摘要:在金融行业,客户投诉、监管公告、合同文本等非结构化数据蕴含着巨大的业务价值。传统方案需要将数据导出到外部 NLP 系统处理,链路长、延迟高且存在数据泄露风险。本文中的最佳实践介绍了如何利用 StarRocks AI Function,通过纯 SQL 实现情感分析、智能分类、信息抽取和 PII 脱敏,实现"数据不出库"的端到端智能分析。
对于数据和 AI 开发者而言,处理非结构化文本一直是个痛点。尤其是在金融场景下,合规要求极高,用户往往面临这样的困境:
-
链路割裂:数据在 StarRocks/MySQL 中,NLP 模型在 Python 服务或第三方 API 中。数据需要反复搬运(Export -> Process -> Import)。
-
延迟高昂:实时舆情监控或即时客服辅助,无法容忍分钟级的批处理延迟。
-
安全风险:将包含 PII(个人敏感信息)的客户工单或合同发送给外部大模型,合规风险极大。
现在,只需写一条 SQL,用户就能直接在数据库引擎内完成情感分析、关键要素提取甚至合规脱敏。这就是 StarRocks AI Function 带来的变革。它让 LLM 能力像 SUM() 或 COUNT() 一样,成为 SQL 的一部分。
核心能力
StarRocks AI Function 提供了一系列内置函数,覆盖金融场景的核心需求:
| 函数 | 功能 | 金融场景应用 |
|---|---|---|
ai_sentiment(text) |
情感分析 | 客户反馈/舆情监控 |
ai_classify(text, categories) |
文本分类 | 工单分类/监管公告分类 |
ai_extract(text, labels) |
信息抽取 | 合同关键要素提取 |
ai_redact(text) |
PII 脱敏 | 客户信息合规处理 |
ai_summarize(text) |
文本摘要 | 研报/公告摘要 |
ai_filter(text, condition) |
语义过滤 | 风险文本筛查 |
ai_complete(prompt, instruction) |
自定义分析 | 复杂金融推理 |
方案优势
StarRocks AI Function 并非简单的函数封装,而是基于数据库内核深度优化的智能计算引擎。相较于传统"数据导出 + 外部脚本调用"的方案,它在以下四个维度实现了代际优势:
-
架构革新(高并发): 摒弃传统的同步阻塞模型,采用独有的异步双 Pipeline + bthread 协作机制。线程在等待 LLM响应时主动让出 CPU,以极少的系统线程(默认4个)即可驱动数百并发请求,彻底解决 OS 线程调度瓶颈。
-
性能突破(低延迟): 通过 SQL 优化器实现谓词下推,仅在必要数据行上调用 LLM;结合内存级 LRU 缓存,相同 Prompt 毫秒级返回且零 Token 消耗。实测端到端延迟降低 40%,并发能力提升 3-5 倍。
-
成本最优(精算账): 内置三层自适应限流与智能重试,避免无效调用浪费;自动注入用户 UID 实现精确分账,让每一分 AI 投入都清晰可控,综合 Token 费用降低 30%+。
-
安全合规(不出库): 数据在 StarRocks 引擎内原地完成分析,无需 ETL 搬运至外部 Python 服务或第三方 API,从物理架构上杜绝了金融敏感数据(PII)的泄露风险。
方案流程
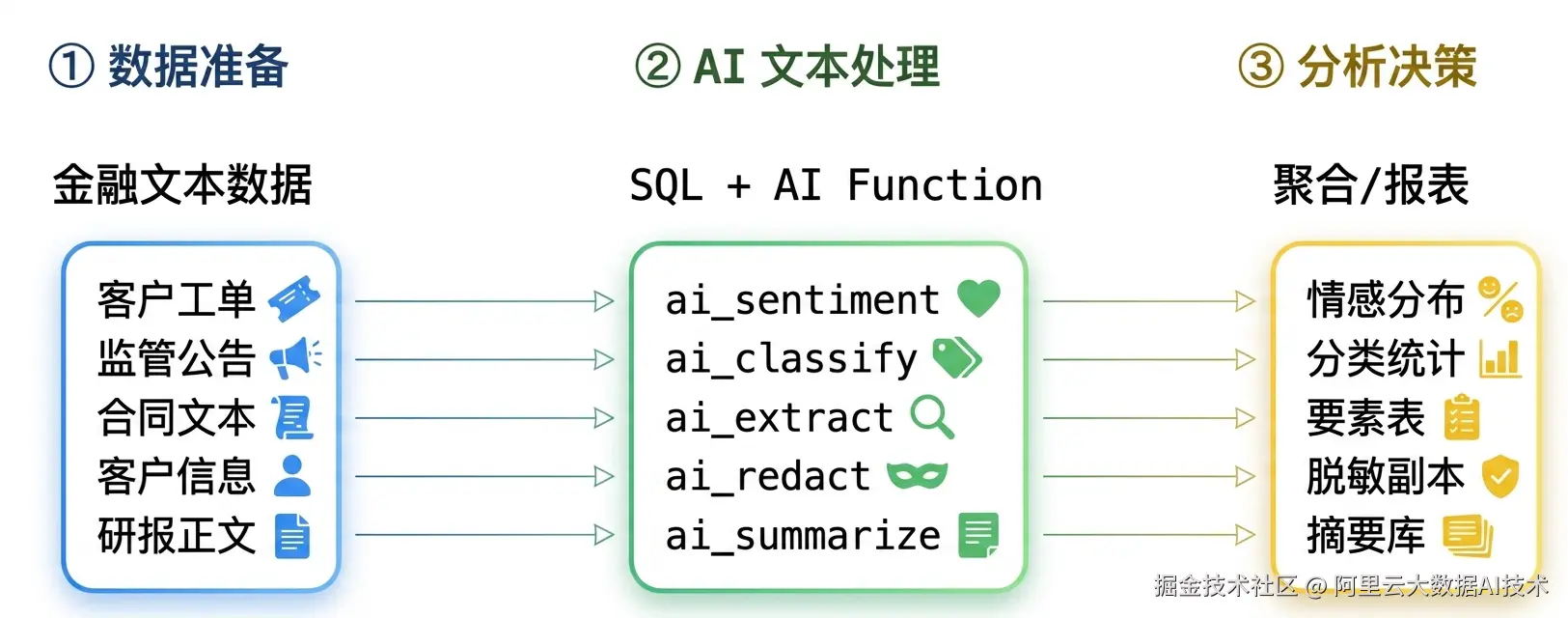
全程数据不出库,SQL 完成端到端处理
准备工作
环境要求
-
EMR Serverless StarRocks Stella 2.1 及以上版本(支持 AI Function)
-
已开通 AI 中心
-
已开启公网
数据准备
本实践模拟金融场景中的五类典型文本数据,创建示例表并写入样本数据。
1. 客户服务工单表
sql
CREATE TABLE fin_customer_tickets (
ticket_id BIGINT,
customer_id VARCHAR(20),
channel VARCHAR(10) COMMENT '渠道:app/web/phone/branch',
product_type VARCHAR(20) COMMENT '产品类型:credit_card/loan/deposit/fund/insurance',
ticket_text VARCHAR(65533) COMMENT '工单内容',
created_at DATETIME
)
DUPLICATE KEY(ticket_id)
DISTRIBUTED BY HASH(ticket_id) BUCKETS 8;
INSERT INTO fin_customer_tickets VALUES
(1001, 'C20240001', 'app', 'credit_card',
'你们这个信用卡账单又出错了!上个月明明还了8000块,结果账单显示还欠5000,这是第三次了!再搞不定我就要投诉到银保监了!', '2026-05-01 09:15:00'),
(1002, 'C20240002', 'phone', 'loan',
'想咨询一下房贷提前还款的流程,需要准备哪些材料?还有提前还款有没有违约金?', '2026-05-01 10:30:00'),
(1003, 'C20240003', 'web', 'fund',
'你们推荐的那个稳健型基金,一个月亏了15%,这叫稳健?我要求赔偿!基金经理是不是在乱操作?', '2026-05-01 11:45:00'),
(1004, 'C20240004', 'app', 'deposit',
'大额存单到期自动续存的功能很方便,利率也还行,比之前高了0.1个百分点,整体体验不错', '2026-05-01 14:00:00'),
(1005, 'C20240005', 'branch', 'insurance',
'保险理赔太慢了,住院花了3万块,提交材料都两个月了还没给结果。催了好几次客服就说在审核中。', '2026-05-01 15:20:00'),
(1006, 'C20240006', 'app', 'credit_card',
'刚开通的白金卡权益不错,机场贵宾厅很舒服,积分兑换也比较划算,推荐给朋友了', '2026-05-01 16:00:00'),
(1007, 'C20240007', 'phone', 'loan',
'车贷每月还款日能不能改一下?现在是5号扣款,但我工资15号才发,每个月都很紧张', '2026-05-02 09:00:00'),
(1008, 'C20240008', 'web', 'fund',
'定投了半年的指数基金,收益还可以,目前年化大概8%左右,准备继续持有', '2026-05-02 10:15:00');2. 监管公告与新闻表
sql
CREATE TABLE fin_regulatory_news (
news_id BIGINT,
source VARCHAR(50) COMMENT '来源机构',
publish_date DATE,
title VARCHAR(500),
content VARCHAR(65533) COMMENT '正文内容'
)
DUPLICATE KEY(news_id)
DISTRIBUTED BY HASH(news_id) BUCKETS 4;
INSERT INTO fin_regulatory_news VALUES
(2001, '中国人民银行', '2026-04-28',
'关于加强金融消费者权益保护工作的通知',
'为进一步加强金融消费者权益保护,规范金融机构经营行为,根据《中华人民共和国消费者权益保护法》等法律法规,现就有关事项通知如下:一、金融机构应当建立健全消费者权益保护工作机制,设立专门部门或岗位负责消费者权益保护工作。二、金融机构在营销宣传、产品销售过程中,应当充分揭示产品风险,不得进行虚假或引人误解的宣传。三、金融机构应当畅通投诉渠道,及时处理消费者投诉,处理时限不得超过15个工作日。'),
(2002, '中国银保监会', '2026-04-25',
'关于规范信贷资金用途的监管要求',
'近期检查发现部分银行信贷资金违规流入房地产市场和股票市场。现要求:各银行业金融机构应加强贷后管理,确保信贷资金用于约定用途。对于经营性贷款,应核实借款人真实经营需求,防止资金挪用。违规机构将面临监管处罚,包括但不限于罚款、限制业务范围等措施。'),
(2003, '中国证监会', '2026-04-20',
'关于进一步规范上市公司信息披露的若干意见',
'为提升上市公司信息披露质量,保护投资者合法权益,现提出以下意见:上市公司应当真实、准确、完整、及时地披露信息,不得有虚假记载、误导性陈述或者重大遗漏。鼓励上市公司自愿披露与投资者决策相关的信息,提高信息透明度。'),
(2004, '中国人民银行', '2026-04-15',
'2026年第一季度货币政策执行报告',
'2026年第一季度,稳健的货币政策精准有力。3月末,广义货币M2余额同比增长8.2%。人民币贷款余额同比增长10.5%,社会融资规模存量同比增长9.8%。利率市场化改革持续推进,企业贷款利率保持在较低水平。下一阶段将继续实施稳健的货币政策,保持流动性合理充裕。');3. 合同/协议文本表
sql
CREATE TABLE fin_contracts (
contract_id VARCHAR(30),
contract_type VARCHAR(20) COMMENT '合同类型:loan/guarantee/pledge',
party_a VARCHAR(200),
party_b VARCHAR(200),
contract_text VARCHAR(65533) COMMENT '合同关键条款'
)
DUPLICATE KEY(contract_id)
DISTRIBUTED BY HASH(contract_id) BUCKETS 4;
INSERT INTO fin_contracts VALUES
('LOAN-2026-0001', 'loan', '某某银行股份有限公司杭州分行', '杭州星辰科技有限公司',
'贷款金额:人民币伍佰万元整(¥5,000,000.00)。贷款期限:自2026年1月15日起至2027年1月14日止,共计12个月。贷款利率:按照LPR加60个基点执行,即年利率4.15%。还款方式:等额本息,每月20日为还款日。违约条款:借款人未按时还款的,应按逾期金额每日万分之五支付罚息。担保方式:以借款人名下位于杭州市西湖区XX路XX号房产提供抵押担保。'),
('LOAN-2026-0002', 'loan', '某某银行股份有限公司上海分行', '上海锦绣贸易有限公司',
'贷款金额:人民币壹仟万元整(¥10,000,000.00)。贷款期限:自2026年3月1日起至2028年2月28日止,共计24个月。贷款利率:固定利率年4.35%。还款方式:先息后本,每季度末支付利息,到期一次性归还本金。违约条款:借款人连续三期未还息或挪用贷款资金的,贷款人有权宣布贷款提前到期。担保方式:由上海锦绣集团有限公司提供连带责任保证担保。'),
('GUAR-2026-0001', 'guarantee', '某某银行股份有限公司杭州分行', '浙江鑫达实业集团有限公司',
'保证方式:连带责任保证。保证范围:主债权本金人民币伍佰万元及利息、罚息、违约金、实现债权的费用。保证期间:自主债务履行期限届满之日起两年。保证人声明:保证人具有完全民事行为能力,愿意以其全部资产为上述债务提供连带责任保证。联系人:张伟,电话:13812345678,身份证号:330102198501153456。');应用场景
场景一:客户工单智能分析
1.1 情感分析------识别客户情绪
快速判断每条工单的客户情绪,优先处理负面反馈:
sql
SELECT
ticket_id,
product_type,
ai_sentiment(ticket_text) AS sentiment,
LEFT(ticket_text, 40) AS preview
FROM fin_customer_tickets
ORDER BY ticket_id;结果示例:
| ticket_id | product_type | sentiment | preview |
|---|---|---|---|
| 1001 | credit_card | negative | 你们这个信用卡账单又出错了!上个月明明还了8000块... |
| 1002 | loan | neutral | 想咨询一下房贷提前还款的流程,需要准备哪些材料... |
| 1003 | fund | negative | 你们推荐的那个稳健型基金,一个月亏了15%,这叫稳健... |
| 1004 | deposit | positive | 大额存单到期自动续存的功能很方便,利率也还行... |
| 1005 | insurance | negative | 保险理赔太慢了,住院花了3万块,提交材料都两个月了... |
| 1006 | credit_card | positive | 刚开通的白金卡权益不错,机场贵宾厅很舒服... |
1.2 工单智能分类------按业务类型自动归类
将自由文本工单自动归入预定义的业务类别:
sql
SELECT
ticket_id,
ai_classify(
ticket_text,
ARRAY['账单争议', '业务咨询', '投诉建议', '产品体验', '理赔纠纷']
) AS category,
ai_sentiment(ticket_text) AS sentiment
FROM fin_customer_tickets;1.3 情感分布分析------按产品维度聚合
将 AI 分析结果直接与 SQL 聚合分析结合:
sql
SELECT
product_type,
ai_sentiment(ticket_text) AS sentiment,
COUNT(*) AS ticket_count
FROM fin_customer_tickets
GROUP BY product_type, ai_sentiment(ticket_text)
ORDER BY product_type, ticket_count DESC;结果示例:
| product_type | sentiment | ticket_count |
|---|---|---|
| credit_card | negative | 1 |
| credit_card | positive | 1 |
| fund | negative | 1 |
| fund | positive | 1 |
| insurance | negative | 1 |
| loan | neutral | 2 |
| deposit | positive | 1 |
ChatBI 实时交互效果:在 ChatBI 中,业务人员只需输入"各产品线的客户情绪分布是怎样的?用堆叠柱状图展示",系统即自动生成上述 SQL 并渲染为可交互的堆叠柱状图------从提问到看到结果,全程无需编写任何代码。
1.4 语义过滤------筛查高风险工单
使用 ai_filter 在 WHERE 子句中按语义条件过滤,找出涉及监管投诉风险的工单:
sql
SELECT
ticket_id,
product_type,
ticket_text,
ai_sentiment(ticket_text) AS sentiment
FROM fin_customer_tickets
WHERE ai_filter(ticket_text, '客户威胁要向监管机构投诉或要求赔偿');
ai_filter返回 BOOLEAN,可直接用于 WHERE 子句,实现"用自然语言写过滤条件"。
ChatBI 风险筛查效果 :在 ChatBI 中追问"有多少高风险工单?占比多少?",系统结合 ai_filter 与聚合统计,直接返回数字卡片------7 条高风险工单,占比 23.3%。对于运营团队而言,这意味着可以在 IM 对话窗口中随时获取风险全局视图。
场景二:监管公告智能分类与摘要
2.1 公告分类
对监管公告按监管领域自动分类:
sql
SELECT
news_id,
source,
title,
ai_classify(
content,
ARRAY['消费者保护', '信贷监管', '信息披露', '货币政策', '反洗钱', '市场准入']
) AS reg_category
FROM fin_regulatory_news;ChatBI 分类可视化效果 :在 ChatBI 中提问"最近的监管公告按领域分类是什么分布",系统自动调用 ai_classify 并渲染为饼图。合规团队无需逐条阅读公告,一眼即可掌握监管动态的领域分布。
2.2 公告摘要
为长篇公告生成简短摘要,便于管理层快速浏览:
sql
SELECT
news_id,
title,
ai_summarize(content) AS summary
FROM fin_regulatory_news
WHERE publish_date >= '2026-04-01';2.3 合规影响分析
使用 ai_complete 进行更深层次的业务分析------判断公告对本行业务的影响:
sql
SELECT
news_id,
title,
ai_complete(
content,
'你是一名银行合规分析师。请分析这条监管公告对商业银行零售业务的具体影响,列出需要整改的要点,限100字以内。'
) AS compliance_impact
FROM fin_regulatory_news
WHERE ai_filter(content, '涉及银行业务合规要求或处罚措施');场景三:合同关键信息抽取
3.1 合同要素提取
从合同文本中自动抽取结构化的关键信息:
sql
SELECT
contract_id,
contract_type,
ai_extract(
contract_text,
ARRAY['贷款金额', '贷款期限', '年利率', '还款方式', '担保方式', '违约条款']
) AS key_elements
FROM fin_contracts
WHERE contract_type = 'loan';结果示例(JSON 格式):
json
{
"贷款金额": "人民币伍佰万元整(¥5,000,000.00)",
"贷款期限": "2026年1月15日至2027年1月14日,共计12个月",
"年利率": "LPR加60个基点,即4.15%",
"还款方式": "等额本息,每月20日还款",
"担保方式": "杭州市西湖区房产抵押担保",
"违约条款": "逾期按每日万分之五支付罚息"
}3.2 合同 PII 脱敏
对包含个人敏感信息的合同文本进行脱敏处理,满足数据合规要求:
sql
SELECT
contract_id,
ai_redact(contract_text) AS redacted_text
FROM fin_contracts
WHERE contract_type = 'guarantee';脱敏效果:
plaintext
原文:联系人:张伟,电话:13812345678,身份证号:330102198501153456
脱敏后:联系人:张**,电话:138****5678,身份证号:330102********34563.3 合同风险评估
结合 ai_extract 和 ai_complete 构建合同风险评估管线:
sql
WITH contract_elements AS (
SELECT
contract_id,
party_a,
party_b,
contract_text,
ai_extract(
contract_text,
ARRAY['贷款金额', '年利率', '担保方式', '违约条款']
) AS elements
FROM fin_contracts
WHERE contract_type = 'loan'
)
SELECT
contract_id,
party_b,
elements,
ai_complete(
CONCAT('合同要素:', CAST(elements AS VARCHAR), '\n\n合同原文:', contract_text),
'你是信贷风控专家。请基于合同要素评估该笔贷款的风险等级(低/中/高),并给出主要风险点,限80字。'
) AS risk_assessment
FROM contract_elements;场景四:综合分析管线
4.1 客户 360 文本分析看板
将多个 AI 函数组合,构建客户反馈的多维分析视图:
sql
SELECT
ticket_id,
customer_id,
product_type,
channel,
ai_sentiment(ticket_text) AS sentiment,
ai_classify(
ticket_text,
ARRAY['账单争议', '业务咨询', '投诉建议', '产品体验', '理赔纠纷']
) AS category,
ai_extract(
ticket_text,
ARRAY['涉及金额', '诉求']
) AS key_info,
ai_summarize(ticket_text) AS summary
FROM fin_customer_tickets
WHERE created_at >= '2026-05-01';当 AI 分析结果通过物化视图或 ETL 管线持久化后,即可接入 QuickBI 构建实时看板。下图展示了一个典型的客户工单分析 Dashboard------情感分布、分类 Top 5、风险等级、每日趋势四个视图联动,管理层打开看板即可获得客户反馈的 360 度全景视图。 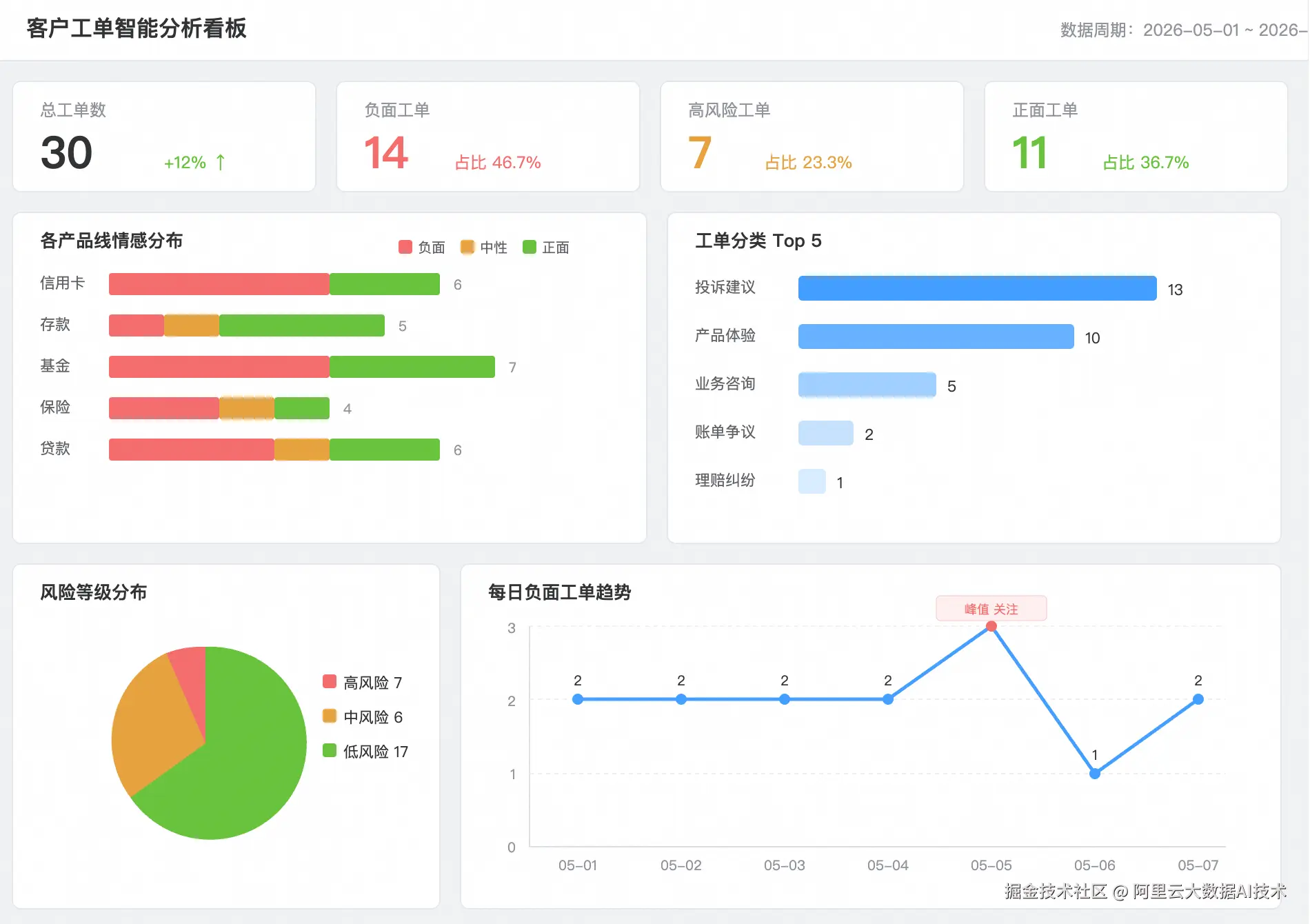
4.2 基于 AI 分析结果构建物化视图
将 AI 分析结果持久化,避免重复计算:
sql
CREATE MATERIALIZED VIEW mv_ticket_analysis AS
SELECT
ticket_id,
customer_id,
product_type,
channel,
created_at,
ai_sentiment(ticket_text) AS sentiment,
ai_classify(
ticket_text,
ARRAY['账单争议', '业务咨询', '投诉建议', '产品体验', '理赔纠纷']
) AS category
FROM fin_customer_tickets;后续查询直接基于物化视图,无需重复调用 AI 函数:
sql
-- 每日负面情感工单量趋势
SELECT
DATE(created_at) AS dt,
product_type,
COUNT(*) AS negative_tickets
FROM mv_ticket_analysis
WHERE sentiment = 'negative'
GROUP BY DATE(created_at), product_type
ORDER BY dt, negative_tickets DESC;ChatBI 趋势追踪效果:业务人员在 ChatBI 中提问"最近 7 天每天的负面工单数量趋势",系统直接查询物化视图并渲染为折线图。从数据入库到 AI 分析到可视化呈现,全链路在 StarRocks 引擎内闭环完成,数据不出库、分析零代码。
4.3 ETL 管线集成:INSERT INTO SELECT
将 AI 处理结果写入下游分析表,构建完整的数据加工管线:
sql
-- 创建分析结果表
CREATE TABLE fin_ticket_analysis_result (
ticket_id BIGINT,
customer_id VARCHAR(20),
product_type VARCHAR(20),
sentiment VARCHAR(20),
category JSON,
key_info JSON,
summary VARCHAR(65533),
analyzed_at DATETIME DEFAULT CURRENT_TIMESTAMP
)
DUPLICATE KEY(ticket_id)
DISTRIBUTED BY HASH(ticket_id) BUCKETS 4;
-- 批量 AI 分析并写入结果表
INSERT INTO fin_ticket_analysis_result
(ticket_id, customer_id, product_type, sentiment, category, key_info, summary)
SELECT
ticket_id,
customer_id,
product_type,
ai_sentiment(ticket_text),
ai_classify(ticket_text, ARRAY['账单争议', '业务咨询', '投诉建议', '产品体验', '理赔纠纷']),
ai_extract(ticket_text, ARRAY['涉及金额', '诉求']),
ai_summarize(ticket_text)
FROM fin_customer_tickets
WHERE ticket_id NOT IN (SELECT ticket_id FROM fin_ticket_analysis_result);最佳实践建议
为了在性能和成本之间取得平衡,建议遵循以下原则:
| 建议 | 说明 |
|---|---|
| 优先使用专用函数 | ai_sentiment 比 ai_complete('分析情感...') 更快、更稳定、成本更低 |
| 批量处理用 INSERT INTO SELECT | 避免逐行调用 AI 函数,批量写入结果表后再查询 |
| 结果持久化 | 对不变文本的 AI 分析结果应写入结果表或物化视图,避免重复计算 |
| ai_filter 用于预筛 | 先用 ai_filter 缩小范围,再对筛选后的小结果集调用重量级函数 |
| 注意 Token 消耗 | 长文本(如合同全文)单次调用 Token 较高,可先 ai_summarize 再分析 |
| 分类标签标准化 | ai_classify 的 categories 参数建议使用业务统一的标签体系 |
总结
StarRocks AI Function 为金融行业提供了一条"数据不出库、分析零代码"的非结构化数据处理新范式。通过 ai_sentiment、ai_classify、ai_extract 等专用函数,企业无需搭建昂贵且复杂的外部 NLP 服务集群,即可在 SQL 层面直接实现客户情感洞察、工单智能路由、合同要素抽取及 PII 合规脱敏。
本方案的核心竞争力在于其创新的底层架构与内核级的成本优化能力,彻底超越了传统脚本方案:
-
架构级的高并发突破: 基于 StarRocks 独有的异步双 Pipeline + bthread 协作模型,解决了传统同步阻塞模型在高并发下的资源瓶颈。仅需 4 个线程即可驱动数百个 LLM 并发请求,资源利用率远超进程式脚本,实现了"小算力驱动大智能"。
-
显著的成本节约与安全闭环: 结合 LRU 结果缓存与 SQL 谓词下推技术,自动过滤无关数据并消除重复计算,实测 Token 消耗降低 30% 以上。同时,数据全程在引擎内原地处理,从物理架构上杜绝了敏感数据外传的泄露风险,完美契合金融合规要求。
-
工业级的稳定体验: 内置三层自适应限流机制(完美兼容阿里云百炼等主流模型服务的非标行为),配合行级容错与智能重试策略,确保百万级数据批量处理时的"零中断"。完善的 Profile 监控能力让性能调优有据可依,告别黑盒运维。
性能实证: 在同等硬件资源下,StarRocks AI Function 的端到端处理延迟较传统"ETL 导出 + Python 外部服务"架构降低约 40%,并发处理能力提升 3-5 倍,轻松支撑千万级日均工单的实时智能分析需求。
StarRocks AI Function 不仅是一组函数,更是企业构建实时、安全、低成本智能数据底座的关键基础设施。建议用户先在测试环境验证效果,随后逐步推广至生产环境,释放非结构化数据的巨大业务价值。
注:AI Function 计费详情请阅读全文参阅 EMR AI Function 定价文档