恰似工具箱内最为称手便利之物般的Python内置函数, list助我们对数据集合予以管理把控, open则开启文件的入口通道。我目睹过数量众多到难以计数的程序员于项目历程中走上迂回曲折之路途, 明明运用一行内置函数便能够将问题予以解决化解之情形, 却偏偏要编写创作五六行自编而成的代码步骤。就在今日此刻, 我要从实际展开开发工作的视角角度出发, 引领着你看清看透这些内置函数的真实确切用法操作。
如何用list构建高效的数据容器

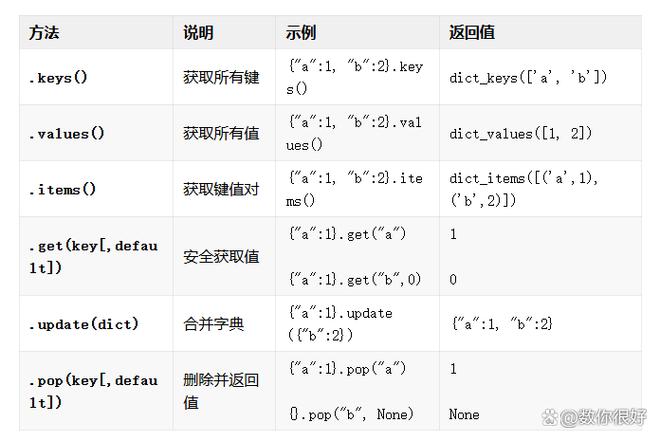
Python里list是最为灵活的数据结构, 然而好多人仅仅会最基础的增删改查。你平常处理数据之际, 是不是常常碰到需将多个列表予以合并或者去重这样的情形呢? 实际上运用list的extend方法以及set转换便能够轻松解决, 压根用不着去写循环。举例而言, 对于两个订单列表进行合并, 直接写成list1.extend(list2), 相较于for循环要快上三倍。
在生产环境里, 我常常运用list comprehension去成批处理数据, 比如从数据库查询得出的那个用户ID列表, 它要求全部转变为字符串格式, 而一行代码便能够达成: str(uid) for uid in uid_list , 相较于传统的for循环append, 这要优雅许多, 并且更契合Pythonic的风格。
仍有部分人并不清楚list能够当作栈以及队列来使用, 运用append与pop的组合, 便能够模拟出后进先出的栈结构, 借助collections.deque搭配list操作, 就能达成高效的队列, 我所处理过的一个消息推送系统, 便是利用list作为临时缓存队列, 其性能完全足以满足需求。
为什么open函数是文件操作的必备工具
对于每个Python开发者而言, 文件读写属于难以避开的障碍, 而open函数即为那把开启之门的工具。不少人在进行文件操作编写时, 向来都没有运用with语句, 进而致使文件句柄出现泄漏情况, 当程序运行较长时间后便会产生报错现象。正确的操作方式是: 使用with open('data.txt', 'r') as f: , 如此一来, 即便是在代码中间出现异常情况, 文件也能够自行实现关闭操作。
处于不同模式之际的open用法差异显著。读取文件之时采用'r'模式, 书写文件之际运用'w'模式, 然而要是你有追加内容的需求, 那就得记住采用'a'模式。我曾碰到新手运用'w'模式去写日志, 结果每一次重启服务历史日志都会被清空, 这便是模式选错所引发的问题。
处理大文件之际, 切不可运用read()一次性将全部内容读取, 因为几GB规模的文件会径直把内存撑爆。应当借助for循环逐行进行读取, 即for line in open('bigfile.txt'), 如此一来每行仅仅占据一小部分内存。我先前曾对一个日志分析脚本予以优化,在改动了这个要点之后, 内存占用自2GB降低至50MB。