Agentic RAG 深度解析:让 Agent 自己决定要不要检索、检索几次,这才是 RAG 的正确打开方式
你有没有遇到过这种情况:搭了一套标准 RAG,上线后发现检索结果驴唇不对马嘴------用户问「2024 和 2025 的年度报告对比一下」,系统只检索到了 2024 的内容,然后大模型用这半桶水给了你一个「信心满满但完全错误」的答案。你反复调 top-K、调 chunk size,就是不稳。根本原因不是参数没调对,而是传统 RAG 的架构本身就没有自我纠错的能力------它就是个固定管道,检一次,生成,完事。
Agentic RAG 的核心思路是:把检索这件事交给 Agent 来决策。要不要检索?检哪个数据源?检完发现不够怎么办?这些都由 Agent 在运行时自主判断,而不是你在代码里硬编码。
这篇从原理到实战,把四种 Agentic RAG 模式拆透。
01 为什么说传统 RAG 是「一次性赌注」
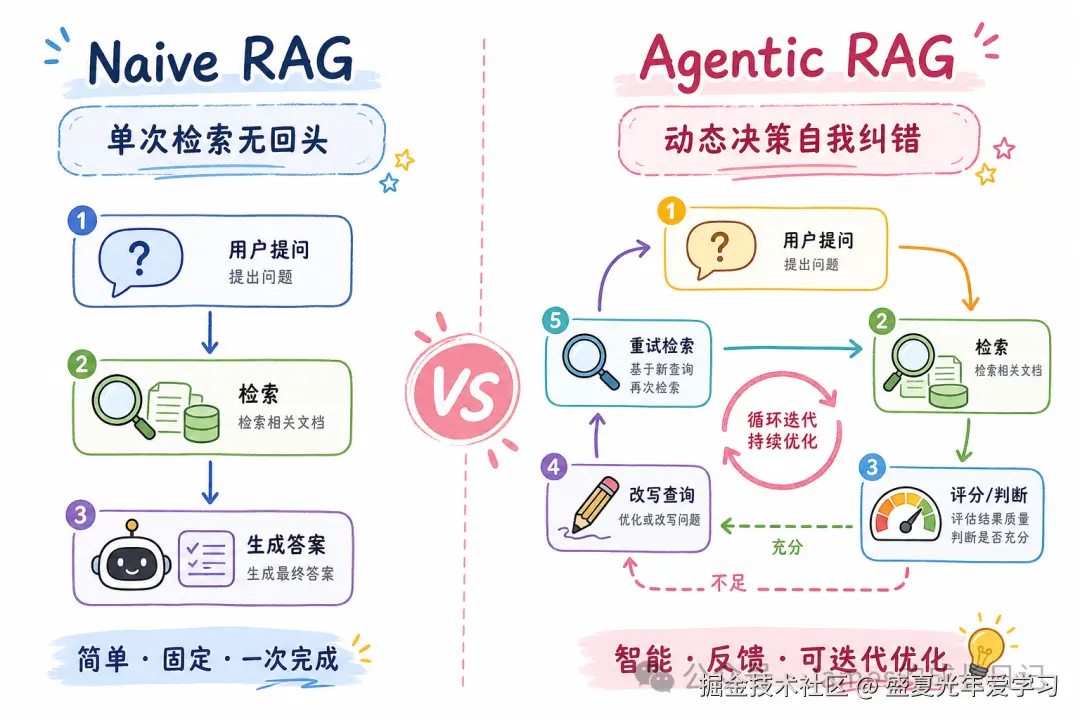
传统 RAG 的执行路径是固定的:用户提问 → Embedding → 向量检索(top-K) → 塞进 Prompt → 生成答案。这个流程在生产环境中有三个死穴:
死穴一:单次检索,没有回头路。 第一次检索结果质量差,没有任何机制能发现这一点并重试。系统会继续往下走,用一堆不相关的 chunk 生成一个「看起来很正经」的错误答案。
死穴二:单一数据源,知识孤岛。 用户的问题往往跨越多个数据域------文档库、数据库、实时 API。传统 RAG 只能连一个向量库,碰到跨域问题直接哑火。
死穴三:无法分解复杂问题。 「对比 Q3 和 Q4 的用户留存率,结合客服反馈分析原因」------这个问题需要至少三次独立检索再汇总。传统管道里,你只能硬塞进一个 query,然后祈祷。
根据多个生产系统的统计,15%-30% 的 RAG 失败都源于检索质量问题------而这些失败,在传统架构里根本无从发现,更无法修复。
Agentic RAG 的解法很直接:在检索和生成之间,加一层「会思考的 Agent」。
| 能力维度 | 传统 RAG | Agentic RAG |
|---|---|---|
| 检索策略 | 固定(单次向量搜索) | 动态(Agent 选数据源、改查询) |
| 检索轮次 | 永远是 1 次 | 按需决定(1 到 N 次) |
| 质量评估 | 无 | Agent 给检索结果打分 |
| 错误恢复 | 无 | 检测到失败后换策略重试 |
| 工具调用 | 无 | 可调用 API、SQL、网页搜索 |
| 查询分解 | 无 | 把复杂问题拆成子问题 |
02 四种模式:Agentic RAG 的设计图谱
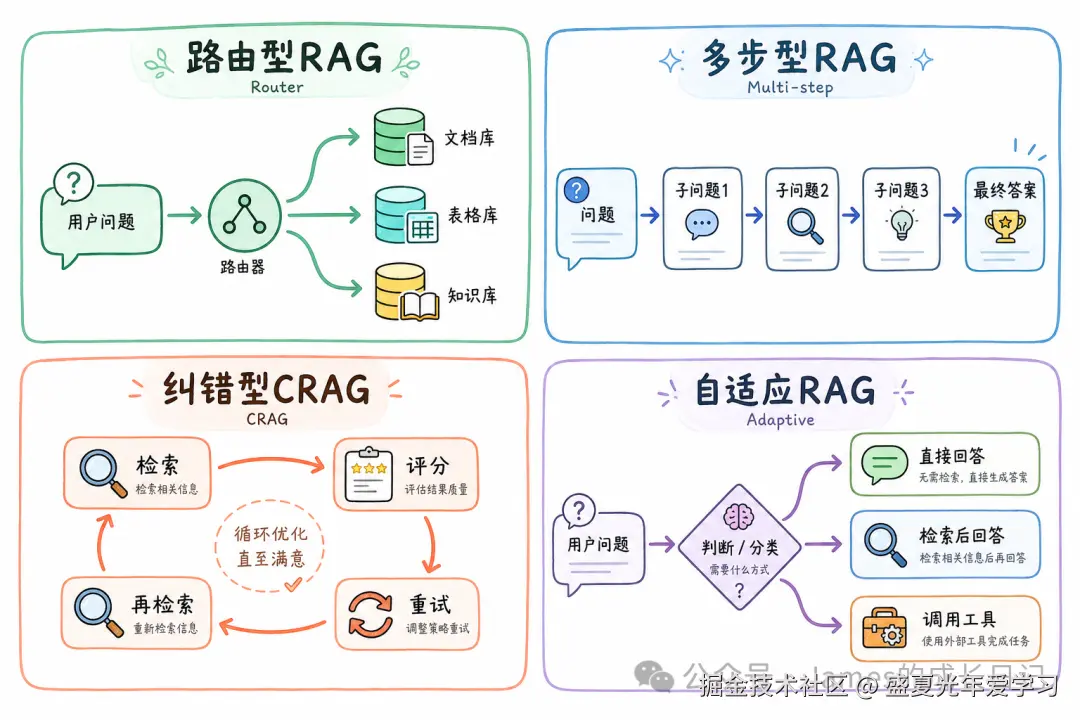
Agentic RAG 不是一种固定架构,而是四种可组合的模式。理解这四种模式,是选型的基础。
模式一:路由型 RAG(Routing RAG) 适用场景:知识分散在多个后端------向量库、SQL 数据库、知识图谱、实时 API。核心逻辑是 Agent 先理解问题意图,再决定去哪里取数据。用户问「Q3 营收」走 SQL,问「产品规格」走向量库,问「最新股价」走实时 API。
模式二:多步型 RAG(Multi-step RAG) 适用场景:单个 Query 需要多轮独立检索才能回答。Agent 把复杂问题拆解成子问题,依次检索,最后汇总。「新定价方案上线后流失率怎么变化,客服反馈如何」拆成三个独立子查询,分别检索,最后合并推理。
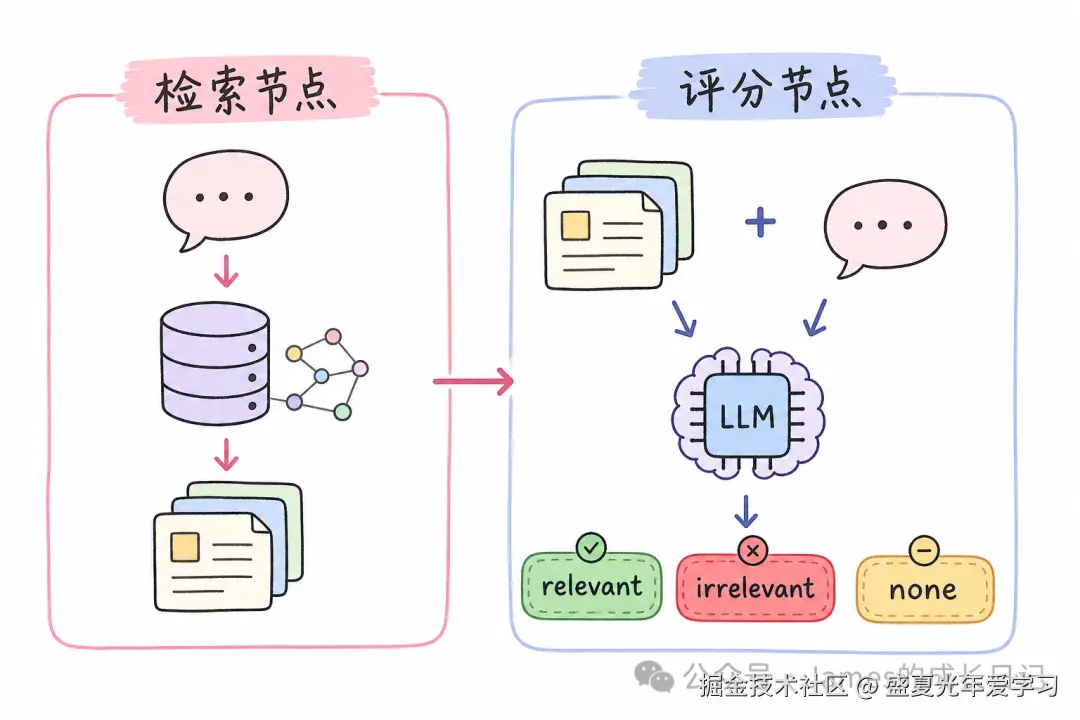
模式三:纠错型 RAG(Corrective RAG / CRAG) 适用场景:需要对检索结果进行可信度评估。检索 → 评分(相关吗?)→ 相关就生成,不相关就改写 Query 重试,完全没有就降级到网页搜索。这是实际项目里最实用的模式。
模式四:自适应型 RAG(Adaptive RAG) 适用场景:需要在「要不要检索」这一步就做判断。Agent 先判断:这个问题是常识、上下文已覆盖,还是真的需要检索?不需要就直接生成,避免无意义的检索开销。
03 CRAG 实战:给检索加一个「评分官」
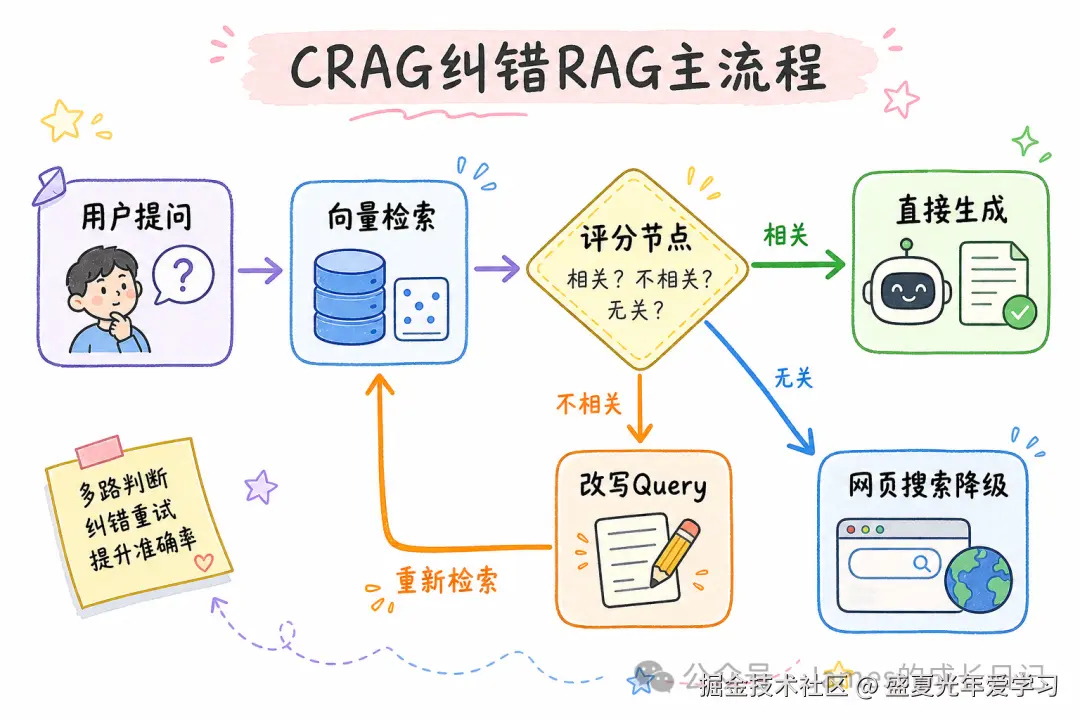
CRAG(Corrective RAG)是工程价值最高的模式,用 LangGraph + TypeScript 完整实现它。
先定义 State 和图结构:
typescript
import { Annotation, StateGraph, END } from "@langchain/langgraph";
import { ChatOpenAI } from "@langchain/openai";
import { z } from "zod";
// 定义 Graph 状态
const AgenticRAGState = Annotation.Root({
question: Annotation<string>(),
documents: Annotation<string[]>({
reducer: (prev, next) => [...prev, ...next],
default: () => [],
}),
generation: Annotation<string>(),
retrieval_grade: Annotation<"relevant" | "irrelevant" | "none">(),
retry_count: Annotation<number>({
reducer: (prev, next) => next,
default: () => 0,
}),
});
type RAGState = typeof AgenticRAGState.State;
const llm = new ChatOpenAI({ model: "gpt-4o-mini", temperature: 0 });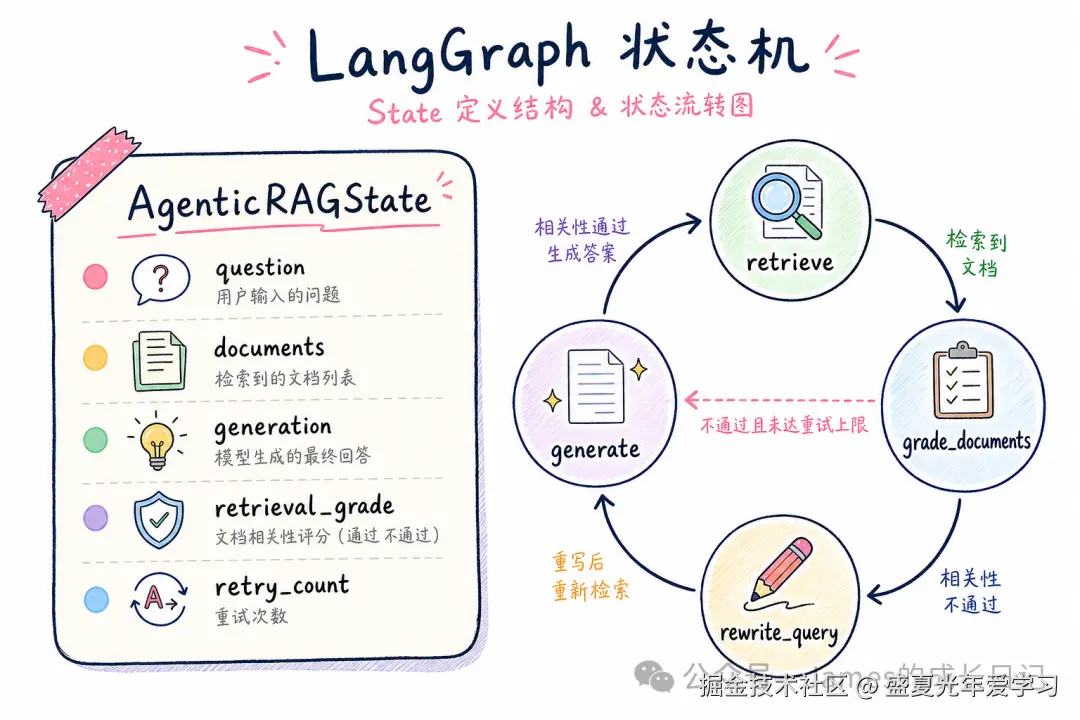
检索节点 + 评分节点------从向量库取文档,再让 LLM 判断相关性:
javascript
// 检索节点
async function retrieveNode(state: RAGState) {
const results = await vectorStore.similaritySearch(state.question, 5);
return { documents: results.map((d) => d.pageContent) };
}
// 评分节点
const GradeSchema = z.object({
score: z.enum(["relevant", "irrelevant", "none"]),
reason: z.string(),
});
async function gradeDocumentsNode(state: RAGState) {
const structuredLLM = llm.withStructuredOutput(GradeSchema);
const prompt = `你是一个检索结果评分器。
用户问题:${state.question}
检索到的文档:
${state.documents.join("\n\n---\n\n")}
评估这些文档是否能回答用户问题:
- relevant:高度相关,可以据此生成可靠答案
- irrelevant:关联性很弱,但还有一些信息
- none:完全无关或为空
给出评分和原因。`;
const result = await structuredLLM.invoke(prompt);
return { retrieval_grade: result.score };
}
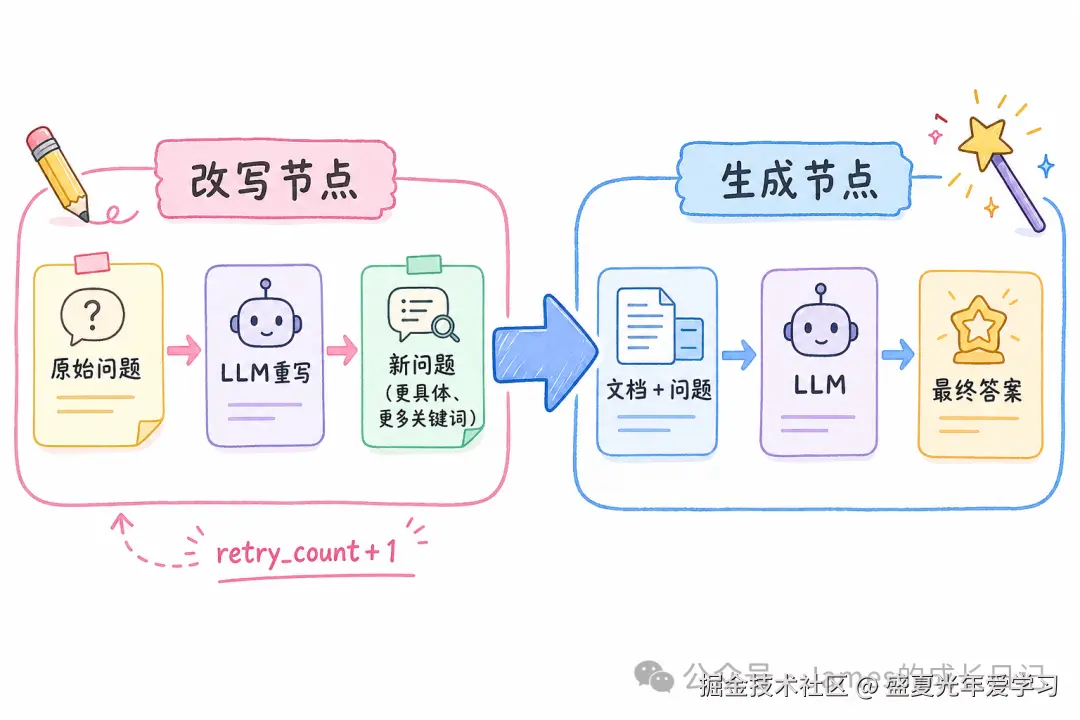
Query 改写节点 + 生成节点:
javascript
// Query 改写节点------检索质量差时优化问题表述
async function rewriteQueryNode(state: RAGState) {
const prompt = `原始问题:${state.question}
向量检索结果质量不佳。请重写问题,包含更多关键词、拆解更具体、去除歧义。
只输出改写后的问题,不要任何解释。`;
const response = await llm.invoke(prompt);
return {
question: response.content as string,
documents: [], // 清空旧结果,准备重新检索
retry_count: state.retry_count + 1,
};
}
// 生成节点
async function generateNode(state: RAGState) {
const context = state.documents.join("\n\n");
const prompt = `基于以下文档回答问题。
文档:${context}
问题:${state.question}
给出准确、有据可查的回答。如果文档不足以完整回答,请明确说明。`;
const response = await llm.invoke(prompt);
return { generation: response.content as string };
}
条件路由 + 组装 Graph:
arduino
// 条件路由------核心决策逻辑
const MAX_RETRY = 2;
function routeAfterGrading(state: RAGState): string {
if (state.retrieval_grade === "relevant") return "generate";
if (state.retry_count >= MAX_RETRY) {
console.log("⚠️ 超过重试上限,降级生成");
return "generate";
}
if (state.retrieval_grade === "none") return "rewrite_query";
return "generate"; // irrelevant 但有一些信息,接受并生成
}
// 组装 Graph
const workflow = new StateGraph(AgenticRAGState)
.addNode("retrieve", retrieveNode)
.addNode("grade_documents", gradeDocumentsNode)
.addNode("rewrite_query", rewriteQueryNode)
.addNode("generate", generateNode)
.addEdge("__start__", "retrieve")
.addEdge("retrieve", "grade_documents")
.addConditionalEdges("grade_documents", routeAfterGrading, {
generate: "generate",
rewrite_query: "rewrite_query",
})
.addEdge("rewrite_query", "retrieve") // 改写后重新检索
.addEdge("generate", END);
const app = workflow.compile();
// 运行
const result = await app.invoke({ question: "LangGraph 的 Checkpoint 是什么?" });
console.log("最终答案:", result.generation);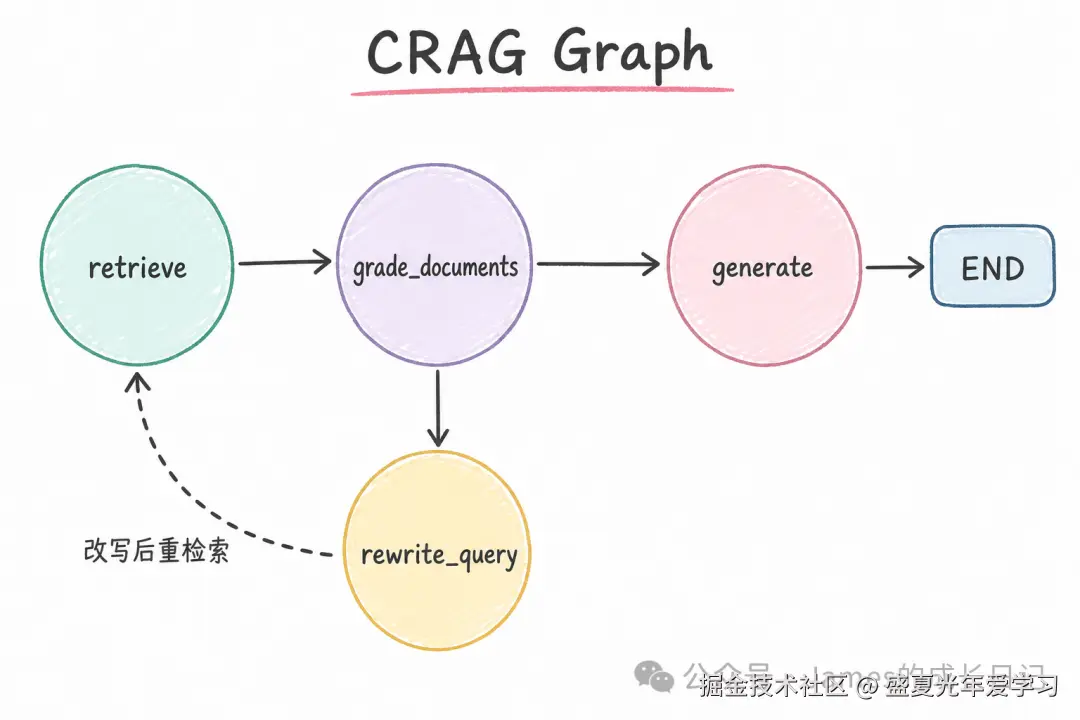
04 路由型 RAG:让 Agent 决定去哪个「图书馆」找书
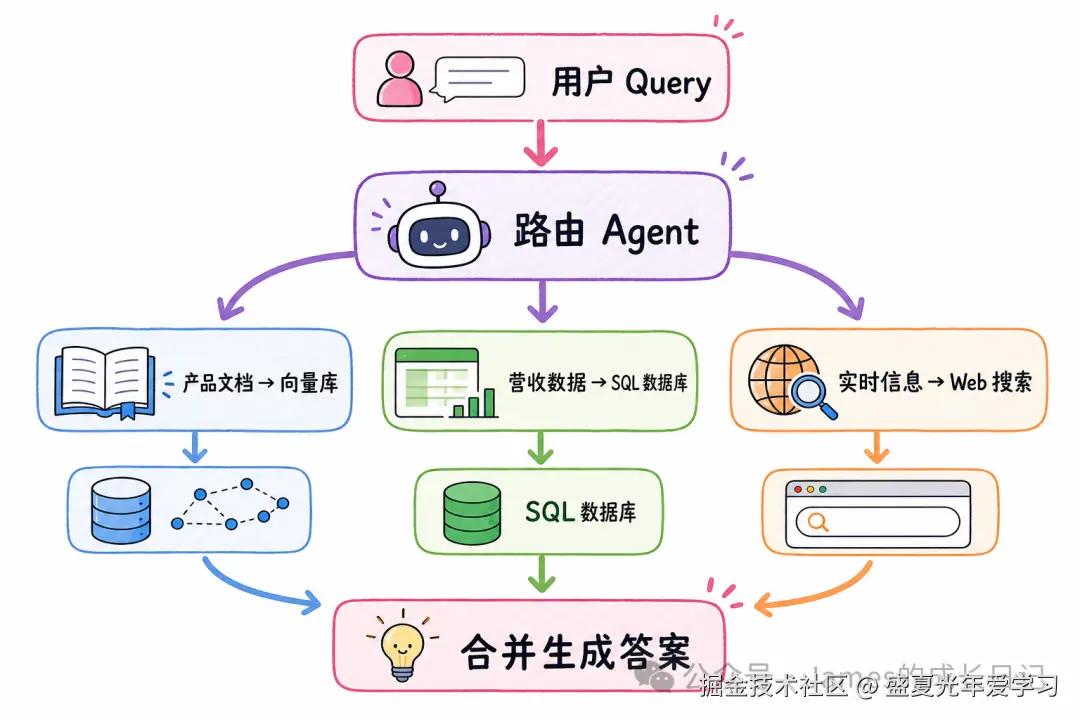
路由型 RAG 的关键在于把每个数据源封装成 Tool,让 LLM 自主选择。
csharp
import { tool } from "@langchain/core/tools";
import { z } from "zod";
// 工具1:向量库搜索(文档、FAQ)
const searchDocsTool = tool(
async ({ query }: { query: string }) => {
const results = await vectorStore.similaritySearch(query, 5);
return results.map((d) => d.pageContent).join("\n\n");
},
{
name: "search_docs",
description:
"搜索产品文档、技术规格、使用指南。适用于功能介绍、操作步骤类问题。",
schema: z.object({ query: z.string() }),
}
);
// 工具2:SQL 数据库(结构化数据)
const queryDatabaseTool = tool(
async ({ sql }: { sql: string }) => {
const result = await db.query(sql);
return JSON.stringify(result.rows);
},
{
name: "query_database",
description:
"查询业务数据库。适用于营收、用户量、留存率等量化指标问题。只支持 SELECT 语句。",
schema: z.object({ sql: z.string().describe("只读 SQL 查询语句") }),
}
);
// 工具3:网页搜索(实时信息)
const webSearchTool = tool(
async ({ query }: { query: string }) => {
const results = await tavilySearch(query);
return results.map((r: any) => r.content).join("\n\n");
},
{
name: "web_search",
description:
"搜索互联网获取最新信息。适用于当前事件、最新版本、外部市场数据。",
schema: z.object({ query: z.string() }),
}
);
// 绑定工具,让 Agent 自主路由
const agentWithTools = llm.bindTools([
searchDocsTool,
queryDatabaseTool,
webSearchTool,
]);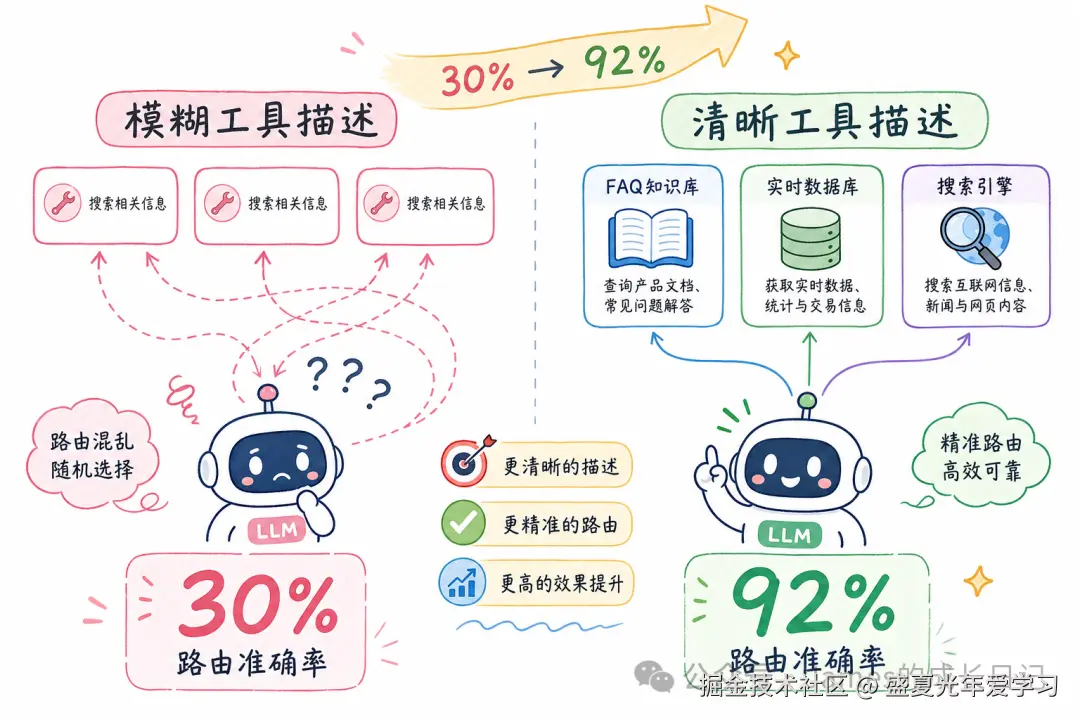
工具描述是路由准确性的关键------越清晰,LLM 选错的概率越低。每个工具描述都要写清楚:适用于什么问题,而不只是「功能是什么」。反例就在上面:如果你把三个工具描述都写成「搜索相关信息」,LLM 会倾向于总选第一个,路由完全失效。
05 自适应 RAG:连「要不要检索」都让 Agent 决定
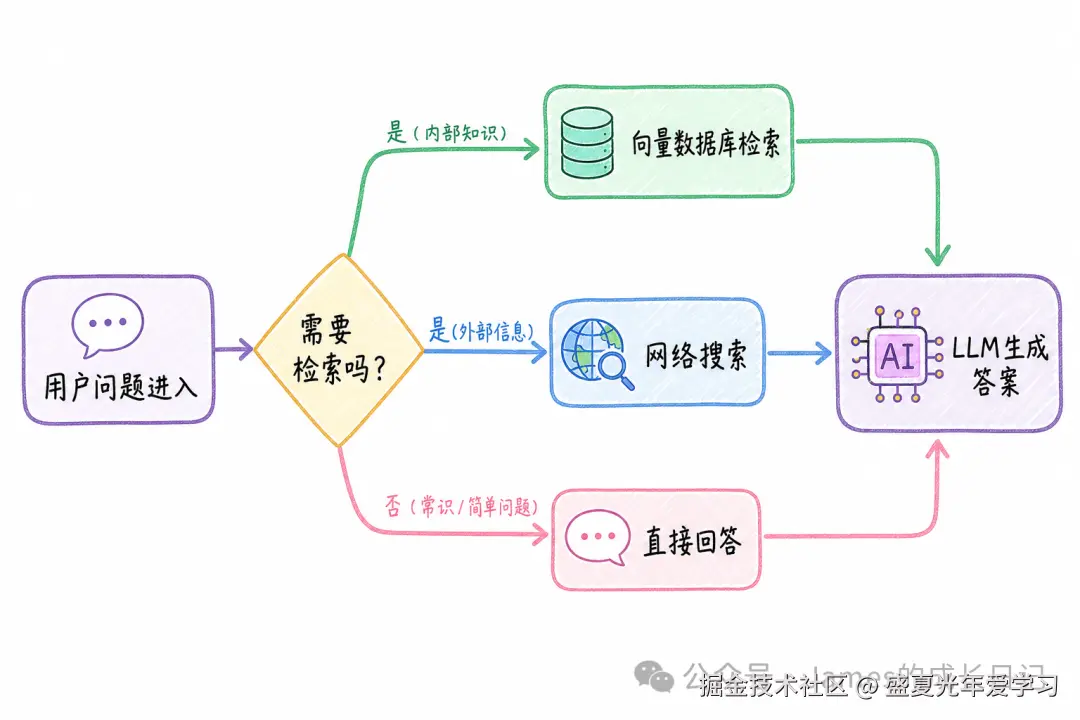
自适应 RAG 在所有模式里成本最优,因为它在最上游就做了一次过滤:这个问题需要检索吗?
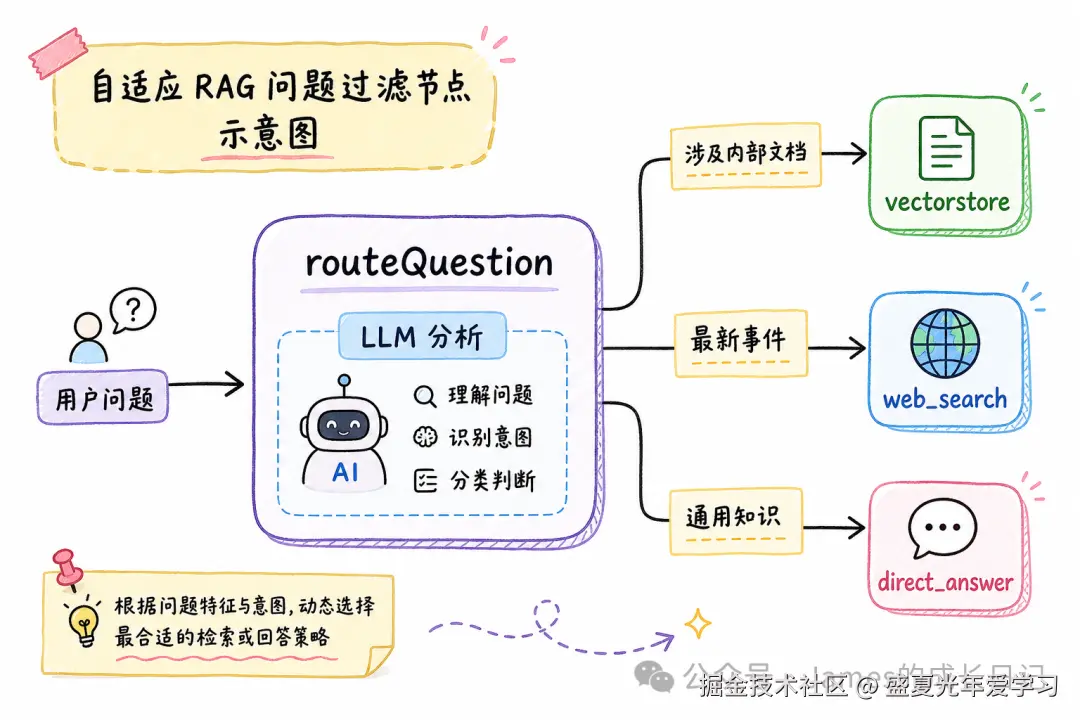
csharp
const RouteSchema = z.object({
datasource: z.enum(["vectorstore", "web_search", "direct_answer"]),
reason: z.string(),
});
async function routeQuestion(state: RAGState) {
const structuredLLM = llm.withStructuredOutput(RouteSchema);
const prompt = `你是一个问题路由器,决定如何最高效地回答用户问题。
问题:${state.question}
选择路由策略:
- direct_answer:通用知识或对话上下文已覆盖,不需要检索
- vectorstore:关于特定文档、产品内部知识
- web_search:需要实时信息或外部知识
选择最合适的一个,给出原因。`;
return await structuredLLM.invoke(prompt);
}
// Graph 中根据路由结果分叉
function routeNode(state: RAGState & { routing_decision?: string }): string {
const decision = state.routing_decision;
if (decision === "direct_answer") return "generate";
if (decision === "web_search") return "web_search";
return "retrieve";
}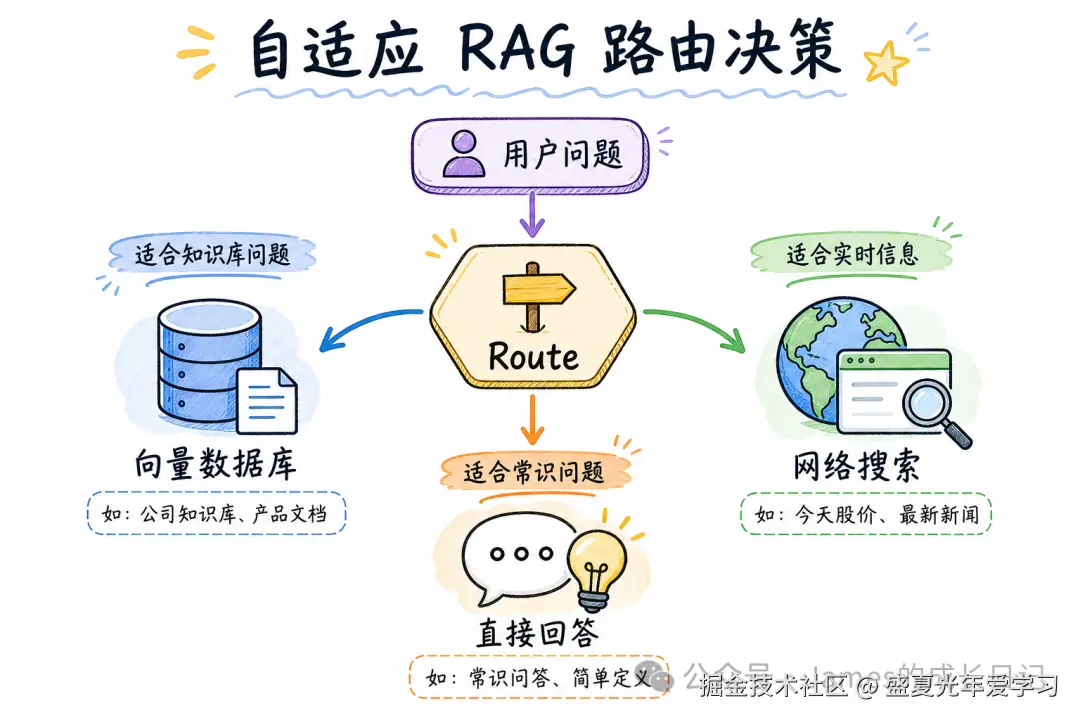
这个模式特别适合通用助手场景------用户既会问「你好,帮我写段代码」(不需要检索),也会问「我们的 API 文档里 rate limit 是多少」(需要检索内部文档)。统一入口,自适应路由。
06 常见坑:Agentic RAG 踩过才知道
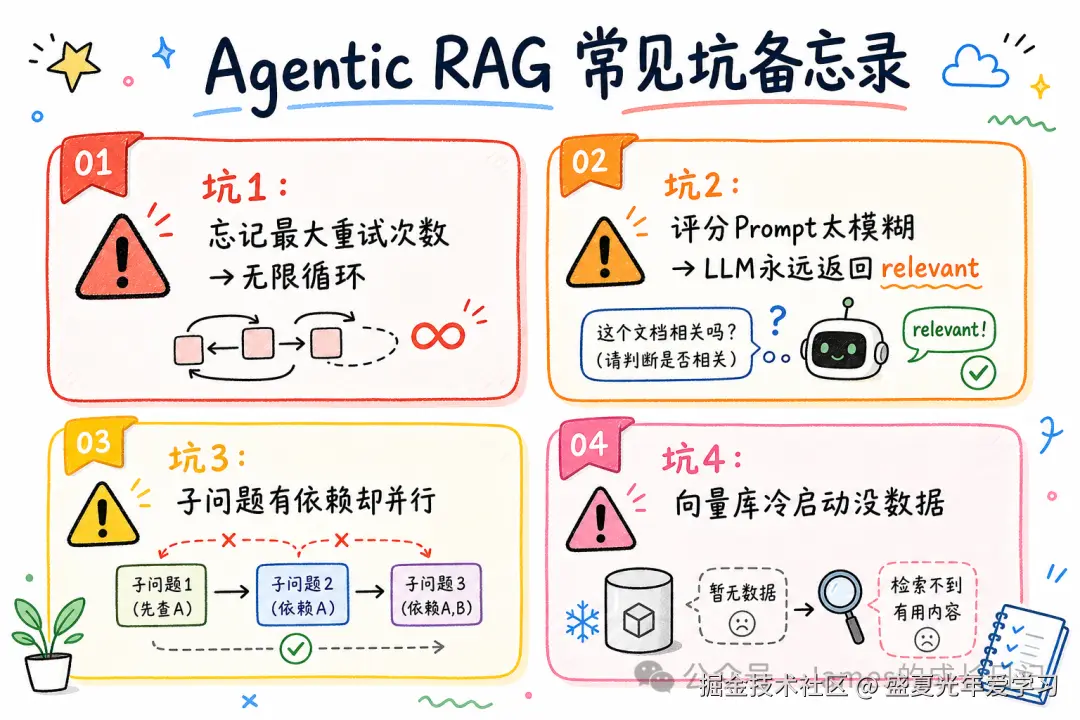
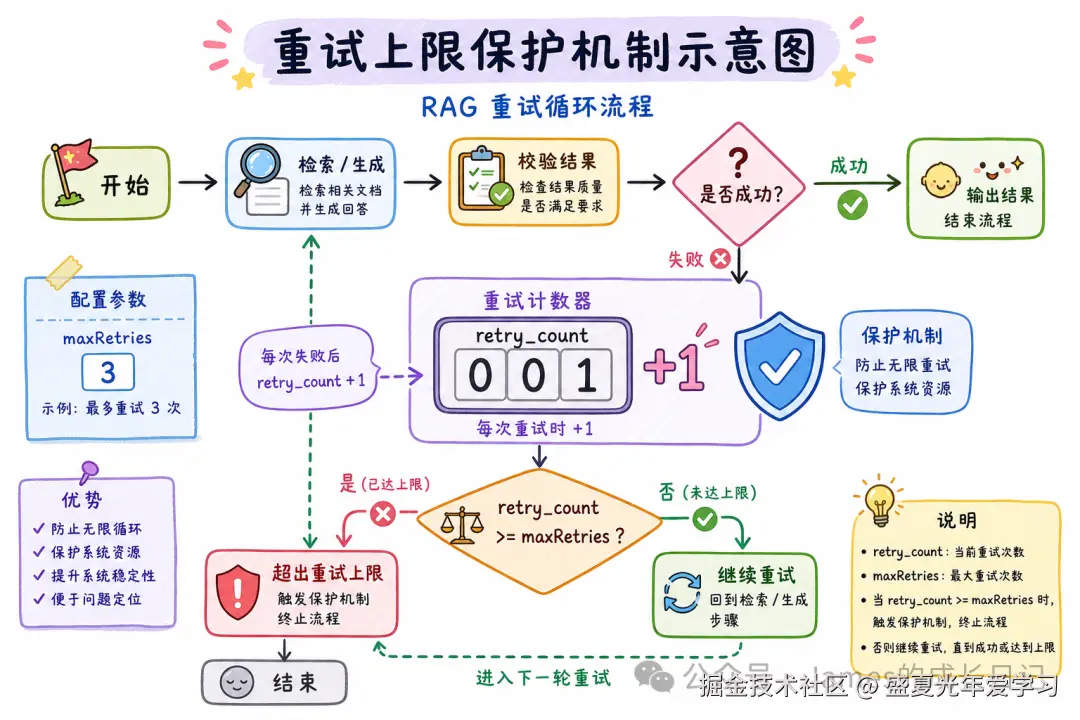
坑1:忘记设置最大重试次数,Graph 无限循环
纠错型 RAG 最容易踩这个坑。如果向量库里压根没有这个知识,CRAG 会一直循环到 token 耗尽。
kotlin
// 正确做法:硬性保护,State 里记录重试计数
if (state.retry_count >= MAX_RETRY) {
return "fallback_generate"; // 降级,绝不继续循环
}
坑2:评分 Prompt 太模糊,LLM 永远返回 "relevant"
如果评分 Prompt 只说「判断文档是否相关」,LLM 倾向于给「相关」------它在训练时被优化为「有帮助」的助手,不喜欢说「这个我不知道」。解法:在 Prompt 里给出具体的 "irrelevant" 判断条件,比如「如果文档只是包含相同关键词但讨论完全不同话题,算 irrelevant」。
坑3:多步 RAG 子问题有依赖却并行执行
把复杂问题拆成子问题后,如果直接并行检索,但子问题 B 的答案依赖子问题 A 的结果,最终合并时会出现逻辑断层。解法:在分解步骤里判断依赖关系,有依赖的串行,独立的才并行。
坑4:工具描述写得太像,LLM 每次都选同一个
路由型 RAG 里,如果三个工具描述都是「搜索相关信息」,LLM 会分布极不均匀。解法:每个工具描述要突出差异化适用场景,用反例说明「什么情况下不要用这个工具」。
坑5:评分节点用大模型,贵还不稳定
用 LLM 评估 LLM 检索结果本身有幻觉风险。评分用小模型(gpt-4o-mini)配 Zod schema 强制结构化输出,不要用大模型做简单分类任务------成本高且评分反而更不稳定。
总结
这篇我们把 Agentic RAG 从头到尾拆完了:
- 传统 RAG 的三个死穴:单次检索无回头、单一数据源孤岛、无法分解复杂问题------不是调参能解决的,是架构层的缺陷。
- 四种模式各有适场:路由型解决多数据源、多步型解决复杂分解、CRAG 解决检索质量、自适应型解决无意义检索开销------实际项目经常组合使用。
- CRAG 是工程价值最高的起点:加一个评分节点 + Query 改写节点 + 重试上限,三步改造让 RAG 具备自我纠错能力。
- 最大重试次数是生命线:任何带循环的 Agentic RAG,都要在 State 里记录重试计数,超限强制降级,永远不要让 Graph 无限重试。
- 工具描述决定路由准确率:路由型 RAG 里,工具的 description 比代码逻辑更关键------写清楚适用场景和反例。
下一篇我们进入「知识库的动态更新」------文档变了、新文档进来了,向量库怎么做增量同步,避免全量重导。