每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

摘要
在多租户 LLM 服务场景中,容量管理是一个核心问题。Databricks 引入了名为 Model Units(模型单位) 的抽象,它类似于云计算中的虚拟机(VM),使得 GPU 资源能够按客户维度进行分配、路由和扩缩容。基于这一抽象构建的成本感知负载均衡与自动扩缩容机制,在满足延迟目标的同时,相较于静态资源预留节省了超过 80% 的 GPU 成本。与此同时,通过黑盒健康检查等运行时可靠性机制,系统能够自动发现并恢复各种隐性故障;而对多模态请求瓶颈的深入分析与优化,则进一步将整体吞吐量提升了三倍以上。
在 Databricks,我们构建了一套统一的推理平台,为几乎所有主流前沿模型提供服务,包括 Kimi、Qwen 等开源模型,以及 OpenAI、Gemini、Claude 等闭源模型。该平台支撑着包括 Superhuman、Yipit Data、Fox Sports 在内的一些全球规模最大的 agentic 应用,目前每月处理超过 125 万亿个 token。
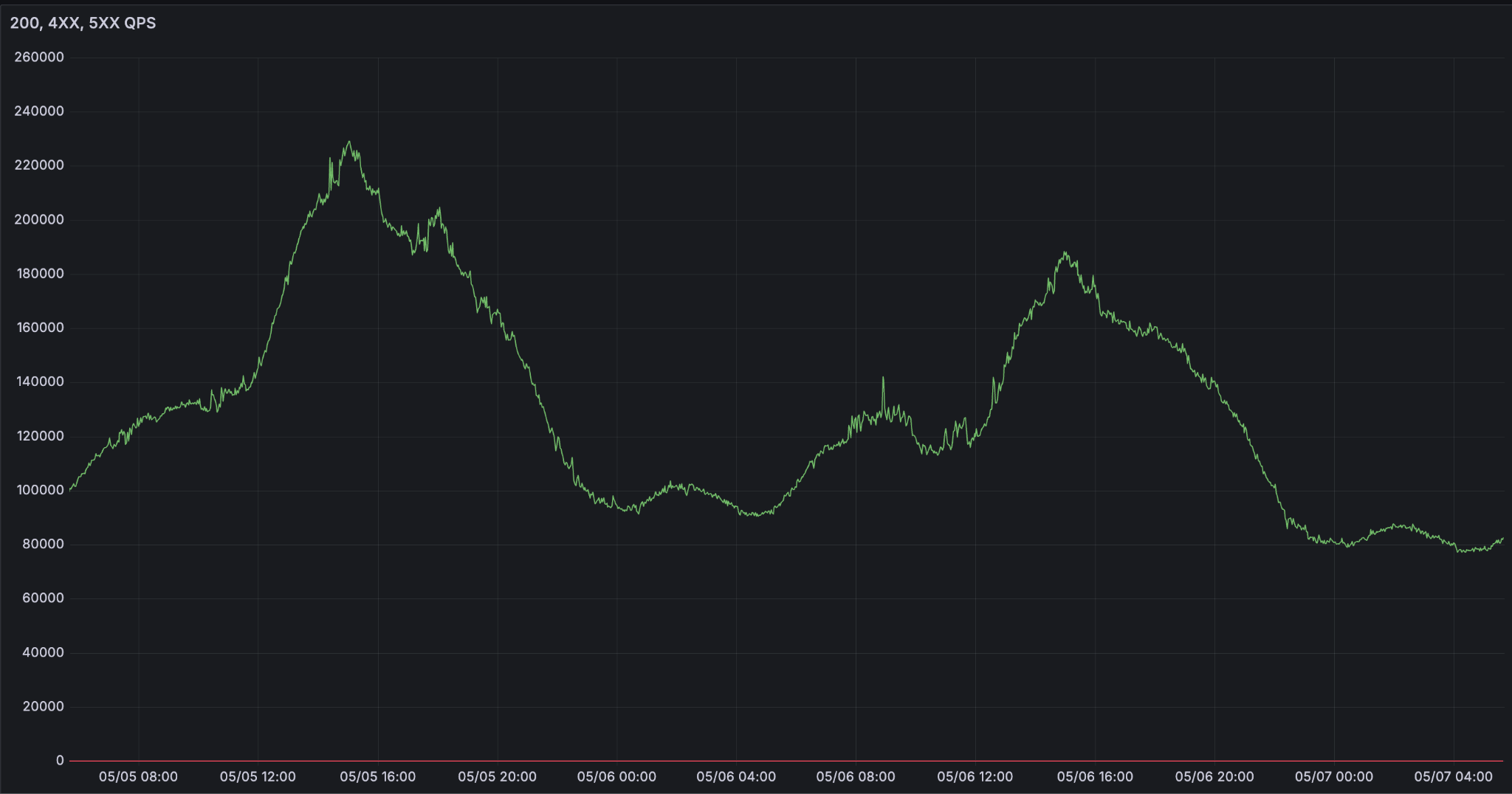
随着 agent 正逐渐成为人们工作和生活的重要交互界面,推理需求呈现指数级增长。我们观察到,大多数企业客户的流量都具有极强的波动性,尤其是在工作时间段内,经常会出现剧烈的流量峰值。正是在这样的背景下,如何保证大规模 LLM 服务的可靠性,成为最具挑战性的工程问题之一。
为什么大规模 LLM 推理如此困难?
表面上看,一个推理平台的职责似乎非常简单:收到请求,然后返回结果。
但实际上,"可靠性"远比这个定义复杂得多。
对于传统服务而言,可用性通常意味着请求是否能够被处理;而在 LLM 场景下,不同应用对延迟的容忍度差异极大,因此延迟本身已经成为可用性的重要组成部分。例如,对于复杂 agent 来说,如果 p95 Time To First Token(TTFT)或 Output Tokens Per Second(OPTS)出现明显退化,即便服务没有完全不可用,用户体验也会受到严重影响。
在多租户 LLM 服务系统中,同时满足可靠性和低延迟目标并不容易,而挑战主要来自两个方面:可靠性与延迟。
可靠性挑战
为了获得最先进模型所需的性能,推理系统通常需要使用最新一代 GPU,并依赖高速互联网络进行 KV Cache 传输。然而,与成熟稳定的 CPU 集群相比,这类 GPU 集群天然更加脆弱,同时成本也高得多。
例如,在 Prefill 和 Decode 解耦部署架构中,各节点之间需要进行 All-to-All 通信,这意味着只要某个节点发生故障,就可能迫使多个相关节点同时重新配置。此外,为了获得最高带宽,许多系统必须部署在同一个物理机架内,例如 NVL72 集群。这种架构虽然性能极高,却带来了更大的故障影响范围------机架内某个关键组件失效,可能直接导致整个服务区域受到影响。
传统分布式系统中的常见做法,例如跨可用区部署(Multi-AZ)或预留备用实例,在 GPU 场景下成本往往难以接受,因为这意味着大量昂贵 GPU 长期处于闲置状态。类似地,超额预留(Overprovisioning)虽然能够提升可靠性,但在 GPU 供应本就紧张的现实条件下也并不可行。因此,推理系统必须能够在资源紧张和高负载条件下持续稳定运行。
与此同时,平台还必须保持足够快的产品迭代速度。Databricks 的推理需求在过去几年中增长了多个数量级,而为了支撑这种增长,团队持续引入图像、视频、安全分类等新能力。每新增一种能力,背后都意味着一套新的预处理系统,而这些系统不仅要能够独立扩展,还必须保持整体架构的稳定性。
更复杂的是,为了支持最新模型架构并获得最佳性能,团队不得不在整个推理栈中进行大量底层优化,包括自定义 CUDA Kernel、自研推理引擎以及各种硬件级调优。然而,每当模型架构发生变化时,新的底层软件组件也会随之引入,而这些组件在大规模环境下往往会暴露出极其隐蔽的问题,例如服务器无响应、GPU 崩溃等,排查过程异常困难。
延迟挑战
除了可靠性之外,延迟管理同样困难。
根本原因在于,LLM 请求的处理成本具有极强的不确定性。即使服务器本身完全健康,只要负载增加,所有请求的响应时间都会变长。因此,在吞吐量(对应成本效率)和延迟目标之间始终存在权衡。
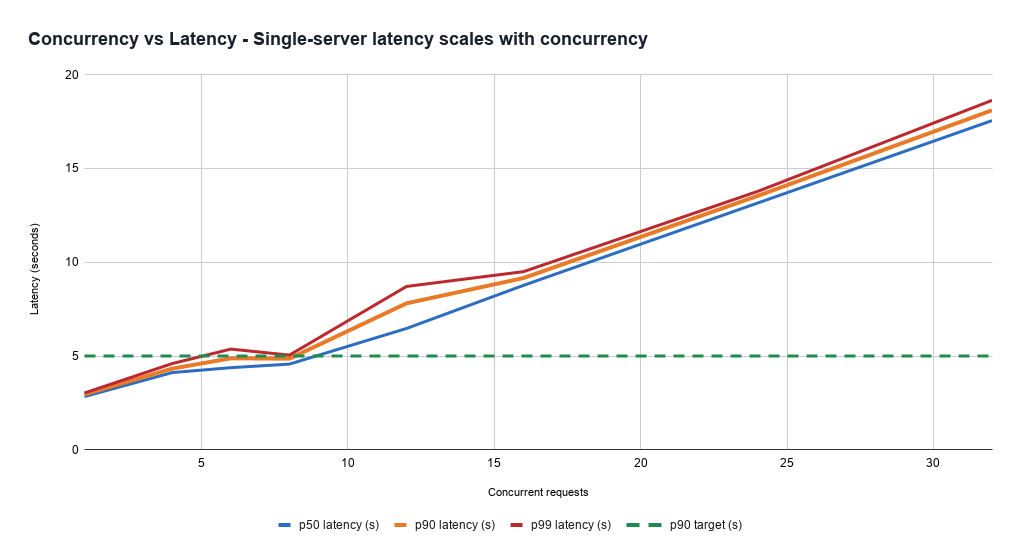
这种问题在 LLM 场景中尤为突出,因为请求成本差异极大。一个短问答请求和一个超长上下文 Agent 请求,对 GPU 的消耗可能相差数十倍甚至数百倍。更糟糕的是,请求的主要成本往往来自输出阶段,而模型究竟会生成多少 token,在请求开始之前很难准确预测。
因此,要实现低延迟服务,系统必须具备复杂的容量管理、负载均衡和请求优先级调度能力。
整体架构
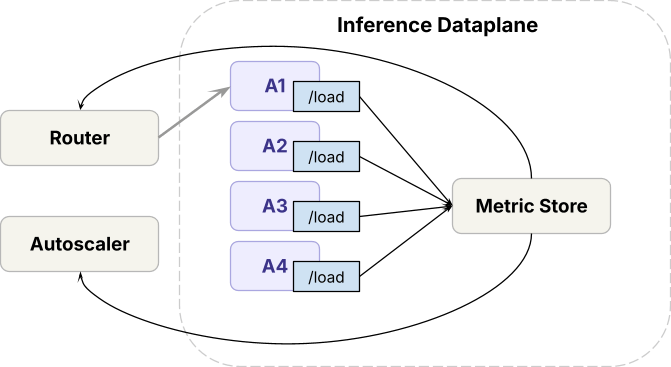
Databricks 的推理平台分为数据平面(Data Plane)和控制平面(Control Plane)两部分。
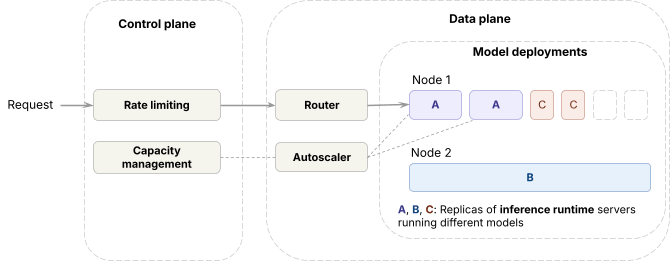
在数据平面中:
- 推理引擎运行在前沿 GPU 集群上;
- 系统使用名为 Axon 的路由器在同一模型的多个副本之间分配流量;
- Autoscaler 根据负载动态调整副本数量。
在控制平面中:
- 所有请求首先经过限流系统;
- 容量管理算法根据实时指标决定每个工作负载能够获得多少 GPU 容量;
- Autoscaler 根据这些决策执行扩缩容操作。
用 Model Units 管理容量
为了管理多租户环境中的 GPU 容量,团队引入了一个关键抽象:Model Units(模型单位)。
其思想类似于云计算中的虚拟机配额。
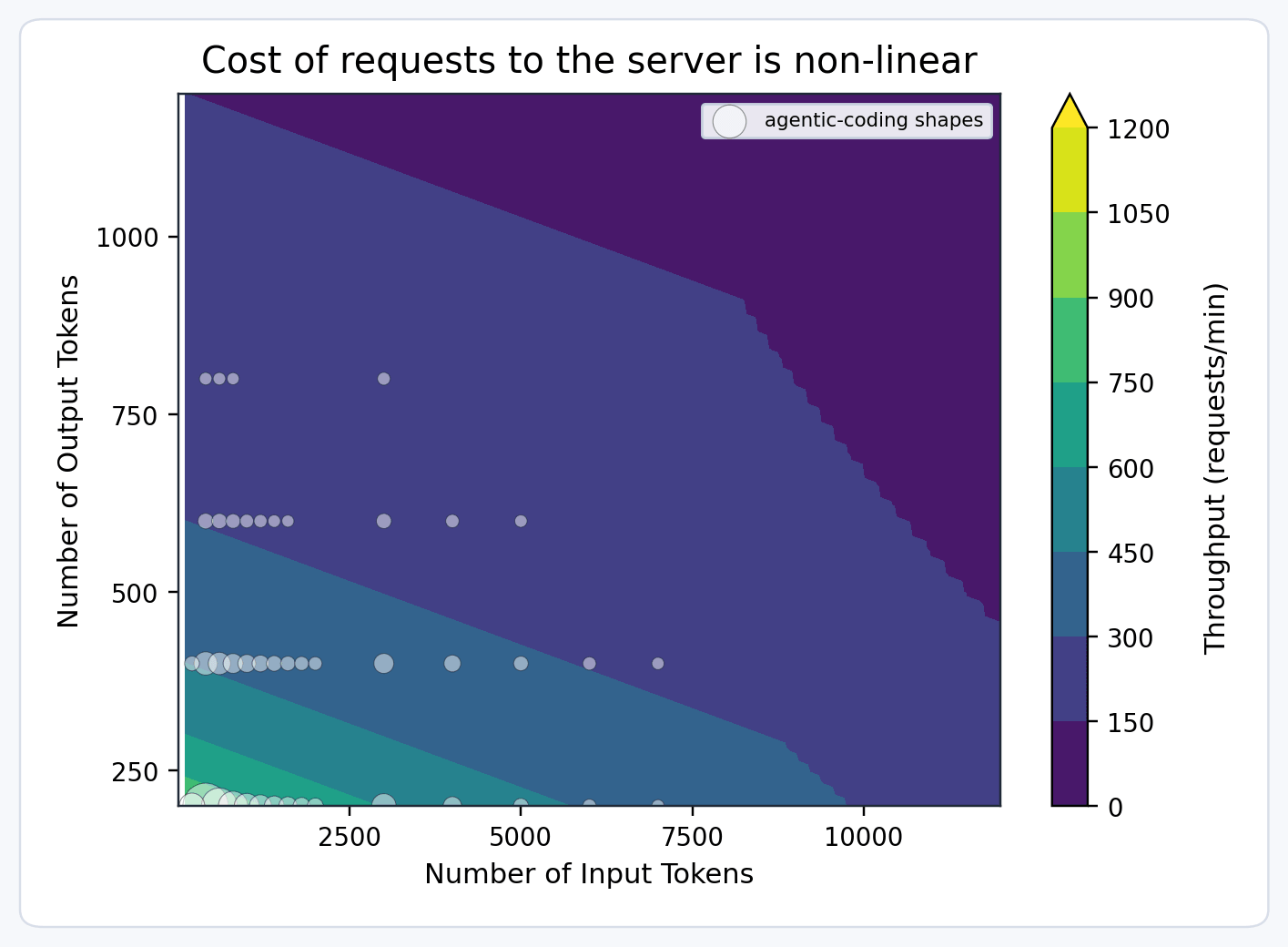
假设某个模型副本每分钟最多能够处理 100 个 Model Units,那么系统就可以将不同请求统一映射到同一种资源度量方式上。
由于不同请求消耗资源的方式不同,因此请求成本需要根据输入与输出 token 数量进行估算:
Cost=α⋅input_tokens+β⋅output_tokens+γ⋅(input_tokens+output_tokens)2Cost=\alpha\cdot input\_tokens+\beta\cdot output\_tokens+\gamma\cdot(input\_tokens+output\_tokens)^2Cost=α⋅input_tokens+β⋅output_tokens+γ⋅(input_tokens+output_tokens)2
其中:
- α、β、γ 通过自动 Benchmark 得出;
- 不同模型和硬件配置拥有不同参数;
- Prefix Cache、多模态请求等特性也会被纳入计算。
这种估算当然不可能完全精确,但它提供了一种统一的容量语言,使复杂的 GPU 推理系统能够像 VM 一样进行资源分配与管理。对于生产级 Agent 应用而言,这种容量保证至关重要,否则平台只能提供无法保证性能的 Best-Effort 服务。
基于成本的负载均衡与自动扩缩容
传统负载均衡系统通常采用 P2C(Power of Two Choices)等统计方法,根据请求队列长度进行路由决策。然而,这类方法在 LLM 场景下效果有限,因为:
- LLM 请求执行时间远高于普通 Web 请求;
- GPU 集群规模远小于 CPU 集群;
- 错误路由的代价极高。
因此,Databricks 开发了名为 Dicer 的自动分片系统。
Dicer 不再根据请求数量进行调度,而是根据服务器当前消耗的 Model Units 进行路由决策。这使系统能够识别长上下文请求带来的真实负载,从而避免部分服务器成为热点而其他服务器闲置。
与此同时,Dicer 还支持会话粘性(Sticky Sessions),使同一工作负载持续落在同一组服务器上,从而提高缓存命中率,这对于代码生成 Agent 等高度依赖 KV Cache 的应用尤为重要。
同样的思想也被应用到自动扩缩容系统中。
相比于简单统计 Pending Request 数量,Model Units 能够更准确地反映 GPU 实际压力。当系统利用率接近最大 Model Units 容量时,Autoscaler 会触发扩容;反之则缩容。这样一来,扩缩容逻辑不再依赖于具体模型,而成为统一的基础设施能力。
实践结果表明,这种机制使系统不再需要长期维持峰值规模运行。对于流量波动明显的模型服务,GPU 使用成本相比静态资源预留降低了超过 80%。
运行时可靠性
即使拥有优秀的路由和扩缩容机制,也无法完全避免推理引擎自身的故障。
无论使用自研引擎还是开源推理框架,在生产环境中总会遇到各种边缘情况和资源竞争问题。因此,系统必须具备自动检测与恢复能力。
自动发现并恢复静默故障
团队经常遇到的一类问题是 Silent Hang。
某些特殊请求(例如结构化输出或复杂多模态输入)可能触发推理引擎中的未处理异常,导致服务器停止响应,却不会产生任何错误日志。
对此,Databricks 实现了定期黑盒健康检查机制。
当服务器长时间没有完成真实请求时,系统会发送一个最小化端到端请求。如果检查失败,Kubernetes Liveness Probe 就会自动重启该实例。由于这是黑盒机制,因此能够适用于所有推理引擎。
不过,高负载场景下又出现了新问题:健康检查本身可能因为排队过久而超时,进而误判正常服务器为故障节点。
为了解决这一问题,团队将健康检查请求设置为最高调度优先级,使其即便在极高负载下也能够快速完成。最终,系统能够在 5 分钟内完成故障检测、实例重启和服务恢复,而误判次数则从每周数次下降到零。
多模态请求带来的意外瓶颈
另一个典型问题出现在大规模图像请求场景中。
当大量多模态请求同时到来时,团队发现错误率和超时率显著上升。然而进一步分析发现,问题甚至还没有进入推理引擎核心阶段。
根本原因来自图像预处理。
对于某些模型而言,图像缩放与归一化操作极其耗费 CPU 资源,其耗时甚至比 Base64 解码高出十倍以上。与此同时,部分 Hugging Face 模型默认使用 PIL 图像处理器,而另一些则使用性能更高的 Torchvision 实现。
团队还发现一个隐藏问题:
在容器环境中,OMP_NUM_THREADS 默认等于宿主机 CPU 核数。例如宿主机拥有 192 个 vCPU,而容器实际只分配到 12 个核心。结果导致 Torch 创建远超容器容量的线程数量,引发严重 CPU Throttling。
通过:
- 统一切换到 Torchvision 图像处理器;
- 正确配置
OMP_NUM_THREADS;
系统最终彻底消除了 CPU 限流问题,并使单机吞吐量提升超过三倍,而无需增加任何 GPU 资源。
总结
要在大规模环境下提供可靠的 LLM 推理服务,必须从推理栈的每一层同时发力。从容量抽象、负载均衡、自动扩缩容,到运行时故障检测、多模态性能优化,每个环节都会直接影响最终的可靠性和成本效率。
Databricks 在这篇文章中分享的经验表明,随着 Agent 应用规模持续增长,推理平台面临的挑战已经远远超出了"把模型跑起来"这么简单。真正困难的部分在于,如何在流量剧烈波动、GPU 资源昂贵且模型持续演进的环境下,依然能够稳定地交付低延迟、高可靠性的服务。
而这还只是整个故事的一部分。容器快速启动、GPU 集群灰度发布、跨云和跨区域容量管理等问题,同样是现代 LLM 基础设施必须面对的重要课题。