#分析不同门店各类商品的库存情况和销售情况
#stores(门店)表
#products(商品)表
#sales_inventory(销售库存)表
# 您的观点"题目要求按商品分类分组"哪里不对?
# 题目原文:"查询每个门店库存数量小于10且销售额超过5000的商品类别、库存数量和销售额。"
# 这句话可以理解为:
# 找出那些满足条件的商品,然后输出这些商品的类别(以及该商品的库存和销售额)。
# 它并没有说要将同一类别的商品合并输出。合并输出通常会说"按商品类别汇总"或"每个类别的总库存、总销售额"。
# 结合排序要求(按 product_id),可以确定题意是按商品明细列出,只是隐藏了商品ID。
select
s1.store_id,#门店的唯一标识符。
s1.store_name,#门店的名称。
p.product_category,#商品类别。
sum(s2.inventory_quantity) as inventory_quantity,#库存数量。
sum(s2.sales_amount) as sales_amount #销售额。
from
stores s1 join sales_inventory s2 on s1.store_id=s2.store_id join products p on s2.product_id=p.product_id
group by s1.store_id, p.product_category,s1.store_name,s2.product_id
having sum(s2.inventory_quantity)<10 and sum(s2.sales_amount)>5000
order by s1.store_id,s2.product_id;
#s2.product_id 必须出现在 GROUP BY 中,因为分组需要精确到每个商品,才能正确汇总并按照商品ID排序。
#标准要求:ORDER BY 中的列(非聚合)必须出现在 GROUP BY 中。
错误解法但通过了线上测试
sql复制代码
select
s1.store_id,#门店的唯一标识符。
s1.store_name,#门店的名称。
p.product_category,#商品类别。
sum(s2.inventory_quantity) as inventory_quantity,#库存数量。
sum(s2.sales_amount) as sales_amount #销售额。
from
stores s1 join sales_inventory s2 on s1.store_id=s2.store_id join products p on s2.product_id=p.product_id
where inventory_quantity<10 and sales_amount>5000
group by s1.store_id, p.product_category,s1.store_name,s2.product_id
order by s1.store_id,s2.product_id;
原 SQL 中使用 WHERE inventory_quantity < 10 AND sales_amount > 5000,但 inventory_quantity 和 sales_amount 是聚合后的别名 ,WHERE 在聚合前执行,无法识别聚合结果。
正确写法应使用 HAVING 对分组后的聚合值进行筛选:
sql复制代码
SELECT
s1.store_id,
s1.store_name,
p.product_category,
SUM(s2.inventory_quantity) AS inventory_quantity,
SUM(s2.sales_amount) AS sales_amount
FROM stores s1
JOIN sales_inventory s2 ON s1.store_id = s2.store_id
JOIN products p ON s2.product_id = p.product_id
GROUP BY s1.store_id, s1.store_name, p.product_category, s2.product_id
HAVING SUM(s2.inventory_quantity) < 10 AND SUM(s2.sales_amount) > 5000
ORDER BY s1.store_id, s2.product_id;
错误原因解释
SQL 解析器按照 FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY 的顺序处理子句。
当解析器读到 HAVING 时,它期望之前已经出现了 GROUP BY(因为 HAVING 是对分组后的结果进行过滤)。
您的 HAVING 出现在 GROUP BY 之前,解析器无法理解,因此报语法错误,提示在 'product_id' 附近出现问题(因为解析器在错误的位置遇到了 GROUP BY 关键字及后续字段,导致混淆)。
总结
s2.product_id 必须出现在 GROUP BY 中,因为分组需要精确到每个商品,才能正确汇总并按照商品ID排序。
它不在 SELECT 中是完全允许的(符合 SQL 标准),只是起到"隐形分组键"的作用。
原 SQL 未报错是因为宽松的 MySQL 设置,但逻辑上应使用 HAVING 而非 WHERE,并建议开启 ONLY_FULL_GROUP_BY 来避免歧义。
ORDER BY 列表中的表达式也必须遵循相同规则:要么是聚合函数(如 SUM, MAX),要么出现在 GROUP BY 中。
原因:ORDER BY 是在 GROUP BY 和聚合计算之后执行的,排序列必须具有确定的值。如果排序列既不在 GROUP BY 中,又不是聚合函数,那么每个分组可能对应多个不同的值,数据库无法决定使用哪个值来排序,这会产生歧义。
示例(标准 SQL 会报错)
sql
复制代码
-- 错误:order by 中的 product_id 不在 group by 中,也不是聚合函数
SELECT store_id, SUM(quantity)
FROM sales
GROUP BY store_id
ORDER BY product_id;
标准 SQL 会返回类似错误:Column 'product_id' is invalid in the ORDER BY clause because it is not contained in either an aggregate function or the GROUP BY clause.
在严格 SQL 模式下(如 ONLY_FULL_GROUP_BY 开启),ORDER BY 中可以使用聚合函数,而不需要该聚合函数出现在 GROUP BY 中。因为聚合函数是对每个分组计算一个确定的值,没有歧义。
示例
场景:统计每个部门的员工总薪资,并按总薪资降序排列。
sql
复制代码
-- 严格模式下合法
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id
ORDER BY SUM(salary) DESC;
这里:
ORDER BY 中使用了聚合函数 SUM(salary)。
该聚合函数没有出现在 GROUP BY 中(GROUP BY 只有 department_id),但这是完全合法的,因为 SUM(salary) 对每个 department_id 分组计算得到一个单一值,用于排序没有问题。
为什么合法?
聚合函数的结果是每组的确定性值 ,不依赖于组内行的选择。因此即使 ORDER BY 中的列没有出现在 GROUP BY 中,只要它是聚合表达式,就不违反 ONLY_FULL_GROUP_BY 规则。标准 SQL 允许这样写。
对比:非聚合列在 ORDER BY 中(非法)
sql
复制代码
-- 严格模式下非法:salary 不是聚合函数,也不在 GROUP BY 中
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY salary; -- 错误,因为 salary 在每个部门中有多个值
示例:了解 2023 年全年所有商品的盈利情况
描述
【背景】:一家公司想要了解 2023 年全年所有商品的盈利情况。
【原始表】:
sales_orders(销售订单)表:
order_id (订单 ID): 订单的唯一标识符
product_id (商品 ID): 商品的唯一标识符
quantity (销售数量): 销售的商品数量
unit_price (销售单价): 商品的销售单价
order_date (订单日期): 订单的日期
purchase_prices(进货价)表:
product_id (商品 ID): 商品的唯一标识符
purchase_price (进货单价): 商品的进货单价
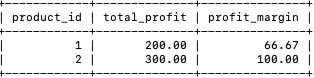
【要求】:需要根据表格数据查询出每个商品在 2023 年的利润,字段包括具体字段名。根据上面这两个表格,查询每个商品在 2023 年的利润,包含的字段:商品 ID、利润。查询出来的数据按照商品 ID 升序排列。要求查询出来的表格的字段如下:
#2023 年全年所有商品的盈利情况
#sales_orders(销售订单)表
#purchase_prices(进货价)表
select
s.product_id,# 商品的唯一标识符。
sum((unit_price-purchase_price)*quantity) as total_profit,# 2023 年的利润(利润 = (销售单价 - 进货单价)* 销售数量)。
round((avg(unit_price)-purchase_price)/purchase_price*100,2) as profit_margin# 单个产品的利润率 (利润率 = (产品平均单价-产品进货单价)/产品进货单价)(round保留2位小数)
from sales_orders s join purchase_prices p on s.product_id=p.product_id
where date_format(order_date,'%Y')='2023'
group by s.product_id
order by s.product_id;
这个SQL为什么没报错,group by 后面只有一个字段
详细解释
1. 标准 SQL 要求
严格模式下,SELECT 列表中的非聚合列必须出现在 GROUP BY 中,除非该列函数依赖于 分组列。
SELECT customer_id, MAX(product_id), SUM(quantity)
FROM orders
GROUP BY customer_id;
MAX(product_id) 是聚合结果,每个分组只有一个值,合法。
情况4:GROUP BY 包含了主键或唯一键,其他表的非键列也可以出现
sql
复制代码
SELECT o.order_id, o.customer_id, c.customer_name, SUM(o.quantity)
FROM orders o JOIN customers c ON o.customer_id = c.customer_id
GROUP BY o.order_id;
SELECT
s.product_id,
SUM((unit_price - purchase_price) * quantity) AS total_profit,
ROUND((AVG(unit_price) - purchase_price) / purchase_price * 100, 2) AS profit_margin
FROM sales_orders s
JOIN purchase_prices p ON s.product_id = p.product_id
WHERE YEAR(order_date) = 2023
GROUP BY s.product_id
ORDER BY s.product_id;