如果你的 AI 助手每次对话都像失忆一样从零开始,这篇文章就是为你写的。
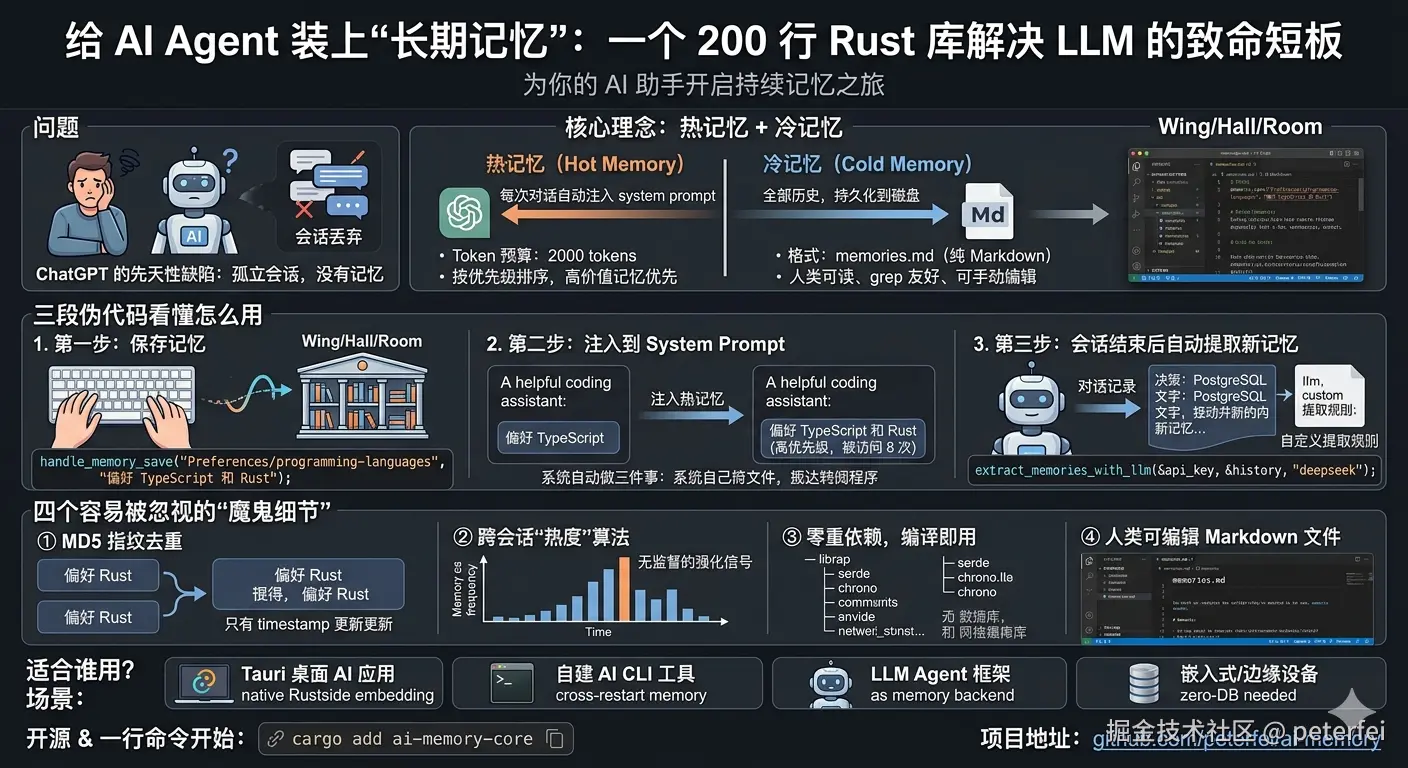
一、ChatGPT 那么强,为什么它还是记不住你?
试过让 GPT 帮你连续写代码吗?第二天打开,它又问你"请提供项目背景"。这不是 GPT 不聪明,而是所有大语言模型(LLM)都有一个先天性缺陷 :每次对话都是孤立会话,没有记忆。
市面上的解决方案五花八门------LangChain 的 Memory 模块、Mem0、Zep、Letta------但它们大多笨重,不是强依赖 Python 生态就是绑定了特定框架。做 Rust 技术栈的 Tauri 应用、嵌入式 Agent,或者需要一个零重依赖、即时可用的记忆系统?选择很少。
于是我写了个开源库:ai-memory-core。核心代码不到 800 行,仅依赖 serde 几项 Rust 标配,却能提供完整的持久化记忆能力。
二、核心理念:热记忆 + 冷记忆
我把记忆拆成两层:
scss
┌────────────────────────────────┐
│ 热记忆 (Hot Memory) │ ← 每次对话自动注入 system prompt
│ Token 预算:2000 tokens │ 按优先级排序,高价值记忆优先
├────────────────────────────────┤
│ 冷记忆 (Cold Memory) │ ← 全部历史,持久化到磁盘
│ 格式:memories.md (纯 Markdown) │ 人类可读、grep 友好、可手动编辑
└────────────────────────────────┘热记忆 丢进 LLM 上下文窗口,让 AI 每次对话都知道你的偏好和项目背景。冷记忆落盘,永远不会丢。
冷记忆的存储用了纯 Markdown 文件 ------对,就是 .md 文件。不是 SQLite,不是向量数据库,不是 Redis。你可以用 VS Code 打开 memories.md 直接看、直接改。极致简单。
三、三段伪代码看懂怎么用
第一步:保存记忆
rust
use ai_memory_core::handle_memory_save;
// 空间路径 + 内容,就这么简单
handle_memory_save("Preferences/programming-languages", "偏好 TypeScript 和 Rust")?;
handle_memory_save("Decisions/database-choice", "生产环境使用 PostgreSQL")?;路径结构是 Wing/Hall/Room 三层分类------想象成图书馆的"馆/厅/室"------让记忆有组织地生长,而不是扔进一个扁平列表。
第二步:注入到 System Prompt
rust
use ai_memory_core::inject_memories_into_system_prompt;
let prompt = "You are a helpful coding assistant.";
let enriched = inject_memories_into_system_prompt(prompt);
// 输出变成了:
// "You are a helpful coding assistant.
// [USER_MEMORY]
// 偏好 TypeScript 和 Rust (高优先级, 被访问 8 次)
// 生产环境使用 PostgreSQL
// [/USER_MEMORY]"系统自动做了三件事:① 加载全部记忆 ② 按"访问频次×是否为高价值记忆"排序 ③ 控制在 2000 token 预算内。你不需要手动截断。
第三步:会话结束后自动提取新记忆
rust
use ai_memory_core::extract_memories_with_llm;
// 传 API Key + 对话记录 + 模型提供商
let count = extract_memories_with_llm(
&api_key,
&conversation_history,
"deepseek" // 也支持 anthropic / openai
).await?;
println!("本次会话提取了 {count} 条新记忆");LLM 会自动从对话中识别偏好、决策、知识,并写进对应的 Memory Hall。你可以在 prompts/memory/extract.md 里自定义提取规则,修改后立即生效,不需要重新编译。
四、三个容易被忽视的"魔鬼细节"
① MD5 指纹去重
相同内容的记忆不会被重复写入,只更新日期。不是靠标题或 ID,是靠内容哈希。你写"偏好 TypeScript"和上次一样,它就只刷时间戳。
② 跨会话"热度"算法
每条记忆背后有一个 MetadataStore,记录访问次数。如果一个偏好被引用了 5 次以上,系统自动标记为"高价值",下次注入更靠前。这本质上是一个无监督的强化信号 ------不是你告诉系统什么重要,而是系统从使用模式中自己学会。
③ 零重依赖,编译即用
核心依赖列表:serde、serde_json、chrono、dirs、md-5。没有 async runtime(除非你开 llm-extraction feature)、没有数据库 driver、没有网络库。编译时间以秒计,二进制增量极小。
五、适合谁用?
| 场景 | 为什么合适 |
|---|---|
| Tauri 桌面 AI 应用 | Rust 原生,直接嵌入 sidecar |
| 自建 AI CLI 工具 | 会话记忆自动持久化,跨重启保留 |
| LLM Agent 框架 | 作为 Memory Backend 接入 Agent 生命周期 |
| 嵌入式/边缘设备 | 零数据库依赖,Markdown 文件即可 |
六、开源 & 一行命令开始
bash
cargo add ai-memory-core
# 如果需要 LLM 自动提取:
cargo add ai-memory-core --features llm-extraction项目地址:github.com/peterfei/ai...
写这个库的初心很简单:AI 应该有记忆,而实现记忆不应该引入一整套基础设施。一个 Markdown 文件 + 几百行 Rust 代码,足够了。
如果你也在做 AI Agent 方向的产品,欢迎试用、提 Issue、提 PR。让 AI 不再"失忆",从这一行 Cargo.toml 开始。
标签:#AI编程 #Rust #LLM #开源工具 #AI记忆系统 #Agent开发