在处理大量数据时,快速定位并突出显示关键信息是一项非常重要的技能。通过高亮显示特定的数据,可以显著提高数据审查、分析和决策的效率。无论是标记异常值、突出显示重要指标,还是标识重复数据,条件格式化和查找高亮功能都能让数据更加直观易懂。
本文将详细介绍如何使用 Spire.XLS for Python 库在 Excel 中查找数据并进行高亮显示。我们将涵盖基于文本查找的高亮、条件格式化高亮、以及多种智能高亮技术,帮助你构建完整的数据可视化解决方案。
环境准备
在开始之前,你需要安装 Spire.XLS for Python 库。可以使用 pip 命令进行安装:
bash
pip install Spire.XLS安装完成后,你就可以在 Python 项目中使用该库来操作 Excel 文档并执行查找和高亮操作了。
查找并高亮的应用场景
在实际工作中,Excel 查找并高亮有多种典型应用场景:
- 数据审查:高亮显示包含特定关键词的单元格,便于快速审查
- 异常检测:标记超出正常范围的数据或异常值
- 重复数据识别:快速发现并高亮显示重复的记录
- 排名分析:突出显示最高或最低的数值
- 趋势分析:标记高于或低于平均值的数据点
- 关键字段标注:对重要字段或数据进行视觉强调
Spire.XLS for Python 提供了两种主要的高亮方法:直接设置单元格背景色和使用条件格式化。前者适合静态高亮,后者则能根据数据变化自动更新高亮效果。
查找文本并高亮显示
最基本的查找高亮操作是搜索工作表中的特定文本,然后为匹配的单元格设置背景颜色。以下示例展示了如何完成这一基本任务:
python
from spire.xls import *
from spire.xls.common import *
def FindAndHighlightText():
"""查找特定文本并高亮显示"""
inputFile = "/input/销售报告.xlsx"
outputFile = "/output/FindAndHighlight.xlsx"
# 创建工作簿对象
workbook = Workbook()
# 加载 Excel 文件
workbook.LoadFromFile(inputFile)
# 获取第一个工作表
worksheet = workbook.Worksheets[0]
# 查找所有包含 "Total" 的单元格
# 参数说明:搜索文本,区分大小写,完全匹配
ranges = worksheet.FindAllString("缺货", True, True)
# 遍历所有找到的单元格并高亮显示
for range in ranges:
# 设置背景颜色为黄色
range.Style.Color = Color.get_Yellow()
# 保存文件
workbook.SaveToFile(outputFile, ExcelVersion.Version2010)
workbook.Dispose()
if __name__ == "__main__":
FindAndHighlightText() 在这个示例中,我们使用
在这个示例中,我们使用 FindAllString() 方法查找所有匹配的单元格。该方法的前两个布尔参数分别控制是否区分大小写和是否完全匹配。返回的结果是一个单元格范围集合,我们可以遍历这个集合并为每个单元格设置背景颜色。
这种方法简单直接,适合用于一次性的高亮操作。高亮效果会永久保存在文件中,不会因为数据变化而改变。
使用条件格式化高亮排名前后的值
条件格式化是一种更智能的高亮方式,它会根据数据的实际值动态应用格式。以下示例展示了如何使用条件格式化来高亮显示最高和最低的数值:
python
from spire.xls import *
from spire.xls.common import *
def HighlightRankedValues():
"""高亮显示排名前后的值"""
inputFile = "/input/销售报告.xlsx"
outputFile = "/HighlightRankedValues.xlsx"
# 创建工作簿
workbook = Workbook()
# 从磁盘加载文件
workbook.LoadFromFile(inputFile)
# 获取第一个工作表
sheet = workbook.Worksheets[0]
# 应用条件格式化到范围 "B3:B16",高亮前 2 个最大值
xcfs = sheet.ConditionalFormats.Add()
xcfs.AddRange(sheet.Range["B3:B16"])
# 添加前 N 个值的条件
format1 = xcfs.AddTopBottomCondition(TopBottomType.Top, 2)
format1.FormatType = ConditionalFormatType.TopBottom
# 设置背景颜色为红色
format1.BackColor = Color.get_Red()
# 应用条件格式化到范围 "E3:E16",高亮后 2 个最小值
xcfs1 = sheet.ConditionalFormats.Add()
xcfs1.AddRange(sheet.Range["E3:E16"])
# 添加后 N 个值的条件
format2 = xcfs1.AddTopBottomCondition(TopBottomType.Bottom, 2)
format2.FormatType = ConditionalFormatType.TopBottom
# 设置背景颜色为森林绿
format2.BackColor = Color.get_ForestGreen()
# 保存文件
workbook.SaveToFile(outputFile, ExcelVersion.Version2010)
workbook.Dispose()
if __name__ == "__main__":
HighlightRankedValues()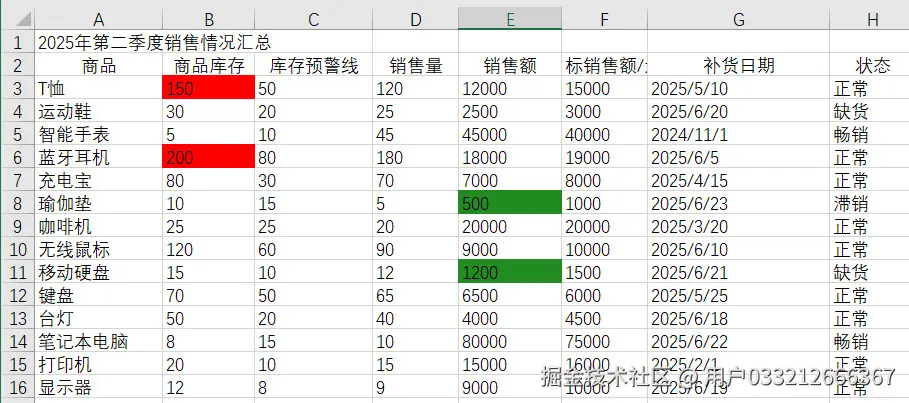
这个示例展示了条件格式化的强大功能。通过 AddTopBottomCondition() 方法,我们可以指定要高亮的是最大值还是最小值,以及要高亮的数量。与直接设置背景色不同,条件格式化是动态的:如果数据发生变化,高亮会自动调整到新的最高或最低值。
这种方法非常适合用于销售数据分析、成绩排名、性能评估等场景,能够自动突出显示表现最好和最差的项目。
高亮显示重复值和唯一值
在数据清理和验证过程中,识别重复数据和唯一数据是非常重要的。以下示例展示了如何使用条件格式化来实现这一点:
python
from spire.xls import *
from spire.xls.common import *
def HighlightDuplicateAndUnique():
"""高亮显示重复值和唯一值"""
inputFile = "/input/销售报告.xlsx"
outputFile = "/HighlightDuplicateUniqueValues.xlsx"
# 创建工作簿
workbook = Workbook()
# 加载文件
workbook.LoadFromFile(inputFile)
# 获取第一个工作表
sheet = workbook.Worksheets[0]
# 使用条件格式化高亮范围 "C3:C16" 中的重复值
xcfs = sheet.ConditionalFormats.Add()
xcfs.AddRange(sheet.Range["C3:C16"])
# 添加重复值条件
format1 = xcfs.AddCondition()
format1.FormatType = ConditionalFormatType.DuplicateValues
# 设置重复值的背景颜色为印度红
format1.BackColor = Color.get_IndianRed()
# 使用条件格式化高亮范围 "H3:H16" 中的唯一值
xcfs1 = sheet.ConditionalFormats.Add()
xcfs1.AddRange(sheet.Range["H3:H16"])
# 添加唯一值条件
format2 = xcfs1.AddCondition()
format2.FormatType = ConditionalFormatType.UniqueValues
# 设置唯一值的背景颜色为黄色
format2.BackColor = Color.get_Yellow()
# 保存文件
workbook.SaveToFile(outputFile, ExcelVersion.Version2010)
workbook.Dispose()
if __name__ == "__main__":
HighlightDuplicateAndUnique()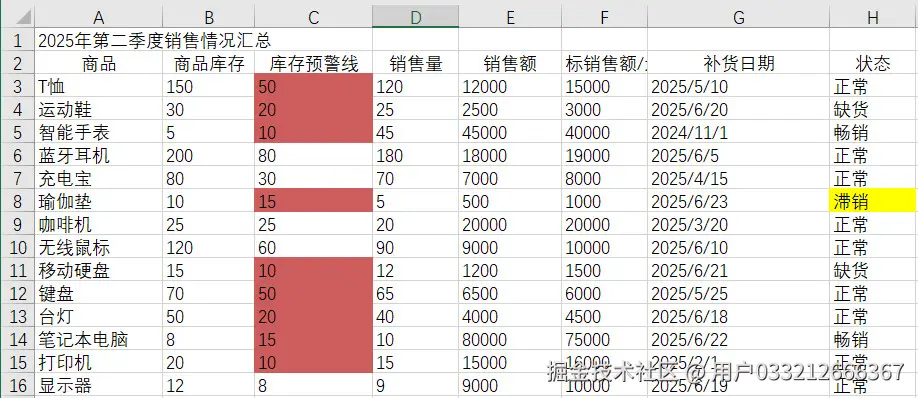 这个示例演示了如何使用
这个示例演示了如何使用 ConditionalFormatType.DuplicateValues 和 ConditionalFormatType.UniqueValues 来分别高亮重复值和唯一值。在数据清理场景中,这可以帮助你快速发现重复录入的记录;在分析场景中,唯一值高亮可以帮你识别稀有的数据点。
需要注意的是,条件格式化可以同时应用于同一个范围,因此重复值和唯一值可以在同一列中用不同的颜色同时显示。
高亮显示高于或低于平均值的数据
在统计分析中,了解哪些数据点高于或低于平均水平是非常有价值的。以下示例展示了如何实现这一功能:
python
from spire.xls import *
from spire.xls.common import *
def HighlightAverageValues():
"""高亮显示高于或低于平均值的数据"""
inputFile = "/销售报告.xlsx"
outputFile = "HighlightAverageValues.xlsx"
# 创建工作簿
workbook = Workbook()
# 加载文件
workbook.LoadFromFile(inputFile)
# 获取第一个工作表
sheet = workbook.Worksheets[0]
# 添加条件格式化以高亮低于平均值的数据
format1 = sheet.ConditionalFormats.Add()
# 设置要应用格式化的单元格范围
format1.AddRange(sheet.Range["E2:E10"])
# 添加低于平均值的条件
cf1 = format1.AddAverageCondition(AverageType.Below)
# 设置低于平均值的单元格背景颜色为天蓝色
cf1.BackColor = Color.get_SkyBlue()
# 添加条件格式化以高亮高于平均值的数据
format2 = sheet.ConditionalFormats.Add()
# 设置要应用格式化的单元格范围
format2.AddRange(sheet.Range["E2:E10"])
# 添加高于平均值的条件
cf2 = format2.AddAverageCondition(AverageType.Above)
# 设置高于平均值的单元格背景颜色为橙色
cf2.BackColor = Color.get_Orange()
# 保存文件
workbook.SaveToFile(outputFile, ExcelVersion.Version2010)
workbook.Dispose()
print(f"平均值高亮完成,文件已保存至: {outputFile}")
if __name__ == "__main__":
HighlightAverageValues()这个示例使用 AddAverageCondition() 方法来创建基于平均值比较的条件格式化。AverageType.Below 表示低于平均值,AverageType.Above 表示高于平均值。这种方法在数据分析中非常有用,可以快速识别表现优于或劣于平均水平的数据点。
例如,在销售数据分析中,你可以用这种方式快速找出哪些产品的销售额高于或低于平均水平;在学生成绩分析中,可以识别哪些学生的成绩高于或低于班级平均分。
实用技巧与高级应用
组合使用查找和条件格式化
在实际应用中,你可能需要结合文本查找和条件格式化来实现更复杂的高亮逻辑。以下是一个实用的工具类,展示了如何封装这些功能:
python
from spire.xls import *
from spire.xls.common import *
class ExcelHighlighter:
"""Excel 高亮显示工具类"""
def __init__(self, input_file):
"""初始化并加载工作簿"""
self.workbook = Workbook()
self.workbook.LoadFromFile(input_file)
self.input_file = input_file
def highlight_by_text(self, sheet_index, search_text,
back_color=None, case_sensitive=False,
exact_match=False):
"""通过文本查找并高亮"""
sheet = self.workbook.Worksheets[sheet_index]
# 查找所有匹配的单元格
ranges = sheet.FindAllString(search_text, case_sensitive, exact_match)
# 设置默认背景颜色
if back_color is None:
back_color = Color.get_Yellow()
highlight_count = 0
for range in ranges:
range.Style.Color = back_color
highlight_count += 1
print(f"工作表 '{sheet.Name}': 高亮了 {highlight_count} 个包含 '{search_text}' 的单元格")
return highlight_count
def highlight_top_values(self, sheet_index, cell_range, top_count=5,
back_color=None):
"""高亮前 N 个最大值"""
sheet = self.workbook.Worksheets[sheet_index]
if back_color is None:
back_color = Color.get_Red()
# 添加条件格式化
xcfs = sheet.ConditionalFormats.Add()
xcfs.AddRange(sheet.Range[cell_range])
format_rule = xcfs.AddTopBottomCondition(TopBottomType.Top, top_count)
format_rule.FormatType = ConditionalFormatType.TopBottom
format_rule.BackColor = back_color
print(f"工作表 '{sheet.Name}': 在范围 {cell_range} 中高亮前 {top_count} 个最大值")
def highlight_bottom_values(self, sheet_index, cell_range, bottom_count=5,
back_color=None):
"""高亮后 N 个最小值"""
sheet = self.workbook.Worksheets[sheet_index]
if back_color is None:
back_color = Color.get_ForestGreen()
# 添加条件格式化
xcfs = sheet.ConditionalFormats.Add()
xcfs.AddRange(sheet.Range[cell_range])
format_rule = xcfs.AddTopBottomCondition(TopBottomType.Bottom, bottom_count)
format_rule.FormatType = ConditionalFormatType.TopBottom
format_rule.BackColor = back_color
print(f"工作表 '{sheet.Name}': 在范围 {cell_range} 中高亮后 {bottom_count} 个最小值")
def highlight_duplicates(self, sheet_index, cell_range,
duplicate_color=None, unique_color=None):
"""高亮重复值和唯一值"""
sheet = self.workbook.Worksheets[sheet_index]
if duplicate_color is None:
duplicate_color = Color.get_IndianRed()
if unique_color is None:
unique_color = Color.get_Yellow()
# 高亮重复值
xcfs = sheet.ConditionalFormats.Add()
xcfs.AddRange(sheet.Range[cell_range])
format1 = xcfs.AddCondition()
format1.FormatType = ConditionalFormatType.DuplicateValues
format1.BackColor = duplicate_color
# 高亮唯一值
xcfs1 = sheet.ConditionalFormats.Add()
xcfs1.AddRange(sheet.Range[cell_range])
format2 = xcfs1.AddCondition()
format2.FormatType = ConditionalFormatType.UniqueValues
format2.BackColor = unique_color
print(f"工作表 '{sheet.Name}': 在范围 {cell_range} 中高亮重复值和唯一值")
def highlight_above_below_average(self, sheet_index, cell_range,
above_color=None, below_color=None):
"""高亮高于和低于平均值的数据"""
sheet = self.workbook.Worksheets[sheet_index]
if above_color is None:
above_color = Color.get_Orange()
if below_color is None:
below_color = Color.get_SkyBlue()
# 高亮高于平均值
format1 = sheet.ConditionalFormats.Add()
format1.AddRange(sheet.Range[cell_range])
cf1 = format1.AddAverageCondition(AverageType.Above)
cf1.BackColor = above_color
# 高亮低于平均值
format2 = sheet.ConditionalFormats.Add()
format2.AddRange(sheet.Range[cell_range])
cf2 = format2.AddAverageCondition(AverageType.Below)
cf2.BackColor = below_color
print(f"工作表 '{sheet.Name}': 在范围 {cell_range} 中高亮高于和低于平均值的数据")
def save(self, output_file=None):
"""保存工作簿"""
if output_file is None:
output_file = self.input_file
self.workbook.SaveToFile(output_file, ExcelVersion.Version2013)
self.workbook.Dispose()
print(f"文件已保存至: {output_file}")
def main():
input_file = "/SampleData.xlsx"
# 创建高亮工具实例
highlighter = ExcelHighlighter(input_file)
# 示例 1: 高亮包含特定文本的单元格
highlighter.highlight_by_text(0, "重要", Color.get_Yellow())
# 示例 2: 高亮前 3 个最大值
highlighter.highlight_top_values(0, "D2:D20", 3, Color.get_Red())
# 示例 3: 高亮后 3 个最小值
highlighter.highlight_bottom_values(0, "E2:E20", 3, Color.get_Green())
# 示例 4: 高亮重复值
highlighter.highlight_duplicates(0, "C2:C20")
# 示例 5: 高亮高于/低于平均值
highlighter.highlight_above_below_average(0, "F2:F20")
# 保存文件
highlighter.save("./Output/HighlightedData.xlsx")
if __name__ == "__main__":
main()这个工具类封装了多种高亮功能,包括文本查找高亮、排名高亮、重复值高亮和平均值高亮。通过实例化这个类,你可以轻松地在项目中复用这些功能,并根据需要组合使用不同的高亮方法。
常见应用场景示例
场景 1:销售数据审查
python
def ReviewSalesData():
"""审查销售数据"""
highlighter = ExcelHighlighter("./Data/SalesReport.xlsx")
# 高亮所有包含"紧急"标记的订单
highlighter.highlight_by_text(0, "紧急", Color.get_Orange())
# 高亮销售额前 10 名的产品
highlighter.highlight_top_values(0, "D2:D100", 10, Color.get_LightGreen())
# 高亮销售额低于平均水平的产品
format1 = highlighter.workbook.Worksheets[0].ConditionalFormats.Add()
format1.AddRange(highlighter.workbook.Worksheets[0].Range["D2:D100"])
cf1 = format1.AddAverageCondition(AverageType.Below)
cf1.BackColor = Color.get_LightCoral()
highlighter.save("./Output/SalesReview.xlsx")场景 2:学生成绩分析
python
def AnalyzeStudentGrades():
"""分析学生成绩"""
highlighter = ExcelHighlighter("./Data/StudentGrades.xlsx")
# 高亮不及格的学生(查找包含"F"的成绩)
highlighter.highlight_by_text(0, "F", Color.get_Red())
# 高亮前 5 名优秀学生
highlighter.highlight_top_values(0, "C2:C50", 5, Color.get_Gold())
# 高亮低于班级平均分的学生
highlighter.highlight_above_below_average(0, "C2:C50")
highlighter.save("./Output/GradeAnalysis.xlsx")场景 3:库存管理
python
def ManageInventory():
"""管理库存数据"""
highlighter = ExcelHighlighter("./Data/Inventory.xlsx")
# 高亮库存为零的产品
highlighter.highlight_by_text(0, "0", Color.get_Red())
# 高亮库存量最低的 10 种产品
highlighter.highlight_bottom_values(0, "D2:D200", 10, Color.get_Yellow())
# 高亮重复的产品编号
highlighter.highlight_duplicates(0, "A2:A200")
highlighter.save("./Output/InventoryReview.xlsx")最佳实践与注意事项
选择合适的高亮方法
- 静态高亮 :使用
range.Style.Color直接设置背景色,适合一次性操作 - 动态高亮:使用条件格式化,适合数据可能变化的场景
颜色选择建议
- 警告/错误:使用红色或橙色系
- 成功/优秀:使用绿色或金色系
- 信息/中性:使用蓝色或黄色系
- 避免过多颜色:保持简洁,通常不超过 3-4 种颜色
性能考虑
- 限制应用范围:只在必要的单元格范围应用条件格式化
- 避免过度嵌套:不要在同一范围应用过多的条件格式化规则
- 及时释放资源 :操作完成后调用
Dispose()方法
常见问题与解决方案
问题 1:高亮颜色不明显
解决方案:选择对比度高的颜色,或者同时设置字体颜色和背景颜色。
问题 2:条件格式化不生效
解决方案:检查单元格范围是否正确,确保数据类型匹配(文本 vs 数字)。
问题 3:文件体积过大
解决方案:减少条件格式化规则的数量,避免在大范围应用复杂的条件格式化。
总结
本文深入探讨了利用 Spire.XLS for Python 在 Excel 中查找并高亮显示数据的多种高效方法,旨在显著提升数据可视化与分析的效率。在实际应用中,开发者不仅可以通过 FindAllString() 方法精准定位特定文本并直接设置背景色进行高亮,还能利用条件格式化实现数据变化时的动态更新。针对更复杂的数据分析需求,该库提供了丰富的条件规则:例如通过 AddTopBottomCondition() 快速锁定排名前后的核心数值,利用 DuplicateValues 和 UniqueValues 自动识别重复或唯一的数据,以及借助 AddAverageCondition() 直观呈现高于或低于平均值的异常情况。此外,通过封装工具类,还能进一步实现更具灵活性的高亮操作与批量处理。全面掌握这些核心技能,将帮助你在数据审查、业务分析以及质量控制等实际应用场景中游刃有余,从而大幅提升日常工作效率与深度数据洞察力。