文档说明
Kafka 全套学习知识手册(入门 → 源码 → 运维 → 面试 → 实战):
本文档整合 Kafka 基础、核心原理、高阶特性、客户端开发、运维调优、故障排查、架构设计、安全、生态、面试考点全体系内容,适用于开发、运维、架构师、面试备考,为企业生产级完整学习资料。
第一部分 基础认知与环境入门
1.1 定位与应用场景
1. 核心定位
Apache Kafka 是一款分布式、分区化、多副本持久化的实时流式事件平台 ,并非单纯的消息队列,是大数据架构、分布式微服务架构的核心中间件,兼具消息收发、实时数据流传输、事件存储、流式计算调度四大核心能力。依托磁盘顺序写、操作系统页缓存、零拷贝、批量处理、数据压缩五大核心技术,突破了传统消息队列吞吐瓶颈,主打超高吞吐、低延迟、高可用、可回溯、可持久化的核心特性,是目前业界主流的实时数据总线标准。
一、核心能力精准拆解
-
消息队列能力:实现业务异步解耦、流量削峰、事件分发,适配微服务异步通信场景,替代传统点对点消息队列;
-
实时数据总线能力:作为企业全域数据流转中枢,统一汇聚业务日志、用户行为、数据库增量数据、设备时序数据,实现多源数据统一分发;
-
持久化存储能力:消息落地磁盘持久化保存,支持自定义过期清理策略,支持历史数据回溯、重放,具备短时时序数据存储能力;
-
流式计算底座能力:对接 Flink、Spark 等实时计算引擎,作为流式计算的标准数据源和数据输出载体,支撑实时分析、实时聚合、实时风控等场景。
二、技术内核核心优势(区别于其他中间件)
-
存储设计差异化:摒弃内存存储为主的设计,以磁盘顺序读写为核心,规避随机IO开销,单机吞吐可达百万级 TPS,远超传统消息队列;
-
架构天然分布式:分区、副本、集群横向扩容无瓶颈,支持超大流量、海量数据场景,适配互联网、大数据高并发业务;
-
数据可回溯性:不主动删除消息,仅按策略清理,支持任意时间、任意位移回溯消费,适配数据修复、业务重跑、故障复盘场景;
-
生态高度闭环:自带流处理组件,无缝对接大数据全栈生态,是唯一兼顾业务消息、大数据流式场景的通用中间件。
三、精准定位区分(避坑认知)
Kafka 不主打 复杂路由、精准延时、强事务一致性、即时消息投递,因此不适合核心金融交易、精准延时任务、复杂消息路由场景;其核心赛道为高吞吐流式数据处理、海量日志采集、全域数据同步、大规模异步事件分发,是大数据实时架构的基石组件。
2. 典型业务场景
(1)日志集中采集与运维监控(核心运维场景)
统一收集服务端日志、Nginx反向代理日志、网关访问日志、系统运行报错日志、容器运行日志,替代传统分散的本地日志存储方案。通过Filebeat、Fluent Bit等工具实时采集推送至Kafka,再流转至ELK、ClickHouse等组件,实现日志实时检索、异常告警、链路排查、故障溯源,是分布式系统日志观测的核心底座,解决微服务架构下日志分散、排查困难的痛点。
(2)用户行为埋点与数据分析(互联网主流场景)
承接APP、小程序、Web端的全量用户行为数据,包括页面曝光、点击事件、浏览时长、跳转行为、下单、收藏、分享等埋点数据。Kafka高吞吐特性可承载瞬时海量埋点流量,避免前端上报阻塞业务,后续对接实时计算引擎完成用户画像统计、热点功能分析、留存转化率计算、精准推荐、运营数据分析,支撑产品迭代与精细化运营。
(3)数据库数据同步与异构流转(数据中台核心)
结合Canal、Debezium等中间件,实时监听MySQL、PostgreSQL等数据库的Binlog增量日志,将数据新增、更新、删除操作实时同步至Kafka。实现跨系统数据异构同步,适配数据库分库分表、数据迁移、数据备份、业务解耦场景,可同步至ES、数据仓库、缓存、下游业务服务,实现数据库与下游系统的数据实时联动,保障数据一致性与实时性。
(4)实时流式计算与业务决策(实时业务核心)
作为Flink、Spark Streaming、Kafka Streams等实时计算引擎的标准数据源与数据出口,承接各类实时数据流。支持实时聚合统计、实时UV/PV计算、实时风控、订单实时监控、交易异常拦截、实时报表展示等业务,毫秒级延迟满足互联网实时业务诉求,是大数据实时计算架构的核心传输载体。
(5)流量削峰填谷与瞬时流量缓冲(高并发场景必备)
针对电商秒杀、整点秒杀、限时活动、优惠券发放、节日流量峰值等瞬时高并发场景,利用Kafka高吞吐、可堆积的特性,承接前端瞬时爆发流量。将同步高并发请求转换为异步平稳流量,缓冲流量峰值,避免瞬时流量直接打垮后端数据库与业务服务,保护系统稳定性,下游匀速消费处理业务请求,实现流量削峰、系统兜底。
(6)微服务异步解耦与非核心业务剥离(架构优化场景)
拆分业务核心链路与非核心异步链路,将消息通知、短信推送、邮件发送、积分发放、日志记录、业务埋点、数据统计等非实时、非核心业务剥离至Kafka异步处理。缩短核心业务接口响应时长,提升核心链路吞吐量与稳定性,实现微服务之间彻底解耦,降低服务依赖,便于业务独立迭代与扩容。
(7)物联网设备时序数据采集(IoT场景)
承接工业设备、智能硬件、物联网终端的实时上报数据,包括设备状态、传感器数据、运行参数、异常告警、位置信息等时序数据。Kafka支持海量设备并发上报、数据持久化回溯,适配IoT海量终端、高频上报、数据持续产生的特性,支撑设备监控、故障预警、时序数据分析、设备运维等场景。
(8)跨机房、跨集群数据同步(容灾多活场景)
依托MirrorMaker2.0实现多机房、异地多活集群的数据双向/单向同步,用于集群数据备份、机房迁移、异地容灾、多活架构数据互通,保障业务异地故障无感切换,提升系统整体容灾能力与可用性。
3. 优缺点
一、核心优点(生产核心优势)
-
超高吞吐性能,适配海量高并发场景:依托磁盘顺序写、批量发送、数据压缩、零拷贝、页缓存五大核心技术,彻底规避随机IO性能瓶颈,单Broker可支撑百万级TPS、百MB级流量吞吐,远超传统消息队列,是海量日志、大数据流式场景的首选中间件。
-
消息持久化可回溯,数据可靠性高:所有消息默认落地磁盘持久化存储,并非内存临时存储,支持自定义数据保留时长,不会消费完立即删除。支持任意时间、任意位移数据回溯重放,可完美支撑故障复盘、数据修复、业务重跑等需求。
-
天然分布式架构,无限水平扩容:基于分区、副本、集群架构设计,无中心节点瓶颈,支持Broker节点、Topic分区横向扩容,可按需承接流量增长,适配互联网海量业务、大数据集群的规模化扩展需求。
-
局部有序性,满足业务有序诉求 :严格保证同一分区内消息有序,可通过单分区实现全局有序、多分区实现分段有序,能够满足订单流水、状态变更、时序数据等需要有序消费的业务场景。
-
生态极致完善,全场景适配:深度兼容大数据全栈生态,无缝对接Flink、Spark、ClickHouse、Elasticsearch、数据仓库等组件,同时适配微服务异步通信、IoT时序数据、数据同步等多场景,是企业统一数据总线的标准组件。
-
高可用容错,集群稳定性强:基于多副本、ISR同步、自动Leader选举机制,节点故障、磁盘异常可自动容错,不影响集群整体读写,极少出现集群不可用情况,适配线上7×24小时稳定运行要求。
-
低延迟读写,兼顾性能与实时性:依托页缓存预热、批量异步处理机制,常规业务端到端延迟维持在1~5ms,批量场景延迟可控,同时满足高吞吐与实时业务诉求。
二、核心缺点(选型避坑、生产短板)
-
原生事务能力薄弱,不适配金融强一致场景:Kafka事务仅支持跨分区原子读写,不支持跨服务、跨组件分布式事务,无法保证业务层面强一致性,不适合支付、转账、订单结算等金融核心交易场景,仅能满足数据流转层面的弱事务需求。
-
无原生延迟队列、死信队列能力:官方未内置精准延时投递、失败消息死信流转能力,针对延时任务、异常消息重试隔离场景,需要业务层自行封装时间轮Topic、重试机制、死信Topic,开发成本更高。
-
默认至少一次投递,天然存在重复消费 :受限于重平衡、网络超时、位移提交失败等场景,Kafka无法保证消息不重复投递,业务侧必须手动实现幂等性设计,否则极易出现数据重复统计、重复下单、重复扣款等问题。
-
消息路由能力简陋,不支持复杂路由:仅支持Key哈希路由、固定分区路由,无通配符、主题转发、条件路由、消息过滤等高级路由功能,相较于RabbitMQ的Exchange交换机机制,无法适配复杂的多分支消息分发场景。
-
不支持读写分离,单节点负载压力集中:所有读写请求仅走Leader副本,Follower仅做数据同步、不承接读写流量,无法通过多副本分担节点压力,热点分区、热点Broker场景下易出现负载倾斜。
-
小消息高频场景存在性能损耗:核心优势依赖批量攒批,若业务为极小流量、单条高频小消息,无法触发批量机制,吞吐优势失效,且会增加频繁网络IO开销,不如传统轻量MQ高效。
-
运维门槛较高,集群调优复杂:涉及分区规划、副本同步、页缓存、日志清理、参数调优、元数据治理等大量细节,分区过多、参数不合理极易引发堆积、延迟、集群抖动,对运维和开发人员技术要求更高。
1.2 核心基础概念(必考)
1. Producer 生产者
定义:负责创建消息、封装数据,主动向 Kafka Topic 推送消息的客户端角色,是消息数据的入口。
核心作用:完成消息构造、序列化、分区路由、批量发送,支撑全量数据流入集群。
核心特性:支持同步/异步发送、消息压缩、批量攒批、幂等发送、事务发送,可通过拦截器做全局预处理。
面试/生产重点:生产者无状态、不占用集群资源,性能瓶颈主要来自批量参数、网络IO、分区路由策略。
2. Consumer 消费者
定义:订阅指定 Topic,主动以 Pull 模式拉取消息、执行业务处理的客户端角色,是消息数据的出口。
核心作用:消费处理流式数据,完成数据计算、业务落地、数据转发等下游逻辑。
核心特性:主动拉取、流量可控、支持批量消费、位移持久化、异常重试。
面试/生产重点:消费者是有状态逻辑,绑定消费组与分区分配,重平衡、堆积、重复消费均出自消费者侧。
3. Consumer Group 消费组(核心必考)
定义:一组拥有相同 `group.id` 的消费者实例集合,是 Kafka 实现集群消费、负载均衡的核心机制。
核心机制 :组内消费者实现负载均衡,一个 Topic 的所有分区会均匀分配给组内在线实例,同一条消息仅被组内一个消费者消费一次;不同消费组完全独立,可重复消费同一批消息,互不干扰。
核心价值:实现多实例水平扩容消费能力、故障自动转移、消费位点统一管理。
生产避坑:同一业务必须使用同一个消费组;不同业务禁止共用消费组,否则会导致分区错乱、重复消费、消费异常。
面试考点 :消费组实例数不能超过分区总数,超出实例会处于空闲状态,无法提升消费并发。
4. Topic 主题
定义:消息的逻辑分类载体,是生产者发送、消费者订阅的统一逻辑单元,无实际存储实体。
核心作用:实现业务数据隔离、分类管理,不同业务、不同数据类型拆分独立 Topic,解耦数据流。
生产规范:按业务线、数据类型拆分(日志Topic、埋点Topic、业务事件Topic),禁止所有业务混用一个Topic。
面试重点:Topic 不决定并发与性能,真正支撑并发的是内部分区。
5. Partition 分区(性能核心)
定义:Topic 的物理拆分最小单元,是 Kafka 数据存储、读写并发、集群扩容的核心载体,一个 Topic 由多个有序分区组成。
核心特性 :单分区内消息严格有序,跨分区消息无序;分区是集群负载均衡、数据分片的基本单位。
并发规则(必考):Topic 最大消费并行度 = 分区数量,消费者扩容上限由分区数决定,分区数不足会直接导致消费瓶颈、消息堆积。
生产细节:分区只能新增、不能减少;分区过多会加重集群元数据压力、增大重平衡耗时。
6. Replica 副本(高可用核心)
定义:为保证数据高可用与可靠性,对每个分区数据做的冗余备份,分为 Leader 主副本、Follower 从副本。
核心机制 :所有生产者、消费者的读写请求仅访问 Leader 副本;Follower 副本仅主动拉取 Leader 数据做同步备份,不承接任何客户端请求。
核心价值:节点故障、磁盘异常时,集群自动从副本中选举新 Leader,实现故障无感切换,彻底避免数据丢失与服务不可用。
生产规范:生产环境禁止单副本,常规业务2副本,核心高可靠业务3副本。
7. Offset 偏移量(消费核心)
定义:分区内每条消息的唯一递增序号,是标记消息存储位置、消费者消费点位的核心标识。
两类偏移量 :一是消息物理偏移量(消息存储位置);二是消费偏移量(消费者已消费的最新点位),新版本持久化在系统 Topic __consumer_offsets 中,旧版本存储在 Zookeeper。
核心作用:实现断点续消费、历史数据回溯、位移重置、故障恢复续跑,是保证消息不丢、可控消费的关键。
面试考点:位移提交滞后、提交失败、重平衡会导致重复消费;位移过期会触发自动重置。
8. Broker
定义:Kafka 独立服务节点,单台部署并启动 Kafka 服务的服务器即为一个 Broker。
核心作用:负责接收生产者消息、持久化存储、副本同步、响应消费者拉取请求、处理集群元数据交互。
生产特性:无主从固定角色,所有 Broker 地位对等,可动态承载不同分区的 Leader 角色。
运维重点:单Broker承载分区数有限,过多会引发负载过高、集群抖动。
9. Cluster 集群
定义:由多个 Broker 节点组成的分布式 Kafka 服务集群,是支撑高可用、高并发、海量数据的基础架构。
核心价值:支持横向扩容、故障容错、负载均衡、异地容灾,突破单节点性能与存储上限。
架构优势:无中心节点,节点故障不影响整体集群可用性。
元数据管理旧版本(2.8以下):完全依赖 Zookeeper 存储集群元数据,包括 Broker节点、Topic、分区、副本、消费组、位移信息,ZK 性能瓶颈会限制集群扩容上限。
新版本(2.8+ KRaft 架构) :彻底移除 Zookeeper,内置 Raft 协议集群控制器,通过 __cluster_metadata 系统Topic统一管理全量元数据,选主更快、扩展性更强、运维成本更低,是目前生产主流架构。
面试对比考点:ZK架构运维复杂、存在性能瓶颈;KRaft架构轻量化、高可用、支持超大集群。
1.3 通信协议与端口规范
- 通信协议
基于自定义 TCP 二进制协议,非 HTTP/AMQP;
协议向前兼容,高版本客户端可访问低版本集群,反向存在限制。
-
默认端口
-
业务端口:9092(消息收发、元数据请求)
-
JMX 监控端口:9999(指标采集、远程运维)
-
KRaft 内部通信:9093
-
Zookeeper 端口:2181(旧架构)
-
-
监听器 Listener(内外网/容器必配)
-
listeners:本机监听地址,用于内网访问 -
advertised.listeners:对外暴露地址,外网/跨机房客户端使用 -
配置错误会导致客户端连接失败、元数据路由异常。
-
1.4 客户端分类 & 版本谱系
1. 主流客户端
(1)Java 官方原生客户端(生产核心首选)
-
核心说明:Kafka 社区官方主力维护的客户端,迭代更新最快,所有新特性(幂等、事务、静态消费组、KRaft适配、分层存储)均优先适配,无功能阉割,是企业Java项目标准选型。
-
核心优势:功能最全、兼容性最强、BUG最少、参数完善、社区支持充足,完美适配所有生产高阶特性;适配Spring生态无缝整合。
-
短板:纯Java实现,高吞吐极致性能弱于librdkafka,内存开销相对更高。
-
适用场景:Java/Scala后端项目、企业核心业务、需要使用事务/幂等/精准位移控制的正式生产服务。
(2)librdkafka 高性能底层客户端(跨语言高性能核心)
-
核心说明 :基于C语言开发的开源高性能Kafka客户端,是目前业界性能天花板级别的客户端,Go、Python、PHP、Node.js等跨语言客户端底层均依赖该库实现。
-
核心优势:极致吞吐、低CPU开销、内存占用极小、批量优化更极致,高并发海量数据场景性能远超Java客户端;支持后台异步队列、自动攒批、网络优化。
-
短板:C库依赖,环境部署稍复杂,部分高阶特性适配滞后,Java不直接使用,跨语言调用存在少量适配成本。
-
适用场景:海量日志采集、超高吞吐埋点上报、IoT高频设备数据上报、非Java高性能中间件服务。
(3)Spring-Kafka 框架封装(Java开发主流)
-
核心说明:Spring生态基于原生Java客户端的二次封装框架,完全兼容原生所有配置与特性,简化开发、规范化编码,是SpringBoot/SpringCloud项目标配。
-
核心优势:注解式开发(@KafkaListener)、自动配置、内置批量消费、重试机制、死信队列、异常处理器、优雅停机,开箱即用,大幅降低开发成本。
-
短板:轻度封装无性能增强,核心能力完全依赖原生客户端,过度封装会隐藏底层参数调优细节。
-
适用场景:日常微服务开发、业务事件消费、中小型吞吐业务、标准化企业项目开发。
(4)Spring Cloud Stream(微服务总线专用)
-
核心说明:Spring生态流式消息框架,适配Kafka、RabbitMQ等多中间件,统一消息编程模型,屏蔽底层中间件差异。
-
核心优势:代码无侵入、中间件可无缝切换、适配事件驱动架构,适合标准化微服务消息总线开发。
-
短板:封装过重,底层调优自由度低,复杂高吞吐、高阶特性场景适配性差。
-
适用场景:标准化微服务事件解耦、低吞吐通用业务、多中间件兼容架构。
2. 版本关键分水岭
(1)0.8.x(初代老旧版本,彻底淘汰)
-
核心短板:无副本机制、数据无冗余,节点故障直接丢数据;消费位移存储在 Zookeeper,频繁读写ZK引发性能瓶颈;不支持消息持久化优化、无批量高级特性。
-
现状 :无任何企业生产使用,架构老旧、稳定性极差,面试仅需了解历史版本缺陷,生产直接规避。
(2)0.10.x(基础功能完善版本)
-
核心更新:新增消息时间戳、时间索引机制,支持按时间回溯消息、按时间清理日志,弥补了旧版本只能按位移、大小清理的短板;优化生产者批量发送逻辑,小幅提升吞吐。
-
生产价值:奠定了Kafka时序数据存储的基础能力,是后续高阶特性的铺垫版本。
(3)0.11.x(里程碑革命性版本,必考)
-
核心重大更新 :正式推出幂等生产者、事务机制、Exactly Once精准投递语义,彻底解决Kafka天然重复消费、无法保证事务的痛点;完善消息批量、压缩、重试机制,可靠性大幅提升。
-
生产意义:让Kafka从单纯的高吞吐日志组件,升级为可用于业务事件流转、数据同步的可靠中间件,是企业规模化落地的分水岭版本。
(4)2.0 ~ 2.7(企业经典稳定版本,存量主流)
-
核心特性 :修复0.11.x事务bug、优化重平衡机制、优化副本同步性能、完善监控指标;2.3版本推出静态消费组,大幅减少滚动发布的重平衡问题。
-
选型建议:稳定性极强、BUG极少、生态兼容完善,目前大量传统企业、存量集群仍在使用,适合保守型生产架构。
(5)2.8+(架构转型版本,双架构兼容)
-
核心突破 :正式引入KRaft架构,支持ZK、KRaft双架构兼容运行,彻底开启去ZK进化之路;优化元数据管理逻辑,缓解ZK集群瓶颈。
-
过渡价值:作为旧ZK架构向新KRaft架构迁移的过渡版本,兼顾稳定性与新特性,适合集群平滑升级迭代。
(6)3.x(新一代生产主流版本,全面推荐)
-
核心升级 :KRaft架构完全成熟、性能稳定,彻底弱化ZK依赖;新增分层存储、远程副本、动态配置优化;大幅优化元数据加载速度、集群扩容能力、重平衡效率。
-
生产优势 :无ZK运维成本、集群扩展性拉满、故障切换更快、适配云原生与超大集群,新建集群首选3.x版本。
版本选型核心原则(生产&面试总结)
-
老旧存量集群:优先维持 2.2~2.7 稳定版,无重大故障无需盲目升级;
-
全新搭建集群、云原生集群、大数据超大集群:强制选择 3.x 最新稳定版;
-
需使用事务、精准一次性消费业务:最低版本不低于 0.11.x;
-
所有 0.8.x、0.10.x 老旧版本,一律禁止线上新业务使用。
1.5 系统内置 Topic(企业运维实战必备)
Kafka 内置系统 Topic 为集群核心元数据、事务状态、消费位点的存储载体,由集群自动管理,生产环境禁止手动删除、修改、清空,是运维故障排查、集群状态核验的核心依据。不同架构(ZK/KRaft)内置Topic存在差异,以下为企业生产实战全量详解。
1. __consumer_offsets(核心高频,全网必考)
架构适配:ZK架构、KRaft架构通用,全局核心系统Topic
核心作用 :持久化存储所有消费组的消费位移、组订阅信息、成员状态、位移提交记录,是消费者断点续消费、故障续跑的核心载体。新版本Kafka彻底摒弃ZK存储位移,全部数据落地该内置Topic。
生产默认配置:默认50个分区,单副本起步,核心集群默认2副本,无手动创建入口,集群初始化自动生成。
企业运维实战场景
-
位移异常排查:消费堆积、重复消费、位移重置异常时,可通过消费该Topic,查看指定消费组、指定分区的历史位移提交记录,定位是客户端未提交、提交失败还是异常重置。
-
消费组溯源:查询离线消费组的历史消费记录、最后消费时间,清理僵尸消费组,减少集群元数据压力。
-
数据恢复兜底:业务误重置位移、误清理消费位点时,可回溯该Topic历史数据,恢复正确消费点位。
生产避坑禁忌
-
禁止手动删除该Topic,删除后所有消费组位移全部丢失,全线业务强制重置位移,引发大规模重复消费或数据丢失。
-
禁止随意修改分区数、副本数、保留策略,默认参数为社区最优配置。
-
该Topic数据不会随意清理,跟随集群全局日志策略,无需单独配置。
2. __transaction_state(事务专属,可靠性核心)
架构适配:0.11.x及以上版本,支持事务、幂等特性的集群通用
核心作用 :存储集群所有事务ID、事务运行状态、事务超时时间、事务关联分区、事务提交/终止记录,是Kafka实现事务机制、Exactly Once精准投递的底层核心。
企业运维实战场景
-
事务故障排查:业务事务提交失败、事务超时、消息悬挂、幂等失效时,消费该Topic可定位事务卡死、状态异常、事务ID冲突等问题。
-
僵尸事务清理:排查长时间未提交、未终止的僵死事务,避免占用事务资源,导致新事务创建失败。
-
精准一致性校验:核对跨分区事务的原子性,确认事务是否完整提交或正常回滚。
生产核心特性:自带事务过期清理机制,自动清理超时失效的事务状态记录,无需人工干预;核心金融、交易集群需重点监控该Topic状态。
3. __cluster_metadata(KRaft架构专属,新版核心)
架构适配:2.8+ KRaft架构,彻底替代ZK的核心系统Topic
核心作用 :存储集群全量元数据,包含Broker节点信息、Topic列表、分区分配、副本分布、集群配置、控制器状态等所有集群核心数据,完全取代Zookeeper的元数据管理能力。
企业运维实战场景
-
集群异常排查:节点上下线、分区分配失败、控制器选举异常、Topic创建删除超时,均需核查该Topic元数据同步状态。
-
集群迁移升级:ZK转KRaft架构迁移时,监控该Topic数据同步进度,判断集群切换是否完成。
-
元数据一致性校验:解决多节点元数据不一致、分区状态错乱、Leader选举异常等集群底层故障。
生产关键说明
-
KRaft架构下该Topic为集群命脉,默认高副本、高可靠存储,不允许任何手动修改。
-
该Topic同步异常会直接导致集群不可用、无法创建Topic、生产消费报错,是新版集群核心监控重点。
4. __consumer_offsets vs __cluster_metadata 核心区别(面试+运维必考)
-
__consumer_offsets :聚焦业务消费层,存储消费组、位移信息,所有通用架构通用,影响业务消费逻辑。
-
__cluster_metadata :聚焦集群底层架构层,存储集群元数据,仅KRaft架构独有,影响集群整体可用性。
企业通用运维规范(生产强制执行)
-
禁止操作:所有系统内置Topic禁止删除、清空、手动修改配置、手动生产消息。
-
监控覆盖:日常运维需监控三大内置Topic的分区状态、ISR同步、堆积、读写异常,提前规避集群隐患。
-
权限隔离:ACL权限严格管控,仅运维账号拥有只读权限,开发账号禁止访问系统Topic。
-
故障兜底:系统Topic异常优先重启控制器、同步元数据,禁止直接重建或删除,避免集群瘫痪。
1.6 环境搭建与基础命令(企业生产实战)
本节为生产级部署规范+高频运维命令大全,摒弃单机玩具化配置,完全贴合企业集群部署、版本选型、环境初始化、日常运维、故障排查场景,所有配置与命令均可直接线上复用。
1. 部署版本选型(生产硬性规范)
-
老旧存量集群:2.2.x ~ 2.7.x(稳定无重大BUG,运维生态成熟,无需盲目升级)
-
全新生产集群:3.2.x / 3.3.x 稳定版(KRaft架构成熟、无ZK依赖、性能更强、云原生适配)
-
绝对禁止:0.8.x、0.10.x 老旧版本,存在数据丢失、性能瓶颈、无高阶特性问题
2. 生产部署架构规范(企业强制)
(1)集群节点规划
-
节点数量:生产集群最少3节点,保障高可用;KRaft架构推荐3/5奇数投票节点,保证Raft选举合法性
-
硬件隔离:日志磁盘独立挂载SSD盘,禁止系统盘、数据盘混用,避免日志打满导致系统宕机
-
环境隔离:开发、测试、预发、生产集群物理隔离,禁止多环境混部
-
机架感知:跨机架部署副本,避免单机架断电导致集群整体故障
(2)系统初始化优化(部署前置必做)
所有节点部署前必须完成系统优化,否则线上极易出现性能抖动、卡顿、磁盘IO阻塞问题
-
关闭SWAP分区:永久关闭,PageCache与SWAP冲突会导致Kafka性能暴跌90%以上
-
调高文件句柄数:临时/永久调整为65535+,解决高并发下文件句柄耗尽问题
-
优化TCP内核参数:调大TCP队列、缩短超时重传时间,适配高吞吐网络场景
-
开启NTP时间同步:所有节点时间严格同步,避免日志索引、副本同步、事务机制异常
-
关闭防火墙&SELinux:集群内网互通放行,减少网络拦截开销
(3)核心配置文件生产规范(server.properties)
仅罗列生产必改核心参数,默认参数不改动
-
基础集群配置broker.id:节点唯一ID,集群内不可重复
-
listeners:内网监听地址,0.0.0.0:9092
-
advertised.listeners:外网/跨机房访问地址,容器/多网卡场景必配,否则客户端连接异常
-
num.network.threads、num.io.threads:根据CPU核心数调整,生产默认8-16
高可用配置
default.replication.factor=2(常规业务)/3(核心金融业务)
min.insync.replicas=2(最小同步副本数,保障数据可靠)
unclean.leader.election.enable=false(禁止非ISR副本选主,杜绝数据丢失)
日志存储配置
log.dirs:独立SSD磁盘日志路径,多磁盘可逗号分隔配置
log.retention.hours=168(默认保留7天,按需调整)
log.segment.bytes=1073741824(1GB分段,生产最优值)
log.cleanup.policy=delete(常规业务默认删除,KV状态数据启用compact)
KRaft架构专属配置(3.x新版)
process.roles=broker,controller(节点双角色)
controller.quorum.voters=节点1:9093,节点2:9093,节点3:9093
metadata.log.dir:元数据独立存储路径
ZK架构专属配置(2.x旧版)
zookeeper.connect=ZK集群地址:2181
zookeeper.session.timeout.ms=60000
3. 集群启停规范(生产严禁暴力操作)
(1)正确启停顺序
-
启动顺序:依赖组件(ZK/KRaft控制器)→ 逐个启动Broker节点 → 校验集群状态 → 业务流量接入
-
停止顺序:下线业务流量 → 逐个停止Broker节点 → 停止依赖组件
(2)生产启停命令(后台常驻)
-
启动集群节点
bin/kafka-server-start.sh -daemon config/server.properties -
停止集群节点(优雅停机)
bin/kafka-server-stop.sh
生产禁忌:禁止直接kill -9暴力杀进程,会导致日志文件损坏、副本同步异常、集群元数据错乱。
(3)开机自启配置
生产统一配置systemd系统服务,实现开机自启、故障自动重启、统一日志管理,替代原生脚本启停,稳定性更强。
4. 企业高频实战命令(日常运维全覆盖)
所有命令为生产高频必用,覆盖Topic管理、消息测试、位移运维、集群状态排查,可直接复制使用。
(1)Topic 核心管理命令
1.创建Topic(生产标准格式,带副本、分区配置)
kafka-topics.sh --create --topic test_topic --bootstrap-server
集群地址:9092 --partitions 8 --replication-factor 2
生产规范:禁止默认参数创建,必须指定分区数、副本数,默认参数单副本极易丢数据。
2.查看所有Topic列表
kafka-topics.sh --list --bootstrap-server 集群地址:9092
3.查看Topic详细配置、分区、副本、ISR状态
kafka-topics.sh --describe --topic test_topic --bootstrap-server
集群地址:9092
4.扩容分区(仅新增,不可减少)
kafka-topics.sh --alter --topic test_topic --partitions 16 --bootstrap-server 集群地址:9092
5.删除Topic(生产谨慎操作)
kafka-topics.sh --delete --topic test_topic --bootstrap-server
集群地址:9092
避坑:删除后元数据残留,需手动清理,优先使用逻辑下线而非物理删除。
(2)生产/消费测试命令
1.控制台生产者(手动推送测试消息)
kafka-console-producer.sh --topic test_topic --bootstrap-server
集群地址:9092
2.控制台消费者(消费最新消息)
kafka-console-consumer.sh --topic test_topic --bootstrap-server
集群地址:9092
3.控制台消费者(消费全量历史消息,回溯排查用)
kafka-console-consumer.sh --topic test_topic --bootstrap-server
集群地址:9092 --from-beginning
4.指定消费组消费(排查消费组专属问题)
kafka-console-consumer.sh --topic test_topic --bootstrap-server
集群地址:9092 --group test_group --from-beginning
(3)消费组与位移运维(故障排查核心)
1.查看所有消费组列表
kafka-consumer-groups.sh --list --bootstrap-server
集群地址:9092
2.查看消费组详情(堆积量、位移、滞后量、分区分配)
kafka-consumer-groups.sh --describe --group test_group --bootstrap-server
集群地址:9092
3.重置消费位移(生产故障修复核心,谨慎操作)
- 重置为最新位移(清空堆积,新消息开始消费)
kafka-consumer-groups.sh --reset-offsets --group test_group --topic test_topic --to-latest --execute --bootstrap-server
集群地址:9092
- 重置为最早位移(全量回溯,数据重跑)
kafka-consumer-groups.sh --reset-offsets --group test_group --topic test_topic --to-earliest --execute --bootstrap-server
集群地址:9092
4.删除僵尸消费组(清理无效元数据)
kafka-consumer-groups.sh --delete --group test_group --bootstrap-server
集群地址:9092
(4)集群状态与副本运维命令
1.查看集群所有Broker节点状态
kafka-broker-api-versions.sh --bootstrap-server
集群地址:9092
2.查询副本同步异常、ISR收缩异常分区
kafka-topics.sh --describe --bootstrap-server
集群地址:9092 | grep -i under
3.手动触发分区副本重分配(负载均衡)
生产节点负载不均时,通过该命令迁移分区、均衡Leader分布,缓解热点压力。
5. 生产部署核心避坑总结
-
禁止单副本上线:所有业务Topic必须2副本及以上,杜绝节点故障数据丢失
-
禁止混用系统盘:日志盘独立SSD,保障高吞吐IO性能
-
禁止暴力启停:严格优雅启停,避免文件损坏、元数据异常
-
禁止随意重置位移:位移重置前必须备份数据、评估影响,防止大规模重复消费
-
新集群优先KRaft:3.x版本无ZK依赖,运维成本更低、稳定性更强
-
参数不随意修改:集群核心参数变更需灰度测试,禁止线上临时改参
简洁:
-
部署模式:单机、伪集群、正式集群
-
启停脚本、后台运行、开机自启
-
常用脚本:
-
kafka-topics.sh:Topic 创建、查询、修改、删除 -
kafka-console-producer.sh:控制台生产者 -
kafka-console-consumer.sh:控制台消费者
-
-
位移重置、分区查询、集群状态查看基础命令。
第二部分 核心架构与全链路原理
2.1 整体流转架构(完整版全链路拆解 + 思维导图)
本节为 Kafka 端到端完整数据流架构,摒弃碎片化认知,从角色分层、数据流转全链路、核心机制联动、架构分层、核心约束五个维度完整拆解,同时附结构化思维导图,适配生产架构认知、面试口述、源码学习铺垫,是理解 Kafka 所有核心原理的基石。
一、架构整体分层(五层标准架构)
Kafka 生产集群严格遵循五层分层架构,每层职责单一、解耦清晰,支撑高吞吐、高可用、分布式流转:
-
客户端接入层:生产者、消费者、运维客户端、生态组件(Filebeat、Flink、Canal),所有数据入口、出口、运维操作均由该层发起,无中心网关,客户端直连集群。
-
集群管控层:KRaft控制器/ ZK、投票节点,负责集群元数据管理、Broker上下线感知、分区Leader选举、权限管控、集群配置同步,是集群的"大脑",不处理业务数据读写。
-
数据服务层(Broker核心层):集群所有Broker节点,承接消息读写、批量处理、数据持久化、副本同步、ISR维护、位移管理,是核心数据处理载体。
-
数据存储层:磁盘日志分段文件、页缓存、系统内核IO,负责消息落地、索引存储、冷热数据留存,依托顺序写、零拷贝实现高性能存储。
-
运维监控层:指标采集、日志监控、告警、分区运维、跨集群同步,保障集群稳定运行、故障快速兜底、容量动态迭代。
二、完整数据流转全链路(生产真实链路)
完整链路:生产者客户端 → 网络传输 → Broker集群 → 副本同步 → 持久化落地 → 消费者拉取 → 业务处理 → 位移提交
-
客户端预处理阶段(生产者侧) 业务代码封装消息(Topic/Key/Value/Header)→ 序列化(Json/Avro/Protobuf)→ 分区路由(Key哈希/粘性分区)→ 写入客户端缓冲区RecordAccumulator → 批量攒批(满足大小/linger超时)→ Sender线程批量发送。
-
网络传输阶段 基于TCP协议二进制传输,支持数据压缩(Snappy/LZ4)、SSL传输加密,客户端直连目标分区Leader节点,跳过中间转发,减少网络开销。
-
Broker写入处理阶段 Leader节点接收批量消息 → 参数校验、权限校验 → 写入页缓存(PageCache)→ 追加写入本地日志文件(顺序写)→ 更新分区索引文件 → 推送数据同步至所有ISR副本。
-
副本同步与数据确认阶段 Follower副本主动拉取Leader增量数据,完成同步后加入ISR集合 → 数据同步至所有ISR后更新分区HW水位线 → 按acks配置返回生产ACK响应(确认写入成功)。
-
数据持久化阶段 消息默认异步刷盘,页缓存数据定时落盘磁盘,避免频繁IO;旧日志分段归档,按时间/大小策略自动清理或压缩,实现数据循环存储。
-
消费者消费阶段 消费者主动Pull轮询Leader节点 → 拉取未消费批量消息 → 业务逻辑处理 → 手动/自动提交消费位移至__consumer_offsets系统Topic → 标记消费点位,实现断点续消费。
三、全链路核心联动机制
-
高可用联动:Broker节点故障 → 管控层感知节点下线 → 从ISR集合自动选举新Leader → 分区读写无缝切换,业务无感知。
-
负载均衡联动:Topic分区均匀分布在集群Broker → 生产流量分散至多节点 → 消费组分区均衡分配,避免单节点热点负载。
-
可靠性联动:多副本冗余 + ISR同步校验 + HW水位线兜底 + 位移持久化,完整实现消息不丢、可控重复。
-
性能联动:客户端批量攒批 + 数据压缩 + 服务端顺序写 + 零拷贝传输 + 页缓存读写,全链路优化吞吐与延迟。
四、整体流转架构 完整版思维导图(结构化可直接背诵)
Kafka整体流转架构
✅ 架构分层
-
- 客户端接入层:生产者、消费者、生态客户端、运维工具
-
- 集群管控层:KRaft控制器/ ZK、Raft投票节点、元数据管理
-
- 数据服务层:Broker节点集群、读写处理、副本同步、ISR维护
-
- 数据存储层:日志分段、索引文件、页缓存、磁盘持久化
-
- 运维监控层:指标监控、故障告警、集群运维、容灾同步
✅ 生产流转链路(上游)
消息构造 → 序列化 → 分区路由 → 缓冲区攒批 → 批量发送
网络传输 → Leader节点接收 → 日志追加写入 → ISR副本同步
更新HW水位线 → 返回ACK确认 → 消息持久化归档
✅ 消费流转链路(下游)
消费者Pull拉取 → 消息反序列化 → 业务逻辑处理
位移提交(自动/手动)→ 位移持久化 → 断点续消费
异常兜底:重试机制、死信转发、位移重置回溯
✅ 核心支撑机制
高可用:多副本、ISR、自动选主、故障容错
高性能:批量、压缩、顺序写、零拷贝、页缓存
高可靠:acks机制、水位线兜底、位移持久化
负载均衡:分区分散部署、消费组负载分配
✅ 架构核心约束
读写仅走Leader,Follower只同步不承接流量
单分区有序、跨分区无序
默认至少一次投递语义,业务需幂等
无中心节点,分布式去中心化架构
五、架构核心优势总结(面试/生产必考)
-
去中心化高可用:无中心瓶颈,节点故障自动容错,集群7×24小时稳定运行。
-
全链路高性能:上下游双层批量优化、内核级IO优化,支撑百万级超高吞吐。
-
数据高可控可靠:副本冗余、水位线校验、位移可回溯,兼顾性能与数据安全。
-
无限横向扩容:基于分区分片机制,集群、分区、客户端均可按需扩容,适配海量数据场景。
-
全生态适配:上下游完美对接大数据、微服务、IoT、数据中台全场景,是通用数据总线。
极简一句话总结 :Kafka整体架构是客户端去中心化直连、服务端分片多副本、全链路批量优化、内核级IO加速、可回溯可容错的分布式实时数据流转架构。
生产者 → Broker 集群(Topic/分区/副本) → 消费者 集群控制器、副本同步、选主、元数据管理贯穿整个数据流转全链路,支撑架构高可用、高吞吐、可容错运行。
2.2 生产者详解
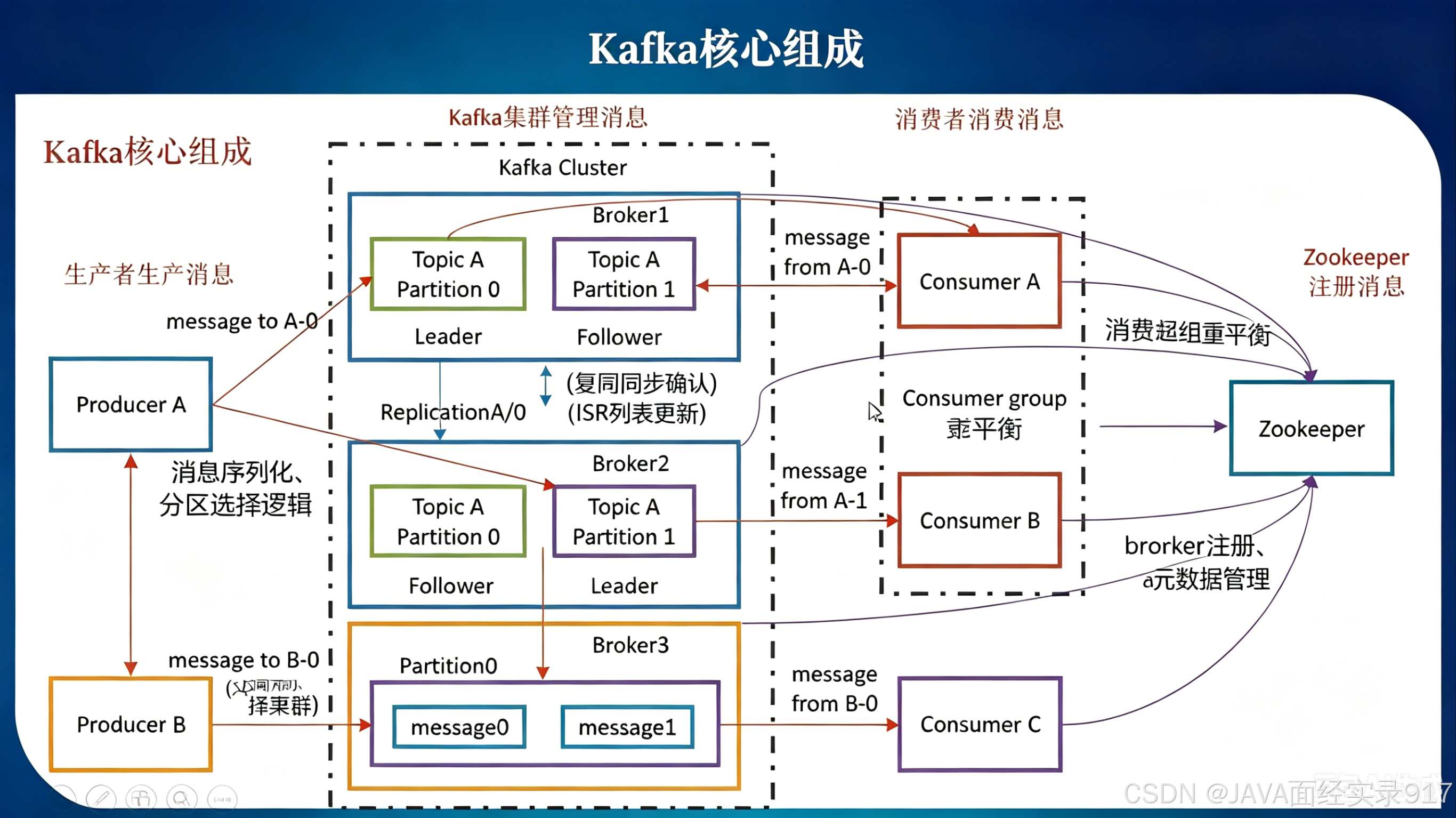
一、基于原图的 Kafka 核心架构流程图
# 1. 生产者生产消息(左)
Producer A ── message to A-0 ──▶ Topic A Partition 0 (Leader, Broker1)
Producer A ── message to A-1 ──▶ Topic A Partition 1 (Leader, Broker2)
Producer B ── message to B-0 ──▶ Topic B Partition 0 (Broker3)
↓
message0 / message1 写入日志
# 2. Kafka 集群管理消息(中)
Kafka Cluster
├─ Broker1
│ ├─ Topic A Partition 0 Leader
│ │ └─ 副本同步 ReplicationA/0 ──▶ Topic A Partition 0 Follower (Broker2)
│ └─ Topic A Partition 1 Follower
├─ Broker2
│ ├─ Topic A Partition 0 Follower
│ └─ Topic A Partition 1 Leader
│ └─ 副本同步 ReplicationA/1 ──▶ Topic A Partition 1 Follower (Broker1)
└─ Broker3
└─ Topic B Partition 0
# 3. 消费者消费消息(右)
Consumer Group
├─ Consumer A ◀── message from A-0 ── Topic A Partition 0
├─ Consumer B ◀── message from A-1 ── Topic A Partition 1
└─ Consumer C ◀── message from B-0 ── Topic B Partition 0
# 4. ZooKeeper 注册与协调(最右)
所有 Broker、Consumer、Consumer Group 信息均在 ZooKeeper 注册二、关键组件与流程解析(对应原图)
(1). 生产者侧
- Producer A 发送消息到
Topic A的两个不同分区(Partition 0和Partition 1),消息直接写入该分区的 Leader Broker。 - Producer B 发送消息到
Topic B的Partition 0,消息写入Broker3,可以看到分区底层就是顺序写入的日志文件(message0、message1)。
(2). 集群侧(核心)
- Broker1 和 Broker2 共同承载
Topic A的两个分区,每个分区都有 Leader + Follower 副本。Topic A Partition 0的 Leader 在 Broker1,Follower 在 Broker2;Topic A Partition 1的 Leader 在 Broker2,Follower 在 Broker1;- Leader 负责接收写入请求,同时同步数据到 Follower 副本,实现高可用。
- 副本同步:图中
ReplicationA/0、ReplicationA/1箭头,就是 Follower 拉取 Leader 数据的过程。
(3). 消费者侧
- 同一个消费组内的
Consumer A、Consumer B、Consumer C采用分区分配 的方式消费:- 每个分区只能被组内一个消费者消费;
Consumer A消费Partition 0,Consumer B消费Partition 1,实现负载均衡。
(4). ZooKeeper 协调(旧版架构)
- 图中紫色箭头代表 Broker、Consumer 都在 ZooKeeper 注册自己的信息:
- Broker 节点注册;
- Consumer 心跳、消费组信息注册;
- 由 ZooKeeper 辅助完成 Leader 选举、分区分配等协调工作。
1. 完整发送流程(步骤详解 + 可视化流程图)
本节完整补全Kafka生产者端端到端完整发送链路,包含客户端全预处理、网络传输、服务端落地、响应回执全流程,同时提供极简流程图,逻辑闭环、可直接面试口述、辅助理解底层原理。
一、逐步骤完整流程详解
-
步骤1:消息初始化封装 业务代码组装消息核心数据,构建
ProducerRecord对象,定义目标 Topic、消息 Key/Value、自定义 Header 消息头(链路追踪、自定义标签等),完成消息实体初始化。 -
步骤2:消息序列化 根据配置的序列化器(String/Json/Avro/Protobuf),将内存中的对象数据序列化为二进制字节数组,规避对象传输问题,适配网络传输与磁盘存储规范。
-
步骤3:分区路由匹配 通过内置分区器完成消息分区路由: - Key非空:根据Key哈希取模分区数,固定分区路由,保证同Key消息有序; - Key为空:2.4+版本默认粘性分区策略,固定单分区攒批,批次结束后切换分区,提升批量吞吐效率。
-
步骤4:客户端缓冲区攒批 序列化、路由后的消息,写入生产者核心缓冲区
RecordAccumulator,并不会立即发送。客户端开启批量攒批机制,等待满足两大条件之一: 1)消息累积量达到batch.size批量阈值; 2)等待时长达到linger.ms超时阈值。 -
步骤5:批量消息预处理 攒批完成后,触发批量预处理:执行生产者自定义拦截器逻辑、按配置算法(Snappy/LZ4/Gzip)批量压缩消息,减少网络传输体积与磁盘占用。
-
步骤6:Sender线程异步发送 唤醒后台 Sender 线程,从缓冲区拉取批量消息,根据分区路由结果,直连对应分区的 Leader 节点,通过TCP二进制协议批量推送消息,无中间转发,降低网络开销。
-
步骤7:Broker服务端写入处理 Leader节点接收批量消息,完成权限校验、参数校验、消息格式校验后,优先写入操作系统 PageCache 页缓存,执行磁盘顺序追加写入,更新分区日志文件与偏移量、时间索引文件。
-
步骤8:ISR副本数据同步 Leader推送增量消息至所有ISR同步副本,Follower节点主动拉取数据完成同步,同步完成后更新分区ISR集合状态与HW高水位线,保障数据多副本冗余可靠。
-
步骤9:生产ACK响应回执 根据
acks配置判定写入成功标准: - acks=0:无需等待响应,直接判定发送成功; - acks=1:Leader写入成功即返回ACK; - acks=-1/all:所有ISR副本同步完成后,返回成功ACK。 -
步骤10:失败重试与结果回调 发送失败时,根据
retries配置自动重试,重试耗尽则触发异常;发送完成后,执行异步回调函数,返回发送成功/失败结果,供业务侧处理。 -
步骤11:缓冲区资源释放 消息发送成功后,清空缓冲区对应批次数据,释放内存资源,等待下一轮攒批写入,完成单次消息发送全流程。
二、生产者完整发送流程【完整版思维导图(可直接背诵)】
Kafka生产者全链路发送思维导图(完整版·生产&面试通用)
(1)、消息前置封装阶段
-
- 消息实体构建:初始化ProducerRecord(Topic、Key、Value、Headers、时间戳)
-
- 数据序列化:对象转二进制字节数组(支持String/Json/Avro/Protobuf)
-
- 分区路由匹配Key非空:Key哈希取模分区数,固定分区,保障同Key消息有序
-
Key为空:2.4+粘性分区策略,固定单分区攒批,批次结束轮换分区
(2)、客户端缓冲攒批阶段(高吞吐核心)
-
写入缓冲区:消息存入RecordAccumulator内存缓冲区
-
批量触发机制(满足其一即发送)大小触发:消息累积量达到batch.size阈值
时间触发:等待时长达到linger.ms超时阈值
- 缓冲区核心控制参数:buffer.memory(最大内存上限,防OOM)
(3)、批量预处理阶段1. 自定义拦截器执行:消息预处理、链路ID追加、日志统计、消息过滤
-
批量消息压缩:Snappy/LZ4/Gzip,客户端压缩、服务端不解压存储、消费端解压
-
异常预处理:拦截器异常捕获,避免批量发送失败
(4)、网络传输发送阶段1. Sender后台线程唤醒,抓取缓冲区就绪批次消息
-
直连目标节点:TCP二进制协议直连分区Leader节点,无中间转发
-
传输保障:支持SSL加密传输、网络超时重试、失败自动重试机制
(5)、Broker服务端落地阶段1. 请求校验:权限校验、参数校验、消息格式合法性校验
-
内存写入:优先写入操作系统PageCache页缓存(异步刷盘,高性能核心)
-
磁盘持久化:磁盘顺序追加写入.log日志文件,更新offset偏移量
-
索引更新:同步更新偏移量索引、时间索引文件,支持后续消息检索
(6)、副本同步与可靠性保障阶段1. Leader推送增量消息至所有ISR同步副本
-
Follower主动拉取数据,完成增量同步
-
更新ISR集合状态、LEO日志末端位移、HW高水位线
-
数据对外可见规则:仅HW之前数据可被消费者消费
(7)、ACK响应与结果处理阶段1. 按acks配置返回应答(可靠性核心)acks=0:无需应答,超高吞吐,存在丢数风险
acks=1(默认):Leader写入成功即返回,性能与可靠均衡
acks=-1/all:所有ISR副本同步完成后返回,最高可靠性
-
失败重试机制:根据retries配置自动重试,耗尽后抛出异常
-
业务回调执行:异步发送触发回调函数,返回成功/失败结果
(8)、资源释放与收尾阶段1. 清空缓冲区已发送批次数据
-
释放客户端内存资源,等待下一轮攒批写入
-
异常兜底:失败批次保留,等待重试,避免消息丢失
**(9)、全流程核心关键机制(面试必背)**性能核心:批量攒批、消息压缩、磁盘顺序写、页缓存、零拷贝传输
有序性核心:单分区严格有序、多分区无序,由路由策略决定
可靠性核心:acks机制+多副本同步+自动重试+缓冲区兜底
异步核心:全程异步攒批、异步发送,同步模式仅阻塞等待ACK
(10)、生产常见坑点与优化点坑点1:linger.ms=0无等待,无法攒批,小消息吞吐极低
坑点2:Key为空+高频切换分区,引发流量倾斜、批量失效
坑点3:acks=0+无重试,高并发场景极易丢消息
优化1:合理搭配batch.size+linger.ms,平衡吞吐与延迟
优化2:核心业务开启幂等生产者,杜绝重试重复消息
优化3:非核心业务开启高压缩算法,降低网络与磁盘开销
三、极简线性流程图(快速复盘)
业务代码封装消息 → 序列化转二进制 → 分区器路由分区 → 写入RecordAccumulator缓冲区 → 批量攒批(大小/超时触发) → 拦截器处理+消息压缩 → Sender线程批量TCP发送 → Leader节点校验+页缓存写入+磁盘顺序写 → ISR副本同步+更新HW水位线 →按acks返回ACK响应 → 失败重试/业务回调 → 释放缓冲区资源
四、流程核心关键总结(面试高频)
-
核心性能关键:客户端批量攒批、消息压缩、服务端顺序写、零拷贝传输,是Kafka高吞吐的核心依托;
-
有序性关键:路由策略决定分区分布,单分区内严格有序,多分区无序;
-
可靠性关键:acks机制+副本同步+失败重试,共同保障消息投递可靠性;
-
异步核心:生产者全程异步攒批、异步发送,仅同步发送模式阻塞等待ACK。
简洁:
-
构造
ProducerRecord(Topic、Key、Value、Header) -
序列化:String / Json / Avro / Protobuf
-
分区器 Partitioner:路由消息到指定分区
-
Key 不为空:
Key % 分区数哈希路由,保证同 Key 有序 -
Key 为空:2.4+ 默认粘性分区,优先固定分区攒批,提升吞吐
-
-
消息写入客户端缓冲区
RecordAccumulator -
满足批量大小 / 等待超时,唤醒 Sender 线程批量发送
-
Broker 写入分区日志,返回 ACK 响应
2. 三种生产者发送模式(深度补全·生产+面试完整版)
Kafka 生产者官方提供同步发送、异步带回调发送、异步无回调发送 三种发送模式,三种模式底层均依赖客户端缓冲区攒批机制,核心差异在于是否阻塞等待ACK、是否处理结果、异常兜底逻辑,适配不同业务可靠性与吞吐诉求,是开发实战必掌握、面试高频考点。
2.1 同步发送(Sync 阻塞发送)
核心原理 :调用 send() 方法后,主线程阻塞等待Broker返回ACK响应,直至消息发送成功、重试耗尽抛出异常,才会释放线程执行后续逻辑,全程同步阻塞。
核心代码示例(Java原生)
java
// 同步发送:get() 方法阻塞等待结果
ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", "key", "同步消息内容");
try {
RecordMetadata metadata = producer.send(record).get();
// 发送成功:获取消息分区、位移、发送时间
System.out.println("发送成功,分区:" + metadata.partition() + ",位移:" + metadata.offset());
} catch (InterruptedException | ExecutionException e) {
// 发送失败:手动处理异常、重试、兜底日志
log.error("同步发送消息失败", e);
}核心特点
-
可靠性极高:线程阻塞等待最终结果,成功则100%落地,失败立即感知;
-
性能吞吐低:单线程串行等待,无法批量并发发送,极大限制TPS;
-
异常可控:所有发送失败、超时、重试异常均可手动捕获处理;
-
无消息丢失隐患:未收到ACK,业务可自行兜底重试。
生产适用场景
核心金融交易、订单事件、支付流水、数据同步等强可靠、低吞吐、零丢失核心业务,优先使用同步发送,杜绝消息丢失与未知异常。
生产坑点:禁止高吞吐业务使用,会直接导致接口阻塞、响应超时、服务吞吐量暴跌。
2.2 异步发送+回调(Async + Callback 主流推荐)
核心原理 :调用 send() 方法后立即返回,主线程不阻塞,持续执行业务逻辑;消息发送结果(成功/失败)由生产者后台Sender线程异步回调通知,统一处理结果与异常。
核心代码示例(Java原生)
java
// 异步带回调发送:主线程不阻塞
ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", "key", "异步回调消息内容");
producer.send(record, (metadata, exception) -> {
if (exception == null) {
// 发送成功回调
log.info("异步发送成功,分区:{},位移:{}", metadata.partition(), metadata.offset());
} else {
// 发送失败统一兜底:日志、重试、死信兜底
log.error("异步发送消息失败", exception);
}
});核心特点
-
吞吐性能优异:主线程无阻塞,充分利用批量攒批机制,最大化集群TPS;
-
结果可感知:通过回调捕获所有成功/失败场景,支持异常兜底;
-
业务无阻塞:不影响主流程响应速度,适配绝大多数线上业务;
-
运维友好:可在回调中埋点统计发送成功率、失败率,便于监控告警。
生产适用场景
微服务异步解耦、业务事件通知、用户行为埋点、日志采集、常规数据流转等兼顾性能与可靠性的绝大多数生产场景,是企业开发默认首选。
生产规范 :回调函数中必须捕获所有异常,禁止空回调,否则失败消息无感知、无兜底。
2.3 异步无回调发送(纯高性能模式)
核心原理 :仅调用 send() 发送消息,不接收返回值、不定义回调函数,主线程完全不阻塞、不关注发送结果,全权交由生产者后台线程处理。
核心代码示例(Java原生)
java
// 异步无回调发送:不关注结果、不处理异常
ProducerRecord<String, String> record = new ProducerRecord<>("test_topic", "key", "纯异步消息内容");
producer.send(record);核心特点
-
性能天花板:无任何阻塞、无回调开销,极致发挥Kafka批量高吞吐能力;
-
存在消息丢失风险 :网络异常、超时、Broker故障、重试耗尽等失败场景完全无感知;
-
无异常兜底:失败消息直接丢弃,无法日志追溯、无法手动重试;
-
运维不可控:无法统计发送成功率,故障时无法快速定位问题。
生产适用场景
非核心、可丢失、无需追溯的低优先级数据:实时日志采集、海量设备心跳数据、非关键埋点统计、临时监控数据等。
生产禁忌:绝对禁止用于业务数据、交易数据、事件通知等需要可靠投递的场景。
2.4 三种发送模式核心对比(面试速记表)
|-------|-------|--------|------|-------|--------------|
| 发送模式 | 阻塞特性 | 可靠性 | 吞吐性能 | 异常感知 | 生产适用场景 |
| 同步发送 | 主线程阻塞 | 最高 | 低 | 完全感知 | 核心交易、强可靠业务 |
| 异步+回调 | 非阻塞 | 较高 | 高 | 完全感知 | 绝大多数常规业务(首选) |
| 异步无回调 | 非阻塞 | 低(可丢数) | 极致高 | 完全无感知 | 日志、埋点等非核心数据 |
2.5 生产通用最佳实践
-
核心业务强制异步+回调:兼顾性能与可靠性,回调内统一做异常重试、日志记录、监控埋点;
-
极核心金融交易:少量使用同步发送,配合高acks、幂等生产者,保障数据绝对可靠;
-
海量非核心数据:使用异步无回调,配合消息压缩、批量攒批,最大化吞吐;
-
禁止混合使用:同一Topic、同一业务链路统一发送模式,避免消息乱序、统计异常;
-
异步回调避坑:回调中禁止执行耗时业务逻辑,仅做日志、统计、重试标记,防止阻塞后台Sender线程。
简洁:
-
同步发送:阻塞等待 ACK,可靠性高,吞吐偏低(核心业务)
-
异步发送+回调:非阻塞,通过回调处理结果,吞吐高(主流)
-
异步无回调:性能最高,丢失消息无感知(日志、埋点等非核心)
3. 分区器补充:粘性分区 Sticky Partitioner(生产默认&面试重点)
粘性分区是 Kafka 2.4 版本正式默认启用 的生产者分区器,彻底替代旧版随机分区器,专门优化无Key消息的批量发送性能,是高吞吐业务的核心底层优化点,也是面试高频考点、生产调优必备知识点。
3.1 核心背景(旧版痛点)
在粘性分区出现前,Kafka 无Key消息默认使用随机分区器:每条无Key消息都会随机选择一个分区发送。该机制存在严重性能缺陷:高频小消息场景下,每条消息都可能切换分区,导致客户端无法有效攒批,频繁发起网络请求,极大降低批量吞吐效率、拉高网络IO开销,无法发挥Kafka批量发送的核心优势。
3.2 核心原理
粘性分区专门针对消息Key为空的场景设计,核心逻辑为「固定分区攒批,批满再切换」,具体流程:
-
生产者初始化后,优先随机选中一个可用分区作为当前粘性分区;
-
所有无Key消息,统一持续发送至该固定分区,持续攒批;
-
当当前批次满足
batch.size大小阈值、或linger.ms超时,批次发送完成; -
上一批次结束后,重新随机选择一个新的可用分区,开启新一轮粘性攒批;
-
循环往复,实现无Key消息的批量聚合发送。
3.3 核心优势
-
极致提升批量效率:规避单条消息随机分区的问题,同一批次消息集中发送至同一个分区,大幅提升批量攒批成功率,最大化集群吞吐;
-
大幅减少网络请求数:多次消息聚合为一次网络IO请求,降低网络开销与Broker请求处理压力;
-
兼顾分区负载均衡:单批次固定分区、批次切换随机换区,长期来看所有分区流量均匀,不会出现永久分区倾斜;
-
无业务侵入:无需业务指定Key,零改造即可提升无Key消息场景的生产性能。
3.4 生产隐性坑点(重点避坑)
-
瞬时分区流量倾斜:单批次所有流量集中在一个分区,瞬时会出现单个分区流量偏高的情况,若业务流量极大、批次超大,可能引发短时分区热点,导致局部消费延迟;
-
批次堆积风险 :若
linger.ms设置过大,批量攒批超时时间过长,会导致消息延迟升高,不适合超低延时实时业务; -
仅适配无Key消息 :如果消息携带Key,会优先执行Key哈希分区策略,粘性分区规则失效,无法优化带Key消息的批量性能。
3.5 新旧分区器核心对比
|-------------|------------|---------------|-----------|-----------|
| 分区器类型 | 适用版本 | 分区选择规则 | 批量性能 | 流量特点 |
| 随机分区器(旧版) | 2.4 之前 | 单条消息随机选分区 | 差,无法有效攒批 | 瞬时均匀,无倾斜 |
| 粘性分区器(新版默认) | 2.4+ 全版本默认 | 批次维度固定分区,批满切换 | 优异,批量效率拉满 | 瞬时倾斜、长期均匀 |
3.6 生产最佳实践
-
默认开启不修改:2.4及以上版本无需手动配置,默认启用粘性分区,禁止手动切回随机分区器;
-
参数适配调优 :高吞吐非实时业务,适当调大
linger.ms(5~20ms),最大化攒批效果;超低延时业务,减小linger.ms,牺牲部分吞吐保障实时性; -
热点分区规避:超大流量Topic,合理规划分区数,避免单分区承载流量过高,抵消粘性分区瞬时倾斜的影响;
-
有序业务适配:需要消息有序的业务,优先使用消息Key哈希分区,放弃粘性分区,保证分区内消息有序。
3.7 面试速记口诀
旧版随机乱分区,无Key攒批性能烂;新版粘性批固定,批满换区保均衡;瞬时倾斜长期匀,高吞吐场景首选,有序业务靠Key分。
-
规则:Key 为空时,固定一个分区攒批,批次结束后再切换分区
-
优势:减少网络请求,大幅提升批量效率
-
隐患:极端场景会加剧分区流量倾斜
4. 生产者拦截器 Interceptor(实战全解+面试必考)
生产者拦截器是 Kafka 客户端提供的全局切面扩展机制,允许用户在消息发送全链路的前置、后置阶段自定义通用逻辑,无侵入实现批量消息增强、监控埋点、异常统一处理,是生产级 Kafka 开发的核心扩展手段,广泛用于企业统一消息规范治理。
4.1 核心执行原理与生命周期
生产者拦截器遵循链式执行、双向切面机制,一个生产者可配置多个拦截器,按配置顺序串行执行前置逻辑,逆序执行后置回调逻辑,全程在生产者客户端线程中执行,不阻塞Broker服务端。
完整执行链路:
-
业务代码调用 send() 发送消息;
-
执行所有拦截器 onSend() 前置方法(消息发送至缓冲区前);
-
消息完成序列化、分区路由、写入客户端缓冲区;
-
消息发送完成(成功/失败)后,执行所有拦截器 onAcknowledgement() 后置回调方法;
-
生产者关闭时,触发所有拦截器close() 销毁方法,释放资源。
核心特性 :拦截器执行在客户端本地完成,不产生网络IO,不与Broker交互,性能开销极低。
4.2 三大核心抽象方法
自定义拦截器需实现 ProducerInterceptor 接口,包含三个核心方法,各司其职:
-
onSend(ProducerRecord record) (前置处理核心) 执行时机:消息构造完成、写入缓冲区之前,全局最先执行的切面逻辑。 核心能力:修改消息Topic、Key、Value、Header,过滤无效消息、统一追加自定义标签、校验消息格式。 返回值:处理后的完整消息对象,可直接篡改、替换原始消息。
-
onAcknowledgement(RecordMetadata metadata, Exception exception)(后置回调核心) 执行时机:消息发送结果回调(无论成功/失败),Broker返回ACK响应后触发。 核心能力:统一统计发送成功率、记录异常日志、上报监控指标、追踪消息发送链路。 参数说明:成功时exception为null,metadata包含消息分区、位移、发送时间;失败时携带异常信息。
-
close()(资源销毁) 执行时机:生产者客户端关闭时触发。 核心能力:释放拦截器占用的线程、连接、缓存等资源,避免内存泄漏。
4.3 企业级使用场景(生产全覆盖)
拦截器核心价值是统一通用逻辑,解耦业务代码,避免每个业务发送消息重复写冗余代码,企业主流落地场景如下:
-
统一消息溯源埋点:全局自动追加链路ID、服务名、环境标识、发送时间戳、机器IP至消息Header,实现全链路追踪,无需业务手动赋值。
-
消息格式统一校验与清洗:前置校验消息非空、格式合规、字段合法,过滤脏数据、无效空消息,避免无效流量占用集群资源。
-
全局监控指标上报:统一统计消息发送总量、成功量、失败量、延迟分布,对接Prometheus/Grafana实现无埋点监控。
-
消息内容统一增强:批量追加业务标签、租户ID、版本号,适配多租户、多环境消息隔离场景。
-
异常统一兜底处理:全局捕获发送异常,统一打印错误日志、上报告警,无需业务逐个try-catch。
-
灰度流量标记:拦截消息并追加灰度标识,实现生产流量灰度分流、测试流量隔离。
4.4 自定义拦截器实战代码模板(可直接复用)
基于Java原生客户端实现通用拦截器,适配所有SpringBoot、原生Java项目:
java
public class CustomProducerInterceptor implements ProducerInterceptor<String, String> {
// 前置处理:消息发送前统一增强
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 1. 统一追加链路追踪ID
String traceId = MDC.get("traceId");
// 2. 统一追加服务标识、环境
record.headers().add("service-name", "order-service".getBytes(StandardCharsets.UTF_8));
record.headers().add("env", "prod".getBytes(StandardCharsets.UTF_8));
record.headers().add("trace-id", traceId.getBytes(StandardCharsets.UTF_8));
// 3. 消息格式简单校验,过滤空消息
if (Objects.isNull(record.value()) || record.value().isEmpty()) {
return null; // 返回null则丢弃该消息
}
return record;
}
// 后置回调:统一统计发送结果
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// 发送成功:上报成功指标
log.info("Kafka消息发送成功,topic:{},partition:{},offset:{}",
metadata.topic(), metadata.partition(), metadata.offset());
} else {
// 发送失败:统一日志+告警
log.error("Kafka消息发送异常", exception);
// 可对接监控告警SDK
}
}
// 资源释放
@Override
public void close() {
// 无特殊资源无需处理
}
// 配置初始化参数
@Override
public void configure(Map<String, ?> configs) {
// 读取生产者全局配置
}
}4.5 拦截器配置方式
支持原生客户端、Spring-Kafka两种主流配置方式:
-
原生Java客户端配置 在生产者配置中指定拦截器全类名,多拦截器逗号分隔,按顺序执行:
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomProducerInterceptor.class.getName()); -
Spring-Kafka配置 注册自定义拦截器Bean,自动注入生效,支持多拦截器有序加载。
4.6 生产核心避坑点(高危易错)
-
必须捕获所有异常 :拦截器内部禁止抛出未捕获异常,onSend、onAcknowledgement一旦抛异常,会直接中断消息发送,导致业务消息丢失、发送失败,所有自定义逻辑必须包裹try-catch。
-
禁止执行耗时逻辑 :拦截器运行在Sender发送线程,耗时操作(IO、数据库查询、远程调用)会阻塞批量发送线程,大幅降低生产吞吐、拉高消息延迟。
-
多拦截器顺序可控:多拦截器按配置顺序执行onSend,逆序执行onAcknowledgement,需严格管控执行顺序,避免逻辑覆盖、参数错乱。
-
谨慎返回null:onSend方法返回null会直接丢弃当前消息,仅用于过滤无效脏数据,禁止业务场景随意返回null,避免正常消息丢失。
-
无事务补偿能力:拦截器仅做切面增强,不参与Kafka事务、幂等机制,拦截器逻辑异常不会触发消息重试、事务回滚,需自行兜底。
4.7 面试速记核心要点
-
核心作用:客户端全局切面,统一消息增强、监控、过滤、溯源,解耦业务通用逻辑;
-
执行顺序:onSend顺序执行、onAcknowledgement逆序执行;
-
高危禁忌:拦截器抛异常、写耗时逻辑,会导致发消息失败、吞吐下降;
-
核心场景:链路追踪、脏数据过滤、统一监控、消息标准化。
简洁:
-
执行时机:消息发送前后全局切面处理
-
适用场景:统一追加链路 ID、消息埋点、日志统计、消息过滤
-
注意:必须捕获异常,拦截器报错会直接导致发送失败。
5. 消息压缩(生产核心调优模块)
Kafka 消息压缩是高吞吐场景核心优化手段,区别于传统MQ的单节点压缩,Kafka采用「客户端压缩、服务端不解压存储、消费端解压」的极简链路,最大化节省磁盘空间、降低网络IO开销,仅增加少量CPU编解码开销,是生产集群降本提效的关键配置。
5.1 核心压缩链路(全程零冗余损耗)
标准链路:客户端批量压缩 → Broker原生压缩存储 → 跨节点同步保留压缩态 → 消费端拉取后解压
-
生产者侧:消息攒批完成后、网络发送前,对整批批量消息统一压缩,单条消息不单独压缩,规避细碎CPU损耗
-
服务端侧:Broker接收压缩后的二进制数据,全程不解压、不重压,直接落盘存储,副本同步、数据流转均保留压缩格式,无二次编解码开销
-
消费者侧:拉取到批量压缩消息后,本地完成解压,执行业务逻辑,仅消费端承担解压CPU消耗
核心优势:整条链路仅一次压缩、一次解压,CPU开销可控,大幅降低网络传输流量、磁盘占用、磁盘IO压力,高吞吐场景收益远大于CPU损耗。
5.2 四大主流压缩算法(生产选型+参数对比)
Kafka原生支持4种压缩算法,不同算法在压缩率、吞吐、CPU开销上差异极大,适配不同业务场景,无通用最优解,需按需选型。
| 压缩算法 | 压缩率 | 编解码速度 | CPU开销 | 生产适用场景 |
|---|---|---|---|---|
| none(不压缩) | 无压缩 | 最快 | 极低 | 低吞吐、小消息、实时极致敏感业务 |
| snappy(默认) | 中等 | 极快 | 低 | 通用生产首选,日志、埋点、常规业务数据流,平衡性能与压缩率 |
| lz4 | 中高 | 很快 | 中低 | 超高吞吐海量数据场景,大数据流式同步、IoT高频上报 |
| gzip | 极高 | 慢 | 高 | 冷数据归档、低流量历史数据存储,极致节省磁盘空间场景 |
5.3 压缩触发机制(核心原理)
-
触发条件 :仅对批量消息生效,单条消息默认不压缩(压缩开销大于收益);满足batch.size或linger.ms攒批条件后,整批消息统一压缩
-
压缩粒度:以生产者批次为单位压缩,而非单条消息,压缩效率极高,适配批量攒批机制
-
兜底机制:单条消息、极小流量场景,自动跳过压缩,避免无效CPU损耗
5.4 双层压缩配置(客户端+服务端)
(1)客户端压缩(业务精准控制,生产主流)
通过生产者参数 compression.type 指定,优先级最高,精准适配单业务数据流特性,支持none/snappy/lz4/gzip。
(2)服务端全局压缩(集群兜底)
Broker端配置 compression.type,针对未开启客户端压缩 的消息做全局兜底压缩,统一集群存储规范,避免部分业务未压缩导致磁盘浪费;客户端压缩优先级高于服务端,不会重复压缩。
5.5 生产核心收益(量化价值)
-
节省网络带宽:日志、文本类数据压缩率可达50%~70%,直接减半网络流量,解决高吞吐带宽瓶颈
-
降低磁盘占用:海量流式数据大幅缩减存储体积,降低磁盘扩容成本,延长磁盘使用寿命
-
提升集群吞吐:网络IO、磁盘IO压力降低,单Broker可承载更高TPS,集群整体性能提升30%+
-
减少IO阻塞:减小单次读写数据量,降低磁盘随机IO、网络传输耗时,间接降低消息延迟
5.6 生产避坑点(高危易错)
-
禁止重复压缩:已压缩的消息二次压缩无收益,反而浪费CPU,集群默认机制不会重复压缩,无需手动干预
-
二进制消息慎压缩:图片、视频、加密二进制数据本身已压缩,开启Kafka压缩会徒增CPU开销,无任何空间收益,此类业务需关闭压缩
-
超低延时业务取舍:毫秒级极致实时、极小流量业务,关闭压缩,避免编解码耗时增加延迟
-
消费者CPU兜底:压缩开销生产者承担压缩、消费者承担解压,高吞吐场景需监控消费者CPU负载,避免解压打满CPU
-
版本兼容无坑:压缩格式向下兼容,高低版本集群、客户端互通无异常,无需担心版本适配问题
5.7 面试高频速记
-
压缩链路:客户端批量压缩→Broker不解压存储→消费端解压,仅两次编解码,CPU可控
-
选型口诀:通用snappy、高吞吐lz4、归档gzip、二进制不压缩
-
核心收益:降带宽、省磁盘、提吞吐、减IO压力
-
核心禁忌:二进制数据、极致低延时小流量业务不开启压缩
压缩链路:客户端压缩 → Broker 不解压存储 → 消费端解压,仅两次编解码,CPU 开销可控。
算法选型
-
snappy:速度快、压缩率中等,生产默认首选
-
lz4:综合性能最优,高吞吐场景推荐
-
gzip:压缩率高、CPU 消耗大,冷数据归档使用
支持 Broker 全局兜底压缩配置。
6. 生产者核心参数(生产必调|参数详解+推荐值+避坑)
Kafka 生产者参数直接决定吞吐、延迟、可靠性、重复率、集群压力,以下为生产环境必配、高频调优核心参数,摒弃默认低效配置,区分高可靠、高吞吐、低延迟三大业务场景,附精准推荐值与踩坑说明,可直接落地配置。
一、消息可靠性核心参数(金融/核心业务必配)
(1) acks :消息写入确认机制,可靠性核心参数参数释义:控制Broker返回生产成功ACK的时机,直接决定消息丢失概率
-
acks=0 :不等待Broker应答,发送即成功,吞吐最高,存在丢消息风险
-
acks=1(默认):Leader副本写入成功即返回ACK,性能与可靠性均衡
-
acks=-1/all:Leader+全部ISR副本同步完成后才返回ACK,最高可靠性,杜绝数据丢失
-
生产推荐:核心交易/支付业务=all;普通日志/埋点业务=1;极致高吞吐可临时用0
-
避坑:acks=all必须配合min.insync.replicas=2使用,否则高可靠失效
(2) retries:发送失败自动重试次数
参数释义:网络抖动、副本同步超时、节点临时故障时,客户端自动重试发送
默认值:旧版本0,新版本2147483647(无限重试)
生产推荐:核心业务=10~20;普通业务=3~5;搭配重试间隔使用
避坑 :开启重试必然产生重复消息,必须开启生产者幂等,或业务做幂等兜底
(3) retry.backoff.ms:重试间隔时间
参数释义:每次重试发送的等待间隔,避免频繁重试打满集群网络
默认值:100ms
生产推荐:300~500ms
避坑:间隔过小引发风暴重试,间隔过大增加消息延迟
(4) enable.idempotence:幂等生产者开关
参数释义:通过PID+消息序列号实现单会话单分区消息去重
默认值:false(旧版本),true(新版本3.x)
生产推荐 :所有生产环境强制开启true
避坑:关闭幂等+开启重试,会造成大量重复消息,引发业务数据异常
二、批量吞吐调优参数(高吞吐场景核心)
(1) batch.size:批量消息最大阈值
参数释义:单个生产者批次的最大数据量,达到阈值立即触发发送
-
默认值:16384(16KB)
-
生产推荐:高吞吐日志/埋点=65536~131072(64KB~128KB);普通业务=32768(32KB);低延迟小流量=16KB
-
避坑:批次过小,频繁发送网络IO暴涨;批次过大,单条消息延迟升高、内存占用增加
(2) linger.ms:批量攒批等待时间
参数释义:消息进入缓冲区后,最长等待攒批时间,超时即发送,弥补小流量无法攒批的问题
默认值:0(不等待,有消息立即发送)
生产推荐:高吞吐场景=5~10ms;低延迟业务=0~2ms
核心价值:极低损耗大幅提升吞吐,是高吞吐场景性价比最高的调优参数
(3) buffer.memory:生产者客户端缓冲区总内存
参数释义:客户端用于缓存待发送消息的总内存上限,满了会阻塞业务发送
默认值:33554432(32MB)
生产推荐:高吞吐服务=64MB~128MB;普通业务=32MB
避坑:缓冲区过小会导致业务发送阻塞、接口超时;过大占用JVM内存
(4) max.in.flight.requests.per.connection:单连接未应答请求数
参数释义:单条网络连接上,允许未收到ACK的最大请求数
默认值:5
生产推荐:开启幂等/事务=5(有序保证);纯高吞吐无序业务=10~20
避坑:大于5且未开幂等,重试会导致消息乱序
三、压缩与性能优化参数(降本提效必备)
(1) compression.type:消息压缩算法
参数释义:客户端批量消息压缩算法,降低网络流量与磁盘占用
-
可选值:none、snappy、lz4、gzip
-
生产推荐:通用业务=snappy(默认均衡);超高吞吐=lz4;冷数据归档=gzip;二进制数据=none
-
核心收益:文本类数据压缩率50%~70%,直接减半带宽与磁盘占用
(2) max.request.size:单条请求最大消息大小
参数释义:限制生产者单次发送的最大数据量,防止超大消息打垮集群
默认值:1048576(1MB)
生产推荐:根据业务调整为2MB~5MB,同时同步修改Broker端message.max.bytes
避坑:客户端与服务端参数不一致,会导致消息发送失败、被Broker拒绝
(3) connections.max.idle.ms:连接空闲超时时间
参数释义:空闲连接自动回收时间,避免无效连接占用端口资源
默认值:540000(9分钟)
生产推荐:300000(5分钟),适配容器动态扩缩容场景
四、事务专属参数(Exactly Once场景)
(1) transactional.id:事务唯一ID
参数释义:开启跨分区事务的唯一标识,必须全局唯一
生产规范:服务名+实例ID+业务标识,避免冲突
(2) transaction.timeout.ms:事务超时时间
默认值:60000ms
生产推荐:30000~60000ms,小于Broker端事务最大超时
避坑:事务超时会自动回滚未提交事务,导致消息发送失败
五、三大场景最终配置模板(直接复制上线)
1. 核心高可靠场景(交易、订单、数据同步)
acks=all、retries=10、enable.idempotence=true、batch.size=32768、linger.ms=2、compression.type=snappy、buffer.memory=67108864
2. 超高吞吐场景(日志、埋点、IoT上报)
acks=1、retries=3、enable.idempotence=true、batch.size=131072、linger.ms=8、compression.type=lz4、buffer.memory=134217728、max.in.flight.requests.per.connection=10
3. 极致低延迟场景(实时通知、即时事件)
acks=1、retries=3、linger.ms=0、batch.size=16384、compression.type=none、buffer.memory=33554432
六、面试速记核心
-
可靠性四件套:acks=-1 + 幂等开启 + 合理重试 + 最小同步副本配置
-
吞吐优化三核心:调大batch.size、开启linger攒批、启用压缩
-
高频坑点:重试+无幂等=重复消息;linger过大=延迟升高;缓冲区过小=发送阻塞
简洁:
-
acks消息确认机制(重中之重)-
acks=0:不等待应答,吞吐最高,可能丢消息
-
acks=1(默认):Leader 写入成功即返回,性能与可靠均衡
-
acks=-1/all:Leader + 全部 ISR 副本同步完成才返回,最高可靠
-
-
retries:发送失败重试次数 -
batch.size:批量消息大小阈值 -
linger.ms:批量等待时间,攒消息提升吞吐 -
buffer.memory:客户端缓冲区上限,防止内存溢出 -
compression.type:压缩算法
7. 消息有序性(生产&面试核心重难点)
Kafka 的消息有序性是分区级有序、全局无序,这是其核心设计特性,也是业务开发中有序场景适配的核心依据,所有有序业务开发、乱序问题排查均围绕该核心规则展开。
一、核心有序规则(铁律)
-
单分区严格有序:生产者发送至同一个分区的消息,会严格按照发送顺序写入磁盘;消费者消费该分区消息时,默认严格保持写入顺序,不会出现乱序,这是Kafka唯一的有序保障。
-
多分区全局无序:同一Topic下不同分区的消息,生产、消费均无全局顺序。多分区并行生产、消费场景下,跨分区消息先后顺序无法保证。
-
有序最小单元:分区是Kafka有序性保障的最小、唯一单元,无任何机制支持跨分区全局有序(默认场景)。
二、两类有序业务实现方案
1. 局部有序(绝大多数业务场景)
适用场景 :用户维度、订单维度、设备维度的串行业务,如单用户订单状态变更、单设备时序数据上报、单账号操作日志等,只需保证单个主体数据有序,无需全量数据全局有序。
实现方案:利用消息Key哈希分区机制,将同一业务主体(同一用户ID、订单ID、设备ID)的消息设置相同Key,Kafka会固定路由至同一个分区,天然保证该主体所有消息有序。
生产规范:有序维度必须作为消息Key,禁止Key随机、Key为空,否则会导致消息随机分区,彻底丢失有序性。
2. 全局有序(极端小众场景)
适用场景:全量数据需要严格串行处理、不容许任何乱序的极简业务,如全局配置变更同步、核心流程串行日志统计等。
实现方案 :将Topic分区数设置为1,所有消息统一写入唯一分区,实现全局严格有序。
核心取舍:彻底牺牲并发性能,Topic最大消费并行度降为1,高吞吐、高并发业务绝对禁止使用该方案。
三、生产消息乱序核心诱因(高频踩坑点)
默认单分区有序失效、业务出现乱序,均由以下人为/场景化因素导致,是线上乱序问题的核心排查点:
-
生产者重试机制(最主要原因):开启失败重试后,后发送的消息发送失败触发重试,会晚于正常发送的前置消息落地分区,直接导致单分区消息乱序。
-
多线程异步发送:生产者多线程并行发送同一Key的消息,线程调度差异导致消息发送顺序混乱,打破分区有序性。
-
未开启幂等+高并发重试:旧版本无幂等机制时,重试消息无序列号管控,极易出现新旧消息错位乱序。
-
分区重平衡/分区扩容:Topic新增分区后,Key哈希路由规则改变,同一主体消息会路由至新分区,出现历史分区与新分区消息顺序错乱。
-
手动指定分区混乱:业务代码手动随机指定分区发送,未遵循固定分区路由规则,破坏有序性。
-
多生产者实例发送同一主体消息:多个生产者同时发送同一Key的消息,无发送顺序管控,引发全局乱序。
四、生产级有序性保障解决方案
1. 单分区有序绝对保障方案
-
强制开启生产者幂等:通过PID+消息序列号,Broker会严格校验消息顺序,重试消息不会插入乱序位置,彻底解决重试导致的单分区乱序。
-
限制单连接未应答请求数 :设置
max.in.flight.requests.per.connection=5(幂等模式默认最优值),禁止无序请求堆叠,保障发送有序。 -
单线程串行发送同主体消息:同一业务主体的消息,统一由单线程发送,避免多线程调度导致的发送乱序。
2. 业务层有序兜底方案
-
消息携带时间戳/版本号:每条消息嵌入业务时间戳、自增版本号,消费端乱序时自动排序、过滤过期旧消息。
-
状态机校验兜底:业务消费时基于状态机判断消息合法性,跳过乱序失效消息,保证业务状态正确。
-
禁止动态扩容有序Topic分区:对有序业务专属Topic,上线后固定分区数,不做分区扩容,避免哈希路由错乱。
五、面试高频速记考点
-
Kafka天然有序范围:单分区有序,多分区全局无序。
-
局部有序核心:相同Key哈希到同一分区。
-
全局有序代价:单分区部署,牺牲并发、吞吐性能。
-
最常见乱序根源:生产者重试,最优解决:开启幂等生产者。
-
有序业务禁忌:动态扩容分区、多线程乱序发送、关闭幂等开启重试。
简洁:
-
分区内:严格保证发送顺序 = 消费顺序
-
全局有序:整个 Topic 只设置 1 个分区(牺牲并发换顺序)
-
乱序诱因:消息重试、多分区、异步发送、分区重平衡
8. 事务边界限制(生产落地&面试必考完整版)
Kafka 事务并非通用分布式事务,存在严格的边界约束,仅适用于特定流式数据场景,无法适配传统业务强事务场景。所有事务失效、提交失败、数据不一致问题,均源于对事务边界的认知不足,以下为全量生产级限制、原理解读与规避方案。
一、核心事务边界全量限制
1. 不支持跨集群、跨会话事务(核心硬限制)
Kafka 事务的生效范围仅限同一个集群、同一个客户端会话。单次事务操作只能针对当前集群的Topic,无法跨多个Kafka集群执行原子读写;客户端重启、会话断开后,未完成的事务会被判定为超时自动回滚,无法延续上一次会话的事务状态,不支持断点续事务。
2. 事务内禁止动态创建/删除/修改Topic
事务上下文仅用于消息读写、位移提交,不支持集群元数据变更操作。若在事务逻辑中执行创建Topic、删除Topic、修改分区/副本配置等操作,会直接导致事务提交失败、会话异常中断,生产事务代码中必须剥离所有元数据操作。
3. 事务消息与普通消息禁止混发
开启事务的生产者会话中,不允许同时发送普通非事务消息。一旦混发,会破坏事务原子性,导致部分消息提交、部分回滚错乱,同时触发Broker事务状态校验异常,造成消息丢失、重复或事务卡死。事务生产者全程只能发送事务消息。
4. 事务存在超时上限,无法无限延续
Kafka 事务有严格超时时间限制(默认60s,最大受Broker端transaction.max.timeout.ms管控),事务开启后,若超过超时时间未执行提交/回滚,集群会自动判定事务失效并强制回滚,释放事务资源。绝对不支持长事务、大批次耗时事务,耗时业务必须拆分。
5. 仅支持Kafka内部事务,不支持跨中间件/跨服务事务
Kafka事务是组件内局部事务,仅能保证同一个事务内、跨Kafka分区的读写原子性。无法联动MySQL、Redis、ES等第三方组件,也不支持跨微服务的分布式事务,无法实现业务层面的最终一致性,不能替代Seata、TCC等分布式事务方案。
6. 事务生产者存在PID绑定限制,重启易失效
事务生产者依赖全局唯一的transactional.id绑定固定PID,服务重启后会重新生成PID,未完成的旧事务无法续接,直接触发回滚。同时同一事务ID不允许多实例复用,否则会出现事务冲突、消息被拦截去重。
7. 事务不支持消费位移跨事务灵活提交
事务内的位移提交必须和消息读写原子绑定,无法实现"多次消费、一次统一提交"的自定义位移逻辑。批量消费、分批处理场景下,事务位移提交粒度固定,灵活度极低。
8. 高并发下事务性能损耗明显
事务机制依赖事务协调器状态校验、事务日志持久化、分区原子锁定,相较于普通生产消费,吞吐量下降30%~50%,高频小消息场景下性能损耗更严重,不适合超高吞吐纯流式场景。
二、事务失效高频场景(生产踩坑汇总)
-
事务内包含数据库读写、缓存更新等跨组件操作,期望整体原子一致性;
-
长耗时业务(大批量数据处理、远程调用)导致事务超时自动回滚;
-
事务生产者中途重启、网络波动,会话中断引发事务回滚;
-
同一事务ID多实例部署,引发事务状态冲突、消息去重异常;
-
事务逻辑中混用普通消息发送,破坏事务上下文。
三、精准适用场景(仅这些场景用Kafka事务)
仅适用于纯Kafka内部数据流转、无跨组件依赖的一致性场景:
-
Flink/Spark实时计算的Source→Sink精准一次性输出;
-
单业务多分区消息同步写入、保证全部成功/全部失败;
-
消费消息+提交位移的原子绑定,杜绝漏消费、重复消费;
-
流式数据修复、批量重跑的数据一致性保障。
四、生产规避方案(适配事务边界)
-
拆分长短事务:将耗时业务拆解为小粒度短事务,规避事务超时问题;
-
隔离事务与普通消息:独立事务生产者、普通生产者,禁止混用;
-
固定事务ID与实例映射:静态消费组+唯一事务ID,避免多实例冲突、重启失效;
-
跨组件事务外置处理:跨数据库/缓存的一致性,改用业务幂等+最终一致性、分布式事务框架兜底;
-
高吞吐场景禁用事务:日志、埋点等非强一致场景,放弃事务,用幂等替代。
五、面试极简背诵总结
-
Kafka事务是集群内、短耗时、纯消息、单会话局部原子事务;
-
不跨集群、不跨组件、不支持长事务、不混发消息、不支持元数据操作;
-
核心价值:保障流式数据Exactly Once,不解决业务分布式事务。
简洁:
-
事务不支持跨集群、跨会话
-
事务内不能动态创建 Topic
-
事务消息与普通消息不可混发
-
事务超时存在上限,不可无限延长
2.3 消费者详解
1. 消费模型
Kafka 核心采用客户端主动 Pull 拉取消费模型,区别于 RabbitMQ、RocketMQ 的服务端 Push 推送模型,是其适配高吞吐、海量数据、弹性消费场景的核心设计,下面从模型原理、推拉对比、消费分类、执行机制、生产适配、核心优缺点全维度补全。
一、核心模型原理
Kafka 消费者无被动接收逻辑,全程由消费者客户端主动发起 poll 轮询请求,主动向 Broker 拉取对应分区的批量消息,完成业务处理后,自主提交消费位移,完成一次完整消费闭环。Broker 仅负责存储消息、响应拉取请求,不会主动向客户端推送任何数据,完全将消费控制权交由客户端。
二、Pull 拉模型 vs Push 推模型(面试高频对比)
-
Kafka Pull 拉模型 核心逻辑:消费者主动轮询拉取消息 核心优势:消费流量完全可控,可根据自身CPU、内存、业务处理能力动态调节拉取频率、批量大小,完美适配消费能力波动场景;Broker无推送压力,极低的服务端开销,支撑超高吞吐集群。 核心短板:存在轮询空耗问题,无消息时会持续空轮询,需通过参数优化;低延迟实时性略弱于Push模型。 适配场景:高吞吐海量数据、消费能力不均、弹性扩容的流式场景。
-
传统MQ Push 推模型 核心逻辑:服务端主动将消息推送至消费者客户端 核心优势:实时性极强,消息抵达无延迟,适配即时消息投递场景。 核心短板:消费端能力不可控,服务端易推送过载,导致客户端消息积压、内存溢出、服务宕机,高并发场景容错性差。 适配场景:低吞吐、高实时、即时通知类业务。
三、三大消费类型(生产全覆盖)
1. 主动轮询消费(常规批量消费)
最主流生产消费方式,消费者通过循环调用 poll() 方法,批量拉取消息处理,可配置单次拉取条数、拉取超时、最小/最大字节数,兼顾吞吐与延迟,适配90%以上的业务场景。
2. 回溯消费(历史数据重跑)
支持手动重置消费位移,从分区最早/指定时间/指定位移位置拉取历史消息,用于数据修复、业务重跑、故障复盘、数据校对等运维场景,是Kafka独有的核心消费能力。
3. 实时长轮询消费(低延迟场景专用)
通过配置 fetch.max.wait.ms 实现长轮询机制:客户端拉取请求到达Broker后,若无新消息,请求会阻塞等待指定时长,期间有消息则立即返回,无消息则超时返回。既解决短轮询的空耗问题,又保障毫秒级实时消费,兼顾低延迟与资源节省。
四、消费并发执行模型(生产核心规范)
Kafka 消费并发严格遵循分区绑定并发原则,无跨分区抢占消费机制:
-
最小消费并发单元:单个分区只能被消费组内一个消费者实例消费,天然保证单分区串行消费、有序处理;
-
最大消费并发上限:消费组总并发数 ≤ Topic总分区数,超出分区数的消费实例会处于空闲状态,无法提升消费能力;
-
多线程消费规范:单个消费者实例不支持多线程并发消费(非线程安全),生产标准方案为多实例+单线程消费,通过扩容实例数量提升整体并发。
五、消费模型核心特性与生产约束
-
无消费抢占机制:分区分配后固定归属指定消费者实例,仅重平衡时会重新分配,消费过程无抢占,稳定性极强;
-
状态自主可控:消费位移、拉取频次、重试逻辑、消费暂停/恢复均由客户端自主控制,适配个性化业务消费逻辑;
-
天然支持批量消费:模型原生适配批量拉取、批量处理、批量位移提交,大幅提升高吞吐场景消费效率;
-
低资源开销:服务端无需维护客户端消费状态、无需主动推送数据,集群负载极低,支撑超大集群部署。
六、生产踩坑点与优化方案
-
空轮询CPU飙升:短轮询间隔过小导致无消息时频繁空请求,优化:配置合理的长轮询超时时间,减少空轮询次数;
-
消费延迟过高 :单次拉取批量过小、轮询间隔过大,优化:调优
max.poll.records、fetch.min.bytes参数,平衡吞吐与延迟; -
并发瓶颈无法突破:只扩容消费实例、不扩容分区,优化:优先规划充足分区数,再横向扩容消费实例;
-
有序消费失效:多线程消费单分区消息,优化:严格遵守单线程消费单分区,有序业务通过Key哈希绑定分区。
七、面试极简总结
-
Kafka消费模型核心:客户端主动Pull拉取、长轮询机制、消费端自主可控;
-
对比Push模型核心优势:流量可控、服务端低开销、适配高吞吐;
-
并发核心规则:分区决定消费并发,单分区单实例串行消费。
2. 消费位移 Offset 提交(生产核心+面试必考)
消费位移(Offset)是消费者的核心状态标识,位移提交本质是消费者将当前分区最新消费点位,持久化到集群系统Topic __consumer_offsets的过程。核心作用:标记消费进度、实现断点续消费、故障重启续跑、避免全局重消费,是管控消息丢失、重复消费的核心机制。
一、位移存储机制演进
-
旧版本(0.10.x及以下):消费位移默认持久化至Zookeeper,频繁读写ZK易引发性能瓶颈,高并发场景下存在位移更新延迟、丢失风险。
-
新版本(0.11.x及以上) :彻底迁移至**__consumer_offsets系统Topic**,以消息形式持久化位移数据,支持高并发读写、位移回溯、历史记录查询,稳定性与性能大幅提升,为目前生产通用方案。
二、两大提交方式全解(原理+优缺点+适用场景)
1. 自动提交(enable.auto.commit=true,默认开启)
核心原理:消费者客户端后台线程定时执行位移提交,无需业务代码手动干预,核心控制参数为 auto.commit.interval.ms(默认500ms)。客户端每间隔指定时间,自动将当前poll拉取的最新位移提交至集群。
核心优点:开发极简、零代码侵入、无需手动管控提交逻辑,适合快速开发、低优先级、非核心业务。
致命缺点(生产避坑核心)
-
极易出现消息丢失:自动提交是定时触发,若位移提交成功后,业务处理消息过程中宕机、报错,当前批次消息已标记消费完成,重启后会跳过该批次,直接导致消息丢失。
-
存在重复消费风险:若业务处理完成、位移未到自动提交时机,此时触发重平衡或服务宕机,重启后会从上次已提交位移继续消费,导致消息重复处理。
-
进度不可控:提交时机与业务处理进度解绑,无法精准匹配业务成功状态。
生产适用场景 :日志采集、用户埋点、非核心流式数据(允许少量消息丢失/重复)。核心业务禁止使用。
2. 手动提交(enable.auto.commit=false,生产主流)
核心原理:关闭自动提交,完全由业务代码控制提交时机,业务处理完全成功后再执行位移提交,实现「处理成功才标记消费」的精准管控,彻底规避消息丢失问题。分为同步提交、异步提交两种实现方式。
(1)同步提交 commitSync()
-
执行逻辑:调用提交方法后,主线程阻塞等待集群返回提交结果,提交成功/失败后才会继续执行后续逻辑。
-
核心优势:提交结果可控,失败可即时重试,位移数据绝对一致,无进度错乱风险。
-
核心短板:阻塞线程,占用消费耗时,高吞吐场景下会大幅降低消费吞吐量。
-
适用场景:核心交易、数据同步、强一致性业务,低吞吐、高可靠优先场景。
(2)异步提交 commitAsync()
-
执行逻辑:调用提交方法后,主线程立即释放继续消费,后台异步等待集群响应,不阻塞业务流程。
-
核心优势:无阻塞、消费效率高,适配高吞吐海量数据场景。
-
核心短板 :提交失败不会即时重试,存在位移覆盖风险(后提交的旧位移覆盖先提交的新位移),可能引发重复消费。
-
适用场景:高吞吐流式业务、大数据实时计算场景。
三、生产最优提交策略(实战落地方案)
-
常规核心业务:手动同步提交 + 失败重试,牺牲部分吞吐保障数据可靠;
-
高吞吐大数据业务:手动异步提交 + 回调校验 + 业务幂等,兼顾吞吐与一致性;
-
批量消费场景 :支持精准批量位移提交,可提交单条消息位移、批次最后位移,适配分批处理、部分成功场景。
四、位移提交失效与异常场景(高频踩坑)
-
重平衡引发位移失效:重平衡期间消费暂停,未提交位移的批次会被重新分配,触发批量重复消费;
-
网络超时导致提交失败:网络波动时提交请求超时,客户端无法确认结果,默认判定失败,重启后回溯消费;
-
自动提交时机错位:业务耗时超过自动提交间隔,出现「未处理完就提交位移」,引发消息丢失;
-
位移过期重置:消费离线时间过长,历史位移数据被集群清理,触发auto.offset.reset自动重置。
五、位移提交生产避坑规范
-
核心业务强制关闭自动提交,杜绝消息丢失风险;
-
位移提交必须后置:严格遵循「消息处理成功 → 执行业务落库 → 提交位移」顺序,禁止前置提交;
-
异步提交必须加回调监控:捕获提交异常,记录日志告警,关键场景补充重试机制;
-
批量消费禁止统一兜底提交:部分消息处理失败时,禁止提交整批次位移,需拆分批次、单独处理失败消息;
-
禁止跨业务共用消费组:避免位移错乱、互相覆盖,导致消费进度异常。
六、面试极简背诵总结
-
位移存储:新版存
__consumer_offsets,旧版存ZK; -
自动提交:简单但易丢消息,非核心业务可用;
-
手动同步:可靠、阻塞、低吞吐,核心业务首选;
-
手动异步:高效、有风险,高吞吐场景适配;
-
核心准则:业务成功再提交,所有重复靠幂等。
3. 位移重置规则 auto.offset.reset(生产核心+面试必考)
核心定义 :当消费者订阅的分区无有效消费位移 (新消费组、位移过期清理、位移数据丢失)时,集群无法识别消费进度,会根据该参数规则自动重置消费起始位移,是管控历史数据回溯、消息漏消费/重复消费的核心参数,仅在位移不存在/失效时生效,位移正常存在时该参数不生效。
一、三大重置规则详细解析
1. earliest(从头消费)
规则逻辑 :忽略所有历史消费记录,直接从分区当前存活的最早消息位移开始消费,完整读取分区内未被日志清理的全量历史数据。
核心适用场景:
-
业务数据误丢失、需要全量回溯修复数据;
-
新业务首次上线,需要同步历史存量数据;
-
消费组位移全部丢失,需要完整恢复消费进度。
生产特点 :大概率触发大批量历史消息重消费,流量瞬间暴涨,可能引发消费堆积、服务压力飙升,生产使用需提前评估集群与服务负载。
2. latest(默认配置,从最新消费)
规则逻辑 :直接定位到分区当前最新消息的下一位移,只消费重置之后新产生的消息,完全丢弃所有历史存量消息。
核心适用场景:
-
日志采集、用户埋点等允许丢失少量历史数据的非核心业务;
-
业务重启、临时重试,无需回溯历史数据;
-
日常线上发布、服务重启,保障业务实时接续。
生产特点 :无历史数据重放压力,启动速度快,流量平稳,但会丢失重置前所有未消费的历史消息,核心业务慎用。
3. none(严格模式,抛异常不自动重置)
规则逻辑 :不自动重置任何位移,当检测到分区无有效消费位移时,直接抛出异常,消费启动失败,交由人工处理位移问题。
核心适用场景:
-
金融交易、数据同步等零容忍数据丢失/错乱的核心业务;
-
需要精准管控消费进度,禁止系统自动兜底重置的场景;
-
生产故障排查、位移异常校验场景。
生产特点:安全性最高,杜绝系统自动重置导致的数据异常,但对运维要求高,位移失效需人工介入修复。
二、自动触发重置的4种核心场景(高频踩坑)
只有满足以下场景,auto.offset.reset 才会生效,正常续跑消费完全不触发:
-
全新消费组首次订阅Topic:消费组无任何历史位移记录,无消费进度可接续;
-
消费位移过期被清理 :消费组长期离线(默认7天无消费行为),
__consumer_offsets系统Topic自动清理过期位移数据; -
手动删除/重置消费组元数据:运维操作清空消费组位移、删除重建消费组;
-
集群元数据异常:ZK/KRaft元数据错乱、系统Topic异常,导致位移数据丢失。
三、手动重置位移生产场景(主动运维操作)
区别于自动重置,手动重置是人工主动运维行为,用于故障修复与数据重跑,生产高频场景:
-
业务消费逻辑BUG,导致数据处理错误,需要回溯历史数据重跑修复;
-
误提交位移、消费进度错乱,需要手动校准消费点位;
-
消息堆积过载,需要清空堆积、重置消费进度恢复业务;
-
新旧业务切换,需要跳过历史存量数据,只消费新流量。
四、生产选型规范(强制落地)
-
核心一致性业务(交易、数据同步、订单) :强制使用 none 模式,杜绝自动重置导致的数据丢失/重复;
-
非核心高吞吐业务(日志、埋点、监控) :默认使用 latest 模式,保障服务平稳启动;
-
数据修复、初始化同步场景 :临时切换为 earliest,数据同步完成后切回常规模式;
-
绝对禁止全局统一配置latest:核心业务会隐性丢失历史数据,线上故障极难排查。
五、高频面试极简总结
-
earliest:从头消费,回溯历史、修复数据用;
-
latest:从新消费,默认配置、保平稳、丢历史;
-
none:严格模式,无位移抛异常,核心业务安全首选;
-
核心前提:位移存在则不生效,仅位移失效才自动重置。
4. 消费者拦截器 & 反序列化异常(生产踩坑+实战解决方案)
一、消费者拦截器 ConsumerInterceptor
消费者拦截器是Kafka客户端提供的前置扩展机制,作用于消息拉取成功后、业务消费逻辑执行前,支持对批量消息做统一拦截、预处理、监控统计、日志埋点、消息过滤等通用操作,无需侵入核心消费业务代码,是生产规范化开发的核心手段。
1. 核心执行时机与流程
消费者拉取批量消息 → 触发拦截器预处理(批量执行) → 过滤/修改/统计消息 → 合法消息进入业务消费逻辑 → 消费完成后执行拦截器后置回调
核心特性:全局生效、批量处理、无业务侵入、支持多拦截器链式执行,所有订阅该Topic的消费消息都会经过拦截器校验。
2. 两大核心方法(源码核心)
-
onConsume(records):前置拦截方法,接收拉取到的原始消息批次,可对消息进行过滤、修改、丢弃、异常捕获,返回处理后的消息批次供业务消费;禁止返回null,否则会触发消费异常。
-
onCommit(offsets):后置回调方法,在消费位移提交成功后触发,可用于位移提交监控、消费进度统计、异常打点上报。
3. 生产通用实战场景
-
统一消息日志埋点:批量打印消息key、偏移量、生产时间、分区信息,统一链路追踪日志,便于故障溯源;
-
非法消息过滤:拦截空消息、格式异常消息、过期无效消息,避免脏数据进入业务逻辑导致消费卡死;
-
消息Header透传处理:统一解析链路追踪ID、灰度标记、来源服务标识,实现全链路追踪;
-
消费指标统计:批量统计单次消费条数、消息大小、消费耗时,上报监控指标;
-
统一权限与流量校验:拦截非法来源消息、超限超大消息,提前拦截异常流量。
4. 自定义拦截器开发规范(生产模板)
实现 ConsumerInterceptor 接口,重写核心方法,配置至消费者客户端参数,全局生效。核心开发禁忌:拦截器内禁止执行业务逻辑、禁止耗时IO、禁止阻塞线程,否则会大幅拖慢整体消费吞吐。
5. 多拦截器执行顺序
配置多个拦截器时,按配置顺序串行执行前置拦截,逆序执行后置回调,生产建议控制拦截器数量(1-2个即可),避免链式嵌套导致性能损耗。
二、反序列化异常(生产高频致命问题)
反序列化异常是消费者最常见的线上故障,核心场景为生产者消息格式变更、脏数据写入、序列化协议不匹配、消息体损坏 ,默认情况下,Kafka消费者遇到单条消息反序列化失败会直接抛出异常、终止消费、无限重试卡死,导致分区消费停滞、消息持续堆积,是生产核心避坑点。
1. 异常高频触发根因
-
前后端协议不兼容:生产者升级序列化字段、删除必填字段、修改字段类型,未做向下兼容,旧消费者无法解析新消息;
-
脏数据/空消息:生产者异常重试、网络抖动、代码BUG导致推送空体、残缺格式消息;
-
序列化协议不统一:生产者使用Json序列化,消费者配置Protobuf/Avro解析,协议完全不匹配;
-
消息损坏:磁盘异常、传输丢包、日志文件损坏,导致消息体不完整;
-
编码格式异常:消息编码错乱、特殊字符污染,导致解析失败。
2. 默认异常致命危害
-
单条脏消息异常卡死整个分区消费,同分区后续所有消息无法消费;
-
持续无限重试消费脏消息,CPU空转、日志刷屏,服务负载飙升;
-
长期堆积引发集群压力、消费延迟飙升、业务数据断层。
3. 生产级完整解决方案(最优落地)
方案一:自定义安全反序列化器(根治卡死问题)
抛弃原生默认序列化器,自定义全局异常捕获反序列化器,解析失败时不抛出终止异常,而是捕获异常、记录日志、上报监控,并封装异常消息向下传递,避免消费卡死。
方案二:异常消息自动转发死信队列(生产标准)
结合拦截器/异常处理器,捕获反序列化异常消息,自动将脏消息转发至独立死信Topic,跳过异常消息,保证正常消息持续消费,同时留存脏数据用于人工复盘修复,兼顾业务连续性与数据溯源。
方案三:严格保障消息格式向下兼容(事前预防)
-
序列化优先使用Protobuf/Avro结构化协议,支持字段兼容、版本迭代;
-
字段新增允许、字段删除/修改严格灰度,禁止直接强制变更;
-
生产上线前做新旧版本序列化兼容性测试。
方案四:空消息、脏消息前置过滤
通过消费者拦截器提前过滤空消息、超大小消息、格式非法消息,从源头规避反序列化异常。
4. Spring-Kafka 专属异常兜底配置
Spring-Kafka可通过配置 ErrorHandler 全局异常处理器,统一捕获反序列化异常,支持重试、死信转发、消息跳过策略,无需手动重复编码,是微服务项目主流方案。
三、面试极简背诵总结
-
消费者拦截器:前置批量预处理、无侵入、统一监控过滤,核心场景日志埋点、脏数据拦截、链路追踪;
-
反序列化异常根源:协议不兼容、脏数据、消息损坏、格式变更;
-
默认危害:单条异常卡死整个分区、无限重试、持续堆积;
-
生产最优解:自定义安全反序列化器 + 死信队列兜底 + 协议向下兼容。
5. 消费组重平衡 Rebalance(生产核心痛点+面试必考)
核心定义 :Rebalance(重平衡)是Kafka消费组为实现分区负载均衡触发的分区重新分配机制。当消费组订阅的分区数量、组内消费者实例数量发生变化,或实例心跳异常时,集群会收回所有已分配分区,重新按照分区分配策略将分区分配给组内在线消费者实例。
重平衡期间,整个消费组会暂停消费,所有消费者停止拉取消息,直至重平衡完成,是线上消费堆积、延迟飙升、重复消费的核心元凶之一。
一、完整触发场景(全覆盖,生产高频踩坑点)
重平衡触发分为主动变更触发 和异常被动触发两大类,其中被动触发是线上故障主要诱因:
1. 主动正常触发(人为运维/业务迭代)
-
消费组扩容/缩容:新增、下线消费实例,服务滚动发布、启停重启
-
Topic分区扩容:对已订阅Topic新增分区,分区总数变更触发重分配
-
订阅Topic变更:消费者新增/取消订阅Topic,订阅列表发生变化
2. 异常被动触发(线上高频故障根源)
-
心跳超时判定下线:消费者网络抖动、GC卡顿、线程阻塞,无法按时上报心跳,集群判定实例离线
-
消费处理超时 :业务消费逻辑耗时过长,超过
max.poll.interval.ms阈值,集群判定实例卡死下线 -
节点资源耗尽:消费者机器CPU、内存打满,线程卡死、进程假死,心跳线程无法正常工作
二、Rebalance完整执行底层流程
Kafka 2.4版本前后分为**老旧Eager机制**和**新式Incremental Cooperative(增量协作)机制**,流程差异极大:
1. 老旧Eager重平衡(默认旧机制)
-
组内任意实例触发重平衡条件,立即向协调器发送重平衡请求;
-
协调器通知组内所有消费者停止消费,立即释放手中所有分区;
-
所有实例重新加入消费组,等待分区重新分配;
-
按照分配策略统一分配全量分区,分配完成后恢复消费。
致命缺陷 :哪怕仅新增1个实例、仅1个分区需要迁移,也会触发全组分区释放+全量重分配,停顿时间长、影响范围极大。
2. 增量协作重平衡(Cooperative,2.4+新版)
-
触发重平衡后,仅释放需要迁移的分区,正常分区继续消费不中断;
-
分批完成分区迁移,无需全组停服、全量重分配;
-
重平衡过程中业务消费基本不中断,大幅降低延迟与堆积。
生产优势:精准缩小重平衡影响范围,是新版本集群优化消费稳定性的核心特性。
三、重平衡带来的四大核心危害(生产致命问题)
1. 消费暂停,消息堆积飙升
重平衡全程消费停滞,上游生产流量持续写入,下游无消费动作,瞬时引发海量消息堆积、消费延迟持续走高,高吞吐业务极易击穿磁盘容量阈值。
2. 大规模重复消费(数据错乱核心)
重平衡前消费者已处理完消息,但未来得及提交位移,分区被强制回收后重新分配,新持有者会从旧位移继续消费,导致大批量消息重复处理,引发数据重复统计、业务重复执行等问题。
3. 分区负载瞬时倾斜
重平衡期间分区分配混乱,部分实例持有大量分区、负载爆满,部分实例空闲,出现瞬时消费不均,整体集群吞吐大幅下降。
4. 业务监控告警刷屏
消费TPS抖动、延迟飙升、堆积突增、实例上下线告警集中触发,干扰运维故障排查,掩盖真实线上问题。
四、生产级全方位优化方案(根治频繁重平衡)
1. 参数调优(核心参数精准适配)
-
session.timeout.ms(会话超时):默认10s,生产调至30s,避免轻微网络抖动、短时GC触发误下线;
-
heartbeat.interval.ms(心跳间隔):默认3s,设置为会话超时的1/3(10s),平稳上报心跳,减少超时概率;
-
max.poll.interval.ms(最大消费间隔):根据业务耗时调大(默认30s,复杂业务调至60s+),避免业务慢消费被判定为卡死;
-
max.poll.records(批量条数):合理减小批量消费条数,避免单次消费耗时过长,频繁触发超时。
2. 架构机制优化(最优根治方案)
-
启用静态消费组(Static Group) :配置
group.instance.id唯一实例标识,滚动发布、短时重启、网络抖动不触发重平衡,仅实例永久下线才触发; -
开启增量协作重平衡 :2.4+版本配置
partition.assignment.strategy=cooperative-sticky,实现局部分区迁移,避免全组停顿; -
固定Topic分区数:业务稳定后禁止随意扩容分区,从源头规避分区变更触发的重平衡。
3. 运维发布规范(杜绝人为触发)
-
灰度滚动发布:单实例启停、分批发布,避免多实例同时下线引发大规模重平衡;
-
避开流量高峰期发布:业务低峰期迭代,降低重平衡带来的堆积影响;
-
禁止频繁启停服务:规范测试、运维操作,避免人为频繁重启服务触发无效重平衡。
4. 业务代码优化(规避超时触发)
-
消费逻辑异步解耦:将耗时业务(IO、数据库查询、复杂计算)异步处理,保证poll方法快速响应;
-
规避长阻塞操作:消费链路禁止同步阻塞、长事务、死循环逻辑;
-
优化GC与机器资源:升级机器配置、优化JVM参数,避免频繁Full GC导致心跳中断。
五、面试高频极简总结(直接背诵)
-
核心本质:消费组分区重新分配机制,用于实现负载均衡;
-
三大触发核心:实例启停扩缩容、分区数变更、心跳/消费超时;
-
两大危害:消费暂停堆积、大批量重复消费;
-
最优解决方案:静态消费组 + 增量粘性分配策略 + 合理参数调优 + 规范发布流程。
6. 静态消费组 Static Group Membership(2.3+ 生产核心优化)
核心定义 :Kafka 2.3 版本推出的静态消费组机制,通过为每个消费实例配置唯一固定的实例ID(group.instance.id) ,替代默认动态随机实例ID,实现实例重启、短时网络抖动、容器重建场景下不触发重平衡(Rebalance),是生产解决频繁重平衡、消费抖动的核心最优方案。
设计背景(动态消费组痛点):默认动态消费组中,服务每次重启、短暂离线,都会生成全新随机实例ID,集群判定为旧实例下线、新实例上线,强制触发全组重平衡,导致消费暂停、重复消费、业务抖动,滚动发布场景尤为严重。
一、核心核心机制原理
-
唯一实例标识 :手动为每个消费实例配置固定
group.instance.id(全局唯一,绑定实例节点/容器),集群会永久记录该实例与分区的绑定关系。 -
离线容错机制:实例短暂离线(重启、网络抖动、容器临时重建),集群不会立即清除该实例的分区分配记录,会等待实例重连。
-
无重平衡恢复 :实例在超时时间内重新上线,集群直接恢复原有分区分配关系,全程不触发Rebalance,消费无缝续跑。
-
永久下线判定:仅当实例长时间离线、超过集群保留阈值,才会判定为永久下线,触发一次重平衡回收分区。
二、核心配置参数(生产必配)
-
group.instance.id :静态实例唯一ID,自定义全局唯一标识(如机器IP+端口、容器ID、服务实例序号),每个实例配置不同值。
-
session.timeout.ms:会话超时时间,生产建议30s+,适配实例重启、短时GC卡顿场景。
-
group.max.session.timeout.ms:集群最大会话超时阈值,需大于客户端配置的session超时,避免参数不生效。
-
consumer.group.instance.id.expire.ms(新版3.x):静态实例离线过期时间,超时未重连则永久剔除,触发重平衡。
三、静态VS动态消费组核心对比
| 对比维度 | 动态消费组(默认) | 静态消费组(推荐) |
|---|---|---|
| 实例ID生成 | 服务启动随机生成,每次重启变更 | 手动固定配置,永久不变 |
| 滚动发布 | 每重启一个实例触发一次重平衡 | 滚动发布零重平衡 |
| 短时网络抖动/GC | 极易误判下线,触发重平衡 | 容忍短时离线,无重平衡 |
| 分区稳定性 | 分区频繁迁移,负载波动大 | 分区绑定固定实例,极度稳定 |
| 重复消费概率 | 高(频繁重平衡导致) | 极低 |
| 适用场景 | 测试环境、低频启停服务 | 生产环境、需频繁迭代发布服务 |
四、生产适用场景(全覆盖)
-
服务滚动发布迭代:微服务常态化灰度发布、分批重启,彻底杜绝发布引发的批量重平衡与消费堆积。
-
容器化云原生部署:K8s环境容器临时重建、节点漂移、弹性扩缩容短时离线场景。
-
高稳定核心业务:订单、交易、数据同步、实时计算等禁止消费中断、禁止重复消费的核心链路。
-
网络波动环境:跨机房、弱网、内网网络抖动频繁的集群环境。
五、生产局限性与避坑规范
-
实例ID必须全局唯一:同一消费组内禁止重复ID,否则会导致分区分配冲突、消费错乱。
-
不支持动态扩缩容 :静态组运行期间,手动新增/删除消费实例,不会自动触发重平衡,无法实现负载均衡;扩缩容需手动重启整个消费组或等待实例过期。
-
僵尸实例残留风险:废弃实例未正常下线、ID未清理,会长期占用分区,导致新实例空闲、消费负载不均,需定期清理无效静态实例ID。
-
版本限制:仅2.3及以上版本支持,低版本集群无法使用该特性。
六、生产最佳落地组合方案
静态消费组 + 增量粘性分区策略(cooperative-sticky)+ 合理超时参数调优,彻底根治生产99%的非人为频繁重平衡问题,是当前Kafka生产消费稳定性的最优解决方案。
七、面试极简必背总结
-
核心作用:固定实例ID,规避重启、抖动、发布引发的重平衡,提升消费稳定性;
-
核心优势:滚动发布零重平衡、减少重复消费、杜绝无效消费堆积;
-
核心短板:不支持动态扩缩容、需手动管理实例ID、存在僵尸实例风险;
-
生产标配:2.3+生产集群核心业务强制开启。
7. 分区分配策略(生产+面试核心完整版)
Kafka 分区分配策略,是消费组发生重平衡时,将Topic的所有分区公平分配给组内在线消费者实例的核心算法,直接决定消费负载均衡度、重平衡开销、分区稳定性,是解决消费倾斜、频繁分区迁移的核心底层配置。Kafka 主流提供三种官方分配策略,不同版本默认策略不同,生产优先使用粘性策略,以下为全维度深度拆解。
版本前置说明 :2.4版本前默认 Range 策略;2.4及以上版本默认 Sticky(粘性策略),同时支持增量协作模式,大幅优化重平衡性能。
(1)Range 区间分配策略(旧版默认)
-
核心算法原理:针对每个Topic独立计算分区分配,将Topic的分区按序号均匀划分为N个区间(N为消费组在线实例数),每个消费者实例固定分配一个区间内的连续分区。
-
分配示例:某Topic有8个分区(0-7),消费组4个实例,平均每个实例分配2个连续分区;若分区数无法被实例数整除,靠前的实例会多分配1个分区。
-
核心优点:算法简单、计算高效、分区分配连续,同实例下分区索引集中,缓存命中率高。
-
致命缺点(生产高频坑点) :多Topic场景极易出现负载倾斜 。多个Topic同时分配时,靠前的消费者会持续多分配分区,累积负载过高,后端实例空闲,导致整体消费吞吐不均。 重
-
平衡开销:重平衡后分区分配完全打乱,无历史继承,分区迁移量大。
-
适用场景 :单Topic消费、实例数与分区数整除、简单低频消费场景,生产高吞吐多Topic业务禁止使用。
(2)RoundRobin 轮询分配策略
-
核心算法原理:将当前订阅的所有Topic的所有分区,按分区序号扁平化排序,以轮询方式依次分配给组内所有消费者实例,跨Topic均衡打散分区。
-
分配示例:订阅2个Topic(各8分区),4个消费实例,分区会交叉轮询分配到各个实例,彻底打散单实例集中分区问题。
-
核心优点 :全局负载最均衡,多Topic、多分区场景下,所有消费者实例负载基本一致,无明显倾斜。
-
核心缺点 :每次重平衡都会全量重新轮询分配,完全抛弃历史分区绑定关系,分区迁移数量极大,重平衡耗时高、消费停顿久、重复消费范围广。
-
重平衡开销:极大,全量分区重新分配,业务抖动明显。
-
适用场景:负载倾斜严重、多Topic批量消费、对重平衡短暂抖动可容忍的业务。
(3)Sticky 粘性分配策略(新版默认+生产最优)
-
核心算法原理 :核心设计为「均衡优先+历史绑定」,首次分配尽量保证全局负载均衡;发生重平衡时,最大限度保留原有分区与消费者的绑定关系,仅迁移少量分区弥补负载不均,无需全量重分配。
-
两大核心优势: 2.1 初始化分配:具备RoundRobin的均衡性,彻底解决Range策略的负载倾斜问题; 2.2 重平衡分配:具备极强的粘性,仅迁移必要分区,大幅减少分区迁移数量。
-
增量协作优化(2.4+) :搭配
cooperative-sticky模式,支持局部重平衡,仅释放需要迁移的分区,其余分区持续消费,全程无大规模消费停顿。 -
核心优点:兼顾负载均衡与重平衡稳定性,分区迁移量最小、重平衡耗时最短、重复消费范围极小、业务抖动最低。
-
核心缺点:算法复杂度高,低版本Kafka不支持,需手动配置启用。
-
适用场景 :100%生产通用,高吞吐、高稳定、禁止频繁抖动的核心业务,滚动发布、云原生容器化场景首选。
一、三种策略核心全方位对比(面试速记表)
|-----------|--------------|--------------|------------|
| 对比维度 | Range策略 | RoundRobin策略 | Sticky粘性策略 |
| 负载均衡性 | 差,多Topic严重倾斜 | 最优,全局绝对均衡 | 优秀,均衡且稳定 |
| 重平衡分区迁移量 | 大 | 极大 | 极小(仅增量迁移) |
| 消费抖动/堆积风险 | 中 | 高 | 极低 |
| 重复消费范围 | 部分重复 | 大范围重复 | 局部少量重复 |
| 算法性能 | 快 | 中等 | 稍慢(复杂度高) |
| 生产推荐度 | 不推荐 | 按需临时使用 | 全员强制推荐 |
二、生产标准配置方式(Spring-Kafka)
2.4+版本生产最优配置,开启增量粘性分区策略,彻底优化重平衡稳定性:
partition.assignment.strategy=org.springframework.kafka.support.serializer.CooperativeStickyPartitionAssignor
低版本集群(2.2-2.3)可配置普通粘性策略: partition.assignment.strategy=StickyPartitionAssignor
三、生产避坑核心规范
-
禁止新版集群使用默认Range策略,规避多Topic负载倾斜导致的消费瓶颈;
-
RoundRobin仅用于临时解决负载不均,长期运行会频繁触发全量重分配,不适合常态化生产;
-
粘性策略+静态消费组是生产黄金组合,可实现滚动发布零重平衡、分区零迁移;
-
分区分配策略为消费组维度配置,同集群不同消费组可独立配置,互不影响。
四、面试极简必背总结
-
Range:区间分配、简单但多Topic倾斜严重,旧版默认;
-
RoundRobin:轮询均衡、但重平衡全量迁移、抖动大;
-
Sticky:兼顾均衡与稳定、增量迁移、重平衡开销最小,生产首选;
-
最优方案:Cooperative-Sticky粘性策略 + 静态消费组,根治生产重平衡问题。
8. 核心消费参数(生产全量参数+调优手册)
本节整理生产环境所有核心消费者参数,包含参数释义、推荐值、调优场景、面试考点及生产避坑点,覆盖消费稳定性、批量性能、重平衡、位移提交全维度,是解决消费堆积、重复消费、频繁重平衡的核心配置依据。
一、位移提交核心参数(消息可靠性核心)
(1)enable.auto.commit
释义:是否开启消费者自动提交消费位移
取值:true(默认)/ false
生产推荐:核心业务强制false,非核心简单业务可true
调优说明:自动提交存在位移超前、重复消费风险;手动提交可精准控制位移提交时机,保证「业务消费成功→再提交位移」,彻底杜绝消息丢失。
释义:自动提交位移的时间间隔
默认值:5000(5秒)
生产调优:开启自动提交时,可缩短为1000~2000ms,减少重启重复消费范围; 避坑:间隔过小会增加集群元数据压力,过大会导致大批量重复消费。
(3)auto.offset.reset
释义:消费位移越界、无历史消费位点时的位移重置策略(面试必考)
取值说明:
-
earliest:重置到分区最早位移,全量回溯历史消息
-
latest(默认):重置到分区最新位移,只消费新消息
-
none:不自动重置,直接抛出异常
生产规范:数据同步、数据复盘业务用earliest;日常业务、日志埋点业务用latest;核心对账业务禁用none,避免消费报错中断。
二、重平衡与心跳超时参数(消费稳定性核心)
释义:消费者会话超时时间,集群判定实例离线的核心阈值
默认值:10000(10秒)
生产推荐:30000~60000(30~60秒)
调优场景:服务存在短时GC、接口卡顿、网络抖动时,调大阈值,避免集群误判实例下线,触发无效重平衡。
释义:消费者向集群发送心跳的间隔时间
默认值:3000(3秒)
生产规范:固定为 session.timeout.ms 的1/3,保证心跳频次充足,稳定保活。
释义:两次poll拉取消息的最大间隔时间,超时判定实例卡死,触发重平衡
默认值:300000(5分钟)
生产调优:根据业务消费耗时调整,若单批次业务处理耗时较长,需同步调大该值;
避坑:业务阻塞、数据库慢查询导致超时,是生产频繁重平衡、批量重复消费的核心诱因。
三、批量消费与拉取参数(消费性能核心)
(1)max.poll.records
释义:单次poll拉取的最大消息条数(批量消费核心参数)
默认值:500条
生产调优:
-
高吞吐业务:调至1000~2000条,提升批量处理效率,减少网络IO开销;
-
低延迟、实时业务:调至100~200条,缩小单次处理批次,降低故障重复消费范围;
-
耗时业务(IO/DB操作多):减小批次,避免单次处理超时触发重平衡。
四、流量阈值与延迟控制参数(精准控速)
(1)fetch.min.bytes
释义:服务端返回消息的最小字节数,攒够对应数据量才响应消费请求
默认值:1字节
调优场景:高吞吐、低实时性业务,调大至10KB~50KB,批量攒数据,减少网络交互次数,提升吞吐。
释义:服务端最大等待超时时间,未达到最小字节数也会超时返回数据
默认值:500ms
调优场景:实时业务缩小至100ms,降低端到端延迟;高吞吐业务维持默认,优先保证批量性能。
(3)fetch.max.bytes
释义:单次拉取消息的最大总字节数
默认值:50MB
生产规范:根据单条消息大小调整,必须大于业务最大消息大小,避免消息拉取失败导致消费卡死。
五、重试与异常兜底参数(故障容错)
(1)retries
释义:消费失败后的重试次数
默认值:0 生产推荐:3~5次,适配临时网络抖动、瞬时数据库异常;
避坑:需配合重试间隔,避免高频重试压垮下游服务。
释义:每次重试的时间间隔
默认值:100ms
生产调优:核心业务调至500~1000ms,阶梯重试,规避瞬时故障。
六、高级稳定性参数(生产进阶必备)
(1)client.id
释义:消费者客户端唯一标识,用于日志、监控、异常溯源
生产规范:手动配置为「服务名-环境-实例序号」,便于故障定位。
(2)receive.buffer.bytes
释义:客户端TCP接收缓冲区大小
默认值:64KB 高吞吐场景
调优:调至128KB~256KB,提升网络数据接收能力。
(3)enable.auto.dns.lookup
释义:自动DNS解析
生产规范:开启,适配容器化、动态IP集群环境。
七、生产参数黄金配置模板(直接复用)
1. 高吞吐日志/埋点业务(优先性能)
XML
enable.auto.commit=false
max.poll.records=1000
fetch.min.bytes=20480
fetch.max.wait.ms=500
session.timeout.ms=30000
heartbeat.interval.ms=10000
max.poll.interval.ms=3000002. 实时交易/数据同步业务(优先稳定、低延迟)
XML
enable.auto.commit=false
max.poll.records=200
fetch.min.bytes=1024
fetch.max.wait.ms=100
session.timeout.ms=60000
heartbeat.interval.ms=20000
max.poll.interval.ms=600000八、面试高频必背总结
-
自动提交适合低优先级、简单业务,核心业务必须手动提交位移保可靠;
-
max.poll.interval.ms 是卡死重平衡的核心关键,需匹配业务处理耗时;
-
心跳间隔固定为会话超时1/3,是生产最优稳活配置;
-
批量大小(max.poll.records)需权衡吞吐与故障影响范围,越大吞吐越高、重复消费范围越大。
简洁:
-
enable.auto.commit:是否自动提交位移 -
auto.commit.interval.ms:自动提交间隔 -
session.timeout.ms:会话超时时间 -
heartbeat.interval.ms:心跳发送间隔 -
max.poll.records:单次拉取消息条数(批量消费) -
max.poll.interval.ms:两次拉取最大间隔,超时判定实例宕机 -
fetch.min.bytes/fetch.max.wait.ms:拉取批量阈值
9. 多线程消费规范(企业实战+可上线代码)
本节为生产级多线程消费标准方案,彻底解决网上普遍存在的「单Consumer多线程并发消费」错误写法,明确企业强制规范、核心原理、优缺点、适用场景,附带原生Java客户端、Spring-Kafka双版本可直接复用的实战代码,适配高吞吐、有序消费、无重复、无数据丢失生产场景。
一、企业核心强制规范(零容错底线)
- 核心铁律:一线程一Consumer实例
KafkaConsumer 是非线程安全类,绝对禁止一个Consumer实例被多线程并发调用poll()、consume、commit ,会引发分区消费错乱、消息乱序、位移提交异常、数据丢失、重平衡崩溃等致命问题。生产唯一合法写法:每个消费线程独立持有一个Consumer实例。
- 并发上限约束
单实例消费线程数 ≤ Topic总分区数,多余线程会处于空闲状态,无法提升消费并发;想要突破并发上限,只能扩容服务实例或扩容Topic分区。
- 有序消费强制约束
若业务需要单分区消息有序,必须保证:一个分区始终被同一个线程消费,禁止跨线程抢占分区,否则彻底丧失有序性。
- 位移提交规范
多线程消费必须使用手动位移提交,禁止自动提交;单线程消费批次处理完成后,再提交对应分区位移,杜绝部分成功、部分失败导致的数据错乱。
- 优雅停机强制要求
多线程场景必须实现优雅停机,关闭时停止拉取消息、等待现有线程任务执行完毕、批量提交最终位移、关闭Consumer资源,避免进程强制终止导致的重复消费、数据堆积。
二、多线程消费架构原理
Kafka多线程消费采用「线程池+独立Consumer+分区独占」架构:
-
消费组分配分区后,每个分区只会分配给组内一个Consumer实例(一个线程);
-
每个线程独立执行poll拉取消息、业务处理、位移提交,线程间互不干扰;
-
天然保证单分区消息有序,多分区并行消费,兼顾性能与数据正确性;
-
重平衡时整体线程池重启,重新绑定分区与线程关系,稳定性可控。
三、原生Java客户端多线程实战代码(可直接上线)
适用场景:自研消费框架、底层中间件、无Spring依赖项目
java
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicBoolean;
/**
* Kafka 原生多线程消费 生产级代码
* 核心规范:一线程一Consumer、手动提交、优雅停机、单分区有序
*/
public class KafkaMultiThreadConsumer {
// 线程数:建议等于topic分区数,最大化并发
private static final int CONSUMER_THREAD_NUM = 8;
// 消费主题
private static final String TOPIC = "business_order_topic";
// 消费组
private static final String GROUP_ID = "business_order_group";
// Kafka集群地址
private static final String BOOTSTRAP_SERVERS = "127.0.0.1:9092";
// 线程池
private final ExecutorService consumerThreadPool;
// 停机标识
private final AtomicBoolean isRunning = new AtomicBoolean(true);
public KafkaMultiThreadConsumer() {
this.consumerThreadPool = Executors.newFixedThreadPool(CONSUMER_THREAD_NUM);
}
/**
* 初始化消费者配置(生产最优参数)
*/
private Properties buildConsumerProps() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 核心配置:手动提交位移(生产强制)
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 单次拉取最大条数,适配批量消费
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
// 会话超时、心跳间隔、拉取超时 生产黄金配置
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000);
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 10000);
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000);
// 位移重置策略:无历史位点消费最新消息
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return props;
}
/**
* 单线程消费任务(每个线程独立Consumer)
*/
private class ConsumerTask implements Runnable {
@Override
public void run() {
// 每个线程独立创建Consumer实例,核心规范!
try (Consumer<String, String> consumer = new KafkaConsumer<>(buildConsumerProps())) {
// 订阅主题
consumer.subscribe(Collections.singletonList(TOPIC));
// 循环消费
while (isRunning.get()) {
// 拉取消息,超时时间100ms
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (records.isEmpty()) {
continue;
}
// 执行业务逻辑(批量处理)
handleBusiness(records);
// 业务执行成功后,手动批量提交位移
consumer.commitSync();
}
} catch (Exception e) {
// 全局异常兜底,避免线程死亡
e.printStackTrace();
}
}
/**
* 自定义业务处理逻辑
*/
private void handleBusiness(ConsumerRecords<String, String> records) {
records.forEach(record -> {
String msgKey = record.key();
String msgValue = record.value();
// 业务处理:订单消费、数据统计、日志解析等
System.out.printf("线程:%s, 分区:%d, 位移:%d, 消息:%s%n",
Thread.currentThread().getName(), record.partition(), record.offset(), msgValue);
});
}
}
/**
* 启动多线程消费
*/
public void start() {
for (int i = 0; i < CONSUMER_THREAD_NUM; i++) {
consumerThreadPool.execute(new ConsumerTask());
}
System.out.println("Kafka多线程消费启动成功,线程数:" + CONSUMER_THREAD_NUM);
}
/**
* 优雅停机
*/
public void stop() {
isRunning.set(false);
consumerThreadPool.shutdown();
System.out.println("Kafka多线程消费优雅停机完成");
}
public static void main(String[] args) {
KafkaMultiThreadConsumer consumer = new KafkaMultiThreadConsumer();
consumer.start();
}
}四、Spring-Kafka多线程企业实战代码(微服务主流)
Spring-Kafka简化多线程配置,通过concurrency参数一键开启多线程消费,底层自动实现「一线程一Consumer」,是微服务生产首选方案。
- 核心配置(application.yml)
XML
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
consumer:
group-id: business_order_group
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 手动提交位移(生产核心)
enable-auto-commit: false
# 批量拉取条数
max-poll-records: 500
# 位移重置策略
auto-offset-reset: latest
# 会话心跳超时配置
session-timeout-ms: 30000
heartbeat-interval-ms: 10000
max-poll-interval-ms: 300000
listener:
# 手动提交模式
ack-mode: manual_batch
# 多线程数量(核心参数,等于分区数最优)
concurrency: 8
# 开启增量粘性分区策略,杜绝重平衡抖动
partition-assignor: cooperative-sticky- 批量多线程消费业务代码
java
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
/**
* Spring-Kafka 多线程批量消费 生产级代码
* 自动根据concurrency参数创建对应消费线程,一线程一Consumer
*/
@Component
public class OrderMultiThreadConsumer {
/**
* 批量消费监听
* 适配多线程、批量处理、手动位移提交、异常兜底
*/
@KafkaListener(topics = "business_order_topic", batch = true)
public void consume(ConsumerRecords<String, String> records, Acknowledgment ack) {
try {
// 批量业务处理
records.forEach(record -> {
// 自定义业务逻辑
handleOrderMsg(record.key(), record.value());
});
// 全部处理成功后,批量提交位移
ack.acknowledge();
} catch (Exception e) {
// 异常兜底:根据业务需求选择重试、死信转发
e.printStackTrace();
// 禁止直接ack,避免异常消息跳过,可自定义重试逻辑
}
}
/**
* 订单消息业务处理
*/
private void handleOrderMsg(String key, String value) {
// 业务逻辑:订单状态更新、积分发放、消息通知等
}
}五、生产级参数适配方案
-
高吞吐日志/埋点业务:concurrency=8~16、max-poll-records=1000,最大化批量吞吐;
-
实时交易/有序业务:concurrency=分区数、max-poll-records=200,缩小故障重复消费范围,保证有序;
-
耗时IO/数据库业务:适当降低并发、调大max-poll-interval-ms,避免业务阻塞触发重平衡。
六、多线程消费常见坑点&解决方案
-
错误写法:单Consumer多线程并发消费 问题:线程安全问题、消息乱序、位移错乱 解决:严格遵守一线程一Consumer
-
线程数大于分区数,并发不生效 问题:多余线程空闲,无法提升吞吐 解决:线程数≤分区数,扩容优先扩分区、扩实例
-
多线程消费导致消息乱序 问题:跨线程抢占同一分区消息 解决:Kafka默认分区独占,无需手动处理,禁止自定义分区抢占逻辑
-
批量消费部分失败,数据不一致 问题:部分消息处理成功、部分失败,位移已提交 解决:手动提交位移,失败不ack,搭配死信队列隔离异常消息
-
频繁重平衡导致多线程批量重复消费 解决:开启cooperative-sticky粘性策略、调优心跳超时、使用静态消费组
七、面试速记总结
-
多线程消费核心:一线程一Consumer,Consumer非线程安全;
-
并发上限由分区数决定,线程数不可超分区数;
-
生产必须手动提交位移,搭配批量消费+优雅停机;
-
Spring-Kafka通过concurrency控制线程数,底层自动实现安全多线程模型;
-
最优组合:多线程批量消费 + 粘性分区策略 + 静态消费组,兼顾性能与稳定性。
简洁:
-
原则:单个消费实例内,消费线程数 ≤ 分区数,多余线程空闲。
-
禁忌:一个
KafkaConsumer多线程并发消费(非线程安全,会乱序、丢数据)。 -
标准写法:一线程一 Consumer 实例。
10. 批量消费异常处理(生产级全方案补全)
批量消费是Kafka生产主流消费模式,核心痛点为批次部分消息成功、部分失败,默认批量提交位移会导致异常消息丢失,盲目重试会引发死循环、数据重复堆积、业务错乱等线上问题。本节全覆盖异常场景、多级容错策略、可直接上线的代码实现、死信闭环、生产规范与面试考点,彻底解决批量消费稳定性问题。
一、批量消费核心异常场景(线上高频)
批量消费一次性拉取多条消息(max.poll.records配置),业务处理中任意单条消息异常,会衍生三类核心问题:
-
数据一致性问题:批次内部分消息处理成功、部分失败,批量提交位移后,失败消息永久丢失;
-
异常死循环问题:不提交位移、整体重试批次,导致正常消息重复消费,异常消息无限重试堆积;
-
集群雪崩问题:大量异常消息持续重试占用线程、IO资源,导致正常业务消费阻塞、集群负载飙升。
二、生产主流三级容错方案(按优先级排序)
1. 分级重试策略(轻度异常兜底)
针对网络抖动、数据库瞬时超时、接口短暂不可用等可自愈临时异常,配置有限次数重试,规避偶发故障,无需人工干预。
-
重试规则:区分可重试异常(网络超时、连接失败)和不可重试异常(参数非法、数据不存在、权限错误),不可重试异常直接跳过,不占用重试次数;
-
重试次数与间隔:生产默认3次重试,采用指数退避策略(1s、3s、5s),避免频繁重试打垮下游服务;
-
核心约束 :重试过程中禁止批量提交位移,全部重试失败后,进入死信队列流程。
2. 批次拆分单条处理(核心兜底方案,生产首选)
批量消费触发异常后,放弃批量处理逻辑,将当前批次消息逐条拆分消费,精准定位异常消息,保障正常消息执行成功,仅隔离异常数据,最大化减少数据影响范围。
-
执行流程:批量处理报错 → 捕获全局异常 → 清空批量上下文 → 遍历单条消息独立处理 → 正常消息逐条提交位移 → 异常消息单独标记;
-
核心优势:避免"一条异常、全批次陪葬",最大限度保障数据完整性,适配绝大多数生产业务场景;
-
性能取舍:仅异常场景触发单条降级,正常场景保持批量高吞吐,兼顾性能与稳定性。
3. 死信队列DLQ隔离(最终兜底闭环)
针对重试耗尽、业务非法、数据损坏等不可自愈异常消息,统一转发至专属死信Topic,彻底脱离正常消费链路,避免阻塞主业务,同时留存异常数据用于人工排查、批量修复重跑。
-
死信Topic规范:命名规则统一为「原Topic-dlq」,独立分区、独立副本,与主业务Topic物理隔离;
-
异常数据留存:转发时追加异常日志、报错时间、消费组、节点信息,便于问题溯源;
-
定期运维:每日监控死信队列堆积量,定期复盘异常原因、批量修复重跑,杜绝异常数据堆积遗忘。
三、生产禁止的错误处理方式(线上高危坑点)
-
禁止异常后直接批量提交位移:会直接丢弃批次内所有未处理消息,造成永久数据丢失;
-
禁止异常不提交位移直接重试:异常消息无限重试,阻塞整个分区消费,引发大规模消息堆积;
-
禁止try-catch全局吞异常:隐藏线上故障,无法感知数据异常,导致业务数据静默错乱;
-
禁止批量异常后重启服务:触发消费者重平衡,加剧重复消费与数据混乱。
四、Spring-Kafka 生产级异常处理代码(可直接上线)
整合「批量消费+异常拆分+分级重试+死信转发+手动位移提交」完整能力,适配微服务生产场景,零数据丢失、零无限重试。
java
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* Kafka批量消费异常处理 生产级实现
* 核心能力:批量正常消费、异常拆分单条处理、分级重试、死信隔离、精准位移提交
*/
@Slf4j
@Component
public class BatchConsumerExceptionHandler {
// 主业务Topic
private static final String BUSINESS_TOPIC = "business_order_topic";
// 死信Topic
private static final String DLQ_TOPIC = "business_order_topic-dlq";
// 最大重试次数
private static final int MAX_RETRY_TIMES = 3;
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 批量消费核心方法
*/
@KafkaListener(topics = BUSINESS_TOPIC, batch = true)
public void consume(ConsumerRecords<String, String> records, Acknowledgment ack) {
if (CollectionUtils.isEmpty(records)) {
return;
}
try {
// 正常场景:批量处理业务,高性能
batchHandleBusiness(records);
// 全部成功后批量提交位移
ack.acknowledge();
} catch (Exception e) {
// 批量异常:降级为单条处理,精准隔离异常数据
log.error("批量消费异常,降级单条处理,批次大小:{}", records.count(), e);
singleHandleWithRetry(records, ack);
}
}
/**
* 批量业务处理逻辑
*/
private void batchHandleBusiness(ConsumerRecords<String, String> records) {
records.forEach(record -> {
// 批量执行业务逻辑:数据清洗、状态更新、统计计算等
handleMsg(record.key(), record.value());
});
}
/**
* 单条带重试处理 + 死信兜底
*/
private void singleHandleWithRetry(ConsumerRecords<String, String> records, Acknowledgment ack) {
records.forEach(record -> {
String key = record.key();
String value = record.value();
boolean isSuccess = false;
// 分级重试机制
for (int i = 0; i < MAX_RETRY_TIMES; i++) {
try {
handleMsg(key, value);
isSuccess = true;
break;
} catch (Exception e) {
log.warn("单条消息消费失败,重试次数:{},key:{}", i + 1, key, e);
// 指数退避等待
try {
TimeUnit.SECONDS.sleep(i + 1);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
}
if (!isSuccess) {
// 重试耗尽:转发死信队列
log.error("消息重试耗尽,转入死信队列,key:{}", key);
kafkaTemplate.send(DLQ_TOPIC, key, value);
}
});
// 所有消息处理完毕(成功/死信隔离),提交当前批次位移
ack.acknowledge();
}
/**
* 通用消息业务处理逻辑
*/
private void handleMsg(String key, String value) {
// 自定义核心业务逻辑
}
}五、原生Java客户端异常处理核心逻辑
原生客户端无框架封装,需手动实现批次拆分、重试、位移精准提交,核心规范如下:
-
捕获批次全局异常后,遍历所有消息单独执行消费逻辑;
-
单条消息重试失败后,记录异常信息并发送至死信Topic;
-
通过分区级精准位移提交,仅提交已处理完成的消息位移,未处理异常消息留存,避免数据丢失;
-
禁止批次整体回滚,最大限度保证数据处理完整性。
六、特殊场景进阶处理方案
1. 有序业务批量异常处理
订单、状态变更等有序业务,禁止拆分批次乱序处理,采用整批次重试+人工兜底方案:
-
异常后不拆分单条,固定重试3次,保障消息时序不乱;
-
重试失败后,整批次转入有序死信队列,暂停对应分区消费,人工排查修复后批量重跑;
-
核心原则:宁可堆积、不可乱序,优先保障业务数据时序一致性。
2. 高吞吐日志类业务异常处理
日志、埋点等低优先级、高吞吐业务,放宽容错机制:
-
单次异常直接跳过,无需多次重试,保障吞吐优先级;
-
异常消息少量丢失可接受,无需转入死信队列,简化运维;
-
批量异常不降级单条,直接跳过当前批次,避免拖累整体消费性能。
3. 事务级批量异常处理(精准一次)
金融、数据同步等需要Exactly Once的业务,结合Kafka事务机制:
-
批量消费、业务处理、位移提交纳入同一事务;
-
批次任意消息异常,整体事务回滚,位移不提交,等待下次重试;
-
配合幂等生产者,彻底杜绝重复消费与数据错乱。
七、生产运维监控规范
-
异常监控告警:监控消费异常率、重试次数、死信队列堆积量,阈值触发即时告警;
-
死信定期巡检:每日定时梳理死信消息,分类统计异常原因(参数错误、下游故障、数据损坏);
-
批量参数适配:异常频发业务适当调小max.poll.records,缩小故障影响范围;稳定高吞吐业务可加大批量参数。
八、面试高频必背总结
-
批量消费最大痛点:单条异常导致全批次阻塞或数据丢失;
-
通用最优方案:批量正常消费+异常拆分单条处理+有限重试+死信隔离;
-
有序业务禁止拆分批次,优先保障时序一致性,牺牲部分吞吐;
-
绝对禁止批量异常后直接批量提交位移,避免数据永久丢失;
-
异常处理核心目标:不丢数据、不堵队列、不乱时序、可追溯复盘。
2.4 副本、ISR、水位线与高可用(底层核心)
1. 副本角色
(1)Leader 主副本核心
定义:每个分区唯一的主服务副本,是分区对外交互的唯一入口,集群自动选举生成,无人工指定。
核心职责:全权承接该分区所有生产者写入、消费者读取请求,处理消息校验、日志追加、索引更新、水位线维护、副本同步管理等核心逻辑,管控分区全量读写与数据流转。
运行特性:一个分区有且仅有一个Leader副本,均匀打散分布在集群不同Broker节点,避免单节点热点集中;集群通过均衡Leader分布,实现全网流量负载均衡。
生产价值:统一数据读写入口,规避多副本读写数据不一致问题,简化分布式数据同步逻辑,保障分区数据有序性与一致性。
面试重点:Kafka不支持读写分离,所有读写流量仅走Leader,Follower不承接任何业务流量。
(2)Follower 从副本核心
定义 :分区的冗余备份副本,作为Leader副本的数据兜底,属于被动同步角色,不对外提供服务。 核心职责:主动发起拉取请求,实时同步Leader副本的增量日志数据,严格复刻Leader的数据内容与偏移量,持续跟进数据进度,维持副本数据一致性。
运行特性:完全被动同步、无自主读写权限,仅负责数据备份;同步进度达标后加入ISR集合,成为可用容错副本。
故障容错机制:当Leader节点宕机、磁盘异常、网络断开导致Leader不可用时,集群控制器会从ISR同步副本中,自动选举最优Follower晋升为新Leader,实现业务无感切换,保障服务高可用、数据不丢失。
生产规范:Follower副本必须部署在与Leader不同的Broker节点,生产环境跨机架部署,杜绝单机故障导致分区所有副本同时失效。
2. ISR 同步副本集合(核心深度补全)
1. 核心定义
ISR(In-Sync Replicas,同步副本集合)是 Kafka 分区高可用的核心机制,指与分区Leader副本数据进度完全同步、延迟在阈值范围内的所有副本集合,包含分区Leader副本本身+所有实时同步的Follower副本。只有在ISR集合内的副本,具备故障后竞选新Leader的资格,是Kafka保障数据不丢、服务高可用的核心基石。
每个分区独立维护专属ISR集合,集群控制器实时监控副本同步状态,动态更新ISR列表。
2. ISR 准入核心条件(生产硬性标准)
Follower副本想要加入ISR集合,必须同时满足以下两个条件,缺一不可:
-
数据进度同步:Follower副本的日志末端位移(LEO),追上Leader副本的最新数据进度,无大量滞后消息;
-
时间阈值合规 :副本同步滞后时间,小于集群配置的最大同步滞后阈值
replica.lag.time.max.ms(默认30s)。
简单来说:同步够快、数据够新的副本,才会被纳入ISR容错池。
3. ISR 动态伸缩机制(核心运行逻辑)
(1)ISR 收缩(副本被移出)
当Follower副本因网络卡顿、磁盘IO过高、节点负载飙升、批量消息过大等原因,同步进度持续滞后,超过 replica.lag.time.max.ms 阈值后,Leader会自动将该Follower副本移出ISR集合。
核心影响:
-
被踢出的副本不再参与Leader选举,失去容错资格;
-
分区ISR集合数量变少,集群容错能力下降;
-
若ISR收缩至仅剩1个Leader副本,集群容错降级,节点故障极易导致数据丢失。
(2)ISR 扩容(副本重新加入)
被移出ISR的Follower副本,后台会持续拉取Leader增量数据追赶进度。当副本同步进度重新追上Leader、滞后时间恢复至阈值内时,自动重新加入ISR集合,恢复容错能力,全程无需人工干预。
4. 核心关联生产参数(必配必考)
-
replica.lag.time.max.ms:ISR同步超时阈值,默认30s。阈值过大,会导致滞后副本长期留在ISR,故障选主易丢数据;阈值过小,会引发ISR频繁伸缩,造成集群抖动。生产核心业务建议调至10~15s。 -
min.insync.replicas:最小ISR同步副本数,生产核心容错参数。常规业务配置2,核心金融业务配置3。当ISR集合数量小于该值时,分区禁止写入数据,牺牲可用性保障数据可靠性,避免数据不一致。 -
unclean.leader.election.enable:非ISR副本选主开关,生产默认false关闭,杜绝滞后副本选主导致数据丢失。
5. ISR 与 ACKS 可靠性联动机制(生产核心)
生产者acks参数的可靠性,完全依赖ISR集合实现:
-
acks=1:仅Leader写入成功即返回ACK,不等待Follower同步,ISR滞后不影响生产,性能高但存在丢数风险;
-
acks=all(-1) :必须等待所有ISR内副本全部同步完成 ,更新HW水位线后,才返回写入成功ACK,是Kafka最高可靠性写入机制。搭配
min.insync.replicas=2,可实现生产零数据丢失。
6. 故障场景兜底机制
(1)ISR集合为空
极端场景下所有Follower副本同步滞后被踢出ISR,仅剩Leader副本,若此时Leader宕机,ISR集合为空。生产默认关闭非ISR选主,分区会进入只读不可写状态,优先保障数据安全,避免强制选主导致大规模数据丢失。
(2)ISR频繁伸缩告警
线上ISR频繁扩容、收缩,属于高危预警,大概率是节点负载不均、网络抖动、磁盘IO瓶颈、大消息阻塞同步导致,需及时排查节点性能与消息规格,避免集群持续抖动。
7. 面试高频核心考点(背诵版)
-
ISR集合包含哪些副本?答:Leader + 实时同步的Follower副本;
-
副本退出ISR的核心条件?答:同步滞后时间超过replica.lag.time.max.ms阈值;
-
Leader宕机后,选主范围是什么?答:仅ISR集合内的同步副本,非ISR副本无选主资格;
-
min.insync.replicas的作用?答:限制最小可用同步副本数,低于阈值禁止写入,保障数据可靠;
-
acks=all一定不丢数据吗?答:必须搭配min.insync.replicas参数,否则单副本场景仍会丢数;
-
ISR频繁收缩的根因?答:节点CPU/IO/网络瓶颈、大消息同步超时、集群负载过高。
3. 水位线 HW(High Watermark)【重点深度补全】
HW(High Watermark,高水位线)是Kafka保障数据一致性、读写可见性、故障数据不丢失的核心底层机制,是分区数据同步与消费可见的权威标尺,也是Leader切换、副本同步、消息可见性控制的核心依据,属于面试必考、生产底层核心知识点。
一、核心定义
分区的高水位线HW :指当前分区内ISR集合中所有副本,全部同步完成的最大消息偏移量。简单来说,该位移之前的所有数据,Leader和所有ISR内的Follower副本完全一致、同步完毕,数据实现多副本持久化,绝对安全可靠。
核心硬性规则 :消费者仅能消费HW位移之前的消息,HW之后的消息对消费者完全不可见,无论Leader是否已经写入该部分数据。
二、核心配套概念:LEO(日志末端位移)
想要彻底理解HW,必须先掌握LEO,二者成对存在、联动工作:
-
LEO(Log End Offset) :每个副本独立拥有的日志末端偏移量,代表当前副本本地已经写入的最新消息位置,Leader和每个Follower副本都有各自独立的LEO。
-
Leader-LEO:Leader副本最新写入的消息位移,代表当前分区最新数据位置;
-
Follower-LEO:对应Follower副本同步到的最新位移,代表该从副本的数据同步进度。
二者核心关系 :HW永远小于等于最小的ISR副本LEO,只有当所有ISR内副本的LEO全部追上某一位置,该位置才会更新为新的HW。
三、HW动态更新机制(全流程拆解)
HW不会随Leader写入实时更新,而是跟随Follower副本同步进度动态更新,完整流程如下:
-
生产者向Leader副本写入新消息,仅更新Leader的LEO,此时HW保持不变,新消息暂时对消费者不可见;
-
Follower副本主动拉取Leader增量数据,同步完成后,更新自身本地LEO;
-
Leader节点实时监听ISR集合内所有Follower的LEO同步进度;
-
当所有ISR副本的LEO都大于等于某一偏移量时,分区HW更新为该最新偏移量;
-
HW更新完成后,该偏移量之前的所有消息正式对外开放,消费者可正常拉取消费。
关键结论:Leader写入成功≠消息可消费,必须等待ISR副本同步完成、HW更新后,消息才会暴露给下游消费者。
四、HW核心四大作用(生产+面试核心)
1. 管控消息可见性,隔离未同步数据
通过HW屏障,严格区分「已同步安全数据」和「未同步临时数据」,未完成全ISR同步的消息,坚决不对外暴露,避免消费者读到仅Leader存在、无副本兜底的不安全数据。
2. 故障切换防数据丢失、防数据错乱
当分区Leader节点宕机、故障下线时,集群只会从ISR集合中选举新Leader,且新Leader的有效数据范围仅截止到原分区HW位置。原Leader中HW之后、未同步到Follower的消息,会被直接截断清理,彻底避免新旧Leader数据不一致、数据错乱问题。
3. 保障多副本数据最终一致性
以HW为统一标尺,强制所有ISR副本的数据对齐,杜绝出现「Leader有、Follower无」的数据差异,从底层保障分布式环境下副本数据一致性。
4. 配合acks机制实现数据可靠性分级
生产者acks参数的可靠性本质由HW决定:
-
acks=1:Leader写入成功即返回ACK,不等待HW更新,存在HW未更新、Leader宕机丢数风险;
-
acks=all(-1):必须等待所有ISR副本同步完成、HW更新后,才返回写入成功ACK,实现数据最高可靠性。
五、典型故障场景推演(生产高频)
场景1:Leader写入新消息,未等Follower同步就宕机
此时新消息仅存在于原Leader本地,未同步至任何ISR副本,分区HW未更新。集群选举ISR内Follower为新Leader后,会自动截断原LeaderHW之后的未同步消息,避免无效脏数据残留,保障集群数据一致性,但会造成该部分未同步消息丢失(可通过acks=all规避)。
场景2:Follower同步滞后,HW更新延迟
若网络卡顿、磁盘IO瓶颈导致Follower同步缓慢,HW会停滞更新,出现「Leader有大量新数据,但消费者无法消费」的现象,直观表现为消费延迟飙升、生产正常消费停滞,是线上消费堆积的隐性诱因之一。
六、HW与副本、ISR联动关系
-
ISR集合扩容/收缩会直接影响HW更新速度,ISR副本越多,HW更新越慢,数据可靠性越高;
-
被踢出ISR的滞后副本,不会参与HW计算,仅剩余同步正常的副本决定HW位置;
-
非ISR副本的数据进度完全不影响HW,无任何数据话语权。
七、面试高频必背简答题(精炼版)
-
HW和LEO的区别? LEO是单副本最新写入位置,HW是所有ISR副本同步完成的最大位置;LEO副本独立,HW分区全局唯一。
-
为什么消费者只能消费到HW位置? HW之后的数据仅Leader存在,无副本兜底,故障易丢失,属于不安全数据,禁止对外消费。
-
Leader切换后为什么会截断数据? 新Leader仅保留HW之前的一致性数据,截断HW后未同步数据,杜绝数据错乱。
-
acks=all的核心原理? 等待所有ISR副本同步完成、HW更新,再返回写入确认,实现数据零丢失。
八、生产调优小规范
核心高可靠业务,搭配 acks=all + min.insync.replicas=2,强制HW必须至少2个副本同步完成才更新,彻底杜绝数据丢失;高吞吐非核心业务,可适当放宽同步阈值,平衡HW更新延迟与集群吞吐性能。
简洁:
-
定义:分区内所有 ISR 副本都已同步完成的最大位移。
-
规则:消费者只能消费到 HW 位置,HW 之后的数据对外不可见。
-
作用:防止新 Leader 数据不全,导致消息丢失或重复。
-
完整同步链路:消息位移 → LEO(日志末端)→ HW 水位线 → 对外可见。
4. Leader 选举规则(深度完整版·生产+面试必考)
(1)核心选举前提 :分区Leader宕机、节点下线、网络分区、副本同步异常触发Leader空缺时,由集群控制器(ZK架构为ZK监听触发,KRaft架构为集群控制器主动调度)发起新一轮Leader选举,仅ISR集合内的存活副本拥有参选资格,非ISR副本默认禁止参选(生产默认配置)。
(2)核心选举优先级规则(自上而下匹配)
规则一:优先选取ISR内同步进度最新的副本(最高优先级) :对比ISR集合内所有存活Follower副本的LEO(日志末端位移),优先选择LEO最大、数据最完整的副本晋升为新Leader,最大限度减少数据截断丢失。
规则二:同步进度一致,优先选取旧Leader副本:若ISR内多个副本LEO完全一致、数据同步进度无差异,优先选择上一轮的分区Leader副本,保证分区Leader稳定性,避免频繁切换引发集群抖动。
规则三:进度与历史一致,按副本ID升序选取:若同步进度、历史Leader身份均无差异,按照Broker节点ID从小到大排序,选取ID最小的副本作为新Leader,实现选举确定性。
(3)关键参数:
unclean.leader.election.enable(脏选举开关)
false(生产默认强制关闭):
ISR集合为空、无可用同步副本时,禁止非ISR滞后副本参选,分区直接进入「只读不可写」状态,牺牲集群可用性,100%保障数据不丢失、不错乱,适配所有生产业务。
true(仅测试/离线场景开启):
ISR为空时,允许集群从非ISR滞后副本 中选举新Leader。该副本数据滞后、未完成全量同步,选举后会强制截断原Leader未同步数据,必然造成数据丢失与数据不一致,线上生产严禁开启。
(4)KRaft与ZK架构选举差异ZK旧架构:依赖Zookeeper临时节点监听触发选举,选举响应慢、存在监听延迟,大规模集群易出现选举拥堵、Leader切换超时问题。
KRaft新架构:由专属集群控制器统一调度选举,基于Raft协议实现毫秒级选主,元数据同步精准,无延迟、无拥堵,故障切换完全无感,是3.x版本核心优势之一。
选举后核心兜底机制新Leader当选后,会以自身LEO为基准,截断所有Follower副本中超出当前HW水位线的未同步脏数据,强制全局副本数据对齐,保障分区数据一致性;
选举完成后,集群自动重新均衡Leader分布,避免单Broker承载过多分区Leader,防止节点热点负载;
选举全程自动完成,无需人工干预,故障恢复后集群自动修复ISR集合。
(5)生产选举禁忌与避坑
禁止手动强制指定分区Leader,极易引发副本数据错乱、同步异常;
禁止开启脏选举开关,核心业务宁可堆积不可丢数;
集群节点故障后,需等待选举完成、ISR恢复正常后再重启节点,避免二次触发选举导致集群抖动。
(6)面试极简背诵总结
选举核心:ISR内优先、数据最新优先、历史Leader优先、ID小者兜底;
生产核心:关闭脏选举,保数据一致性优先于可用性;
架构差异:KRaft选主更快、更稳定,彻底解决ZK选举性能瓶颈。
5. 副本同步滞后 replica lag(生产核心监控&故障高频考点)
replica lag 是 Kafka 集群运维核心黄金监控指标,用于衡量 Follower 副本与 Leader 副本的数据同步差距,直接反映集群副本同步健康度、节点负载、网络状态,是预判集群抖动、数据风险、同步异常的核心依据,线上必须实时监控告警。
一、核心定义
副本同步滞后(replica lag) :指分区 Follower 副本的日志末端位移(LEO),落后于 Leader 副本 LEO 的消息偏移量差值,部分监控体系也支持时间滞后维度统计。
简单理解:lag 值 = 最新Leader消息位移 - Follower已同步消息位移。
-
lag = 0:Follower 与 Leader 数据完全同步,副本状态健康,稳定处于 ISR 集合;
-
lag > 0:Follower 同步滞后,存在数据差距,lag 越大,同步延迟越高、集群容错风险越大;
-
lag 持续上涨:副本同步速度跟不上 Leader 生产速度,同步链路阻塞,属于高危异常。
二、生产分级阈值规范(企业通用标准)
结合集群稳定性与业务容错性,定义三级告警阈值,适配全生产场景:
-
正常状态(绿色):lag = 0 或 恒定极小值(100以内),同步正常,无风险;
-
轻微预警(黄色):0 < lag < 1000,短暂同步波动,多为瞬时流量峰值导致,可自动恢复;
-
严重告警(橙色):1000 < lag < 10000,同步持续滞后,节点或网络存在性能瓶颈,需介入排查;
-
高危故障(红色):lag > 10000 或 持续上涨,极易触发 ISR 收缩、副本踢出,存在数据丢失、集群容错降级风险。
核心时间阈值联动:
若副本滞后时间超过 replica.lag.time.max.ms(默认30s),无论lag数值大小,都会被强制踢出ISR集合,降低集群容错能力。
三、滞后核心成因(全场景拆解)
1. 节点硬件资源瓶颈(最常见)
-
磁盘IO瓶颈:Follower节点机械磁盘读写速度慢、磁盘使用率过高、磁盘坏道,导致日志写入跟不上同步速度;多分区共享磁盘,IO争抢严重;
-
CPU负载过高:节点CPU打满,副本同步线程、日志处理线程调度阻塞,同步逻辑无法正常执行;
-
内存不足:PageCache占用耗尽、内存溢出,系统频繁触发内存交换,大幅拖累IO读写性能。
2. 网络传输异常
-
集群节点间网络抖动、延迟高、丢包、TCP重传,导致Follower拉取数据超时、重试频繁;
-
跨机房/跨机架部署,网络带宽不足,大流量场景下同步带宽被占满;
-
防火墙、安全组策略拦截,导致同步数据包传输异常。
3. 消息与业务流量问题
-
超大消息阻塞:单条消息超过默认批量大小、同步缓冲区大小,导致单次同步超时,卡住后续所有数据同步;
-
瞬时流量峰值:业务突发高吞吐流量,Leader快速写入数据,Follower同步能力不足以追赶写入速度;
-
消息压缩率过高,Follower解压消耗大量CPU资源,拖慢同步进度。
4. 集群参数配置不合理
-
副本同步线程数过少、同步缓冲区(replica.fetch.buffer.size)偏小,单次拉取数据量有限;
-
ISR超时阈值设置过小,轻微滞后就触发副本踢出,加剧同步波动;
-
节点IO线程、网络线程配置不足,无法支撑高并发同步场景。
5. 集群负载不均
-
部分Broker节点承载过多分区Leader/Follower角色,负载过载,资源被耗尽;
-
热点分区流量集中,对应Follower副本同步压力远超普通分区。
四、滞后引发的生产风险
-
ISR 频繁收缩扩容:副本反复进出ISR集合,引发集群元数据频繁更新,造成集群抖动、性能下降;
-
集群容错降级:滞后副本被踢出ISR,可用同步副本数减少,若剩余ISR副本故障,极易引发数据丢失;
-
Leader切换数据截断:滞后Follower无选主资格,若ISR为空,分区只读不可写,影响业务可用性;
-
消费延迟飙升:极端场景下HW水位线停滞更新,新消息无法对外消费,引发大规模消息堆积。
五、生产标准排查流程(可直接落地)
-
定位异常分区 :通过
kafka-topics.sh --describe或监控平台,筛选lag不为0的异常分区、对应Follower节点; -
核查节点资源:查看异常节点CPU、磁盘IO、内存、网卡流量,确认是否存在资源瓶颈;
-
排查网络状态:检测节点间延迟、丢包、TCP重传,排除网络传输问题;
-
核查消息规格:查看对应Topic是否存在超大消息、瞬时流量峰值;
-
校验集群参数:核对同步线程、缓冲区、ISR超时等核心参数配置;
-
均衡集群负载:判断是否为节点负载不均,执行分区重分配、Leader均衡。
六、生产优化解决方案(根治方案)
1. 硬件与系统优化
-
所有数据节点挂载SSD高速磁盘,规避机械磁盘IO瓶颈,独立磁盘存储日志;
-
永久关闭SWAP分区,优化TCP内核参数,提升网络传输稳定性;
-
集群节点资源配比均衡,避免单节点负载过高。
2. 集群参数调优
-
调大副本同步缓冲区、同步线程数,提升Follower批量拉取能力;
-
核心业务微调
replica.lag.time.max.ms至10~15s,避免频繁ISR收缩; -
合理限制单条消息最大大小,拦截超大消息阻塞同步链路。
3. 业务与流量优化
-
拆分热点Topic、扩容分区数,打散高并发流量,避免单分区同步压力过大;
-
规范消息规格,拆分超大消息,文件类数据仅传递链接,不传递二进制大文件;
-
流量峰值场景提前扩容节点,预留30%以上性能冗余。
4. 运维常态化保障
-
开启lag指标实时监控+告警,提前感知同步异常,规避故障扩大;
-
定期执行分区重分配、Leader均衡,保障集群负载均匀;
-
集群升级、节点维护避开业务高峰期,减少同步波动。
七、面试高频必背考点
-
replica lag 持续上涨的根因? 节点CPU/磁盘IO/网络瓶颈、超大消息阻塞、流量峰值超过同步能力、参数配置不合理;
-
lag不为0一定有问题吗? 不一定,瞬时小幅lag是正常同步波动,持续上涨、高数值lag才是异常;
-
lag和ISR的关系? 副本lag超时会被踢出ISR,lag归零后自动重新加入ISR;
-
如何快速解决副本同步滞后? 短期扩容节点资源、限流超大消息;长期优化分区规划、调优同步参数、均衡集群负载;
-
生产是否允许存在小幅lag? 允许,瞬时小幅滞后属于正常同步机制,只要不超时、不持续上涨,无集群风险。
6. 副本迁移与分区重分配(生产核心运维)
分区重分配(Partition Reassignment)是Kafka集群运维核心能力,核心用于节点扩容、缩容、负载均衡、故障节点下线、机架均衡场景。通过手动/自动迁移分区与副本分布,解决集群节点负载倾斜、热点分区、副本机架集中、新旧节点数据不均等问题,是集群常态化运维的必备操作。
一、核心概念与本质
-
分区重分配:变更Topic分区的Leader/Follower副本所属Broker节点,调整分区在集群中的分布位置,包含副本迁移、Leader切换、数据同步全流程。
-
副本迁移:重分配的核心动作,将分区副本从旧节点迁移至新节点,保证迁移前后副本数、分区数、数据完整性不变。
-
核心特性:全程在线迁移、业务无感知、不中断生产消费、支持带宽限速、支持机架感知调度。
二、生产适用场景(必用场景)
-
集群扩容数据均衡:新增Broker节点后,新节点无数据、无流量,通过重分配迁移部分分区,均衡全集群负载,让新节点承接读写流量。
-
故障节点下线替换:节点硬件故障、性能老化、版本升级需要下线时,提前迁移该节点所有分区副本,清空节点数据后安全下线。
-
解决节点负载倾斜:部分Broker承载过多Leader分区、热点流量,导致单节点CPU/磁盘IO/带宽打满,通过重分配打散热点分区。
-
机架容灾优化:修正副本同机架部署问题,将分区多副本分散到不同机架/机房,避免单机架断电导致分区不可用、数据丢失。
-
集群版本灰度迁移:新旧版本集群混部时,逐步迁移业务分区至新集群,实现业务平滑迁移、零停机升级。
三、核心优势(生产设计亮点)
-
在线无损迁移:迁移过程不停止生产消费,数据双向同步,业务零中断、零感知。
-
迁移带宽限速:支持动态限制副本迁移带宽,避免大量数据同步打满集群网卡、拖垮线上业务。
-
机架感知调度:结合集群机架配置,自动规避同机架副本部署,保障容灾能力。
-
自动容错回滚:迁移过程节点故障、网络异常时,自动暂停迁移,原有分区读写不受影响。
四、完整迁移执行流程(生产标准流程)
1. 生成重分配计划
通过kafka-reassign-partitions.sh工具,基于目标Topic、目标Broker节点,生成JSON格式迁移计划,系统自动计算最优分区分布、副本排布方案,避免人工配置出错。
2. 执行副本数据迁移
集群根据分配计划,在目标新Broker节点创建空副本,新副本主动拉取原Leader节点全量历史数据,完成数据同步,此阶段新旧副本共存,集群副本数临时翻倍,保障数据安全。
3. 同步完成切换副本
新副本数据完全同步、加入ISR集合后,集群触发Leader切换(按需),将分区读写流量切换至新Leader节点,旧副本保留一段时间作为兜底。
4. 清理旧副本资源
确认新副本服务正常、数据一致、无同步滞后后,删除旧节点冗余副本,完成分区重分配全流程,释放旧节点磁盘与集群资源。
五、核心运维命令(可直接生产复用)
1. 生成重分配方案
指定Topic与目标Broker列表,生成预分配计划,不执行实际迁移:
kafka-reassign-partitions.sh --bootstrap-server
集群地址:9092 --topics-to-move-json-file topics.json --generate --broker-list 0,1,2
2. 执行正式迁移
加载生成的分配方案,执行在线分区迁移:
kafka-reassign-partitions.sh --bootstrap-server
集群地址:9092 --reassignment-json-file reassign.json --execute
3. 查看迁移进度
实时核查迁移完成情况、剩余分区、同步状态:
kafka-reassign-partitions.sh --bootstrap-server
集群地址:9092 --reassignment-json-file reassign.json --verify
4. 迁移带宽限速(生产关键)
通过replica.alter.log.dirs.bytes.per.second参数限制每秒迁移流量,避免抢占业务带宽,常规生产限速10~20MB/s。
六、Leader分区均衡(配套优化)
分区重分配仅调整副本分布,不会自动均衡Leader角色,长期会出现单节点承载过多Leader分区、负载偏高的问题,需手动执行Leader均衡:
-
命令:
kafka-leader-election.sh -
作用:手动触发分区Leader重新选举,均匀分布Leader节点
-
生产规范:集群扩容、分区迁移完成后,必须执行一次Leader均衡,抹平节点负载差异
-
注意:Leader切换会瞬时触发分区读写抖动,需避开业务高峰期执行
七、生产避坑规范(高危禁忌)
-
禁止高峰期迁移:流量峰值迁移会加剧网络、磁盘IO压力,引发同步滞后、消费堆积,仅允许低峰期操作。
-
禁止无限速迁移:超大Topic迁移不限速会打满集群带宽,导致全集群业务延迟飙升。
-
禁止单次批量迁移大量分区:单次迁移分区过多会造成集群元数据频繁更新、ISR频繁波动,分批灰度迁移更稳定。
-
迁移不允许中断进程:迁移中途强制终止脚本,会残留无效副本、脏数据,需手动清理元数据。
-
下线节点必须先迁移再停机:禁止直接下线承载Leader副本的节点,优先迁移分区,再下线节点,避免业务中断。
八、面试高频考点(精炼必背)
-
分区重分配核心流程? 生成分配计划 → 新节点同步全量数据 → 新副本加入ISR → 切换Leader → 清理旧副本。
-
迁移是否影响业务? 在线无感知迁移,仅瞬时少量网络开销,不中断生产消费。
-
为什么迁移后要做Leader均衡? 重分配只迁移副本,不调整Leader分布,易导致节点负载倾斜。
-
迁移限速的意义? 防止副本同步流量抢占业务带宽,保障线上业务稳定性。
-
副本迁移和分区扩容的区别? 迁移不改变分区数,仅调整分布;扩容是新增分区,提升并发上限。
2.5 磁盘存储原理(高性能根源)
1. 日志分段 Segment(核心深度补全)
Kafka 分区并非以单个大文件存储所有消息,而是采用日志分段(Log Segment)机制 ,将单个分区的海量日志数据,拆分为多个固定大小、独立管理的分段文件,是 Kafka 实现日志清理、索引检索、冷热分离、高效运维的核心底层设计。单个分区由多个有序的 Segment 分段 组成,同一时间仅有**一个活跃分段(Active Segment)**用于接收新消息写入,其余均为只读旧分段。
一、Segment 完整文件组成
每个日志分段是一组同名前缀的文件集合,绝非单一日志文件,共包含3类核心文件,各司其职、配套工作:
-
.log 日志数据文件(核心主体) :存储当前分段下所有生产者推送的原始消息数据,包含消息体、Key、Header、时间戳、位移、CRC校验码等完整信息,所有新消息均以顺序追加方式写入文件末尾。
-
.index 偏移量索引文件:稀疏索引结构,记录「消息相对位移 → 文件物理偏移地址」的映射关系,用于快速定位指定位移消息在.log文件中的位置,避免全量文件扫描。
-
.timeindex 时间戳索引文件:同样为稀疏索引,记录「消息时间戳 → 消息位移」映射关系,支撑按时间回溯消息、按时间清理过期日志的核心能力。
补充辅助文件:部分版本会生成 .txnindex 事务索引文件,用于存储分段内事务消息状态,支撑事务机制与消息原子性。
二、Segment 命名规则(面试必考)
所有分段文件的文件名前缀,为当前分段的起始全局偏移量(Base Offset),
格式统一为 xxxxxx.log / xxxxxx.index / xxxxxx.timeindex。
-
首个分段文件前缀为 0,代表该分段从位移0开始存储消息;
-
新分段滚动生成后,文件名前缀为上一个分段的结束位移;
-
通过文件名即可快速判断分段的消息存储位移范围,无需打开文件检索。
示例:0000000000000001000.log 代表该分段存储的消息起始位移为1000。
三、活跃分段与只读分段机制
-
活跃分段(Active Segment):分区当前唯一可写分段,所有新消息、新索引数据均写入该分段,文件大小持续递增,无固定上限(未触发滚动前)。
-
只读旧分段:触发滚动后,原活跃分段立即变为只读状态,不再接收任何新消息写入,仅保留数据用于消费、回溯、持久化,等待后续日志清理或压缩。
该机制完美适配 Kafka 顺序写特性,同时避免单文件过大导致的索引查询缓慢、日志清理卡顿、文件损坏风险。
四、索引文件核心特性(稀疏索引详解)
Kafka 索引采用稀疏索引设计,区别于稠密索引(每条数据建索引),不会为每一条消息单独生成索引记录,大幅节省磁盘存储空间,是 Kafka 轻量化存储的关键。
-
索引间隔规则:默认每间隔一定字节/一定消息数生成一条索引记录(由参数控制);
-
检索逻辑 :查询目标消息时,先通过索引文件快速定位到近似文件位置,再在小范围.log文件中顺序扫描精准匹配,兼顾查询速度与存储成本;
-
自动修复机制:若索引文件损坏、丢失,Broker 重启时会自动扫描对应.log日志文件,完整重建索引文件,不会影响数据完整性;
-
内存加载机制:Broker 启动后,所有索引文件会预加载到页缓存,保障检索速度,避免磁盘IO查询延迟。
五、生产核心参数调优(Segment 专属)
所有参数均为生产高频配置,直接影响集群性能、日志清理效率与故障恢复速度:
-
log.segment.bytes:单个分段最大文件大小,生产默认 1GB,达到阈值触发日志滚动;大流量场景可适当调大至2GB,减少频繁滚动开销,小流量场景保持默认即可。
-
log.roll.ms / log.roll.hours:时间维度滚动阈值,默认未开启,可配置固定时长(如24h)强制滚动分段,避免低流量场景文件长期不滚动、日志无法清理。
-
log.index.interval.bytes:索引生成间隔字节数,默认4096字节,数值越大索引越稀疏、占用磁盘越小,检索速度略慢;数值越小索引越密集、检索越快,按需平衡性能与存储。
-
log.segment.delete.delay.ms:分段文件删除延迟时间,默认60s,触发清理后不会立即删除,延迟兜底,避免消费过程中误删活跃数据。
六、Segment 机制核心优势
-
规避超大文件风险:拆分海量数据为固定大小小文件,避免单文件数十GB导致的索引加载缓慢、文件损坏风险、清理卡顿问题;
-
高效日志清理:只读旧分段可直接整体删除/压缩,无需解析大文件,大幅提升日志清理效率,减少集群CPU、IO开销;
-
精准数据回溯:结合时间索引、位移索引,支持按时间、按位移快速定位历史数据,适配故障复盘、业务重跑场景;
-
故障容错性强:单个分段文件损坏仅影响局部数据,不会导致整个分区数据不可用,降低故障影响范围;
-
适配冷热数据分离:旧分段冷数据可迁移至对象存储,活跃分段热数据留存本地磁盘,适配3.x分层存储架构。
七、面试高频必背考点
-
为什么Kafka要做日志分段? 避免单文件过大、优化日志清理效率、提升索引检索速度、缩小故障影响范围、适配冷热数据分层;
-
什么是活跃分段? 分区唯一可写分段,新消息仅写入活跃分段,滚动后变为只读;
-
稀疏索引的优缺点? 优点是节省磁盘空间、减少索引加载内存;缺点是精准查询需要二次顺序扫描,速度略低于稠密索引;
-
低流量场景日志堆积无法清理的原因? 流量过低长期不触发文件大小滚动,无新分段生成,旧分段无法执行清理,需配置时间维度滚动阈值强制分段。
2. 日志滚动 Rolling(新建 Segment 条件,生产+面试完整版)
日志滚动(Log Rolling)是Kafka底层核心机制,指分区**活跃日志分段(Active Segment)**满足指定阈值后,自动关闭当前可写分段、新建空白分段承接后续新消息写入的全过程。该机制是日志分段管理、过期清理、索引维护的基础,彻底解决单日志文件过大、无法按需清理、检索效率低等问题,所有滚动操作由Broker后台线程自动触发,无需人工干预。
一、四大核心触发条件(满足任意1项即触发滚动)
Kafka日志滚动支持大小触发、定时触发、固定时间触发、启动强制触发四种机制,全方位适配高低流量业务场景,规避日志残留无法清理的问题:
(1)文件大小阈值触发(核心默认)
对应参数:log.segment.bytes,生产默认1GB
机制:当活跃分段文件大小达到设定阈值时,立即触发日志滚动,关闭当前分段并置为只读,新建以「上一段结束位移」为起始偏移量的新活跃分段。
适用场景:高吞吐业务,流量充足可快速打满分段,依靠大小阈值正常滚动。
(2)固定时长超时触发(低流量必备)
对应参数:log.roll.ms(毫秒)/ log.roll.hours(小时),默认未开启
机制:距离上一次日志滚动达到设定时长,无论当前分段文件大小是否达标,强制触发新建分段。
核心作用:解决低流量业务日志卡死问题------低流量场景下文件长期达不到1GB大小,无法触发滚动,旧分段持续处于活跃可写状态,导致过期日志无法执行删除/压缩清理,堆积海量无效数据。生产低吞吐业务建议固定配置24小时定时滚动。
(3)每日定点时间触发
对应参数:log.roll.schedule
机制:支持配置Cron表达式,指定每日固定时间(如凌晨0点)强制日志滚动。
适用场景:需要按自然日切割日志、按天归档数据的业务,便于按日期追溯、统计每日数据量。
(4)Broker启动强制触发
内置机制,无配置参数
机制:Kafka Broker重启后,无论原有活跃分段大小、时长,都会自动触发一次日志滚动,新建全新活跃分段。
核心目的:规避重启前后消息写入混乱,统一分段存储边界,便于故障后数据溯源与分段管理。
二、完整日志滚动执行流程
-
阈值检测:Broker后台日志管理线程,实时检测活跃分段的文件大小、存活时长、定时规则、服务状态;
-
关闭旧分段 :触发滚动条件后,立即停止向当前活跃分段写入新消息,将其标记为只读分段,不再接收任何数据;
-
生成新分段:创建新的.log日志文件、.index偏移量索引文件、.timeindex时间索引文件,新文件前缀为旧分段的结束位移,作为新分段的起始位移;
-
切换写入链路:所有新生产消息、索引数据,全部写入全新的活跃分段;
-
旧分段等待处理:只读旧分段进入待命状态,等待后续日志清理线程执行删除、压缩操作。
三、生产核心参数调优规范
-
高吞吐业务(日志/埋点) :保持默认
log.segment.bytes=1GB,无需开启定时滚动,避免频繁小文件生成,减少文件IO开销;超大流量集群可微调为2GB,降低滚动频次。 -
低吞吐业务(事件/通知) :必须开启
log.roll.hours=24,强制每日滚动,保证过期日志可正常清理,杜绝磁盘堆积。 -
时间归档业务 :配置
log.roll.schedule=0 0 0 * * ?,每日凌晨定点滚动,实现日志按自然日切割。 -
分段删除延迟 :
log.segment.delete.delay.ms=60000(默认60s),滚动后的旧分段不会立即删除,预留消费兜底时间,避免正在消费的日志被误删。
四、生产常见问题与解决方案
-
问题1:低流量业务日志长期不清理,磁盘持续上涨 根因:仅依赖大小阈值滚动,流量不足无法打满1GB文件,无新分段生成,旧分段持续活跃,日志清理策略不生效 解决方案:开启24小时定时滚动参数,强制每日新建分段。
-
问题2:高频滚动产生大量小文件,集群IO飙升 根因:分段大小设置过小、定时滚动时长过短,频繁创建/关闭文件、生成索引 解决方案:调大
log.segment.bytes、延长定时滚动周期,减少滚动频次。 -
问题3:Broker重启后出现大量空分段 根因:重启强制滚动机制触发,新建空白活跃分段,旧分段无数据残留 解决方案:正常现象,无需处理,空分段会随后续写入自动覆盖或随过期清理。
五、面试高频必背考点
-
日志滚动的核心作用? 拆分超大日志文件、支撑日志定时清理、优化索引检索效率、精准按时间/位移回溯数据、规避单文件损坏风险。
-
为什么低流量Kafka集群容易磁盘爆满? 低流量无法触发大小滚动,无新分段生成,旧分段持续活跃,过期日志无法删除,导致数据持续堆积。
-
重启Broker为什么会触发日志滚动? 统一重启前后数据存储边界,避免消息写入混乱,方便故障溯源与分段管理。
-
多个滚动条件同时生效,会冲突吗? 不会,任一条件满足立即触发滚动,优先级互不影响,是多层兜底机制。
3. 索引机制(全维度深度补全·生产+面试完整版)
Kafka 索引机制是其海量日志快速检索、精准数据回溯、高效日志清理 的核心底层支撑,区别于传统数据库稠密索引,采用独创的分段稀疏索引架构,极致平衡检索性能与磁盘内存占用。所有索引文件随日志分段(Segment)独立生成、独立销毁,完全适配日志分段的存储架构,是Kafka高性能、低资源开销的关键设计。
一、索引整体架构与核心特性
-
分段索引隔离:每个日志Segment对应独立的偏移量索引、时间戳索引,不同分段索引互不干扰,单分段索引损坏仅影响当前分段,故障隔离性极强。
-
纯稀疏索引设计:不逐条消息建立索引,仅间隔固定字节/消息数生成索引条目,相比稠密索引,磁盘占用降低90%以上,无内存溢出风险。
-
内存预加载机制:Broker启动时自动将所有有效索引文件加载至操作系统PageCache,后续检索全程走内存,规避磁盘IO延迟。
-
自动自愈机制:索引文件损坏、丢失、格式异常时,Broker不会启动失败,会后台扫描对应.log日志文件,全自动重建完整索引。
-
只读不可写:旧分段索引永久只读,仅活跃分段索引随消息写入动态追加更新。
二、三大核心索引文件详解
1. 偏移量索引(.index)------ 核心检索索引
Kafka最核心的索引文件,用于通过消息全局偏移量,快速定位消息在日志文件中的物理存储位置。
存储结构:固定大小二元组索引条目,每条记录占8字节(4字节相对偏移量 + 4字节文件物理位置),结构极简、检索极快。
-
相对偏移量:当前Segment起始位移的差值(Base Offset为基准),而非全局位移,大幅压缩数值大小,节省存储空间。
-
文件物理位置:消息在当前.log分段文件中的字节偏移地址,精准定位消息存储位置。
核心作用:支撑按位移精准消费、位移重置、历史消息回溯,是消费者正常消费的基础。
2. 时间戳索引(.timeindex)------ 时间维度检索索引
用于通过时间戳快速匹配对应消息偏移量,支撑按时间回溯数据、按时间清理过期日志、定时数据重跑等核心能力。
存储结构:固定大小二元组,每条记录12字节(8字节时间戳 + 4字节相对偏移量)。
核心作用:解决无法按时间检索日志的问题,是日志定时清理、时间维度数据复盘的底层依赖,弥补了仅靠位移检索的局限性。
3. 事务索引(.txnindex)------ 高阶特性专属索引
0.11.x及以上版本新增专属索引文件,随事务消息生成,存储分段内所有事务消息的状态、起止偏移量、事务执行记录。
核心作用:支撑事务消息原子性、事务状态校验、僵尸事务清理,保障幂等与Exactly Once语义正常生效。
三、稀疏索引核心工作原理(面试必考)
1. 索引生成规则
Kafka不会为每条消息生成索引,仅当分段内消息写入字节差达到阈值 时,生成一条索引记录,核心控制参数:log.index.interval.bytes=4096(默认4KB)。即每写入4KB消息数据,新增一条索引,极大减少索引条目数量。
2. 二级检索流程
稀疏索引并非精准定位,采用「索引粗定位 + 日志精扫描」的二级检索模式,兼顾性能与存储:
-
第一步:索引粗定位:检索内存中的索引条目,通过二分查找,快速匹配小于目标值的最大索引记录,锁定消息所在的局部文件区间。
-
第二步:顺序精扫描:在锁定的极小范围.log日志区间内,顺序逐条扫描消息,精准匹配目标偏移量/时间戳。
核心优势:相比全文件扫描速度提升百倍,相比稠密索引节省90%以上磁盘空间,是极致的性能与存储平衡设计。
四、索引写入、加载、重建全流程
1. 索引写入流程
-
生产者消息写入活跃Segment的.log文件,记录消息位移、时间戳、物理位置;
-
系统检测当前分段写入字节差,达到
log.index.interval.bytes阈值则生成索引条目; -
索引数据写入PageCache,随日志数据异步刷盘,不阻塞消息写入;
-
分段滚动后,索引文件同步固化,不再新增、修改条目。
2. 索引加载流程
Broker启动阶段会执行索引预热:遍历所有Segment的索引文件,校验文件合法性,将所有有效索引条目批量加载至PageCache,全程内存操作,保障启动后检索无延迟。
3. 索引重建机制(核心自愈)
当索引文件丢失、损坏、格式错乱、版本不匹配时,Kafka触发自动重建:
-
Broker启动检测索引异常,标记当前分段索引失效;
-
后台独立线程扫描完整.log日志文件,逐条解析消息位移、时间戳;
-
按照默认索引间隔规则,重新生成完整.index、.timeindex文件;
-
重建完成后自动加载至内存,恢复正常检索能力。
关键特性:索引重建不丢失任何业务数据,仅重构索引元数据,对业务读写无感知。
五、生产核心参数调优
-
log.index.interval.bytes:索引生成间隔字节数,默认4096B。 ✅ 高吞吐场景:调大至8192B,减少索引数量、节省磁盘内存; ✅ 精准检索场景:保持4096B,缩小扫描范围,提升检索速度。
-
log.index.max.bytes:单分段索引文件最大上限,默认100MB,防止超大分段索引内存溢出。
-
log.segment.delete.delay.ms:索引文件删除延迟,默认60s,避免消费未完成时误删索引导致检索异常。
六、生产常见问题与解决方案
-
问题1:索引文件过多,占用大量inode 根因:分段过小、索引间隔过小,生成大量小索引文件 方案:调大segment分段大小、加宽索引生成间隔,减少文件数量。
-
问题2:Broker启动缓慢,索引加载耗时久 根因:历史分段过多、索引总量过大,启动预热耗时高 方案:合理配置日志保留时长,清理过期冷数据,减少索引文件总量。
-
问题3:按时间回溯数据不准 根因:稀疏索引间隔过大,时间索引粒度粗糙,精准时间点无索引记录 方案:适当缩小索引间隔字节数,提升时间索引精度。
-
问题4:索引损坏导致集群启动告警 方案:无需手动修复,重启Broker自动重建索引,业务无影响。
七、高频面试必背考点
-
Kafka为什么采用稀疏索引而非稠密索引? 稠密索引每条消息生成索引,海量数据下会产生超大索引文件,占用大量磁盘和内存;稀疏索引通过二级检索,用极小的性能损耗,换取极低的资源占用,适配海量流式数据存储场景。
-
索引文件损坏会丢失消息吗? 不会。索引仅为检索元数据,真实业务数据存储在.log文件中,索引损坏可自动重建,不影响消息完整性。
-
稀疏索引的优缺点? 优点:磁盘内存占用极低、文件数量少、加载速度快; 缺点:精准检索需要二次顺序扫描,极致检索速度略低于稠密索引。
-
低流量场景索引会失效吗? 不会。低流量虽无法快速打满分段,但定时滚动机制会生成新分段,索引正常生成,仅索引稀疏度相对更高。
-
时间索引和偏移量索引的区别? 偏移量索引:按位移精准定位消息,服务日常消费、位移重置; 时间索引:按时间范围定位消息,服务日志清理、时间回溯、数据复盘。
4. 三大核心底层技术(Kafka超高吞吐核心根源·完整版)
Kafka 碾压传统消息队列的超高吞吐、低延迟性能,核心依托三大底层操作系统级技术:磁盘顺序写、零拷贝传输、页缓存PageCache,三者协同形成全链路性能优化闭环,以下为生产级原理、优势、面试考点、底层细节完整补全。
一、磁盘顺序写(核心性能基石)
1. 核心原理
Kafka 所有消息写入操作,均采用**文件末尾追加(Append)**的顺序写入模式,全程无磁盘随机写操作。生产者推送的新消息,只会追加到对应分区活跃日志分段文件的末尾,不会修改、覆盖文件原有历史数据,磁盘磁头无需频繁跳转寻址。
传统数据库、普通消息队列大量使用磁盘随机写,磁头需要在磁盘不同位置频繁跳转,寻址耗时极高;而顺序写全程磁头连续工作,规避了99%的磁盘寻址开销,性能实现质的飞跃。
2. 性能数据对比(生产实测)
-
磁盘顺序写:机械硬盘HDD可达100~200MB/s,SSD硬盘可达500MB/s+,性能接近内存读写;
-
磁盘随机写:机械硬盘仅1~5MB/s,性能差距近百倍;
-
核心结论:Kafka 依托顺序写,让低速磁盘具备了支撑高并发海量数据的能力,彻底突破磁盘IO瓶颈。
3. 生产配套设计
-
只读旧分段机制:日志滚动后旧分段只读,保证历史数据不会被修改,全程维持顺序写入特性;
-
批量攒批写入:配合生产者批量发送机制,单次IO写入多条消息,进一步放大顺序写性能优势;
-
数据持久化兜底:顺序写落地磁盘,保障数据持久化,规避内存存储的断电丢失风险。
4. 面试必背考点
-
为什么Kafka用磁盘存储还能超高吞吐? 核心不是磁盘本身快,是规避了随机IO,全程磁盘顺序写,结合批量、压缩机制,抵消磁盘低速短板;
-
顺序写的核心优势? 无磁头寻址开销、IO利用率拉满、吞吐极高、性能稳定无波动;
-
为什么传统MQ吞吐不如Kafka? 多数传统MQ依赖内存读写,持久化采用随机写,高并发下IO瓶颈严重,无法支撑海量数据。
二、零拷贝 sendfile(网络传输性能天花板)
1. 传统文件传输四次拷贝痛点
常规Java程序读取磁盘文件并网络发送,需要经过四次数据拷贝、四次内核态/用户态切换,CPU开销极大、延迟高:
-
磁盘 → 内核缓冲区(DMA拷贝);
-
内核缓冲区 → 用户态内存(CPU拷贝,状态切换);
-
用户态内存 → 内核Socket缓冲区(CPU拷贝,状态切换);
-
Socket缓冲区 → 网卡(DMA拷贝,发送数据)。
高并发海量数据场景下,频繁的内存拷贝和状态切换会耗尽CPU资源,严重限制吞吐上限。
2. Kafka零拷贝核心原理
Kafka 基于 Linux 内核 sendfile() 系统调用实现零拷贝,核心定义:全程不经过用户态内存,无CPU数据拷贝。
完整传输链路:磁盘文件 → 内核PageCache页缓存 → 网卡,仅两次DMA拷贝,彻底跳过用户态,规避所有CPU拷贝与状态切换开销。
3. 核心优势
-
零CPU开销:数据拷贝全程由DMA硬件完成,不占用CPU资源,CPU只需处理指令调度;
-
极低延迟:减少两次状态切换、两次内存拷贝,传输延迟大幅降低;
-
超高吞吐:彻底释放CPU性能,支撑单机百万级消息吞吐;
-
内存节省:无需分配用户态临时内存存储消息,减少内存占用。
4. 生产适用场景
消费者拉取历史海量日志、批量消息消费、日志回溯重放、跨节点副本同步,全程启用零拷贝传输,是Kafka高并发消费的核心保障。
三、页缓存 PageCache(性能与持久化平衡核心)
1. 核心原理
PageCache 是 Linux 操作系统内核维护的磁盘文件高速缓存区。Kafka 不会直接将消息写入磁盘,而是优先写入内存中的PageCache页缓存,由操作系统内核异步、批量将缓存数据刷入磁盘。
2. 核心机制
-
写机制:消息写入PageCache即返回写入成功,无需等待磁盘落盘,大幅降低写入延迟;
-
刷盘机制:内核定时、定量批量刷盘,合并多次小IO为一次大IO,减少磁盘写入次数;
-
读机制:热点消息常驻PageCache,消费者拉取数据优先读内存,速度接近内存读写。
3. 核心价值(解决核心矛盾)
完美平衡性能 与数据持久化的矛盾: 如果同步刷盘,每次写入都等待磁盘落盘,延迟极高、吞吐暴跌; 如果纯内存存储,断电数据全部丢失、无持久化能力; PageCache 实现「内存级读写速度 + 磁盘级数据持久化」,兼顾极致性能与数据可靠。
4. 生产核心规范与避坑
-
禁止开启SWAP:SWAP会将PageCache内存数据置换到磁盘,直接废掉页缓存性能,生产必须永久关闭;
-
内存预留:服务器预留充足内存给PageCache,禁止Kafka堆内存占满整机内存;
-
刷盘参数不随意修改:依赖内核默认异步刷盘策略,无需手动强制同步刷盘,避免性能损耗。
四、三大技术联动闭环(面试压轴考点)
写入链路 :生产者批量攒批 → 写入PageCache(低延迟) → 磁盘顺序刷盘(高吞吐持久化) 读取链路:优先读取PageCache(内存极速读) → 零拷贝sendfile传输(无CPU开销) → 推送消费者 三大技术层层联动,从写入、存储、读取、传输全链路优化,构成Kafka高吞吐、低延迟、高可靠的底层核心架构。
5. 读写分离误区(生产高频踩坑+面试深挖完整版)
Kafka原生完全不支持传统数据库式读写分离,所有生产、消费的读写请求必须仅访问分区Leader副本,Follower副本仅承担数据同步备份职责,不承接任何业务读写流量,这是Kafka核心架构硬性约束,也是大量开发、运维的高频认知误区。
一、核心底层机制(为什么不支持读写分离)
-
架构设计初衷 :Kafka核心优先保障数据一致性、时序性、高吞吐稳定性。所有读写收敛到Leader单节点,可规避多副本读写带来的数据不一致、消息时序混乱、位移错乱等问题,大幅简化分布式数据同步与消费位点管理逻辑。
-
Follower副本核心职责:仅主动拉取Leader增量数据、同步日志、维护ISR集合、故障待命接管,全程只读不对外提供服务,无任何读写请求处理逻辑。
-
位移机制约束 :消费位移、HW高水位线、LEO日志末端位移均以Leader节点数据为唯一基准,Follower数据存在短暂同步延迟,若从Follower消费,会出现数据漏读、重复读、消费位移错乱等严重问题。
二、三大高频认知误区(生产普遍踩坑)
误区1:多副本可以分担读压力,实现读写分离
真相:Follower副本不承接任何消费读请求,无论配置多少副本,所有读流量全部集中在Leader节点,副本数量无法分担读压力,仅能提升高可用容错能力,无法优化读性能。热点分区场景下,多副本完全无法解决单Leader负载过高的问题。
误区2:KRaft新架构支持读写分离
真相:KRaft仅优化了集群元数据管理、控制器选举、集群扩展性,业务数据读写逻辑完全未改动,依旧严格遵循Leader单节点读写机制,不支持Follower读流量分担。
误区3:从Follower消费可以降低Leader负载
真相:官方禁止、生产不推荐。Follower数据存在同步延迟,从Follower消费
会导致:新消息消费延迟、瞬时数据缺失、重平衡后位移重置异常、数据一致性错乱,得不偿失。
三、单Leader读写架构的优缺点
1. 核心优点(架构取舍的核心价值)
-
数据绝对一致:唯一Leader读写入口,无多节点数据同步延迟问题,消费数据时序、状态完全统一。
-
消费逻辑极简可靠:位移提交、重平衡、故障切换逻辑无需适配多节点读写,大幅降低分布式bug概率。
-
时序严格保障:严格保证单分区消息有序,不会因多节点分流打乱消息时序。
2. 核心缺点(生产性能瓶颈根源)
-
读能力上限固定:分区读并发完全绑定Leader节点,无法通过副本扩容读性能,单分区读TPS存在硬性上限。
-
热点负载无法分散:热点分区的读写压力全部集中在单一Leader Broker,极易引发单节点CPU、网卡、IO负载过高,导致集群负载倾斜。
-
资源利用率低:集群中大量Follower副本节点处于闲置待命状态,硬件资源无法充分利用。
四、生产读性能优化替代方案(规避读写分离短板)
既然无法通过Follower分担读压力,生产中通过以下合规方案提升整体消费能力,替代读写分离:
-
扩容分区数量(核心最优解) 分区是Kafka并发的唯一载体,增加分区数可拆分热点流量,分散至多Broker节点的Leader,横向提升整体读写并发能力,从根源解决读瓶颈。
-
扩容消费实例并行消费 在分区数充足的前提下,增加消费组实例数,提升单Topic整体消费TPS,适配高并发读场景。
-
拆分热点Topic 对超高流量热点业务,拆分独立Topic,与普通业务流量物理隔离,避免单点负载溢出影响全局。
-
开启批量消费、批量拉取 优化消费者
fetch.min.bytes、max.poll.records等参数,提升单次消费吞吐量,降低频繁拉取的网络开销。 -
数据预计算、缓存兜底 对重复查询、热点消费数据,通过Flink预计算、本地缓存、Redis缓存兜底,减少重复消费拉取压力。
五、面试高频压轴考点
-
Kafka为什么不做读写分离? 核心为了保障数据时序一致性、消费位移可靠性。多副本读写分离会引发数据延迟、漏读重读、时序混乱,牺牲一致性换取性能,不符合Kafka流式数据精准流转的核心定位。
-
Kafka副本的核心作用是什么? 不用于负载均衡,仅用于故障容灾、数据冗余备份,Leader故障时自动选举新Leader,保障业务不中断、数据不丢失。
-
如何解决Kafka读性能瓶颈? 核心方案:扩容分区、拆分热点Topic、优化消费批量参数、扩容消费实例,无读写分离捷径。
-
Kafka和RabbitMQ读写机制的核心区别? RabbitMQ支持多节点负载分担读写,Kafka严格单Leader读写,架构设计侧重点完全不同,Kafka优先可靠时序,RabbitMQ优先负载均衡。
2.6 日志清理策略(生产核心+面试必考·完整版)
Kafka 所有消息持久化落地磁盘后,不会消费完成即删除,依赖后台日志清理线程 自动回收过期、冗余数据,实现磁盘循环复用。核心支持 Delete 删除、Compact 日志压缩 两种策略,同时支持两种策略混用,不同策略适配完全不同的业务场景,是生产Topic配置、数据留存、磁盘治理的核心依据。
全局核心前置规则:日志清理仅针对已归档的只读日志分段,当前活跃写入的Segment不会执行清理、压缩操作,避免破坏正在写入的数据流,保障读写稳定性。
1. Delete 删除策略(默认策略)
Delete 是 Kafka 全局默认日志清理策略,核心逻辑为基于时间/文件大小阈值,自动清理过期只读日志分段,逐条回收磁盘空间,适用于流式临时数据场景。
1.1 核心触发条件(满足任一即触发清理)
-
时间阈值(最常用) :通过
log.retention.ms配置消息最大保留时长,集群默认7天(604800000ms)。消息存储时长超过该值后,对应日志分段标记为过期,等待后台线程清理。 -
空间阈值 :通过
log.retention.bytes配置单分区最大磁盘占用上限。当分区总日志大小超过该阈值,会优先清理最旧的日志分段,直至空间低于阈值。
1.2 配套核心参数(生产必调)
-
log.segment.bytes:日志分段大小,默认1GB,单文件达到阈值触发分段滚动,转为只读文件等待清理。 -
log.cleaner.backoff.ms:日志清理线程执行间隔,默认15s,控制清理频率,避免频繁IO占用资源。 -
file.delete.delay.ms:日志文件标记过期后,延迟删除时间,默认60s,防止文件正在被消费、读取时误删,规避业务异常。
1.3 适用场景
-
实时流式临时数据:日志采集、用户埋点、实时流量数据、异步事件消息;
-
无需长期存储、无需回溯历史全量数据的常规业务;
-
数据仅用于实时消费,过期数据无业务价值。
1.4 生产避坑要点
-
默认7天保留时长需按需调整,超大流量集群建议缩短至1-3天,避免磁盘爆满;
-
仅过期只读分段会被清理,活跃分段即使数据超时也不会删除,存在短暂数据冗余;
-
空间阈值优先级高于时间阈值,配置后会优先保障磁盘空间不溢出。
2. Compact 日志压缩策略(状态数据专属)
日志压缩是 Kafka 专为KV状态型数据 设计的特殊清理策略,核心逻辑为保留每个消息Key的最新版本数据,删除所有历史旧版本数据,在保留最新状态的同时大幅节省磁盘空间,区别于单纯的过期删除。
2.1 核心执行原理
-
后台专属日志压缩线程(Cleaner)扫描分区所有只读日志分段;
-
基于消息Key做全局去重,仅留存同一Key的最新一条消息;
-
清理Key对应的所有历史冗余消息,生成新的精简日志分段;
-
替换旧分段,保留最新状态数据,实现磁盘空间回收;
-
活跃写入分段不参与压缩,保证新消息写入无阻塞。
2.2 关键特殊机制(面试高频)
-
删除墓碑机制:若消息为Key+空Value(墓碑消息),代表该Key已被删除。压缩后会保留该墓碑消息,等待指定时间后彻底清除,保证下游消费感知Key删除状态,避免数据一致性问题。
-
压缩延迟性:压缩为后台定时异步操作,非实时执行,Key更新后短期内仍会残留历史旧数据,无法立即瘦身。
-
起点保留机制:压缩后的日志会保留分区起始位移,保证消费者可以从分区头部正常消费,不破坏日志连续性。
2.3 核心配置参数
-
log.cleanup.policy=compact:开启日志压缩策略; -
log.cleaner.min.compaction.lag.ms:消息最小压缩延迟,保证新写入数据不会立即被压缩; -
log.cleaner.max.compaction.lag.ms:最大压缩延迟,超时强制触发压缩,避免数据长期冗余; -
delete.retention.ms:墓碑消息保留时长,默认24小时,超时彻底删除无效Key数据。
2.4 适用场景
核心适配状态变更、配置同步、KV映射类低频更新、需留存最新状态的业务:
-
用户配置、账号状态、权限信息实时同步;
-
数据库全量+增量同步最终状态留存;
-
设备状态、业务配置、缓存映射数据更新;
-
需要随时回溯最新数据状态,无需历史变更记录的场景。
2.5 生产优缺点总结
优点:极致节省磁盘空间、永久留存每个Key最新状态、支持从分区头部消费最新全量数据、适配配置类数据持久化;
缺点:压缩存在延迟,短期存在数据冗余;后台压缩线程占用少量CPU/IO资源;不适合无固定Key、高频无序流式数据。
3. 混合清理策略(compact,delete 生产高阶用法)
Kafka 支持同时开启 压缩+删除 双策略,兼顾状态留存与过期清理,是中高端生产场景常用配置。
3.1 执行逻辑
优先执行日志压缩(保留各Key最新数据),再基于时间阈值清理压缩完成后的过期数据,既保证最新状态不丢失,又避免数据无限堆积。
3.2 适用场景
-
需留存最新状态,同时需清理数月前过期历史数据的业务;
-
核心配置数据、设备状态数据,兼顾状态有效性与磁盘容量管控。
4. 生产核心规范与避坑大全
-
策略严格匹配场景:流式日志、埋点数据用Delete;配置、状态、KV数据用Compact;长期留存状态需过期清理用混合策略,禁止策略混用错配。
-
禁止关闭日志清理:手动设置永久保留数据会导致磁盘无限膨胀,最终引发集群磁盘爆满、只读故障。
-
压缩Topic必须带Key:无Key消息无法去重压缩,会导致压缩失效、磁盘无法瘦身,状态类业务必须规范消息Key设计。
-
规避压缩性能抖动:超大分区避免频繁压缩,合理配置压缩延迟参数,错开业务流量高峰期执行压缩任务。
-
墓碑消息合理配置:短生命周期业务可缩短墓碑保留时长,快速释放磁盘空间;核心状态业务保留默认时长,保证数据同步一致性。
5. 面试高频必背考点
-
两种日志清理策略的核心区别? Delete:按时间/大小清理过期全量日志,适配流式临时数据; Compact:按Key去重保留最新状态,适配KV状态数据,不依赖过期时间清理。
-
日志压缩会删除最新数据吗? 不会,仅删除同一Key的历史旧数据,严格保留最新版本,且不处理活跃写入分段。
-
墓碑消息的作用是什么? 标记Key删除状态,避免下游消费丢失删除事件,等待超时后彻底清理无效数据,保障分布式数据一致性。
-
为什么压缩Topic消息必须带Key? 日志压缩的核心维度是消息Key,无Key消息无法完成去重逻辑,压缩策略直接失效。
-
混合策略的执行顺序? 先压缩去重,再删除过期数据,兼顾状态留存与磁盘空间回收。
2.7 消息完整生命周期(超全生产级完整版)
Kafka 一条消息从业务生成、客户端发送、集群存储、副本同步、消费处理、位移提交、最终磁盘清理 ,会经历完整的全链路生命周期。本节拆解七大核心阶段、20+细分步骤,补齐底层机制、参数关联、生产特性、面试考点,是理解Kafka数据可靠性、性能原理、故障问题的核心基石。
第一阶段:客户端消息构造与预处理(生产者侧)
该阶段完成消息封装、格式处理、路由分发,是消息生命周期的起点,所有优化(批量、压缩、分区路由)均在此阶段生效。
-
业务消息初始化:业务代码生成原始数据,封装Kafka消息核心载体,包含Topic、Key、Value、Headers、时间戳、消息序号等核心字段,无格式数据直接丢弃。
-
数据序列化:根据配置的序列化器(Json/Avro/Protobuf),将对象数据转为二进制字节数组,未序列化、序列化失败的消息直接拦截,不会进入发送队列。
-
分区路由计算:根据消息Key、分区策略(哈希路由/粘性分区/自定义路由)计算目标分区,无Key消息默认启用粘性分区策略,保证批量消息发送至同一分区,提升批量效率。
-
客户端缓冲区攒批 :消息写入生产者核心缓冲区RecordAccumulator,按照
batch.size(批量大小)、linger.ms(等待超时)双阈值攒批,未满足条件则持续等待攒批,最大化批量发送性能。 -
消息压缩处理:满足批量条件后,按照配置的压缩算法(LZ4/Snappy/GZIP)批量压缩消息,减少网络传输流量与磁盘存储占用,压缩后统一封装为批量消息批次。
-
网络异步发送 :Sender后台线程轮询缓冲区,将批量消息批次发送至目标分区Leader节点 ,自动重试机制处理临时网络抖动、发送失败场景,重试次数由
retries参数控制。
第二阶段:集群写入与持久化(Broker Leader侧)
消息抵达集群Leader节点,完成校验、缓存写入、磁盘落地,正式存入Kafka集群,完成数据持久化核心流程。
-
请求校验与解析:Leader Broker接收TCP请求,完成权限校验、消息格式校验、Topic与分区合法性校验,非法请求直接返回异常,丢弃无效消息。
-
页缓存优先写入:消息不直接落盘磁盘,优先写入Linux PageCache页缓存,写入缓存即视为写入成功(默认异步刷盘),大幅降低写入延迟。
-
磁盘顺序追加写入 :消息以Append追加方式,顺序写入分区当前活跃日志Segment文件,无随机IO操作,保障超高写入吞吐。
-
索引文件同步更新:同步更新分区位移索引、时间索引,记录当前消息的物理存储位置与时间戳,为后续消息检索、回溯、清理提供索引支撑。
-
磁盘异步刷盘 :由操作系统内核定时、定量批量将PageCache数据刷入磁盘,规避频繁小IO开销,刷盘策略由
log.flush.*系列参数控制,生产默认异步刷盘兼顾性能与可靠。
第三阶段:副本同步与数据确认(高可用核心)
该阶段实现多副本数据冗余,保障消息不丢失,是Kafka高可用的核心环节,完全依赖ISR、HW水位线机制。
-
Follower拉取增量数据:ISR集合内的所有Follower副本,主动定时拉取Leader节点的增量消息数据,同步本地日志与索引文件。
-
ISR同步状态校验:Follower完成数据同步后,维持在ISR集合内;同步超时、滞后过多的副本会被踢出ISR,等待重新同步。
-
更新分区HW高水位线 :当消息同步至所有ISR副本后,分区HW水位线更新至当前消息位移,标记该消息已完成集群可靠存储。
-
返回生产ACK响应 :根据生产者
acks配置返回写入结果:acks=0无需确认、acks=1 Leader写入即确认、acks=-1需ISR全同步确认,生产者接收ACK后判定消息发送成功。
第四阶段:数据静态存储与留存(待机等待消费)
消息完成集群存储后,进入静态留存阶段,等待消费者拉取消费,期间不会主动删除,支持任意时间回溯重放。
-
活跃分段常驻缓存:当前正在写入的活跃日志Segment常驻PageCache,消费者可毫秒级拉取,保障热点数据读取性能。
-
日志分段滚动归档 :当活跃分段大小达到
log.segment.bytes(默认1GB)或到达滚动时间阈值,触发日志滚动,当前分段转为只读归档文件,新建空分段承接新消息写入。 -
数据长期留存:归档后的只读分段,按照Topic配置的保留时长、空间阈值持续留存,默认保留7天,期间支持消费者任意回溯消费、故障数据重跑。
第五阶段:消费者拉取与业务处理(消费核心链路)
消费者主动拉取消息、执行业务逻辑,完成消息的业务落地,是消息生命周期的核心业务环节。
-
消费者初始化与分区分配:消费组实例启动,完成集群元数据拉取、分区负载分配,绑定对应消费分区,监听分区新消息。
-
批量Pull拉取消息 :消费者主动向分区Leader节点发起拉取请求,根据
fetch.min.bytes、max.poll.records批量拉取未消费消息,默认批量拉取提升消费吞吐。 -
零拷贝传输与反序列化:Broker通过sendfile零拷贝机制传输批量消息,消费者接收后完成二进制数据反序列化,还原原始业务数据。
-
业务逻辑执行:消费者执行业务处理(数据统计、事件分发、数据同步、流程流转等),处理失败则触发本地重试、死信转发机制。
-
异常兜底处理:消费异常、业务报错时,根据配置策略重试,多次失败后转发至死信Topic,避免消息无限堆积阻塞消费链路。
第六阶段:消费位移提交与状态固化(可靠性兜底)
位移提交是标记消息消费状态的核心,决定消息是否重复消费、丢失,是消费可靠性的关键环节。
-
位移提交时机判定 :分为自动提交(定时提交)、手动提交(业务执行成功后提交),生产核心业务强制手动后置提交,规避消息丢失问题。
-
位移持久化写入 :将当前分区最新消费位移,批量提交至集群
__consumer_offsets系统Topic,永久固化消费点位。 -
断点续消费生效:服务重启、重平衡、节点故障后,消费者重启后自动读取持久化位移,从上次消费位置继续消费,实现断点续跑。
-
重平衡容错处理:消费组实例变更触发重平衡时,未提交位移的消息会重新分配给组内其他实例,天然产生重复消费,需业务层幂等兜底。
第七阶段:日志清理与磁盘回收(生命周期终结)
消息完成消费、超出留存周期后,集群后台线程自动清理冗余数据,释放磁盘空间,完成消息生命周期闭环。
-
后台清理线程扫描:集群日志清理线程定时扫描所有只读归档分段,根据Topic配置的清理策略判定是否清理。
-
策略差异化处理: 1. Delete策略:清理超出时间/空间阈值的全量过期分段,回收磁盘空间; 2. Compact策略:保留每个Key的最新消息,删除历史冗余版本,留存最新状态数据; 3. 混合策略:先压缩去重、再清理过期数据,兼顾状态留存与磁盘管控。
-
墓碑消息过期清理:压缩策略下的Key删除墓碑消息,超时后彻底清除,完全释放无效数据占用的磁盘空间。
-
磁盘空间复用:清理后的磁盘空间由集群自动回收,用于存储新消息,实现磁盘资源循环利用,单条消息生命周期彻底终结。
一、生命周期核心机制串联(面试必背)
高性能链路:客户端批量攒批+数据压缩 → 磁盘顺序写 → PageCache缓存读写 → 零拷贝传输
高可靠链路:多副本ISR同步 → HW水位线兜底 → 位移持久化 → 日志策略可控清理
容错链路:生产重试机制 → 消费重试/死信兜底 → 重平衡位移容错 → 历史数据可回溯
二、生命周期高频面试考点
-
消息什么时候才算真正写入成功? 以acks配置为准,acks=-1时,消息写入Leader、同步至所有ISR副本、更新HW水位线后,才算真正写入成功,数据不会丢失。
-
消息消费完成后会立即删除吗? 不会。Kafka无消费即删机制,消息仅按时间/大小/压缩策略后台清理,消费完成后仍会留存,支持回溯重放。
-
重复消费的核心生命周期节点? 重平衡、位移提交失败、网络超时重试,均会导致已处理消息未固化位移,触发重新拉取消费。
-
数据丢失的关键风险节点? Leader未落盘宕机、acks配置过低、位移前置提交、消息未消费即被日志清理,是四大丢数场景。
-
PageCache在生命周期中的作用? 写入阶段低延迟落盘、读取阶段热点数据极速读取,平衡磁盘持久化与内存级性能,是全链路性能核心。
简洁
生产者发送 → 写入 Leader 日志 → Follower 同步 → 数据到达 HW → 消费者拉取消费 → 提交位移 → 消息超时/大小触发日志清理。
第三部分 高阶特性(生产必备)
3.1 三大消息投递语义(面试高频·完整版)
Kafka 消息投递语义,定义了生产者发送消息、消费者消费消息 的最终一致性保障规则,是解决消息丢失、重复消费、数据一致性问题的核心理论基础,也是面试必考、生产必懂的核心知识点。Kafka 原生支持三种投递语义,核心差异在于消息丢失、消息重复的取舍,所有生产消息一致性问题,均围绕这三种语义展开。
1. 至多一次(At Most Once)
核心定义 :消息最多被消费一次,绝对不会重复消费,但存在丢失风险。
核心实现原理 :先提交消费位移,后执行业务消费逻辑。消费者拉取到消息后,立刻向集群提交最新消费位移,标记消息已消费,再执行业务处理。
触发问题场景:位移提交成功后,若服务宕机、程序报错、进程终止,后续业务逻辑未执行完成,消息永久丢失,无法再次消费。
生产配置与落地方式:
-
开启消费者自动位移提交(默认开启);
-
位移提交时机早于业务执行,无手动兜底逻辑。
优缺点总结
-
优点:无重复消费,无需业务幂等设计,消费性能最高;
-
缺点:存在消息丢失,数据可靠性极低。
适用业务场景:对数据完整性无强要求,允许少量数据丢失的极致高吞吐场景,如非核心日志采集、临时用户埋点、实时监控打点、设备心跳上报。
面试高频追问:生产中几乎不主动使用,仅老旧简陋业务存在该场景,核心业务绝对禁止。
2. 至少一次(At Least Once)【Kafka 默认语义】
核心定义 :消息绝对不会丢失,一定会被消费至少一次,但存在重复消费风险,是 Kafka 出厂默认的投递语义。
核心实现原理 :先执行业务消费逻辑,成功后再提交消费位移。消费者拉取消息后,优先完成业务处理,业务执行无异常,再提交位移标记消费完成。
重复消费核心诱因(面试必考)
-
业务消费成功,位移提交前服务宕机、重启;
-
网络超时、集群抖动,位移提交请求未送达集群;
-
消费组触发重平衡(Rebalance),未提交位移的分区被重新分配;
-
消费者会话超时,集群判定消费者离线,重置消费位点。
生产配置与落地方式:
-
默认配置即为至少一次语义;
-
生产核心业务建议关闭自动提交,开启手动后置位移提交,强化可靠性。
优缺点总结
-
优点:零消息丢失,数据可靠性高,适配绝大多数生产业务;
-
缺点:天然存在重复消费,必须业务层兜底。
生产强制解决方案 :业务全局实现幂等性,保证重复消费不会产生脏数据、重复下单、重复统计等问题。
幂等常用实现方案:唯一主键去重、业务状态机校验、Redis 分布式锁、全局唯一ID幂等校验。
适用业务场景:绝大多数核心业务,如数据同步、订单事件、消息通知、用户行为统计、实时数据分析、IoT设备数据采集。
3. 恰好一次(Exactly Once)【精准一致性】
核心定义 :消息零丢失、零重复,有且仅有一次消费,是消息投递的最高一致性语义。
核心落地难点:无法仅靠消费者位移实现,必须生产者、服务端、消费者三层联动,是 Kafka 高阶特性的核心难点。
完整实现条件(面试必背四件套)
-
开启幂等生产者:解决生产者重试导致的消息重复发送问题,依托PID+消息序列号实现单分区、单会话去重;
-
开启Kafka事务机制:支持跨分区、跨批次原子读写,保证批量消息要么全部写入成功,要么全部回滚;
-
事务式位移提交:将消费位移提交、业务消息生产纳入同一事务,实现消费+生产的原子性;
-
配合集群高可靠机制:acks=-1、最小同步副本数校验,杜绝消息丢失。
核心适用场景:对数据一致性、精准度要求极高,绝对不允许丢失和重复的业务,如金融交易数据同步、实时账单统计、库存扣减、数据仓库精准计算、计费结算业务。
优缺点总结
-
优点:实现精准一次性消费,数据绝对一致;
-
缺点:性能损耗10%~20%、配置复杂、开发成本高、仅高版本(0.11+)支持。
4. 三大语义核心对比&面试总结表
|----------|------|------|--------------|-------------|
| 投递语义 | 消息丢失 | 消息重复 | 核心方案 | 适用场景 |
| 至多一次 | 可能丢失 | 绝不重复 | 先提交位移、后消费 | 非核心、可丢数据场景 |
| 至少一次(默认) | 绝不丢失 | 可能重复 | 后置提交位移+业务幂等 | 绝大多数生产业务 |
| 恰好一次 | 绝不丢失 | 绝不重复 | 幂等+事务+事务位移提交 | 金融、精准计算核心场景 |
5. 面试终极压轴考点
-
Kafka默认的消息投递语义是什么?为什么? 默认至少一次。优先保障数据不丢失,适配绝大多数互联网业务,重复消费可通过业务幂等兜底,是可靠性与性能的最优平衡。
-
为什么不能默认恰好一次? 恰好一次需要开启事务、幂等机制,会损耗集群吞吐性能,配置复杂、运维成本高,绝大多数业务无需极致一致性,性价比极低。
-
不开启事务,仅靠业务幂等能实现恰好一次吗? 不能。仅业务幂等只能解决重复消费问题,无法解决生产者重试、跨分区数据不一致问题,无法实现真正的Exactly Once。
-
三种语义如何手动切换? 至多一次:前置提交位移;至少一次:后置手动提交位移;恰好一次:开启幂等+事务+事务位移提交。
3.2 幂等生产者 + 事务(0.11+ 核心高阶,生产必落地)
Kafka 在 0.11.0 版本 重磅引入幂等生产者与事务机制,彻底解决原生消息重复发送、跨分区数据不一致问题,是实现 Exactly Once 精准投递语义 的核心基石。二者搭配使用,可实现生产-消费全链路数据一致性,支撑金融、计费、精准统计等核心业务。
1. 幂等生产者(解决生产者重复发送问题)
1.1 核心背景
默认生产者存在重试重复发送 问题:网络抖动、Broker 临时拥堵、响应超时场景下,生产者未收到 ACK 响应,会触发重试机制重复发送同一条消息,导致下游重复消费,业务产生脏数据。幂等生产者就是为解决单会话、单分区消息重复发送问题而生。
1.2 开启配置(生产标准)
全局开启幂等能力,新版 Kafka 客户端默认关闭,需手动开启:
-
enable.idempotence=true(核心开关,开启幂等生产者) -
开启后自动适配参数:
retries=Integer.MAX_VALUE、max.in.flight.requests.per.connection=5,无需手动修改
1.3 底层实现原理(面试必考)
Kafka 为每个幂等生产者客户端分配唯一标识 PID(生产者ID) ,同时为每条消息分配全局递增的 Sequence 序列号,核心去重逻辑:
-
生产者启动时,向集群申请唯一 PID,同一客户端会话 PID 固定;
-
发送消息时,每条消息携带
PID+分区+Sequence序列号三元组标识; -
Broker 端存储每个 PID、对应分区的最新最大序列号;
-
收到重复三元组消息时,Broker 直接静默丢弃,不返回异常、不重复存储,实现服务端自动去重。
1.4 核心使用限制(生产避坑重点)
-
仅支持单会话去重:生产者重启后会重新申请 PID,旧 PID 失效,重启前未确认的消息重试会产生重复,无法跨会话去重;
-
仅支持单分区去重:序列号为分区维度递增,跨分区无法校验重复,不解决跨分区消息重复问题;
-
不支持无序发送:开启幂等后,强制保证单分区消息有序,禁止乱序发送,无序消息会触发发送失败。
1.5 生产适用场景
需要规避网络重试导致的消息重复发送、单分区数据精准写入、无需跨分区事务的绝大多数业务场景,是生产通用标配配置。
2. Kafka 事务机制(解决跨分区/跨会话原子性)
幂等生产者仅能解决单分区、单会话重复问题,无法实现跨分区、跨批次、生产者重启后的原子一致性,事务机制弥补该短板,实现批量消息、多分区读写的原子性(要么全部成功、要么全部回滚)。
2.1 核心事务组件
-
事务ID(transactional.id):业务唯一标识,可跨生产者会话复用,实现断点续事务;
-
事务协调器(Transaction Coordinator):集群指定 Broker,负责管理事务状态、处理事务提交/回滚、超时判定;
-
事务状态日志(__transaction_state):系统内置 Topic,持久化存储所有事务的运行状态、关联分区、超时时间,保证事务可靠性。
2.2 完整事务执行流程
-
事务初始化:带事务ID的生产者启动,向事务协调器发起注册,获取事务状态;
-
开启事务 :客户端调用
beginTransaction(),标记事务开始; -
批量消息写入:向多个分区发送消息,所有消息暂存事务上下文,不对外可见;
-
事务提交/回滚:业务执行成功则提交事务,所有消息批量生效;业务异常则回滚,所有消息废弃;
-
状态固化:事务最终状态同步至 __transaction_state,集群全局生效。
2.3 核心能力与价值
-
支持跨多个分区、多个批次消息原子写入;
-
支持消费-生产事务:将消费位移提交、新消息生产纳入同一事务;
-
支持跨生产者会话事务恢复,规避重启导致的数据不一致;
-
事务未提交的消息,消费者默认不可见,避免脏数据消费。
2.4 生产强制配置参数
-
enable.idempotence=true:事务依赖幂等能力,必须开启; -
transactional.id=xxx-business-trans:唯一业务事务ID,全局唯一; -
transaction.timeout.ms=60000:事务超时时间,默认1分钟,超时自动回滚; -
消费者配置:
isolation.level=read_committed(仅消费已提交事务消息,默认配置)。
2.5 事务核心限制(生产避坑)
-
事务消息会产生性能损耗(10%-20%),高吞吐非核心业务不建议滥用;
-
事务超时未提交会被强制回滚,导致批量消息丢失,需合理配置超时时间;
-
不支持跨 Topic 大量分区事务,分区过多会导致事务状态同步超时;
-
事务ID必须全局唯一,重复会导致事务状态冲突、消息发送失败。
3. Exactly Once 精准投递 完整落地方案(生产标准)
单独幂等、单独事务均无法实现真正的恰好一次语义,必须四件套组合生效,覆盖生产、存储、消费全链路:
-
开启幂等生产者:解决单会话、单分区生产重复问题;
-
开启Kafka事务机制:解决跨分区、跨会话、批量读写原子性问题;
-
事务式位移提交:将消费位移提交与业务消息生产纳入同一事务,实现消费+生产原子性;
-
服务端高可靠兜底 :配置
acks=-1、min.insync.replicas=2,杜绝消息丢失。
4. 生产代码极简实战(Java)
java
// 1. 事务生产者配置
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "集群地址:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 开启幂等
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 配置全局唯一事务ID
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "order-business-trans-01");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 初始化事务
producer.initTransactions();
try {
// 开启事务
producer.beginTransaction();
// 批量发送多分区消息
producer.send(new ProducerRecord<>("order-topic", "order1", "订单创建"));
producer.send(new ProducerRecord<>("pay-topic", "pay1", "支付记录"));
// 业务逻辑执行...
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 异常回滚事务
producer.abortTransaction();
} finally {
producer.close();
}5. 面试高频压轴考点
-
幂等生产者和事务的区别? 幂等:解决单分区、单会话生产重复 ,无原子性能力,性能高; 事务:解决跨分区、跨会话原子一致性,依赖幂等,有性能损耗。
-
为什么开启事务必须开启幂等? 事务机制的消息去重、状态校验底层依赖幂等生产者的 PID+序列号机制,不开启幂等则事务无法保证数据唯一性。
-
消费者需要什么配置才能感知事务? 默认
read_committed模式,仅消费事务提交成功的消息,忽略回滚、未完成事务的消息,避免脏数据。 -
仅用业务幂等能替代Kafka事务吗? 不能。业务幂等只能解决消费重复问题,无法解决生产者重试、跨分区数据不一致、事务回滚场景的数据脏写问题。
-
幂等生产者支持跨生产者实例去重吗? 不支持。仅单实例会话有效,生产者重启、扩容后 PID 变更,无法实现跨实例去重,需事务机制兜底。
3.3 延迟队列 & 死信队列(原生短板+生产全套落地方案)
核心前置结论(面试/生产必考) :Kafka 无原生延迟队列、无原生死信队列、无消息重试机制,这是相较于RocketMQ、RabbitMQ的核心短板。官方仅聚焦流式数据传输与高吞吐能力,未封装业务层延时、异常消息隔离逻辑,所有延时任务、消息重试、死信兜底场景,均需业务层自主封装实现,以下为企业生产标准化落地全套方案。
一、Kafka原生核心短板详解
-
无精准延时投递能力:不支持指定消息延时消费(5分钟/1小时后消费),无法直接实现订单超时取消、定时任务、延时通知等场景;
-
无内置重试机制:消费异常、业务报错、临时故障时,消息不会自动重试,直接丢失或永久堆积;
-
无死信隔离机制:消费失败的脏消息、异常消息无法自动隔离,会持续阻塞消费链路,导致正常消息无法消费;
-
无消息生命周期管控:无法自定义消息重试次数、重试间隔,异常消息会无限重试,引发服务雪崩。
二、延迟队列 生产全套落地方案
针对Kafka无原生延时能力,业界主流两套生产级方案,分别适配简单低精度延时 和高精度海量延时场景。
1. 分层时间轮Topic方案(零依赖、轻量首选)
(1)核心原理
按照延时时间梯度拆分多个专用延时Topic,对消息进行分类投递,消费者轮询监听所有延时Topic,到达指定时间后转发至业务Topic,实现延时消费效果。完全基于Kafka原生能力,无第三方组件依赖,运维成本极低。
(2)分层规范(企业通用梯度)
按业务常用延时维度拆分,覆盖绝大多数延时场景:
-
delay-1m:1分钟延时(订单待支付、临时校验)
-
delay-5m:5分钟延时
-
delay-10m:10分钟延时
-
delay-30m:30分钟延时
-
delay-1h:1小时延时
-
delay-24h:24小时延时(次日通知、超时复盘)
(3)完整执行流程
-
业务生成延时消息,根据预设延时时长,投递到对应梯度的延时Topic;
-
专属延时消费者持续轮询监听所有延时Topic;
-
消费时判断当前时间是否达到消息预设执行时间;
-
未到执行时间:不处理,等待下一轮轮询;
-
到达执行时间:将消息转发至目标业务Topic,供业务消费者正常消费;
(4)优缺点与适用场景
-
优点:零外部依赖、实现简单、稳定性高、适配海量消息、无性能瓶颈;
-
缺点:仅支持固定梯度延时,无法实现任意精准延时;轮询存在秒级误差;
-
适用场景:订单超时取消、超时未支付、延时通知、简单定时任务等低精度延时场景。
2. 外置调度框架方案(高精度任意延时)
(1)核心原理
结合 Redis时间轮 / XXL-Job / Quartz 等调度组件,存储延时消息的唯一ID、执行时间、目标Topic、消息体,通过调度框架精准触发延时任务,到期后推送消息至业务Topic。
(2)执行流程
-
业务生成延时消息,将消息元数据存入调度框架;
-
调度框架精准计时,到达指定延时时间;
-
主动拉取消息体,推送至对应业务Kafka Topic;
-
业务消费者正常消费处理。
(3)优缺点与适用场景
-
优点:支持任意精准延时、毫秒级精度、灵活度极高;
-
缺点:依赖第三方组件、架构复杂度提升、需保障调度组件高可用;
-
适用场景:精准定时任务、限时活动、精准延时回调、高精准度业务场景。
3. 生产避坑要点
-
禁止单Topic承载所有梯度延时消息,会导致轮询压力集中、延时不准;
-
延时消息必须携带唯一业务ID、预设执行时间、目标业务Topic,避免转发错乱;
-
延时消费者需单独配置消费组,与业务消费组隔离,互不影响;
-
超大流量延时场景优先使用分层时间轮方案,避免调度框架性能瓶颈。
三、死信队列DLQ 生产标准化方案
死信队列(Dead Letter Queue)是Kafka业务容错的核心机制,用于隔离多次消费失败、异常脏数据、无法正常处理的消息,避免异常消息阻塞主消费链路,保障核心业务稳定运行,是生产必须落地的规范。
1. 核心定义与适用消息
满足以下条件的消息,统一转发至死信Topic:
-
业务消费报错、数据格式异常、参数缺失,无法正常处理;
-
配置最大重试次数后,仍消费失败的消息;
-
非法脏数据、过期数据、不符合业务规范的异常消息。
2. 标准执行流程(生产通用)
-
正常消费:消费者拉取业务消息,执行业务逻辑;
-
异常重试:消费失败后,触发本地重试机制(默认3次,可自定义),间隔固定时间重试;
-
重试失败兜底:达到最大重试次数仍消费失败,判定为死信消息;
-
死信转发:将消息完整转发至对应业务的死信Topic,记录异常日志、报错信息、重试次数;
-
清空本地位点:正常提交当前消息位移,避免重复重试、阻塞消费链路;
-
事后运维兜底:定时监控死信Topic堆积,人工排查问题、修复数据、批量重试恢复。
3. 企业Topic命名规范(强制统一)
按业务维度拆分死信Topic,禁止全局共用死信Topic,避免业务耦合:
-
标准格式:
{business}-topic-dlq -
示例:order-business-dlq(订单业务死信)、user-behavior-dlq(用户行为死信)
4. Spring-Kafka 生产级配置(可直接复用)
依托Spring-Kafka内置重试+死信机制,无需手动硬编码,开箱即用:
java
// 消费重试+死信队列配置
@Bean
public RetryTopicConfiguration retryTopicConfiguration(KafkaTemplate<String, String> kafkaTemplate) {
// 最大重试3次,重试间隔1秒
return RetryTopicConfigurationBuilder
.newInstance()
.maxAttempts(3)
.fixedBackOff(1000)
// 开启死信队列,自动命名
.dltProcessingEnabled(true)
.dltSuffix("-dlq")
.kafkaTemplate(kafkaTemplate)
.build();
}5. 死信消息运维规范
-
实时监控告警:死信Topic产生消息即触发告警,及时发现业务异常;
-
消息溯源:死信消息必须保留原始消息体、异常堆栈、重试次数、消费时间,便于问题排查;
-
定期清理与重试:修复业务BUG后,支持批量消费死信Topic,重跑异常数据;
-
禁止自动删除:死信消息需留存7天以上,用于故障复盘、数据对账。
四、面试高频核心考点总结
-
Kafka为什么不支持原生延迟队列和死信队列? Kafka核心定位是高吞吐流式数据总线,聚焦数据高速流转、持久化、分布式存储,而非业务层任务调度、异常容错。延时、死信、重试属于业务场景能力,会增加集群复杂度、损耗吞吐性能,因此社区选择轻量化内核,由业务层自主实现。
-
分层时间轮延迟队列的优缺点? 优点:无第三方依赖、性能高、稳定性强、适配海量场景;缺点:仅支持固定梯度延时,无任意精准延时能力。
-
死信队列的核心作用? 隔离消费失败的异常消息,避免脏数据阻塞主消费链路,保障正常业务运行,同时留存异常数据用于故障排查和数据恢复。
-
可以所有业务共用一个死信Topic吗? 不可以。共用会导致业务异常耦合、问题排查困难、数据混乱,生产必须按业务线拆分独立死信Topic。
3.4 流式计算生态(生产实战+面试核心全解)
Kafka 核心定位为分布式流式数据平台 ,不止是消息队列,更是实时流式计算的核心底座。完整流式生态以 Kafka 为数据总线,搭配轻量内置流处理、重量级分布式计算引擎,覆盖轻量实时清洗、复杂流式聚合、实时数仓、实时风控等全场景,是大数据实时架构的核心基石。本节完整拆解全生态组件、核心原理、技术对比、时间语义、窗口机制与生产落地规范。
一、流式生态整体架构
完整实时流式链路:多源数据采集 → Kafka 数据缓冲与分发 → 流式计算引擎处理 → 结果落地存储/业务消费
-
数据接入层:Filebeat、Fluent Bit、Canal、业务客户端,统一汇聚全量实时数据流
-
数据总线层:Kafka 承担数据解耦、持久化、流量削峰、数据回溯,统一数据口径
-
流式计算层:Kafka Streams、Flink、Spark Streaming 分层适配不同计算场景
-
数据落地层:MySQL、ES、ClickHouse、数据湖、业务服务、监控告警系统
二、Kafka Streams 官方轻量级流处理
1. 核心定位与特性
Kafka Streams 是 Kafka 官方内置的轻量级、无集群依赖流式计算库,无需独立部署集群,仅通过客户端 API 即可实现流式数据实时处理,主打轻量化、低延迟、零运维,是简单实时计算场景的首选。
核心优势
-
无额外集群、无运维成本,嵌入业务代码运行,轻量化部署
-
原生适配 Kafka 所有特性:分区并行、故障自动容错、数据回溯重放
-
内置状态存储、窗口计算、数据JOIN、聚合统计能力
-
毫秒级低延迟,适配轻量实时业务场景
核心短板
-
不支持大规模分布式集群调度,复杂大规模计算性能不足
-
状态存储能力有限,超大状态数据集场景适配性差
-
缺少复杂事件处理、精准水印、高阶容错机制
2. 核心抽象概念(面试必考)
-
KStream(流式流):无界、有序、可重放的键值对数据流,每条数据独立存在,支持持续追加更新,适用于日志、埋点、事件流等增量数据
-
KTable(表流):基于 Key 的更新型数据表,同一 Key 新数据会覆盖旧数据,自动维护最新状态,适用于用户维度、商品维度的状态更新场景
-
GlobalKTable(全局表流):全局广播表,全节点加载全量数据,解决跨分区JOIN数据不匹配问题,适配维度表关联场景
3. 核心能力与适用场景
-
数据实时清洗、过滤、字段脱敏、格式转换
-
轻量实时聚合:分钟级UV、访问量统计、简单指标计算
-
流表关联、维度补全、数据 enrichment
-
简单事件监听、异常数据实时筛选转发
三、主流重量级流式计算引擎(Flink/Spark Streaming)
1. Apache Flink(生产主流、实时计算标杆)
目前企业实时计算绝对首选引擎,完美适配 Kafka 数据流,支持高吞吐、低延迟、有状态计算、精准时间语义,覆盖所有复杂实时场景。
核心优势
-
真正的流式计算,毫秒级延迟,适配实时风控、实时报表、实时数仓
-
完善的状态管理、检查点(Checkpoint)、保存点(Savepoint)机制,故障自动恢复
-
支持事件时间、水印、乱序数据处理,解决业务数据时序错乱问题
-
丰富的窗口、聚合、JOIN、CEP复杂事件处理能力
-
支持批流一体,统一处理实时流与离线批量数据
生产适配场景:金融实时风控、交易监控、实时大屏、分层实时数仓、用户行为实时分析、时序数据聚合。
2. Spark Streaming(存量经典、离线转实时过渡)
基于微批处理的流式计算引擎,将实时数据流拆分为极小批次任务处理,吞吐能力强,延迟秒级,适合高吞吐、低时效要求的实时场景。
核心特点
-
微批调度机制,高吞吐、秒级延迟,无法实现毫秒级实时
-
批处理能力强悍,适配海量数据批量聚合统计
-
状态管理、乱序处理能力弱于 Flink,实时性较差
生产适配场景:海量日志统计、离线数据增量同步、非实时用户画像、存量大数据集群兼容场景。
3. 三大计算组件选型对比(生产规范)
|-----------------|------|---------|------------------|------------------|
| 计算组件 | 延迟级别 | 运维成本 | 核心能力 | 适用场景 |
| Kafka Streams | 毫秒级 | 极低(无集群) | 轻量清洗、简单聚合 | 简单实时处理、轻量化业务 |
| Apache Flink | 毫秒级 | 中高 | 全功能、有状态、乱序处理、CEP | 核心实时业务、精准计算、实时数仓 |
| Spark Streaming | 秒级 | 中 | 高吞吐微批聚合 | 海量数据统计、低时效流式场景 |
四、流式计算核心基础(面试必背)
1. 三大时间语义
-
事件时间(Event Time):消息产生的原始时间(埋点/业务生成时间),不受传输、处理延迟影响,数据时序最准确,生产核心首选,适配乱序数据场景
-
处理时间(Processing Time):数据被计算引擎处理的系统时间,性能高、实现简单,易受服务器负载、网络延迟影响,数据精度差,仅适用于粗略统计场景
-
摄入时间(Ingestion Time):数据进入 Kafka 集群的时间,介于两者之间,兼顾精度与性能,使用场景较少
2. 水印 Watermark(乱序数据核心)
水印是处理流式乱序、迟到数据的核心机制,核心作用:标记数据流的时间进度,定义窗口关闭时机,兼顾数据完整性与计算时效性。
-
核心原理:基于事件时间生成水印,设定最大乱序容忍时间,超过阈值的迟到数据丢弃或单独处理
-
生产价值:解决网络抖动、设备时间不一致导致的数据乱序、时序错乱问题
-
面试考点:水印只能推进、不能回退,是实现精准窗口计算的关键
3. 四大核心窗口机制
窗口是流式无界数据转为有界批量计算的核心手段,所有实时聚合统计均依赖窗口实现:
-
滚动窗口(Tumbling Window):固定时长、无重叠、无间隙,如1分钟/5分钟窗口,适用于周期规整统计(分钟级UV、小时级报表)
-
滑动窗口(Sliding Window):固定窗口大小+滑动步长,窗口重叠,高频刷新统计结果,适用于实时趋势监控、滚动数据统计
-
会话窗口(Session Window):基于数据间隔划分窗口,无固定时长,空闲超时则窗口关闭,适用于用户会话行为分析、单次操作链路统计
-
全局窗口(Global Window):全量数据聚合,无时间边界,适用于全局累计指标统计
4. 状态管理与容错机制
-
无状态计算:仅处理单条数据,不依赖历史数据,如过滤、清洗、字段转换,故障无数据影响,恢复简单
-
有状态计算:依赖历史累计数据,如聚合、计数、JOIN、窗口计算,需持久化状态快照,故障可回溯恢复
-
容错核心:Checkpoint 定期快照状态、Savepoint 手动保存镜像,搭配 Kafka 数据回溯,实现故障精准恢复、数据不丢不重
五、生产落地规范与避坑要点
-
场景分层选型:简单清洗/轻量聚合用 Kafka Streams,核心实时精准计算用 Flink,海量低时效统计用 Spark Streaming
-
强制使用事件时间:生产实时业务禁止使用处理时间,避免延迟、负载导致的数据统计失真
-
合理设置水印延迟:根据业务数据乱序程度配置容忍时间,平衡数据完整性与时效性
-
状态定期清理:有状态任务配置状态过期策略,避免状态无限膨胀导致内存溢出、任务卡顿
-
窗口闭环兜底:配置窗口延迟关闭、迟到数据侧写策略,防止数据丢失、统计偏差
六、面试高频压轴考点
-
Kafka Streams 和 Flink 核心区别? Kafka Streams 无集群、轻量零运维,适合简单流式处理;Flink 是独立分布式计算引擎,支持复杂有状态、乱序处理、CEP,适合核心精准实时业务,功能更全面、性能更强。
-
为什么生产优先使用事件时间? 业务数据存在网络传输延迟、乱序、设备时间偏差,处理时间无法真实反映业务时序,事件时间基于原始业务时间,统计结果精准,不受外部环境影响。
-
水印的作用是什么?没有水印会怎样? 水印用于界定流式数据时间进度、关闭窗口、处理迟到数据;无水印会导致窗口无法自动关闭、数据堆积、统计结果重复/缺失。
-
滚动窗口和滑动窗口适用场景差异? 滚动窗口适合固定周期规整报表统计;滑动窗口适合高频实时监控、趋势分析,结果刷新更及时。
-
流式计算如何保证 Exactly Once? Kafka 精准投递语义 + 引擎 Checkpoint 状态快照 + 位移精准对齐 + 业务幂等,实现端到端恰好一次消费。
3.5 跨集群同步 MirrorMaker(生产多活/容灾核心全解)
MirrorMaker 是 Kafka 官方自带的跨集群数据同步工具 ,无需额外部署中间件,核心实现不同Kafka集群之间的Topic数据、消费组位移、集群配置的单向/双向同步,是企业实现异地容灾、同城多活、集群迁移、数据备份的核心方案。目前生产主流为 MirrorMaker 2.0,彻底解决1.0版本的诸多缺陷,以下为全维度生产级详解。
一、MirrorMaker 两大版本核心差异
1. MirrorMaker 1.0(老旧淘汰版本)
基于原生消费者+生产者简单封装,核心逻辑为:消费源集群Topic消息 → 转发写入目标集群,属于基础转发模式,目前已基本被生产淘汰。
核心短板
-
仅支持单向消息同步,无法实现双向数据互通,不支持多活架构;
-
仅同步消息数据,不同步消费组位移、Topic配置、分区信息,集群切换后需手动重置位移、重建配置;
-
无偏移量同步机制,集群切换会导致大量重复消费或数据丢失;
-
无链路监控、无同步校验机制,数据一致性无法保障;
-
不支持动态Topic同步,新增Topic需手动配置,运维成本极高。
2. MirrorMaker 2.0(生产主流标准版)
随 Kafka 2.4 版本正式推出,基于 Kafka 原生复制协议重构,摒弃1.0简单转发逻辑,是目前企业生产唯一使用版本,完整适配容灾、多活、迁移全场景。
核心能力升级
-
支持单向/双向/多集群网状同步,完美适配异地多活架构;
-
全量同步:消息数据、消费组位移、Topic分区配置、副本策略、ACL权限、日志保留策略;
-
内置位移镜像机制,支持集群无缝切换,业务无感知、无重复消费;
-
自动发现新增Topic,无需手动配置,适配集群动态扩容、新增业务场景;
-
内置同步监控、链路校验、异常重试机制,保障跨集群数据一致性;
-
适配KRaft/ZK双架构,兼容新旧版本Kafka集群迁移。
二、核心工作原理(MM2)
MirrorMaker 2.0 核心基于远程主题镜像+位移同步器+元数据同步器三大核心组件实现跨集群同步,底层复用Kafka分区复制机制,而非简单的消费转发。
1. 三大核心组件
-
MirrorSource:核心数据同步组件,消费源集群增量消息,批量同步至目标集群,保障数据时序一致性;
-
MirrorCheckpoint:位移同步核心,定时同步源集群消费组位移至目标集群,实现故障切换后断点续消费;
-
MirrorHeartbeat:心跳检测组件,实时探测双集群连接状态、同步链路健康度,异常自动重试、断连续传。
2. 同步核心机制
-
元数据预同步:主动拉取源集群Topic列表、分区、配置、权限,在目标集群自动创建镜像Topic,配置完全对齐源集群;
-
增量数据实时同步:基于位移点位持续同步新增消息,支持断点续传,断网、集群重启后自动恢复同步;
-
位移定时校验同步:周期性同步所有消费组的消费位点,保障双集群消费进度一致;
-
链路自愈机制:同步延迟、网络抖动、节点故障时自动重试,故障恢复后自动补齐滞后数据。
3. 镜像Topic命名规范(生产固定)
MM2 自动对跨集群同步Topic做标识,避免主题冲突,统一规范:{源集群名}.{原Topic名}
示例:源集群为bj-cluster,原Topic为order-topic,目标集群镜像Topic为:bj-cluster.order-topic
三、企业生产核心应用场景
1. 异地容灾 & 故障兜底(核心刚需)
核心业务集群部署主备架构,主集群承载日常业务流量,通过MM2实时同步全量数据至备用集群。当主集群出现机房断电、网络瘫痪、整体故障时,快速将业务流量切换至备用集群,实现故障无感兜底,杜绝数据丢失、业务停服。
2. 异地多活架构(中大型互联网企业标配)
部署多地域集群,通过MM2双向同步数据,实现北京、上海、广州等多机房数据互通,各地域业务优先访问本地集群,降低跨地域网络延迟;单机房故障不影响全局业务,支撑高可用、高并发的全域业务架构。
3. 集群版本平滑迁移 & 硬件迭代
老旧ZK架构集群升级KRaft架构、低版本升级高版本、老旧服务器硬件替换时,通过MM2同步新旧集群数据,实现双集群并行运行、灰度切换流量,无需停机、无数据丢失,保障业务迭代零感知。
4. 数据汇总与离线分析
将多业务线、多机房Kafka数据统一同步至数据中心集群,集中对接Flink、数据仓库、ELK等组件,实现全域数据统一分析、日志汇总、数据对账,适配数据中台架构。
5. 开发测试环境数据同步
生产集群实时同步增量数据至测试环境,为测试、压测、研发提供真实生产数据样本,避免测试数据失真,提升测试准确性。
四、生产级核心配置(可直接复用)
基于Kafka 3.x KRaft架构,通用双向同步核心配置 mirror.properties,精简生产刚需参数:
XML
# 1. 集群命名(自定义唯一标识)
clusters=bj-cluster,sh-cluster
# 2. 集群地址配置
bj-cluster.bootstrap.servers=192.168.1.10:9092,192.168.1.11:9092
sh-cluster.bootstrap.servers=192.168.2.10:9092,192.168.2.11:9092
# 3. 开启双向同步
mirror.enable= true
mirror.topics.include=.* # 同步所有Topic,可自定义指定业务Topic
mirror.topics.exclude=__.* # 排除系统内置Topic,避免元数据冲突
# 4. 位移同步配置(故障切换核心)
checkpoint.enable=true
checkpoint.interval.ms=10000 # 10秒同步一次消费位移
# 5. 心跳检测配置
heartbeat.enable=true
heartbeat.interval.ms=5000
# 6. 同步性能优化
producer.batch.size=16384
producer.linger.ms=5
consumer.fetch.min.bytes=10240五、生产启停与运维命令
1. 启动MirrorMaker2(后台常驻)
适配新版KRaft架构,通用启动命令:
XML
bin/kafka-mirror-maker.sh --config config/mirror.properties --daemon2. 日常运维核查命令
-
查看同步链路状态:监控镜像Topic创建状态、同步延迟
-
核查位移同步一致性:对比主备集群消费组位移差值,判断同步是否正常
-
排查同步异常:查看MM2日志,定位网络抖动、权限不足、配置错误等问题
六、生产避坑核心规范
-
禁止同步系统Topic:务必排除 __consumer_offsets、__cluster_metadata 等内置Topic,避免集群元数据错乱、冲突;
-
双向同步防循环刷屏:配置Topic黑白名单,避免镜像Topic二次同步,形成数据循环复制导致数据爆炸;
-
网络带宽预留:跨机房同步占用专线带宽,需预留30%以上带宽冗余,避免同步流量抢占业务流量;
-
双集群配置对齐:主备集群副本数、日志保留策略、分区数尽量一致,防止同步适配异常;
-
禁止高频修改同步配置:同步规则变更需灰度测试,避免触发全量数据重同步引发集群压力;
-
同步延迟监控告警:核心业务必须监控跨集群同步延迟,延迟过高及时排查链路问题。
七、面试高频压轴考点
-
MM1和MM2的核心区别? MM1仅简单转发消息,不同步位移和配置,仅单向同步、无自愈能力;MM2基于集群复制协议重构,支持双向同步,同步消息、位移、全量配置,支持无缝集群切换,是生产可用版本。
-
MirrorMaker2如何实现集群无缝切换? 通过MirrorCheckpoint组件定时同步消费组位移,目标集群完整复刻源集群消费进度,故障切换后业务直接消费镜像Topic,无需重置位移,无重复消费、无数据丢失。
-
双向同步会出现数据循环问题吗? 合理配置黑白名单不会,通过区分原生Topic和镜像Topic,禁止镜像Topic反向同步,阻断循环链路;未配置规范会引发数据无限循环复制。
-
MirrorMaker同步的核心局限性? 存在毫秒~秒级跨机房同步延迟,不适合对实时性要求极高的核心交易业务;仅做数据同步,不支持跨集群事务一致性。
-
多活架构下,如何保证双集群数据一致? MM2实时增量同步+定时位移校验+业务幂等设计,保障最终数据一致性,适配绝大多数生产业务场景。
3.6 分层存储与远程副本(3.x 新特性)
-
分层存储:热数据存本地磁盘,冷数据自动迁移至 OSS/S3 对象存储,降低成本。
-
远程副本:跨机房远程副本,轻量化替代传统镜像,用于海量冷数据灾备。
3.7 KRaft 架构(新版本核心)
1. 角色划分
-
Controller 控制器:集群全局唯一,负责选主、元数据管理、故障转移
-
Broker:负责消息读写、存储
-
Quorum 投票节点:基于 Raft 协议选举控制器,建议部署奇数节点
2. ZK vs KRaft 对比
|-------|-----------|-----------------------|
| 维度 | ZK 架构 | KRaft 架构 |
| 外部依赖 | 独立 ZK 集群 | 无外部组件,内置 Raft |
| 元数据存储 | ZK + 本地日志 | 内部 __cluster_metadata |
| 选主速度 | 慢 | 毫秒级快速切换 |
| 扩展性 | 受 ZK 瓶颈限制 | 扩展性更强 |
| 运维成本 | 高(双集群维护) | 低(单集群) |
3. 迁移方案
本节提供生产零停机、无损平滑迁移方案,适配 Kafka 2.8+ 所有版本,支持 ZK 架构集群平稳迁移至 KRaft 架构,全程不中断业务生产消费、无数据丢失、无需停机,包含前置准备、分步迁移、验证校验、故障回滚全流程,是企业集群架构升级标准方案。
1. 迁移前置准备(必做,规避迁移风险)
-
版本校验:确认集群版本≥2.8.x,仅2.8及以上版本支持ZK/KRaft双架构兼容,低版本需先灰度升级至2.8+稳定版(优先2.8.x、3.x);
-
集群状态核验:迁移前确保集群无ISR收缩、无副本同步异常、无消息堆积、无节点离线,集群处于健康稳态;
-
数据备份:备份集群核心配置、Topic配置、ACL权限、消费组位移数据,同时确认日志数据保留完整,预留数据兜底方案;
-
环境适配:完成服务器系统优化(关闭SWAP、调大文件句柄、时间同步),保证所有节点网络互通、端口开放(9093控制器通信端口);
-
客户端兼容校验:确认业务客户端版本适配新架构,高版本客户端兼容双架构,避免迁移后客户端连接异常。
2. 核心迁移原理
Kafka 2.8+ 支持双模式共存迁移,迁移期间集群同时兼容ZK元数据管理与KRaft控制器管理,实现元数据双向同步、业务无感过渡。核心逻辑:先启用KRaft投票节点接管控制器能力,完成元数据全量迁移,验证集群稳定后,下线ZK依赖,完成架构彻底切换。
3. 分步平滑迁移流程(生产标准四步法)
第一步:集群版本统一升级
将所有ZK架构的Broker节点,逐个灰度升级至2.8+及以上版本(推荐3.x稳定版),升级过程单节点滚动重启,不中断集群业务。升级后集群仍完全依赖ZK管理元数据,保持原有架构不变,保障业务稳定。
第二步:部署KRaft控制器节点(新增投票节点)
在现有集群中,选取奇数个节点(3/5个,满足Raft选举机制),修改节点配置,开启控制器角色,搭建KRaft投票集群:
核心新增配置:
process.roles=broker,controller controller.quorum.voters=节点1:9093,节点2:9093,节点3:9093
metadata.log.dir=自定义元数据独立存储路径
zookeeper.connect=原有ZK集群地址(保留双架构兼容)
逐节点重启生效,此时集群进入ZK+KRaft双架构兼容模式,KRaft控制器开始同步ZK中的全量元数据(Topic、分区、副本、消费组、ACL)。
第三步:切换集群元数据管理模式
等待双架构元数据同步完全一致(无元数据差异、无同步延迟)后,执行集群模式切换,将元数据管理权限从ZK全权移交至KRaft集群:
-
设置集群参数
zookeeper.metadata.migration.enable=true,开启元数据迁移托管; -
等待集群自动完成元数据全量同步、校验,确认KRaft的
__cluster_metadataTopic数据完整; -
集群控制器正式切换为KRaft节点,ZK仅做数据备份,不再参与集群管控。
第四步:下线ZK依赖,完成最终迁移
持续观察集群运行稳态(建议观察3-7天,无异常、无延迟、无重平衡异常)后,逐节点删除ZK相关配置,重启节点:
-
删除配置项
zookeeper.connect及ZK超时、鉴权相关配置; -
单节点滚动重启,避免集群抖动;
-
所有节点重启完成后,集群彻底脱离ZK依赖,纯KRaft架构迁移完成。
4. 迁移后核心校验项(必验)
-
元数据一致性:校验所有Topic、分区、副本分布、ISR状态与迁移前完全一致;
-
业务可用性:生产、消费流量正常,TPS无波动,无消息堆积、无重复/丢失消息;
-
消费组状态:所有消费组在线、位移正常,无异常重置、无重平衡频发;
-
集群容错性:手动下线单个Broker/控制器节点,验证自动选主、故障切换正常;
-
系统Topic状态 :
__cluster_metadata同步正常、无堆积、无异常日志。
5. 故障回滚方案(迁移兜底)
迁移过程中若出现集群异常、业务波动,可一键回滚至ZK架构,全程业务无感:
-
临时关闭KRaft元数据迁移开关,恢复ZK元数据管控权限;
-
所有节点恢复ZK完整配置,滚动重启集群节点;
-
集群退回原生ZK架构,校验业务、数据、元数据恢复正常;
-
排查迁移异常问题后,重新启动迁移流程。
6. 生产迁移核心避坑规范
-
禁止跨大版本跳跃迁移:低版本(0.10/0.11)禁止直接升级3.x,必须先升级至2.x过渡版本,再迁移KRaft;
-
控制器节点专属部署:核心生产集群建议控制器节点独立部署,避免与业务Broker节点争抢资源;
-
避开业务高峰期迁移:选择凌晨低流量时段执行迁移、重启操作,降低集群波动影响;
-
禁止手动修改系统Topic :迁移期间严禁操作
__cluster_metadata、__consumer_offsets,防止元数据错乱; -
分批灰度不一刀切:严格执行单节点滚动重启,禁止全集群同时重启,保障集群高可用。
7. 面试高频迁移考点
-
KRaft迁移是否需要停机? 不需要,依托双架构兼容特性,全程滚动升级、无感迁移,业务生产消费不中断。
-
迁移的核心风险点是什么? 元数据同步不一致、集群控制器切换异常、节点重启引发短暂重平衡、客户端版本不兼容。
-
双架构模式的核心作用? 实现元数据双向同步、故障可回滚,规避一次性切换的架构风险,保障迁移平稳性。
-
为什么必须奇数个控制器节点? KRaft基于Raft协议,奇数节点可避免投票平局,保障控制器选举高效、合法。
第四部分 安全体系(生产强制规范)
4.1 认证 Authentication(防匿名接入,生产必开)
Kafka 认证机制核心作用为拒绝匿名非法客户端接入集群 ,实现客户端(生产者、消费者、运维工具)与服务端的身份合法性校验,解决集群裸奔、非法接入、数据随意读写的安全风险。生产环境禁止集群匿名访问,必须开启身份认证,主流基于 SASL 安全框架实现,同时支持SSL双向认证,适配不同安全等级的企业架构。
SASL 核心认知:SASL(简单身份认证与安全层)是一套通用安全认证框架,并非具体认证算法,Kafka 基于SASL封装了三种主流认证模式,适配从普通业务集群到金融高安全集群的全场景需求,三种模式差异、配置、优缺点及生产规范如下:
1. SASL/PLAIN(明文账号密码认证)
核心原理:基于固定的用户名+密码明文校验,客户端连接集群时,必须携带合法账号密码,服务端校验通过才可建立连接、进行读写操作,是最简单、最易落地的认证方式。
生产配置(极简可复用)
- Broker服务端配置(server.properties)
XML
# 开启SASL认证
listeners=SASL_PLAINTEXT://0.0.0.0:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
# 配置JAAS认证文件路径(存储账号密码)
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="admin" \
password="Admin@123456" \
user_admin="Admin@123456" \
user_producer="Produce@123" \
user_consumer="Consume@123";- 客户端配置(生产者/消费者通用)
XML
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="producer" password="Produce@123";核心优缺点
-
优点:配置极简、无复杂依赖、运维成本极低、适配所有Kafka版本,中小型企业集群首选
-
缺点:账号密码明文存储、明文传输(未搭配SSL时),存在信息泄露风险,安全性较低
适用场景:内网隔离集群、中小规模业务集群、测试预发环境,不对外网暴露的生产集群。
2. SASL/SCRAM(加密账号密码认证,生产主流推荐)
核心原理 :基于加盐哈希加密算法实现身份认证,区别于PLAIN明文模式,账号密码不会明文存储、明文传输,客户端与服务端通过哈希校验完成身份认证,支持动态创建、删除用户,安全性大幅提升,是目前互联网生产集群标准选型。
核心特性
-
密码加盐哈希存储,杜绝明文泄露风险
-
支持动态用户管理,无需重启集群即可新增/删除业务账号
-
兼容新旧版本Kafka,完美替代PLAIN模式
生产实操命令(用户创建)
XML
# 创建管理员用户
kafka-configs.sh --bootstrap-server 集群地址:9092 --alter --add-config 'SCRAM-SHA-256=[password=Admin@123456]' --entity-type users --entity-name admin
# 创建生产者专用用户
kafka-configs.sh --bootstrap-server 集群地址:9092 --alter --add-config 'SCRAM-SHA-256=[password=Produce@123]' --entity-type users --entity-name producer核心优缺点
-
优点:加密存储传输、安全性高、运维灵活、无集群重启成本、适配绝大多数生产场景
-
缺点:配置略复杂,低版本Kafka(0.11以下)不支持
适用场景:对外暴露的集群、中大型生产集群、需要精细化用户管理的业务环境。
3. SASL/GSSAPI(Kerberos,高安全企业级认证)
核心原理:基于Kerberos第三方认证服务的重量级安全认证机制,依托独立的Kerberos服务实现票据式身份校验,采用 Ticket 票据机制认证,无密码直接传输,具备极高的防篡改、防伪造能力。
架构角色
-
KDC服务:核心认证服务,负责票据发放、身份校验
-
Client客户端:申请认证票据,携带票据访问集群
-
Kafka Broker:校验客户端票据合法性,放行合法请求
核心优缺点
-
优点:金融级安全、防伪造、防窃听、适配高合规要求场景
-
缺点:架构复杂、依赖独立Kerberos集群、运维成本极高、部署繁琐
适用场景:金融、银行、政企等对数据安全、合规性有强制要求的高端安全集群,普通互联网业务极少使用。
4. 认证+加密组合方案(生产最高安全规范)
单纯SASL认证仅校验身份,无法加密传输数据,存在网络抓包泄露风险。高安全集群必须采用SASL+SSL/TLS组合方案:
-
SASL负责身份认证:拦截非法匿名客户端,校验访问权限
-
SSL/TLS负责传输加密:加密客户端与Broker、集群节点间的通信数据,防止抓包窃听、数据篡改
5. 生产认证选型规范(强制执行)
-
测试/内网集群:优先 SASL/PLAIN,兼顾简单性与内网安全性
-
通用生产集群:强制 SASL/SCRAM-SHA-256,平衡安全与运维成本
-
金融/合规级集群:SASL/GSSAPI(Kerberos)+SSL传输加密
-
所有线上集群禁止开启匿名访问,必须关闭匿名接入权限
6. 面试高频考点
-
PLAIN和SCRAM核心区别? PLAIN明文存储传输账号密码,安全性低、配置简单;SCRAM加盐哈希加密,支持动态用户管理、无需重启集群,生产主流推荐。
-
SASL认证的核心作用? 杜绝匿名客户端接入,校验访问者身份合法性,防止非法设备读写集群数据,是Kafka安全体系的第一道防线。
-
为什么生产不推荐PLAIN模式? 明文密码易泄露,无加密防护,存在数据被非法窃取、篡改的安全隐患,无法满足线上集群安全规范。
4.2 授权 Authorization(ACL 权限,生产精细化管控核心)
Kafka 认证(SASL/SSL)解决谁能访问 的问题,而 ACL 授权解决能做什么的问题。ACL(Access Control List,访问控制列表)是 Kafka 官方原生的权限管控机制,用于对已通过身份认证的用户、IP地址,精细化管控其对集群资源的操作权限,杜绝权限泛滥、越权读写、误操作删改等生产风险。
生产环境必须遵循认证+授权双重防护规范,禁止认证通过后拥有集群全量权限,是企业集群安全合规、多业务隔离、权限分级的核心手段。
一、ACL 核心组成四要素(权限匹配核心)
Kafka ACL 权限由「资源+主体+操作+权限类型」四部分组成,精准锁定权限管控范围,支持细粒度组合授权:
-
资源 Resource:被管控的集群对象,包含 Topic、消费组、集群、事务ID、Token 等
-
主体 Principal:被授权的访问对象,对应SASL认证的用户名、客户端IP地址
-
操作 Operation:允许/禁止的具体行为,如读、写、创建、删除、修改配置等
-
权限类型 PermissionType:Allow(允许,默认)、Deny(拒绝,优先级更高)
二、全量可管控资源与对应权限
1. 核心资源类型
-
Topic 主题资源:最常用,管控消息生产、消费、查询权限
-
Group 消费组资源:管控消费组创建、位移提交、组查询、组删除权限
-
Cluster 集群资源:管控集群级操作,如创建Topic、查询集群状态、扩容分区
-
TransactionalId 事务资源:管控幂等/事务生产者的事务提交、回滚权限
-
DelegationToken 令牌资源:管控临时访问令牌的创建、使用权限(云原生集群常用)
2. 全量操作权限清单(生产全覆盖)
-
读写核心权限:Read(消费消息、读位移)、Write(生产消息)
-
资源管理权限:Create(创建Topic/消费组)、Delete(删除资源)、Alter(修改配置/分区)
-
查询权限:Describe(查询资源信息、集群状态)、DescribeConfigs(查询配置)
-
高级权限:AlterConfigs(修改集群/主题配置)、IdempotentWrite(幂等写入)、TransactionalWrite(事务写入)
三、生产标准授权原则(强制执行)
-
最小权限原则:仅授予业务必需的权限,多余权限一律回收。生产者仅开放 Write/Describe 权限,消费者仅开放 Read/Describe 权限,禁止业务账号拥有 Delete/Alter 高危权限。
-
权限隔离原则:不同业务线、不同环境(测试/生产)账号权限完全隔离,禁止跨业务、跨环境权限复用。
-
分级授权原则:区分运维账号、业务账号、测试账号,运维账号拥有全量管控权限,业务账号仅拥有业务读写权限。
-
默认拒绝原则:所有未配置ACL权限的主体,默认禁止访问任何集群资源,杜绝匿名、未授权访问。
-
权限白名单原则:优先使用Allow白名单授权,高危场景搭配Deny黑名单做权限兜底,禁止宽泛授权。
四、企业高频ACL实操命令(可直接复用)
所有命令适配2.x/3.x版本集群,基于SASL/SCRAM认证体系,覆盖99%生产授权场景
1. Topic 读写权限授权(业务核心)
XML
# 给生产者账号授予指定Topic写入权限
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:producer \
--operation Write --operation Describe \
--topic order_topic
# 给消费者账号授予指定Topic读取权限
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:consumer \
--operation Read --operation Describe \
--topic order_topic2. 消费组权限授权(位移操作必备)
XML
# 授权消费者账号操作指定消费组权限(读取、提交位移)
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:consumer \
--operation Read --operation Describe \
--group order_consumer_group3. 集群基础权限授权(业务必备)
XML
# 授予业务账号查询集群、Topic配置的基础权限
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:producer \
--cluster --operation DescribeConfigs --operation Describe4. 事务/幂等权限授权(高阶业务)
XML
# 授权幂等、事务生产者写入权限
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:tx_producer \
--operation IdempotentWrite --operation TransactionalWrite \
--transactional-id tx_order_id5. IP维度权限管控(精准限流)
XML
# 仅允许指定IP的生产者访问Topic
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--add --allow-principal User:producer \
--allow-host 192.168.1.100 \
--operation Write \
--topic order_topic6. 权限查询与删除(运维常用)
XML
# 查询指定账号所有ACL权限
kafka-acls.sh --bootstrap-server 集群地址:9092 --list --principal User:producer
# 删除指定Topic的ACL权限
kafka-acls.sh --bootstrap-server 集群地址:9092 \
--delete --allow-principal User:consumer \
--topic order_topic五、通配符授权规范(批量授权)
支持通配符 * 批量匹配资源,适合同类型业务批量授权,生产慎用宽泛通配符避免权限溢出:
-
*:匹配所有Topic/消费组,仅运维账号可用,业务账号禁止使用 -
order_*:匹配所有order前缀的Topic,适合订单业务批量授权 -
log_*:匹配所有日志类Topic,适配日志采集业务统一授权
六、生产避坑核心规范
-
禁止宽泛授权 :严禁给业务账号授予
*全量Topic权限、Delete/Alter高危权限,防止误删业务数据、越权操作 -
权限及时回收:下线业务、废弃账号及时清理对应ACL权限,避免僵尸权限堆积引发安全风险
-
Deny权限优先级最高:当Allow与Deny规则冲突时,Deny拒绝规则优先生效,可用于紧急封禁异常账号
-
系统Topic权限隔离 :禁止业务账号获取
__consumer_offsets、__cluster_metadata系统Topic权限,仅运维账号保留只读权限 -
权限变更灰度校验:ACL新增、修改、删除后,必须验证业务生产消费可用性,避免权限配置错误导致业务中断
-
禁止匿名权限开启:生产集群严格关闭匿名访问,所有操作必须经过身份认证+ACL授权双重校验
七、面试高频必考考点
-
认证和授权的区别? 认证(SASL/SSL)校验客户端身份合法性,解决「能不能连」的问题;授权(ACL)校验客户端操作权限,解决「能做什么」的问题,二者搭配实现集群安全访问管控。
-
生产者、消费者最小权限分别是什么? 生产者:Describe(查询Topic元数据)+ Write(写入消息); 消费者:Describe(查询元数据)+ Read(消费消息)+ 对应消费组Read权限(提交位移)。
-
ACL中Allow和Deny优先级? Deny拒绝权限优先级高于Allow允许权限,可用于临时封禁特定账号、IP的高危操作。
-
为什么业务账号禁止授予Delete权限? 防止业务侧误操作删除核心业务Topic、清空数据,引发线上数据丢失、业务停服故障,所有资源删除权限仅保留给运维账号。
-
跨IP访问权限异常如何排查? 优先核查ACL是否配置对应Host白名单、账号权限是否仅绑定内网IP、客户端连接IP是否变更,IP不匹配会直接触发权限拒绝。
4.3 数据加密(生产安全合规核心)
Kafka数据加密是集群安全体系的核心兜底能力,弥补SASL身份认证仅校验身份、不保护数据内容的短板,解决网络传输窃听、抓包篡改、服务器本地数据泄露 两大核心风险。生产高安全集群、对外暴露集群、金融合规集群必须强制开启,分为传输加密(SSL/TLS) 和磁盘存储加密两大模块,以下为生产可直接落地的完整方案、配置规范与避坑要点。
1. 传输加密 SSL/TLS(链路加密,必开优先项)
传输加密针对客户端与Broker、Broker节点之间、跨集群同步 的所有通信链路,对传输中的二进制数据流全程加密,杜绝网络抓包、数据窃听、中间人篡改攻击,是互联网生产集群最常用的加密方案。Kafka支持SSL/TLS单向、双向加密,生产优先双向SSL认证加密,兼顾安全与稳定性。
1.1 核心加密原理
-
采用非对称加密校验身份、对称加密传输数据的混合机制,兼顾加密效率与安全性;
-
服务端持有密钥库(Keystore),存储自身公私钥与证书;客户端持有信任库(Truststore),存储可信服务端证书;
-
链路建立前完成证书双向校验,校验通过后协商会话密钥,后续所有数据通过会话密钥加密传输;
-
支持TLS1.2/1.3协议,废弃老旧不安全的SSL1.0/2.0/3.0协议。
1.2 生产证书生成规范(JKS证书,通用标准)
生产统一使用JDK自带keytool工具生成证书,禁止使用开源非标证书,所有Broker节点证书独立生成,统一CA签名,避免证书冲突。
XML
# 1. 生成服务端密钥库(每个Broker单独生成,绑定节点IP/域名)
keytool -genkey -alias kafka-server -keyalg RSA -keysize 2048 -dname "CN=kafka-node" -keystore server.keystore.jks -storepass Server@123 -keypass Server@123
# 2. 导出服务端公钥证书
keytool -export -alias kafka-server -keystore server.keystore.jks -file kafka-server.crt -storepass Server@123
# 3. 生成客户端信任库,导入服务端证书
keytool -import -alias kafka-server -file kafka-server.crt -keystore client.truststore.jks -storepass Client@123
# 4. 集群互通:所有Broker互相导入节点证书,保障节点间SSL通信1.3 Broker服务端生产配置(server.properties)
XML
# 开启SSL双向加密端口,兼容内网外网访问
listeners=SSL://0.0.0.0:9093
advertised.listeners=SSL://集群外网IP:9093
# 集群内部通信开启SSL加密
security.inter.broker.protocol=SSL
# 禁用老旧不安全协议,指定加密套件
ssl.protocol=TLSv1.2
ssl.enabled.protocols=TLSv1.2,TLSv1.3
ssl.cipher.suites=TLS_AES_256_GCM_SHA384,TLS_AES_128_GCM_SHA256
# 服务端密钥库配置
ssl.keystore.location=/kafka/config/ssl/server.keystore.jks
ssl.keystore.password=Server@123
ssl.key.password=Server@123
# 客户端信任库配置(校验客户端证书)
ssl.truststore.location=/kafka/config/ssl/client.truststore.jks
ssl.truststore.password=Client@123
# 开启双向证书校验(生产强制开启)
ssl.client.auth=required1.4 客户端加密配置(Java/Spring-Kafka通用)
XML
# 客户端协议指定SSL
security.protocol=SSL
# 客户端信任库、密钥库配置
ssl.truststore.location=classpath:ssl/client.truststore.jks
ssl.truststore.password=Client@123
ssl.keystore.location=classpath:ssl/client.keystore.jks
ssl.keystore.password=Client@123
ssl.key.password=Client@123
# 禁用主机名校验(内网集群可开启,外网建议关闭,严格校验域名)
ssl.endpoint.identification.algorithm=1.5 生产传输加密选型规范
-
测试/内网隔离集群:可开启SSL单向加密(仅客户端校验服务端),简化配置;
-
通用生产集群:强制SSL双向加密+TLS1.2及以上协议;
-
金融/合规集群:开启TLS1.3+自定义加密套件,定期轮换证书。
1.6 传输加密生产避坑点
-
证书过期会直接导致集群通信中断,需配置证书过期监控、自动轮换机制;
-
多节点集群必须统一证书、统一信任库,避免节点间SSL校验失败;
-
SSL加密会带来5%~10%的性能损耗,高吞吐集群需提前压测适配;
-
禁止混用SSL与非SSL端口,避免数据裸奔传输。
2. 磁盘存储加密(静态数据加密,兜底防护)
传输加密仅保护传输过程中 的数据,磁盘存储加密针对落地磁盘的持久化数据,防止服务器硬盘被盗、本地文件泄露、运维人员非法读取本地日志文件,是数据静态安全的最后一道防线,核心业务、合规集群强制开启。
2.1 加密机制说明
-
加密对象:Kafka所有日志分段文件(.log)、索引文件(.index/.timeindex)、事务日志、系统Topic数据;
-
加密时机:消息写入PageCache、落地磁盘前完成加密,读取数据时内存解密,磁盘全程密文存储;
-
密钥体系:支持数据密钥+主密钥双层加密,数据密钥加密业务数据,主密钥加密数据密钥,支持密钥轮换。
2.2 生产落地两种方案
方案一:Kafka原生文件加密(轻量、无依赖)
3.x版本原生支持日志文件加密,无需第三方组件,通过配置密钥直接开启,适合中小集群。核心配置:
XML
# 开启磁盘日志加密
log.encryption.enable=true
# 配置加密密钥(AES-256高强度加密)
log.encryption.key=自定义256位密钥
# 开启密钥轮换
log.encryption.rotate.key=true
log.encryption.rotate.interval.days=30方案二:系统层磁盘加密(企业主流、安全等级更高)
不依赖Kafka自身能力,通过服务器底层加密方案实现全盘加密,适配所有Kafka版本,稳定性更强:
-
Linux系统:LUKS磁盘加密,对Kafka数据盘整体加密;
-
云服务器:云盘加密(阿里云/腾讯云原生磁盘加密),由云厂商托管密钥;
-
优势:无业务侵入、不损耗Kafka性能、适配所有版本、运维简单。
2.3 存储加密生产规范
-
密钥禁止明文配置在配置文件,优先接入密钥管理系统(KMS)动态获取;
-
定期轮换加密密钥,避免长期使用单一密钥带来的泄露风险;
-
加密集群禁止随意拷贝磁盘日志文件,密文文件无法直接解析,防止数据外泄;
-
数据备份文件同步开启加密,保障备份数据安全。
3. 全链路安全加密组合方案(生产最高标准)
企业高合规、高安全集群必须采用认证+传输加密+存储加密三重防护体系,无任何数据安全死角:
-
身份层:SASL/SCRAM-SHA-256 加密身份认证,杜绝非法接入;
-
传输层:SSL/TLS双向加密,保障链路数据不被窃听、篡改;
-
存储层:磁盘静态加密,保障落地数据、备份数据安全;
-
权限层:ACL精细化授权,严控数据读写操作权限。
4. 面试高频必考考点
-
传输加密和存储加密的区别? 传输加密保护网络链路中的动态数据,防止抓包窃听;存储加密保护磁盘落地的静态数据,防止本地文件泄露,二者防护场景互补,缺一不可。
-
SSL单向加密和双向加密区别? 单向加密仅客户端校验服务端证书,安全性低、配置简单;双向加密客户端与服务端互相校验证书,杜绝伪造服务端/客户端,生产环境强制使用。
-
开启SSL加密会影响Kafka性能吗? 会有轻微损耗(5%-10%),主要消耗在证书校验、加解密计算,高吞吐集群可通过优化加密套件、升级服务器CPU抵消性能损耗。
-
为什么内网生产集群也需要开启加密? 内网存在员工恶意抓包、内网主机入侵、日志文件泄露风险,合规要求核心数据全程加密,不可依赖内网环境安全。
第五部分 运维、监控、压测与容量规划
5.1 核心监控指标(线上必监控,含释义+告警阈值)
本节整理生产环境强制全覆盖的Kafka监控指标,摒弃无效指标,全部为故障预警、性能瓶颈、集群稳定性核心观测项,按层级分类,附带标准告警阈值、异常诱因,可直接对接Prometheus+Grafana、Zabbix等监控体系。
一、集群全局监控指标(集群稳定性兜底)
(1)集群在线Broker数
指标释义:当前集群正常存活的Broker节点总数
告警阈值:存活节点数 < 集群规划节点数
异常影响:节点下线导致分区Leader切换、ISR收缩、集群负载不均
排查方向:节点宕机、进程退出、网络中断、KRaft/元数据同步异常
(2)集群控制器状态
指标释义:KRaft架构控制器节点存活、选举状态
告警阈值:无活跃控制器、控制器频繁切换(1分钟>3次)
异常影响:无法创建/删除Topic、分区选举失败、元数据更新失效
排查方向:控制器节点负载过高、网络抖动、Raft投票异常
(3)系统Topic状态
指标释义:__consumer_offsets、__cluster_metadata、__transaction_state 同步、堆积、ISR状态
告警阈值:系统Topic存在ISR不全、消息堆积、同步延迟
异常影响:消费位移提交失败、元数据错乱、事务失效
排查方向:系统Topic分区负载过高、节点同步异常
二、Broker节点层级指标(基础性能监控)
(1)节点CPU使用率
告警阈值:持续5分钟>80%,峰值>90%
异常诱因:批量攒批频繁、消息压缩/解压缩耗时、SSL加解密开销、元数据计算压力大
(2)节点内存&PageCache使用率
告警阈值:内存使用率>85%,PageCache命中率<90%
异常诱因:消息读写频繁、缓存失效、内存泄漏、SWAP开启
(3)磁盘使用率
告警阈值:磁盘使用率>80%(预警)、>90%(紧急告警)
异常诱因:消息堆积、日志保留时间过长、死信日志残留、分区过多
(4)磁盘IO负载
告警阈值:磁盘util持续>90%、IO等待过高
异常诱因:大消息批量写入、日志分段切换频繁、磁盘性能不足、随机IO增多
(5)网卡出入流量
告警阈值:流量持续打满网卡带宽、流量突降/突增>50%
异常诱因:业务流量暴涨、副本同步频繁、跨集群同步拥堵、网络故障
(6)TCP重传率
告警阈值:TCP重传率>1%
异常诱因:内网网络抖动、端口拥堵、节点间网络不稳定,会导致生产重试、消费超时
三、生产者核心指标(写入性能&可靠性)
(1)生产TPS/QPS
指标释义:单位时间消息写入总量,核心流量观测指标
监控重点:流量突增、突降、归零,适配业务峰值预警
(2)生产失败率
告警阈值:生产失败率>0.1%
失败类型:网络超时、acks校验失败、权限不足、分区不可用、消息超限
核心影响:业务数据丢失、数据统计缺失
(3)生产延迟(P95/P99) 告警阈值:P95延迟>20ms、P99延迟>50ms
异常诱因:批量攒批超时、网络拥堵、Leader节点负载过高、副本同步缓慢
(4)消息批量大小/攒批耗时
指标释义:生产者单次批量发送消息数、linger攒批耗时
异常特征:批量过小导致吞吐低、批量过大导致延迟飙升
(5)消息压缩率
指标释义:消息压缩前后体积比例,判断压缩策略有效性
异常特征:压缩失效、压缩率过低,带宽资源浪费
(6)生产者重试次数
告警阈值:单位时间重试次数激增
异常诱因:网络波动、节点临时不可用、ISR同步超时
四、分区&副本核心指标(高可用核心)
(1)ISR同步副本数
告警阈值:分区ISR数量 < 最小同步副本数(min.insync.replicas)
核心风险:数据可靠性下降,节点故障极易丢数据
(2)副本同步延迟(Replica Lag)
告警阈值:副本同步消息条数>1000条,持续3分钟未恢复
异常诱因:Follower节点CPU/IO负载高、网络带宽不足、大消息同步超时
风险:ISR收缩、分区降级、故障无法切换
(3)Leader分区分布不均
告警阈值:单Broker承载Leader分区数远超集群均值
异常影响:节点负载倾斜、热点节点性能瓶颈、集群资源浪费
(4)离线副本数
告警阈值:存在离线副本、无效副本
风险:集群容错能力下降,多节点故障直接丢数据
(5)分区未同步消息水位(HW滞后)
指标释义:Leader与Follower水位线差值,反映同步进度
异常:差值持续扩大,副本完全无法跟进主节点数据
五、消费者核心指标(线上故障高发重点)
(1)消费堆积量(最大核心指标)
告警阈值:单分区堆积>10000条、全局堆积持续上涨
分级预警:轻微堆积(可自愈)、中度堆积(需关注)、重度堆积(紧急处理)
根因:消费能力不足、业务阻塞、分区数不足、流量倾斜、频繁重平衡
(2)消费延迟(消费滞后时间)
告警阈值:消费滞后时间>10s(普通业务)、>3s(实时业务)
释义:当前最新消息时间与最后消费消息时间差值,直接反映实时性
(3)消费TPS
告警阈值:消费TPS突降、归零,与生产TPS差值持续扩大
异常:消费挂死、订阅异常、权限失效、分区未分配
(4)消费重平衡次数
告警阈值:1分钟内重平衡次数>1次
核心危害:重平衡期间停止消费、引发大规模堆积、重复消费
诱因:服务启停频繁、心跳超时、网络抖动、消费组配置异常
(5)位移提交失败率
告警阈值:位移提交失败率>0
后果:位移无法持久化、重启/重平衡后重复消费
诱因:客户端卡顿、元数据异常、系统Topic故障
(6)消费组在线实例数
告警阈值:在线实例数少于配置实例数、实例频繁上下线
异常:服务宕机、健康检查失败、网络超时
(7)重复消费次数
指标释义:单位时间重复消费消息数,校验业务幂等有效性
六、日志与存储监控指标
(1)日志清理失败次数
告警阈值:存在日志清理、压缩失败记录
后果:磁盘持续爆满、无效日志堆积
(2)日志分段切换频率
异常:频繁切换分段,引发IO波动、性能抖动
(3)消息过期丢弃数量
告警阈值:大量消息过期丢弃
根因:消费长时间停滞、消息保留时长过短,引发数据丢失
七、事务&幂等监控(高阶业务必监控)
-
事务提交/回滚次数
-
事务超时挂起数量
-
幂等消息重试失败率
-
异常影响:事务失效、数据不一致、Exactly Once语义破坏
八、生产监控核心规范(强制执行)
-
必配告警:节点离线、ISR不全、磁盘爆满、消费堆积、重平衡频繁、生产失败
-
核心观测优先级:消费堆积 > 副本ISR状态 > 节点负载 > 生产延迟 > 重平衡次数
-
数据留存规范:监控指标留存30天,故障日志留存90天,用于复盘溯源
-
基线对比:以日常平稳流量为基线,监控指标波动阈值,适配业务潮汐流量
5.2 核心配置文件(生产级完整版+参数详解)
Kafka 核心配置分为服务端server.properties、生产者producer.properties、消费者consumer.properties三类,以下为生产环境最优配置合集,包含参数释义、默认值、生产推荐值、适用场景,可直接复制落地,适配2.x/3.x主流版本,区分ZK旧架构与KRaft新架构。
一、服务端核心配置 server.properties(集群全局核心)
该文件为Broker节点主配置,管控集群架构、存储、高可用、权限、性能全量能力,是集群稳定运行的核心,所有参数均为生产强制优化项。
1. 基础集群配置
XML
# 节点唯一ID,集群内不可重复,手动依次配置1、2、3
broker.id=1
# 集群唯一ID,所有节点保持一致,KRaft架构必填
cluster.id=kafka-cluster-prod
# 内网监听地址,0.0.0.0监听所有网卡
listeners=PLAINTEXT://0.0.0.0:9092
# 对外暴露地址,外网/跨机房/容器环境必改,客户端连接核心配置
advertised.listeners=PLAINTEXT://192.168.x.x:9092
# 网络处理线程数,适配CPU核心数,生产默认8-16
num.network.threads=12
# IO读写处理线程数,核心调优参数,生产默认16-24
num.io.threads=20
# 后台线程池大小,用于日志清理、副本同步等后台任务
background.threads=10
# 队列最大积压请求数,防止节点请求雪崩
queued.max.requests=5002. 存储日志核心配置
XML
# 日志存储路径,独立SSD磁盘,多磁盘逗号分隔
log.dirs=/data/kafka/logs
# 单日志分段文件大小,生产最优1GB,平衡切换频率与IO性能
log.segment.bytes=1073741824
# 日志分段滚动超时,无论文件大小,7天强制生成新分段
log.roll.hours=168
# 日志保留时长,默认7天,按需调整,实时业务可缩短为3天
log.retention.hours=168
# 日志最大存储容量,优先触发大小清理,兜底防磁盘爆满
log.retention.bytes=107374182400
# 日志清理策略:delete(删除过期数据)、compact(日志压缩,状态数据专用)
log.cleanup.policy=delete
# 日志压缩线程数,开启compact策略时调优
log.cleaner.threads=4
# 索引文件最大内存,防止索引溢出
log.index.max.size.bytes=1048576003. 高可用与副本配置(生产重中之重)
XML
# 默认Topic副本数,常规业务2副本,核心金融业务3副本
default.replication.factor=2
# 最小同步副本数,保障数据可靠性,默认2,不可低于2
min.insync.replicas=2
# 禁止非ISR副本选主,彻底杜绝数据丢失,生产强制关闭
unclean.leader.election.enable=false
# 分区Leader自动均衡,开启后均衡集群负载
auto.leader.rebalance.enable=true
# 副本同步最大超时时间,超时将剔除ISR
replica.lag.time.max.ms=30000
# 副本抓取最大消息数,控制同步批量大小
replica.fetch.max.bytes=104857604. 消息刷盘与持久化配置
XML
# 后台刷盘间隔条数,异步刷盘兜底,无需频繁刷盘
log.flush.interval.messages=10000
# 后台刷盘最大超时时间,强制定时落盘
log.flush.interval.ms=1000
# 关闭同步刷盘,依托页缓存异步刷盘,保障超高吞吐
log.flush.scheduler.interval.ms=30005. KRaft架构专属配置(3.x新版集群必配)
XML
# 节点角色:broker(数据节点)、controller(管控节点),集群节点统一配置
process.roles=broker,controller
# Raft投票节点列表,填写集群所有节点内网地址:9093
controller.quorum.voters=192.168.x.1:9093,192.168.x.2:9093,192.168.x.3:9093
# 元数据日志独立存储路径,与业务日志磁盘隔离
metadata.log.dir=/data/kafka/metadata
# 元数据分区副本数,保障集群元数据高可用
metadata.replication.factor=3
# 元数据最小同步副本数
metadata.min.insync.replicas=26. ZK架构专属配置(2.x旧版集群必配)
XML
# ZK集群连接地址,多节点逗号分隔
zookeeper.connect=192.168.x.1:2181,192.168.x.2:2181,192.168.x.3:2181
# ZK会话超时时间,防止网络抖动误判节点下线
zookeeper.session.timeout.ms=60000
# ZK连接超时时间
zookeeper.connection.timeout.ms=30000
# ZK最大客户端连接数
zookeeper.max.inflight.requests=1007. 安全权限基础配置
XML
# 关闭匿名访问,生产强制开启认证
allow.anonymous=false
# 开启ACL权限管控
authorizer.class.name=kafka.security.authorizer.AclAuthorizer
# 超级运维账号,拥有集群全量权限
super.users=User:admin二、生产者核心配置 producer.properties(生产级最优参数)
管控消息发送、批量、压缩、重试、可靠性,适配高吞吐、高可靠业务,区分普通生产、幂等生产、事务生产场景。
XML
# 集群连接地址,多节点逗号分隔
bootstrap.servers=192.168.x.1:9092,192.168.x.2:9092,192.168.x.3:9093
# 消息键序列化器
key.serializer=org.apache.kafka.common.serialization.StringSerializer
# 消息值序列化器
value.serializer=org.apache.kafka.common.serialization.StringSerializer
# 生产者客户端ID,用于监控溯源
client.id=prod-producer-client
# 【可靠性核心】acks配置:0(无确认)、1(Leader确认)、all(全ISR确认)
# 高吞吐业务=1,核心可靠业务=all
acks=1
# 生产失败重试次数,生产默认3次,避免临时网络抖动丢数据
retries=3
# 重试间隔时间,毫秒级,防止频繁重试压垮集群
retry.backoff.ms=100
# 【批量吞吐优化】
# 单个批量消息阈值,达到大小立即发送
batch.size=16384
# 攒批超时时间,等待批量凑满,平衡吞吐与延迟
linger.ms=5
# 生产者缓冲区大小,缓存未发送消息
buffer.memory=67108864
# 【消息压缩】生产首选LZ4,压缩率与性能平衡最优
compression.type=lz4
# 压缩级别,默认6级,兼顾压缩率与CPU开销
compression.level=6
# 【幂等/事务配置】精准一次性业务开启
# 开启幂等生产者,解决重复发送问题
enable.idempotence=true
# 事务前缀,全局唯一
transactional.id=prod-tx-producer-
# 事务超时最大时间
transaction.timeout.ms=60000
# 最大单条消息大小,适配大消息业务按需调大
max.request.size=10485760
# 最大未确认请求数,控制并发发送量
max.in.flight.requests.per.connection=5三、消费者核心配置 consumer.properties(避坑最优参数)
管控消息拉取、位移提交、重平衡、消费重试,解决重复消费、堆积、重平衡频繁等线上高频问题。
XML
# 集群连接地址
bootstrap.servers=192.168.x.1:9092,192.168.x.2:9092,192.168.x.3:9093
# 反序列化器,与生产者一一对应
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费组ID,业务全局唯一,禁止跨业务共用
group.id=prod-business-consumer-group
# 【位移初始策略】无历史位移时生效:earliest(从头消费)、latest(消费最新)
auto.offset.reset=latest
# 关闭自动位移提交,生产强制手动提交,杜绝丢消息
enable.auto.commit=false
# 自动提交间隔(关闭自动提交后失效,仅预留配置)
auto.commit.interval.ms=5000
# 【消费性能优化】
# 单次拉取最小消息数,攒批消费提升吞吐
fetch.min.bytes=10240
# 单次拉取最大消息数,控制单次消费体量
fetch.max.bytes=10485760
# 拉取超时时间,平衡延迟与空轮询
fetch.max.wait.ms=500
# 【重平衡优化核心】
# 消费者心跳超时,默认10s,生产调优避免误判下线
heartbeat.interval.ms=3000
# 会话超时时间,最大禁止超过30s
session.timeout.ms=20000
# 静态消费组,减少滚动发布重平衡,3.x版本强力推荐
group.instance.id=consumer-static-01
# 【异常重试】
# 消费失败最大重试次数
max.poll.records=500
# 单次消费最大处理超时,超时触发重平衡,适配耗时业务调大
max.poll.interval.ms=300000
# 客户端监控ID
client.id=prod-consumer-client
# 关闭分区自动均衡,手动管控更稳定
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignor四、生产配置核心避坑总结
-
禁止默认配置上线:原生默认参数单副本、自动位移提交、允许非ISR选主,极易引发丢数据、重复消费故障;
-
参数成对调优:生产者batch.size+linger.ms、消费者fetch参数需根据业务吞吐适配,不可单独修改;
-
可靠性取舍:日志、埋点高吞吐业务用acks=1,订单、交易核心业务必须acks=all+min.insync.replicas=2;
-
位移提交规范:生产一律关闭自动提交,业务执行成功后手动提交,彻底解决丢消息问题;
-
KRaft与ZK参数隔离:新旧架构配置不可混用,升级集群需清空旧架构专属参数。
5.3 全层级性能调优(生产级完整版|内核+服务端+客户端+网络+架构)
本节为Kafka全链路、全层级生产性能调优终极方案,摒弃浅层配置修改,从操作系统内核、Broker服务端、生产者、消费者、网络内核、业务架构六大维度,拆解调优原理、核心参数、生产最优值、适配场景、禁忌坑点,解决线上吞吐低、延迟高、IO抖动、负载不均、频繁卡顿等核心性能问题,适配2.x/3.x全版本集群,可直接落地复用。
一、操作系统内核层调优(性能基石,重中之重)
Kafka性能高度依赖磁盘IO、PageCache、网络内核,系统参数不合理是80%线上性能抖动的根源,所有集群节点必须统一配置。
1. 内存内核调优(核心:最大化利用PageCache)
(1)彻底关闭SWAP分区(生产强制)
调优原理:Kafka读写重度依赖PageCache,SWAP交换分区会导致内存数据频繁磁盘置换,直接造成性能暴跌50%以上,引发延迟飙升、吞吐抖动。
落地命令:swapoff -a && sed -i '/swap/s/^/#/' /etc/fstab
生产规范:永久关闭,所有节点无例外,禁止临时开启SWAP。
(2)调高PageCache脏页刷新参数
调优参数:vm.dirty_ratio=80、vm.dirty_background_ratio=5
原理:提升脏页内存占比阈值,减少频繁小批量刷盘,适配Kafka批量顺序写特性,降低磁盘IO次数。
最优值:常规集群dirty_ratio=80,高吞吐集群可调至85,避免内存积压过多。
(3)调整内存回收策略
参数:vm.min_free_kbytes=1048576
作用:预留足够空闲内存,避免系统频繁回收缓存,保障PageCache稳定可用。
2. 磁盘IO调优(核心:强化顺序写性能)
(1)磁盘IO调度策略修改
机械硬盘:设置mq-deadline调度,优化批量顺序IO;
SSD固态硬盘:设置none无调度,减少内核调度开销(生产SSD标配)。
(2)禁止磁盘挂载日志更新
挂载参数:noatime,nodiratime
原理:关闭文件访问时间记录,避免频繁小IO写入,释放磁盘IO资源,提升读写性能。
(3)独立磁盘挂载
硬性规范:Kafka日志盘、系统盘、元数据盘物理隔离,禁止混部,防止系统日志、服务日志抢占IO资源。
3. 文件句柄与线程限制调优
-
全局文件句柄数 :
ulimit -n 655350(永久生效) 解决高并发下文件句柄耗尽、连接创建失败、日志文件无法写入问题。 -
最大进程线程数 :
ulimit -u 655350适配Kafka多线程模型(网络线程、IO线程、后台清理线程),杜绝线程创建失败。
4. 系统时间同步
- 所有节点开启NTP时间同步,时间偏差控制在1s内 规避隐患:时间不同步导致日志索引错乱、副本同步超时、事务状态异常、消息过期误清理。
二、网络内核层调优(解决延迟、重传、连接拥堵)
针对高吞吐、高并发网络场景优化TCP内核参数,减少网络抖动、重传、连接超时,稳定集群通信。
(1)调大TCP队列缓存
参数:net.core.somaxconn=32768、net.core.rmem_max=16777216、net.core.wmem_max=16777216 作用:提升TCP连接队列与读写缓冲区,应对瞬时海量连接、批量数据传输,避免网络拥堵。
(2)优化TCP超时与重传机制
参数:net.ipv4.tcp_retries2=5、net.ipv4.tcp_syn_retries=2
作用:缩短无效连接重试超时,快速释放死连接,减少无效网络开销。
(3)开启TCP快速回收
参数:net.ipv4.tcp_tw_recycle=1、net.ipv4.tcp_tw_reuse=1
作用:快速回收TIME_WAIT连接,解决高并发下连接数耗尽问题。
(4)禁用TCP时间戳
参数:net.ipv4.tcp_timestamps=0 规避内网网络环境下的时间戳漂移导致的随机丢包、重传问题。
三、Broker服务端深度调优(集群核心性能优化)
1. 线程池参数精准调优
线程数并非越大越好,需匹配CPU核心数,避免上下文切换过载
-
num.network.threads(网络线程):生产最优8~16 负责接收客户端连接、处理网络请求,8核CPU标配12,16核CPU标配16。
-
num.io.threads(IO读写线程):生产最优16~24 核心读写线程,承担日志写入、索引更新、副本同步,是性能核心参数,高配机器可设32。
-
background.threads(后台线程):生产最优10~16 负责日志清理、分区迁移、元数据同步、副本校验,避免后台任务阻塞业务读写。
-
log.cleaner.threads(日志压缩线程):常规4,状态数据集群8 仅开启compact压缩策略的集群需调大,普通删除策略保持默认即可。
2. 存储与刷盘机制调优
(1)禁用同步刷盘,全量异步刷盘
生产绝对禁止开启同步刷盘,依托PageCache异步落盘,兼顾超高吞吐与数据安全(多副本兜底)。
核心参数:log.flush.interval.messages=10000、log.flush.interval.ms=1000,兜底刷盘,不影响性能。
(2)日志分段大小优化
标准业务固定1GB(log.segment.bytes=1073741824),大流量日志业务可上调至2GB
原理:减少日志分段切换次数,降低索引重建、文件切换带来的IO抖动。
(3)合理配置日志保留策略
高吞吐临时数据(日志、埋点):保留3天,减少磁盘存储压力与清理开销;
核心业务数据:保留7天,兼顾数据回溯与存储成本。
3. 副本与高可用性能调优
(1)副本同步参数优化
replica.lag.time.max.ms=30000:避免网络轻微抖动导致ISR频繁收缩; replica.fetch.max.bytes=10485760:单次最大同步10MB,提升副本同步效率,减少滞后。
(2)开启Leader自动均衡
参数:auto.leader.rebalance.enable=true 定时均衡集群Leader分区分布,避免单节点热点负载,均衡全集群读写压力。
(3)禁止非ISR选主
强制关闭unclean.leader.election.enable=false,杜绝数据丢失,同时避免异常选主引发的性能波动。
4. 元数据性能调优(3.x KRaft专属)
-
调大元数据日志分区副本数为3,保障元数据高可用;
-
独立挂载元数据磁盘,与业务日志磁盘物理隔离,避免业务IO抢占元数据读写资源;
-
优化Raft投票超时参数,减少控制器频繁切换引发的集群卡顿。
四、生产者客户端调优(写入吞吐最大化)
生产者是流量入口,核心调优思路:批量攒批、数据压缩、减少网络交互、合理重试,平衡吞吐与延迟。
1. 批量攒批参数黄金组合
-
batch.size=16384(16KB):批量消息阈值,达到大小立即发送;
-
linger.ms=5:最长攒批等待时间,5ms平衡吞吐与延迟;
-
buffer.memory=67108864(64MB):客户端缓冲区,承载瞬时堆积消息;
-
适配场景:90%企业业务通用,高吞吐大流量可上调batch.size至32KB,低延迟业务下调linger.ms至2ms。
2. 数据压缩调优(性价比最高的性能优化)
-
首选LZ4压缩:压缩速度快、CPU开销低、解压效率高,适配绝大多数生产场景;
-
高压缩需求选Snappy:兼顾压缩率与性能,日志、埋点业务专属;
-
禁止Gzip常态化使用:压缩率高但CPU开销极大,仅适配冷数据归档场景;
-
压缩级别固定6级,避免过高级别导致CPU飙升。
3. 重试与并发调优
-
retries=3、retry.backoff.ms=100:3次重试、100ms间隔,解决临时网络抖动,避免频繁重试压垮集群;
-
max.in.flight.requests.per.connection=5:限制单连接未确认请求数,避免消息乱序与集群拥堵;
-
开启幂等生产者,杜绝重试导致的消息重复,无性能损耗,生产强制开启。
4. 消息大小管控
-
常规业务限制单条消息≤1MB,超大消息拆分传输;
-
特殊业务可调大
max.request.size,但禁止超过10MB,防止大消息同步超时、阻塞批量写入。
五、消费者客户端调优(解决堆积、提升消费效率)
消费者性能核心痛点:消费阻塞、重平衡频繁、单次消费体量过小、位移提交低效,调优围绕提升并发、减少阻塞、稳定重平衡、批量消费展开。
1. 批量拉取与消费参数优化
-
fetch.min.bytes=10240(10KB):攒够10KB消息再拉取,减少空轮询、网络交互次数;
-
fetch.max.bytes=10485760(10MB):单次最大拉取10MB,提升批量消费体量;
-
fetch.max.wait.ms=500:最大等待500ms,平衡实时性与批量效率。
-
max.poll.records=500:单次消费最大500条,适配业务处理能力,避免单次处理过多导致超时重平衡。
2. 重平衡彻底优化(生产核心)
-
开启静态消费组 :配置
group.instance.id,滚动发布、实例重启不触发重平衡; -
超时参数调优 :
heartbeat.interval.ms=3000、session.timeout.ms=20000,避免网络轻微抖动误判实例下线; -
禁止频繁启停服务:规范发布流程,灰度发布,杜绝批量重启消费者引发全局重平衡。
3. 位移提交优化
-
生产强制关闭自动提交,采用业务执行成功后手动批量提交;
-
高吞吐业务支持批量位移提交,减少频繁IO交互,提升消费性能;
-
杜绝消费前提交位移,避免数据丢失,同时减少无效提交开销。
4. 消费并发匹配原则
-
消费并发数 ≤ Topic分区数,杜绝空闲实例;
-
单分区消费线程数固定1,避免多线程消费同一分区导致无序、锁竞争;
-
业务消费逻辑异步化,避免同步阻塞拖慢整体消费速度。
六、业务架构层调优(根治性能瓶颈)
80%的性能问题并非参数问题,而是架构设计不合理,架构调优是终极性能解决方案。
1. 分区数精准规划
-
单分区稳定TPS:1000~3000,峰值可承载5000;
-
总分区数 = 业务峰值TPS / 2000(中间值预留冗余);
-
单Broker承载分区数≤1500,避免分区过多导致元数据压力过大、重平衡超时;
-
禁止分区过少(消费瓶颈)、分区过多(集群抖动)。
2. 流量拆分与隔离
-
高吞吐日志、埋点流量与核心业务流量物理Topic隔离,避免大流量抢占核心业务资源;
-
热点Topic单独部署Broker节点,实现流量隔离,杜绝全局负载倾斜;
-
瞬时峰值流量通过批量攒批、异步削峰平滑处理。
3. 消息规范治理
-
统一消息格式,精简无效字段,减少消息体积,降低传输与存储开销;
-
超大消息采用「链接+OSS存储」方案,禁止直接推送大消息至Kafka;
-
无效日志、重复埋点提前过滤,减少无效流量占用集群资源。
七、各场景专属调优方案(直接套用)
1. 高吞吐日志/埋点场景
acks=1、LZ4压缩、批量攒批最大化、异步刷盘、分区数充足、放宽延迟要求,优先保障吞吐。
2. 低延迟实时业务场景
linger.ms=0、减小批量大小、缩短拉取超时、优化消费逻辑、减少重平衡,优先保障毫秒级延迟。
3. 高可靠核心交易场景
acks=all、min.insync.replicas=2、3副本配置、手动位移提交、开启幂等/事务,牺牲部分吞吐换取数据绝对可靠。
4. 海量IoT高频小消息场景
调大linger.ms适度攒批、开启极致压缩、优化TCP网络参数,解决小消息高频IO开销问题。
八、调优禁忌与避坑总结
-
禁止盲目调大线程数:线程过多会导致CPU上下文切换频繁,反而降低性能;
-
禁止混用刷盘策略:生产统一异步刷盘,同步刷盘仅用于线下测试;
-
禁止过度压缩:高CPU负载集群无需开启高等级压缩,避免CPU瓶颈;
-
禁止参数单独修改:批量、重试、拉取参数需配套调整,单一修改易引发性能失衡;
-
忽略系统层调优:仅调Kafka参数不调系统内核,性能提升上限极低;
-
分区数过度扩容:分区过多会导致元数据爆炸、集群不稳定、重平衡耗时剧增。
简洁:
1. 操作系统层
-
调高文件句柄、最大线程数
-
磁盘:独立挂载日志盘,优先 SSD
-
内存:调大 PageCache,彻底关闭 SWAP 交换分区
-
网络:优化 TCP 内核参数
2. Broker 服务端调优
-
副本数:生产建议 2~3 副本
-
分区数合理规划,避免过多/过少
-
刷盘策略:默认异步刷盘,兼顾性能
-
日志清理、压缩按需配置
3. 生产者调优
合理配置批量、linger、压缩、acks、缓冲区、重试。
4. 消费者调优
批量拉取、优化线程数、减少 Rebalance、规范位移提交。
5.4 日常运维操作(生产全流程落地版)
本章节聚焦企业生产日常高频运维操作,摒弃基础入门命令,覆盖集群扩缩容、节点上下线、分区运维、副本均衡、位移管控、元数据清理、日常巡检全流程,所有操作均为生产安全规范,规避误删、数据丢失、集群抖动等风险,可直接线上复用。
一、集群扩缩容运维(核心高频)
1. 集群扩容(新增Broker节点)
适用场景:集群负载过高、分区数不足、磁盘容量告警、流量增长扩容
生产规范流程:环境初始化 → 配置文件部署 → 节点启动 → 元数据同步 → 分区重均衡 → 负载核验
-
前置准备:新节点完成系统优化(关闭SWAP、调大文件句柄、NTP时间同步、独立SSD磁盘挂载),系统环境与存量节点保持一致;
-
配置文件适配:新节点server.properties配置与集群统一,KRaft架构填写集群投票节点,ZK架构填写ZK集群地址,保证cluster.id全局一致,broker.id唯一不重复;
-
启动新节点:执行优雅启动命令,启动后等待1-3分钟完成集群元数据同步,通过集群查询命令核验节点上线成功;
-
核心操作:分区重均衡:新节点上线后无任何分区流量,需手动执行分区重分配,将存量Topic分区均匀迁移至新节点,实现集群负载均衡;
-
后置核验:查看节点Leader分区数、磁盘占用、CPU/IO负载,确认流量均匀分布,无分区同步异常。
生产禁忌:新增节点后不做分区均衡,导致新节点空闲、旧节点负载堆积。
2. 集群缩容(下线Broker节点)
适用场景:节点硬件老旧、资源闲置、故障节点替换、集群规模精简
安全操作流程(禁止直接停机)
-
流量迁移前置:优先将待下线节点上的所有Leader分区、Follower分区迁移至集群其他健康节点,确保待下线节点无任何分区副本;
-
分区清空核验:通过describe命令核查待下线节点,确认无任何分区分配,无副本同步任务;
-
优雅停止节点:执行stop优雅停机命令,禁止kill -9暴力停机;
-
集群状态核验:检查集群ISR状态、Leader分布、元数据同步,确认无异常、无分区下线;
-
资源清理:节点下线成功后,清理集群残留元数据,更新集群节点台账。
核心避坑:缩容必须先迁移分区再停机,直接下线节点会导致分区副本缺失、ISR收缩、数据丢失风险。
二、Topic全生命周期运维
1. Topic规范创建(生产强制标准)
禁止默认参数创建,必须指定分区数、副本数,适配业务流量,统一命名规范(业务线-数据类型-环境),例如:order-event-prod、log-gateway-prod
标准创建命令
XML
# 生产标准:8分区、2副本,适配常规业务
kafka-topics.sh --create \
--topic business-topic-prod \
--bootstrap-server 集群地址:9092 \
--partitions 8 \
--replication-factor 22. Topic配置动态修改
适用场景:调整消息保留时长、日志清理策略、最大消息大小、压缩策略
XML
# 修改消息保留时长为3天
kafka-configs.sh --alter \
--entity-type topics \
--entity-name business-topic-prod \
--add-config retention.ms=259200000
# 开启日志压缩策略(状态数据Topic专用)
kafka-configs.sh --alter \
--entity-type topics \
--entity-name business-topic-prod \
--add-config cleanup.policy=compact3. Topic安全删除(生产谨慎操作)
生产原则:优先逻辑下线(停止生产消费、保留数据回溯),非必要不物理删除
删除前置校验:确认无业务依赖、无消费组订阅、无数据回溯需求,备份关键数据
XML
# 物理删除Topic
kafka-topics.sh --delete --topic business-topic-prod --bootstrap-server 集群地址:9092残留清理:删除后若存在元数据残留,需清理集群日志元数据,避免幽灵分区报错。
三、分区专项运维(解决负载倾斜、性能瓶颈)
1. 分区扩容(唯一支持的分区操作)
核心规则 :分区只能新增、不能减少,分区不足导致消费瓶颈、消息堆积时必须扩容
XML
# 分区从8扩容至16
kafka-topics.sh --alter \
--topic business-topic-prod \
--partitions 16 \
--bootstrap-server 集群地址:9092扩容后操作:新增分区默认无历史数据,需手动均衡Leader分布,避免新分区无流量、旧分区堆积。
2. 分区副本重分配(负载均衡核心)
适用场景:节点负载倾斜、Leader分区分布不均、扩容缩容后负载失衡、热点分区优化
操作流程:生成分配方案 → 核验方案合理性 → 执行重分配 → 同步进度监控 → 负载核验
XML
# 1. 生成分区重分配方案
kafka-reassign-partitions.sh \
--bootstrap-server 集群地址:9092 \
--topics-to-move-json-file topics.json \
--generate \
--reassignment-json-file result.json
# 2. 执行分区重分配
kafka-reassign-partitions.sh \
--bootstrap-server 集群地址:9092 \
--reassignment-json-file result.json \
--execute
# 3. 监控重分配进度
kafka-reassign-partitions.sh \
--bootstrap-server 集群地址:9092 \
--reassignment-json-file result.json \
--verify生产规范:重分配优先业务低峰期执行,避免大流量迁移引发集群IO飙升、延迟抖动。
3. Leader分区手动均衡
适用场景:分区Leader集中在单节点,导致节点热点负载
XML
# 触发Topic Leader自动均衡
kafka-leader-election.sh \
--bootstrap-server 集群地址:9092 \
--topic business-topic-prod \
--election-type preferred四、副本运维与高可用保障
1. 副本状态巡检(日常必查)
定期核查异常副本、ISR收缩、副本同步滞后分区,提前规避故障风险
XML
# 查询所有ISR异常、副本未同步分区
kafka-topics.sh --describe --bootstrap-server 集群地址:9092 | grep -i under2. 副本数动态调整
适用场景:普通业务升级为核心业务、单副本老旧集群整改、提升数据可靠性
通过kafka-reassign-partitions工具配合配置文件,动态增加副本数,无需停机、不影响业务。
3. 副本同步异常修复
针对Follower副本同步滞后、ISR频繁收缩问题:优先排查节点CPU/磁盘IO/网络带宽,优化节点负载,重启异常副本同步线程,严重时重新分配副本分布。
五、消费组与位移运维(故障修复核心)
1. 消费组日常巡检
XML
# 查看所有消费组
kafka-consumer-groups.sh --list --bootstrap-server 集群地址:9092
# 查看消费组详情(堆积、位移、滞后量、分区分配、实例状态)
kafka-consumer-groups.sh --describe --group 消费组名 --bootstrap-server 集群地址:90922. 位移重置(生产故障修复核心,谨慎操作)
适用场景:数据重跑、消费异常、位移错乱、误提交位移、业务修复回溯数据
XML
# 1. 重置为最新位移:清空堆积,从新消息开始消费
kafka-consumer-groups.sh --reset-offsets \
--group 消费组名 \
--topic 主题名 \
--to-latest \
--execute \
--bootstrap-server 集群地址:9092
# 2. 重置为最早位移:全量回溯,历史数据重跑
kafka-consumer-groups.sh --reset-offsets \
--group 消费组名 \
--topic 主题名 \
--to-earliest \
--execute \
--bootstrap-server 集群地址:9092
# 3. 按指定时间重置位移(精准回溯)
kafka-consumer-groups.sh --reset-offsets \
--group 消费组名 \
--topic 主题名 \
--to-datetime "2025-01-01 00:00:00" \
--execute \
--bootstrap-server 集群地址:9092生产强制规范:位移重置前必须停止消费服务、备份位移数据、评估重复消费影响,核心业务需报备操作。
3. 僵尸消费组清理
清理长期无消费、无实例的僵尸消费组,释放集群元数据资源,减少集群压力
XML
kafka-consumer-groups.sh --delete --group 僵尸消费组名 --bootstrap-server 集群地址:9092六、集群日常巡检运维(每日必做)
1. 集群状态巡检项
-
节点状态:所有Broker在线、无节点离线、无异常重启;
-
副本状态:无ISR收缩、无离线副本、副本同步正常;
-
负载状态:CPU/内存/磁盘IO/网络带宽无持续高负载,负载均匀;
-
磁盘状态:磁盘使用率正常、无爆满预警、日志清理正常;
-
业务状态:无大规模消息堆积、消费TPS正常、无频繁重平衡;
-
元数据状态:KRaft/ZK元数据同步正常、无选举异常。
2. 日志巡检
每日核查Broker日志、客户端日志,排查生产失败、消费异常、同步超时、权限报错等隐性故障,提前干预修复。
七、元数据运维(KRaft架构专属)
-
元数据同步校验:定期核查__cluster_metadata分区同步状态,确保所有节点元数据一致;
-
控制器运维:监控控制器节点状态,避免控制器频繁切换引发集群卡顿;
-
元数据修复:元数据错乱时,优先重启控制器节点同步元数据,禁止手动修改系统Topic。
八、生产运维通用红线禁忌
-
禁止高峰期执行分区重分配、节点上下线、位移重置、集群参数修改等高风险操作;
-
禁止手动删除、修改系统内置Topic(__consumer_offsets、__cluster_metadata、__transaction_state);
-
禁止单副本Topic长期在线运行,禁止非ISR选主参数开启;
-
禁止暴力启停集群节点,禁止线上随意修改核心性能、高可用参数;
-
禁止多业务共用同一个消费组、同一个Topic,避免数据错乱、消费异常。
简洁:
Topic 增删改查、分区扩容、分区迁移、副本重分配、手动重置位移、集群扩缩容、节点上下线。
5.5 压测工具 & 性能基准
-
官方压测脚本
-
kafka-producer-perf-test.sh生产者压测 -
kafka-consumer-perf-test.sh消费者压测
-
-
性能基准(物理机)
-
单 Broker 写入:80~150 MB/s
-
单 Broker 读取:100~200 MB/s
-
端到端延迟:正常 1~5ms,批量场景 10~20ms
-
5.6 生产级完整容量规划公式(可直接落地测算)
本节为企业精准容量测算标准公式,解决简易公式测算不准、预留不足、资源浪费问题,覆盖磁盘、分区、带宽、机器节点四大核心维度,附带参数解释、取值规范、实战计算案例,适配所有线上Kafka集群规划。
一、磁盘容量精准计算公式(核心必用)
完整公式: \\text{总磁盘容量(GB)} = \\text{日峰值消息总量(GB)} \\times \\text{副本数} \\times \\text{数据保留天数} \\div \\text{压缩率系数} \\div 0.9(\\text{磁盘预留阈值}) \\times 1.3(\\text{峰值冗余系数})
参数详细释义(生产取值标准)
-
日峰值消息总量:业务每日高峰期产生的原始消息总容量(非压缩后),需统计峰值流量,不可用日均流量,避免高峰期容量不足;
-
副本数:生产常规2副本、核心业务3副本,对应公式代入2/3;
-
数据保留天数 :日志/埋点业务3-7天,核心业务7-30天,按集群实际配置
log.retention.hours换算; -
压缩率系数:无压缩=1,LZ4/Snappy=0.4-0.6(压缩后体积为原始40%-60%),Gzip=0.2-0.3;未开启压缩固定取1;
-
磁盘预留阈值0.9:磁盘安全使用率上限90%,预留10%空间避免磁盘爆满、集群只读;
-
峰值冗余系数1.3:预留30%冗余,适配业务流量增长、瞬时峰值、临时数据堆积,规避扩容不及时风险。
实战计算案例
场景:日志业务,日原始流量500GB,2副本,保留7天,开启LZ4压缩(系数0.5)
测算:500 × 2 × 7 ÷ 0.5 ÷ 0.9 × 1.3 ≈ 20222GB,集群总磁盘容量需预留20TB以上
二、Topic分区数精准计算公式(解决并发瓶颈)
核心公式: \\text{最优分区数} = \\lceil \\frac{\\text{业务峰值总TPS}}{\\text{单分区稳定TPS}} \\rceil \\times 1.2(\\text{冗余系数})
参数取值规范
-
单分区稳定TPS:生产安全阈值1000~3000 TPS,高可靠业务取低值1000-1500,高吞吐日志业务可取2000-3000;
-
冗余系数1.2:预留20%分区冗余,适配业务流量逐年增长,避免频繁扩容分区;
-
约束上限:单Broker节点承载分区数≤1500,超出需新增节点,防止元数据压力过大、集群抖动。
实战案例
场景:业务峰值TPS 20000,常规业务单分区稳定TPS取2000
测算:(20000 ÷ 2000) × 1.2 = 12分区,最优配置12-16分区预留冗余
三、网络带宽容量规划公式
峰值带宽计算公式: \\text{所需峰值带宽(Mbps)} = \\text{峰值消息流量(MB/s)} \\times 8 \\times 1.3(\\text{网络冗余})
参数说明
-
乘以8:字节(MB)转比特(Mbps)网络带宽单位;
-
1.3冗余:适配网络协议开销、重传流量、瞬时峰值波动;
-
生产规范:单网卡带宽预留≥测算值,高吞吐集群建议10G网卡,杜绝带宽打满。
四、Broker节点数量规划公式
节点数计算公式: \\text{最小节点数} = \\lceil \\frac{\\text{集群总分区数}}{\\text{单Broker最大承载分区数}} \\rceil
生产约束规范
-
单Broker安全分区上限:1000~1500个;
-
高可用硬性要求:生产集群节点数≥3,KRaft架构必须为奇数节点(3/5)保障选举合法;
-
负载均衡约束:节点Leader分区数均匀分布,单节点Leader分区占比不超过总分区30%。
五、极简速算公式(日常快速评估)
-
磁盘速算:日流量 × 副本数 × 保留天数 × 2.5(默认含压缩、冗余、预留阈值,快速粗估)
-
分区速算:峰值TPS ÷ 2000 × 1.2(通用业务万能速算)
-
带宽速算:峰值MB/s × 10(简化冗余系数,快速评估带宽)
六、容量规划核心避坑准则
-
禁止用日均流量 测算,必须以业务峰值流量为基准,避免高峰期容量不足;
-
压缩系数必须精准代入,开启压缩不计算会导致容量预留过大、资源浪费;
-
分区数不可过度冗余,分区过多会引发元数据爆炸、重平衡超时、集群卡顿;
-
所有容量测算必须预留20%-30%冗余,适配业务迭代增长,杜绝满负荷运行;
-
KRaft架构需单独预留元数据磁盘容量,不与业务日志磁盘共用。
简洁:
-
磁盘容量 = 日消息总量 × 副本数 × 保留天数 × 压缩系数
-
分区数参考:单分区合理 TPS 1000~3000 总分区数 ≈ 峰值 TPS / 单分区 TPS
-
带宽预留:峰值流量基础上预留 30% 冗余。
第六部分 线上故障排查 & 冷门坑点
6.1 通用排查流程
线上Kafka故障通用标准化排查SOP(优先级从快到慢、从宏观到微观),适配所有线上异常(堆积、丢消息、重复消费、集群卡顿、读写报错、延迟飙升等),全程可直接落地执行,兼顾快速止血与根因定位,是运维、开发排查Kafka问题的统一标准流程。
第一步:告警核验 & 故障范围锁定(1分钟快速定性)
核心目标:快速区分是全局集群故障、单节点故障、单Topic故障还是单消费组业务故障,避免盲目排查。
-
监控指标核验:优先查看核心监控面板,确认异常指标:消费堆积量、生产/消费TPS、端到端延迟、Broker CPU/磁盘IO/网络带宽、磁盘使用率、副本同步延迟
-
故障范围判定全局异常:所有Topic生产/消费异常、多节点负载飙升、集群元数据报错 → 集群层级故障
-
局部异常:单个/少数Topic堆积、仅部分业务报错 → 业务Topic或消费组层级故障
-
单点异常:单Broker节点负载过高、离线、同步失败 → 节点硬件/服务故障
影响范围统计:确认受影响业务线、是否核心业务、是否需要紧急止血降级,判断故障等级
第二步:集群全局状态巡检(2分钟集群兜底排查)
核心目标:排除集群底层故障,集群正常再排查业务层问题,规避底层架构问题导致的业务异常。
-
节点状态核查:确认所有Broker节点在线、无重启、无进程异常,KRaft架构检查控制器节点状态、无频繁切换
-
副本与ISR状态核查(核心) :执行命令排查所有ISR收缩、副本同步异常、离线分区, 命令:
kafka-topics.sh --describe --bootstrap-server 集群地址:9092 | grep -i under异常特征:ISR列表缩水、副本滞后、分区处于under-replicated状态,直接导致读写延迟、堆积、数据不一致 -
磁盘状态核查:检查磁盘使用率、磁盘IO负载、是否存在磁盘爆满、只读、IO打满卡顿,磁盘故障是线上高频底层问题
-
元数据状态核查:KRaft架构校验__cluster_metadata同步正常,ZK架构校验ZK连接、元数据读写无异常,无元数据超时、错乱报错
第三步:生产侧问题排查(定位是否为写入异常)
核心目标:确认消息是否正常写入集群,排查写入失败、写入卡顿、流量异常问题。
-
生产流量核验:查看Topic生产TPS,判断是无流量、流量骤降、流量暴涨
-
生产报错排查:查看业务生产者日志,重点捕获:连接超时、权限报错、序列化失败、acks超时、消息超限、分区路由异常
-
生产者参数校验:核查批量参数、重试机制、压缩配置、幂等/事务配置是否异常,是否存在参数变更导致写入失败
-
写入兜底测试:控制台手动推送测试消息,验证Topic是否可正常写入,快速定位是客户端问题还是集群服务端问题
第四步:消费侧核心排查(80%故障根源)
核心目标:绝大多数堆积、延迟、不消费、重复消费问题均出自消费侧,精细化排查消费组、分区、位移、重平衡问题。
-
消费组基础信息核查 :查看消费组状态、在线实例数、分区分配情况, 命令:
kafka-consumer-groups.sh --describe --group 消费组名 --bootstrap-server 集群地址:9092 -
堆积与滞后核验:查看分区滞后量、当前消费位移、最新位移,确认是全局堆积、单分区热点堆积还是无位移推进
-
重平衡异常排查:检查服务启停日志、心跳超时、会话超时记录,确认是否存在频繁重平衡导致消费中断、堆积
-
位移异常排查:核查位移是否异常重置、超前/滞后、提交失败、位移越界,确认重复消费、不消费的根因
-
消费业务逻辑排查:查看消费者业务日志,是否存在消费阻塞、报错重试、事务超时、外部接口超时,导致消费速度远低于生产速度
-
并发匹配校验:核查消费实例数、并发线程数是否小于分区数,存在消费并发瓶颈
第五步:Topic与分区专项排查(解决负载倾斜、热点问题)
-
分区状态校验:检查分区Leader分布是否均匀、是否存在单节点热点分区、分区数量是否不足
-
消息特性排查:核查是否存在超大消息、畸形消息、批量异常消息,导致分区同步超时、消费阻塞
-
Topic配置校验:检查消息保留时长、清理策略、最大消息大小、压缩策略是否配置异常,引发消息过期、截断、堆积
第六步:网络与系统层排查(隐性故障定位)
核心目标:排查隐性底层问题,多数偶发延迟、抖动、超时均由系统/网络导致。
-
网络排查:检测集群节点间、客户端与集群网络延迟、丢包、重传,检查TCP连接数、TIME_WAIT连接是否打满
-
系统内核排查:检查SWAP是否开启、文件句柄是否耗尽、CPU上下文切换是否过高、页缓存是否异常
-
时间同步排查:校验所有节点NTP时间是否同步,时间差过大会导致索引异常、副本同步失败、事务失效
第七步:紧急止血 & 故障恢复(优先保业务)
排查定位问题后,优先执行快速止血操作,再优化根治,避免故障扩大。
-
消费能力不足:扩容消费实例、优化消费阻塞逻辑、临时提升消费并发
-
分区热点/并发瓶颈:扩容Topic分区、重分配分区均衡负载
-
集群节点异常:下线故障节点、触发Leader重选、迁移分区负载
-
大量消息堆积:临时重置位移、清理无效堆积、扩容磁盘空间
-
重复消费/丢消息:临时开启业务幂等、手动校准消费位移、调整acks可靠性参数
第八步:根因复盘 & 长效优化(杜绝复发)
故障恢复后完成闭环复盘,定位底层根因,输出优化方案,避免同类问题重复出现:
-
参数层面:优化不合理的批量、重试、超时、位移、副本同步参数
-
架构层面:拆分热点Topic、优化分区规划、完善流量隔离
-
运维层面:完善监控告警、增加隐性指标告警、规范发布与运维操作
-
业务层面:完善消息幂等、异常重试、死信兜底、消息规范校验
排查核心口诀(快速记忆)
先看监控定范围,再查集群稳底盘; 先判写入通不通,再查消费堵在哪; 分区负载看均衡,网络内核查隐性; 先保业务快止血,最后复盘治根本。
6.2 高频故障(现象+原因+解决方案)
1. 消息堆积、消费延迟飙升(线上最高频故障)
一、故障核心现象
-
监控指标:Topic消费堆积量持续上涨、消费滞后量(lag)居高不下、端到端延迟从毫秒级飙升至秒级/分钟级
-
流量特征:生产者TPS正常稳定,消费者TPS显著低于生产TPS,甚至消费TPS归零
-
业务表现:实时数据统计滞后、业务事件处理超时、日志/埋点数据延迟落地、数据看板更新卡顿
二、全维度根因拆解(生产全覆盖)
1. 消费侧核心瓶颈(占80%故障场景)
-
消费并发能力不足:Topic分区数过少,消费者实例数/消费线程数达到分区上限,无法扩容提升并发,生产流量持续大于消费处理流量;单分区承载超大流量,单线程消费无法跟进。
-
消费业务逻辑阻塞:消费逻辑包含同步数据库查询、外部接口调用、事务操作、复杂计算,出现接口超时、数据库慢查询、锁等待问题,导致单条消息消费耗时过长,整体消费链路阻塞。
-
频繁消费者重平衡:服务灰度发布、实例上下线、网络抖动触发心跳/会话超时,引发消费组全局重平衡,重平衡期间消费暂停,流量持续堆积;重平衡频繁反复,导致堆积持续递增。
-
消费参数配置不合理:单次消费批量条数过小、拉取间隔过长、最大拉取字节数偏小,无法批量处理消息;自动提交位移频繁、重试参数过高,加重消费阻塞。
2. 分区与流量架构问题
-
分区流量倾斜(热点分区):消息Key哈希分布不均,大量流量集中在少数分区,其余分区空闲;单分区流量打爆单线程消费上限,出现局部堆积,整体集群负载看似正常但业务延迟严重。
-
分区规划不合理:业务流量上涨后未及时扩容分区,分区数无法匹配峰值TPS,天生存在消费并发瓶颈。
-
超大消息阻塞分区:存在超过配置阈值的超大消息、畸形消息,导致单分区消费卡顿、同步超时,后续消息全部阻塞堆积。
3. 集群服务端异常
-
副本同步异常、ISR收缩:Broker节点CPU/磁盘IO/网络打满、磁盘故障、节点负载过高,导致Follower副本同步滞后,分区处于非同步状态,Broker读写限流,消息写入与消费拉取卡顿。
-
集群元数据异常:KRaft控制器频繁切换、ZK连接超时、元数据同步错乱,导致消费者无法正常拉取分区数据,消费中断。
-
磁盘性能瓶颈:机械磁盘IO低效、系统盘数据盘混用、PageCache异常、开启SWAP,导致日志读写延迟飙升,拖累消费速度。
4. 客户端隐性问题
-
消费位移异常:位移提交失败、位移越界、手动重置位移后数据重跑,导致短期大量消息堆积;重复消费重试逻辑死循环,持续占用消费资源。
-
客户端参数异常:消费者超时参数过小、重试次数过多、拦截器逻辑耗时,导致消费频繁失败重试,无法正常推进位移。
三、分级解决方案(紧急止血 + 根治优化)
1. 紧急止血方案(5分钟快速恢复业务)
-
临时扩容消费能力:横向新增消费者实例,匹配分区最大并发,快速拉升消费TPS,消化存量堆积。
-
暂停无效重试:临时关闭消费失败无限重试逻辑,超时消息直接转入死信队列,避免重试阻塞正常消费。
-
规避热点阻塞:针对卡顿热点分区,临时调整消费优先级,优先消费正常分区,缓解整体延迟。
-
紧急节点兜底:下线负载异常、IO打满的故障Broker节点,触发分区Leader重选,恢复正常读写。
2. 短期根治方案(1小时落地优化)
-
优化消费阻塞逻辑:将消费内同步操作改为异步处理,外部接口调用增加超时熔断、降级策略,去除消费链路慢查询、锁竞争逻辑,压缩单条消息消费耗时。
-
优化消费者参数:调大单次批量消费条数、拉取最大字节数,合理设置拉取超时;关闭自动提交,改为业务成功后手动批量提交位移。
-
解决频繁重平衡:开启静态消费组(配置group.instance.id),调优心跳、会话超时参数,规范灰度发布流程,禁止批量重启消费实例。
-
清理异常消息:定位并跳过超大消息、畸形阻塞消息,通过位移重置跳过故障点位,恢复分区消费。
3. 长期架构优化(彻底杜绝复发)
-
合理规划分区数:按照峰值TPS测算最优分区数,预留20%冗余,流量上涨及时扩容分区,从根源解决并发瓶颈。
-
解决流量倾斜:优化消息Key设计,打散热点Key;针对固定热点业务,独立拆分专属Topic,实现流量隔离。
-
集群硬件与参数优化:日志盘独立挂载SSD、永久关闭SWAP、优化TCP内核参数;常态化巡检ISR状态、节点负载,提前规避集群性能瓶颈。
-
完善消息治理:统一消息大小阈值,超大消息采用OSS存储+链接传递方案,禁止大消息直接入Kafka;前置过滤无效消息,减少无效流量堆积。
四、生产预防机制(日常落地)
-
配置堆积量级、延迟时长双维度告警,提前感知小规模堆积,避免故障扩大;
-
新业务上线前完成压测,验证分区数、消费并发是否匹配峰值流量;
-
常态化巡检分区流量分布、节点负载、副本同步状态,提前优化热点问题;
-
所有消费服务统一封装超时、熔断、死信兜底机制,杜绝消费阻塞死循环。
简洁:
原因:消费能力不足、业务阻塞、分区数不足、频繁 Rebalance、流量倾斜 方案:优化消费逻辑、扩容消费实例、扩容分区、打散热点分区。
2. 重复消费(生产高频、面试必考核心)
一、核心本质(底层原理) Kafka 天然默认是 At-Least-Once 至少一次投递语义 ,无原生精准一次消费能力。核心本质:消费位移提交滞后/失败/重置,导致分区消费位点回退,客户端重新拉取历史消息,是所有重复消费的根本原因,而非消息被生产者重复推送。
二、全量生产触发场景(全覆盖,无遗漏)
1. 消费者重平衡引发的批量重复(最常见)
-
触发条件:服务灰度发布、实例上下线、心跳超时、会话超时、网络抖动、消费组配置变更,触发消费者组 Rebalance。
-
重复原理:重平衡期间消费暂停,未及时提交的位移全部作废;分区被重新分配给组内其他实例后,新实例从旧位点继续消费,区间内消息全部重复消费。
-
特征:批量、集中式重复,重启/发布后瞬间出现大量重复消息。
2. 位移提交机制异常导致重复
-
自动提交位移隐患 :默认定时自动提交(默认5s),若提交间隔内消息消费成功,但未到自动提交时间服务宕机/重启,位点未落地,重启后从上次已提交位点重新消费。
-
手动提交失败:业务消费成功后,网络抖动、元数据异常导致位移提交请求失败、超时、重试,位点未更新,下次消费重复拉取。
-
异步提交无回调:使用异步位移提交且不做结果校验,提交静默失败无感知,长期累积重复消费隐患。
3. 生产者重试与幂等失效引发重复推送
-
生产超时重试:生产者发送消息后,网络超时未收到Broker ACK,客户端判定发送失败触发重试,实际消息已成功入库,造成服务端存在重复消息。
-
未开启幂等生产者:非幂等生产者无生产序列号去重,重试消息直接写入Topic,产生重复数据。
4. 手动运维操作导致回溯重复
-
故障修复、数据重跑时手动重置位移到更早位点,主动回溯历史消息,引发全量/区间重复消费。
-
僵尸消费组残留、消费组ID变更错乱,导致位点异常回退重复。
5. 客户端隐性异常场景
-
消费业务超时:单条消息消费耗时过长,超过消费者会话超时时间,被集群判定为离线,触发重平衡,引发重复消费。
-
消费组脑裂:网络分区导致同一消费组存在多组活跃实例,同时消费同一分区,大规模重复消费。
三、重复消费核心危害(生产避坑)
-
业务数据错乱:订单重复创建、积分重复发放、对账数据重复统计、库存重复扣减;
-
下游数据异常:ES/数据库重复写入、数据冗余、报表统计失真;
-
消费死循环:重复消息触发业务报错重试,持续堆积,拖垮消费链路;
-
资源浪费:重复消费占用CPU、IO、网络资源,降低集群吞吐。
四、分级解决方案(临时止血 + 根治落地 + 面试标准答案)
1. 紧急止血方案(快速止损)
-
临时开启业务层本地去重缓存,拦截短时重复消息,快速恢复业务正常;
-
关闭消费者无限重试策略,异常消息直接转入死信队列,避免重复消费死循环;
-
核查并修复异常网络、超时参数,杜绝频繁重平衡。
2. 短期优化方案(解决90%重复场景)
-
规范位移提交机制(核心) :关闭自动提交,统一使用业务执行成功后手动批量提交位移,实现「先消费、后执行业务、成功再提交位点」,彻底规避位移滞后问题。
-
优化重平衡机制 :开启静态消费组(配置group.instance.id),固定实例身份,滚动发布不触发全局重平衡;调优心跳、会话超时参数,适配网络波动。
-
生产者开启幂等:生产环境默认开启幂等生产者,依托PID+序列号机制,服务端自动过滤重试重复消息。
3. 长期根治方案(生产强制落地)
(1)业务全局幂等设计(最终兜底方案):
所有消费业务必须实现幂等,适配任意重复消费场景,是Kafka生产的强制规范。
常用幂等方案:
-
唯一键约束:数据库唯一索引、主键去重,重复写入直接报错拦截;
-
全局唯一ID去重:基于消息ID、业务单号做Redis分布式锁+幂等记录表;
-
状态机幂等:基于业务状态判断,已处理消息直接跳过,不重复执行业务逻辑。
(2)完善异常消息兜底:
搭建死信队列(DLT),消费失败消息统一转发,禁止无限重试,避免重复堆积。
规范运维操作:位移重置、数据重跑必须评估重复影响,提前开启幂等兜底,禁止随意回溯位点。
五、面试满分背诵总结
Kafka默认至少一次投递,重复消费核心源于位移提交滞后、重平衡分区重分配、生产重试无幂等、位点手动回退 。解决方案分三层:短期优化手动提交位移、开启静态消费组、生产者幂等 ;长期核心依靠业务全局幂等兜底;配套死信队列处理异常消息,彻底解决重复消费带来的业务问题。
六、生产落地禁忌
-
禁止依赖Kafka原生机制杜绝重复消费,必须业务层幂等兜底;
-
禁止线上长期使用自动位移提交,高可靠业务一律手动提交;
-
禁止消费业务无状态、无唯一标识,导致无法做幂等去重。
简洁:
原因:自动提交时机异常、手动提交失败、Rebalance、网络重试 方案:业务全局幂等、规范位移提交、减少重平衡。
3. 消息丢失(生产致命问题、面试核心重难点)
核心前置认知 :Kafka 本身设计上可做到消息不丢 ,线上99%的消息丢失均为参数配置错误、编码逻辑不当、运维操作不规范导致,而非组件本身缺陷。Kafka 服务端、生产者、消费者三侧均存在丢消息风险,以下为全场景全覆盖拆解、根因、落地解决方案与预防规范。
一、生产者侧消息丢失(写入阶段丢消息)
核心本质:消息未成功写入Broker集群,客户端判定成功或失败无感知,导致数据直接丢失
场景1:acks=0 极致高性能模式
-
原理:生产者发送消息后无需等待Broker任何ACK响应,直接判定发送成功,网络丢包、Broker宕机、写入失败均无感知,消息直接丢失。
-
适用场景:仅适配日志、埋点等允许数据丢失的极致高吞吐场景,核心业务绝对禁止使用。
-
解决方案:核心业务禁用acks=0,统一使用acks=1或acks=all。
场景2:acks=1 单副本确认 + Leader节点宕机
-
原理:生产者消息写入Leader副本成功,返回ACK确认,但Follower副本尚未同步;此时Leader节点立刻宕机,集群从ISR中选举新的Leader(无该条消息),旧Leader重启后多余消息被截断,造成消息永久丢失。
-
高频场景:单副本Topic、集群负载过高、副本同步滞后。
-
解决方案:核心业务开启多副本,搭配acks=all+min.insync.replicas=2,保障消息同步至少2个副本后再返回成功。
场景3:生产者无重试 + 瞬时网络异常
-
原理:网络抖动、Broker限流、超时导致消息发送失败,生产者默认不重试,直接丢弃消息,无任何日志记录。
-
解决方案:开启生产者重试机制(retries>0),生产环境建议配置3-5次重试,搭配重试间隔,规避瞬时网络异常。
场景4:消息超限被静默丢弃
-
原理:消息大小超过Broker配置的
message.max.bytes阈值,服务端直接拒绝接收,客户端未捕获异常,消息静默丢失。 -
解决方案:统一上下游消息大小规范,服务端与客户端参数对齐,业务前置拦截超大消息。
场景5:生产者缓冲区溢出丢消息
-
原理:客户端缓冲区RecordAccumulator已满、批量消息积压,新消息无法写入,且未配置阻塞策略,直接丢弃消息。
-
解决方案:调优缓冲区大小、阻塞超时时间,开启缓冲区溢出告警。
二、服务端侧消息丢失(存储阶段丢消息)
核心本质:消息写入集群成功后,因集群机制、配置、故障导致数据被截断、清理、丢失
场景1:非ISR副本选主引发消息截断
-
原理:开启
unclean.leader.election.enable=true(允许非ISR副本选主),当所有ISR副本离线,落后的非ISR副本被选为新Leader,旧Leader已同步但未同步到新Leader的消息会被直接截断,永久丢失。 -
解决方案:生产环境强制关闭非ISR选主,参数固定为false,牺牲部分可用性换取数据可靠性。
场景2:日志过期清理过快,未消费消息被清空
-
原理:集群消息保留时长/保留大小设置过小,消息还未被消费者消费,就被日志清理机制自动删除,导致消息丢失。
-
高频场景:消费长时间堆积、服务停机维护,叠加短保留时长。
-
解决方案:根据业务消费速率合理配置
log.retention.hours,预留故障兜底时间,禁止保留时长过短。
场景3:分区副本同步异常、数据截断
-
原理:Broker磁盘IO异常、文件损坏、节点重启,导致副本数据不一致,集群为保证副本统一,自动截断多余分区数据,引发少量消息丢失。
-
解决方案:保障磁盘性能、禁止系统盘混用,常态化巡检副本同步状态。
三、消费者侧消息丢失(消费阶段伪丢失/真丢失)
核心本质:消息已成功写入集群,因消费逻辑、位移提交顺序错误导致消息未消费但位点已提交,触发消息丢失
场景1:先提交位移,后执行业务逻辑(最高频消费侧丢消息)
-
原理:消费者拉取消息后,提前自动提交位移,随后执行业务逻辑;若业务处理过程中宕机、报错、重启,当前批次消息未真正消费,但位移已落地,重启后直接从下一位点消费,未处理消息永久丢失。
-
触发条件:开启默认自动位移提交 + 消费逻辑异常/服务宕机。
-
解决方案:高可靠业务关闭自动提交,改为业务消费成功后手动批量提交位移。
场景2:位移越界自动重置丢失历史消息
-
原理:消费者长时间离线,集群自动清理过期消费位移;服务重启后无有效位点,根据
auto.offset.reset策略重置为latest,直接跳过所有历史堆积消息,造成批量消息丢失。 -
解决方案:延长位移过期时间,核心业务离线后优先手动回溯位移,避免自动重置。
场景3:消费异常批量跳过消息
-
原理:批量消费模式下,批次内单条消息报错,未做异常兜底,直接提交整批次位移,导致同批次正常消息被跳过丢失。
-
解决方案:批量消费拆分异常、单条重试,异常消息转入死信队列,禁止批量跳过。
四、生产级全方位防丢消息方案(强制落地规范)
1. 生产者防丢配置(核心业务标配)
-
acks=all:等待所有ISR副本同步完成后返回ACK
-
retries=5:开启重试机制,规避瞬时网络异常
-
开启幂等生产者:避免重试导致消息重复,同时保障写入可靠性
-
max.in.flight.requests.per.connection=1:保证重试消息有序,避免乱序丢数
2. 服务端防丢核心参数
-
default.replication.factor=2/3:禁止单副本部署
-
min.insync.replicas=2:至少2个副本同步成功才算写入完成
-
unclean.leader.election.enable=false:禁止非ISR选主,杜绝数据截断
-
合理配置日志保留时长,适配业务消费节奏
3. 消费者防丢编码规范
-
关闭自动位移提交,采用消费成功后置手动提交
-
异常消息兜底:死信队列转发,禁止直接丢弃、跳过
-
禁止消费前提交位移,严格遵循「消费-处理-成功-提交」顺序
-
配置合理的会话超时、心跳超时,减少异常重平衡
五、面试满分背诵总结
Kafka消息丢失分为三侧场景:生产者侧主要是acks配置过低、无重试、网络异常、消息超限 ;服务端侧核心是非ISR选主、副本同步滞后、日志提前清理、数据截断 ;消费者侧最高频是先提交位移后执行业务、位移自动重置、批量消费异常跳过。防丢核心方案:服务端多副本+关闭非ISR选主+合理保留策略;生产者acks=all+开启重试与幂等;消费者手动后置提交位移+死信兜底,全方位杜绝消息丢失。
简洁:
丢失场景:
生产者acks=0/1、无重试、超大消息丢弃;
服务端非ISR选主截断数据、日志过期清理;
消费者先提交位移后业务处理、位移自动重置、批量异常跳过。
解决方案:核心业务acks=all+多副本+最小同步副本配置、关闭非ISR选主、开启生产者重试与幂等、消费者手动后置提交位移、异常死信兜底、合理配置日志保留时长。
场景1:acks=0/1 + Leader 宕机,数据未落盘
场景2:消费先提交位移,后执行业务,宕机丢消息
场景3:消息未消费就被日志清理
方案:调高 acks、后置提交位移、合理设置消息保留时长。
4. 副本同步异常、ISR 收缩(集群高可用核心故障)
一、核心定义与故障现象
ISR(In-Sync Replicas,同步副本集):指与Leader副本数据完全同步、无数据滞后的副本集合,包含分区Leader+所有正常同步的Follower副本,是Kafka高可用、数据可靠性的核心保障。
ISR收缩:Follower副本因同步滞后、超时、节点异常被踢出ISR集合,导致分区同步副本数减少,集群容错能力大幅下降,严重时分区进入非同步状态,触发集群告警、读写性能降级。
线上典型现象:
-
集群告警:under-replicated-partitions(副本同步异常分区)、isr-shrink(ISR收缩)告警触发;
-
Topic分区ISR列表长度持续减少,原本2/3副本同步,仅剩Leader单副本存活;
-
生产写入延迟飙升、瞬时吞吐下降,acks=all的生产请求大面积超时;
-
节点日志频繁打印副本同步滞后、拉取数据超时、ISR剔除日志;
-
极端场景下分区不可用、业务写入失败,集群稳定性大幅降级。
二、底层核心原理
Follower副本会主动周期性拉取Leader增量数据保持同步,Kafka通过两个核心参数判定副本是否同步:
-
replica.lag.max.messages:副本最大滞后消息数,超出阈值直接踢出ISR;
-
replica.timeout.ms:副本同步超时时间,指定时间内无有效同步请求、无数据跟进,判定副本失效。
只要Follower满足「数据滞后过多」或「同步超时无响应」任一条件,就会被剔除ISR,造成ISR收缩;若所有Follower全部退出ISR,分区仅剩Leader副本,集群失去故障容错能力,节点宕机必丢数据。
三、全维度根因拆解(生产全覆盖)
1. 节点硬件与系统层瓶颈(最常见)
-
磁盘IO性能不足:使用机械硬盘、日志盘与系统盘混用、磁盘满负载读写,Follower落地消息速度跟不上Leader写入速度,数据持续滞后;开启SWAP、页缓存异常进一步加剧IO卡顿。
-
节点负载过高:Broker节点CPU打满、线程耗尽、内存溢出,导致副本同步线程无法正常工作,同步进度停滞。
-
系统参数不规范:文件句柄数不足、TCP内核参数优化缺失、网络队列溢出,引发同步连接超时、数据传输中断。
2. 网络传输层异常
-
集群网络带宽瓶颈:节点间内网带宽不足、瞬时流量打满,Follower拉取副本数据传输延迟、丢包、重传,同步进度缓慢滞后。
-
网络抖动与分区:机房网络波动、跨机架/跨机房链路不稳定、防火墙拦截、端口限流,导致副本同步心跳中断、超时。
-
节点时间不同步:未开启NTP时间同步,节点时间差过大,引发同步时序判定异常,误剔除正常副本。
3. 消息与业务流量异常
-
超大消息阻塞同步:单条消息超过批量同步阈值、IO处理耗时过长,卡住Follower同步流程,导致后续增量数据无法跟进,触发同步超时。
-
瞬时流量暴涨:业务峰值流量突发,Leader批量写入速度远超Follower同步速度,短时间内数据滞后量超标,直接踢出ISR。
-
热点分区压力集中:单分区承载超大流量,Leader写入压力过载,同步数据推送延迟,拖累Follower同步进度。
4. Kafka参数配置不合理
-
同步超时参数过小:replica.timeout.ms配置过低,轻微流量波动、网络延迟就触发副本剔除,导致频繁ISR收缩。
-
批量同步参数不匹配:Follower拉取批量大小过小、同步线程数不足,无法跟进高吞吐写入节奏。
-
日志清理冲突:Leader节点后台日志清理、分段归档占用IO资源,抢占副本同步IO,导致同步卡顿滞后。
5. 集群运维与版本问题
-
节点滚动重启/扩容:集群运维、版本升级、节点上下线期间,副本重新同步,短暂滞后引发临时ISR收缩。
-
版本BUG:低版本Kafka(0.10/0.8)存在副本同步死循环、ISR误剔除BUG,导致常态化同步异常。
-
分区过多过载:单Broker承载分区数过多,元数据同步压力大,副本同步线程资源被耗尽。
四、分级解决方案(紧急止血 + 根治优化)
1. 紧急止血(5分钟恢复集群高可用)
-
限流削峰:对热点Topic临时限流,降低瞬时写入压力,缓解Leader节点负载,给Follower留出同步时间。
-
恢复异常节点:重启负载异常、卡死的Broker节点,恢复副本同步线程,等待Follower自动追平数据、重新加入ISR。
-
临时关闭非ISR选主 :严格保证
unclean.leader.election.enable=false,避免ISR收缩后劣质副本选主导致数据丢失。 -
紧急扩容带宽/节点:缓解单机IO、网络瓶颈,快速恢复副本同步链路。
2. 短期根治(1小时落地优化)
-
优化系统与硬件环境:日志盘独立挂载SSD、永久关闭SWAP、调大文件句柄数、优化TCP内核参数,消除底层IO瓶颈。
-
调优副本同步参数:合理调高replica.timeout.ms超时时间、增大Follower批量拉取大小、增加同步线程数,适配高吞吐场景。
-
治理超大消息:统一拦截、拆分超大消息,禁止超限消息写入,避免单条消息阻塞全部分区同步。
-
修复网络环境:开启全集群NTP时间同步、优化内网带宽、关闭防火墙多余拦截,保障节点间链路稳定。
3. 长期架构优化(彻底杜绝复发)
-
规范分区规划:合理拆分热点Topic、均衡分区分布,避免单节点、单分区流量过载;控制单Broker分区数量,防止元数据压力过载。
-
优化集群运维规范:禁止批量重启节点,滚动重启错开流量峰值,单次仅操作单节点,预留副本同步缓冲时间。
-
版本升级迭代:淘汰老旧0.8/0.10版本,升级至2.7+稳定版或3.x KRaft架构,修复底层同步BUG。
-
完善监控告警:新增ISR收缩、副本同步滞后、under-replicated分区专项告警,提前感知微小滞后,避免故障扩大。
五、生产强制规避规范
-
生产集群必须2副本及以上,单副本集群无ISR容错能力,极易引发数据丢失;
-
核心业务禁止机械硬盘存储,必须独立SSD磁盘承载日志读写;
-
所有节点强制开启NTP时间同步,杜绝时序异常导致的同步误判;
-
峰值流量必须预留20%以上集群冗余,避免瞬时流量打满引发同步滞后;
-
常态化巡检ISR状态、副本同步延迟、节点负载,做到早发现早修复。
六、面试满分背诵总结
ISR收缩本质是Follower副本数据滞后或同步超时,被集群踢出同步副本集。核心诱因分为底层硬件(磁盘IO、CPU负载)、网络波动、超大消息阻塞、瞬时流量峰值、参数配置不合理、运维操作不当六大类。故障会导致集群容错能力下降、写入延迟飙升、存在数据丢失风险。解决方案:紧急限流恢复同步、优化硬件与网络环境、调优副本同步参数、治理超大消息与热点流量、规范集群运维,长期通过合理分区规划和完善监控彻底规避问题。
简洁:
原因:磁盘IO瓶颈、网络抖动/带宽不足、超大消息阻塞、瞬时流量过载、同步参数不合理、节点负载过高。
方案:SSD独立磁盘、优化网络稳定性、拆分拦截大消息、调优副本同步超时与批量参数、热点分区拆分、错开峰值运维、常态化监控ISR状态。
5. 频繁 Rebalance
原因:服务频繁启停、心跳/会话超时不合理、网络抖动 方案:调优超时参数、规范发布、使用静态成员。
6. 磁盘爆满、集群只读
一、故障核心现象
-
集群磁盘使用率100%,磁盘inode耗尽、无法写入新文件
-
Kafka集群自动进入只读模式,生产者推送消息全部失败、报错日志提示磁盘空间不足
-
分区日志无法追加写入、日志分段归档失败,集群整体读写降级
-
伴随服务卡顿、副本同步中断、ISR批量收缩、消费堆积暴涨连锁故障
-
严重时Broker进程卡死、重启失败,集群局部/整体不可用
二、全维度根因拆解
1. 消息堆积过载(最核心场景)
-
消费服务异常、消费阻塞、频繁重平衡、消费暂停,导致海量消息持续堆积无法消费,日志文件无限膨胀
-
业务峰值流量持续冲高,集群消费能力跟不上生产速度,存量数据不断累积打满磁盘
-
离线任务、数据重跑批量回溯消息,瞬时产生海量存量数据堆积
2. 日志保留参数配置不合理
-
日志保留时长过长:log.retention.hours配置过大,低流量业务、低频消费场景数据长期留存不清理
-
日志保留大小阈值过高:未限制单Topic最大存储,分区持续写入无上限约束
-
日志清理策略失效:开启compact压缩策略的Topic,清理机制滞后、无效历史KV数据堆积占用磁盘
-
清理线程参数过小,磁盘空闲时清理不及时,累积垃圾日志
3. 无效日志与冗余数据堆积
-
大量死信消息、异常重试消息持续写入,无定时清理机制,长期占用磁盘空间
-
删除Topic后元数据、残留日志文件未彻底清理,产生磁盘垃圾碎片
-
集群日志、GC日志、异常堆栈日志未分割轮转,超大日志文件占用数据盘空间
-
系统盘与数据盘混用,系统日志、临时文件挤占Kafka日志磁盘空间
4. 集群运维与参数隐性问题
-
磁盘告警阈值设置过高,临近打满无提前预警,错过扩容、清理窗口期
-
单Broker分区数量过多,元数据文件、索引文件累积占用大量磁盘
-
集群长期未巡检,热点Topic无容量规划,流量增长后磁盘容量未同步扩容
三、紧急止血方案(5分钟快速恢复集群读写)
-
临时清理无效数据:优先删除测试Topic、废弃日志、过期死信数据,快速释放磁盘空间,解除集群只读锁定
-
临时缩短日志保留时长:动态调小log.retention.hours,触发集群自动清理过期消息,快速腾空磁盘冗余空间(核心业务谨慎操作,避免误删有效数据)
-
紧急扩容磁盘:在线扩容磁盘分区、临时挂载空闲磁盘,规避磁盘彻底写死问题
-
限流止损:对超高吞吐热点Topic临时限流,停止无效流量写入,防止磁盘继续暴涨
-
恢复消费能力:快速修复消费阻塞、重启异常消费实例、扩容消费并发,加速消化存量堆积数据
四、短期根治优化(1小时落地)
-
优化日志清理参数:根据业务消费节奏适配保留时长,常规业务保留3-7天,低频业务按需缩减;调大日志清理线程数,提升垃圾清理效率
-
治理无效消息流量:搭建死信队列统一隔离异常消息,配置定时清理规则;过滤无效测试流量、重复流量,减少无效磁盘占用
-
规范磁盘使用:严格隔离系统盘与数据盘,禁止日志混存;配置日志轮转、自动压缩清理规则
-
修复消费瓶颈:优化消费阻塞逻辑、扩容分区与消费实例,解决长期消息堆积根源问题
五、长期架构与运维规范(彻底杜绝复发)
-
容量规划常态化:按业务峰值流量+30%冗余规划磁盘容量,月度巡检磁盘使用率、流量增长趋势,提前扩容
-
完善双层告警机制:配置磁盘使用率80%预警、90%紧急告警,提前介入清理扩容,杜绝磁盘打满
-
Topic精细化治理:废弃Topic及时下线清理,热点Topic独立磁盘部署,避免单Topic打满全局磁盘
-
自动化运维兜底:配置磁盘自动清理脚本、过期数据自动归档规则,无需人工干预
-
冷热数据分层:超大集群开启分层存储,冷数据迁移至低成本存储介质,释放高性能磁盘空间
六、面试&生产简洁总结
原因:消费堆积过载、日志保留时长过长、无效死信/冗余日志累积、磁盘容量规划不足、系统数据盘混用。 方案:紧急清理无效数据+临时缩短保留时长止血;优化消费能力、规范日志参数、治理无效流量根治;完善磁盘告警与容量规划、冷热分层架构长效兜底。
7. 分区 Leader 分布不均、节点负载倾斜
一、故障核心现象
-
节点负载两极分化:集群内部分Broker节点CPU、磁盘IO、网络带宽持续打满,负载居高不下;其余节点空闲、资源利用率极低,集群资源整体浪费严重。
-
读写流量高度集中:所有Topic的Leader分区集中分布在少数Broker,集群读写流量全部压在热点节点,无法发挥分布式集群多节点负载均衡优势。
-
局部业务延迟飙升:热点节点负载过载,导致消息写入延迟、消费拉取延迟大幅升高,瞬时流量峰值极易触发生产超时、消费堆积,非热点节点资源完全闲置。
-
集群容错能力下降:热点节点承载大量Leader分区,一旦该节点宕机、重启或负载异常,会引发大批量分区Leader重选,触发全域业务抖动、ISR收缩、消息堆积等连锁故障。
-
运维扩容失效:新增集群节点后无流量分配,负载依然集中在旧节点,横向扩容无法分担压力,集群扩容收益归零。
二、全维度根因拆解(生产全覆盖)
1. 初始分区分配不合理(先天问题)
-
Topic创建时集群节点数量少,所有分区Leader集中分配在初始少数节点,后续新增节点无存量Leader分区,仅作为Follower副本同步数据,不承接读写流量。
-
批量创建多个Topic时,分区分配算法扎堆分配,未均匀打散至全集群节点,导致部分节点累积大量Leader分区。
2. 运维操作不规范(后天核心诱因)
-
节点上下线、滚动重启:节点下线后,其上所有Leader分区自动迁移至剩余在线节点,多次滚动重启后,Leader分区逐步聚集,最终形成负载倾斜。
-
分区手动扩容不规范:新增分区时未指定机架、节点分配策略,新增分区默认集中分配在负载较高的节点,加剧倾斜问题。
-
故障重启自动选主:故障节点重启后,原有Leader分区不会自动回迁,持续保留在临时接管节点,长期累积负载失衡。
3. 流量热点分化(业务层面倾斜)
-
热点Topic集中:高吞吐核心Topic的Leader分区全部集中在同一批节点,低吞吐冷门Topic分散其余节点,形成明显负载差异。
-
分区流量不均:同一Topic下部分分区为热点分区,承载90%以上业务流量,对应Leader节点负载极高,其余分区节点空闲,造成局部热点倾斜。
4. 集群机制与参数限制
-
Kafka默认Leader均衡机制仅在节点重启、分区重分配时触发,无自动定时均衡Leader的能力,长期运行后必然出现分区聚集。
-
未开启集群自动负载均衡策略,无法根据节点资源使用率动态调整Leader分布。
三、故障核心危害
-
集群性能天花板受限:整体集群吞吐被热点单节点性能限制,无法发挥多节点集群性能优势,资源利用率极低。
-
故障风险集中:热点节点承载核心读写流量,单点故障直接引发大批量业务异常,集群稳定性极差。
-
扩容无效化:新增节点无法承接读写流量,只能同步副本数据,硬件资源闲置,扩容成本浪费。
-
运维成本飙升:长期负载不均导致节点损耗差异大,热点节点频繁出现IO、CPU过载,故障频次大幅提升。
四、分级解决方案(紧急止血 + 根治优化)
1. 紧急止血方案(快速均衡负载)
-
手动触发分区重分配:通过kafka-reassign-partitions.sh脚本,将热点节点的Leader分区批量迁移至空闲节点,快速打散分区分布,均衡读写负载。
-
临时限流兜底:对超高负载热点节点对应的Topic临时限流,降低瞬时写入压力,避免节点持续打满引发业务故障。
-
分批重启热点节点:低峰期滚动重启负载过高节点,触发分区Leader重新选举,临时缓解单点压力。
2. 短期根治方案(1小时落地优化)
-
批量均衡全集群Leader分区:生成全集群分区分配方案,统一规整所有Topic的Leader、Follower分布,保证每个Broker节点承载的Leader分区数、流量基本均匀。
-
规范分区扩容流程:后续新增Topic、扩容分区时,手动指定节点分配策略,强制分区均匀打散至全集群所有节点,避免新增分区扎堆。
-
优化滚动发布策略:节点滚动重启、运维操作错开业务峰值,单次仅操作单节点,避免批量分区迁移导致的集中倾斜。
3. 长期架构与运维规范(彻底杜绝复发)
-
开启机架感知部署:集群配置机架感知,分区副本跨机架、跨节点均匀部署,从底层规避分区集中扎堆问题。
-
定期集群负载均衡巡检:每周核查各节点Leader分区数量、资源使用率、流量负载,发现轻微倾斜及时手动均衡,避免问题累积。
-
热点Topic独立隔离部署:超高吞吐核心热点Topic独立部署专属集群/节点,避免挤占普通业务节点资源,防止全域负载倾斜。
-
流量打散优化:针对热点分区业务,优化消息Key规则、拆分超大热点Topic,实现流量均匀分布,解决单分区、单节点热点问题。
-
新版本特性适配:3.x高版本Kafka支持更完善的集群自动均衡机制,升级新版集群可实现动态负载均衡,减少人工运维成本。
五、生产强制规范
-
禁止长期存在单节点Leader分区数量远超集群平均水平的情况,负载倾斜差值控制在20%以内;
-
所有Topic创建、分区扩容必须遵循均匀分配原则,禁止随意默认创建;
-
节点运维、故障恢复后,必须核查分区分布状态,及时回迁Leader分区;
-
核心业务集群必须开启机架感知,规避单点、单机架集中故障与负载倾斜。
六、面试满分背诵总结
分区Leader分布不均、节点负载倾斜核心是初始分区分配集中、运维滚动重启导致分区迁移聚集、热点Topic流量集中、集群无自动均衡机制引发。直接导致单节点资源打满、集群性能瓶颈、扩容失效、故障风险集中。
解决方案:短期通过分区重分配脚本均衡Leader分布、规整集群负载;中期规范Topic创建与运维操作、隔离热点业务;长期开启机架感知、定期巡检均衡、升级高版本集群,彻底解决负载倾斜问题,最大化利用集群分布式性能。
简洁:
原因:初始分区分配集中、节点滚动运维导致Leader聚集、热点Topic流量集中、无自动负载均衡机制。
方案:通过分区重分配均衡Leader分布、规范分区创建与运维流程、热点业务隔离部署、开启机架感知、定期巡检集群负载。
8. 消费 TPS 为 0,完全不消费
一、故障核心现象
-
监控面板消费TPS持续为0,无任何消息消费记录,生产者可正常推送消息,服务端消息持续堆积
-
消费者进程正常存活、无崩溃报错,日志无明显异常,但完全不拉取、不处理消息
-
Topic分区持续堆积,消息滞后量不断上涨,业务链路完全中断
-
部分场景下消费者频繁重平衡、分区分配为空,导致无消费权限
二、全维度根因拆解(生产全覆盖)
1. 客户端配置与订阅异常(最高频)
-
Topic订阅错误:消费者配置Topic名称拼写错误、大小写不一致,导致订阅无效,无消息可消费;多Topic订阅时部分配置失效,整体消费停滞。
-
消费组配置异常:多个业务共用同一个消费组、消费组ID配置错乱,引发分区分配冲突,导致当前实例分配不到任何分区。
-
订阅权限未生效:集群开启ACL权限管控,消费组、客户端IP未配置订阅/消费权限,权限校验失败,静默不消费无报错。
2. 分区分配与集群状态异常
-
无可用分区分配:消费者实例数大于Topic分区数,多余实例处于空闲状态,TPS为0;分区全部被其他消费实例占用,当前实例无分配分区。
-
分区状态异常:Topic分区无Leader、ISR全部收缩、分区处于离线/同步异常状态,集群禁止读写,消费者无法拉取消息。
-
元数据同步失败:客户端与集群元数据同步超时、错乱,无法获取分区Leader信息,无法建立消费连接。
3. 消费位移异常卡死
-
位移越界自动重置失效:消费组长时间离线,位移记录过期被清理,auto.offset.reset配置异常(配置错误/未生效),无法重置位点,消费停滞。
-
位移数据损坏:__consumer_offsets系统Topic异常,导致消费位移读取失败,消费者无法定位消费位点,停止消费。
-
批量位移提交卡死:上批次消息位移提交失败、卡死,阻塞后续所有消费拉取请求。
4. 客户端参数与逻辑阻塞
-
超时参数配置极端:session.timeout.ms、heartbeat.interval.ms配置不合理,客户端频繁判定离线、持续重平衡,无法正常消费。
-
消费逻辑死锁阻塞:消费回调逻辑存在死锁、无限循环、同步阻塞请求,单条消息消费卡死,阻塞后续批量消费。
-
批量消费参数异常:批量拉取大小、超时参数配置过大,客户端长期等待批量消息,无消费输出。
5. 网络与集群链路异常
-
客户端网络不通:消费者服务器无法访问集群9092端口、内网链路拦截、端口防火墙限制,无法拉取消息。
-
监听器配置错误:集群advertised.listeners配置异常,客户端获取错误集群地址,连接失败、无法消费。
-
集群限流熔断:集群开启消费限流、分区熔断,当前消费组被限流,禁止拉取消息。
三、生产分步排查流程(快速定位根因)
-
核查集群与Topic状态:通过describe命令查看Topic分区、Leader、ISR状态,确认分区无离线、无同步异常。
-
校验消费组分配状态:查看消费组详情,确认当前实例是否分配到有效分区,排查实例空闲、分配为空问题。
-
核对订阅与权限配置:检查客户端Topic名称、消费组ID配置,核查ACL消费权限是否正常生效。
-
排查位移状态:查看消费组当前位移、滞后量,确认是否存在位移过期、越界、卡死问题,按需重置位移。
-
检查客户端日志:排查重平衡日志、权限报错、网络超时、逻辑阻塞报错,定位客户端异常。
-
校验网络连通性:测试客户端与集群端口连通性,核查监听器、防火墙、网络策略配置。
四、分级解决方案(紧急止血 + 根治优化)
1. 紧急止血(快速恢复消费)
-
修正错误的Topic、消费组配置,重启消费者实例,恢复正常订阅;
-
手动重置异常消费位移(earliest/latest),解除位移卡死阻塞;
-
临时减少消费实例数,保证实例数≤分区数,避免实例空闲;
-
放行网络端口、修复ACL权限,打通客户端与集群通信链路。
2. 短期根治(解决99%异常场景)
-
规范消费组使用:严格遵循「一个业务一个消费组」,禁止多业务共用消费组,杜绝分区分配冲突;
-
优化消费者参数:合理配置会话超时、心跳间隔、批量拉取参数,减少无效重平衡;开启静态消费组,避免频繁分区重分配;
-
优化消费代码逻辑:拆解阻塞式消费逻辑,添加超时控制、异步处理、异常兜底,杜绝业务死锁卡死消费链路;
-
完善权限管控:统一梳理集群ACL权限,保障消费组、客户端IP权限全覆盖,避免权限静默失效。
3. 长期规避规范
-
新增消费业务上线前,强制校验Topic订阅、消费组、分区分配、权限配置,做预发布校验;
-
新增消费TPS为0、消费停滞专项告警,提前感知消费中断问题;
-
规范分区与消费实例扩容逻辑,保证消费并发与分区数匹配,杜绝资源闲置;
-
统一封装消费者模板,内置异常重试、超时兜底、状态监控,避免自定义编码漏洞。
五、面试满分背诵总结
消费TPS为0、完全不消费的核心原因分为五大类:
一是订阅配置错误、消费组冲突、权限缺失导致订阅失效;
二是实例数大于分区数、分区状态异常导致无分区可消费;
三是消费位移过期、越界、卡死阻塞消费链路;
四是客户端参数不合理、业务逻辑阻塞死锁导致消费停滞;
五是网络、监听器配置异常导致通信失败。排查需优先校验分区分配、位移状态、订阅权限,
解决方案以修正配置、重置位移、优化参数、规范消费组使用为主,结合代码兜底与监控告警彻底规避消费中断问题。
简洁:
原因:Topic订阅错误、消费组冲突/混用、实例数超分区数空闲、分区无Leader/异常、位移越界卡死、权限不足、网络不通、消费逻辑阻塞死锁。
方案:修正订阅与消费组配置、匹配分区与消费实例数量、修复分区集群状态、重置异常位移、补齐ACL权限、优化网络与消费者参数、解耦阻塞消费逻辑。
9. 大消息问题(生产高频致命故障)
一、故障核心现象
-
生产者发送超时、同步发送大面积报错、消息推送失败,批量发送链路阻塞
-
Broker节点IO飙升、磁盘吞吐打满、单分区处理卡顿,集群整体性能降级
-
副本同步超时、ISR频繁收缩、分区临时下线,高可用机制失效
-
消费者拉取消息超时、消费阻塞、消费TPS骤降,海量消息堆积
-
极端场景触发Broker进程卡死、GC频繁、节点重启,引发全域业务抖动
-
日志出现
Message size too large超大消息拦截报错、网络缓冲区溢出报错
二、核心定义与阈值规范
大消息定义 :超过Kafka集群默认/自定义最大消息长度的消息,生产通用判定标准:单条消息大小 >1MB 视为大消息,>10MB 为超大危险消息,极易触发集群故障。
核心关联参数(全局联动)
-
message.max.bytes(Broker端):集群允许接收的单条消息最大字节数,全局管控,默认1048576(1MB) -
producer.max.request.size(生产者端):生产者单次请求最大发送大小,必须小于等于Broker阈值 -
fetch.max.bytes(消费者端):消费者单次拉取最大消息大小,过小会导致大消息无法消费、持续堆积 -
replica.fetch.max.bytes(副本同步端):Follower副本同步最大消息大小,过小将导致大消息同步失败、ISR收缩
三、底层故障根因(原理级拆解)
1. 网络传输层面阻塞
Kafka基于TCP批量传输,大消息会突破单次网络缓冲区上限,导致单次请求传输耗时剧增、网络链路阻塞,引发生产超时、重传失败;同时占用节点独享网络带宽,挤压正常小消息传输资源,造成全局吞吐下降。
2. 磁盘IO性能击穿
虽然Kafka是顺序写,但超大消息单次写入磁盘数据量巨大,会瞬间打满磁盘IOPS与吞吐,阻塞后续批量小消息的追加写入;同时日志分段、索引写入耗时大幅增加,触发日志归档卡顿,拖累全分区读写性能。
3. 副本同步机制失效
Follower副本同步大消息耗时远超常规超时阈值,同步过程极易超时中断,导致副本持续滞后、被踢出ISR集合,引发ISR收缩、分区单副本运行,彻底丧失高可用容错能力。
4. 客户端内存资源耗尽
生产者缓冲区、消费者拉取缓冲区需加载完整大消息,超大消息会占用大量客户端内存,导致缓冲区溢出、线程阻塞、频繁GC,严重时客户端进程OOM崩溃。
5. 集群参数不匹配触发拦截
若客户端与服务端消息阈值配置不统一,生产者发送超大消息会被Broker直接拦截丢弃,返回报错,业务侧出现静默丢数、发送失败问题。
四、生产全维度负面影响
-
集群性能雪崩:单条大消息拖垮整个分区、甚至单节点性能,引发批量消息堆积、吞吐暴跌
-
高可用降级:持续ISR收缩,分区长期单副本运行,节点故障直接丢数据
-
业务稳定性受损:消息发送失败、消费中断,核心业务流程卡顿、数据断层
-
运维排查困难:大消息故障无明显堆栈报错,仅表现为IO飙升、堆积增加,隐蔽性极强
五、分级解决方案(紧急止血 + 根治优化)
1. 紧急止血(5分钟快速恢复集群)
-
临时适配阈值:紧急统一调大Broker、生产者、消费者、副本同步四大消息大小参数,临时放行大消息,解除消息拦截、同步超时问题,快速恢复读写。
-
限流隔离流量:对存在大消息的热点Topic临时限流,避免持续超大流量冲击集群,防止故障扩散。
-
重启异常节点:重启IO卡死、同步异常的Broker节点,恢复副本同步链路,修复ISR状态。
2. 短期根治(业务层快速优化)
-
统一消息大小规范:生产强制约束单条业务消息 ≤1MB,杜绝超大消息写入,从源头规避故障。
-
大消息拆分处理:将超大报文、批量数据、文件报文拆分为多条小消息分片发送,消费端接收后合并组装,适配Kafka批量吞吐特性。
-
参数全局统一校准 :所有集群节点、客户端统一消息阈值参数,严格遵循
消费者阈值 ≥ 副本同步阈值 ≥ 生产者阈值 ≤ Broker阈值的配置原则,避免参数不匹配。
3. 长期架构最优方案(生产标准落地)
-
消息与文件分离架构(企业首选) :业务大文件、超大报文不直接投递Kafka,先上传至OSS、对象存储、文件服务器,Kafka仅传输文件链接、唯一标识、元数据信息,消费端通过链接拉取完整文件数据,彻底规避大消息痛点。
-
大消息独立Topic隔离:无法拆分的大消息单独创建专属Topic,独立配置更大的消息阈值、独立磁盘、独立集群,避免影响普通小消息业务集群。
-
前置拦截校验:生产者统一封装拦截器,发送前校验消息大小,超限直接拦截、告警、转入异常队列,禁止无效大消息入集群。
六、生产强制配置规范
-
常规业务集群默认统一消息阈值:1MB,所有业务严格适配
-
禁止随意调大全局消息阈值,特殊大消息业务单独Topic差异化配置
-
四大核心消息大小参数必须全局统一,禁止客户端与服务端配置不一致
-
新增业务上线前强制做消息大小校验,纳入预发布校验标准
七、面试满分背诵总结
Kafka大消息问题核心是单条消息过大引发网络传输超时、磁盘IO阻塞、副本同步失败、ISR收缩 ,直接导致集群吞吐下降、消息堆积、高可用降级。故障根源为四大核心参数不匹配、业务未拆分超大报文、无前置大小拦截。解决方案:紧急统一参数恢复集群;短期拆分大消息、规范消息大小;长期采用文件与消息分离架构,Kafka仅传元数据,同时隔离大消息业务Topic,从架构层面彻底根治大消息故障。
简洁速记版
现象:消息发送超时、IO飙升、副本同步超时、ISR收缩、消费堆积、节点卡顿。 原因:单条消息超集群阈值、四大消息参数不统一、超大报文阻塞IO与网络。 方案:统一全局参数、拆分大消息、前置拦截校验、大文件上传OSS仅传链接、独立Topic隔离部署。
6.3 冷门隐性坑点(生产高频隐形故障|面试加分专项)
本节汇总线上极易踩坑、文档极少提及、排查难度极高的Kafka隐性故障点,均为生产真实频发问题,涵盖底层机制、参数隐性失效、架构短板、运维隐形坑、业务适配陷阱,附带故障现象、根因、解决方案、速记总结,补齐普通手册缺失的高阶实战知识点。
1. 幽灵分区(残留分区元数据)
故障现象:Topic已执行删除命令,客户端、控制台查询无该Topic,但Broker节点日志持续报错、启动卡顿,集群元数据刷新异常,偶尔出现未知分区读写残留日志;新增同名Topic时分区错乱、数据异常。
核心根因 :Kafka删除Topic为异步逻辑删除,仅标记元数据删除,不会立即清理磁盘日志文件、节点元数据缓存;老旧版本ZK架构元数据残留严重,导致集群存在"幽灵分区",占用集群资源、干扰正常元数据调度。
解决方案
-
临时修复:手动进入各Broker日志目录,清理残留的废弃分区日志文件夹;ZK架构需手动清理ZK残留节点数据。
-
长效优化:配置
delete.topic.enable=true,开启自动清理;定期巡检磁盘残留日志,低版本集群手动规整元数据;禁止高频反复创建/删除同名Topic。
速记:删Topic仅标记不清理,元数据残留产生幽灵分区,清理磁盘与ZK元数据即可修复,规避高频删改同名Topic。
2. 集群节点时间不同步(隐形时序故障)
故障现象:无明显硬件、网络异常,但副本同步频繁超时、日志时间戳错乱、按时间回溯消费偏移异常、事务提交失败、消息清理策略失效,故障随机复现,排查无明确报错。
核心根因:Kafka强依赖节点时序一致性,副本同步心跳、日志索引生成、过期数据清理、事务超时判定均以节点时间为基准;集群节点时间差超过1s即会触发时序判定异常,时间偏差越大,故障越频繁。
解决方案
-
全集群节点强制开启NTP时间同步服务,配置开机自启、定时校准,保证所有节点时间偏差≤100ms。
-
新增集群巡检项,实时监控节点时间差,超时立即告警修复。
速记:时间不同步引发时序类隐形故障,全集群统一NTP时间同步,是生产必备基础规范。
3. PageCache失效 & SWAP开启性能雪崩
故障现象:集群磁盘IO正常、CPU负载不高,但生产/消费延迟飙升、吞吐断崖式下跌、副本同步卡顿,无任何业务报错,性能莫名降级。
核心根因 :Kafka核心高性能依赖OS PageCache页缓存,SWAP分区开启后,系统会将内存数据置换到磁盘,页缓存命中率大幅下降,顺序写、零拷贝机制完全失效,性能直接暴跌90%;同时引发内存抖动、GC频繁。
解决方案
-
生产集群所有节点永久关闭SWAP分区,写入fstab配置禁止开机自动挂载。
-
优化页缓存参数,调整内核
vm.dirty_ratio、vm.dirty_background_ratio,适配批量读写场景。
速记:SWAP是Kafka性能杀手,生产必须彻底关闭,保障PageCache高效命中。
4. 消费组脑裂(双实例同时消费、重复消费泛滥)
故障现象:同一消费组下多组消费者实例同时正常消费,无报错,业务出现海量重复数据、重复统计、重复下单,消费位移错乱。
核心根因
-
消费者心跳超时、会话超时参数配置过大,网络短暂抖动导致客户端判定离线失效;
-
新旧消费实例共存、静态/动态消费组混用,集群分区分配冲突;
-
跨网段消费、防火墙间断拦截心跳包,引发集群误判实例离线,触发双重分配。
解决方案
-
规范参数配置:
heartbeat.interval.ms为session.timeout.ms的1/3,适配网络波动; -
核心业务开启静态消费组,杜绝滚动发布引发的重分配与脑裂;
-
统一网段部署消费服务,放行集群心跳端口,屏蔽网络拦截。
速记:心跳超时、网络抖动、实例混用引发消费组脑裂,优化超时参数、开启静态消费组可根治。
5. 消息截断Truncation(隐形数据丢失)
故障现象:无报错、无ISR大面积收缩,但少量尾部消息莫名丢失,数据链路不完整,复盘发现分区尾部数据被截断。
核心根因 :分区Leader故障下线,ISR中滞后的Follower副本被选举为新Leader,新Leader数据版本落后于旧Leader;集群为保证副本数据一致性,会自动截断新旧Leader的差异数据,导致旧Leader尾部未同步消息永久丢失。
解决方案
-
生产强制关闭非ISR选主:
unclean.leader.election.enable=false,禁止滞后副本抢占Leader; -
合理配置
min.insync.replicas=2,保证至少2个同步副本,降低数据截断概率; -
监控分区水位线、副本滞后量,提前修复同步滞后节点。
速记:滞后副本选主触发消息截断,关闭非ISR选主、保障多副本同步可规避隐形丢数。
6. 批量攒批超时隐形堆积
故障现象:业务流量平稳、无报错、无大消息,但生产延迟持续走高,客户端缓冲区消息堆积,瞬时流量突发时吞吐跟不上。
核心根因 :生产者linger.ms攒批超时参数配置过大,低流量场景下,消息无法凑齐批量大小,长期等待攒批超时才发送,导致单条消息延迟堆积,低吞吐场景性能严重退化。
解决方案:高低吞吐业务差异化配置,高吞吐场景适当调大linger.ms,低延迟、低流量场景调小攒批超时,平衡吞吐与延迟。
7. 日志压缩策略失效(KV数据错乱)
故障现象:开启compact压缩策略的状态型Topic,重复Key数据未被清理,日志无限膨胀,查询Key数据错乱、新旧数据混杂。
核心根因 :日志压缩仅对已关闭的日志分段生效,活跃分段不会触发压缩;同时压缩线程优先级低、参数配置过小,高频更新Key的场景压缩跟不上写入速度。
解决方案:调大日志压缩线程数、缩短压缩周期;状态类Topic合理控制分段大小,避免长期存在超大活跃分段。
8. 空闲分区持续占用资源
故障现象:下线废弃Topic、长期零流量分区仍持续占用集群元数据、线程资源,导致集群元数据负载过高,新Topic创建、分区分配变慢。
核心根因:Kafka不会自动清理长期空闲、零流量的僵尸分区,元数据常驻内存,集群分区基数持续累积膨胀。
解决方案:定期巡检零流量、长期无消费的僵尸Topic,及时下线清理;控制集群总分区数量,避免元数据过载。
9. 跨机房监听地址错乱(隐形连接失败)
故障现象:内网访问正常,外网/跨机房/容器环境客户端偶尔连接失败、元数据路由异常,无规律报错。
核心根因 :listeners(内网监听)与advertised.listeners(外网暴露)配置混淆,容器环境IP动态变化、多网卡场景未精准配置对外地址,客户端获取错误的Broker地址,连接路由错乱。
解决方案:严格区分内外网监听配置,容器、跨机房场景强制配置advertised.listeners,固定对外访问地址。
10. 位移提交成功但消费重复(隐性位移bug)
故障现象:业务日志显示位移提交成功,无重平衡、无超时,但重启消费后大量重复消费。
核心根因 :异步位移提交存在提交成功回调丢失隐性bug,客户端显示提交成功,实际服务端未持久化位移,重启后重置为旧位点引发重复消费。
解决方案 :核心业务禁用异步提交,优先使用手动同步位移提交;消费成功、业务落库后再提交位移,兜底幂等校验。
第七部分 架构设计、混合架构、容灾
7.1 分区数规划原则(生产级完整落地版)
分区是 Kafka 并发、吞吐、负载均衡的最小核心单元,分区数规划不合理是线上堆积、负载倾斜、元数据卡顿、重平衡超时的首要诱因。以下为企业统一落地的分区规划标准,包含计算公式、阈值约束、场景适配、扩容规范、避坑细则,兼顾性能、稳定性、运维成本。
一、核心规划公式(生产必用)
1、消费并发上限公式
Topic 最大消费并行度 = Topic 分区总数
消费实例数 ≤ 分区数,超出实例永久空闲;分区数不足会直接锁死消费并发,引发消息堆积 。因此规划分区数必须满足:分区数 ≥ 业务所需最大消费实例数,预留30%~50%扩容冗余。
2、单分区吞吐阈值(黄金标准)
单分区稳定吞吐区间:1000~3000 TPS(普通报文)
高压缩小报文场景:单分区最高可支撑5000 TPS
超大报文、复杂业务场景:单分区建议控制在1000 TPS以内
分区数基础计算公式:分区数 = 业务峰值TPS ÷ 单分区安全TPS + 冗余分区数
二、全局上下限硬性阈值(生产强制约束)
1、单Broker分区上限(集群稳定底线)
-
常规生产集群:单Broker 承载分区总数 ≤ 1000
-
高配高性能集群(SSD、大内存):单Broker 上限 ≤ 2000
-
超限危害:元数据加载缓慢、集群Controller卡顿、Topic创建/扩容超时、重平衡耗时剧增、集群抖动频发
2、单Topic分区上下限
-
下限:核心业务Topic分区数 ≥ 4,避免并发过低、无法扩容
-
上限:普通业务单Topic ≤ 64分区;超大流量业务 ≤ 128分区
-
禁忌:禁止单Topic数百上千分区,极易引发集群元数据压力过载
三、分场景精细化规划标准
1、高吞吐日志/埋点场景(无严格有序)
业务特征:流量大、峰值高、允许无序、容错性高
规划策略:按峰值TPS计算分区数,单分区拉满3000~5000 TPS,预留50%流量冗余,优先保证吞吐能力,放宽有序性要求。
2、业务事件场景(订单/交易/状态变更)
业务特征:需要局部有序、可靠性高、流量平稳
规划策略:单分区控制1000~2000 TPS,分区数适配消费并发,通过Key哈希保证同业务有序落在同一分区,兼顾并发与有序性。
3、低频低吞吐场景(通知/日志/辅助业务)
业务特征:流量小、无并发压力、长期低负载
规划策略:无需过多分区,4~8分区即可满足需求,避免分区冗余占用集群元数据资源。
4、有序强依赖场景(全局有序)
业务特征:必须保证消息严格顺序消费
规划策略:单分区部署,牺牲并发换取全局有序;高流量有序业务需拆分Topic、拆分业务Key,实现分段有序。
四、分区扩容硬性规范(生产避坑核心)
-
分区只能新增、不能减少:分区创建后无法缩减,初始规划必须预留足够冗余,避免后期频繁扩容
-
扩容时机:消费堆积常态化、CPU/IO持续打满、消费实例无法扩容时,立即新增分区
-
扩容禁忌:禁止单次大批量扩容分区,避免瞬间元数据压力暴涨、集群抖动
-
扩容配套:分区扩容后需重新均衡Leader分布,防止节点负载倾斜
五、生产禁忌与常见坑点
-
禁止分区数过少:并发锁死、流量峰值极易堆积,无扩容空间
-
禁止分区数泛滥:集群总分区过多,元数据膨胀、Controller压力过载、集群稳定性下降
-
禁止分区数与消费实例数严重不匹配:实例过多空闲浪费,实例过少并发不足堆积
-
禁止热点Topic分区集中部署:需配合机架感知、分区重分配均匀打散
六、面试满分背诵总结
Kafka分区数规划核心围绕吞吐能力、消费并发、集群稳定性三大维度:分区数决定最大消费并行度,单分区安全TPS控制在1000~3000;单Broker分区不超2000,规避元数据压力;高吞吐场景按峰值流量算分区,有序场景单分区保障顺序;分区只增不减,预留流量冗余,同时匹配消费实例数量,避免负载倾斜与消息堆积,平衡集群性能与运维稳定性。
简洁速记版
分区数≥最大消费实例数;
单分区TPS1000-3000;单Broker分区≤2000;
有序业务用单分区,高吞吐多分区扩容;
分区只增不减,预留冗余,杜绝分区泛滥与并发瓶颈。
-
分区数 ≥ 消费实例最大并行度
-
单分区 TPS 控制在 1000~3000
-
单 Broker 分区建议上限:1000~2000,分区过多加重元数据压力。
7.2 副本部署规范
-
生产禁止单副本
-
副本跨机架/跨机房部署,防机架整体故障
-
主流副本数:2 / 3
7.3 企业通用分层架构
-
采集层:Filebeat/Fluentd 采集日志、埋点 → Kafka
-
总线层:Kafka 作为统一数据流转中心
-
计算层:Flink/Spark 实时计算、清洗、聚合
-
落地层:数据写入 MySQL / ES / 数据仓库、推送业务服务
7.4 混合中间件架构(Kafka + RocketMQ + RabbitMQ)生产完整版
在企业微服务与大数据混合架构中,Kafka、RocketMQ、RabbitMQ 三者并非替代关系,而是互补协同关系 。没有万能的中间件,企业生产均采用「三MQ混合部署、场景化分工」架构,兼顾高吞吐流式计算、核心交易高可靠、灵活路由适配三大核心诉求。本节完整拆解三者核心差异、精准选型场景、混合架构落地模型、业务协同流程与生产强制规范。
一、三大中间件核心维度横向对比(面试/架构必考)
| 对比维度 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 核心定位 | 分布式流式数据总线、高吞吐日志中间件 | 企业级可靠交易消息中间件 | 轻量灵活路由消息队列 |
| 吞吐能力 | 百万级TPS(三者天花板) | 十万级TPS(中高吞吐) | 万级TPS(低吞吐) |
| 消息可靠性 | 高(多副本、持久化),弱事务 | 极高(强事务、幂等、重试、死信) | 高(确认机制、持久化),事务薄弱 |
| 核心特性 | 分区并发、数据可回溯、流式联动、数据压缩 | 定时延时队列、事务消息、顺序消息、死信队列、消息重试 | 丰富Exchange路由、消息过滤、灵活绑定、轻量易用 |
| 消息语义 | 默认至少一次,支持事务实现精准一次 | 原生支持精准一次、事务消息、幂等投递 | 默认至少一次,无原生事务能力 |
| 有序性 | 单分区有序、跨分区无序 | 原生全局/分区有序,适配交易有序场景 | 单队列有序,无分布式有序能力 |
| 运维难度 | 高(分区、元数据、参数调优复杂) | 中(架构简洁、运维友好) | 低(部署简单、可视化完善) |
| 最佳适配场景 | 海量日志、用户埋点、大数据流式计算、数据同步 | 订单、支付、积分、交易、延时任务、核心业务 | 内部通知、简单异步、复杂路由、老旧系统对接 |
二、场景化精准选型规范(生产强制落地)
1. Kafka 专属场景(高吞吐、大数据、非核心流式业务)
-
海量数据采集场景:系统日志、Nginx访问日志、容器运行日志、用户行为埋点、IoT设备时序数据上报
-
大数据流转场景:对接Flink/Spark实时计算、数据仓库同步、数据中台全域数据总线
-
高并发流量削峰场景:电商大促、活动秒杀、瞬时海量流量缓冲兜底
-
数据同步场景:Canal Binlog数据中转、跨集群数据镜像、多源数据统一汇聚分发
严格禁用场景:核心金融交易、精准延时任务、强事务一致性、复杂消息路由业务
2. RocketMQ 专属场景(核心交易、高可靠、强一致性业务)
-
核心交易场景:电商订单创建、支付回调、退款、库存扣减、账单生成
-
延时/定时任务场景:订单超时取消、售后延时处理、定时通知、任务调度
-
强有序业务场景:订单状态变更、资金流水、账户变动等需严格顺序消费的业务
-
高可靠重试场景:短信补发、积分发放、业务重试、死信隔离治理
严格禁用场景:超海量日志采集、极低价值流式数据传输(运维成本高于收益)
3. RabbitMQ 专属场景(轻量、灵活路由、低吞吐异步业务)
-
复杂路由分发场景:多条件消息过滤、通配符路由、扇形广播、多分支消息分发
-
轻量异步通知场景:企业内部消息推送、邮件通知、系统告警、业务简单异步解耦
-
老旧系统适配场景:传统项目、老旧架构对接,无需高吞吐、追求稳定易用的场景
-
小流量广播场景:配置同步、集群通知、多服务统一消息推送
严格禁用场景:高并发海量流量、大数据流式计算、核心高可靠交易业务
三、企业标准混合架构落地模型
主流互联网/企业级架构统一采用「三队列分层协同架构」,实现业务分层、流量隔离、能力互补,彻底解决单一中间件能力短板。
1. 数据层:Kafka 承载全域流式数据
统一承接企业所有非交易类海量数据,作为全域数据总线,向下对接大数据计算、监控告警、数据统计系统,不参与核心业务交易链路,保障高吞吐、低成本流转。
2. 业务核心层:RocketMQ 承载交易核心数据
独立部署核心集群,承载所有支付、订单、资金、库存等核心交易消息,依靠事务、重试、死信、有序机制保障业务绝对可靠,支撑核心营收业务稳定运行。
3. 辅助业务层:RabbitMQ 承载轻量异步数据
部署轻量集群,承接非核心、低吞吐、需要复杂路由的辅助业务,轻量化解耦,降低核心中间件集群压力。
四、混合架构核心协同流程(生产真实链路)
电商完整业务链路示例:
-
用户下单,核心交易链路通过 RocketMQ 投递订单消息,保障订单可靠生成、状态有序变更、超时自动取消;
-
订单支付完成后,异步触发积分、优惠券、通知消息,通过 RabbitMQ 灵活路由分发至各通知服务;
-
用户点击、浏览、下单行为埋点、服务运行日志、接口访问记录全部推送至 Kafka;
-
Kafka 流转数据至Flink实时计算,完成UV/PV统计、用户画像、运营数据分析、故障日志告警;
-
三类中间件集群物理隔离、流量互不干扰,各司其职保障全域业务稳定。
五、混合架构生产强制规范(避坑核心)
-
集群物理隔离:三者必须独立部署集群、独立服务器/容器、独立磁盘网络,禁止混部,避免高吞吐流量冲击核心交易集群。
-
业务严格边界:禁止跨场景乱用,杜绝用RocketMQ传海量日志、用Kafka做订单交易、用RabbitMQ承载高并发流量。
-
统一消息规范:三类中间件统一消息协议(JSON/Protobuf)、命名规范、超时重试策略、监控告警体系,降低运维与开发成本。
-
流量分层隔离:核心交易流量、辅助异步流量、海量流式流量完全隔离,避免故障扩散。
-
运维权限分级:RocketMQ核心集群权限收紧,仅核心运维可操作;Kafka、RabbitMQ开放常规运维权限,适配不同运维场景。
六、面试满分背诵总结
企业混合MQ架构核心是场景互补、各司其职、分层隔离。Kafka主打高吞吐、大数据流式数据传输,适配日志、埋点、数据同步场景;RocketMQ主打高可靠、强事务、有序、延时能力,承载订单支付等核心交易业务;RabbitMQ主打灵活路由、轻量易用,适配内部通知、简单异步解耦场景。生产中三者物理隔离、业务分层、统一规范,规避单一中间件短板,兼顾系统性能、可靠性与灵活性,是企业标准分布式消息架构。
简洁速记版
Kafka扛海量流式数据、RocketMQ保核心交易可靠、RabbitMQ做轻量路由解耦;三集群隔离部署、场景严格拆分、能力互补,构成企业标准混合消息架构。
分工原则(场景化选型)
-
Kafka:日志、埋点、大数据流式、高吞吐非核心业务
-
RocketMQ:订单、支付、事务、延时、死信、核心高可靠交易业务
-
RabbitMQ:复杂路由、老旧系统对接、低吞吐内部通知
7.5 容灾与多活架构
-
节点级容灾:多副本、自动选主
-
机房级容灾:同城双机房 + MirrorMaker 同步
-
城市级容灾:异地多活、跨城镜像、流量调度
7.6 云原生 & 托管服务
-
K8s 部署:StatefulSet、PV 持久化、资源配额、优雅启停
-
云厂商托管 Kafka:阿里云 CKafka、腾讯云 CKafka,免运维集群。
第八部分 客户端实战(Java + Spring-Kafka)
8.1 原生 Java 客户端(生产级完整实战)
原生Java客户端是Kafka官方标准客户端,无框架封装、底层可控、参数透明,是Spring-Kafka底层依赖核心,适合精细化参数调优、高阶特性使用(幂等/事务)、高性能自定义开发场景。本节提供全套可直接复制上线的代码、配置、避坑规范,覆盖生产所有主流用法。
1. 核心Maven依赖(生产稳定版)
统一选用与集群适配的客户端版本,客户端版本≥服务端版本保证特性兼容,推荐2.8.x/3.x稳定版
XML
<!-- Kafka 原生Java客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.2</version>
</dependency>2. 公共基础配置(生产通用)
抽取全局公共配置,统一序列化、超时、重试、网络参数,避免代码冗余,适配生产高可用场景
java
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Properties;
/**
* Kafka原生客户端公共配置工具类
* 生产统一规范,所有生产者/消费者复用
*/
public class KafkaCommonConfig {
// 集群地址,生产配置多节点逗号分隔,避免单节点单点故障
public static final String BOOTSTRAP_SERVERS = "127.0.0.1:9092,127.0.0.2:9092";
/**
* 获取公共客户端基础配置
*/
public static Properties getCommonProps() {
Properties props = new Properties();
// 集群节点地址
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 超时配置:客户端请求超时(生产建议30s)
props.put(CommonClientConfigs.REQUEST_TIMEOUT_MS_CONFIG, 30000);
// 元数据拉取超时
props.put(CommonClientConfigs.METADATA_FETCH_TIMEOUT_MS_CONFIG, 10000);
// 失败重试次数 + 重试间隔
props.put(CommonClientConfigs.RETRIES_CONFIG, 3);
props.put(CommonClientConfigs.RETRY_BACKOFF_MS_CONFIG, 1000);
return props;
}
/**
* 字符串序列化器(通用文本消息)
*/
public static Properties getStringSerdeProps() {
Properties props = getCommonProps();
props.put(CommonClientConfigs.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(CommonClientConfigs.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(CommonClientConfigs.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(CommonClientConfigs.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
return props;
}
}3. 生产者实战(同步/异步/回调/幂等/事务)
3.1 基础异步生产者(生产主流高吞吐方案)
异步发送+回调监听,不阻塞业务线程,适配高吞吐场景,可捕获发送异常、消息回溯
java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* 基础异步生产者(生产高吞吐首选)
* 特性:非阻塞、回调确认、异常捕获、批量攒批
*/
public class KafkaAsyncProducer {
public static Producer<String, String> createProducer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
// 生产者批量大小:16KB,适配中小流量批量攒批
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 攒批超时:5ms,平衡吞吐与延迟
props.put(ProducerConfig.LINGER_MS_CONFIG, 5);
// 数据压缩:LZ4,高压缩率、低CPU开销
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4");
// 缓冲区内存:64MB
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 67108864);
// acks配置:1 平衡吞吐与可靠性,日志/埋点场景首选
props.put(ProducerConfig.ACKS_CONFIG, "1");
return new KafkaProducer<>(props);
}
/**
* 异步发送消息 + 回调监听
*/
public static void asyncSend(Producer<String, String> producer, String topic, String key, String value) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 异步发送,回调监听结果
producer.send(record, (RecordMetadata metadata, Exception exception) -> {
if (exception != null) {
// 生产异常兜底:日志告警、落地异常队列、手动重试
exception.printStackTrace();
} else {
// 发送成功:记录点位,用于数据溯源
System.out.printf("消息发送成功,分区:%d,偏移量:%d%n", metadata.partition(), metadata.offset());
}
});
}
public static void main(String[] args) {
Producer<String, String> producer = createProducer();
// 模拟业务消息发送
asyncSend(producer, "test_topic", "user_1001", "用户行为埋点数据");
// 优雅刷新缓冲区,确保消息全部发送
producer.flush();
// 优雅关闭
producer.close();
}
}3.2 同步生产者(高可靠业务场景)
同步发送阻塞线程,等待ACK确认,适合订单、交易等需要强发送确认的核心业务
java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
/**
* 同步生产者(核心高可靠业务专用)
* 阻塞等待发送结果,确保消息落地成功再执行业务后续逻辑
*/
public class KafkaSyncProducer {
public static Producer<String, String> createProducer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
// 核心业务acks=all,等待所有ISR副本同步完成,极致可靠
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 无限重试,规避临时网络抖动丢数
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
return new KafkaProducer<>(props);
}
/**
* 同步发送消息
*/
public static boolean syncSend(Producer<String, String> producer, String topic, String key, String value) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
try {
// 阻塞等待发送结果
RecordMetadata metadata = producer.send(record).get();
System.out.printf("同步发送成功,分区:%d,偏移量:%d%n", metadata.partition(), metadata.offset());
return true;
} catch (InterruptedException | ExecutionException e) {
// 核心业务异常兜底:告警、事务回滚、消息落盘重试
e.printStackTrace();
return false;
}
}
public static void main(String[] args) {
Producer<String, String> producer = createProducer();
syncSend(producer, "order_topic", "order_20260601", "订单创建消息数据");
producer.flush();
producer.close();
}
}3.3 幂等生产者(解决重复发送问题)
原生幂等生产者,自动去重,解决网络重试、客户端重发导致的消息重复投递问题,生产常规业务必开
java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.Properties;
/**
* 幂等生产者(生产通用必开)
* 自动解决单会话消息重复发送问题,无需业务手动去重
*/
public class KafkaIdempotentProducer {
public static Producer<String, String> createIdempotentProducer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
// 开启幂等模式(核心配置)
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 幂等必须配合acks=all、无限重试
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
// 有序重试,避免消息乱序
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);
return new KafkaProducer<>(props);
}
}3.4 事务生产者(实现Exactly Once)
支持跨分区、跨Topic原子发送,结合幂等特性实现精准一次投递,适合数据同步、流式计算一致性场景
java
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 事务生产者(Exactly Once精准一次)
* 适用于数据同步、流式计算、需要原子发送的业务
*/
public class KafkaTransactionProducer {
public static Producer<String, String> createTransactionProducer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
// 开启幂等
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// 唯一事务ID(集群全局唯一)
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction-producer-001");
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);
return new KafkaProducer<>(props);
}
/**
* 事务批量发送:要么全部成功,要么全部回滚
*/
public static void transactionSend(Producer<String, String> producer) {
// 初始化事务
producer.initTransactions();
try {
// 开启事务
producer.beginTransaction();
// 批量发送多条消息(跨分区/跨Topic均可)
producer.send(new ProducerRecord<>("order_topic", "order_001", "订单数据"));
producer.send(new ProducerRecord<>("pay_topic", "pay_001", "支付数据"));
// 提交事务
producer.commitTransaction();
} catch (Exception e) {
// 异常回滚事务
producer.abortTransaction();
e.printStackTrace();
}
}
public static void main(String[] args) {
Producer<String, String> producer = createTransactionProducer();
transactionSend(producer);
producer.flush();
producer.close();
}
}4. 消费者实战(自动/手动提交、批量消费)
4.1 基础自动提交消费者(低可靠简单场景)
自动定时提交位移,代码简洁,适合日志、监控等允许少量重复消费的非核心业务
java
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 自动提交消费者(简单低可靠场景)
* 无需手动管理位移,定时自动提交,开发成本低
*/
public class KafkaAutoCommitConsumer {
public static Consumer<String, String> createConsumer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
// 消费组ID(业务唯一)
props.put(ConsumerConfig.GROUP_ID_CONFIG, "auto-consumer-group-01");
// 开启自动位移提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 自动提交间隔:500ms
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 500);
// 初始无位移时,消费最早消息
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 会话超时、心跳间隔(减少重平衡)
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 3000);
return new KafkaConsumer<>(props);
}
public static void main(String[] args) {
Consumer<String, String> consumer = createConsumer();
// 订阅Topic
consumer.subscribe(Collections.singletonList("test_topic"));
// 循环拉取消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> {
System.out.printf("消费消息:key=%s, value=%s, 分区=%d, 偏移量=%d%n",
record.key(), record.value(), record.partition(), record.offset());
});
}
}
}4.2 手动同步提交消费者(生产核心必备)
业务处理成功后手动提交位移,彻底杜绝业务未执行完但位移已提交导致的数据丢失,核心业务强制使用
java
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 手动同步提交消费者(生产核心业务首选)
* 业务处理成功后再提交位移,杜绝数据丢失
*/
public class KafkaManualSyncConsumer {
public static Consumer<String, String> createConsumer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
props.put(ConsumerConfig.GROUP_ID_CONFIG, "manual-consumer-group-01");
// 关闭自动提交,手动管控位移
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 3000);
return new KafkaConsumer<>(props);
}
public static void main(String[] args) {
Consumer<String, String> consumer = createConsumer();
consumer.subscribe(Collections.singletonList("order_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
records.forEach(record -> {
// 执行业务核心逻辑
handleBusiness(record.key(), record.value());
});
// 所有消息处理完成后,手动同步提交位移
consumer.commitSync();
}
}
}
/**
* 模拟业务处理逻辑
*/
private static void handleBusiness(String key, String value) {
System.out.printf("核心业务处理:key=%s, value=%s%n", key, value);
}
}4.3 批量消费消费者(高吞吐优化)
单次拉取批量消息,减少网络IO次数,大幅提升高吞吐场景消费性能,适配日志、埋点海量数据消费
java
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 批量消费消费者(高吞吐场景优化)
* 批量拉取、批量处理、批量提交,减少网络IO开销
*/
public class KafkaBatchConsumer {
public static Consumer<String, String> createConsumer() {
Properties props = KafkaCommonConfig.getStringSerdeProps();
props.put(ConsumerConfig.GROUP_ID_CONFIG, "batch-consumer-group-01");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 单次最大拉取条数
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
// 拉取超时时间
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, 500);
return new KafkaConsumer<>(props);
}
public static void main(String[] args) {
Consumer<String, String> consumer = createConsumer();
consumer.subscribe(Collections.singletonList("log_topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
// 批量处理消息
batchHandle(records);
// 批量提交位移
consumer.commitSync();
}
}
}
private static void batchHandle(ConsumerRecords<String, String> records) {
records.forEach(record ->
System.out.printf("批量消费:分区=%d, 偏移量=%d%n", record.partition(), record.offset())
);
}
}5. 生产级通用封装规范
5.1 统一封装核心能力
-
统一序列化:生产优先使用Protobuf/Avro序列化,替代String序列化,压缩率更高、传输更快、格式更规范
-
全局异常兜底:生产者回调、消费者业务异常统一捕获,接入告警系统,避免静默失败
-
优雅启停 :服务下线时调用
close()关闭客户端,刷新缓冲区、提交最终位移,避免消息丢失/重复 -
参数环境隔离:集群地址、消费组、超时参数通过配置文件注入,区分开发/测试/生产环境
5.2 生产强制参数规范
-
核心业务:开启幂等+事务+acks=all+手动同步位移提交,保障数据精准一致
-
高吞吐业务:开启异步发送+数据压缩+批量攒批+批量消费,极致提升吞吐
-
所有生产消费者:关闭自动位移提交,杜绝数据丢失隐患
-
统一配置会话超时、心跳间隔,减少不必要的重平衡
6. 原生客户端优缺点(面试/选型考点)
优点
-
无框架封装损耗,底层参数完全可控,适配所有高阶特性
-
版本迭代同步社区,新特性优先支持,无功能阉割
-
轻量无依赖,性能稳定,适合高性能、高可靠定制化场景
缺点
-
原生API偏底层,开发代码量大,需要手动封装重试、异常、位移逻辑
-
无内置死信、重试机制,需要业务自行实现
-
不支持注解开发,日常快速开发效率低于Spring-Kafka
7. 面试满分总结
原生Java客户端是Kafka官方标准客户端,支持同步/异步、幂等、事务全能力。生产选型规范:高吞吐日志埋点场景使用异步发送+批量压缩 ;核心交易场景使用同步发送+手动位移提交+幂等事务;所有核心业务禁止自动位移提交,通过手动提交保障数据不丢不重。原生客户端底层可控、无封装损耗,适合精细化调优与高阶特性开发,是Spring-Kafka的底层基础。
简洁:
-
Maven 依赖引入
-
基础生产者:同步、异步、带回调
-
幂等生产者、事务生产者实现
-
基础消费者:自动提交、手动提交、批量消费
-
生产级封装:统一异常、序列化、优雅停机、动态配置。
8.2 Spring-Kafka 框架(开发主流)
Spring-Kafka 是 Spring 生态基于 Kafka 原生 Java 客户端的轻量化封装框架 ,完全兼容原生所有底层特性,屏蔽了繁琐的原生API初始化、参数配置、资源关闭逻辑,提供注解式开发、自动配置、内置重试、死信队列、优雅停机、异常统一处理等能力,是目前 SpringBoot/SpringCloud 微服务项目的绝对主流选型,兼顾开发效率与生产稳定性。
1. 核心依赖与版本适配规范
版本严格遵循版本适配原则:Spring-Kafka 版本、SpringBoot 版本、Kafka 客户端版本、服务端版本必须兼容,避免特性缺失、连接报错、参数不生效问题。
XML
<!-- SpringBoot 整合Kafka核心依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.9.10</version>
</dependency>版本选型规范:
-
SpringBoot 2.x:适配 Spring-Kafka 2.x 版本,兼容 Kafka 2.x/3.x 服务端
-
SpringBoot 3.x:必须使用 Spring-Kafka 3.x 版本,适配新版特性
-
统一规则:客户端版本 ≥ 服务端版本,保证向下兼容,新特性正常使用
2. 核心核心组件(必懂)
-
KafkaTemplate:生产者核心操作类,封装同步/异步发送、消息回调、事务发送,替代原生 Producer,开箱即用,支持泛型消息发送
-
@KafkaListener:消费者核心注解,实现订阅Topic、监听消息、业务消费,支持单条消费、批量消费、指定消费组、指定分区监听
-
ConcurrentKafkaListenerContainerFactory:消费者容器工厂,核心配置入口,定义消费并发数、批量消费、重试策略、异常处理器、死信绑定
-
KafkaTransactionManager:Spring 事务管理器,适配 Kafka 原生事务,支持 Spring 声明式事务,实现跨消息精准一次投递
-
DeadLetterPublishingRecoverer:死信消息处理器,内置异常消息拦截、转发死信Topic能力,无需手动封装
3. 生产级完整配置(application.yml)
整合高可靠、高吞吐、异常兜底、批量消费全套参数,区分核心业务与普通业务,可直接线上复用
XML
spring:
kafka:
# 集群地址,多节点逗号分隔
bootstrap-servers: 127.0.0.1:9092,127.0.0.2:9092
# 生产者全局配置
producer:
# 序列化器
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 核心业务可靠配置
acks: all
# 开启幂等,防止重复发送
properties:
enable.idempotence: true
# 无限重试,规避临时网络抖动
retries: 3
# 单连接单批次请求数,保证有序重试
max.in.flight.requests.per.connection: 1
# 批量攒批大小、超时时间,平衡吞吐与延迟
batch-size: 16384
linger-ms: 5
# LZ4压缩,低CPU高压缩率
compression-type: lz4
# 消费者全局配置
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 初始无位移时消费最早消息
auto-offset-reset: earliest
# 关闭自动提交,生产强制手动提交,杜绝丢数
enable-auto-commit: false
# 单次最大拉取消息数(批量消费核心)
max-poll-records: 500
# 会话超时、心跳间隔,减少重平衡
session-timeout-ms: 10000
heartbeat-interval-ms: 3000
# 监听容器全局配置
listener:
# 手动提交模式
ack-mode: manual_immediate
# 消费超时时间
poll-timeout: 100
# 优雅停机:服务关闭时等待消费完成
close-timeout: 300004. 生产者实战(KafkaTemplate)
4.1 基础异步发送(主流高吞吐)
默认异步发送,非阻塞业务线程,搭配回调监听发送结果,适配日志、埋点等高吞吐场景
java
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import javax.annotation.Resource;
@Service
public class KafkaProducerService {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 异步发送消息(高吞吐首选)
*/
public void asyncSend(String topic, String key, String value) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, key, value);
// 回调监听发送结果
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
// 发送成功日志记录,用于溯源
System.out.println("消息发送成功,分区:" + result.getRecordMetadata().partition()
+ ",偏移量:" + result.getRecordMetadata().offset());
}
@Override
public void onFailure(Throwable ex) {
// 异常兜底:日志告警、落盘重试、推送监控
ex.printStackTrace();
}
});
}
}4.2 同步发送(核心交易业务)
阻塞等待发送结果,确保消息落地成功再执行业务后续逻辑,适配订单、支付、库存等核心高可靠场景
java
public boolean syncSend(String topic, String key, String value) {
try {
// 同步阻塞获取发送结果
kafkaTemplate.send(topic, key, value).get();
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}4.3 事务发送(Exactly Once 精准一次)
整合Spring声明式事务,实现跨Topic、跨消息原子发送,适配数据同步、流式计算一致性场景
java
import org.springframework.transaction.annotation.Transactional;
@Transactional(rollbackFor = Exception.class)
public void transactionSend() {
// 多条消息原子发送,要么全部成功,要么全部回滚
kafkaTemplate.send("order_topic", "order_001", "订单创建数据");
kafkaTemplate.send("pay_topic", "pay_001", "支付流水数据");
}5. 消费者实战(@KafkaListener 核心)
5.1 单条消费+手动提交(核心业务必备)
逐条消费、业务处理完成后手动提交位移,彻底杜绝数据丢失,生产核心业务强制使用
java
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
/**
* 单条消费、手动提交、高可靠模式
* @param record 消息记录
* @param ack 位移提交对象
*/
@KafkaListener(topics = "order_topic", groupId = "order-consumer-group")
public void consumeSingle(ConsumerRecord<String, String> record, Acknowledgment ack) {
try {
// 执行业务核心逻辑
String key = record.key();
String value = record.value();
handleBusiness(key, value);
// 业务处理成功,手动提交位移
ack.acknowledge();
} catch (Exception e) {
// 异常兜底:重试、死信转发、告警
e.printStackTrace();
}
}
private void handleBusiness(String key, String value) {
// 自定义业务处理逻辑
}
}5.2 批量消费(高吞吐场景优化)
批量拉取、批量处理、批量提交,大幅减少网络IO次数,适配日志、埋点、海量数据消费场景,提升消费吞吐量3-5倍
java
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Service;
@Service
public class KafkaBatchConsumerService {
/**
* 批量消费监听
* containerFactory 指定批量消费工厂
*/
@KafkaListener(topics = "log_topic", groupId = "log-consumer-group", containerFactory = "batchFactory")
public void consumeBatch(ConsumerRecords<String, String> records, Acknowledgment ack) {
try {
// 批量处理消息
records.forEach(record -> {
// 单条消息处理逻辑
});
// 批量提交位移
ack.acknowledge();
} catch (Exception e) {
e.printStackTrace();
}
}
}5.3 批量消费容器工厂配置
自定义批量消费、并发参数,适配高吞吐业务,统一全局消费规则
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
@Configuration
public class KafkaConsumerConfig {
/**
* 批量消费容器工厂
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> batchFactory(ConsumerFactory<String, String> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// 开启批量消费
factory.setBatchListener(true);
// 设置消费并发数,根据分区数调整(不超过分区总数)
factory.setConcurrency(8);
// 关闭即时启动,适配优雅启停
factory.setAutoStartup(true);
return factory;
}
}6. 核心高阶能力(生产必备)
6.1 消费并发控制(concurrency 参数)
-
作用 :
concurrency代表单实例消费线程数,控制单机消费并发能力 -
核心规则:单实例 concurrency 总数 + 集群实例数 ≤ Topic 分区总数,超出部分线程空闲,无法提升并发
-
生产配置:根据分区数合理设置,避免并发不足导致堆积、并发过高导致频繁重平衡
6.2 内置重试机制
Spring-Kafka 内置消费重试机制,无需手动实现重试逻辑,支持自定义重试次数、间隔、异常类型
java
@Bean
public Retry retry() {
// 最大重试3次,间隔1s
return RetryBuilder.maxAttempts(3).fixedBackoff(1000).build();
}6.3 死信队列 DLT 自动转发
消费重试失败的异常消息,自动转发至死信Topic,避免异常消息阻塞消费链路,实现异常消息隔离治理
java
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> dltFactory(ConsumerFactory<String, String> consumerFactory, KafkaTemplate<String, String> kafkaTemplate) {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// 重试失败消息转发死信队列
factory.setRecovery(new DeadLetterPublishingRecoverer(kafkaTemplate));
return factory;
}6.4 优雅停机机制
框架内置优雅停机能力,服务重启、发布、下线时,会等待当前批次消息消费完成、位移提交完毕后再关闭容器,彻底避免重启导致的消息重复消费、丢失问题
7. 生产避坑核心规范
-
禁止自动位移提交:所有生产消费者必须关闭自动提交,手动提交位移,杜绝业务异常导致的数据丢失
-
并发匹配分区数:消费并发数、实例数严格匹配分区数,避免并发瓶颈或线程空闲浪费
-
核心业务必开幂等:生产环境统一开启生产者幂等,解决网络重试导致的消息重复问题
-
异常消息必进死信:禁止异常消息无限重试阻塞队列,必须配置死信隔离,人工复盘兜底
-
禁止跨业务共用消费组:不同业务严格拆分消费组,避免分区分配错乱、消费异常
-
批量消费适配场景:有序业务禁止使用批量消费,防止消息顺序错乱
8. 面试高频考点总结
-
Spring-Kafka 核心组件及各自作用?KafkaTemplate、@KafkaListener、容器工厂的核心职责?
-
concurrency 参数原理?消费并发与分区数的关系?
-
手动提交与自动提交的区别?生产为什么禁止自动提交?
-
内置重试、死信队列的实现原理与生产落地规范?
-
Spring-Kafka 事务实现方式,如何达成 Exactly Once?
-
优雅停机的作用,如何避免发布重启重复消费?
9. 框架优缺点总结
优点:注解式开发效率高、自动配置开箱即用、内置重试/死信/优雅停机、完美适配Spring生态、底层兼容原生所有特性、大幅减少重复编码。
缺点:轻度封装存在少量底层屏蔽、极致高性能场景不如原生客户端灵活、高阶定制需要手动覆盖默认配置。
生产选型结论:95%的微服务业务优先使用 Spring-Kafka;超高吞吐、极致定制、底层深度调优场景选用原生Java客户端。
简洁:
-
核心组件:
KafkaTemplate、@KafkaListener -
注解使用:批量监听、异常处理器、容器工厂
-
concurrency参数:对应启动消费线程数/实例数 -
内置重试、死信队列 DLT,开箱即用。
8.3 跨语言开发补充
-
librdkafka:高性能 C 底层库,性能优于 Java 客户端,注意内存泄漏问题。
-
多语言序列化:优先 Avro / Protobuf,保证格式统一。
第九部分 生态工具汇总
9.1 日志采集
Filebeat、Fluentd、Fluent Bit、Logstash
9.2 流计算框架
Kafka Streams、Apache Flink、Spark Streaming
9.3 可视化运维工具
Kafka Manager、Kafka Eagle、Kafdrop、Confluent Control Center
9.4 数据同步
Canal(MySQL Binlog 同步)、MirrorMaker(跨集群同步)
第十部分 面试高频考点(背诵版)
1. 基础概念
-
分区、副本、消费组各自作用?分区与并发的关系?
-
Leader / Follower / ISR 机制原理?
-
HW 水位线作用?
-
Kafka 为什么性能极高?(顺序写、零拷贝、页缓存、批量、压缩)
2. 可靠性与消息语义
-
acks 三个取值区别与使用场景?
-
三种消息投递语义?默认是哪一种?
-
消息丢失场景与解决方案?
-
重复消费原因?如何解决?
-
如何实现 Exactly Once?
3. Rebalance 专题
-
Rebalance 触发条件、危害、优化方案?
-
三种分区分配策略区别?
-
静态消费组作用?
4. 存储与日志
-
日志分段、索引机制?
-
两种日志清理策略及适用场景?
-
零拷贝原理?
5. 高阶特性
-
幂等生产者、事务的作用与限制?
-
Kafka 如何实现延迟队列、死信队列?
-
KRaft 对比 ZK 架构优势?迁移方案?
6. 调优与故障
-
消息堆积如何排查与解决?
-
副本同步滞后原因?
-
分区数如何规划?分区过多有什么问题?
7. 架构选型
Kafka / RocketMQ / RabbitMQ 三者区别、选型场景。
完整学习路线图(按顺序学习)
-
基础概念 → 环境搭建 → 控制台命令
-
生产者全流程、参数、分区、压缩、拦截器
-
消费者全流程、位移、重平衡、分区分配
-
分区、副本、ISR、HW、高可用底层原理
-
磁盘存储、日志分段、索引、清理机制
-
消息语义、幂等、事务、Exactly Once
-
运维、监控、压测、容量规划
-
线上故障排查、隐性坑点
-
Java 原生客户端 + Spring-Kafka 实战开发
-
架构设计、混合架构、容灾、云原生
-
安全体系、生态组件
-
源码阅读 + 面试刷题