目录
[2.2.1、基础体验型(运行 1.5B - 7B 小模型)](#2.2.1、基础体验型(运行 1.5B - 7B 小模型))
[2.2.2、进阶推荐型(流畅运行 7B - 13B 主流模型)](#2.2.2、进阶推荐型(流畅运行 7B - 13B 主流模型))
[2.2.3、专业发烧型(运行 32B - 70B+ 超大模型)](#2.2.3、专业发烧型(运行 32B - 70B+ 超大模型))
[3、Ollama 常用命令](#3、Ollama 常用命令)
Ollama 是一个开源、跨平台的本地大模型运行工具。不是模型本身,而是用于轻松部署和运行开源大语言模型(如 Llama 3、Mistral、DeepSeek、Qwen 等)的轻量级框架。Ollama 是运行引擎,实际大模型由社区提供。
支持 Windows、macOS、Linux。
提供本地 RESTful API(默认端口 11434。http://localhost:11434),可集成到 Python、Java、LangChain 等。
所有计算在本机完成,数据不上传云端,适合敏感场景或离线使用。
使用参考:
https://github.com/ollama/ollama
https://github.com/datawhalechina/handy-ollama(https://gitee.com/wxmingit/handy-ollama)
1、安装
安装完成后,电脑右下角任务栏托盘区出现一个小羊驼图标,这代表 Ollama 已经在后台自动启动并运行了。
1.1、修改模型存储位置
Ollama 默认会把下载的 AI 模型存放在 C 盘(通常在 C:\Users\用户名\.ollama\models)。由于大模型动辄占用十几 GB 甚至几十 GB 的空间,很容易把 C 盘塞满。建议在开始下载模型前,先给它换个家:
- 右键点击任务栏托盘区的小羊驼图标 ,选择 Quit Ollama 退出程序。
- 打开 Windows 的"设置",搜索 "环境变量"。
- 在"系统变量或用户变量"区域,点击 "新建" :变量名 填写:
OLLAMA_MODELS。变量值 填写:想要存放模型的新路径(例如F:\OllamaModels)。 - 连续点击"确定"保存。重新从开始菜单或桌面快捷方式启动 Ollama,以后下载的模型就会自动存放到指定的新盘符里了。
验证环境变量设置:在cmd窗口运行,查看结果:
echo %OLLAMA_MODELS%1.2、命令启动Ollama
命令行语句:
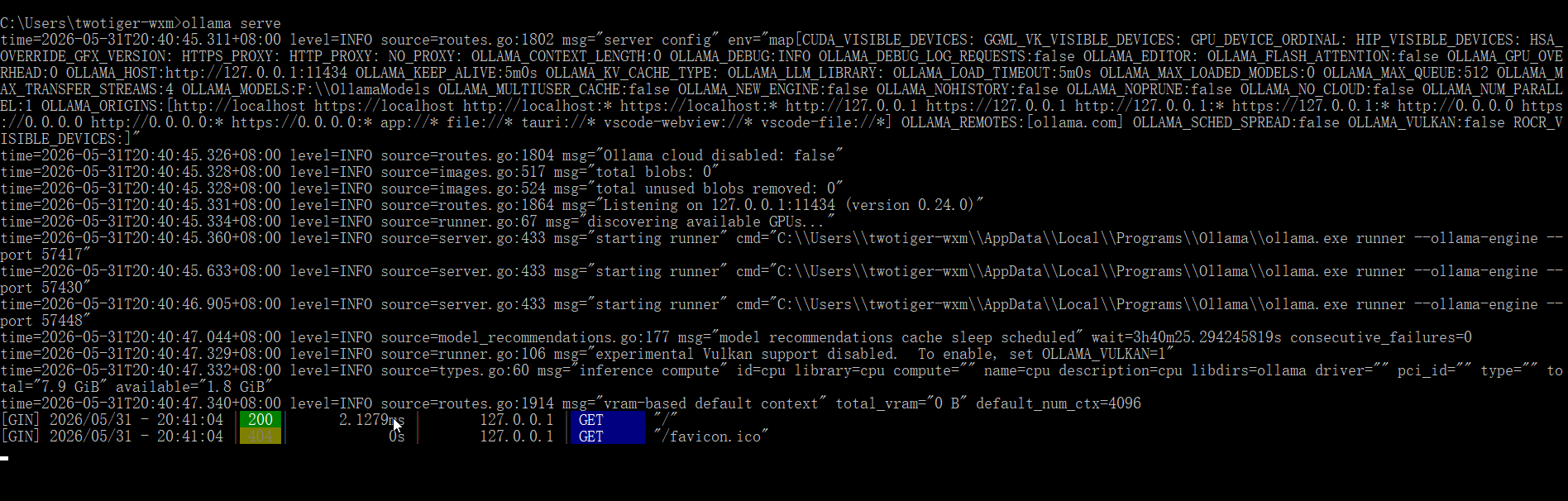
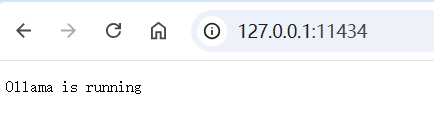
ollama serve启动 Ollama 时会报错如下,因为 Windows 系统安装 Ollama 时会默认开机启动 ,Ollama 服务默认是 http://127.0.0.1:11434
目前 Ollama 在 Windows 系统下默认开机自启,如果不需要开机自启,打开任务管理器,点击 启动,禁用 Ollama。
1.3、验证安装与运行第一个模型
安装完成并启动后,可以直接在命令行中体验:
- 按下
Win + R,输入cmd或powershell打开终端。 - 输入命令
ollama --version,如果成功返回了版本号(如 v0.x.x),说明OK。 - 运行模型 :输入命令
ollama run qwen2.5(以阿里的通义千问模型为例,中文能力很强)。
首次运行时,Ollama 会自动联网下载模型文件(很大!!!)。

2、模型运行
2.1、支持的模型
Ollama 支持的模型库列表:https://ollama.com/library
部分信息:
| Model | Tag | Parameters | Size | Download |
|---|---|---|---|---|
| DeepSeek-R1 | - | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | - | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | - | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | - | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | - | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | - | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | - | 405B | 231GB | ollama run llama3.1:405b |
| Gemma 2 | - | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | - | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | - | 27B | 16GB | ollama run gemma2:27b |
| mistral | - | 7b | 4.1GB | ollama run mistral:7b |
| qwen | - | 110b | 63GB | ollama run qwen:110b |
| Phi 4 | - | 14B | 9.1GB | ollama run phi4 |
| codellama | Code | 70b | 39GB | ollama run codellama:70b |
| qwen2 | - | 72b | 41GB | ollama run qwen2:72b |
| llava | Vision | 7b | 4.7GB | ollama run llava:7b |
| nomic-embed-text | Embedding | v1.5 | 274MB | ollama pull nomic-embed-text:v1.5 |
以DeepSeek为例:deepseek-r1
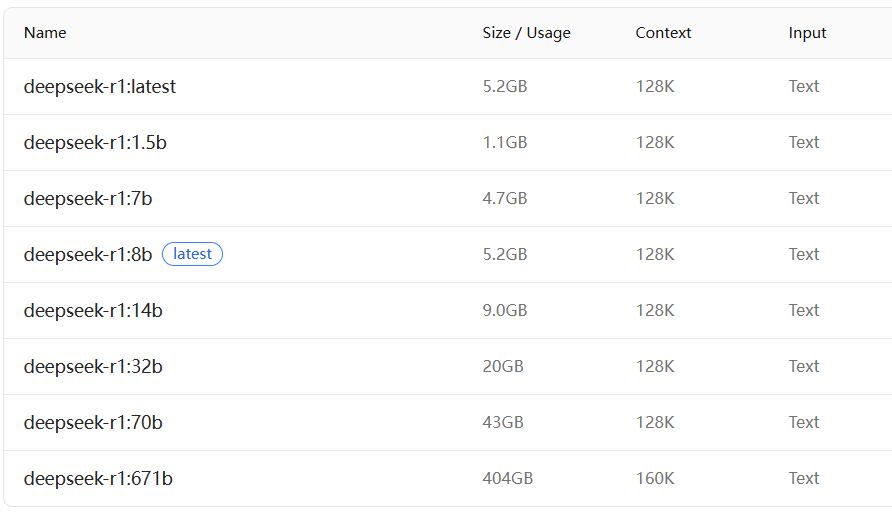
DeepSeek-R1-0528-Qwen3-8B
ollama run deepseek-r1:8bDeepSeek-R1-Distill-Qwen-1.5B
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-Qwen-7B
ollama run deepseek-r1:7bDeepSeek-R1-Distill-Qwen-14B
ollama run deepseek-r1:14bDeepSeek-R1-Distill-Qwen-32B
ollama run deepseek-r1:32bDeepSeek-R1-Distill-Llama-70B
ollama run deepseek-r1:70b注意:运行 7B 模型至少需要 8GB 内存,运行 13B 模型至少需要 16GB 内存,运行 33B 模型至少需要 32GB 内存。
2.2、硬件要求
Ollama 对硬件的宽容度非常高,核心原则是:硬件配置决定了能流畅运行多大参数规模的模型。
2.2.1、基础体验型(运行 1.5B - 7B 小模型)
适合日常简单的对话、文本生成或代码补全。
- CPU:现代 4核 CPU(如近几年的 Intel i5/i7 或 AMD Ryzen 5/7)。
- 内存 (RAM) :8GB 是起步门槛,建议预留 4GB-6GB 给 Ollama 使用。
- 硬盘:强烈建议使用固态硬盘(SSD),能大幅缩短模型的加载时间。至少预留 10GB-20GB 空间存放模型文件。
- 显卡 (GPU):无独立显卡也可运行(依靠 CPU),但如果有 NVIDIA 或 AMD 显卡(显存 4GB 以上),推理速度会快几倍。
2.2.2、进阶推荐型(流畅运行 7B - 13B 主流模型)
这是目前性价比最高的配置,能够流畅运行 Llama 3、Qwen 2.5 等主流开源模型,适合大多数开发者和重度用户。
- CPU:8核及以上的处理器。
- 内存 (RAM) :16GB 或以上。
- 显卡 (GPU) :配备 8GB 左右显存的独立显卡(如 NVIDIA RTX 3060/4060 及以上)。GPU 加速能让对话几乎达到"秒回"的效果。
2.2.3、专业发烧型(运行 32B - 70B+ 超大模型)
适合需要处理复杂逻辑、长文本分析或进行模型微调的专业场景。
- 内存 (RAM) :32GB 起步,若要运行 70B 级别的模型,建议配备 64GB 甚至更高的内存。
- 显卡 (GPU):需要大显存的高端显卡。例如 NVIDIA RTX 4090(24GB 显存)可以完整加载并流畅运行 32B 的模型;若要跑满血版 70B 模型,通常需要多张高端显卡或专业级显卡(如 A100)。
对照表:
| 需求定位 | 常见模型规模 | 核心配置建议 (内存 + 显存) |
|---|---|---|
| 基础体验 | 1.5B - 7B | 8GB 内存 (无独显也可) |
| 进阶推荐 | 7B - 13B | 16GB 内存 + 8GB 显存 |
| 专业发烧 | 32B - 70B+ | 32GB-64GB+ 内存 + 24GB+ 显存 |
2.2.4、展开讲解:
注意:大模型文件通常很大(一个 7B 模型约 4-5GB,70B 模型可能超过 40GB)。通过环境变量 OLLAMA_MODELS 把模型存放到其他盘符!!!
这里的"7B"和"70B"代表的是模型的参数规模(B 是 Billion 的缩写,意为"十亿")。简单来说,参数越多,模型就越聪明、懂的知识越广,但相应的,它的体积也就越大,对电脑配置的要求也越高。
对运行内存/显存的硬性门槛(能不能跑得动):模型不仅要存在硬盘里,运行时还必须完整地加载到内存(RAM)或显卡显存(VRAM)中。 如果容量不够,模型根本跑不起来,或者会卡死电脑。
做一个简单的换算来理解为什么 70B 模型需要那么大的内存:Ollama 默认使用的模型通常是经过"量化"压缩的版本(一般是 4-bit 量化)。这意味着每 10 亿(1B)个参数,大约需要占用 0.7GB - 0.8GB 的内存/显存。
1)、运行一个 7B 模型:
- 计算:7 × 0.7GB ≈ 4.9GB。
- 结论:电脑至少要有 6GB - 8GB 的空闲内存才能流畅运行它。这也是为什么建议基础体验型电脑至少配备 8GB 内存。
2)、运行一个 70B 模型:
- 计算:70 × 0.7GB ≈ 49GB。
- 结论:电脑至少要有 48GB - 64GB 的物理内存!普通的 16GB 或 32GB 内存的电脑,面对这种巨型模型是完全无法加载的。
3、Ollama 常用命令
| 命令 | 描述 |
|---|---|
ollama serve |
启动 Ollama |
ollama create |
从 Modelfile 创建模型 |
ollama show |
显示模型信息 |
ollama run |
运行模型 |
ollama stop |
停止正在运行的模型 |
ollama pull |
从注册表中拉取模型 |
ollama push |
将模型推送到注册表 |
ollama list |
列出所有模型 |
ollama ps |
列出正在运行的模型 |
ollama cp |
复制模型 |
ollama rm |
删除模型 |
ollama help |
显示任意命令的帮助信息 |
| 标志 | 描述 |
|---|---|
-h, --help |
显示 Ollama 的帮助信息 |
-v, --version |
显示版本信息 |
多行输入命令时,可以使用 """ 进行换行。使用 """ 结束换行。

终止 Ollama 模型推理服务,可以使用 /bye。
在 PowerShell 中,如果Ollama 进程一直运行,如果需要终止 Ollama 所有相关进程,可以使用以下命令:
Get-Process | Where-Object {$_.ProcessName -like '*ollama*'} | Stop-Process