本文分析 realtime-vla,在单张消费级 RTX 4090 GPU 上的实时推理,达成 30Hz 图像推理速率 、最高 480Hz 轨迹控制频率。
支持pi0、pi0.5、DM0等VLA模型 🔥 ,模型加速后的推理时间:
| Model / Backend | RTX 4090 (1 view) | RTX 4090 (2 views) | RTX 4090 (3 views) | RTX 5090 (1 view) | RTX 5090 (2 views) | RTX 5090 (3 views) |
|---|---|---|---|---|---|---|
| Pi0 Triton | 20.0ms | 27.3ms | 36.8ms | 17.6ms | 24.0ms | 31.9ms |
| Pi05 Triton | 22.1ms | 29.2ms | 38.9ms | 20.1ms | 26.6ms | 34.2ms |
| DM0 Triton | 55.8ms |
论文地址:Running VLAs at Real-time Speed
开源地址:https://github.com/dexmal/realtime-vla
论文复现,参考我这篇博客:《VLA 系列》复现 realtime-vla | 加速推理 | Triton后端
一、VLA 实时性 分析
1.1 目前VLA的问题
当前十亿参数级别的 VLA(Vision-Language-Action)模型虽然有一点泛化能力,但推理延迟高达数百毫秒,无法满足动态实时任务需求(如抓取下落物体)。论文的核心目标是:
在单张消费级 RTX 4090 GPU 上,将 π0 级别的多视角 VLA 推理速度提升至 30Hz(≤33ms),并实现最高 480Hz 的轨迹控制频率。
关键指标对比:
| 方法 | 1视角 | 2视角 | 3视角 |
|---|---|---|---|
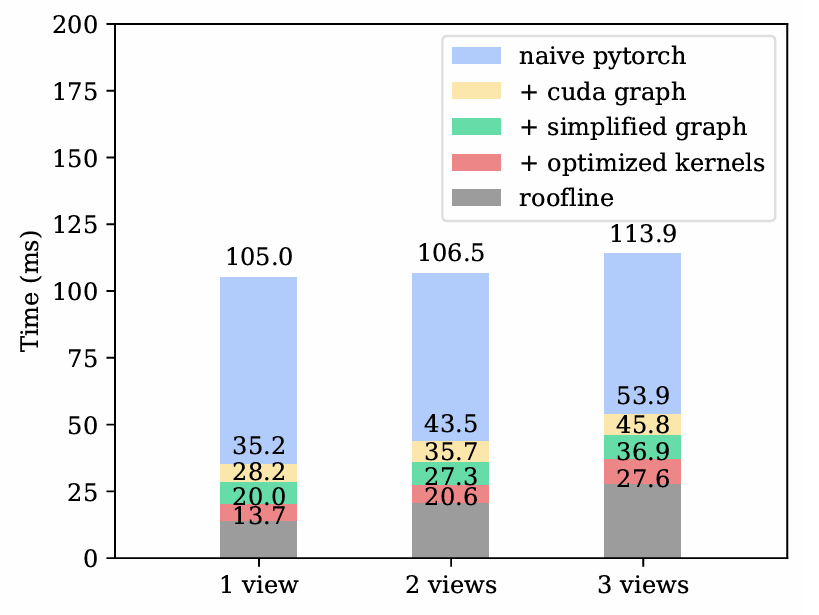
| PyTorch | 105.0 ms | 106.5 ms | 113.9 ms |
| openpi/jax | 43.8 ms | 53.7 ms | 67.6 ms |
| realtime-vla | 20.0 ms | 27.3 ms | 36.8 ms |
关键洞察:33ms 是实时操作的临界点(对应 30FPS 相机流全帧处理)。即使达到 34ms,也会因丢帧导致最坏情况延迟增加一整帧。
1.2 动态任务的实时性需求
案例选择策略:
- "grasping a moving object"(抓取移动物体) :直观易懂,同时涉及感知 (视觉跟踪)和动作(抓取时机),契合 VLA 的 Vision-Language-Action 定位。
时间尺度对比:
css
人类反应时间: ~200ms (视觉刺激 → 动作启动)
VLA 推理时间: ~100-500ms (仅模型前向传播)
差距: 模型推理已接近甚至超过人类总反应时间1.3 优化策略三层递进
三层策略的逻辑关系:
css
┌─────────────────────────────────────────┐
│ 第一层: CUDA Graph │
│ 作用域: 跨 kernel 的调度开销 │
│ 收益: ~2x 加速 (105ms → ~50ms) │
│ 性质: 通用,加速效果显著,做成"静态计算图"
├─────────────────────────────────────────┤
│ 第二层: 计算图简化 │
│ 作用域: 模型结构层面的等价变换 │
│ 收益: 再减 7-8ms │
│ 性质: 需要理解模型数学结构 │
├─────────────────────────────────────────┤
│ 第三层: Kernel 内优化 │
│ 作用域: 单个 kernel 的并行效率 │
│ 收益: 逼近 roofline 下限 │
│ 性质: 硬核优化,需要深入硬件架构 │
└─────────────────────────────────────────┘不同策略的加速效果对比:
| 视角 | PyTorch | +CUDA Graph | +计算图简化 | +优化 Kernel | Roofline | 总加速比 |
|---|---|---|---|---|---|---|
| 1 view | 105.0 | 35.2 (-66.5%) | 28.2 (-20.0%) | 20.0 (-29.1%) | 13.7 | 5.25× |
| 2 views | 106.5 | 43.5 (-59.2%) | 35.7 (-17.9%) | 27.3 (-23.5%) | 20.6 | 3.90× |
| 3 views | 113.9 | 53.9 (-52.7%) | 36.9 (-31.5%) | 27.6 (-25.2%) | 27.6 | 4.13× |
1.4 范式升级:Full Streaming Inference
传统三层架构 vs realtime-vla:
css
传统认知:
┌─────────────┐ 1-10 Hz VLM 高层规划
├─────────────┤ 30 Hz VLA 中层控制 ← 传统认为 VLA 只在此层
├─────────────┤ 100-1000 Hz 力控/力矩控制 ← 传统认为需其他算法
realtime-vla 发现: VLA 内部结构天然包含不同频率层级
• VLM(视觉-语言模型)→ 适合 30Hz 视觉循环
• AE(动作专家)→ 可运行至 480Hz 高频循环未来展望:
- 近期(System 1 层):VLM 作为高层感知规划,1-10Hz
- 远期(多感官融合):力觉、视觉-触觉接入 AE,实现更精细的实时控制
二、基于 π0 系列的 架构基础
2.1 宏观架构:VLM + AE 双塔结构
css
┌─────────────────────────────────────────────────────────────────┐
│ π0 模型架构 │
│ (Vision-Language-Action) │
├─────────────────────────────┬───────────────────────────────────┤
│ VLM Backbone │ Action Expert (AE) │
│ (PaliGemma) │ (300M 参数) │
│ (3B) │ │
├─────────────────────────────┼───────────────────────────────────┤
│ ┌─────────────────────┐ │ ┌─────────────────────────┐ │
│ │ Vision Encoder │ │ │ Action-Time Embedding │ │
│ │ (SigLIP 400M) │ │ │ action[32] ──→ embed │ │
│ │ │ │ │ time[1] ─────→ embed │ │
│ │ image ──→ patch │ │ │ ↓ concat │ │
│ │ tokens │ │ │ hidden[1024] ──→ SiLU │ │
│ │ ↓ │ │ │ ↓ │ │
│ │ ┌─────────────┐ │ │ │ feature[1024] │ │
│ │ │ Gemma │ │ │ │ ↓ │ │
│ │ │ LLM 2.6B │ │ │ │ Flow Matching │ │
│ │ │ │ │ │ │ Denoising (10 steps) │ │
│ │ │ text ──→ │ │ │ │ ↓ │ │
│ │ │ hidden │ │ │ │ action trajectory │ │
│ │ │ states │ │ │ │ [chunk_size, dim] │ │
│ │ └─────────────┘ │ │ └─────────────────────────┘ │
│ │ ↓ │ │ │
│ │ output tokens │ │ │
│ │ (language/vision) │ │ │
│ └─────────────────────┘ │ │
├─────────────────────────────┴───────────────────────────────────┤
│ MoE 耦合机制 │
│ • VLM 输出 → 路由到 AE (作为条件/上下文) │
│ • AE 的 KV Cache 来自 VLM 最后层 │
│ • 多视角图像 + 任务提示 → VLM │
│ • 机器人状态 + 动作噪声 → AE │
└─────────────────────────────────────────────────────────────────┘2.2 参数规模对比
| 组件 | 模型 | 参数量 | 占比 | 功能定位 |
|---|---|---|---|---|
| Vision Encoder | SigLIP | 400M | 11.4% | 视觉特征提取 |
| LLM | Gemma | 2.6B | 74.3% | 语言/视觉理解 |
| Action Expert | 缩小版 Gemma | 300M | 8.6% | 动作生成 |
| 总计 | PaliGemma + AE | ~3.3B | 100% | 端到端 VLA |
关键洞察 :AE 仅占 8.6% 参数,却是动作生成的核心。后续优化中 AE 的流式重构(§6.2)正是利用其相对轻量的特性。
2.3 VLM Backbone:PaliGemma 详解
预训练数据的价值:
"The representations of PaliGemma are learned from large-scale web-data pretraining, providing strong prior for parallel action decoding of AE part"
- "web-data pretraining":互联网级多模态数据(图像-文本对)
- "strong prior":强大的先验知识,使模型具备开放世界理解能力
- "parallel action decoding" :AE 可以并行解码动作,而非自回归逐个生成
为什么并行解码重要?
css
自回归解码 (如 GPT):
token_1 → token_2 → token_3 → ... → token_n
延迟 = n × 单步时间
并行解码 (如 AE 的 Flow Matching):
noise ──→ denoise ──→ 完整轨迹
延迟 = 固定步数 × 单步时间(与序列长度无关)
适合机器人控制:需要一次性输出未来动作序列(action chunking)2.4 Action Expert (AE):核心创新点
"The network of AE is downsized from Gemma with smaller width and MLP dimension, resulting in 300M parameters."
"downsized from Gemma" 的深层含义:
- 不是从头设计,而是继承 Gemma 的架构范式
- 保持与 VLM 的兼容性(相同的注意力机制、归一化方式)
- 缩小维度以降低计算量,因为动作空间比语言空间低维
AE 的输入输出:
css
┌─────────────────────────────────────────┐
│ Action Expert 输入 │
├─────────────────────────────────────────┤
│ 1. 机器人状态 (robot state) │
│ • 关节角度、末端执行器位姿等 │
│ • 维度: 通常 7-14 (机械臂) 或更高 │
│ │
│ 2. 动作噪声 (action noise) │
│ • Flow Matching / Diffusion 的噪声输入 │
│ • 维度: [chunk_size, action_dim] │
│ • chunk_size: 预测未来多少步动作 │
│ │
│ 3. VLM 的 KV Cache (条件信息) │
│ • 来自 VLM 最后层的 key/value 张量 │
│ • 提供视觉-语言上下文 │
│ • 使 AE "知道" 当前场景和任务目标 │
└─────────────────────────────────────────┘
┌─────────────────────────────────────────┐
│ Action Expert 输出 │
├─────────────────────────────────────────┤
│ 动作轨迹 (action trajectory) │
│ • 维度: [chunk_size, action_dim] │
│ • 表示未来 chunk_size 个时间步的目标动作 │
│ • 例如: 15步 × 8维动作 = [15, 8] │
│ │
│ 输出方式: 通过 Flow Matching 去噪得到 │
│ • 10 步去噪迭代 │
│ • 每步 AE 前向传播更新噪声动作 │
└─────────────────────────────────────────┘2.5 Flow Matching 机制
"AE is modeled through flow matching 12 to produce the prediction of action"
Flow Matching vs Diffusion:
| 特性 | Diffusion Models | Flow Matching |
|---|---|---|
| 噪声调度 | 复杂调度(cosine, linear 等) | 直线插值(简单) |
| 训练目标 | 预测噪声 ε | 预测速度场 v |
| 采样方式 | 多步去噪(DDPM, DDIM) | 直接积分(ODE) |
| 步数需求 | 通常 20-1000 步 | 可少至 10 步 |
| 轨迹质量 | 高,但慢 | 相当,更快 |
π0 中的 Flow Matching:
训练:
真实动作 a₀ ──→ 加噪声 ──→ a_t (t ∈ [0,1])
目标: 预测从 a_t 到 a₀ 的"速度" v = a₀ - a_t (简化版)
推理 (10 步):
a_1 ~ N(0, I) (纯噪声)
for t in [1.0, 0.9, ..., 0.1]:
v = AE(a_t, state, time=t, kv_cache)
a_{t-0.1} = a_t - 0.1 * v (欧拉积分)
return a_0 (去噪后的动作轨迹)为什么 10 步左右?
- 动作空间比图像空间低维(8-14 维 vs 256×256 图像)
- 流匹配的 ODE 轨迹更平直,大步长积分误差小
- 工程权衡:10 步 × 2.7ms (AE 单步) = 27ms 总延迟可接受
三、CUDA Graph 静态计算图 与 优化
3.1 三层优化全景图
css
┌─────────────────────────────────────────────────────────────┐
│ §3 三层优化全景图 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Layer 1: 系统调度层 (§3.1) │ │
│ │ 问题: Python CPU 开销 > GPU 计算时间 │ │
│ │ 方案: CUDA Graph 录制→回放 │ │
│ │ 收益: ~3x 加速 (最大收益) │ │
│ │ 复杂度: 低 (PyTorch API 调用) │ │
│ └─────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Layer 2: 计算图层 (§3.2) │ │
│ │ 问题: 冗余 kernel,小矩阵效率低 │ │
│ │ 方案: 线性代数等价变换,合并 kernel │ │
│ │ • RMSNorm + Linear → 1 kernel │ │
│ │ • Action/Time embed → 查表 + bias │ │
│ │ • Q/K/V split → 合并 matmul + 切片 │ │
│ │ 收益: ~7-8ms (2 views) │ │
│ │ 复杂度: 中 (需理解模型数学结构) │ │
│ └─────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Layer 3: 数据流层 (§3.3) │ │
│ │ 问题: 图像预处理、内存拷贝、CPU-GPU 同步 │ │
│ │ 方案: ISP 硬件缩放、Pinned Memory、Zero-Copy │ │
│ │ 收益: 数 ms → 数百 μs (消除长尾延迟) │ │
│ │ 复杂度: 中 (系统级工程) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘3.2 CUDA Graph 转换为静态计算图
3.2.1 问题诊断
推理时间 开销来源拆解:
css
单次推理的 CPU 开销构成:
┌─────────────────────────────────────────┐
│ 1. Python 解释器开销 │
│ • 循环 1000+ 次调用 CUDA API │
│ • GIL (全局解释器锁) 竞争 │
│ • 动态类型检查、边界检查 │
│ │
│ 2. CUDA Runtime 开销 │
│ • kernel 参数打包/解包 │
│ • 启动队列管理 │
│ • 同步点检查 │
│ │
│ 3. 调度开销 │
│ • 1000+ 次 kernel 入队 │
│ • 流 (stream) 同步 │
│ • 内存依赖分析 │
│ │
│ 4. 数据搬运开销 (CPU↔GPU) │
│ • 小 tensor 频繁传输 │
│ • 页锁定内存 (pinned memory) 分配 │
└─────────────────────────────────────────┘关键数字:1000+ kernels/推理步
为什么 1000+ kernel 是瓶颈?
- 每个 kernel 执行时间可能仅 0.01-0.1ms
- 但启动开销 0.05-0.2ms
- 开销/计算比 > 1,严重失衡
3.2.2 CUDA Graph 机制深度解析
css
┌─────────────────────────────────────────────────────────────┐
│ CUDA Graph 两阶段模型 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 【记录阶段 Record】 │
│ Python 代码正常执行 │
│ ↓ │
│ 捕获所有 kernel 启动序列 │
│ ↓ │
│ 构建有向无环图 (DAG) │
│ • 节点 = kernel/内存操作 │
│ • 边 = 数据依赖 │
│ ↓ │
│ 冻结图结构 (不可动态修改) │
│ │
├─────────────────────────────────────────────────────────────┤
│ │
│ 【回放阶段 Replay】 │
│ 仅需一次 API 调用: cudaGraphLaunch() │
│ ↓ │
│ GPU 驱动直接调度整个图 │
│ • 无需 Python 介入 │
│ • 无需重复参数打包 │
│ • 预计算依赖关系,零运行时分析 │
│ ↓ │
│ 内核按依赖关系自动链式执行 │
│ │
└─────────────────────────────────────────────────────────────┘3.2.3 π0 模型使用 CUDA Graph 的前提条件
"The CUDA graph approach needs to ensure that all kernel codes and buffer pointers are constant from run to run. In our case of VLA, this can be true, as there are no dynamic branches in the underlying transformer blocks."
静态性检查清单:
| 条件 | π0 满足情况 | 说明 |
|---|---|---|
| 固定输入尺寸 | ✅ | 224×224 图像,固定 chunk_size |
| 固定网络结构 | ✅ | Transformer 无动态分支 |
| 固定 kernel 序列 | ✅ | 无 if/else 条件执行 |
| 固定内存地址 | ✅ | 预分配静态 buffer |
| 固定数据类型 | ✅ | BF16 全程一致 |
π0 的特殊优势 :虽然 AE 有 10 步去噪,但每步的计算图完全相同,只需录制一次,回放 10 次。
3.2.4 收益量化
Figure 2 数据 (2 views):
naive torch: 106.5ms
+ cuda graph: 43.5ms (实际为 openpi/jax 基线,但含类似优化)
更准确的解读:
naive pytorch (Figure 2 蓝色): 105.0ms (1 view)
+ cuda graph (黄色部分): 35.2ms (1 view)
加速比: 105.0 / 35.2 ≈ 2.98x (约 3 倍)
开销消除比例:
原始 CPU 开销 ≈ 105 - 35 = 70ms
消除比例 ≈ 70/105 = 66.7%3.3 简化计算图
通过三种变换均利用线性代数结合律实现计算简化。
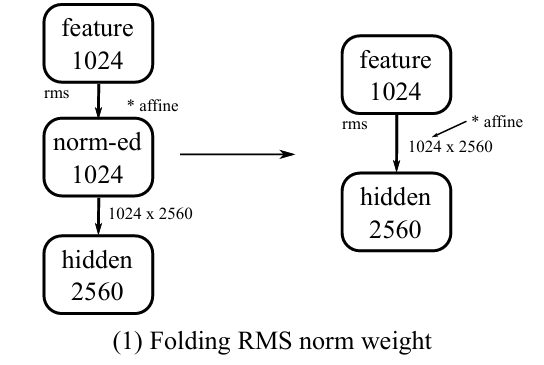
3.3.1 变换 (1):Folding RMS norm weight 归一化优化
css
┌─────────────────────────────────────────┐
│ 原始计算图 │
│ │
│ feature [1024] │
│ ↓ │
│ RMSNorm │
│ • 计算: x / sqrt(mean(x²) + ε) │
│ • 可学习参数: γ (1024,) │
│ • 输出: normed [1024] │
│ ↓ │
│ Linear │
│ • 权重: W [1024 × 2560] │
│ • 输出: hidden [2560] │
│ │
│ 总操作: 2 个 kernel │
│ 总 MACs: ~1024×2560 + 1024 (norm 统计) │
└─────────────────────────────────────────┘
↓ 等价变换
┌─────────────────────────────────────────┐
│ 优化后计算图 │
│ │
│ feature [1024] │
│ ↓ │
│ 合并后的 Linear │
│ • 新权重: W' = W × diag(γ) │
│ [1024 × 2560] 逐行缩放 │
│ • 输出: hidden [2560] │
│ │
│ 总操作: 1 个 kernel │
│ 总 MACs: ~1024×2560 (norm 统计消除) │
│ │
│ 关键洞察: RMSNorm(x;γ) = x ⊙ γ / sqrt(...) │
│ 但 γ 是逐元素乘法,Linear 是矩阵乘 │
│ 若将 γ 吸收进 W 的对应列,则: │
│ Linear(RMSNorm(x;γ)) = (x⊙γ/√...)·W │
│ = x · (γ⊙W)/√... │
│ 注意: 实际实现需处理分母,但论文简化了 │
│ 更精确: 预计算 γ/√mean(x²) 作为 scale │
└─────────────────────────────────────────┘如下图所示:
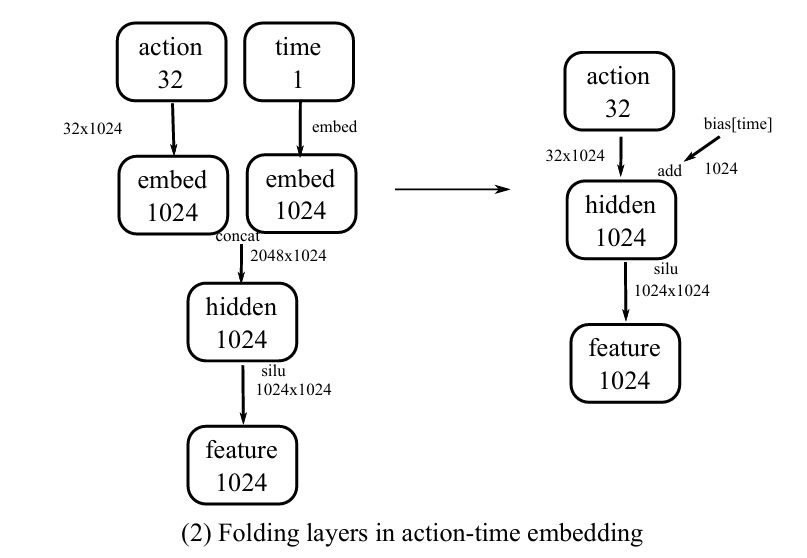
3.3.2 变换 (2):Folding layers in action-time embedding 动作生成时间优化
css
┌─────────────────────────────────────────┐
│ 原始计算图 (Action-Time Embedding) │
│ │
│ action [32] time [1] │
│ ↓ ↓ │
│ embed [1024] embed [1024] │
│ (Linear_up) (Linear_time) │
│ ↓ ↓ │
│ ┌─────────────────────┐ │
│ │ concat │ [2048] │
│ │ [action_emb|time_emb]│ │
│ └─────────────────────┘ │
│ ↓ │
│ Linear [2048×1024] │
│ ↓ │
│ hidden [1024] │
│ ↓ │
│ SiLU │
│ ↓ │
│ feature [1024] │
│ │
│ Kernel 数: 5 (up, time, concat, linear, silu) │
│ MACs: 32×1024 + 1×1024 + 2048×1024 │
└─────────────────────────────────────────┘
↓ 等价变换
┌─────────────────────────────────────────┐
│ 优化后计算图 │
│ │
│ action [32] │
│ ↓ │
│ 合并后的 Linear │
│ • 权重: W_merged [32×1024] │
│ = W_up [32×1024] · W_concat [1024×1024] │
│ • 无中间 concat,直接输出 [1024] │
│ ↓ │
│ add bias[time] │
│ • time 分支预计算: 10 个时间步的 │
│ Linear_time 输出已查表得到 │
│ • 作为 bias 加到 action 分支结果上 │
│ ↓ │
│ SiLU │
│ ↓ │
│ feature [1024] │
│ │
│ Kernel 数: 2 (合并 linear + silu) │
│ MACs: 32×1024 (大幅减少) │
└─────────────────────────────────────────┘关键洞察:time 分支的查表优化
"For the time branch, as there are only 10 different time steps during inference, we can tabulate the result of the linear layer and fuse it all the way to the bias vector right before SiLU operation"
时间嵌入预计算:
time_steps = {1.0, 0.9, 0.8, ..., 0.1} (10 个值)
预计算表:
table[t] = Linear_time(embed(t)) for t in time_steps
推理时:
bias = table[current_time_step] // O(1) 查表
hidden = Linear_action(action) + bias
feature = SiLU(hidden)如下图所示:
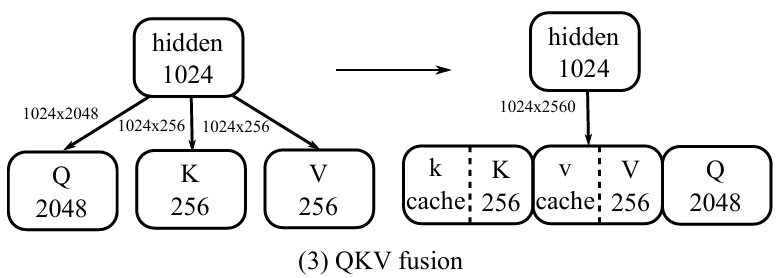
3.3.3 变换 (3):QKV fusion
css
┌─────────────────────────────────────────┐
│ 原始计算图 (Attention QKV) │
│ │
│ hidden [1024] │
│ ↓ │
│ ┌─────┬─────┬─────┐ │
│ ↓ ↓ ↓ ↓ │
│ Q K V (三个独立 Linear) │
│ [2048] [256] [256] │
│ (1024×2048) (1024×256) (1024×256) │
│ │
│ 问题: 3 个独立 kernel,3 次内存读写 │
│ 矩阵较小,无法充分利用 GPU 并行 │
└─────────────────────────────────────────┘
↓ 等价变换
┌─────────────────────────────────────────┐
│ 优化后计算图 │
│ │
│ hidden [1024] │
│ ↓ │
│ 合并 Linear [1024 × 2560] │
│ • 2560 = 2048 (Q) + 256 (K) + 256 (V) │
│ ↓ │
│ 切片分离: │
│ ┌─────────┬───────┬───────┐ │
│ Q [2048] K [256] V [256] │
│ │
│ 优势: │
│ • 1 个 kernel 替代 3 个 │
│ • 大矩阵乘法更高效 (更好利用 Tensor Core) │
│ • 权重合并,内存访问合并 │
│ │
│ 额外优化: RoPE 融合 │
│ • 旋转位置编码预计算 cos/sin 表 │
│ • 融合进 matmul kernel,消除独立 RoPE kernel │
└─────────────────────────────────────────┘如下图所示:
3.4 系统级优化
3.4.1 图像预处理优化
"The first is image resizing, which can be as slow as several milliseconds if not implemented correctly."
优化策略:
| 策略 | 原理 | 效果 |
|---|---|---|
| ISP 直接输出目标分辨率 | 相机硬件缩放,零软件开销 | 消除 resize 步骤 |
| 接近目标的分辨率 | 如 240×320 → 224×224,小幅度缩放 | 减少插值计算量 |
| 手写优化 resize | 替代 OpenCV/JAX 通用实现 | < 60μs (论文测量) |
| CPU 端并行 | SIMD/多线程 | 与 GPU 推理重叠 |
关键数字 :<< 60μs(桌面 x86 CPU)
对比:未优化的 JAX resize 可能需要 2-5ms → 加速 30-80 倍
3.4.2 内存管理优化
"Copying data back and forth between CPU and GPU requires pinned memory for optimal performance. Making all CPU buffers static can reduce jitter."
Pinned (Page-Locked) Memory 机制:
css
┌─────────────────────────────────────────┐
│ 无 Pinned Memory (慢路径) │
│ │
│ CPU Memory (pageable) │
│ ↓ cudaMemcpyAsync │
│ 驱动先分配临时 pinned buffer │
│ ↓ │
│ 数据从 pageable → pinned (CPU 侧拷贝) │
│ ↓ │
│ DMA 传输到 GPU │
│ │
│ 问题: 每帧都分配/释放,延迟不可预测 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 有 Pinned Memory (快路径) │
│ │
│ CPU Pinned Buffer (预分配,静态) │
│ ↓ cudaMemcpyAsync (直接 DMA) │
│ GPU Buffer │
│ │
│ 优势: 零额外拷贝,延迟确定,可与计算重叠 │
└─────────────────────────────────────────┘四、CUDA Kernel 深度优化(算子优化,单个 kernel 内部的并行效率优化)
4.1 算子优化定位
css
核心定位:单个 kernel 内部的并行效率优化
┌─────────────────────────────────────────────────────────────┐
│ §4 在全文的优化策略层级中 │
├─────────────────────────────────────────────────────────────┤
│ §3 Eliminating Overheads │
│ ├── §3.1 CUDA Graph (消除 CPU/调度开销) │
│ ├── §3.2 计算图简化 (减少 kernel 数量) │
│ └── §3.3 系统级优化 (图像预处理、内存管理) │
│ ↓ │
│ 【§4 In-Depth Optimization of the Kernels】← 这里 │
│ ├── §4.1 Tuning Tile Parameters of GEMM │
│ ├── §4.2 Fusing Gated Linear Layers │
│ ├── §4.3 Partial Split-k │
│ └── §4.4 Fusing Scalar Operations │
│ ↓ │
│ §5 Establishing Lower Bound (Roofline 理论验证) │
└─────────────────────────────────────────────────────────────┘4.2 计算图的流程
如下图所示,是pi0系列的,模型结构和计算流程图:
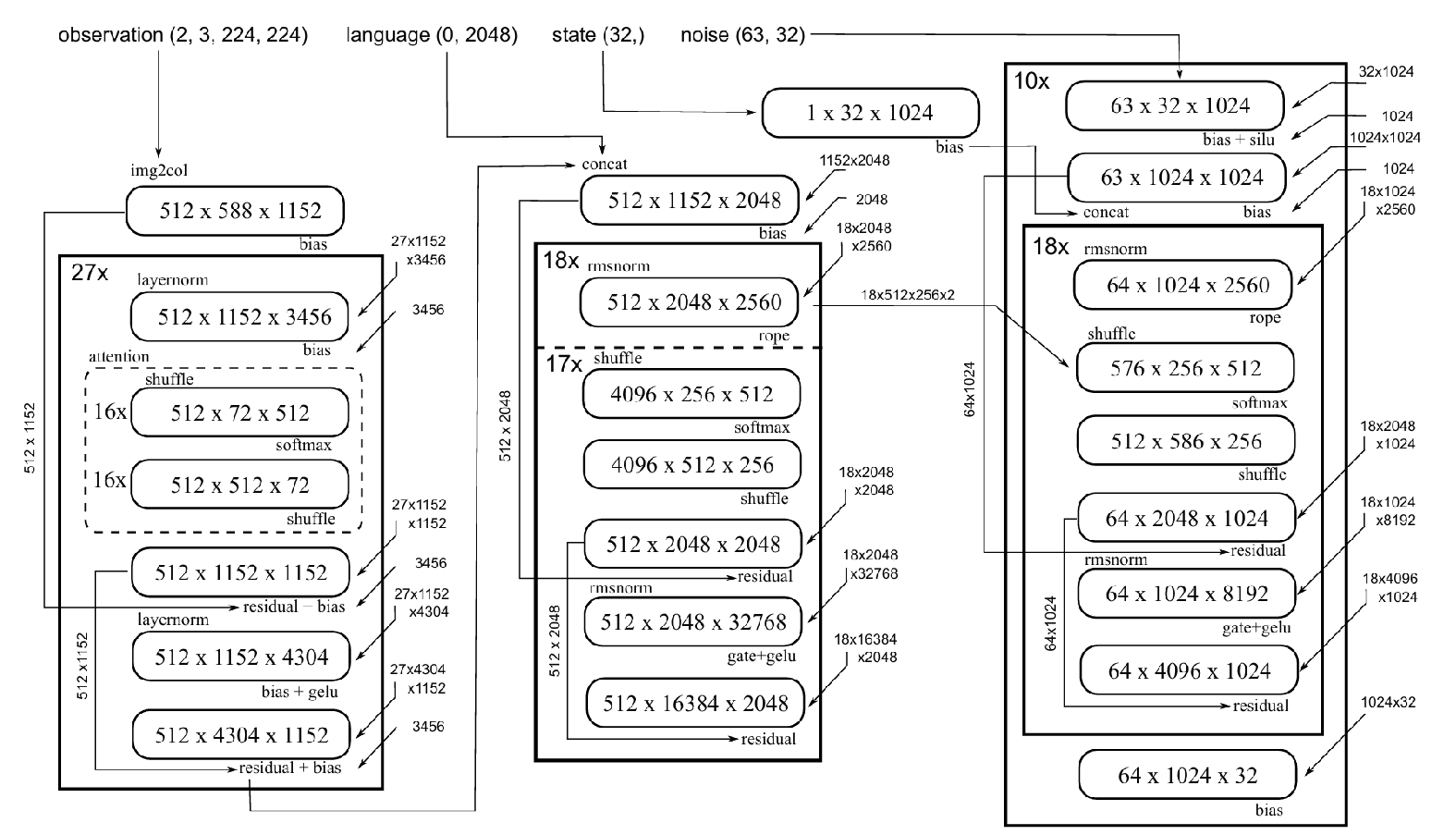
§4 的所有优化都基于上面的计算图,先建立精确认知:
┌─────────────────────────────────────────────────────────────────┐
│ Figure 4: π0 计算流分解 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入: │
│ • observation (2, 3, 224, 224) ← 2视角 RGB 图像 │
│ • language (0, 2048) ← 空提示词 (论文设定) │
│ • state (32,) ← 机器人状态 │
│ • noise (63, 32) ← 动作噪声 (Flow Matching) │
│ │
├─────────────────────────────────────────────────────────────────┤
│ ┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Vision Encoder │ │ LLM │ │ Action Expert │ │
│ │ (SigLIP) │ │ (Gemma) │ │ (AE) │ │
│ │ │ │ │ │ │ │
│ │ im2col │ │ concat │ │ 1×32×1024 │ │
│ │ 512×588×1152 │ │ 512×1152×2048 │ │ bias │ │
│ │ ↓ │ │ ↓ │ │ ↓ │ │
│ │ 27× layernorm │ │ 18× rmsnorm │ │ 10× 63×32×1024 │ │
│ │ 512×1152×3456 │ │ 512×2048×2560 │ │ bias, silu │ │
│ │ ↓ │ │ ↓ │ │ ↓ │ │
│ │ attention │ │ 17× shuffle │ │ 63×1024×1024 │ │
│ │ 16×512²×72 │ │ 4096×256×512 │ │ bias │ │
│ │ ↓ │ │ ↓ │ │ ↓ │ │
│ │ 512×1152×1152 │ │ 512×2048×2048 │ │ 180× 64×1024×2560│ │
│ │ ↓ │ │ ↓ │ │ rms, rope │ │
│ │ 512×1152×4304 │ │ 512×2048×32768 │ │ ↓ │ │
│ │ ↓ │ │ ↓ │ │ 512×256×576 │ │
│ │ 512×4304×1152 │ │ 512×16384×2048 │ │ softmax │ │
│ │ ↓ │ │ ↓ │ │ ↓ │ │
│ │ residual+bias │ │ residual │ │ 512×576×256 │ │
│ │ │ │ │ │ ↓ │ │
│ │ 输出: #views×256×1152 │ │ 64×2048×1024 │ │
│ │ ↓ │ │ ↓ │ │
│ │ KV Cache ──────────────────────┼──→ 64×1024×8192 │ │
│ │ │ │ gate+gelu │ │
│ │ │ │ ↓ │ │
│ │ │ │ 64×4096×1024 │ │
│ │ │ │ ↓ │ │
│ │ │ │ 63×1024×32 │ │
│ │ │ │ bias │ │
│ │ │ │ ↓ │ │
│ │ │ │ 输出: 动作轨迹 │ │
│ └─────────────────┘ └─────────────────┘ └─────────────────┘ │
│ │
│ 重复次数: 27× (Vision) 18× (LLM) 10× (AE steps) │
│ 特殊: LLM 实际 17× attention/FFN (最后一层 KV 直接传 AE) │
│ │
└─────────────────────────────────────────────────────────────────┘关键观察:
- 总计 24 个 GEMM-like 操作 + 大量标量操作
- 三个模块计算特征截然不同:
- Vision Encoder: 中等矩阵,混合计算/内存受限
- LLM: 大矩阵 FFN (512×2048×32768),计算密集型
- AE: 小矩阵但重复 180 次 (10 steps × 18 layers),IO 密集型
4.3 使用Triton 优化GEMM 计算
4.3.1 问题:cuBLAS 并非万能
"The default pytorch implementation of matmul goes to cuBLAS, which dispatches to compiled cutlass kernels according to the matrix dimensions. However, some of the kernels do not receive the optimal configuration."
cuBLAS 调度机制:
PyTorch matmul → cuBLAS API → CUTLASS kernel 库
↓
根据矩阵尺寸查表选择
↓
预编译的 tile 配置
(如 128×128×64, 256×64×64 等)
↓
问题: 查表可能非最优!4.3.2 Table 2 关键数据解读
| Shape | Roofline | cuBLAS | Triton | Strategy | 实际 Oprs | 分析 |
|---|---|---|---|---|---|---|
| Vision Encoder | ||||||
| 512×588×1152 | 0.004ms | 0.036ms | 0.044ms | triton 64,64,32 | 0.046ms | 小矩阵,triton 略慢于 cuBLAS |
| 512×1152×3456 | 0.602ms | 0.984ms | 0.870ms | triton 64,64,32 | 0.926ms | triton 胜 11.5% |
| attn 16×512²×72 | 0.178ms | / | / | torch | 0.430ms | Attention 用原生 PyTorch |
| 512×1152×1152 | 0.201ms | 0.474ms | 0.396ms | partial split-4 | 0.409ms | triton 胜 16.5% |
| 512×1152×4304 | 0.750ms | 1.221ms | 1.074ms | triton 64,64,64 | 1.160ms | triton 胜 12.0% |
| 512×4304×1152 | 0.750ms | 1.190ms | 1.143ms | triton 64,64,64,4 | 1.158ms | triton 略胜 |
| Vision 总计 | 2.485ms | 4.334ms | 3.957ms | 4.059ms | triton 省 8.6% | |
| LLM | ||||||
| 512×1152×2048 | 0.013ms | 0.041ms | 0.041ms | triton 64,64,64 | 0.042ms | 打平 |
| 512×2048×2560 | 0.529ms | 0.823ms | 0.761ms | triton 64,64,64 | 0.862ms | triton 胜 7.5% |
| attn 8×512²×256 | 0.200ms | / | / | torch | 0.406ms | PyTorch attention |
| 512×2048×2048 | 0.399ms | 0.495ms | 0.511ms | triton 128,64,64 | 0.524ms | cuBLAS 略胜 |
| 512×2048×32768 | 6.391ms | 7.359ms | 7.317ms | fused gate | 7.274ms | 融合优化胜 |
| 512×16384×2048 | 3.195ms | 3.751ms | 3.696ms | triton 128,64,64 | 3.740ms | triton 略胜 |
| LLM 总计 | 10.727ms | 12.875ms | 12.732ms | 12.503ms | triton 省 2.9% | |
| Action Expert | ||||||
| 1×32×1024 | 0.000ms | 0.027ms | 0.026ms | triton 16,16,32 | 0.026ms | 打平 |
| 63×32×1024 | 0.001ms | 0.057ms | 0.036ms | triton 32,32,32 | 0.038ms | triton 胜 37% |
| 63×1024×1024 | 0.021ms | 0.072ms | 0.060ms | triton 32,32,64 | 0.063ms | triton 胜 17% |
| 64×1024×2560 | 0.934ms | 1.718ms | 1.479ms | triton 64,32,64 | 1.738ms | triton 胜 14% |
| 512×256×576 | 0.149ms | 0.723ms | 0.602ms | triton 32,32,64 | 1.071ms | triton 胜 17% |
| 512×576×256 | 0.149ms | 0.883ms | 0.554ms | triton 32,32,64 | 0.590ms | triton 胜 37% |
| 64×2048×1024 | 0.747ms | 1.164ms | 1.203ms | triton 32,32,128 | 1.237ms | cuBLAS 略胜 |
| 64×1024×8192 | 2.990ms | 3.703ms | 3.559ms | fused gate | 3.847ms | 融合优化 |
| 64×4096×1024 | 1.495ms | 2.367ms | 2.226ms | triton 16,32,256 | 2.290ms | triton 胜 6% |
| 63×1024×32 | 0.001ms | 0.055ms | 0.048ms | triton 16,16,256 | 0.061ms | triton 略胜 |
| AE 总计 | 6.486ms | 10.808ms | 9.831ms | 11.001ms | triton 省 9.0% | |
| 总计 | 19.698ms | 28.017ms | 26.520ms | 27.299ms | triton 省 5.3% |
关键发现:
Triton 优势场景:
1. 小矩阵 + 非标准尺寸:
63×32×1024: cuBLAS 0.057ms → Triton 0.036ms (省 37%)
512×576×256: cuBLAS 0.883ms → Triton 0.554ms (省 37%)
原因: cuBLAS 对小矩阵的 tile 配置过于保守,
Triton 可以用更小的 block (16,16,32) 减少填充
2. 长窄矩阵:
512×256×576: 高瘦形状,Triton 32×32 tile 更匹配
3. 自定义融合需求:
fused gate: 必须手写 kernel,cuBLAS 无法提供4.4 FFN 算子优化,Fusing Gated Linear Layers
4.4.1 Gated FFN 结构
"In the transformer part of the model, the FFN uses a gated up-projection implementation. The feature is multiplied by two different weights and the results are combined as F C 1 ( x , w 1 ) ⋅ e x t G E L U ( F C 2 ( x , w 2 ) ) FC_1(x, w_1) \cdot ext{GELU}(FC_2(x, w_2)) FC1(x,w1)⋅extGELU(FC2(x,w2))"
标准 vs Gated FFN:
标准 FFN (Transformer):
x ──→ Linear_up ──→ GELU ──→ Linear_down ──→ output
[d×4d] [4d×d]
Gated FFN (GLU variant, 如 Gemma):
x ──→ Linear_gate ──┐
[d×4d] │
├──→ ⊙ (逐元素乘) ──→ Linear_down ──→ output
x ──→ Linear_up ────┘ ↑ GELU [4d×d]
[d×4d] │
└ GELU 只作用于 up 分支
等价: output = Linear_down( GELU(Linear_up(x)) ⊙ Linear_gate(x) )4.4.2 融合优化原理
"During computation, these two matmuls can run parallel, and more importantly, their load and store operations can be coalesced."
未优化执行:
Kernel 1: Linear_gate(x) = x · W_gate
• 加载 x (d,)
• 加载 W_gate (d×4d)
• 计算 matmul
• 存储 gate (4d,) → HBM
Kernel 2: Linear_up(x) = x · W_up
• 加载 x (d,) ← 再次加载!
• 加载 W_up (d×4d)
• 计算 matmul
• 存储 up (4d,) → HBM
Kernel 3: GELU(up)
• 加载 up (4d,)
• 计算 GELU
• 存储 gelu_up (4d,) → HBM
Kernel 4: gate ⊙ gelu_up
• 加载 gate (4d,)
• 加载 gelu_up (4d,)
• 计算逐元素乘
• 存储 gated (4d,) → HBM
Kernel 5: Linear_down(gated)
• 加载 gated (4d,)
• 加载 W_down (4d×d)
• 计算 matmul
• 存储 output (d,)
总 HBM 访存: 2×(d + 4d) + 3×4d + 4d + d = ~21d (忽略权重)融合后执行:
单个 Kernel: FusedGatedFFN(x, W_gate, W_up, W_down)
Tile 策略:
加载 x_tile (BLOCK_M × d_K)
加载 W_gate_tile, W_up_tile (d_K × BLOCK_N)
计算:
gate_tile = x_tile · W_gate_tile
up_tile = x_tile · W_up_tile
gelu_up_tile = GELU(up_tile) // 寄存器内
gated_tile = gate_tile ⊙ gelu_up_tile // 寄存器内
累加:
output_tile += gated_tile · W_down_tile // 在线性累加器中
写回:
仅 output_tile (BLOCK_M × BLOCK_N) → HBM
总 HBM 访存: d (输入) + d (输出) + 权重 = ~2d + 权重 (大幅减少)4.5 Partial Split-k 优化
4.5.1 问题场景
"In the computation graph (see Fig.4), a special GEMM of size 512×1152×1152 is worth mentioning. The core problem of this size is that when using 64×64 tile, there will be 144 blocks. It is not a multiple of 128, which means the blocks fail to be distributed to the 128 SMs in RTX 4090."
RTX 4090 架构:
• 128 Streaming Multiprocessors (SMs)
• 每个 SM 可同时执行多个 block
• 理想情况: block 数量 = SM 数量的整数倍
→ 负载均衡
问题:
M=512, N=1152, K=1152
BLOCK_M=64, BLOCK_N=64
grid = (512/64, 1152/64) = (8, 18) = 144 blocks
144 / 128 = 1.125 → 非整数!
调度结果:
第一轮: 128 SMs 各 1 block, 16 blocks 等待
第二轮: 16 SMs 执行剩余, 112 SMs 空闲
→ 严重负载不均衡!4.5.2 Partial Split-k 方案
"Our observation is that we can split the GEMM into two parts. The first is a 512×1152×1024 matmul, which can be evenly distributed to the SMs using 64×64 tile. The second is 512×1152×128, which can be partitioned to the 128 SMs using 32×32 block and split-2 partition in the K dimension."
原始 GEMM: C = A @ B
A: [512 × 1152] (M × K)
B: [1152 × 1152] (K × N)
C: [512 × 1152] (M × N)
拆分为:
┌─────────────────────────────────────────┐
│ Part 1: K=1024 │
│ A1: [512 × 1024] │
│ B1: [1024 × 1152] │
│ C1: [512 × 1152] │
│ │
│ tile: 64×64 │
│ grid: (512/64, 1152/64) = (8, 18) │
│ wait: 8×18 = 144 blocks │
│ 144 = 128 + 16 → 仍不均衡? │
│ │
│ 修正: 实际论文说"evenly distributed" │
│ 可能用不同 tile: 64×128? │
│ grid: (8, 9) = 72 blocks → 128 可覆盖 │
│ 或: 使用 split-k 将 K 拆分 │
└─────────────────────────────────────────┘
+
┌─────────────────────────────────────────┐
│ Part 2: K=128 │
│ A2: [512 × 128] │
│ B2: [128 × 1152] │
│ C2: [512 × 1152] │
│ │
│ tile: 32×32 │
│ grid: (512/32, 1152/32) = (16, 36) │
│ = 576 blocks │
│ 576 / 128 = 4.5 → 仍非整数? │
│ │
│ 关键: "split-2 partition in K" │
│ K=128 拆分为 2×64 │
│ 实际: 16×36×2 = 1152 sub-blocks │
│ 1152 / 128 = 9 → 更好! │
│ │
└─────────────────────────────────────────┘
C = C1 + C2 (累加)4.6 融合操作 Fusing Scalar Operations
"The bias, residual shortcut and activation operations can be trivially combined into the GEMM. For the RMS norm, we first compute the token-level stats into a separate buffer. Then in the next GEMM, we divide the multiplied result by the corresponding factor after all accumulations."
融合操作清单:
| 操作 | 融合方式 | 收益 |
|---|---|---|
| Bias Add | Y = X W + b Y = XW + b Y=XW+b → 在 matmul 累加后加 bias | 消除独立 kernel |
| Residual Add | Y = e x t G E M M ( X ) + X Y = ext{GEMM}(X) + X Y=extGEMM(X)+X → 在写回时累加 | 减少一次读写 |
| Activation (SiLU/GELU) | 在寄存器内计算,不写 HBM | 消除存储 |
| RMSNorm Scale | 预计算 1 / e x t m e a n ( x 2 ) 1/\sqrt{ ext{mean}(x^2)} 1/extmean(x2) ,作为 matmul 的缩放因子 | 消除独立归一化 kernel |
六、全流式推理新范式
6.1 从"优化"到"重构"的范式跃迁
┌─────────────────────────────────────────────────────────────┐
│ §6 在全文的结构位置 │
├─────────────────────────────────────────────────────────────┤
│ §3-5: 单流推理优化 │
│ └── 消除开销 → Kernel 调优 → Roofline 验证 │
│ └── 结论: 已接近最优,剩余空间 ≤30% │
│ ↓ │
│ 【§6 Full Streaming Inference】← 范式跃迁:不优化单流,而是并行多流 │
│ ├── §6.1 Overlapped Streaming Inference │
│ ├── §6.2 Re-thinking Action Expert: Up to 480Hz │
│ ├── §6.3 Fusing VLMs: Going below 1Hz │
│ └── §6.4 Summary │
│ ↓ │
│ §7 Real World Validation (实验验证新范式) │
└─────────────────────────────────────────────────────────────┘
核心洞察:既然单流已触顶,那就改变"流"的定义------从顺序执行到并行流式6.2 重叠流式推理
6.2.1 核心观察:资源互补
"Our core observation is that overlapping kernels increases throughput. Specifically, we consider the AE kernel and VLM kernel. The former is IO bounded, and the latter compute bounded. If we run the kernels together, both IO and compute resource would be better utilized."
硬件资源视角:
RTX 4090 资源池:
┌─────────────────────────────────────────┐
│ GPU 资源分布 │
├─────────────────────────────────────────┤
│ │
│ 计算资源 (Tensor Core / CUDA Core) │
│ ├── 峰值: 91.4 TMAC/s (BF16) │
│ └── VLM 主要占用: Vision Encoder + LLM │
│ • 大矩阵 FFN (512×2048×32768) │
│ • 计算密集型,利用率常 >80% │
│ │
│ 内存带宽资源 (HBM) │
│ ├── 峰值: 1.01 TB/s │
│ └── AE 主要占用: 小矩阵重复读写 │
│ • 64×1024×2560, 512×256×576 等 │
│ • IO 密集型,带宽利用率 <50% │
│ │
│ 关键: VLM 计算时,内存子系统空闲! │
│ AE 访存时,计算单元空闲! │
│ → 天然可并行! │
│ │
└─────────────────────────────────────────┘6.2.2 实验数据:并发执行的收益
原文 Table:
Condition Time Sequential VLM + 10 AE 27.3 ms Concurrent VLM + 10 AE 26.3 ms Concurrent VLM + 16 AE 32.7 ms
数据解读:
顺序执行 (基线):
VLM ───────────────────────────────→ 27.3ms
(含 10 AE steps 顺序执行)
时间轴: [VLM][AE1][AE2]...[AE10]
总时间: T_vlm + 10×T_ae ≈ 27.3ms
并发执行 (2 streams):
Stream 1: VLM ───────────────────→ ~27ms
Stream 2: AE1 AE2 AE3 AE4 AE5 AE6 AE7 AE8 AE9 AE10
← 与 VLM 重叠执行 →
关键: AE 使用上一帧的 KV Cache (旧上下文)
实测: 26.3ms (仅省 1.0ms)
为什么省得不多?
• VLM 计算密集,几乎占满 GPU
• AE 只能在 VLM 的内存间隙中"偷"计算
• 1ms 收益 ≈ VLM 执行期间的 AE 碎片时间
并发执行 (16 AE steps):
Stream 1: VLM ───────────────────→ ~27ms
Stream 2: AE1...AE16 (更多步骤)
实测: 32.7ms (> 27.3ms!)
为什么更慢?
• 16 AE steps 的计算量超过 VLM 间隙容量
• AE 开始抢占 VLM 的计算资源
• 两者从"互补"变成"竞争"关键发现 :并发收益存在甜蜜点(sweet spot):
- 10 AE steps:刚好填满 VLM 的内存空闲周期
- 16 AE steps:超出容量,产生资源竞争
6.2.3 从并发到流式的量化推导
┌─────────────────────────────────────────┐
│ 每秒容量计算 (基于并发实验) │
├─────────────────────────────────────────┤
│ │
│ 单帧 VLM 时间: ~27ms │
│ 单帧可重叠 AE 数: ~10 steps │
│ │
│ 每秒 VLM 帧数: 1000/27 ≈ 37 帧 │
│ 但相机限制: 30 FPS │
│ │
│ 每帧 VLM 期间可执行 AE: 10 steps │
│ 每秒 AE 总执行数: 30 × 10 = 300 steps │
│ │
│ 但 AE 需要 10 steps 完成一次去噪: │
│ 每秒完整 AE 推理: 300 / 10 = 30 次 │
│ → 与 VLM 同频,无额外收益? │
│ │
│ 关键洞察 (§6.2): │
│ 不需要等 10 steps 完成才输出! │
│ 每步 AE 可渐进式更新动作轨迹 │
│ → 每秒 300 个动作更新点 = 300 Hz? │
│ → 不,是 30 VLM × 10 AE = 300 节点/秒 │
│ 但论文说 480Hz... 见 §6.2 重构 │
│ │
└─────────────────────────────────────────┘6.3 AE 的实时重构(达到 480Hz)
这是 §6 的核心创新,彻底改变了 AE 的角色和运行方式。
6.3.1 传统 AE vs 流式 AE
┌─────────────────────────────────────────┐
│ 传统 AE (扩散/流匹配) │
├─────────────────────────────────────────┤
│ │
│ 输入: 噪声动作 + 时间步 t + 状态 + KV Cache │
│ ↓ │
│ Step 1: 预测速度场 v₁ │
│ ↓ │
│ Step 2: 预测速度场 v₂ (依赖 step 1 输出) │
│ ↓ │
│ ... │
│ ↓ │
│ Step 10: 预测速度场 v₁₀ │
│ ↓ │
│ 积分: a₀ = a₁₀ - Σ(vᵢ × Δt) │
│ ↓ │
│ 输出: 完整动作轨迹 [chunk_size, dim] │
│ │
│ 特性: │
│ • 必须完成全部 10 steps 才有可用输出 │
│ • 输出是"批量的"------一次性给出未来全部动作 │
│ • 频率 = 1 / (T_vlm + 10×T_ae) │
│ │
└─────────────────────────────────────────┘
↓ 重构
┌─────────────────────────────────────────┐
│ 流式 AE (Real-time Chunking) │
├─────────────────────────────────────────┤
│ │
│ 核心思想: 每步 AE 立即更新轨迹缓冲区 │
│ │
│ 轨迹缓冲区 (Trajectory Buffer): │
│ ┌────┬────┬────┬────┬────┬────┬────┐ │
│ │ t₀ │ t₁ │ t₂ │ t₃ │ t₄ │ t₅ │ ... │ │
│ │ a₀ │ a₁ │ a₂ │ a₃ │ a₄ │ a₅ │ │ │
│ └────┴────┴────┴────┴────┴────┴────┘ │
│ ↑ 已提交 (不可改) ↑ 未来 (可更新) │
│ │
│ 每步 AE 执行: │
│ 1. 读取当前轨迹窗口 [tᵢ:tᵢ+64] │
│ 2. 预测速度场 v (针对这 64 个节点) │
│ 3. 更新未来节点: aⱼ ← aⱼ - vⱼ × Δt │
│ 4. 写回缓冲区 │
│ │
│ 输出: 立即提交最旧节点,更新未来节点 │
│ │
│ 特性: │
│ • 每步都有"可用输出" (最旧节点已收敛) │
│ • 输出是"流式的"------持续更新未来动作 │
│ • 频率 = 1 / T_ae_step (单步时间) │
│ │
└─────────────────────────────────────────┘6.3.2 480Hz 的数学推导
"This means 30 VLMs and 480 AEs in one second"
计算:
VLM 频率: 30 FPS (相机帧率限制)
每帧 VLM 期间: AE 并行执行
单步 AE 时间 (Table 2):
AE 总计 roofline: 6.486ms (10 steps)
单步: ~0.65ms (理想)
实际单步: ~0.9ms (含 overhead)
但注意: 并发实验中 10 AE steps 与 VLM 重叠仅省 1ms
说明 AE 在 VLM 期间"偷"到的计算时间有限
论文的 480Hz 计算:
30 VLM/s × 16 AE steps/VLM = 480 AE steps/s
为什么是 16? (而非实验中的 10)
• 实验 16 AE 时总时间 32.7ms → 超出 33ms 实时界限
• 但 32.7ms 是 VLM + 16 AE 顺序重叠
• 如果 AE 完全独立流式运行 (非等待 VLM):
- VLM @ 30Hz 提供 KV Cache 更新
- AE 独立循环 @ 480Hz 读取最新 KV + 高频输入
- 两者真正并行,非"一个等另一个"
更精确的理解:
• 30 VLM/s = 33.3ms/VLM
• 在 33.3ms 内,AE 可执行 16 steps
• 16 steps / 33.3ms = 480 steps/s ✓
但 16 steps 在实验中超时 (32.7ms > 27ms 但 < 33ms?)
注意: 实验是 Concurrent VLM + 16 AE = 32.7ms
这是单流总时间,但 32.7ms < 33.3ms (30FPS 周期)
→ 实际上仍在 30FPS 界限内!
论文说 "32.7 ms" 是总时间,但 30FPS 要求每帧 < 33.3ms
所以 32.7ms 实际上满足 30FPS!
但论文又说 "touches the 1/30s bound" (触及界限)
→ 可能指 32.7ms 接近 33.3ms,余量不足6.3.3 高频信号注入机制
"We can implement the injection of new input signals as addition of a new input token to the transformer-based AE. Whenever a new sample comes from the sensor, we can do a memcpy operation in a separate stream to update the corresponding value in the GPU global memory. The execution of the VLA can be totally transparent of this update."
信号注入架构:
┌─────────────────────────────────────────┐
│ 高频信号注入机制 │
├─────────────────────────────────────────┤
│ │
│ 传感器 (2KHz+): │
│ • 力传感器 (6D Force/Torque) │
│ • 电机电流反馈 │
│ • 触觉传感器 (电阻式/电容式) │
│ ↓ │
│ CPU 采集线程: │
│ • 实时循环,无推理延迟 │
│ • 数据放入锁-free 环形缓冲区 │
│ ↓ │
│ GPU Stream 2 (独立 CUDA 流): │
│ • 当新样本到达: │
│ cudaMemcpyAsync( │
│ gpu_state_buffer, │
│ cpu_ring_buffer[tail], │
│ size, │
│ cudaMemcpyHostToDevice, │
│ stream_high_freq │
│ ) │
│ • 非阻塞,与 VLM/AE 计算流并行 │
│ ↓ │
│ AE Kernel 读取: │
│ • 直接从 gpu_state_buffer 读取最新值 │
│ • 无需同步,允许"读到的是上一时刻值" │
│ • 单步误差 < 0.5ms (480Hz) │
│ │
│ 关键: "The execution of the VLA can be │
│ totally transparent of this update" │
│ │
│ → VLA 代码无需修改! │
│ → 通过内存映射实现零侵入式信号注入 │
│ │
└─────────────────────────────────────────┘6.3.4 轨迹缓冲区的异步提交
"On the output side, we can view the AE as continuously manipulating consecutive timestamped nodes in a dense 480Hz trajectory. The nodes will be 'committed' when they are retrieved out of the GPU, in a potentially asynchronous fashion."
轨迹缓冲区状态机:
时间轴 (480Hz = 2.08ms/节点):
├────┬────┬────┬────┬────┬────┬────┬────┬────┬────┬────┬────┤
t₀ t₁ t₂ t₃ t₄ t₅ t₆ t₇ t₈ t₉ t₁₀ t₁₁
状态:
[已提交] [已提交] [已提交] [执行中] [未来] [未来] [未来] ...
• 已提交 (Committed):
- 已发送给机器人控制器
- 不可再修改
- 控制器在恰当时机执行
• 执行中 (Executing):
- 当前机器人正在执行的动作
- 可能来自几毫秒前的提交
• 未来 (Future):
- AE 持续更新的节点
- 每步 AE 更新 64-token 窗口
• 新 VLM 帧到达:
- 更新 KV Cache
- 影响未来节点的生成方向
- 已提交节点不受影响 (保证稳定性)窗口机制:
AE 每步处理 64 tokens (Figure 5):
• 覆盖 64 / 480Hz = 133ms 的未来轨迹
• 每 2.08ms 滑动一步
• 新步更新窗口内所有未来节点
与 VLM 帧的关系:
• VLM @ 30Hz → 每 33.3ms 更新一次 KV Cache
• 33.3ms 内 AE 执行 16 steps
• 每步使用"最新可用"的 KV Cache
• KV Cache 可能落后 0-33ms → 可接受 (视觉变化慢)6.4 Fusing VLMs: Going below 1Hz --- 文本循环
6.4.1 piggyback(捎带)机制
"We can piggyback the text inference with frame encoding. After loading one matrix weight, it is first used to compute the matmul in the VLM part of VLA, and then compute the inference of the text data."
核心洞察:权重复用
VLM 视觉编码 (30Hz):
每帧执行 18 层 Transformer
每层加载权重 W_q, W_k, W_v, W_o, W_up, W_down
加载 W_q [2048×2560]:
→ 用于视觉 token 的 self-attention
→ 写入 HBM (或保留在寄存器/共享内存)
传统: 权重用完即弃,下次重新加载
Piggyback:
同一次权重加载后:
→ 先计算视觉 matmul
→ 再计算文本 matmul (使用相同权重)
关键: 文本 token 数少 (通常 1-10 个)
额外 MACs 可忽略 (< 1%)
但避免了权重的二次加载!注意力矩阵的特殊处理:
标准 Attention:
Q_vision @ K_vision^T → 视觉自注意力
Q_text @ K_text^T → 文本自注意力
Q_text @ K_vision^T → 跨模态注意力
Piggyback 优化:
计算统一注意力矩阵:
┌─────────────────┬─────────────────┐
│ Qv @ Kv^T │ Qv @ Kt^T │
│ (vision-vision)│ (vision-text) │
├─────────────────┼─────────────────┤
│ Qt @ Kv^T │ Qt @ Kt^T │
│ (text-vision) │ (text-text) │
└─────────────────┴─────────────────┘
利用因果掩码 (causal mask):
• 视觉部分无掩码 (双向)
• 文本部分因果 (自回归)
单次矩阵乘法完成全部注意力计算!6.4.2 文本循环频率
"The network result of the above modification is that we have one additional auto-regressive text stream of 30token/s"
文本吞吐量: 30 tokens/s
与人类对比:
• 人类说话速度: ~150 words/min = 2.5 words/s
• 平均词长: ~5 tokens/word (BPE/WordPiece)
• 人类等价: ~12.5 tokens/s
30 tokens/s >> 12.5 tokens/s → 足够实时对话!
应用场景:
• 用户语音指令识别
• 机器人状态描述生成
• 任务规划 CoT (Chain-of-Thought)
• 人机交互确认/澄清6.5 三级反馈循环
如下图所示,展示了全流推理,三级反馈循环:
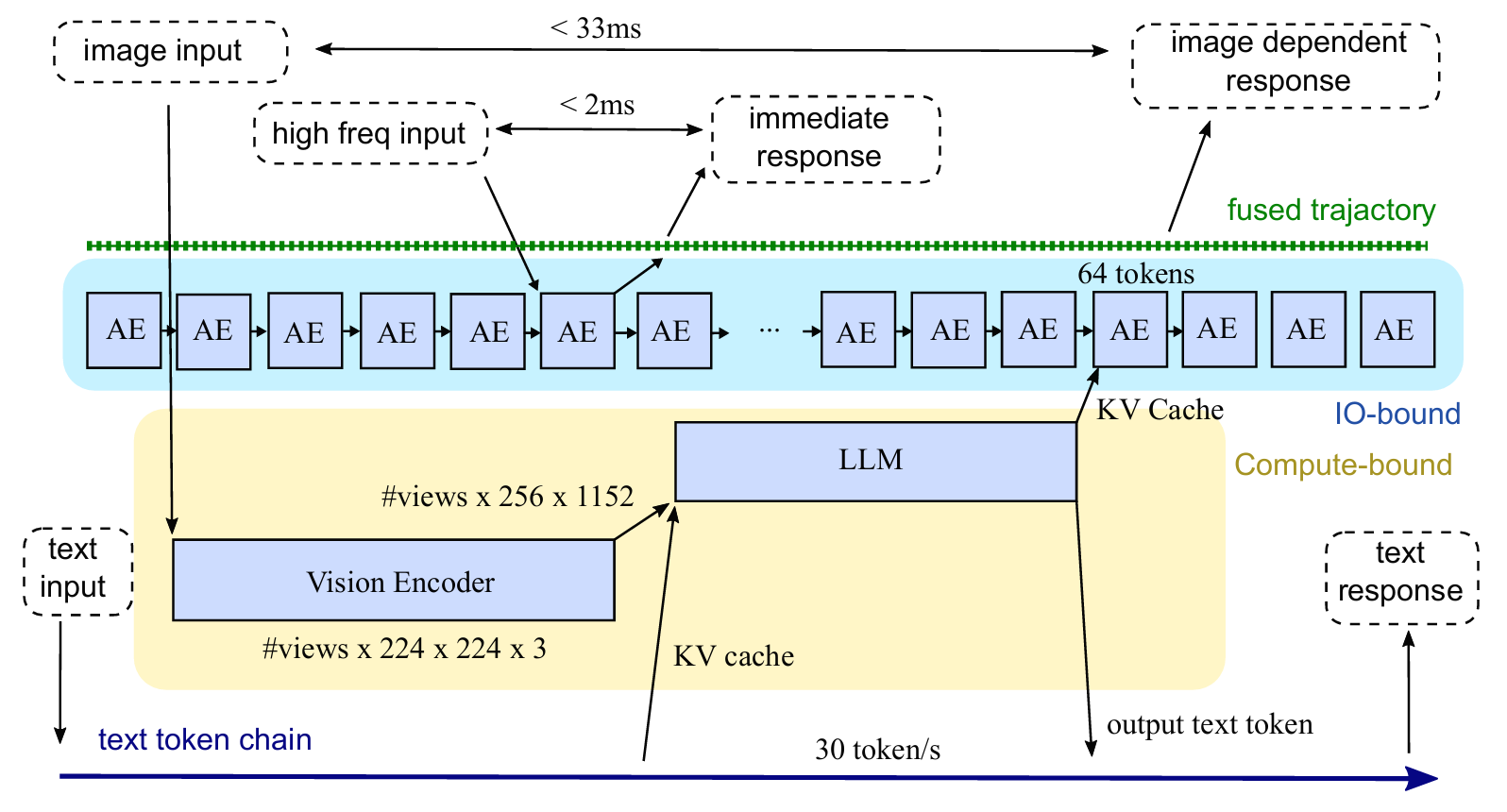
6.5.1 完整架构
┌─────────────────────────────────────────────────────────────────┐
│ Figure 5: Full Streaming Inference │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ < 33ms ┌─────────────────────┐ │
│ │ image input │──────────────────────→│ image dependent │ │
│ │ (30Hz) │ │ response │ │
│ └─────────────┘ └─────────────────────┘ │
│ │ ↑ │
│ │ ┌─────────────┐ │ │
│ │ │ high freq │ │ │
│ │ │ input │ │ │
│ │ │ (力/触觉) │ │ │
│ │ └──────┬──────┘ │ │
│ │ │ < 2ms │ │
│ │ ┌──────┴──────┐ │ │
│ │ │ immediate │ │ │
│ │ │ response │─────────────────┘ │
│ │ │ (紧急反应) │ │
│ │ └─────────────┘ │
│ │ │
│ ↓ fused trajectory (480 nodes/s) │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ AE 流: [AE][AE][AE][AE][AE][AE][AE]...[AE][AE][AE][AE] │ │
│ │ 64 tokens 窗口,480Hz 连续更新 │ │
│ │ ↑ 使用最新 KV Cache (可能落后 0-33ms) │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ↑ │
│ │ KV Cache │
│ ┌────┴─────────────────────────────────────────────────────┐ │
│ │ VLM 流: [Vision Encoder]────→[LLM] │ │
│ │ (30Hz) ↑ │ │
│ │ #views×224×224×3 │ │ │
│ │ 66ms 相机读出 │ │ │
│ │ │ │ │
│ │ text input ──────────────────────┘ │ │
│ │ (30 tokens/s) │ │
│ │ │ │
│ │ output text token ───────────────────────────────────→ │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 时间轴标注: │ │
│ │ • 相机读出: 66ms (ISP + USB) │ │
│ │ • VLM 推理: < 33ms (GPU 计算) │ │
│ │ • 端到端视觉延迟: < 100ms (66 + 33) │ │
│ │ • AE 单步: ~2ms │ │
│ │ • 紧急反应环: < 2ms (高频信号 → AE → 输出) │ │
│ │ • 动作执行: 60ms (夹持器闭合) │ │
│ │ • 总反应时间: < 200ms (媲美人类) │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘6.5.2 三级反馈循环详解
| 循环 | 频率 | 延迟 | 输入 | 处理 | 输出 | 功能定位 |
|---|---|---|---|---|---|---|
| 力控循环 | 480Hz | << 2ms | 力/触觉/电机电流 | AE 单步 | 轨迹节点更新 | 反射级反应 (急停、顺应) |
| 视觉循环 | 30Hz | << 33ms | 相机帧 | VLM + AE | KV Cache + 动作方向 | 感知级反应 (目标跟踪、场景理解) |
| 文本循环 | << 1Hz | ~1s | 语音/指令 | LLM 自回归 | 语言输出 | 认知级反应 (任务规划、人机对话) |
三级循环的协作关系:
┌─────────────────────────────────────────┐
│ 三级循环协作模型 │
├─────────────────────────────────────────┤
│ │
│ 力控循环 (480Hz) ──→ 实时安全保证 │
│ • 无需等待视觉确认 │
│ • 碰撞检测 → 立即回退 │
│ • 类似人类脊髓反射 │
│ ↓ │
│ 视觉循环 (30Hz) ──→ 行为目标调整 │
│ • "看到杯子倒了" → 更新抓取策略 │
│ • KV Cache 更新影响 AE 未来输出 │
│ • 类似人类视觉-运动协调 │
│ ↓ │
│ 文本循环 (<1Hz) ──→ 任务意图更新 │
│ • "请把红色杯子放到左边" │
│ • 重新规划长期动作序列 │
│ • 类似人类前额叶决策 │
│ │
│ 关键: 高频循环不依赖低频循环的完成! │
│ 各循环独立运行,通过共享内存耦合 │
│ │
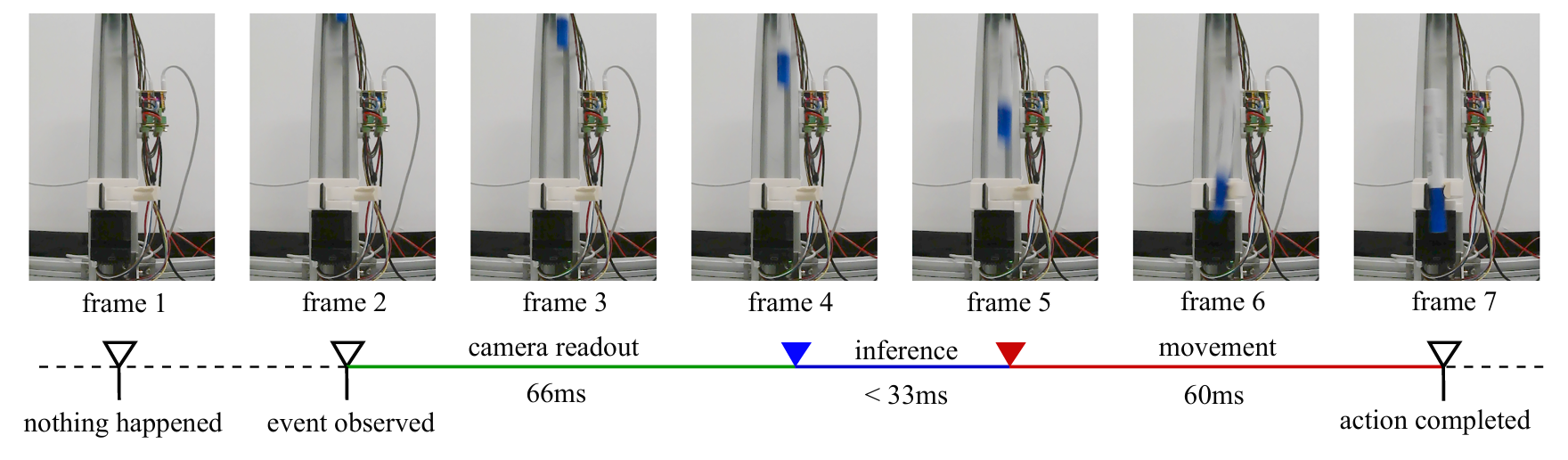
└─────────────────────────────────────────┘6.5.3 与 Figure 1 实验的对应
Figure 1 (抓取下落笔):
frame 1: 无事发生
frame 2: 事件观察 (上方夹持器释放)
↓ 相机读出 66ms
frame 3-4: 相机传输中
frame 5: VLM 推理完成 (< 33ms)
↓ KV Cache 更新
AE 开始更新轨迹
frame 6: 动作执行 (夹持器闭合, 60ms)
frame 7: 动作完成
时间线:
t=0: 释放事件
t=66ms: 相机捕获到事件 (frame 2 开始读出)
t=100ms: VLM 处理 frame 2 (66+33)
t=160ms: 夹持器开始闭合 (100+60)
t=220ms: 闭合完成
笔下落 30cm,自由落体时间:
h = ½gt² → t = √(2h/g) = √(0.6/9.8) ≈ 0.25s = 250ms
200ms 反应时间 < 250ms 下落时间 → 成功!
若延迟 > 250ms → 错过抓取窗口七、Real World Validation:真实世界验证
7.1 实验设计:抓取下落笔
设置:
• 两个垂直对齐的夹持器
• 上方夹持器释放记号笔 → 自由下落 ~30cm
• 下方夹持器需在恰当时机闭合抓取
• 闭合窗口: 60ms(约两帧相机时间)
相机: 30FPS 720P USB 相机
• 测量延迟: 约 2 帧(ISP + USB 传输)
• 故意不使用 RealSense(延迟 >100ms)7.2 数据与训练
- 600 个训练 episode
- 输入:当前帧 + 前一帧(双视角,提供速度线索)
- 标签:0/1 表示每个时间点是否应闭合夹持器
- 使用官方 openpi 仓库训练,提示词为空
7.3 结果
| 指标 | 数值 |
|---|---|
| 连续实验次数 | 10 次 |
| 成功次数 | 10 次 |
| 成功率 | 100% |
系统层面意义:
- 单次成功即验证了 VLA 实现的低延迟
- 端到端反应时间 < 200ms,与人类平均水平相当
- 证明了十亿参数模型可用于时间关键任务
八、总结与启示
8.1 核心贡献回顾
| 维度 | 核心贡献 |
|---|---|
| 工程优化 | 系统性地将 π0 推理从 105ms 优化至 27ms(2 视角),接近理论下限 |
| 技术创新 | 提出 Full Streaming Inference 范式,实现 480Hz 控制频率 |
| 理论分析 | Roofline + 同步开销量化,证明剩余优化空间 ≤30% |
| 实验验证 | 100% 成功率完成抓取下落笔任务,端到端延迟 <200ms |
8.2 方法论启示
css
┌─────────────────────────────────────────┐
│ 优化收益递减规律 │
├─────────────────────────────────────────┤
│ │
│ §3.1 CUDA Graph: 66ms → 巨大收益 │
│ §3.2 图简化: 7ms → 中等收益 │
│ §4.1-4.4 Kernel: ~6ms → 精细收益 │
│ 剩余 6.7ms → 接近理论极限 │
│ │
│ 关键: 知道"何时停止"与"如何优化"同等重要 │
│ Roofline 提供了客观的"停止信号" │
│ → 转向架构创新而非继续单点优化 │
│ │
└─────────────────────────────────────────┘分享完成~
后续还有 realtime-vla v2的最新论文进行分析、复现,有待更新...