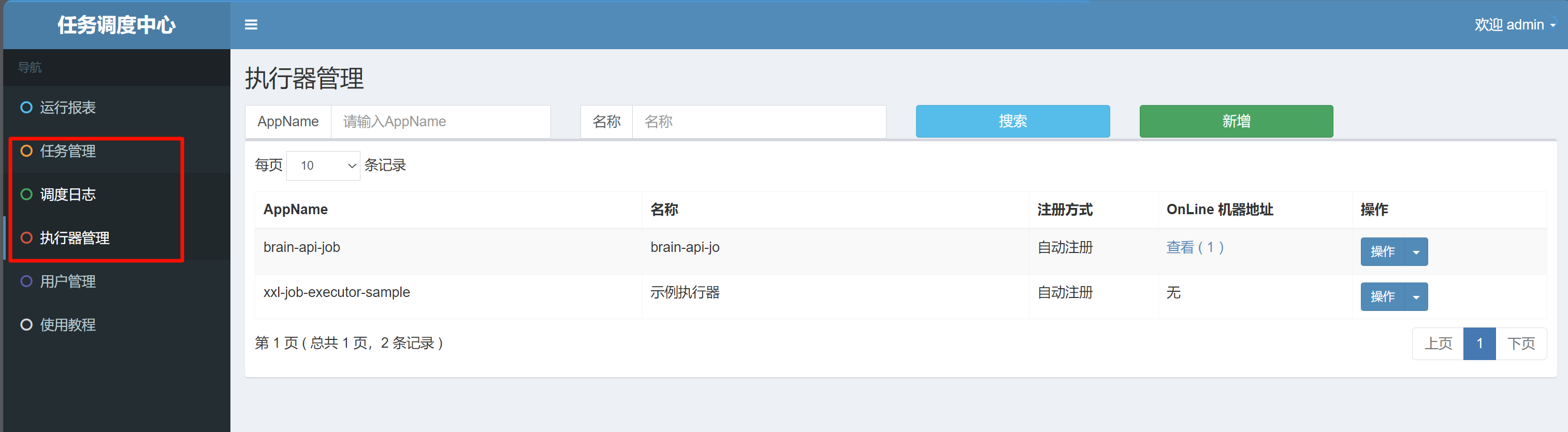
1)XXL-JOB里那三样东西
调度中心(xxl-job-admin):网页后台 + 任务配置的地方。它负责"按时/按需叫人干活"。
执行器(Executor):干活的人(你的 brain-api-job 容器)。它在 9999 端口等着被调度中心喊去干活。
任务(Job):一条"让执行器做什么"的配置记录(比如"跑报告生成")。
一句话:任务属于调度中心,干活在执行器里。
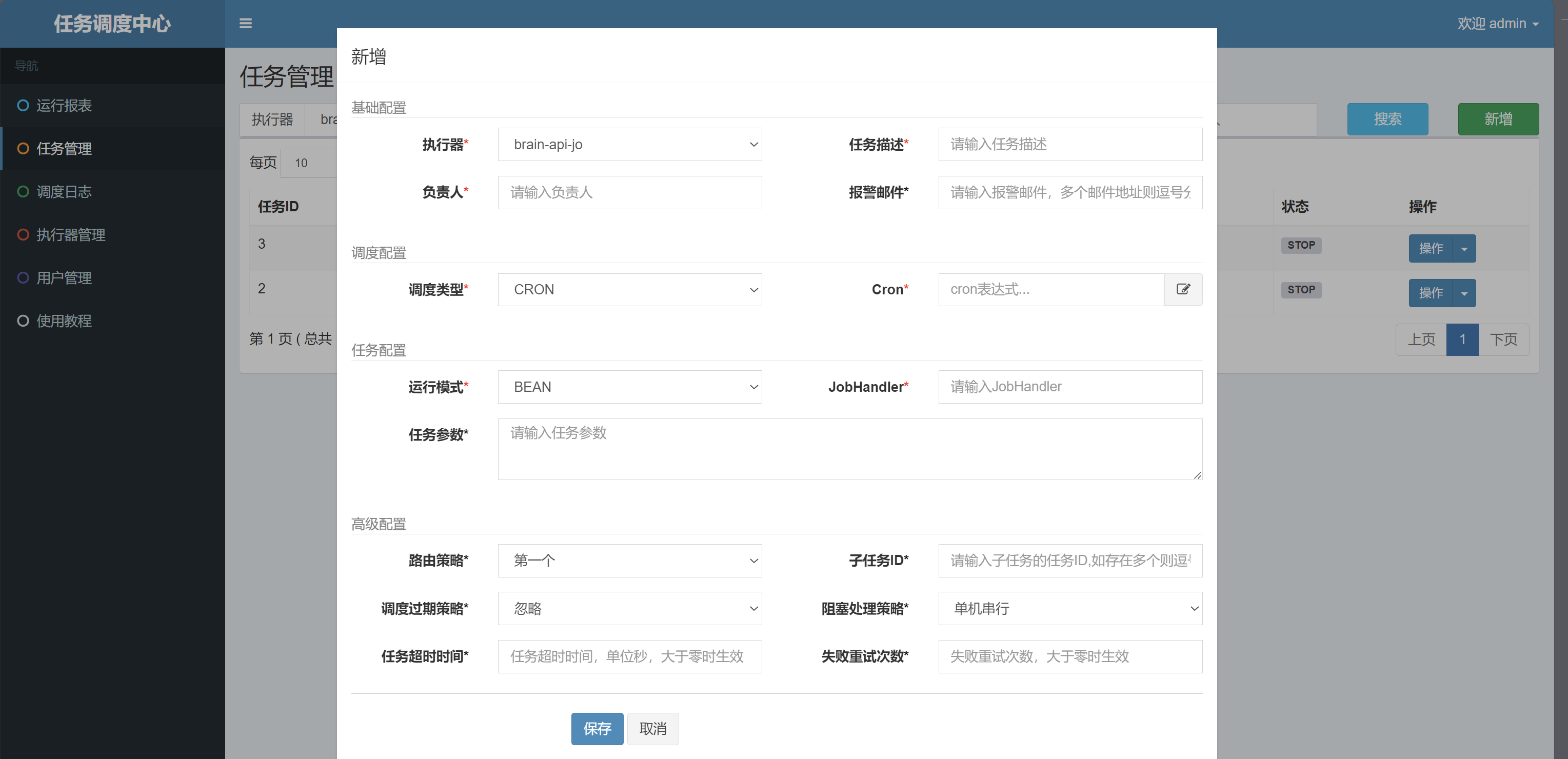
2)新增任务里常见参数的意思
- 执行器(brain-api-job)
选"把任务派给哪一类工人"(哪个服务来跑) - 运行模式:BEAN
意思是"执行器里用Spring Bean的方式找 handler"(也就是用 @XxlJob("xxx") 这种)
项目就是用这个,所以固定选它 - 调度类型:CRON
定时器,按生产环境具体配置。 - 路由策略:第一个
如果一个执行器下面未来会有多台机器在线(多实例),这个决定"派给哪台"
现在你只有 1 台,所以选啥都一样;"第一个"最简单 - 阻塞处理策略:单机串行
如果上一次还没跑完,又来了一次触发,怎么办?
"单机串行"=排队一个个来,不会同一台机器并发跑同一个任务(最稳妥) - 任务超时时间:0
0 通常表示不单独设置超时 - 失败重试次数:0
失败不自动重试;学习阶段先 0,避免失败后反复刷日志
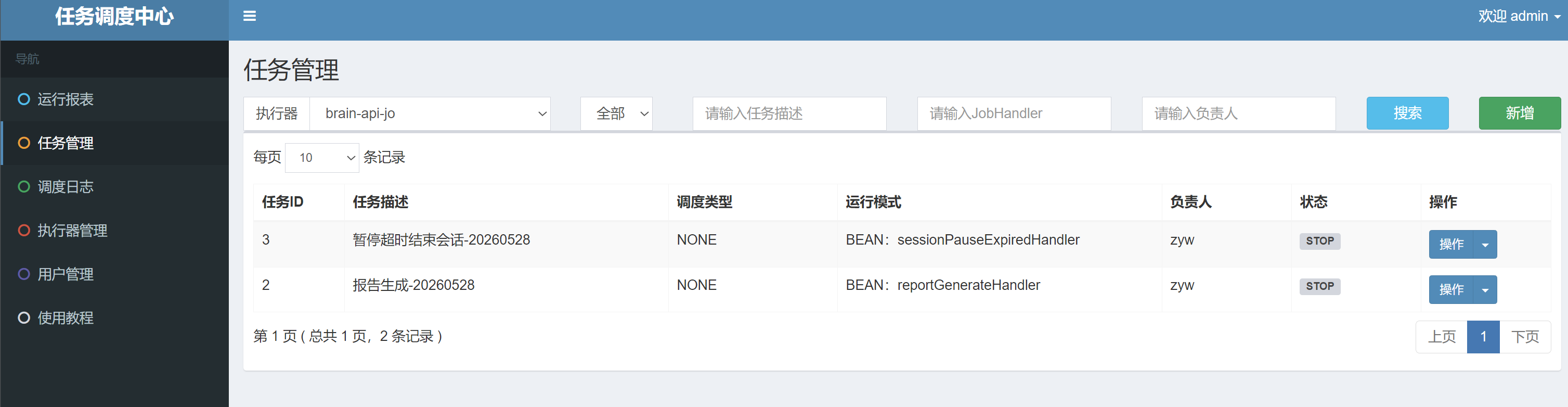
3)JobHandler
JobHandler 本质就是"函数名/入口名"
代码里就是这样写的:
@XxlJob("reportGenerateHandler")
@XxlJob("sessionPauseExpiredHandler")
4)点"执行一次"弹窗里,"任务参数"和"机器地址"填什么
机器地址=派给哪台机器干;任务参数=这次干活要带的口令/附加说明。
- 机器地址
选的是自动注册,一般不用自己填,它会从在线地址列表里挑一台(日志里就是 http://172.20.0.10:9999/)
只有在"手动录入地址/固定某台机器"这种场景才需要选/填 - 任务参数(JobParam/任务参数)
就是一段字符串,调度中心会原样传给 handler
只有handler 代码里读取了参数,这个才有用
我现在学习用的是报告生成 / 暂停超时,从代码看是"扫表处理",通常 不需要参数,所以留空就对了
5)生产环境(prod)应该怎么配"执行器和任务"?
① 执行器(分组/AppName)
生产也建一个执行器分组,AppName 一定要和代码里一致(默认就是 brain-api-job)
如果生产也跑一份 job 服务(通常会),它会自动注册地址(多台就会出现多个地址)
② 任务(Job)
把你需要的任务都建成记录(和dev一样),JobHandler 仍然填那段英文
生产差别主要在两点:
调度类型从 NONE 改为 CRON
路由策略如果有多台实例,建议用"轮询/一致性哈希/故障转移"等(先用"轮询"也行)
③ 一个关键原则
一个 JobHandler 对应一条任务配置(不要把两个 handler 写到一个任务里)
每条任务的"责任"越单一越好(出问题好定位)