HELM等。
对比传统测评
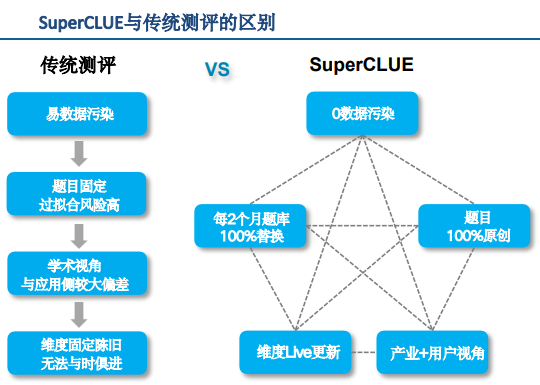
三大特征:
- Live更新,0数据污染:测评题库每2个月100%替换且全部原创,杜绝过拟合风险。体系维度根据大模型进展Live更新。
- 测评方式与用户交互一致:测评任务贴近真实落地场景,高度还原用户视角。
- 独立第三方,无自家模型:承诺提供无偏倚的客观、中立评测结果。
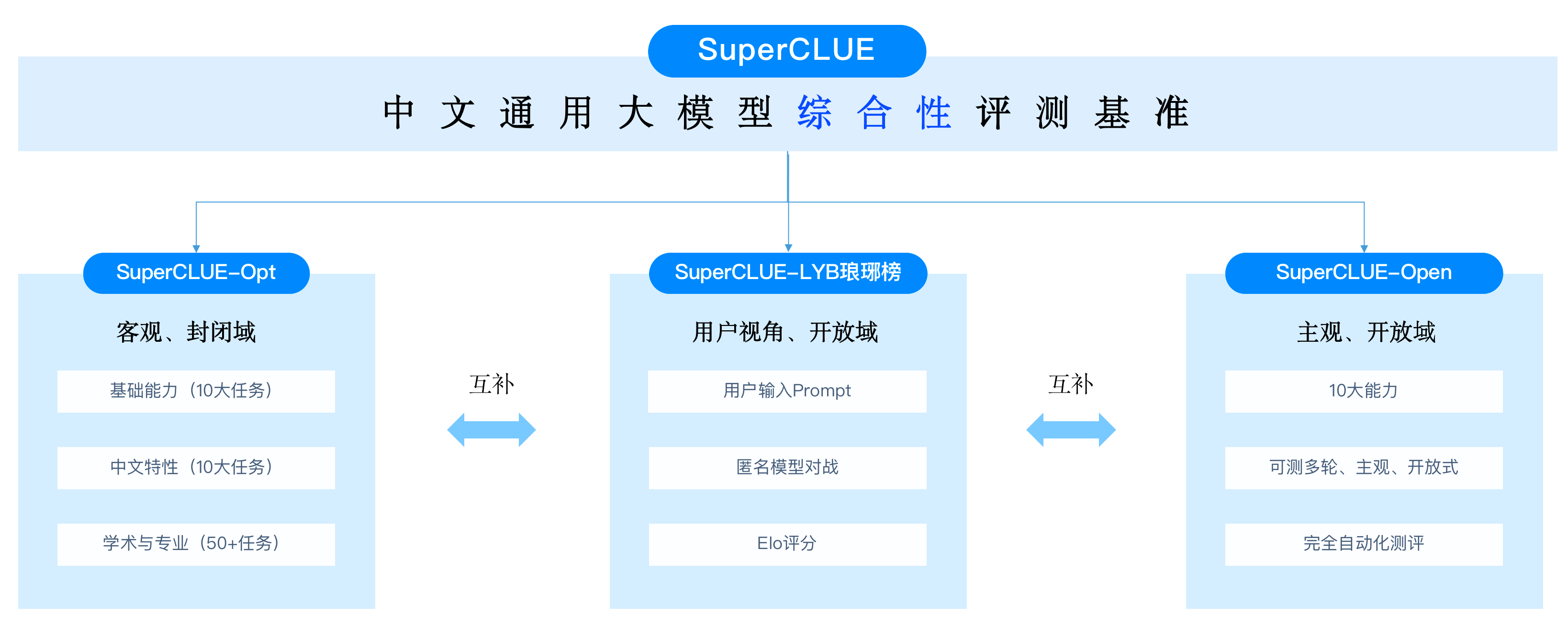
包括三大基准:OPEN多轮开放式基准、OPT三大能力客观题基准、琅琊榜匿名对战基准。
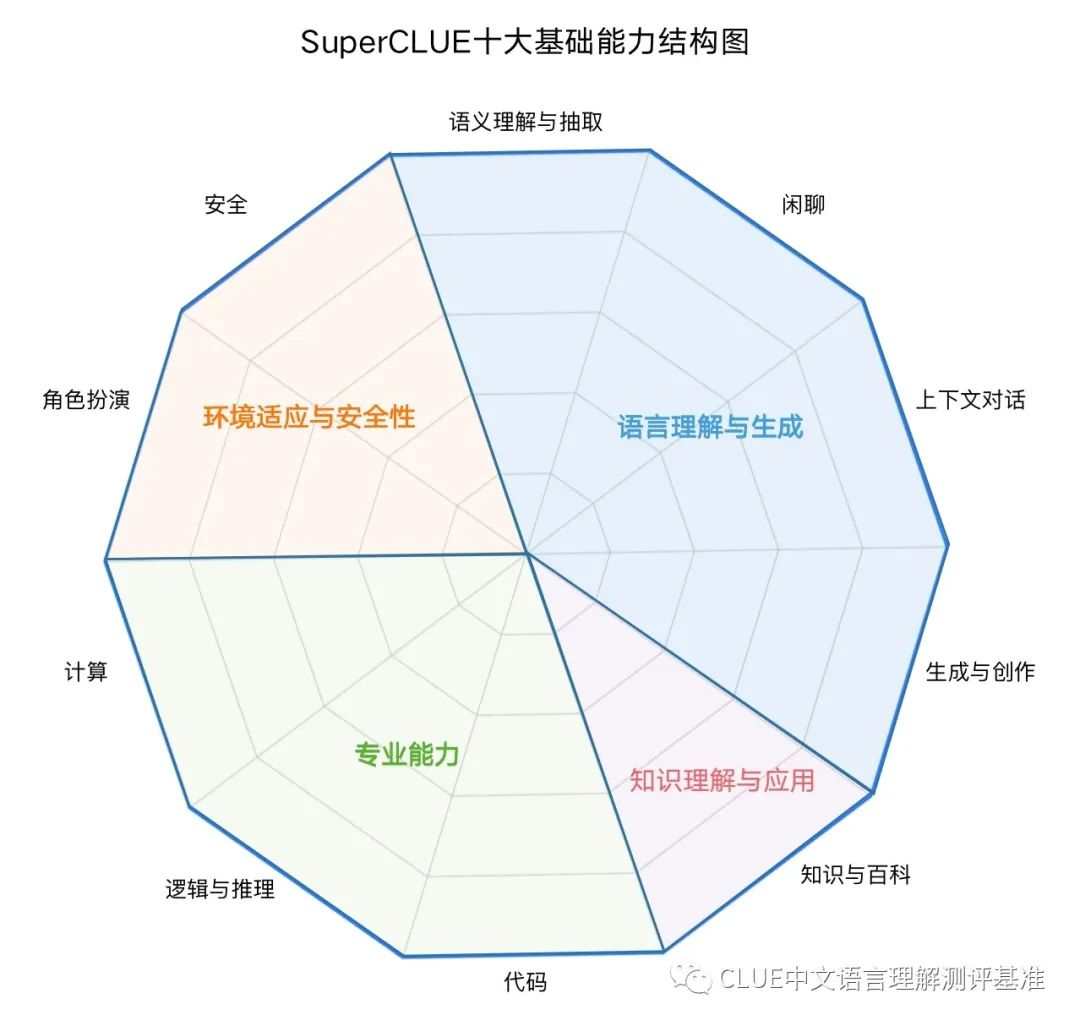
其中基础能力分为4大类共10个:
- 语言理解与生成
- 语言理解与抽取
- 闲聊
- 上下文对话
- 生成与创作
- 知识理解与应用:知识与百科
- 专业能力:
- 代码
- 逻辑与推理
- 计算
- 环境适应与安全性
- 角色扮演
- 安全
通过多个层面,考研市面上主流的中文GPT大模型的能力:
- 一是基础能力:上面提过
- 二是专业能力:包括中学、大学与专业考试,涵盖数学、物理、地理到社会科学等50多项;
- 三是中文特性能力:针对有中文特点的任务,包括中文成语、诗歌、文学、字形等10项。
数据集和评价方式

体系
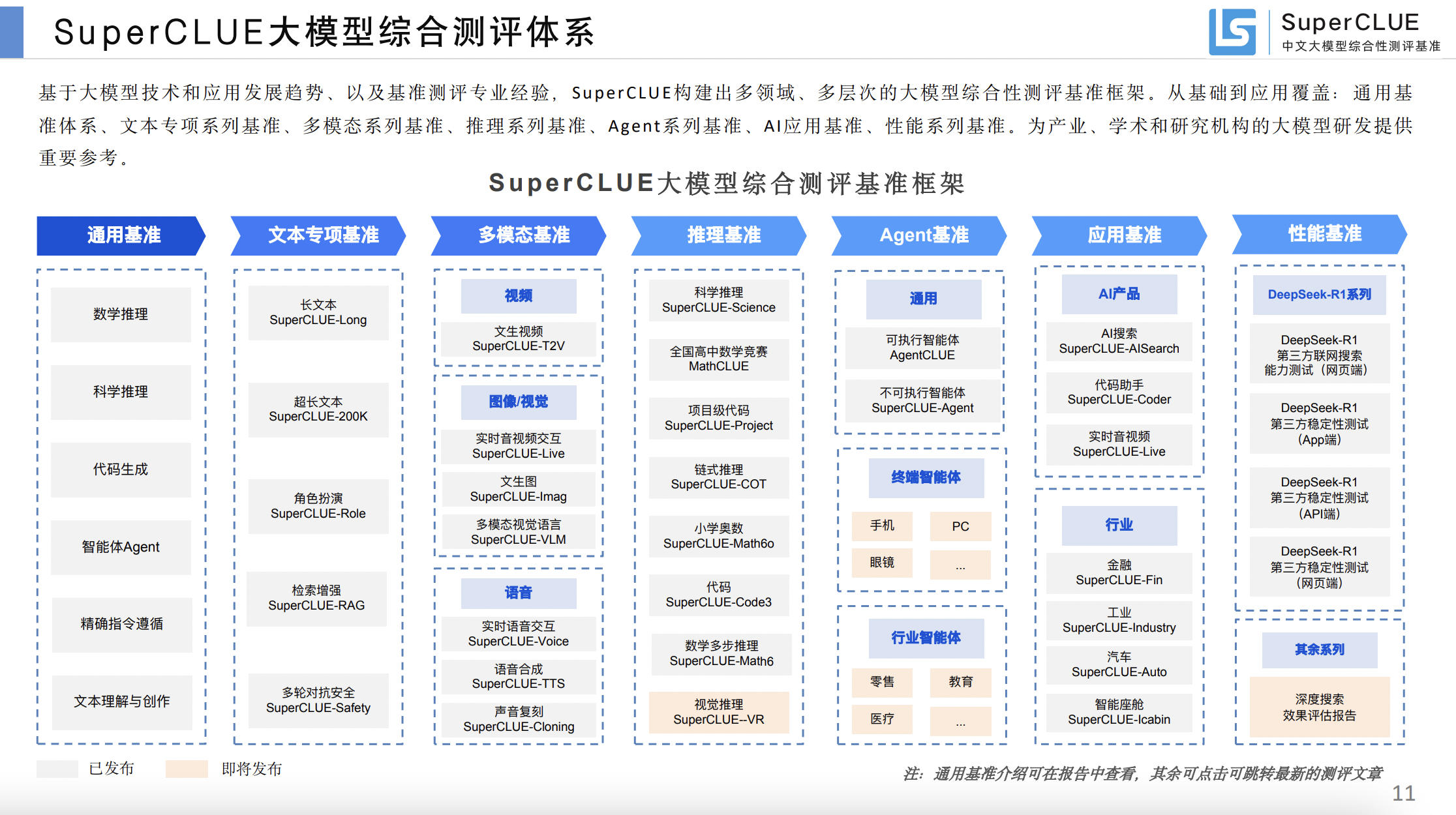
评估能力
中文LLM能力
├── 基础语言能力
│ ├── 语言理解(语义/篇章/跨语言)
│ ├── 语言生成(质量/创意/摘要)
│ └── 知识(百科/时事/领域)
├── 专业技能
│ ├── 数学(算术/代数/应用)
│ ├── 代码(生成/调试/算法)
│ ├── 逻辑(演绎/归纳/类比)
│ └── 中文特色(成语/诗词/古文)
└── 对齐能力
├── 指令遵循(理解/格式/多约束)
├── 安全合规(拒绝/价值观/隐私)
└── 事实准确(幻觉控制/引用/时效)多模态
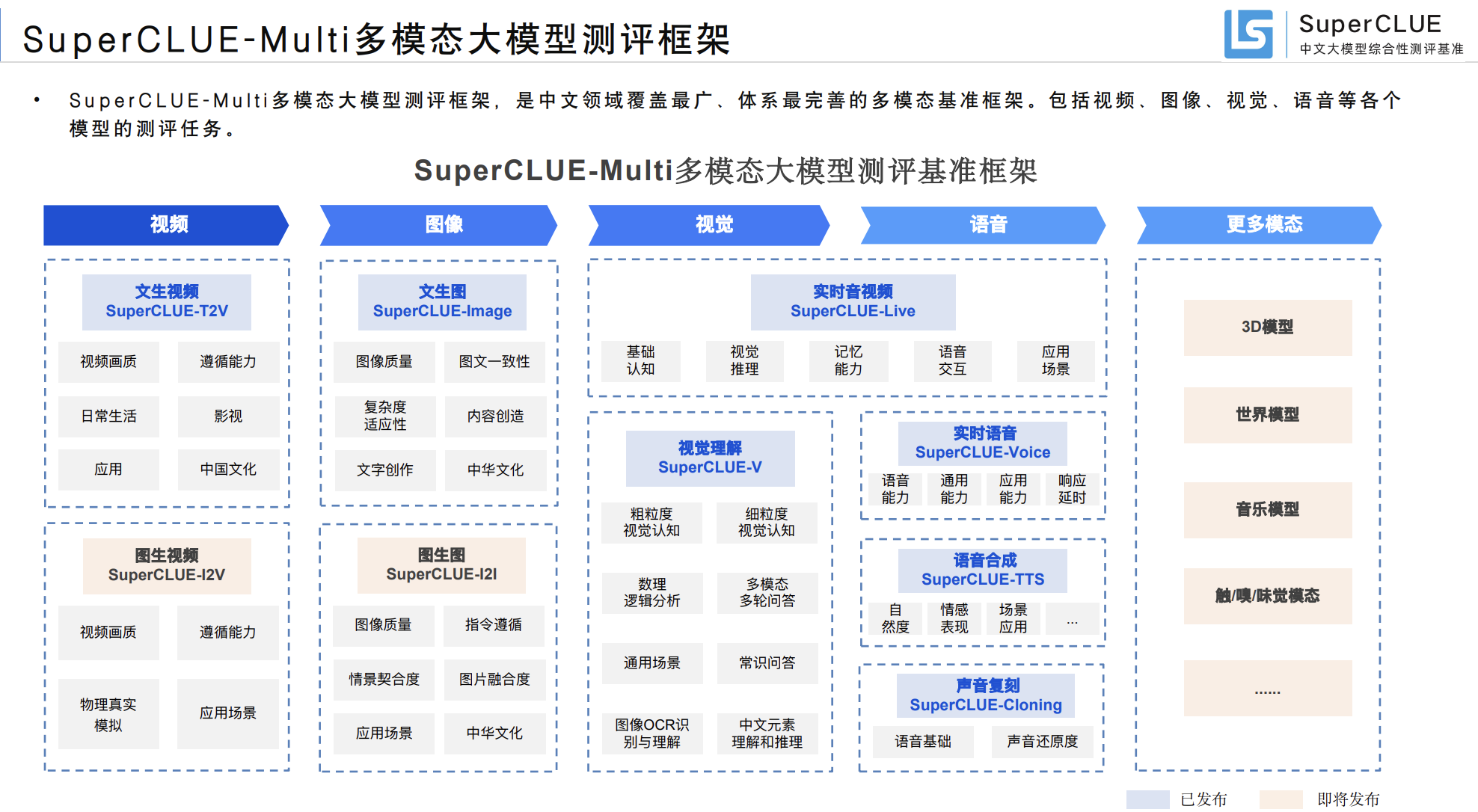
包括:
- T2I:Text-to-Image,文生图,专为中文设计,提供全面公正的评估框架,覆盖图像质量、图文一致性、文字生成、对话式生图和创作能力五大核心维度构建评测体系,旨在为文生图模型的发展提供客观、公正的参考标准。
- I2I:Image-to-Image,图生图,
- T2V:Text-to-Video,文生视频,英文基准,如VBench、FETV和EvalCrafter。AIGVBench-T2V,中文专用的多层次基准,旨在通过一系列详尽的评估指标和测试数据集,全面衡量中文视频生成模型在生成质量、多样性及一致性等方面的性能。
- I2V:Image-to-Video,图生视频,该基准立足于中文语境,围绕运动流畅性、内容一致性、物理真实性、动漫风格、写实风格和奇幻风格六大任务构建评测体系,旨在为图生视频模型的发展提供客观、公正且具有针对性的评估标准。
- Voice:实时语音交互,旨在深入评估新一代实时语音交互产品在中文语音交互中的整体表现。全面考察产品在打断、说话风格等语音交互核心能力上的表现,重点评估其在记忆能力、联网能力等通用能力上的综合水平。特别关注产品在实时翻译、教育辅导等五大实际应用场景中的表现,旨在为语音交互技术的多场景落地提供全面的评判标准。
- TTS:Text-to-Speech,语音合成,该基准评估关注模型的语音合成基础能力,全面衡量模型所生成的语音的准确度、清晰度、自然度与情感表现能力,并纳入大量应用场景的考察。
- V:Vision,多模态视觉理解,从基础能力和应用能力两个大方向,以开放式问题形式对多模态大模型进行评估,涵盖8个一级维度30个二级维度。
- VLM:V的升级版,该基准立足于中文场景特点,围绕基础认知、视觉推理和视觉Agent执行力三大核心维度构建评测体系,旨在为多模态模型的发展提供客观、公正的参考标准。
- VLR:视觉推理,在VLM基础上,提取视觉推理能力的部分,进行优化。该基准专注于考察视觉语言模型的推理能力,并围绕数学推理、科学推理、空间推理、代码推理、逻辑推理、时间推理等六大核心维度构建测评体系。
SuperCLUE-Safety
论文,开源(GitHub,151 Star,12 Fork)中文大模型多轮对抗安全基准。
三个特点:
- 融合对抗性技术,具有较高的挑战性:通过模型和人类的迭代式对抗性技术的引入,大幅提升安全类问题的挑战性;可以更好的识别出模型在各类不良诱导、恶意输入和广泛领域下的安全防护能力
- 多轮交互下安全能力测试:不仅支持单轮测试,还同时支持多轮场景测试。能测试大模型在多轮交互场景下安全防护能力,更接近真实用户下的场景
- 全面衡量大模型安全防护能力:除了传统安全类问题,还包括负责任人工智能、指令攻击等新型和更高阶的能力要求
局限性
- 维度覆盖:由于大安全类问题具有长尾效应,存在很多不太常见但也可以引发风险的问题。
- 模型覆盖:目前已经选取国内外代表性的一些闭源服务、开源模型(10+),但还很多新的模型没有纳入(如豆包、混元)。
- 自动化评估存在误差:虽然通过自动化与人类评估的一致性实验(后续会进一步报告),获取高度一致性,但自动化评估的准确率存在着进一步研究和改进的空间。
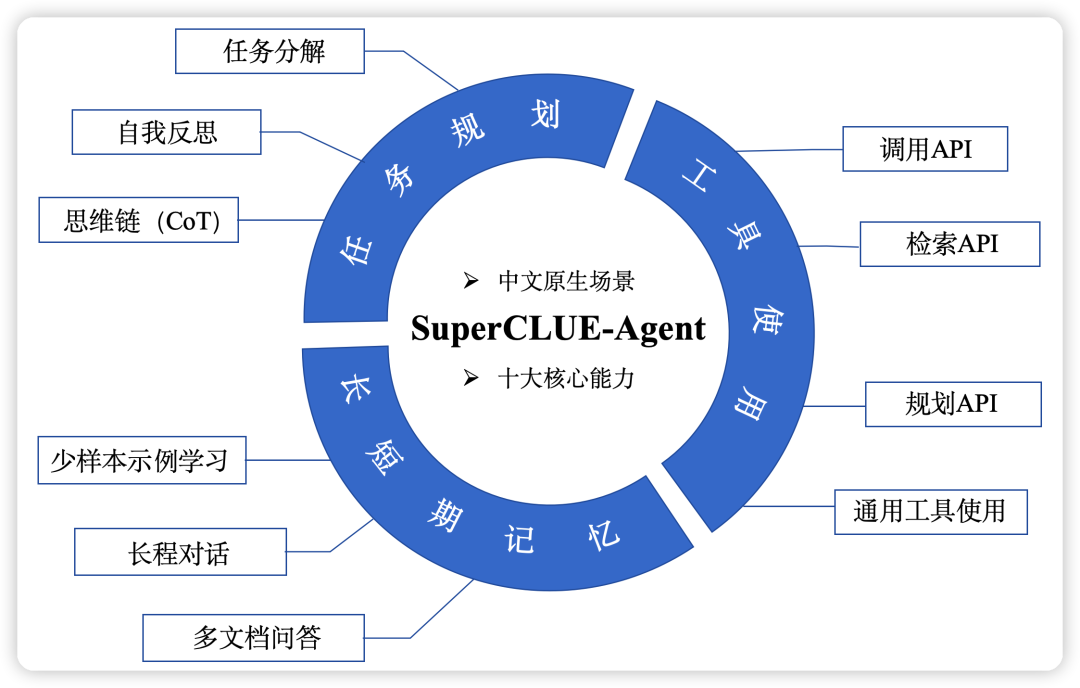
SuperCLUE-Agent
介绍,开源(GitHub,94 Star,6 Fork),面向AI智能体的测评基准,聚焦于Agent能力的多维度基准测试,用于评估LLM在核心Agent能力上的表现,包括、和能力。
包括3大核心能力10大基础任务:
- 工具使用:调用API、检索API、规划API、通用工具使用;
- 任务规划:任务分解、自我反思、思维链CoT;
- 长短期记忆:少样本示例学习、多文档问答、长程对话。
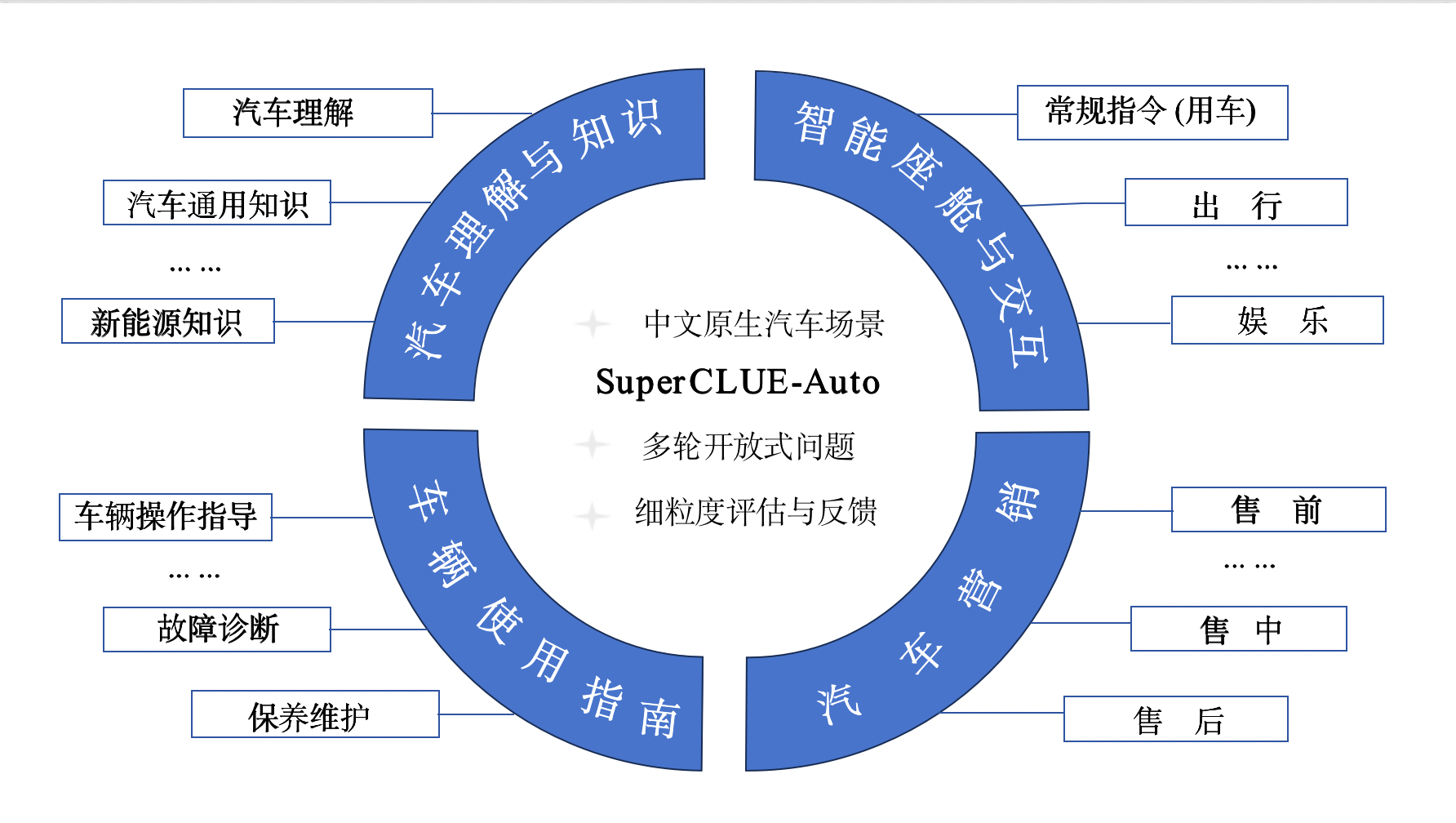
SuperCLUE-Auto
介绍,开源(GitHub,38 Star,4 Fork),首个汽车行业大模型多维度多轮开放式问题的测评基准。
包括:
- 智能座舱与交互:用车、出行、娱乐、信息获取等;
- 汽车营销:包括但不限于:汽车厂商的产品发布会文案、汽车媒体介绍产品亮点、汽车测评、4S宣传促销文案、选车、汽车视频、汽车资讯等;
- 车辆使用指南:车辆操作指导、保养维护、故障诊断、售后资源等;
- 汽车理解与知识:汽车理解、汽车通用知识、新能源知识等;
SuperCLUE-Code3
开源(GitHub,15 Star,1 Fork),针对中文大模型代码生成能力的测评集和基准,HumanEval的中文升级版。
特点:
- 中文原生环境测试:着重考查模型在处理中文编程问题上的性能,所有编程问题有多个测试用例、经过多重校验、可进行端到端的测试,确保评估的准确性和专业性。
- 全面的任务类型:从字符串处理到数据分析到算法问题,包含编程中的8种常见问题类型,旨在全面评估中文大模型在不同编程领域的能力。
- 多级难度评估:通过将测试任务分为初级、中级和高级,可提供不同层次的评估结果,帮助模型开发者了解模型在不同复杂程度的编程问题上的表现。
GLUE
General Language Understanding Evaluation,官网,论文,开源(GitHub,827 Star,176 Fork),不过代码库最后一次提交还是6年多,且已明确标记废弃。
包含9个不同NLU任务:
- CoLA:语法性判断(Corpus of Linguistic Acceptability)
- SST-2:情感分析(Stanford Sentiment Treebank)
- MRPC:语义相似度(Microsoft Research Paraphrase Corpus)
- STS-B:语义文本相似度(连续分数,0-5)
- QQP:Quora 问题对匹配
- MNLI:多类型自然语言推理(Matched + Mismatched)
- QNLI:问答推理(从 SQuAD 转换)
- RTE:文本蕴含识别
- WNLI:Winograd NLI(代词消歧)
评分机制:各任务使用对应指标,综合评分取平均。人类基线约87.1,BERT发布时达到80.5,目前最好模型已超越人类。
SuperGLUE
| 任务 | 全称 | 类型 |
|---|---|---|
| BoolQ | Boolean Questions | 是否类问答 |
| CB | CommitmentBank | 三类 NLI |
| COPA | Choice of Plausible Alternatives | 因果推理 |
| MultiRC | Multi-Sentence Reading Comprehension | 多选阅读理解 |
| ReCoRD | Reading Comprehension with Commonsense Reasoning Dataset | 完形填空 |
| RTE | Recognizing Textual Entailment | 文本蕴含 |
| WiC | Words in Context | 词义消歧 |
| WSC | Winograd Schema Challenge | 代词消歧/常识推理 |
| AX-b | Broad Coverage Diagnostic | 诊断数据集 |
| AX-g | Winogender Schema Diagnostics | 性别偏见诊断 |