AI Agent 记忆系统设计与实现:让 AI 记住一切
前言
记忆系统是 AI Agent 能否长期有效工作的关键。一个没有记忆的 Agent 每次交互都像是与陌生人对话,而有完善记忆系统的 Agent 则可以像老朋友一样理解你的偏好、记住你的请求历史、提供连贯的服务。
我之前设计过一个客服 Agent,最初没有完善的记忆系统,导致每次对话都是独立的,用户需要反复说明背景信息。加入记忆系统后,用户体验有了质的飞跃。今天分享一些记忆系统的设计经验和实现方法。
记忆系统的分层架构
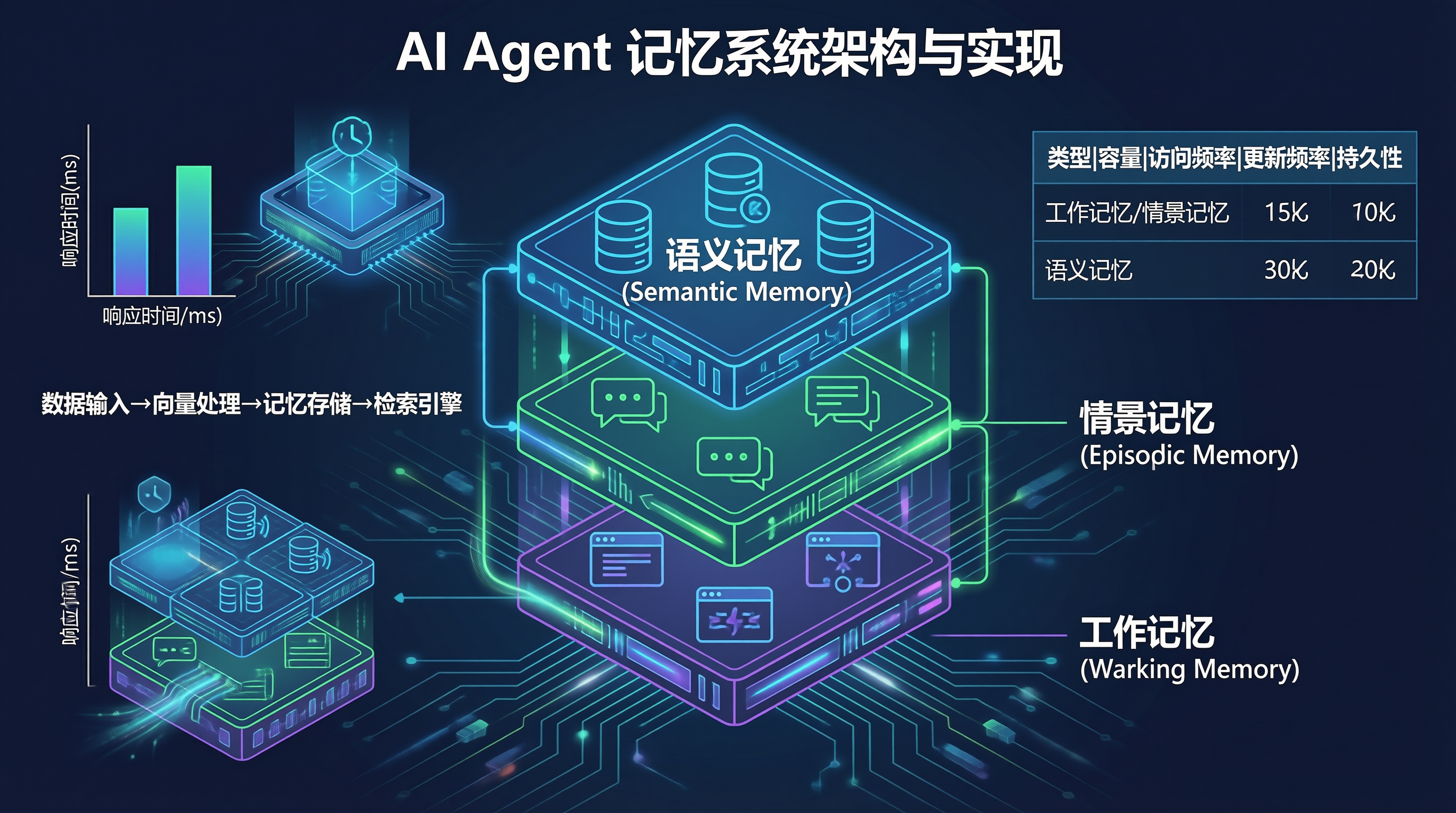
三层记忆模型
┌─────────────────────────────────────────────────────┐
│ Semantic Memory (语义记忆) │
│ 存储长期知识:事实、概念、通用规则 │
│ 特点:持久存储,很少变化 │
├─────────────────────────────────────────────────────┤
│ Episodic Memory (情景记忆) │
│ 存储过去事件:对话摘要、已完成任务 │
│ 特点:定期更新,可遗忘旧内容 │
├─────────────────────────────────────────────────────┤
│ Working Memory (工作记忆) │
│ 当前任务上下文:当前对话、最近状态 │
│ 特点:临时存储,快速访问 │
└─────────────────────────────────────────────────────┘记忆类型对比
| 类型 | 容量 | 访问频率 | 更新频率 | 持久性 |
|---|---|---|---|---|
| 工作记忆 | 几 KB | 每轮 | 每轮 | 会话级 |
| 情景记忆 | 几 MB | 每次新会话 | 每天 | 长期 |
| 语义记忆 | 无限制 | 偶尔 | 很少 | 永久 |
核心组件实现
1. 工作记忆
python
from dataclasses import dataclass, field
from typing import List, Dict, Optional
from datetime import datetime
import json
@dataclass
class Message:
"""消息记录"""
role: str # "user" | "assistant" | "system"
content: str
timestamp: datetime = field(default_factory=datetime.now)
metadata: Dict = field(default_factory=dict)
class WorkingMemory:
"""工作记忆 - 当前会话的上下文"""
def __init__(self, max_messages: int = 50):
self.messages: List[Message] = []
self.max_messages = max_messages
self.session_id: Optional[str] = None
self.metadata: Dict = {}
def add_message(self, role: str, content: str, metadata: Dict = None):
"""添加消息"""
message = Message(
role=role,
content=content,
metadata=metadata or {}
)
self.messages.append(message)
# 清理超出限制的消息
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]
def get_context(self, max_tokens: int = 3000) -> str:
"""获取当前上下文"""
context_parts = []
current_tokens = 0
# 从最近的消息开始
for msg in reversed(self.messages):
msg_text = f"{msg.role}: {msg.content}"
msg_tokens = self._count_tokens(msg_text)
if current_tokens + msg_tokens > max_tokens:
break
context_parts.insert(0, msg_text)
current_tokens += msg_tokens
return "\n\n".join(context_parts)
def get_recent(self, n: int = 5) -> List[Message]:
"""获取最近 n 条消息"""
return self.messages[-n:]
def clear(self):
"""清空工作记忆"""
self.messages = []
def _count_tokens(self, text: str) -> int:
"""简单 token 计数"""
return len(text) // 4 # 粗略估计2. 情景记忆
python
import sqlite3
from typing import List, Optional
from datetime import datetime, timedelta
@dataclass
class Episode:
"""情景记忆条目"""
id: str
session_id: str
summary: str
key_points: List[str]
entities: List[str] # 提到的实体
timestamp: datetime
importance: float # 重要性评分
access_count: int = 0
last_accessed: Optional[datetime] = None
class EpisodicMemory:
"""情景记忆 - 跨会话的记忆"""
def __init__(self, db_path: str = "./episodic_memory.db"):
self.db_path = db_path
self._init_db()
def _init_db(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
conn.execute("""
CREATE TABLE IF NOT EXISTS episodes (
id TEXT PRIMARY KEY,
session_id TEXT,
summary TEXT,
key_points TEXT,
entities TEXT,
timestamp DATETIME,
importance REAL,
access_count INTEGER,
last_accessed DATETIME
)
""")
conn.commit()
conn.close()
def add_episode(
self,
session_id: str,
messages: List[Message],
summary: str = None
):
"""添加情景记忆"""
if summary is None:
summary = self._generate_summary(messages)
key_points = self._extract_key_points(messages)
entities = self._extract_entities(messages)
episode = Episode(
id=f"{session_id}_{datetime.now().timestamp()}",
session_id=session_id,
summary=summary,
key_points=key_points,
entities=entities,
timestamp=datetime.now(),
importance=1.0
)
self._save_episode(episode)
return episode
def _generate_summary(self, messages: List[Message]) -> str:
"""生成摘要"""
# 简化实现,实际可用 LLM
contents = [m.content[:100] for m in messages if len(m.content) > 20]
return " | ".join(contents[:3])
def _extract_key_points(self, messages: List[Message]) -> List[str]:
"""提取关键点"""
# 简化实现
return []
def _extract_entities(self, messages: List[Message]) -> List[str]:
"""提取实体"""
# 简化实现
return []
def search(
self,
query: str,
max_results: int = 5,
recency_days: int = 30
) -> List[Episode]:
"""搜索相关记忆"""
conn = sqlite3.connect(self.db_path)
cursor = conn.execute("""
SELECT * FROM episodes
WHERE timestamp > datetime('now', '-' || ? || ' days')
ORDER BY importance DESC, timestamp DESC
LIMIT ?
""", (recency_days, max_results))
rows = cursor.fetchall()
conn.close()
episodes = []
for row in rows:
episodes.append(Episode(
id=row[0],
session_id=row[1],
summary=row[2],
key_points=json.loads(row[3]),
entities=json.loads(row[4]),
timestamp=datetime.fromisoformat(row[5]),
importance=row[6],
access_count=row[7],
last_accessed=datetime.fromisoformat(row[8]) if row[8] else None
))
return episodes
def _save_episode(self, episode: Episode):
"""保存到数据库"""
conn = sqlite3.connect(self.db_path)
conn.execute("""
INSERT INTO episodes
(id, session_id, summary, key_points, entities,
timestamp, importance, access_count, last_accessed)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
""", (
episode.id,
episode.session_id,
episode.summary,
json.dumps(episode.key_points),
json.dumps(episode.entities),
episode.timestamp.isoformat(),
episode.importance,
episode.access_count,
episode.last_accessed.isoformat() if episode.last_accessed else None
))
conn.commit()
conn.close()3. 语义记忆
python
from typing import Dict, List, Optional
import hashlib
@dataclass
class Knowledge:
"""知识条目"""
id: str
content: str
source: str
confidence: float
tags: List[str]
created_at: datetime
updated_at: datetime
class SemanticMemory:
"""语义记忆 - 长期知识库"""
def __init__(self, vector_store, embedding_model):
self.vector_store = vector_store
self.embedding_model = embedding_model
self.knowledge_graph: Dict[str, dict] = {}
def add_knowledge(
self,
content: str,
source: str,
tags: List[str] = None,
embedding: Optional[List[float]] = None
):
"""添加知识"""
knowledge_id = hashlib.md5(content.encode()).hexdigest()
if embedding is None:
embedding = self.embedding_model.encode([content])[0]
knowledge = Knowledge(
id=knowledge_id,
content=content,
source=source,
confidence=1.0,
tags=tags or [],
created_at=datetime.now(),
updated_at=datetime.now()
)
# 存储到向量数据库
self.vector_store.add(
id=knowledge_id,
vector=embedding,
payload={"content": content, "source": source}
)
# 更新知识图谱
self.knowledge_graph[knowledge_id] = {
"content": content,
"tags": tags,
"related": []
}
return knowledge
def retrieve(self, query: str, top_k: int = 5) -> List[Knowledge]:
"""检索相关知识"""
query_embedding = self.embedding_model.encode([query])[0]
results = self.vector_store.search(
vector=query_embedding,
top_k=top_k
)
return [
Knowledge(
id=r["id"],
content=r["payload"]["content"],
source=r["payload"]["source"],
confidence=r["score"],
tags=r["payload"].get("tags", []),
created_at=datetime.now(),
updated_at=datetime.now()
)
for r in results
]
def update_knowledge(self, knowledge_id: str, content: str):
"""更新知识"""
if knowledge_id in self.knowledge_graph:
self.knowledge_graph[knowledge_id]["content"] = content
self.knowledge_graph[knowledge_id]["updated_at"] = datetime.now()完整记忆系统
python
class UnifiedMemory:
"""统一记忆系统"""
def __init__(
self,
vector_store=None,
embedding_model=None,
llm=None
):
self.working_memory = WorkingMemory()
self.episodic_memory = EpisodicMemory()
self.semantic_memory = SemanticMemory(vector_store, embedding_model)
self.llm = llm
def add_user_message(self, content: str):
"""添加用户消息"""
self.working_memory.add_message("user", content)
def add_assistant_message(self, content: str):
"""添加助手消息"""
self.working_memory.add_message("assistant", content)
def get_full_context(self, include_semantic: bool = True) -> str:
"""获取完整上下文"""
parts = []
# 1. 语义记忆(长期知识)
if include_semantic and self.llm:
semantic_context = self._get_semantic_context()
if semantic_context:
parts.append(f"【背景知识】\n{semantic_context}")
# 2. 情景记忆(历史经验)
episodic_context = self._get_episodic_context()
if episodic_context:
parts.append(f"【相关历史】\n{episodic_context}")
# 3. 工作记忆(当前对话)
working_context = self.working_memory.get_context()
if working_context:
parts.append(f"【当前对话】\n{working_context}")
return "\n\n".join(parts)
def _get_semantic_context(self) -> str:
"""获取语义记忆上下文"""
if not self.llm:
return ""
# 从当前对话提取关键信息
recent = self.working_memory.get_recent(3)
if not recent:
return ""
query = " ".join([m.content for m in recent])
# 检索相关知识
relevant_knowledge = self.semantic_memory.retrieve(query, top_k=3)
if not relevant_knowledge:
return ""
return "\n".join([
f"- {k.content} (来源: {k.source})"
for k in relevant_knowledge
])
def _get_episodic_context(self) -> str:
"""获取情景记忆上下文"""
recent = self.working_memory.get_recent(3)
if not recent:
return ""
# 搜索相关情景
query = " ".join([m.content for m in recent])
episodes = self.episodic_memory.search(query, max_results=2)
if not episodes:
return ""
return "\n".join([
f"- {e.summary}"
for e in episodes
])
def save_session(self, session_id: str):
"""保存当前会话到情景记忆"""
messages = self.working_memory.messages
if not messages:
return
self.episodic_memory.add_episode(session_id, messages)
self.working_memory.clear()
def clear_session(self):
"""清空当前会话"""
self.working_memory.clear()记忆检索优化
基于重要性的衰减
python
class MemoryWithDecay(UnifiedMemory):
"""带重要性衰减的记忆系统"""
def __init__(self, decay_rate: float = 0.95):
super().__init__()
self.decay_rate = decay_rate
def decay_importance(self, days_passed: int) -> float:
"""计算衰减后的重要性"""
return self.decay_rate ** days_passed
def prune_old_memories(self, threshold: float = 0.1):
"""清理不重要的记忆"""
# 删除重要性低于阈值的历史记录
pass主动记忆增强
python
class ProactiveMemory(UnifiedMemory):
"""主动记忆增强"""
def __init__(self, *args, summary_threshold: int = 20, **kwargs):
super().__init__(*args, **kwargs)
self.summary_threshold = summary_threshold
def should_summarize(self) -> bool:
"""判断是否需要总结"""
return len(self.working_memory.messages) >= self.summary_threshold
def proactive_summarize(self, session_id: str):
"""主动生成总结"""
if not self.should_summarize():
return
messages = self.working_memory.messages
# 使用 LLM 生成总结
summary_prompt = f"""请总结以下对话的关键信息:
{chr(10).join([f"{m.role}: {m.content}" for m in messages])}
请提取:
1. 对话主题
2. 关键决策或结论
3. 用户偏好或需求
4. 待处理事项
总结:"""
summary = self.llm.generate(summary_prompt)
# 保存到情景记忆
self.episodic_memory.add_episode(session_id, messages, summary)
# 清空并保留摘要
self.working_memory.clear()
self.working_memory.add_message(
"system",
f"[对话摘要] {summary}"
)实际应用
python
class MemoryfulAgent:
"""带有记忆的 Agent"""
def __init__(self):
# 初始化各组件
self.memory = UnifiedMemory()
self.llm = OpenAILLM()
# 加载长期偏好
self._load_preferences()
def _load_preferences(self):
"""加载用户偏好"""
prefs = self.semantic_memory.retrieve("user preferences", top_k=5)
for p in prefs:
self.memory.working_memory.metadata["preferences"] = json.loads(p.content)
def chat(self, user_input: str) -> str:
"""聊天"""
# 1. 记录用户消息
self.memory.add_user_message(user_input)
# 2. 获取完整上下文
context = self.memory.get_full_context()
# 3. 构建 prompt
prompt = f"""{context}
用户:{user_input}
请基于以上上下文回答用户问题。
"""
# 4. 生成回答
response = self.llm.chat(prompt)
# 5. 记录回答
self.memory.add_assistant_message(response)
return response
def end_session(self, session_id: str):
"""结束会话"""
# 保存情景记忆
self.memory.save_session(session_id)
# 提取并保存用户偏好
self._extract_and_save_preferences()总结
记忆系统是 AI Agent 的重要组成部分:
- 三层记忆:工作记忆、情景记忆、语义记忆各有分工
- 工作记忆:处理当前对话上下文
- 情景记忆:跨会话存储历史经验
- 语义记忆:长期知识和偏好
- 主动优化:定期总结和清理
关键要点:
- 合理的分层设计提高效率
- 定期总结防止上下文溢出
- 重要性衰减保证记忆时效性
- 与 LLM 结合实现智能检索