第一部分 基础原理
一、行数据转 Key-Value 规则
TiDB SQL 层可将表行数据,转换为底层 KV 引擎(TiKV)可识别的键值对。
- Key 拼接规则
表前缀 + 全局表编号 + 行前缀 + 表内唯一行号 - 示例 表前缀:
t,表 ID:10,行前缀:r,行号:1最终 Key:t10_r1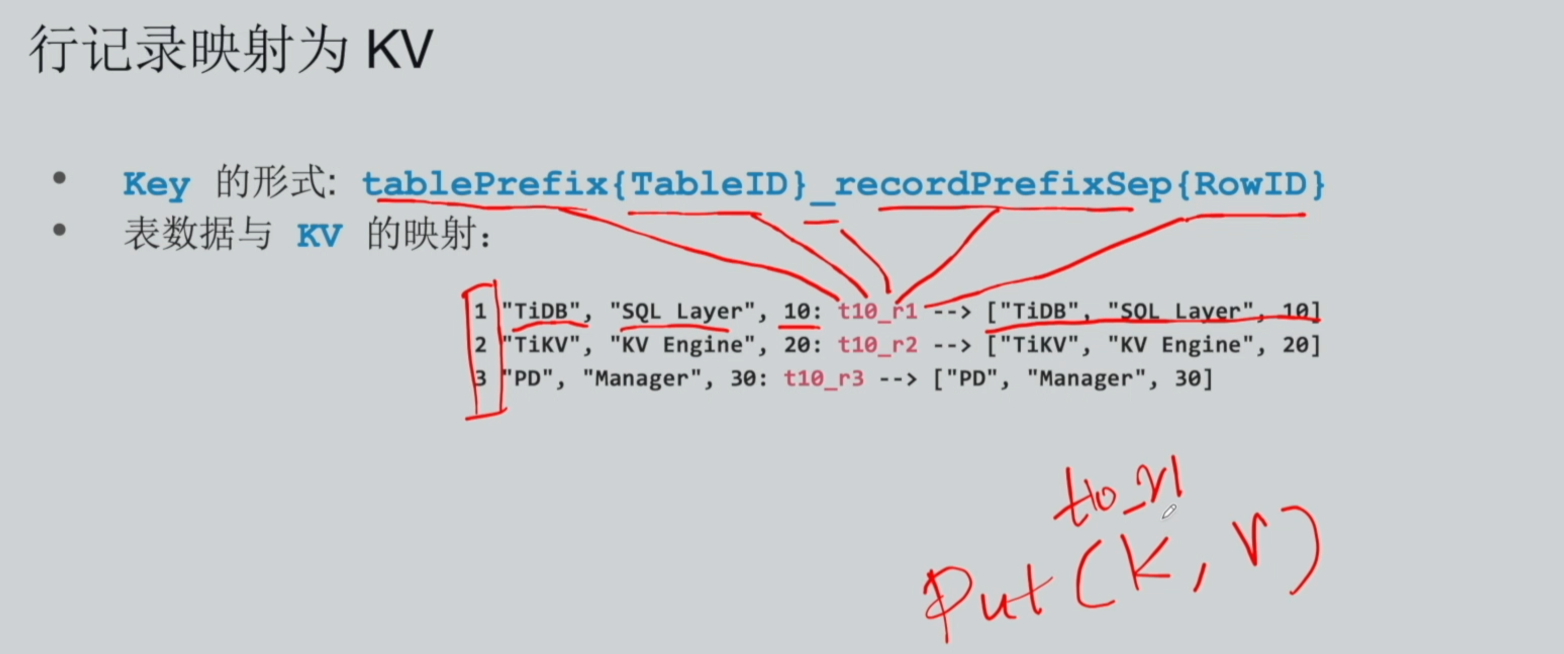
- 转换逻辑 原始行数据作为 Value ,拼接字符串作为 Key ,通过 KV API 写入底层存储。

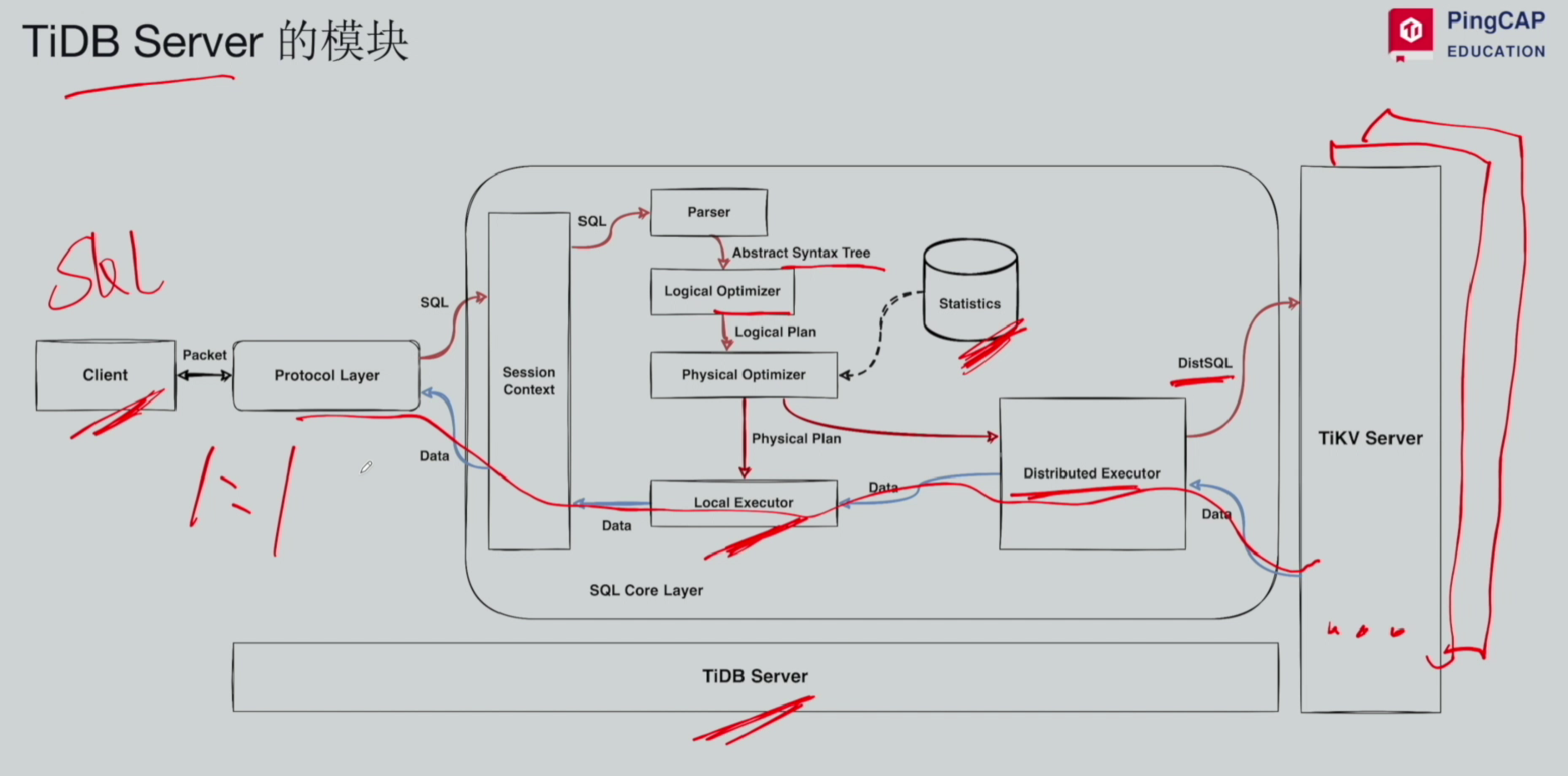
二、TiDB Server 模块 & SQL 执行全流程
客户端与 TiDB Server 为1:1 连接,同一客户端同一时间仅连接单台 TiDB Server。完整执行链路:
- **会话上下文(Session Context)**客户端建立网络连接,完成身份鉴权,分配专属会话承接请求。
- **解析器(Parser)**解析 SQL 语法,生成逻辑树,识别操作对象与操作类型。
- 逻辑优化器 依据通用规则改写 SQL,剔除冗余逻辑,输出逻辑执行计划。
- 物理优化器 读取表统计信息(行数、单行长度、数据分布等),结合实际数据生成最优物理执行计划。
- 执行器(Executor)
- 本地执行:任务在当前连接的 TiDB Server 上运行
- 分布式执行:指令下发至 TiKV 集群,多节点并行计算
- 数据回传 TiKV 执行完毕后,数据原路返回,最终推送至客户端。
三、TiDB Server 宕机处理逻辑
核心特性
TiDB Server 为无状态(Stateless) 服务,不存储任何业务数据:
- 业务数据:持久化在 TiKV 集群
- 集群元数据 / 调度数据:存储在 PD 组件
故障应对
- 单台节点宕机客户端重新连接其他正常 TiDB 节点,重试失败 SQL,业务无异常、数据不丢失。
- 多台 / 全部节点宕机重启或新增 TiDB 节点后,客户端重连重试即可恢复。
生产优化
客户端与 TiDB 集群之间部署 负载均衡 / 代理(Proxy、F5 等),自动实现故障转发与节点调度,提升稳定性。
第二部分 节点宕机实操演示
一、测试环境与脚本说明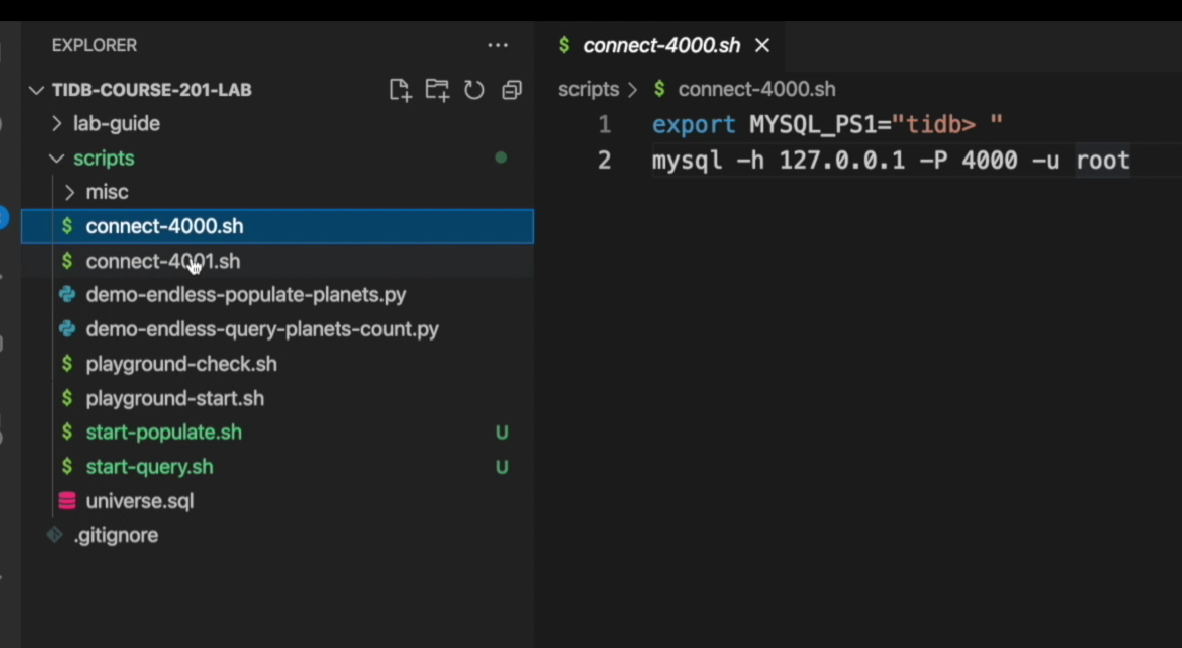
脚本统一存放于代码仓库 scripts 目录,测试集群共 3 个 TiDB 节点 ,端口:4000、4001、4002。
| 脚本名称 | 功能说明 |
|---|---|
| connect | 连接 TiDB Server,默认端口 4000 |
| start_populated | 循环写入程序,向 universe 库随机插入行星数据(名称、质量) |
| start_query | 循环查询程序,实时统计行星总数、平均质量 |
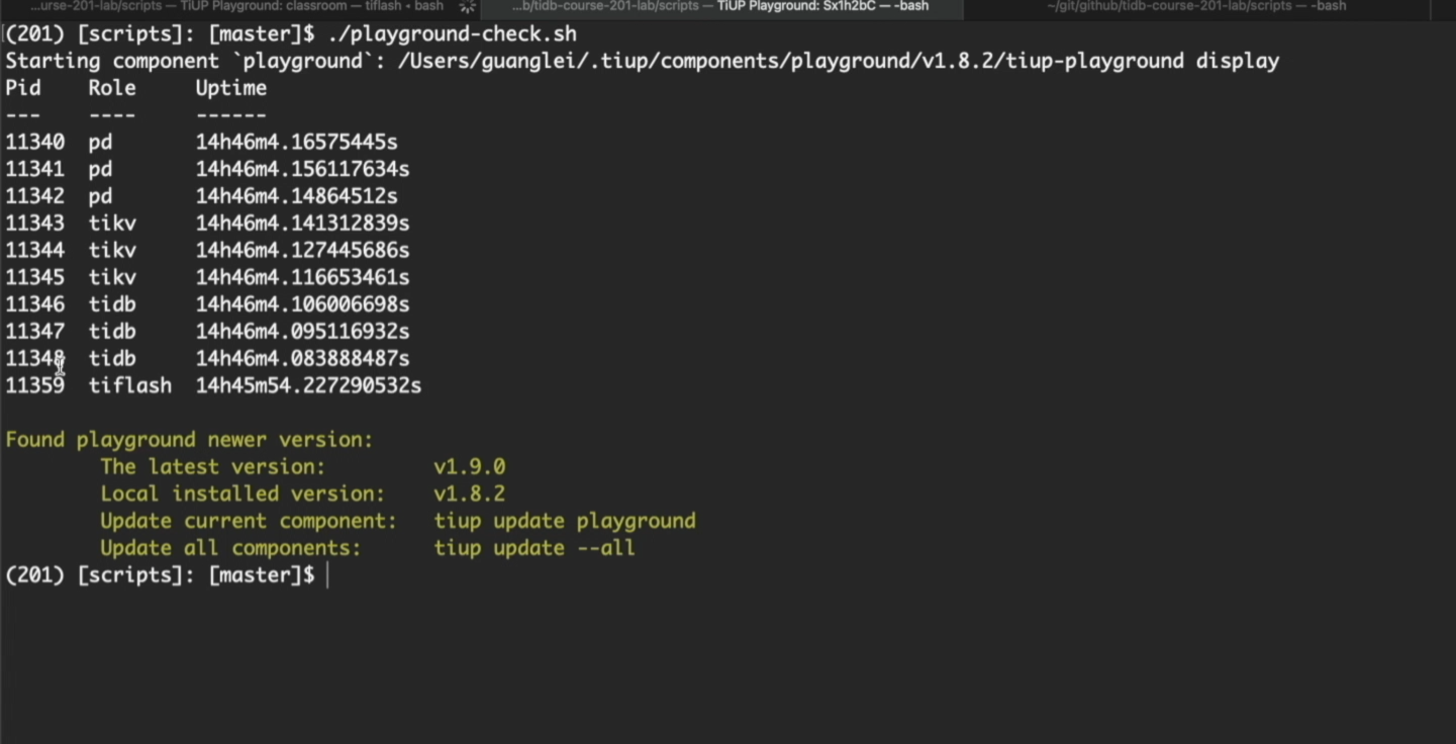
| playground_check | 集群状态检查,查看节点数量、进程号、端口 |
补充:写入、查询程序均基于 while true 死循环实现,内置异常捕获与自动重试逻辑,节点异常时不会直接退出。
二、程序正常运行状态
两个程序同时启动后:
- 写入端:持续随机生成数据并入库
- 查询端:实时刷新统计结果整体运行稳定。
三、分步模拟节点宕机
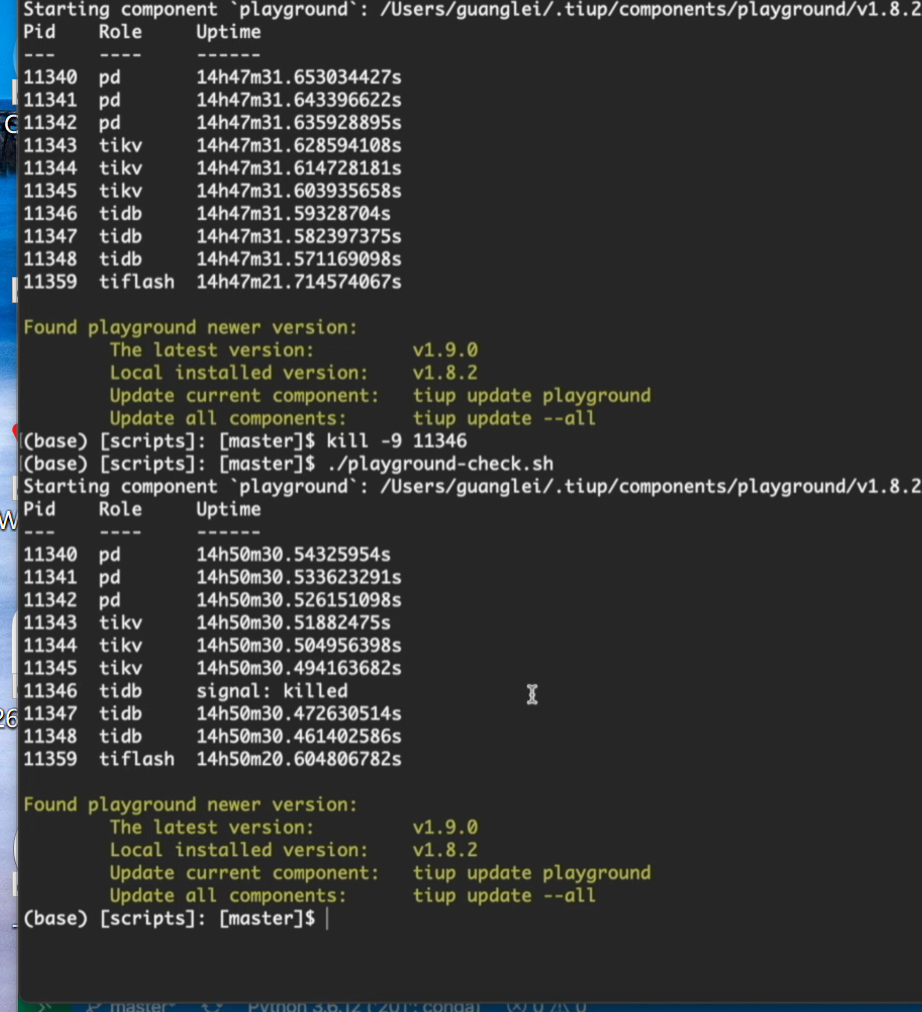
1. 关停 4000 端口节点(单节点宕机)
执行 kill -9 强制终止该节点进程。
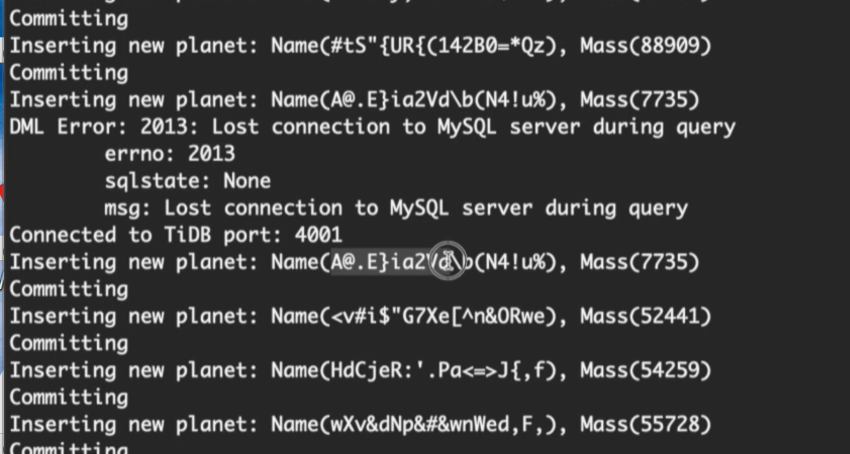
- 现象:读写程序短暂报错,随后自动重试并切换至其他可用节点,业务恢复正常;集群仅剩 2 个可用节点。
- 结论:单节点故障,业务无中断、数据无丢失。
2. 关停第二个 TiDB 节点
- 现象:程序短暂异常后快速恢复,依托最后一个节点继续提供服务。
- 结论:剩余节点可正常承接全部业务。
3. 关停全部 TiDB 节点
- 现象:程序持续重试连接,始终无法建立会话,业务暂时停滞。
- 核心结论:数据零丢失。TiDB 不持久化数据,底层 TiKV、PD 数据不受影响。
四、节点恢复方案
- 测试环境:使用「添加 TiDB 实例」脚本,基于
tiup工具一键新增节点。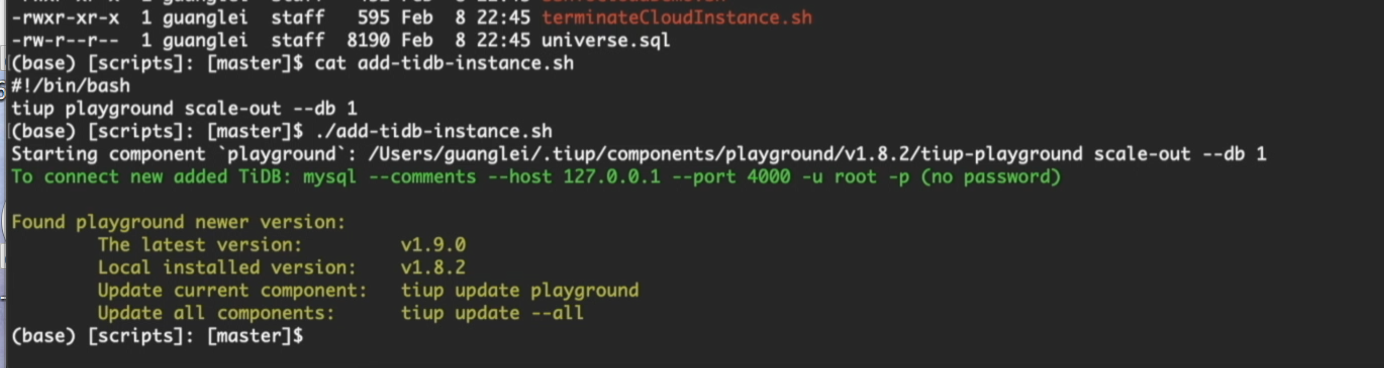
- 恢复效果:新节点启动后,程序自动重连,业务恢复运行。
- 生产环境:新增、重启 TiDB 节点操作逻辑与测试环境一致,操作简单。
整体总结
- 架构特点:TiDB Server 无状态,启停、扩缩容均不会损坏 TiKV/PD 中的数据。
- 故障表现
- 存在可用节点:带重试逻辑的业务程序可自动切换节点,业务无感;
- 全节点下线:业务临时中断,数据安全完好,恢复节点即可重启业务。
- 生产建议:搭配负载均衡 / 代理组件,进一步提升集群高可用能力。
官网资料学习整理,原视频地址如下:201.1-TiDB 的架构与特点 :02 TiDB-Server 的主要功能