前言
在移动应用开发的漫长演进中,长列表渲染(Long List Rendering)始终是检验底层框架性能与前端架构功底的终极试金石。从 Android 时代的 RecyclerView 到 iOS 体系的 UICollectionView,开发者们为了追求 120Hz 的极致丝滑,在节点复用、异步布局与内存压榨上倾注了无数心血。

进入 HarmonyOS 的 ArkUI 声明式时代,视图的更新不再依赖于手动干预 DOM 节点,而是完全交由状态驱动(State-Driven)。这种"数据即视图"的范式极大提升了开发效率,但也悄然掩盖了底层的内存危机:如果不加节制地使用全量数据绑定,ArkUI 引擎将在内存中为成百上千个列表项构建庞大的虚拟节点树,最终引发灾难性的内存溢出(OOM)或滑动掉帧。
《轻心记 (MoodLite)》作为一款主打情绪追踪的日记应用,其核心场景之一便是承载用户长年累月记录的"时间轴(Timeline)"。为了保障极端数据量下的性能,MoodLite 在 V2.0 重构方案的架构层明确提出了严苛的性能指标:"优化长列表(懒加载)与图表渲染的内存占用"。
本文将深入剖析 MoodLite 在 ArkUI 环境下的长列表渲染策略。我们将跳出简单的框架 API 调用,从内存分配、ViewModel 数据组装算法、再到组件生命周期管控,全面解析如何打造一个工业级的高性能复杂长列表。
一、声明式列表的内存陷阱与 ArkUI 渲染机制

在探讨优化策略之前,我们必须深刻理解 ArkUI 处理列表时的底层逻辑,以及常规写法为什么会导致性能崩塌。
1.1 ForEach 的"全量实例化"灾难
在 ArkUI 中,最直观的列表渲染方式是使用 List 组件包裹 ForEach 循环。对于极其简单、数量有限的配置项列表,这是一种极佳的做法。然而,当数据量突破一定阈值时,ForEach 的运行机制将暴露出致命的缺陷。
ForEach 的设计哲学是"响应式绑定"。当我们将一个包含 1000 条情绪记录的数组交给 ForEach 时,ArkUI 引擎会在初始化阶段(哪怕这些节点并不在屏幕的可视区域内)为这 1000 条数据全量创建对应的组件节点(Component Nodes)。这意味着:
- 主线程阻塞:创建 1000 个复杂节点需要极高的 CPU 计算力,直接导致页面加载时的白屏或卡顿。
- 内存暴涨:每一个声明式节点在底层 C++ 引擎中都对应着一套复杂的实体结构(包含布局参数、事件监听器、绑定的状态闭包)。1000 个节点将瞬间吞噬掉数十兆的运行内存。
- Diff 算法失效:当往数组中 push 一条新记录时,如果不加控制,状态变更会触发整个数组的重排与 Diff 比对,消耗大量的无用算力。
1.2 复杂卡片带来的 GPU 与内存双重惩罚
如果列表项仅仅是一行纯文本,全量实例化的代价或许尚能忍受。但 MoodLite 的 UI 规范采用了极具现代感的"玻璃拟态(Glassmorphism)"设计。
在时间轴列表中,每一个情绪记录卡片都可能包含:
- 带有弥散阴影(
shadow)的底层卡片。 - 通过大圆角和半透明色值实现的背景。
- 根据情绪净值动态计算的高亮颜色条。
- 情绪图标(
Image)与多行文本(Text)。
这些复杂的 UI 描述在底层对应着极高的渲染指令(Render Commands)开销。如果在内存中全量驻留这些带有高级特效的视图对象,不仅会造成内存溢出,更会因为层叠渲染引发严重的 GPU Overdraw(过度绘制)。
为了彻底斩断这一性能瓶颈,MoodLite 团队没有单纯依赖框架底层的魔法,而是从源头的数据流向入手,设计了一套基于 ViewModel 的分页降维策略。
二、第一道防线:数据降维与按需供给 (Data Pagination)

最彻底的内存优化,就是根本不让多余的数据进入 UI 渲染管线。
在 TimelineTab.ets(记录时间线)的实现中,MoodLite 巧妙地避开了一次性加载所有记录的陷阱,转而采用了一种基于时间的逻辑分页模式:月份隔离。
2.1 顶级数据源的切分:MonthGroup
项目定义了专门的懒加载与数据承载接口 MonthGroup:
TypeScript
// LazyDataSource.ets
import { MoodRecord } from '../model/MoodRecord';
export interface MonthGroup {
monthTitle: string;
records: MoodRecord[];
}在全局状态管理中,应用并没有直接下发一个极其庞大的 MoodRecord[],而是将数据按月切割,包装成了 MonthGroup[] 的形式传递给 TimelineTab 组件。
2.2 视图层的按需提取:refreshDays 算法
在 TimelineTab 组件内部,维持了 currentYear 和 currentMonth 两个极为轻量级的局部状态(Local State)。
真正的内存防波堤,建立在 refreshDays 方法之中:
TypeScript
@Prop @Watch('onGroupsChange') groupedRecords: MonthGroup[] = [];
@State dayGroups: DayGroup[] = [];
@State currentYear: number = new Date().getFullYear();
@State currentMonth: number = new Date().getMonth() + 1;
refreshDays(): void {
const monthKey = this.currentYear + '年' + this.currentMonth + '月';
// 关键步骤 1:时间维度的精准过滤,彻底抛弃非本月数据
const group = this.groupedRecords.find(g => g.monthTitle === monthKey);
// 关键步骤 2:对本月数据进行 ViewModel 层的二次聚合与转化
this.dayGroups = group ? this.buildDayGroups(group.records) : [];
}这段代码看似简单,实则蕴含了深刻的性能考量。当用户在浏览 5 月份的记录时,无论历史数据库里存了多少年的数据,组件的状态树 @State dayGroups 中永远只包含 5 月份的数据。
ArkUI 的视图树因此被死死地限制在了一个绝对可控的规模内。当用户点击"上一月"或"下一月"按钮时,currentMonth 发生改变,触发 refreshDays 重新计算。系统会优雅地销毁上个月的虚拟节点,并创建新月份的节点,永远保持内存的"动态平衡"。
2.3 @Watch 机制的防抖与更新管控
请注意 @Prop @Watch('onGroupsChange') groupedRecords 这一声明。
当应用的底层数据库发生变动(例如在别的页面新增了一条日记,导致全局 groupedRecords 改变并重新下发给 TimelineTab)时,ArkUI 会触发 @Watch 指定的回调函数。
如果没有 @Watch 进行拦截,一旦父组件传递的数据发生变化,整个 TimelineTab 的 build() 可能会被直接拉起重绘。而通过 @Watch 拦截,组件仅仅是在内存中重新执行了 refreshDays() 过滤算法,只有当筛选后的本月 dayGroups 发生实质性变化时,才会真正触发 UI 的重排。这种精细化的生命周期管理,极大减少了不必要的渲染开销。
三、ViewModel 层的"脏活":O(n) 数据重组与算法降级
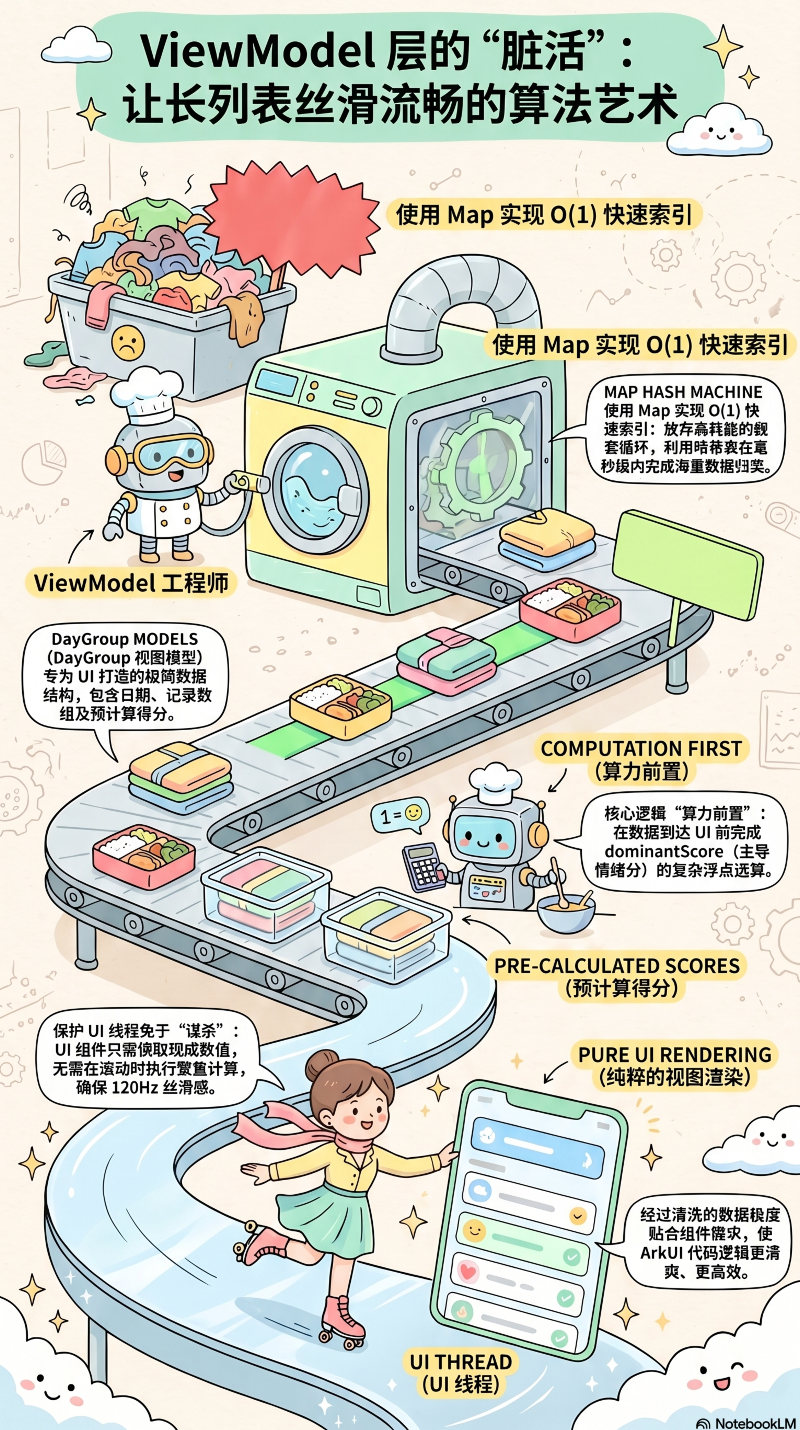
有了月份级别的控制,是不是就可以直接把数组丢给 UI 渲染了呢?依然不行。
在产品设计上,时间轴需要将同一天内的多次记录合并在同一个"日期卡片"下,并且该卡片的头部颜色,需要由当天所有情绪的"主导色彩(Dominant Emotion)"来决定。
如果将"按照日期分组"和"计算每天的主导情绪颜色"写在 List 组件的 build() 闭包中,这就意味着每次页面滚动、任何微小的状态刷新,都会让 UI 线程去执行繁重的数组分组和浮点运算。这无疑是对 UI 线程的谋杀。
3.1 引入 DayGroup 视图模型
为了保证 UI 的绝对纯粹,MoodLite 在当前作用域内定义了专门的视图模型 DayGroup:
TypeScript
interface DayGroup {
dateStr: string;
records: MoodRecord[];
dominantScore: number;
}这个结构就是 UI 组件真正想要的最优形态:一个日期对应一组记录,同时附带了预计算好的 dominantScore。
3.2 高性能的数据重组算法:buildDayGroups
将扁平的 MoodRecord[] 转化为嵌套的 DayGroup[],其核心算法在 buildDayGroups 中实现。为了保障性能,这段算法严禁使用高时间复杂度的嵌套循环(如 O(n2)O(n^2)O(n2) 的 filter + map),而是采用了经典的哈希映射与一次性遍历算法:
TypeScript
buildDayGroups(records: MoodRecord[]): DayGroup[] {
const map = new Map<string, DayGroup>();
// 阶段一:O(n) 复杂度的线性遍历与哈希归类
for (const r of records) {
let dg = map.get(r.dateStr);
if (!dg) {
// 懒初始化,避免空对象开销
dg = { dateStr: r.dateStr, records: [], dominantScore: 0 };
map.set(r.dateStr, dg);
}
dg.records.push(r);
}
const result: DayGroup[] = [];
// 阶段二:聚合运算与局部排序
map.forEach((v) => {
let sum = 0;
for (const r of v.records) sum += r.score;
// 提前计算均分,UI 层直接消费数字,拒绝浮点计算
v.dominantScore = sum / v.records.length;
// 同一天内按时间升序(旧→新)
v.records.sort((a, b) => a.timestamp - b.timestamp);
result.push(v);
});
// 阶段三:全局分组排序
// 按日期升序(旧日期在上)直接利用高效率的底层字符串比对
result.sort((a, b) => a.dateStr.localeCompare(b.dateStr));
return result;
}这段基于 ViewModel 的数据清洗代码,是整个复杂长列表性能优化的灵魂:
- O(1) 的分组查找 :利用
Map<string, DayGroup>作为数据桶,基于dateStr直接匹配,使得十万条数据的分组时间也缩减到毫秒级。 - 算力前置(Pre-computation) :每天情绪值的平均数
dominantScore在此处被计算完毕并固化到对象内存中。当 UI 渲染卡片头部时,仅仅是一次微不足道的内存读取操作,没有任何 CPU 负担。 - 彻底隔离 UI 层 :经过洗礼后,输出的
result数组结构极度贴合视图渲染的需要,使得后续 ArkUI 组件的代码变得异常清爽。
四、UI 骨架层的降级渲染与视图解耦
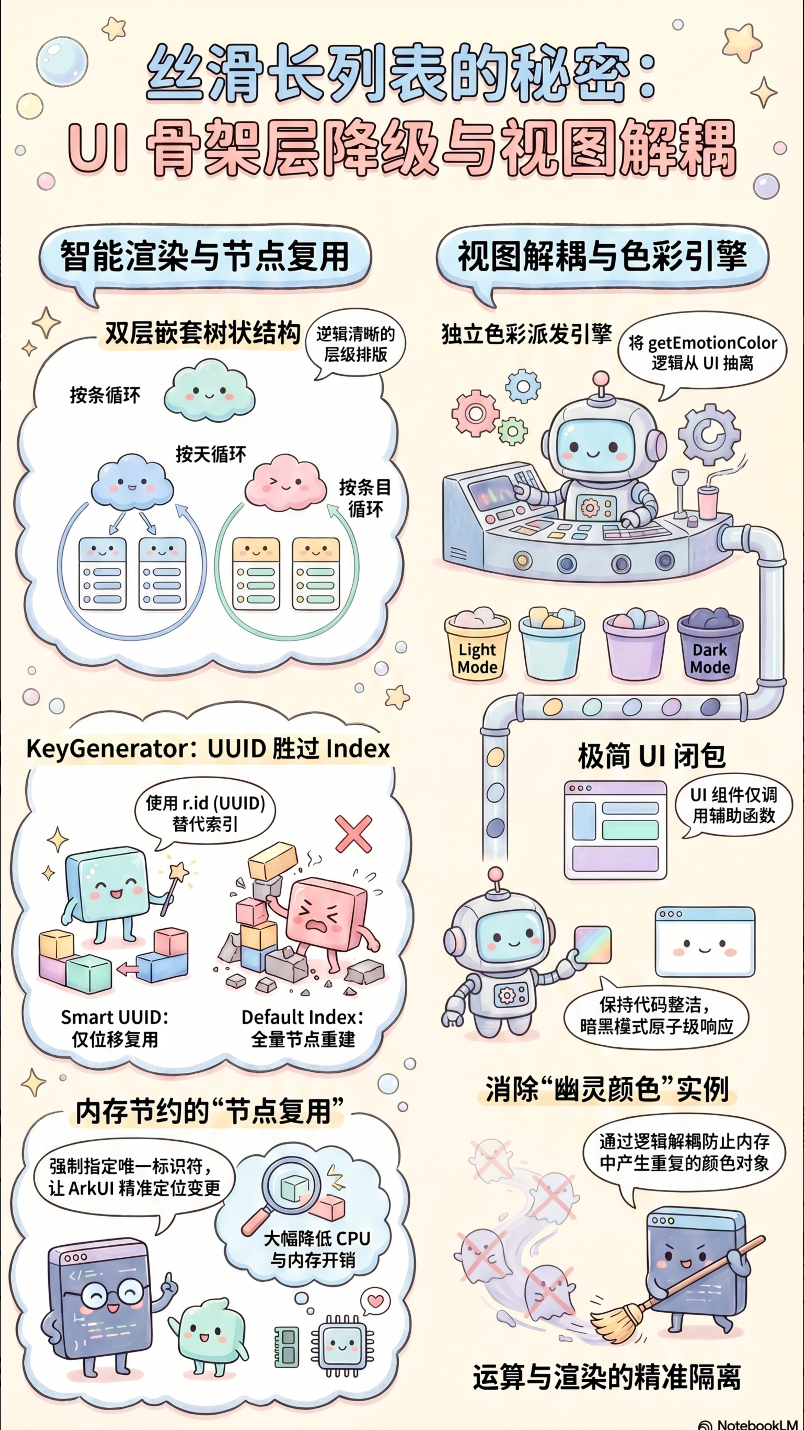
在数据层被完美控制后,我们再来审视 TimelineTab 真正的 UI 渲染结构。为了应对极其复杂的长列表排版,MoodLite 在布局层利用了 ArkUI 的嵌套能力与组件拆分。
4.1 嵌套列表的结构化展示
时间线的视图结构是一个典型的二级树状结构:外层按天循环,内层按条目循环。
TypeScript
// 外层 List 承载全局滑动
List({ space: 16 }) {
// 顶层 ForEach 渲染日期块
ForEach(this.dayGroups, (day: DayGroup) => {
ListItem() {
Column() {
// 1. 日期头部渲染:极简的色块映射
Row() {
Column().width(6).height(6)
.backgroundColor(heatmapColor(this.computeMoodCode(day.records), 2.0, true, this.darkMode))
Text(this.formatDate(day.dateStr))
}
.backgroundColor(heatmapColor(this.computeMoodCode(day.records), Math.abs(day.dominantScore), true, this.darkMode))
// 2. 内层 ForEach 渲染当天的所有单条记录
Column({ space: 20 }) {
ForEach(day.records, (r: MoodRecord) => {
Row() {
// 图标渲染
Image(getMoodIconResource(r.score))
// 文本渲染
Column() {
// 标题、标签、截断文本
}
}
}, (r: MoodRecord) => r.id) // 强制绑定 UUID 作为重排标识
}
}
}
}, (day: DayGroup) => day.dateStr) // 外层以日期作为标识
}4.2 严格把控 Key 生成器 (KeyGenerator)
在上述的双重 ForEach 循环中,最值得关注的是每一个 ForEach 最后的第三个参数:KeyGenerator 键值生成器。
- 外层 Key :
(day: DayGroup) => day.dateStr。 - 内层 Key :
(r: MoodRecord) => r.id。
这是声明式框架中内存优化最基础但也最容易被忽视的一环。如果省略这个参数,ArkUI 默认会使用数组的索引(Index)结合字符串的序列化作为 Key。
试想,如果用户在 5 月 15 日补签了一条上午的日记。根据前面的排序算法,这条日记会被插入到内层 records 数组的中间。如果使用默认 Index 作为 Key,系统会认为该插入位置之后的所有组件发生了改变,从而销毁并重建后续所有的列表项节点!
通过强制指定 r.id (绝对不重复的 UUID) 作为唯一标识符,ArkUI 的 Diff 算法就能精准定位到:这仅仅是一个新组件的插入。原有的其他列表项节点可以在内存中被直接保留并复用,仅仅做一下垂直坐标的位移操作(Translation),极大节省了内存回收与重建的开销。
4.3 视觉颜色的独立派发引擎
在列表渲染时,卡片背景色和文本颜色需要根据情绪分数动态改变。在未优化的代码中,开发者极易在组件内写满 if (score > 1) { return Color.Pink } 的样板逻辑。
MoodLite 将这些逻辑全部抽离,利用专门的方法进行代理:
TypeScript
getEmotionColor(score: number): string {
const mc = score >= 0.5 ? 3 : (score <= -0.5 ? 1 : 2);
return heatmapColor(mc, Math.abs(score) >= 1 ? 1.5 : 0.5, true, this.darkMode);
}
UI 组件只需调用 this.getEmotionColor(r.score)。这些辅助函数充当了视图控制器(View-Controller)的职责,既保持了 UI 代码的整洁度,又确保了在深色模式(darkMode)切换时,色彩系统能够实现原子级的迅速响应与全局同步,而不会产生内存中的幽灵颜色实例。
五、未来蓝图:向终极的 LazyForEach 迈进
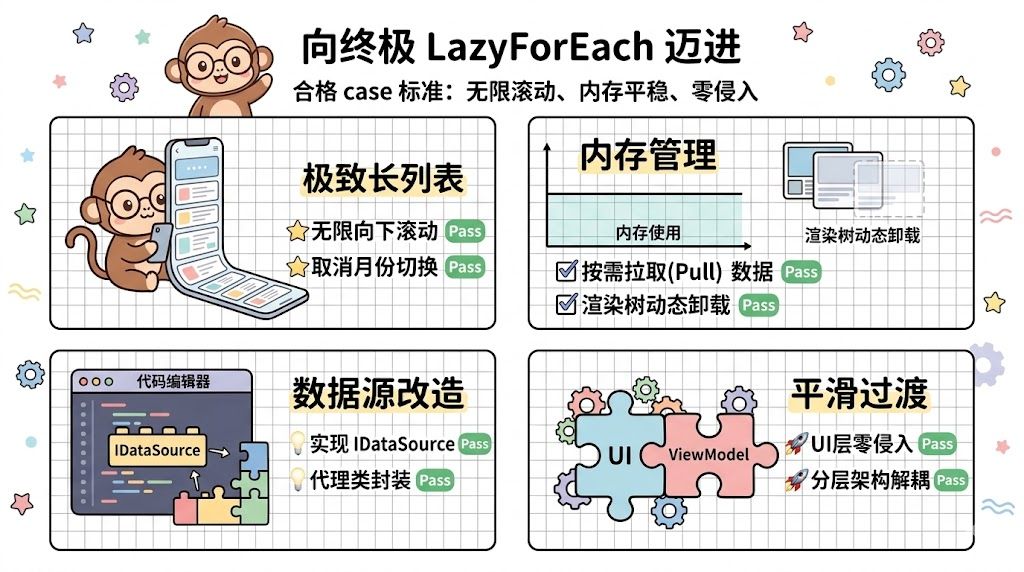
尽管当前 MoodLite 通过"月份隔离 + ViewModel 预聚合"的策略,将基于 ForEach 的渲染压力降到了最低,在绝大多数场景下保障了极致的流畅体验。但团队在产品架构文档中依然高瞻远瞩地确立了"极致优化长列表(懒加载)"的目标。
当系统面临长达十年的日记无缝瀑布流浏览需求时(即取消月份切换按钮,实现真正的无限向下滚动),现有的 ForEach 将彻底触及物理内存的边界。此时,基于 IDataSource 的 LazyForEach 将成为唯一的救世主。
5.1 从全量状态到受控数据源 (Controlled Data Source)
真正的长列表懒加载(LazyForEach)要求开发者放弃对 @State 数组的直接依赖,而是必须实现一个包含完整生命周期监听的 IDataSource 接口类。
这是一种底层控制权的交接:
- 在目前的
ForEach中,数据是"推(Push)"给框架的。数据一变,框架全部知晓并试图重绘。 - 在未来的
LazyForEach架构中,数据源是被"拉(Pull)"的。List容器只会根据当前的滚动偏移量,精准计算出屏幕可见区域(以及cachedCount预加载区域)内那十几个组件的 Index,然后主动调用dataSource.getData(index)请求数据。
对于那些滚出屏幕的组件,ArkUI 框架会将其从内存的渲染树中卸载,释放巨大的运行内存,从而使内存曲线保持在一条极其平稳的水平线上,无论用户滑动了 10 条还是 10 万条数据。
5.2 现有架构对懒加载的平滑过渡能力
得益于 MoodLite 当前严谨的架构设计,向 LazyForEach 的迁移成本几乎为零。
- 结构已就绪 :应用目前已经抽离了
entry/src/main/ets/viewmodel/LazyDataSource.ets模块,为构建继承自IDataSource的类预留了物理空间。 - 逻辑已剥离 :由于数据的清洗和组装已经完全由
buildDayGroups这种纯函数在 ViewModel 层完成,我们只需要构建一个代理类:
TypeScript
export class TimelineDataSource implements IDataSource {
private dataArray: DayGroup[] = [];
// 内部封装对监听器 listeners 的增删改查通知
public getData(index: number): DayGroup {
return this.dataArray[index];
}
}- UI 无侵入 :视图层的
ListItem及内部结构无需任何修改,只需将ForEach关键字替换为LazyForEach,并传入实例化的TimelineDataSource即可。
这就是优秀分层架构的魅力:底层引擎的切换和内存加载机制的重构,不会引发上层业务逻辑和视觉表现的任何震荡。
结语:性能优化的系统级思维
通过深度拆解 MoodLite 的时间线长列表渲染机制,我们可以清晰地看到,在声明式 UI 范式下,解决内存与性能问题从来都不是单纯的依靠某个 API 或配置项。
它是一项需要贯穿全栈的系统级工程:从底层领域模型的 UUID 主键约束,到应用层面的逻辑分页(月份隔离),从视图模型(ViewModel)里极限追求 O(n) 与 O(1) 的重组算法,最后到 UI 骨架层严格的 Key 绑定策略。
这些被隐藏在优雅界面之下的代码巧思,共同构筑了一道坚不可摧的性能护城河。正是因为做到了数据与视图的彻底解耦、运算与渲染的精准隔离,MoodLite 才得以在使用极其消耗 GPU 的玻璃拟态特效的同时,依然保持应用内存占用的克制与运行的极致丝滑,完美兑现了其作为工业级鸿蒙原生应用的工程承诺。