写在前面

欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
AIGC算法岗/开发岗面试面经交流社群 (涵盖AI Agent、AIGC图像创作、AI视频、LLM大模型、AI多模态、数字人、传统深度学习、具身智能等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
码字不易,希望大家能多多点赞!
GAN的技术周期已经彻底结束,因此Rokcy将只撰写这一篇文章彻底总结GAN的在AI行业的本质价值与历史定位。
谨以此文,献给2018年那个曲折探索的传统深度学习时代和Rocky当时对GAN以及生成式AI技术的战略豪赌。
那些年遇到的灿烂的阳光、可贵的品质、鲜活的面容、坚强的精神和年轻的我们,相信是我们在AIGC时代和未来的AGI时代持续前进的认知底色。
大家好,我是Rocky。
2022年至今,Stable Diffusion、FLUX、Nano Banana、Seedream(即梦)、Midjourney、DeepSeek、Sora以及GPT-4o等AIGC大模型密集爆发,引领了全新的AI科技浪潮,AI行业正式进入AIGC时代。
生成对抗网络(GAN,Generative Adversarial Network)模型曾是传统深度学习时代图像生成领域无可争议的"王者"。 但进入 AIGC 时代后,其核心应用场景 ------ 图像生成创作,与Stable Diffusion、FLUX等扩散模型高度重合,并且Stable Diffusion/FLUX的整体生成能力更加强大、开源生态更加繁荣。 一时间,"GAN已死"、"扩散模型全面取代GAN" 的论调在自媒体圈甚嚣尘上。
但GAN真的在 AIGC 时代一无是处、彻底凉了、被行业全面弃用了吗?
答案恰恰相反。GAN不仅没有被淘汰,反而在AIGC时代找到了最精准的定位与不可替代的价值 ------ 成为AIGC图像创作领域的关键辅助模型。 在如今以"Stable Diffusion/FLUX系列AIGC基座大模型 + LoRA系列微调模型 + ControlNet系列控制模型 + 各类AIGC可控生成技术"为核心的主流AIGC图像创作解决方案/产品中,GAN已经化身为无处不在的"万金油"模块。它在数据增强、图像超分辨率重建、人脸修复、图像Low-Level处理、图像编辑、风格迁移、图像融合等细分方向上持续发挥着不可替代的作用。
可以说,这一次随着AIGC时代的全面到来,曾经被诟病"难以落地"的GAN模型,终于迎来了真正意义上的大规模产业落地。
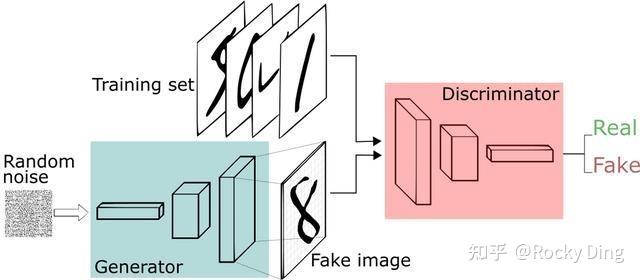
在本文中,Rocky主要将对GAN模型在AIGC时代中的全维度各个方面的知识都做一个深入浅出的分析讲解,其中包括GAN模型的核心原理与架构讲解、GAN主流变体模型的跨周期创新点与核心价值讲解、GAN主流优化技术的原理讲解、StyleGAN系列和GigaGAN等AIGC时代依旧在细分领域挑大梁的核心模型原理讲解、GAN在AIGC时代的主流应用场景讲解、GAN模型的核心资源整合汇总等干货内容,希望能给大家带来帮助!

4. GAN的主流变体模型及其在AIGC时代的主流应用场景深入浅出完整讲解
4.1 AIGC时代主流的Low-Level技术概念及其核心GAN模型
在AIGC时代,虽然商业级的文生图、图生图、图像可控生成、图像文字渲染、图像补全等AIGC图像创作核心方向已经由Stable Diffusion/FLUX为主的扩散模型所接手,但是GAN在图像超分、图像去噪/Deblur、人脸修复、图像增强、图像补全、人脸磨皮、人像美白等Low-Level功能领域彻底落地。
GAN模型的优势在于低延迟 、端到端轻量 、 效果稳定,所以在这些AIGC细分任务中持续发挥着关键作用。
下面Rocky将详细阐述有价值的Low-Level技术领域的任务需求、主流GAN模型,以及这些模型如何实现相应功能。
| 任务类型 | 训练数据设计 | 代表GAN模型 | 核心 AIGC 应用价值 |
|---|---|---|---|
| 图像超分辩率重建 | 低清图像/高清图像数据对 | ESRGAN、Real-ESRGAN、AuraSR | 解决 AIGC 生成图像分辨率不足、放大后模糊的痛点,同时实现海量低质素材(老照片、低清截图、监控画面)的高清化放大,是 AIGC 画质提升的核心底座 |
| 低质盲人脸修复 | 严重退化人脸/高质量人脸数据对 | GFPGAN | AIGC 数字人生成、低清人脸修复、证件照提质的核心技术,既要恢复人脸高清细节,又要严格保证身份不偏移 |
| 通用盲图像修复 | 严重退化图像/高质量图像数据对 | DeblurGANv2、MPRNet、Restormer | 解决 AIGC 素材、摄影作品、视频帧的混合退化问题(运动模糊、高斯噪声、JPEG 压缩伪影、雨雾遮挡),是图像/视频画质增强、素材修复的核心技术。 |
| 图像到图像翻译 | 草图 / 语义 → 成片 | Pix2PixHD、SPADE / GauGAN、CycleGAN、StarGAN v2 | 实现不同域之间的图像转换,保留输入语义内容的同时转换域属性,是 AI 绘画草图转实景、语义标签转场景、风格迁移、数字孪生场景生成的核心底座 |
| 图像补全(Inpainting) | 破损图片/完整图片数据对 | LaMa | 实现图像缺失、破损、遮挡区域的合理填充,是 PS AI 填充、AI 修图工具、老照片破损修复、水印 / 瑕疵去除、内容重绘的核心底层技术 |
| 交互式生成/编辑 | 高质量图像数据集 | StyleGAN2/3、DragGAN 等 | 在 GAN 潜空间或特征上编辑语义,实现图像属性的解耦、控制、编辑 |
在AIGC时代扩散模型和GAN融合发展的生态中,以上的核心功能特点常作为复杂AIGC工作流中的一环,例如在Stable Diffusion、FLUX等扩散模型的前处理和后处理中,扮演"得力助手"的角色。
4.2 GAN模型在超分辨率重建场景的应用
超分辨率重建(Super-Resolution, SR)是指通过AI算法将低分辨率图像转换为高分辨率图像的过程 。这个过程可以使用GAN模型和AIGC扩散模型来提升图像的细节和清晰度。这一过程对于许多AI应用场景至关重要,如作为AIGC图像创作解决方案的前/后处理、视频/图像增强等。
接下来,Rocky将以Real-ESRGAN模型为例,解析一下GAN模型在超分辨率重建领域的发展脉络。

Real-ESRGAN(Real-Enhanced Super-Resolution Generative Adversarial Networks) 是经典的采用生成对抗网络(GAN) 架构,核心由生成器(SR 网络) 和判别器两部分组成的主流超分辨率重建模型。
本系列的发展脉络为SRGAN -> ESRGAN -> BSRGAN -> Real-ESRGAN,Rocky在这里重点讲解Real-ESRGAN的核心原理,并在最后对整个系列模型的发展脉络与各系列的标志性创新点进行汇总分享。
【Real-ESRGAN生成器架构】
Real-ESRGAN 的生成器沿用了 ESRGAN 的残差密集块(RRDB) 主干网络,这是目前超分领域最成熟的生成器结构之一。论文在此基础上扩展了对×2、×1 超分的支持,并通过工程优化大幅降低了计算开销。
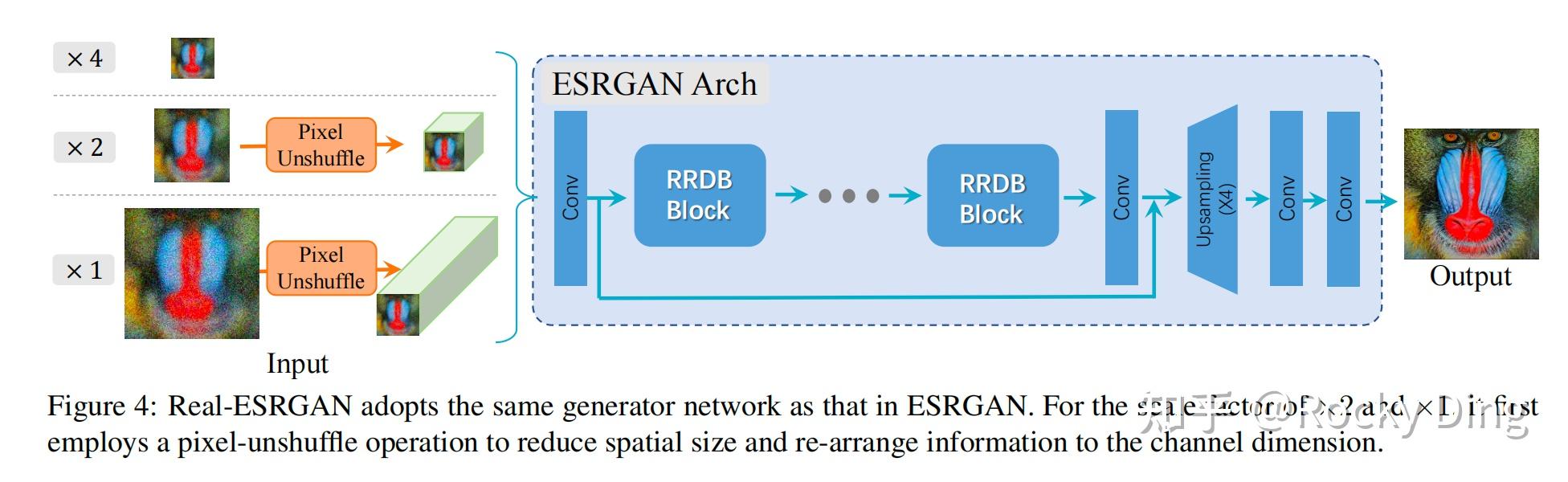
-
基础 RRDB 主干(×4 超分原生架构)
输入(LR) → 初始卷积层 → 23个串联RRDB块 → 上采样模块(×4) → 输出卷积层 → 输出(HR)
- RRDB 块:由多个残差块和密集连接组成,相比普通残差块具有更强的特征提取能力和梯度传播效率,能有效恢复高频细节。
- 上采样模块 :采用像素洗牌(Pixel Shuffle) 操作实现×4 上采样,避免了转置卷积常见的棋盘格伪影。
- 多尺度扩展(×2、×1 超分)
为了支持×2 和×1 超分(×1 主要用于去噪、去伪影等图像增强任务),论文引入了像素反洗牌(Pixel Unshuffle) 操作作为输入预处理:
输入(任意尺度) → Pixel Unshuffle → 降维后的特征图 → RRDB主干 → 上采样模块 → 输出(HR)- Pixel Unshuffle 原理:是 Pixel Shuffle 的逆操作,将空间维度的信息重排到通道维度。例如,×2 超分时,先将输入的 H×W×3 特征图转换为 (H/2)×(W/2)×12,再送入 RRDB 主干。
- 核心优势 :将大部分计算转移到更低分辨率的特征空间,减少了70%以上的GPU显存占用和计算量,同时保持了与原生×4架构相当的性能。
- 生成器变体:Real-ESRNet
Real-ESRNet 是生成器的PSNR 导向版本,仅使用 L1 损失训练,不包含 GAN 部分。它作为 Real-ESRGAN 训练的初始化权重,保证了基础重建质量,避免了 GAN 训练初期的模式崩溃问题。
【Real-ESRGAN判别器架构】
这是 Real-ESRGAN 与 ESRGAN 最大的区别。ESRGAN 采用 VGG 式的全局判别器,而 Real-ESRGAN 提出了带谱归一化的 U-Net 判别器,彻底解决了复杂退化场景下判别能力不足和训练不稳定的问题。

-
U-Net 结构设计
输入(HR/生成图像) → 下采样编码器(4层) → 瓶颈层 → 上采样解码器(4层) → 逐像素真实度输出
↓ ↑
└───跳跃连接─────┘
- 编码器:由4个带谱归一化的卷积层组成,逐步降低空间分辨率,提取高层语义特征。
- 解码器:由4个上采样卷积层组成,逐步恢复空间分辨率,同时通过跳跃连接融合编码器的低层细节特征。
- 输出 :与输入图像同尺寸的逐像素真实度图,每个像素值表示该位置是真实图像的概率。
- 与 VGG 式判别器的核心优势对比
| 特性 | VGG 式判别器(ESRGAN) | U-Net 判别器(Real-ESRGAN) |
|---|---|---|
| 输出 | 全局单一真假概率 | 逐像素真实度图 |
| 梯度反馈 | 全局粗粒度 | 局部细粒度 |
| 特征捕捉 | 仅高层语义特征 | 高低层特征融合 |
| 适用场景 | 简单双三次退化 | 复杂真实世界退化 |
- 谱归一化(SN)正则化
论文在 U-Net 判别器的所有卷积层都应用了谱归一化:
- 原理:约束判别器权重矩阵的谱范数为1,保证判别器满足 Lipschitz 连续性。
- 核心作用:
- 从根本上稳定 GAN 训练动态,避免了模式崩溃和梯度爆炸。
- 显著缓解了 GAN 训练常见的过锐和不自然伪影问题。
- 让判别器在更大的退化空间中仍能提供准确的梯度反馈。
【Real-ESRGAN完整训练流程与损失函数】
Real-ESRGAN 采用两阶段训练策略,配合多损失函数联合监督,实现了重建精度和感知效果的平衡。
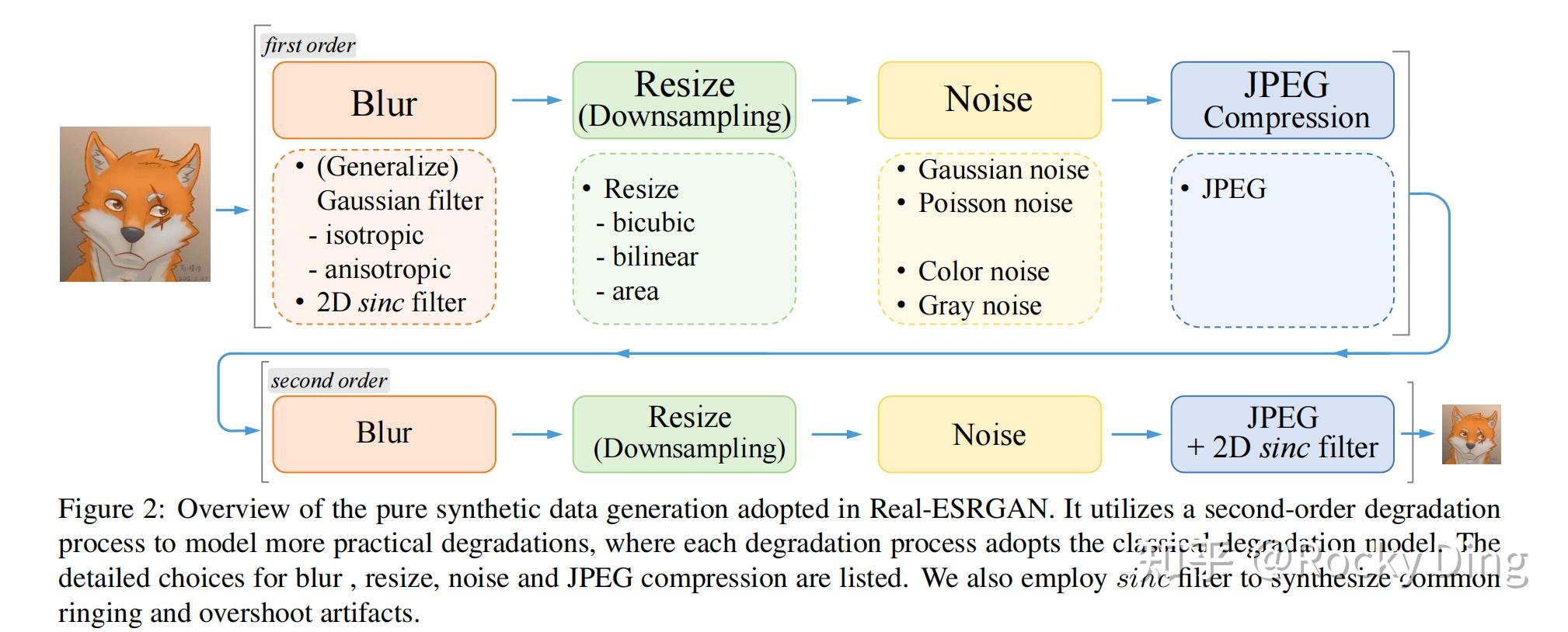
- 第一阶段:训练 Real-ESRNet(PSNR 导向)
- 损失函数:仅使用 L1 损失(像素级重建损失)。
- 训练目标:让生成器学习基础的图像重建能力,保证输出图像的整体结构正确。
- 训练细节:在 DIV2K、Flickr2K 和 OutdoorSceneTraining 数据集上训练 1000K 迭代,学习率 2×10⁻⁴。
L L 1 = E x ∼ p L R ( x ) , y ∼ p H R ( y ) ∥ G θ ( x ) − y ∥ 1 \mathcal{L}{L1} = \mathbb{E}{x \sim p_{LR}(x), y \sim p_{HR}(y)} \left \\left\\\| G_{\\theta}(x) - y \\right\\\|_1 \\right LL1=Ex∼pLR(x),y∼pHR(y)∥Gθ(x)−y∥1
符号定义:
- G θ G_{\theta} Gθ:参数为 θ \theta θ 的生成器网络(即 Real-ESRNet)
- x x x:输入的低分辨率(LR)图像
- y y y:对应的高分辨率(HR)真值图像
- ∥ ⋅ ∥ 1 \|\cdot\|_1 ∥⋅∥1:L1 范数(像素级绝对误差)
- E ⋅ \mathbb{E}\\cdot E⋅:对训练数据分布的期望
- 第二阶段:训练 Real-ESRGAN(GAN 导向)
- 初始化:使用第一阶段训练好的 Real-ESRNet 权重初始化生成器。
- 损失函数:三种损失加权组合,总权重为 1:1:0.1:
- L1 损失:保证像素级重建精度,避免颜色和结构失真。
- 感知损失:使用预训练 VGG19 网络的 conv1-conv5 特征图计算,提升视觉感知质量。
- GAN 损失:基于 U-Net 判别器的逐像素输出计算,驱动生成器恢复真实自然的纹理细节。
- 训练细节:训练 400K 迭代,学习率 1×10⁻⁴,采用指数移动平均(EMA)进一步稳定训练。
总损失公式:
L t o t a l = λ L 1 ⋅ L L 1 + λ p e r c e p ⋅ L p e r c e p + λ g a n ⋅ L g a n \mathcal{L}{total} = \lambda{L1} \cdot \mathcal{L}{L1} + \lambda{percep} \cdot \mathcal{L}{percep} + \lambda{gan} \cdot \mathcal{L}_{gan} Ltotal=λL1⋅LL1+λpercep⋅Lpercep+λgan⋅Lgan
论文官方权重设置:
λ L 1 = 1 , λ p e r c e p = 1 , λ g a n = 0.1 \lambda_{L1}=1, \quad \lambda_{percep}=1, \quad \lambda_{gan}=0.1 λL1=1,λpercep=1,λgan=0.1
L1 像素损失(与第一阶段一致)作用:保证生成图像与真值在像素级上的一致性,避免颜色偏移和结构失真。公式同第一阶段。
感知损失(Perceptual Loss)作用:在特征空间而非像素空间衡量图像相似度,更符合人类视觉感知,能有效提升图像的视觉质量。Real-ESRGAN 使用预训练 VGG19 网络 的特征图计算感知损失,且采用激活前的特征图(比激活后效果更好)。具体公式如下:
L p e r c e p = E x , y ∑ i = 1 5 w i ⋅ ∥ ϕ i ( G θ ( x ) ) − ϕ i ( y ) ∥ 1 \mathcal{L}{percep} = \mathbb{E}{x, y} \left \\sum_{i=1}\^{5} w_i \\cdot \\left\\\| \\phi_i(G_{\\theta}(x)) - \\phi_i(y) \\right\\\|_1 \\right Lpercep=Ex,yi=1∑5wi⋅∥ϕi(Gθ(x))−ϕi(y)∥1
符号定义:
- ϕ i ( ⋅ ) \phi_i(\cdot) ϕi(⋅):预训练 VGG19 网络第 i i i 个卷积层(conv1-conv5)的特征提取函数
- w i w_i wi:第 i i i 层特征的权重
论文官方层权重设置:
| VGG19 层 | conv1_2 | conv2_2 | conv3_4 | conv4_4 | conv5_4 |
|---|---|---|---|---|---|
| 权重 w_i | 0.1 | 0.1 | 1.0 | 1.0 | 1.0 |
逐像素 GAN 损失(Pixel-wise GAN Loss)是 Real-ESRGAN 与 ESRGAN 最核心的损失差异。ESRGAN 使用全局判别器输出单一标量的 GAN 损失,而 Real-ESRGAN 的 U-Net 判别器输出逐像素的真实度图,因此 GAN 损失是逐像素计算的。
生成器 GAN 损失(非饱和形式):
L g a n G = E x − 1 H × W ∑ h = 1 H ∑ w = 1 W log D ϕ ( G θ ( x ) ) h , w \mathcal{L}{gan}^G = \mathbb{E}{x} \left -\\frac{1}{H \\times W} \\sum_{h=1}\^{H} \\sum_{w=1}\^{W} \\log D_{\\phi}(G_{\\theta}(x))_{h,w} \\right LganG=Ex−H×W1h=1∑Hw=1∑WlogDϕ(Gθ(x))h,w
判别器 GAN 损失:
L g a n D = E y − 1 H × W ∑ h = 1 H ∑ w = 1 W log D ϕ ( y ) h , w + E x − 1 H × W ∑ h = 1 H ∑ w = 1 W log ( 1 − D ϕ ( G θ ( x ) ) h , w ) \mathcal{L}{gan}^D = \mathbb{E}{y} \left -\\frac{1}{H \\times W} \\sum_{h=1}\^{H} \\sum_{w=1}\^{W} \\log D_{\\phi}(y)_{h,w} \\right + \mathbb{E}_{x} \left -\\frac{1}{H \\times W} \\sum_{h=1}\^{H} \\sum_{w=1}\^{W} \\log(1 - D_{\\phi}(G_{\\theta}(x))_{h,w}) \\right LganD=Ey−H×W1h=1∑Hw=1∑WlogDϕ(y)h,w+Ex−H×W1h=1∑Hw=1∑Wlog(1−Dϕ(Gθ(x))h,w)
符号定义:
- D ϕ D_{\phi} Dϕ:参数为 ϕ \phi ϕ 的 U-Net 判别器
- D ϕ ( I ) h , w D_{\phi}(I)_{h,w} Dϕ(I)h,w:判别器对图像 I I I 在位置 ( h , w ) (h,w) (h,w) 处的真实度预测值(0~1)
- H , W H, W H,W:输入图像的高度和宽度
最后,Rocky在总结一下Real-ESRGAN vs ESRGAN vs BSRGAN vs SRGAN核心差异对比表(标志性创新):
| 对比维度 | SRGAN (2017) | ESRGAN (2018) | BSRGAN (2021) | Real-ESRGAN (2021) |
|---|---|---|---|---|
| 整体框架 | 首个GAN-based超分框架 生成器+VGG式全局判别器 | SRGAN的改进版 生成器+VGG式全局判别器 | 实用化盲超分GAN 生成器+带SN的VGG式判别器 | 纯合成数据训练的盲超分GAN 继承ESRGAN生成器+革命性U-Net判别器 |
| 生成器主干 | 16个普通残差块 无密集连接 | 23个RRDB残差密集块 残差+密集连接融合 | 16个RDB残差密集块 纯密集连接 | 完全继承ESRGAN的23个RRDB块 新增Pixel Unshuffle预处理 |
| 生成器多尺度支持 | 仅原生支持×4超分 | 仅原生支持×4超分 | 仅原生支持×4超分 | 原生支持×1/×2/×4超分 ×1用于去噪/去伪影 ×2/×4用于超分辨率 |
| 生成器上采样 | 首次引入Pixel Shuffle(×4) 替代转置卷积消除棋盘格伪影 | Pixel Shuffle(×4) | Pixel Shuffle(×4) | Pixel Shuffle(×4) 配合Pixel Unshuffle实现多尺度高效推理 |
| 判别器结构 | VGG19式全局判别器 无谱归一化 输出单一全局真假概率 | VGG19式全局判别器 无谱归一化 输出单一全局真假概率 | VGG19式全局判别器 带谱归一化(SN) 输出单一全局真假概率 | U-Net结构判别器 全卷积+跳跃连接 全层带谱归一化(SN) 输出逐像素真实度图 |
| 判别器梯度反馈 | 全局粗粒度 仅能指导整体风格 | 全局粗粒度 比SRGAN更稳定 | 全局粗粒度 比ESRGAN更稳定 | 局部细粒度 每个像素独立梯度 精准指导纹理细节恢复 |
| 退化建模阶数 | 一阶退化 模糊→下采样→噪声 | 一阶退化 模糊→下采样→噪声→JPEG | 一阶随机打乱退化 单一退化操作随机排列 无重复执行完整流程 | 二阶高阶退化 两次独立执行完整经典退化流水线 最贴合真实世界多次退化过程 |
| 模糊核类型 | 仅各向同性高斯模糊 | 仅各向同性高斯模糊 | 各向同性/异性高斯模糊 | 各向同性/异性高斯(70%) 广义高斯(15%) 平台形核(15%) 更好模拟真实相机模糊 |
| 振铃/过冲伪影建模 | ❌ 完全未建模 | ❌ 完全未建模 | ❌ 完全未建模 | ✅ Sinc滤波器专门建模 两个插入位置+顺序随机化 |
| 下采样操作 | 固定双三次下采样 | 固定双三次下采样 | 随机双线性/双三次/面积下采样 | 随机双线性/双三次/面积下采样 排除最近邻避免对齐问题 |
| 噪声类型 | 仅加性高斯噪声 | 仅加性高斯噪声 | 高斯噪声+泊松噪声 | 高斯噪声(50%)+泊松噪声(50%) 支持彩色噪声/灰度噪声(40%概率) |
| JPEG压缩建模 | ❌ 完全未建模 | ✅ 固定质量因子 | ✅ 随机质量因子10,95 | ✅ 随机质量因子30,95 采用可微分DiffJPEG实现 |
| 训练策略 | 两阶段训练 1. PSNR导向预训练(MSE损失) 2. GAN微调 | 两阶段训练 1. PSNR导向预训练(L1损失) 2. GAN微调 | 两阶段训练 1. PSNR导向预训练 2. GAN微调 | 两阶段训练 1. 训练Real-ESRNet(PSNR导向) 2. GAN微调 新增训练对池提升退化多样性 |
| 基础重建损失 | MSE损失 | L1损失 | L1损失 | L1损失 |
| 损失函数权重 | MSE:感知:GAN = 1:0.006:0.001 | L1:感知:GAN = 1:1:0.001 | L1:感知:GAN = 1:1:0.05 | L1:感知:GAN = 1:1:0.1 更强的GAN监督以恢复真实纹理 |
| 感知损失特征层 | VGG19 relu5_4 | VGG19 conv1-conv5(激活前) | VGG19 conv1-conv5 | VGG19 conv1-conv5(激活前) |
| 训练技巧 | 无特殊技巧 | 指数移动平均(EMA) 相对论GAN损失 | 指数移动平均(EMA) | 指数移动平均(EMA) 锐化真值训练(Real-ESRGAN+) |
| 核心创新点 | 1. 首次将GAN引入超分领域 2. 提出感知损失+GAN损失的组合 3. 用Pixel Shuffle替代转置卷积 | 1. 提出RRDB残差密集块 2. 改进相对论GAN损失 3. 优化感知损失计算 | 1. 随机打乱退化流程 2. 实用化退化参数设置 3. 带SN的VGG判别器 | 1. 二阶高阶退化建模 2. Sinc滤波器模拟振铃伪影 3. U-Net+SN判别器 4. 纯合成数据泛化到真实世界 |
| 适用场景 | 理想双三次退化图像 仅学术研究使用 | 理想双三次退化图像 如游戏截图、高清图压缩 | 一般真实世界图像 泛化性有限 | 绝大多数真实世界复杂退化图像 包括老照片、网图、手机拍照、扫描件 |
| 典型NIQE分数(越低越好) | RealSR-Canon: >7.0 DRealSR: >9.0 | RealSR-Canon: 6.7715 DRealSR: 8.6335 | RealSR-Canon: 5.7489 DRealSR: 6.1362 | RealSR-Canon: 4.5899 DRealSR: 4.9796 |
【GAN与UltimateSDUpscale组合进行超分辨率AI图像创作生成】
UltimateSDUpscale ComfyUI地址:ComfyUI_UltimateSDUpscale
UltimateSDUpscale WebUI地址:ultimate-upscale-for-automatic1111
- 首先使用GAN模型(AuraSR、R-ESRGAN 4x+ Anime6B等)对图像进行超分辨率重建(4x、2x等)。
- 在获得高分辨率图像后,再使用UltimateSDUpscale框架对高分辨率图像进行切片(tiles),获得多个切片图像。
- 接着再使用SD系列模型对每个切片图像进行图生图(img2img)重新绘制(inpaints)。
- 最后将重绘好的切片图像进行拼接融合,再对各边缘进行伪影抑制处理(Seams fix)。
4.3 GAN模型在盲人脸修复场景的应用
GFPGAN(Generative Facial Prior GAN)是腾讯PCG应用研究中心(ARC)提出的真实场景盲人脸修复模型,核心突破是将预训练人脸StyleGAN中封装的丰富生成先验融入修复流程,在单次前向推理中实现人脸修复的真实感与保真度的平衡,同时完成细节修复与色彩增强,解决了传统方法在真实低质人脸场景下效果差、泛化弱、落地难的核心痛点。
盲人脸修复的目标是从存在未知退化(低分辨率、模糊、噪声、JPEG压缩伪影等)的低质人脸中,恢复出高保真、高真实感的高清人脸。传统方法存在两大核心瓶颈:
- 几何先验失效:依赖人脸关键点、解析图、组件热力图等几何先验,但极低质输入下无法准确估计这些先验,且其仅能提供几何约束,缺少纹理、色彩等细节信息;
- 参考先验落地难:需要同身份的高质量参考图或人脸组件字典,现实中高质量参考图难以获取,字典的容量有限,无法覆盖人脸的多样性,对头发、耳朵、人脸轮廓等非字典区域修复效果差;
- GAN反演方法缺陷:传统GAN反演需将低质图像映射到预训练GAN的潜码空间,再通过逐图迭代优化生成结果,推理成本极高,且低维潜码无法精准保留输入人脸的身份与细节,保真度严重不足。
GFPGAN的核心逻辑是利用预训练人脸GAN(StyleGAN2)中隐式编码的生成人脸先验(Generative Facial Prior, GFP),替代传统的几何/参考先验,通过精细化的网络设计与损失约束,将生成先验无缝融入修复流程,在单次前向推理中实现真实感与保真度的较好平衡。
- 预训练的StyleGAN2在大规模人脸数据上学习到了人脸的几何结构、纹理细节、色彩分布等丰富且通用的先验知识,这些知识封装在模型权重中,无需从低质输入中估计,从根源上解决了传统先验的失效问题;
- 摒弃传统GAN反演的迭代优化模式,通过潜码映射+多分辨率通道拆分空间特征调制(CS-SFT),既利用GAN先验生成高真实感的人脸细节,又精准保留输入人脸的身份、姿态、表情等核心信息;
- 借助生成先验中包含的色彩先验,实现人脸修复与色彩增强/黑白上色的端到端联合处理,无需额外模型分支。
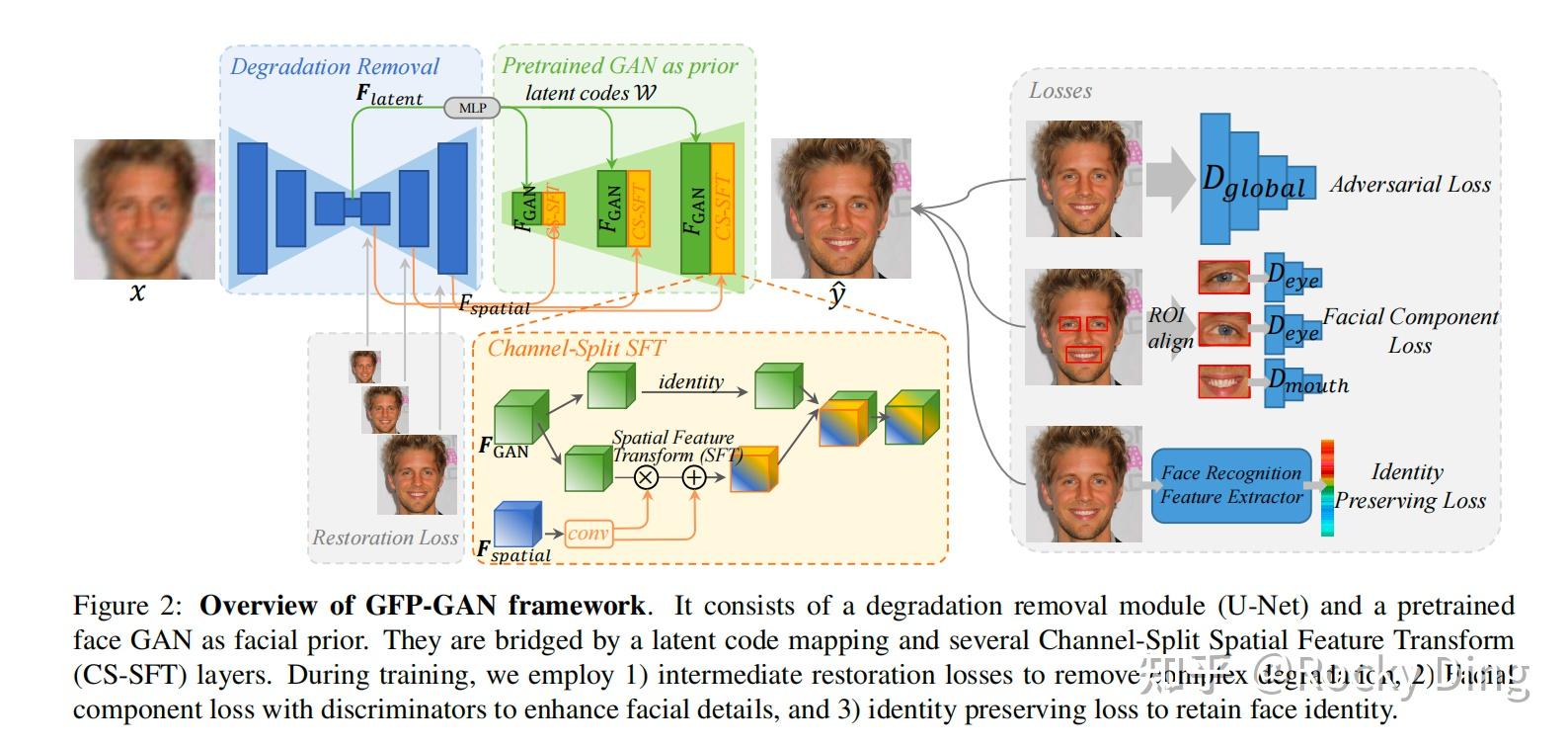
【GFPGAN模型架构】
GFPGAN是端到端的编解码架构,核心由退化去除模块、生成人脸先验模块、CS-SFT桥接模块、多维度损失约束模块四大部分组成,整体架构如下图所示:
低质人脸输入 → 退化去除U-Net → 潜特征Flatent + 多分辨率空间特征Fspatial
↓ ↓
潜码映射MLP → StyleGAN2 → GAN特征FGAN → CS-SFT层(粗到细)→ 修复高清人脸输出退化去除模块。该模块采用7次下采样+7次上采样的U-Net结构,每个采样单元均包含残差块,是模型的前置核心模块,核心作用有两点:
- 显式去除输入图像中的混合退化(模糊、噪声、压缩伪影、低分辨率等),降低后续模块的处理负担;
- 提取两类核心特征:
- 潜特征Flatent:用于映射到StyleGAN2的潜空间,找到与输入人脸最匹配的潜码;
- 多分辨率空间特征Fspatial:用于后续对StyleGAN2的特征进行空间调制,保留输入的空间与身份信息。
同时,该模块引入金字塔重建损失做中间监督:对U-Net解码器每个分辨率的输出都施加L1损失,约束其与真值图像的高斯金字塔对齐,强化模型对复杂退化的去除能力。
生成人脸先验与潜码映射模块。该模块以预训练的512×512分辨率StyleGAN2为核心载体,是生成人脸先验(GFP)的来源,核心流程为:
- 潜码映射:U-Net输出的Flatent通过多层线性层(MLP),映射到StyleGAN2的中间潜空间W(相比原始Z空间,W空间能更好地保留人脸语义一致性);
- GAN特征生成:映射得到的潜码W输入到StyleGAN2的每一层卷积中,生成不同分辨率的中间特征FGAN。这些特征封装了预训练阶段学到的人脸纹理、几何、色彩等丰富先验,为修复提供充足的细节支撑;
- 额外能力:该模块的生成先验天然包含色彩分布信息,可直接支持黑白照片上色、老旧照片色彩还原,实现修复与色彩增强的联合处理。
通道拆分空间特征变换(CS-SFT)层。CS-SFT层是连接退化去除模块与预训练GAN模块的核心桥接,也是模型的核心创新单元,解决了生成先验融入时"真实感与保真度难以平衡"的行业难题。
- 基础SFT原理:传统空间特征变换(SFT)通过输入的空间特征生成仿射变换参数(α,β),对GAN特征做逐空间位置的缩放与偏移,公式为: F o u t p u t = α ⊙ F G A N + β F_{output} = \alpha \odot F_{GAN} + \beta Foutput=α⊙FGAN+β 全通道SFT会让输出过度偏向低质输入,丢失GAN先验带来的真实感;而完全不做空间调制,仅靠潜码映射,又会严重丢失输入人脸的身份保真度。
- CS-SFT创新设计:在通道维度将FGAN拆分为两个分支:
- 分支1:恒等映射分支,直接保留原始GAN特征,确保生成结果的真实感,充分利用生成人脸先验;
- 分支2:SFT调制分支,用输入的Fspatial生成的α、β做空间特征变换,保留输入人脸的空间、身份、表情信息,确保保真度; 最终将两个分支的特征在通道维度拼接,公式为: F o u t p u t = C o n c a t I d e n t i t y ( F G A N s p l i t 0 ) , α ⊙ F G A N s p l i t 1 + β F_{output} = Concat\leftIdentity(F_{GAN}\^{split0}), \\alpha \\odot F_{GAN}\^{split1} + \\beta\\right Foutput=ConcatIdentity(FGANsplit0),α⊙FGANsplit1+β
- 部署方式:CS-SFT层以从粗到细的方式,部署在StyleGAN2的每个分辨率层级,实现多尺度的特征调制,同时降低了调制所需的计算量,提升了推理效率。
多维度损失约束模块。模型的整体训练目标由4类损失组合而成,公式为:
L t o t a l = L r e c + L a d v + L c o m p + L i d \mathcal{L}{total} = \mathcal{L}{rec} + \mathcal{L}{adv} + \mathcal{L}{comp} + \mathcal{L}_{id} Ltotal=Lrec+Ladv+Lcomp+Lid
通过多维度损失约束,同时保障修复结果的像素一致性、真实感、细节精度与身份保真度。
| 损失类型 | 核心构成与作用 |
|---|---|
| 重建损失 | 由L1像素损失+VGG-19感知损失构成,约束修复结果与真值在像素空间和深层特征空间的一致性,减少基础重建误差 |
| 对抗损失 | 采用全局判别器的逻辑斯蒂损失(与StyleGAN2一致),推动修复结果贴近真实人脸的自然分布,生成逼真的人脸纹理,避免过度平滑 |
| 人脸组件损失 | 针对人眼、嘴巴等视觉敏感区域,通过ROI Align裁剪对应区域,训练独立的局部判别器;同时加入基于Gram矩阵的特征风格损失,匹配真实与修复区域的纹理统计特性,大幅提升关键区域的细节真实感,减少伪影 |
| 身份保持损失 | 基于预训练的ArcFace人脸识别模型,约束修复结果与真值在人脸特征空间的距离,确保修复后人脸身份不发生偏移,解决传统GAN方法易出现的"换脸"问题 |
GFPGAN的训练完全基于合成退化数据,同时构建了多维度测试集验证模型的泛化能力,具体构建方案如下:
- 基础训练数据集
模型的基础训练数据为FFHQ人脸数据集,该数据集包含70000张高质量高清人脸图像,覆盖不同种族、年龄、姿态、表情、光照条件,人脸多样性极强。训练阶段,所有图像均统一resize到512×512分辨率,为模型提供高质量的GroundTruth。
- 合成退化训练数据构建
为模拟真实世界中未知、混合的人脸退化,论文设计了通用的退化模型,对FFHQ的高清真值图像做随机退化处理,生成配对的低质训练输入,退化公式为:
x = ( y ⊛ k σ ) ↓ r + n δ J P E G q x = \left\\left(y \\circledast k_{\\sigma}\\right) \\downarrow_{r} + n_{\\delta}\\right{JPEG{q}} x=(y⊛kσ)↓r+nδJPEGq
退化流程与参数范围如下:
-
高斯模糊 :高清真值图像y与高斯模糊核 k σ k_\sigma kσ做卷积,核标准差σ从{0.2:10}中随机采样,模拟真实场景中的运动模糊、失焦模糊;
-
下采样:对模糊后的图像做缩放因子r的下采样,r从{1:8}中随机采样,模拟低分辨率退化;
-
高斯噪声添加 :添加加性高斯白噪声 n δ n_\delta nδ,噪声标准差δ从{0:15}中随机采样,模拟真实图像的传感器噪声、传输噪声;
-
JPEG压缩:对图像做JPEG压缩,质量因子q从{60:100}中随机采样,模拟图像压缩带来的块效应、伪影退化。
-
训练数据增强
训练阶段额外加入水平随机翻转 与颜色抖动增强策略,进一步提升模型对不同人脸姿态、色彩偏移场景的鲁棒性,同时强化模型的色彩增强与上色能力。
- 测试集构建
为全面验证模型效果,论文构建了1个合成测试集与3个真实世界测试集,所有测试集均与训练集无重叠:
- CelebA-Test:合成测试集,包含3000张CelebA-HQ测试集图像,采用与训练一致的退化方式生成低质输入,用于量化评估模型的基础修复能力;
- LFW-Test:真实场景测试集,从LFW野生人脸数据集的验证集中提取1711张低质人脸图像,验证模型在野生场景的泛化性;
- CelebChild-Test:真实场景测试集,包含180张名人童年低质人脸图像,多为黑白老照片,验证模型对儿童人脸、老照片的修复能力;
- WebPhoto-Test:真实场景测试集,从互联网爬取188张真实生活中的低质照片,提取407张人脸,包含严重退化、色彩失真的老旧照片,验证模型在极端真实场景的鲁棒性。
4.4 GAN与MultiDiffusion组合进行超高清图像的精细化生成
在AIGC时代中,通过GAN+MultiDiffusion的组合,我们能够在6-8G的显卡上基于Stable-Diffusion创作4K超清大图!
MultiDiffusion中主要包括MultiDiffusion和Mixture of Diffusers两种方式,其核心思路是先基于一个预训练完成的扩散模型,将输入的噪声图像划分区块,针对每一个区块分别进行图像的生成。但是存在的问题是,不同的区块之间可能会存在区块边缘不连贯的问题,因此MultiDiffusion将不同区块的不连续部分进行融合,然后送入一个全局去噪采样后,即能保证最终生成图像的一致性。
下面是MultiDiffusion的核心代码,其提取图像各区块,并进行去噪采样的过程就生动的展现出来了:
with torch.autocast('cuda'):
for i, t in enumerate(self.scheduler.timesteps):
count.zero_()
value.zero_()
for h_start, h_end, w_start, w_end in views:
# TODO we can support batches, and pass multiple views at once to the unet
latent_view = latent[:, :, h_start:h_end, w_start:w_end]
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latent_view] * 2)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeds)['sample']
# perform guidance
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_cond - noise_pred_uncond)
# compute the denoising step with the reference model
latents_view_denoised = self.scheduler.step(noise_pred, t, latent_view)['prev_sample']
value[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
count[:, :, h_start:h_end, w_start:w_end] += 1
# take the MultiDiffusion step
latent = torch.where(count > 0, value / count, value)在每个区块生成的同时,对每个区块使用GAN模型进行超分辨率重建,即可在6-8G的显卡上生成4k的超清大图。
4.5 GAN模型在交互式生成/编辑场景的应用
DragGAN是2023年SIGGRAPH最佳论文之一,由马普所、MIT等机构联合提出,核心是通过"点拖拽"实现GAN生成图像的像素级精准、交互式编辑,同时保持生成结果的真实性。它解决了传统GAN编辑依赖标注/3D先验、灵活性差、精度低的问题,支持跨类别(人物、动物、汽车、风景)的姿态、形状、表情、布局编辑。
DragGAN有一个核心洞察,即GAN生成器的中间特征空间具有极强的判别性,足以同时支撑两个核心任务:
- 驱动图像内容向用户指定方向移动(运动监督)
- 精准跟踪编辑过程中手柄点的语义位置(点跟踪)
所有编辑操作都在GAN学习到的生成图像流形上进行,因此即使是遮挡内容生成(如狮子张嘴露出牙齿)、刚性形变(如马腿弯曲)也能保持真实感。
DragGAN基于StyleGAN2实现,核心依赖其隐码空间和分层生成机制:
- 隐码空间:512维的
w空间(全局一致)和更灵活的w+空间(每层独立隐码,支持更精细编辑) - 分层控制:前6层主要控制图像的空间属性(姿态、形状),后层仅影响外观(纹理、颜色)
- 中间特征:生成器第6个block的特征图(256×256)在分辨率和判别性之间达到最优平衡,是DragGAN的核心计算载体
DragGAN的整体工作流程:
用户只需在图像上点击定义手柄点(红色,要移动的点)和目标点(蓝色,要到达的位置) ,可选绘制掩码(指定可编辑区域),系统通过迭代优化+点跟踪完成编辑:
- 初始化 :获取初始图像对应的隐码
w和生成器第6层的特征图F₀ - 迭代循环(通常30-200次,直到手柄点到达目标): (1)运动监督:通过损失函数优化隐码,使手柄点向目标点移动一小步。(2)点跟踪:在更新后的特征图上,重新定位手柄点的语义位置
- 终止:当所有手柄点与对应目标点的距离小于阈值(1-2像素)时停止
DragGAN有两大核心组件。
- 运动监督(Motion Supervision)
目标:不依赖任何额外网络,通过优化隐码驱动手柄点向目标点移动。核心机制为移位特征块损失,定义为:
L = ∑ i = 0 n ∑ q i ∈ Ω 1 ( p i , r 1 ) ∥ F ( q i ) − F ( q i + d i ) ∥ 1 + λ ∥ ( F − F 0 ) ⋅ ( 1 − M ) ∥ 1 \mathcal{L}=\sum_{i=0}^{n} \sum_{q_{i} \in \Omega_{1}\left(p_{i}, r_{1}\right)}\left\| F\left(q_{i}\right)-F\left(q_{i}+d_{i}\right)\right\| {1}+\lambda\left\| \left(F-F{0}\right) \cdot(1-M)\right\| _{1} L=i=0∑nqi∈Ω1(pi,r1)∑∥F(qi)−F(qi+di)∥1+λ∥(F−F0)⋅(1−M)∥1
其中各参数含义:
- p i p_i pi :第i个手柄点
- t i t_i ti :第i个目标点
- d i d_i di :从 p i p_i pi 指向 t i t_i ti 的单位向量
- Ω 1 ( p i , r 1 ) \Omega_1(p_i, r_1) Ω1(pi,r1) :以 p i p_i pi 为中心、半径 r 1 r_1 r1 的局部特征块
- F ( q ) F(q) F(q) :特征图F在像素q处的特征值
- M M M :用户指定的可编辑区域掩码
- λ \lambda λ :非编辑区域的权重系数(默认20)
- 单向梯度传播 :反向传播时不通过 F ( q i ) F(q_i) F(qi)计算梯度,确保只有手柄点向目标移动,而非目标向手柄点移动
- 分层隐码优化:仅优化StyleGAN2前6层的隐码,固定后层,保证编辑过程中图像外观(纹理、颜色)不变
- 掩码约束:第二项损失强制非掩码区域的特征与初始特征一致,实现"局部编辑、全局固定"
- 点跟踪(Point Tracking)
目标:在每次隐码优化后,精准更新手柄点的语义位置,避免后续运动监督作用于错误区域。
核心机制为特征空间最近邻搜索。传统点跟踪依赖光流模型(如RAFT、PIPs),存在效率低、累积误差大的问题。DragGAN直接利用GAN自身的特征判别性实现跟踪:
- 保存初始手柄点 p i p_i pi对应的特征 f i = F 0 ( p i ) f_i=F_0(p_i) fi=F0(pi)
- 隐码优化后,得到新的特征图 F ′ F' F′
- 在以当前 p i p_i pi为中心、半径 r 2 r_2 r2的局部窗口 Ω 2 ( p i , r 2 ) \Omega_2(p_i, r_2) Ω2(pi,r2)内,搜索与 f i f_i fiL1距离最小的特征点,作为新的手柄点位置: p i : = a r g m i n q i ∈ Ω 2 ( p i , r 2 ) ∥ F ′ ( q i ) − f i ∥ 1 p_{i}:=\underset{q_{i} \in \Omega_{2}\left(p_{i}, r_{2}\right)}{arg min }\left\| F'\left(q_{i}\right)-f_{i}\right\| _{1} pi:=qi∈Ω2(pi,r2)argmin∥F′(qi)−fi∥1优势:
- 无需额外训练或加载跟踪模型,计算效率极高
- 避免了光流模型在GAN生成图像上的伪影和漂移问题
- 实验证明其跟踪精度优于RAFT和PIPs(人脸关键点跟踪平均误差仅2.44像素)
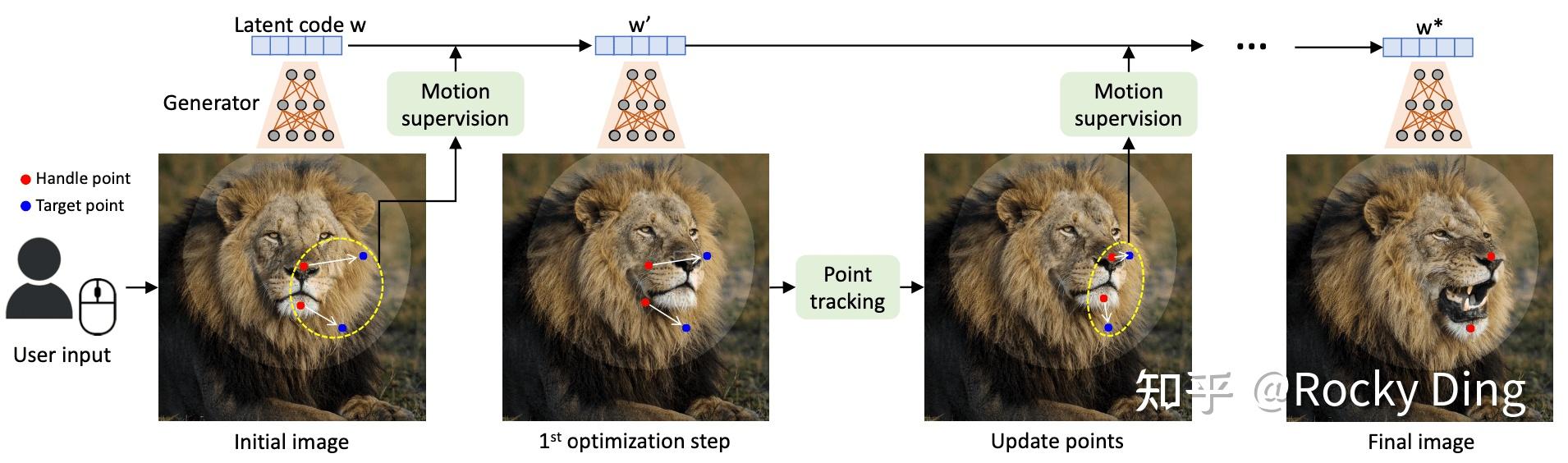
DragGAN的核心优势:
- 三性统一:同时满足灵活性(多属性编辑)、精度(像素级)、通用性(跨类别)
- 无额外依赖:仅需预训练StyleGAN2,无需标注数据、3D模型或辅助网络
- 实时交互:单张RTX 3090 GPU上单次编辑仅需2秒左右
- 真实感强:在生成流形上编辑,能自动生成遮挡内容并遵循物体刚性约束
DragGAN的局限性:
- 编辑质量依赖训练数据多样性,超出分布的姿态/形状会产生伪影
- 无纹理区域(如纯色墙面)的手柄点容易发生跟踪漂移
- 目前仅支持StyleGAN2架构,尚未扩展到扩散模型
5. StyleGAN系列模型基础知识详解
5.1 StyleGAN 系列的核心设计思想
StyleGAN 系列是 NVIDIA Tero Karras 团队打造的里程碑式生成对抗网络,从 2018 年首次提出至今,围绕生成质量、可控性、解耦性、训练稳定性、小数据适配、几何等变性六大核心方向持续迭代,彻底改变了高保真图像生成的技术范式。
在人脸高保真生成领域 ,在 StyleGAN 之前的 GAN 模型的生成器是典型的 "黑盒",即输入隐向量 z z z 直接送入网络,通过前馈网络逐层上采样生成图像。这种设计存在三个缺陷:
- 隐空间严重纠缠: 输入隐空间 Z Z Z 必须贴合训练数据的分布,导致不同语义特征(如人脸的姿态、性别、年龄)高度耦合,无法独立控制;
- 生成过程不可控: 无法分层控制图像的高层语义与底层细节,插值效果非线性严重,易出现特征突变;
- 随机细节生成低效: 网络需要消耗大量容量从隐向量中生成伪随机细节(如毛发、雀斑),易出现重复纹理和伪影。
StyleGAN 系列的核心突破,是借鉴风格迁移的思想,将图像生成拆解为 "风格编码" 与 "分层合成" 两个独立过程,通过中间隐空间 W W W 实现特征解耦,通过逐层风格调制实现对生成过程的细粒度控制,从根本上解决了在人脸高保真领域传统 GAN 的黑盒问题。
同时,所有StyleGAN系列的人脸编辑功能,都建立在同一个核心假设之上:人脸的所有语义属性,都对应隐空间中的一个线性方向。
编辑的过程,就是在隐空间中沿着某个语义方向,对隐向量 W W W 进行线性偏移:
w ′ = w + α ⋅ d w' = w + \alpha \cdot d w′=w+α⋅d
其中:
- w w w :原始人脸的风格向量
- d d d :对应某个属性(如性别、年龄、微笑)的单位方向向量
- α \alpha α :编辑强度(正负表示属性的两个方向,如+α=变老,-α=变年轻)
StyleGAN系列的所有改进,本质都是让这个假设更接近现实。这个假设的成立程度,直接决定了编辑的精度、平滑性和无副作用程度。
主流的编辑方式分为风格特征差值、风格特征混合和隐空间向量运算,接下来Rocky带着大家详细了解三种编辑方式。
【风格特征插值:两个创意的"无缝渐变"】
StyleGAN的风格向量 w w w 空间都是连续的欧几里得空间 。这意味着:如果我们有两个风格特征A和B,把它们转换成风格向量 w A w_A wA 和 w B w_B wB ,那么对这两个向量做线性插值 (加权平均),得到的中间向量w_interp = α*w_A + (1-α)*w_B(α从0到1),对应的图像就是从A到B的平滑过渡。
值得注意的是:插值的是"语义特征",也不是两张图的像素拼接。
Rocky举一个通俗的例子通俗,假设我们取四个角落的风格特征:
- 左上角:"现代风格的白色别墅,晴天"
- 右上角:"维多利亚风格的复古别墅,晴天"
- 左下角:"现代风格的白色别墅,日落"
- 右下角:"维多利亚风格的复古别墅,日落"
我们固定同一个随机隐向量z(保证整体构图、视角完全一致),然后对风格向量做二维插值:
- α=0.0:完全是左上角的现代白别墅晴天
- α=0.3:房子还是现代风格,但开始出现复古的雕花装饰,天空微微泛黄
- α=0.5:房子一半现代一半复古,天空是晴天到日落的过渡色
- α=0.7:房子变成维多利亚风格为主,天空变成橙红色
- α=1.0:完全是右下角的复古别墅日落
效果航整个过渡过程没有任何断层,房子的结构、风格、光影、天空颜色都是连续变化的,就像看一个"创意渐变动画"。
【风格特征混合:"结构不变,风格随便换"】
风格特征混合的本质就是:用风格向量A控制前几层(保留A的结构和布局),用风格向量B控制后几层(替换成B的风格和细节)。
Rocky接着举一个通俗例子,比如我们固定结构,换材质/画风:
- 基础图像内容:"一个立方体放在木质桌子上"(生成一个普通的白色立方体)
- 风格特征B1:"牛仔布纹理"
- 风格特征B2:"梵高油画风格"
- 风格特征B3:"金属拉丝质感"
操作:用A的风格向量控制前3层(保留"立方体在桌子上"的布局),用B1/B2/B3的风格向量控制后5层(替换细节)。
- 结果1:桌子上放着一个牛仔布做的立方体,纹理清晰,桌子还是木质的
- 结果2:桌子上放着一个梵高油画风格的立方体,笔触明显,整体色调是梵高的黄蓝色
- 结果3:桌子上放着一个银色金属拉丝的立方体,反光效果逼真
我们还可以固定物体,换场景/光影:
- 基础图像内容 A:"一只猫坐在草地上"
- 风格特征 B:"夜晚星空下,月光照亮"
操作:保留A的前几层(猫的姿态、位置),替换后几层为B的风格。
- 结果:还是那只猫,还是那个坐姿,但背景变成了星空,猫身上有月光的冷色调反光,草地变成了夜晚的暗绿色。
【隐空间向量运算:"加减属性,精准控图"】
我们已经知道在StyleGAN的 w w w 隐空间中,特定的方向对应着特定的语义属性。比如,存在一个"戴眼镜"的方向向量v_glasses,一个"女性化"的方向向量v_female,一个"变老"的方向向量v_old。
隐空间向量运算的本质就是:在基础图像的隐向量上,加上或减去某个属性的方向向量,就能让图像获得或失去对应的属性。
公式:w_new = w_base + λ * v_attribute
- λ是强度系数,λ越大,属性越明显;λ为负就是反向属性(比如"变年轻"就是减去v_old)。
Rocky举一个经典的"眼镜运算"例子:
- 基础向量w_man:对应图像"一个没戴眼镜的年轻男人"
- 向量w_man_glasses:对应图像"一个戴眼镜的年轻男人"
- 计算"戴眼镜"的方向向量:v_glasses = w_man_glasses - w_man
然后我们就可以用这个方向向量,给任意人脸加眼镜:
- w_woman + v_glasses:得到"一个戴眼镜的年轻女人"
- w_old_man + 1.5 * v_glasses:得到"一个戴厚眼镜的老年男人"
- w_man - 0.5 * v_glasses:得到"一个戴很薄眼镜的年轻男人"
更多常见的属性运算:
| 基础图像 | 运算操作 | 结果图像 |
|---|---|---|
| 短发女人 | + v_long_hair | 长发女人 |
| 微笑的猫 | + v_angry | 生气的猫 |
| 白天的街道 | + v_night | 夜晚的街道 |
| 普通汽车 | + v_sports_car | 跑车 |
最后,Rocky总结了三者的核心概念对比表:
| 功能 | 核心操作 | 控制粒度 | 典型应用 | 扩散模型替代方案 | GAN优势 |
|---|---|---|---|---|---|
| 风格特征插值 | 两个风格向量线性加权 | 整体语义过渡 | 创意渐变、关键帧生成 | 无(插值效果差) | 丝滑无断层,语义连贯 |
| 风格特征混合 | 前几层用A,后几层用B | 结构与风格分离 | 换材质、换画风、换光影 | ControlNet+Inpaint | 无需额外输入,结构保真 |
| 隐空间向量运算 | 加减属性方向向量 | 单个语义属性 | 人脸编辑、属性调整 | LoRA+Inpaint | 精准可控,可预测性强 |

5.2 StyleGAN1的核心原理
StyleGAN1 是系列的开山之作,首次提出了基于风格的生成器架构,彻底重构了传统GAN的生成器设计。主要来解决在人脸高保证领域传统 GAN 生成器的黑盒特性、隐空间纠缠、分层可控性缺失、随机细节与高层语义无法解耦的问题。
StyleGAN中的**"Style"**是指训练数据集中人脸的主要属性,比如人物的姿态等信息,而不是风格转换中的图像风格,这里Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。
总的来说,StyleGAN 用风格(style)特征来影响人脸的姿态、身份特征等,用独立噪声 ( noise )特征来影响头发丝、皱纹、肤色等细节部分。
可能有读者会有疑问,上述的功能是如何实现的呢?Don't Worry,Rocky在接下来的章节中将为大家娓娓道来,深入浅出讲解StyleGAN的本质原理与思想。
【StyleGAN1的整体架构】
StyleGAN1的生成器分为映射网络(Mapping Network) 、合成网络(Synthesis Network)两大核心模块,辅以显式噪声输入 、AdaIN(自适应实例归一化)风格调制 和 混合正则化(Mixing Regularization) 三大关键机制,整体结构如下:
输入z(512维高斯) → 映射网络(8层MLP) → 中间隐向量w(512维)
↓
仿射变换(A模块) → 风格向量y
↓
常量输入(4×4×512) → 合成网络(18层卷积) → 生成图像(1024×1024)
↑
逐层高斯噪声输入(B模块)映射网络 f : Z → W f: Z → W f:Z→W 包含8层全连接MLP,输入输出均为512维,将服从标准高斯分布的输入隐向量 z z z 映射到中间隐空间 W W W 。
为什么使用 w w w 空间,而不是原始 z z z 空间呢 ?
经典GAN的输入 z z z 直接从高斯分布采样,存在严重的 特征纠缠 。StyleGAN1论文中通过实验证明:
- z z z 空间是纠缠的:单个维度的变化会同时影响多个语义属性
- w w w 空间是部分解耦的:不同维度的变化更倾向于对应独立的语义属性
- 映射网络能够一定程度上"拉直"隐空间,将扭曲的高斯分布 z z z ,映射为更均匀、更线性的 w w w 分布
合成网络 g g g 摒弃了传统GAN将 z z z 直接输入的设计,而是从一个固定的4×4×512可学习常量张量开始生成 ,完全通过风格向量控制生成过程。合成网络 g g g 共18层卷积,对应从4×4到1024×1024的9个分辨率,每个分辨率包含2层卷积;每层的核心执行模块为:3×3卷积 → 显式噪声注入 → AdaIN风格调制 → 非线性激活,低分辨率层后接2倍上采样。
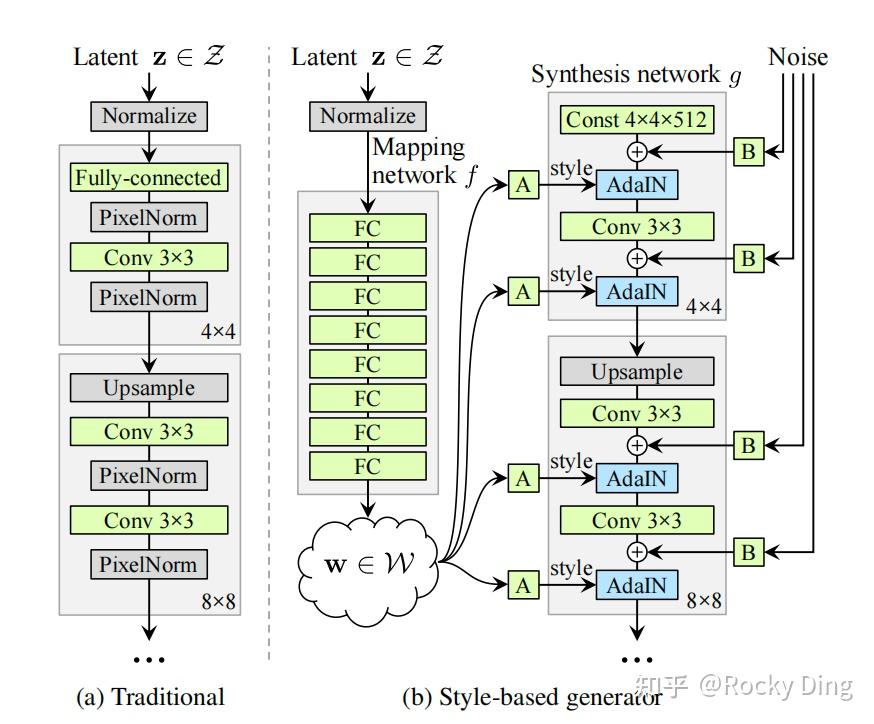
StyleGAN的生成器架构
其中AdaIN风格调制 是风格控制的核心算子,公式如下:
A d a I N ( x i , y ) = y s , i x i − μ ( x i ) σ ( x i ) + y b , i AdaIN\left( x_{i},y\right) =y_{s,i} \frac {x_{i}-\mu (x_{i})}{\sigma (x_{i})}+y_{b,i} AdaIN(xi,y)=ys,iσ(xi)xi−μ(xi)+yb,i
其中 x i x_i xi 是卷积输出的第 i i i 个特征图, y = ( y s , y b ) y=(y_s, y_b) y=(ys,yb) 是风格向量,由 w w w 通过仿射变换得到: y i = A i ⋅ w + b i y_i = A_i \cdot w + b_i yi=Ai⋅w+bi 。
接着将 y i y_i yi 按通道维度拆分为两部分,即得到该层的风格参数:
y i = y s , i y b , i y_i = \begin{bmatrix} y_{s,i} \\ y_{b,i} \end{bmatrix} yi=ys,iyb,i
先对每个特征图做实例归一化(零均值、单位方差),消除原有特征的统计信息;再用风格向量的缩放 y s y_s ys 和偏置 y b y_b yb 重新调制特征,实现风格对图像特征的控制。
显式噪声输入 同样是StyleGAN精妙的设计之一,为合成网络的每一层都注入独立的单通道高斯噪声,通过可学习的通道级缩放因子,加到卷积输出的特征图上。
x i ′ = x i + σ i ⊙ n i x_i' = x_i + \sigma_i \odot n_i xi′=xi+σi⊙ni
其中:
- x i x_i xi :第 i i i 层卷积操作的输出特征图,维度为 R d i × H i × W i \mathbb{R}^{d_i \times H_i \times W_i} Rdi×Hi×Wi (通道×高度×宽度)
- n i n_i ni :第 i i i 层的显式噪声图,维度为 R 1 × H i × W i \mathbb{R}^{1 \times H_i \times W_i} R1×Hi×Wi ,从标准高斯分布 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1) 中独立采样
- σ i \sigma_i σi :第 i i i 层的可学习缩放参数向量,维度为 R d i \mathbb{R}^{d_i} Rdi (每个通道一个独立的缩放因子)
- ⊙ \odot ⊙ :广播逐元素相乘(噪声图 n i n_i ni 会被广播到所有 d i d_i di 个通道)
这样做的核心作用是将图像的 细节特征(毛发、雀斑、皮肤毛孔、背景纹理) 与高层语义(身份、姿态)完全解耦,显式噪声仅影响局部细节特征,不改变全局语义和整体构图。它将生成器从 "既要生成语义结构,又要生成细节特征" 的双重负担中解放,让风格向量专注于编码语义信息,让显式噪声专注于编码细节信息,从而实现了生成质量和真实感的巨大飞跃。
而 混合正则化(Mixing Regularization) 则是在训练时,随机选取一定比例的图像,用两个随机隐向量 z 1 / z 2 z1/z2 z1/z2 生成 w 1 / w 2 w1/w2 w1/w2 ,在合成网络的随机选择一层切换风格( w 1 w1 w1 控制最一层和之前的所有层, w 2 w2 w2 控制后续层)。
Rocky接下来对混合正则化技术进行深入浅出的讲解,首先我们要求区分两个概念:
| 概念 | 阶段 | 目的 | 本质 |
|---|---|---|---|
| 混合正则化 | 训练阶段 | 正则化生成器,强制风格局部化 | 一种训练技巧,提升模型的分层控制能力 |
| 风格混合编辑 | 推理阶段 | 实现人脸特征融合 | 一种编辑方法,利用训练好的模型的分层特性 |
简单来说:混合正则化是"因",风格混合编辑是"果"。StyleGAN之所以能在推理时实现"换脸不换皮"、"换发型不换五官",完全是因为训练时用了混合正则化。
混合正则化的训练流程非常简单,在正常训练时,每个样本的生成过程是:
- 采样一个隐向量 z ∼ p z ( z ) z \sim p_z(z) z∼pz(z)
- 通过映射网络得到风格向量 w = f ( z ) w = f(z) w=f(z)
- 将同一个 w w w 输入到合成网络的所有层,生成图像 x = G ( w ) x = G(w) x=G(w)
在进行混合正则化训练流程时,对于每个训练样本,以固定概率触发混合正则化,流程如下:
- 独立采样两个完全无关的隐向量 z 1 , z 2 ∼ p z ( z ) z_1, z_2 \sim p_z(z) z1,z2∼pz(z)
- 通过映射网络得到两个独立的风格向量 w 1 = f ( z 1 ) , w 2 = f ( z 2 ) w_1 = f(z_1), w_2 = f(z_2) w1=f(z1),w2=f(z2)
- 随机选择一个交叉点 k ∈ { 1 , 2 , . . . , L − 1 } k \in \{1, 2, ..., L-1\} k∈{1,2,...,L−1},其中 L L L 是合成网络的总层数(1024×1024分辨率下 L = 18 L=18 L=18)
- 构造混合风格向量序列: w mix = w 1 , w 1 , . . . , w 1 ⏟ 前 k 层 , w 2 , w 2 , . . . , w 2 ⏟ 后 L − k 层 w_{\text{mix}} = \\underbrace{w_1, w_1, ..., w_1}_{前k层}, \\underbrace{w_2, w_2, ..., w_2}_{后L-k层} wmix=前k层 w1,w1,...,w1,后L−k层 w2,w2,...,w2
- 将混合风格序列输入合成网络,生成混合图像 x mix = G ( w mix ) x_{\text{mix}} = G(w_{\text{mix}}) xmix=G(wmix)
- 用混合图像 x mix x_{\text{mix}} xmix 代替正常图像 x x x 进行对抗训练,计算损失并更新参数
StyleGAN官方默认超参数:
- 混合概率:0.9(即90%的样本使用混合正则化,10%的样本使用正常的单风格训练)
- 交叉点范围:所有可能的层边界(1到L-1),均匀随机选择
- 适用范围:合成网络的所有层,没有例外
如果没有混合正则化,合成网络的所有层永远接收同一个风格向量 w w w。在这种情况下,网络会自发地学习到相邻层风格的强相关性:
知道了第 i i i层的风格参数,就可以几乎完美地预测第 i + 1 i+1 i+1层的风格参数。
这是因为,对于同一个 w w w,所有层的风格参数都是由同一个向量通过仿射变换得到的,它们之间天然存在相关性。网络会利用这种相关性来简化学习过程,导致:
- 分层控制失效:无法单独改变某一层的风格,改变一层必然会影响其他层
- 风格全局化:所有层都倾向于编码全局信息,而不是局部信息
- 推理时风格混合产生伪影:网络从来没有见过"前半部分是w1,后半部分是w2"的输入,会生成不真实的图像
这是混合正则化技术最精妙的地方,它通过随机打破相邻层的风格相关性,解决了上述的这些问题。在训练过程中,网络会不断遇到这样的情况:
- 第 i i i层的风格来自 w 1 w_1 w1,第 i + 1 i+1 i+1层的风格来自完全无关的 w 2 w_2 w2
- 交叉点 k k k是完全随机的,任何相邻层之间都可能被切断
为了在这种情况下仍然生成真实的图像,网络别无选择,只能学会:
每一层的风格参数,必须只包含该层所需的信息,不能依赖其他层的风格参数。
换句话说,网络必须将不同层级的语义信息,完全分离到不同的层中:
- 粗层只能编码全局结构信息(姿态、脸型),不能编码细层的纹理信息
- 细层只能编码局部细节信息(肤色、纹理),不能编码粗层的结构信息
这就是混合正则化的核心机制:它不是通过损失函数直接惩罚相关性,而是通过构造对抗性的训练样本,迫使网络为了生存而自发地去相关。
混合正则化不仅让层与层之间解耦,还让隐空间中的不同语义属性之间更加解耦,这是因为:
- 不同的语义属性天然对应不同分辨率的层
- 当层与层之间解耦后,对应不同层的语义属性自然也解耦了
论文中的定量实验表明,加入混合正则化后,隐空间的互信息gap提升了约40%,解耦性显著增强。
正是因为训练时网络已经见过了所有可能的交叉点组合,所以在推理时,我们可以任意选择交叉点,将任意两个人脸的风格混合,生成自然、无伪影的新图像。如果没有混合正则化,推理时的风格混合会产生严重的伪影,比如人脸的上半部分和下半部分脱节、五官错位等。并且混合正则化还有一个意外的好处:它相当于一种数据增强技术,增加了训练样本的多样性,从而轻微提升了训练稳定性和生成质量。论文中的消融实验显示,加入混合正则化后,FID分数降低了约5%,生成图像的真实感略有提升。
总的来说,Rocky认为它的核心逻辑可以用一句话概括:
通过在训练时随机切断相邻层的风格联系,迫使网络将不同层级的语义信息完全分离到不同的层中,从而实现真正的分层风格控制。
没有混合正则化,就没有StyleGAN强大的人脸编辑能力,也就没有后来基于StyleGAN的一系列编辑技术。最后在StyleGAN的推理实验中,通过不同变量的控制实验,得出了如下不同层的特征控制经验:
- 粗尺度层( 4 2 − 8 2 4^2-8^2 42−82 ):控制姿态、脸型、发型、眼镜等高层全局属性;
- 中尺度层( 16 2 − 32 2 16^2-32^2 162−322 ):控制面部细节、眼睛开合、发型细节等中层特征;
- 细尺度层( 64 2 − 1024 2 64^2-1024^2 642−10242 ):控制颜色、纹理、微观细节等底层像素特征。
5.3 StyleGAN2的核心改进
StyleGAN1虽然有很多开创性的贡献,但也有一些不足。比如AdaIN会带来的水滴状伪影、渐进式增长架构会导致图像相位不一致,同时StyleGAN本身存在高分辨率生成细节失真、训练稳定性不足的问题。
StyleGAN2 针对 StyleGAN1 生成图像的伪影问题进行了优化,同时进一步提升了隐空间解耦性和训练稳定性。
【权重解调(Weight Demodulation)】
在StyleGAN2中,使用权重解调(Weight Demodulation)替代了AdaIN。StyleGAN1的AdaIN会对每个特征图独立归一化,破坏了特征图之间的相对幅值关系,是伪影的核心来源。StyleGAN2将风格调制从激活层转移到卷积权重上:
- 先通过风格向量对卷积核进行调制(Modulation),缩放卷积核的输出通道;
- 再对调制后的卷积核做解调(Demodulation),对每个输出通道的权重做归一化,保证输出特征的标准差为1。
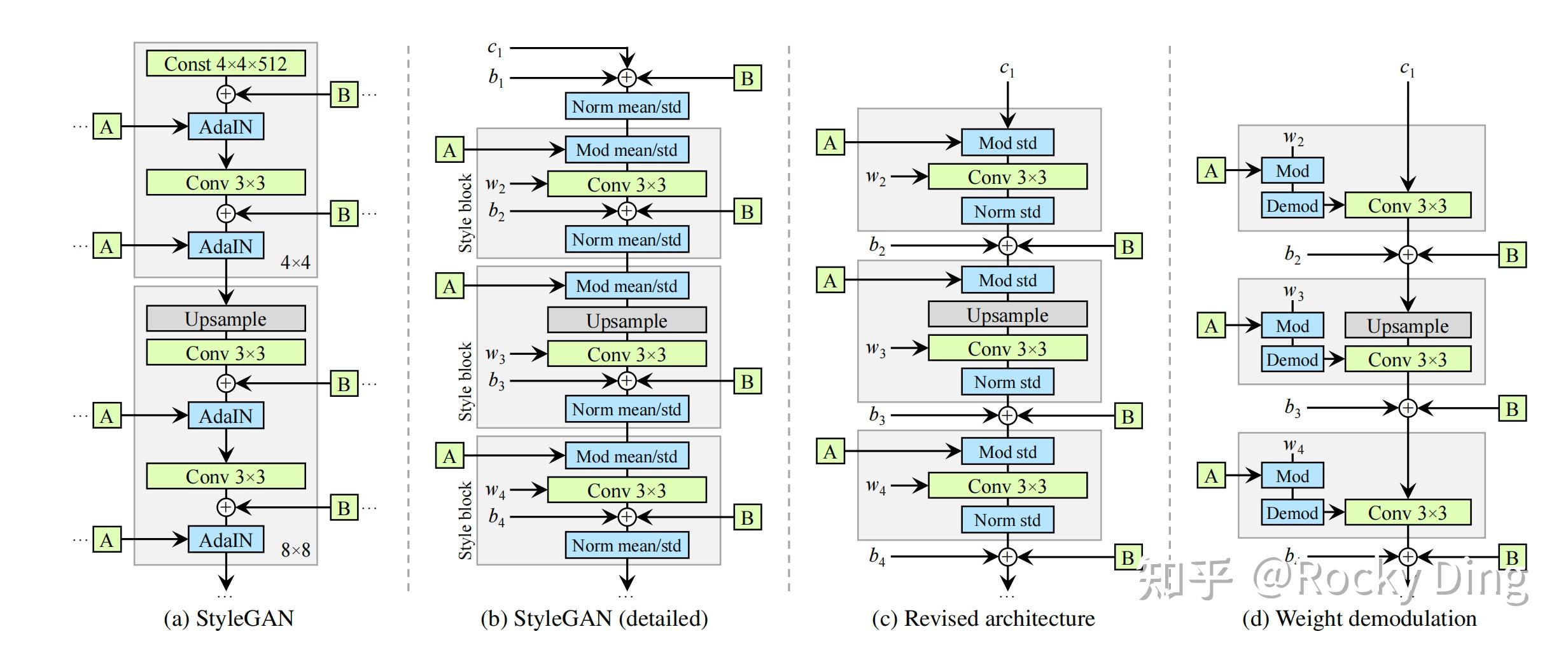
Rocky接下来详细讲解一下StyleGAN的权重调制和解调的完整流程。
StyleGAN2的天才之处,就是发现了一个极其简单但极其深刻的事实:
风格调制不需要在激活层进行,完全可以在卷积核上进行。
这个小小的位置移动,从根本上解决了AdaIN的所有问题。
我们先看一个标准卷积操作的数学表达式:
y j , k = ∑ i w i , j ⋅ x i , k y_{j,k} = \sum_{i} w_{i,j} \cdot x_{i,k} yj,k=i∑wi,j⋅xi,k
其中:
- x i , k x_{i,k} xi,k:输入特征图的第 i i i个通道,第 k k k个空间位置
- w i , j w_{i,j} wi,j:卷积核的权重,连接输入通道 i i i和输出通道 j j j
- y j , k y_{j,k} yj,k:输出特征图的第 j j j个通道,第 k k k个空间位置
现在,假设我们想对输入特征图的每个通道 i i i乘以一个缩放因子 s i s_i si(这就是风格调制的本质):
y j , k = ∑ i w i , j ⋅ ( s i ⋅ x i , k ) = ∑ i ( s i ⋅ w i , j ) ⋅ x i , k y_{j,k} = \sum_{i} w_{i,j} \cdot (s_i \cdot x_{i,k}) = \sum_{i} (s_i \cdot w_{i,j}) \cdot x_{i,k} yj,k=i∑wi,j⋅(si⋅xi,k)=i∑(si⋅wi,j)⋅xi,k
看到了吗?对输入特征图的缩放,完全等价于对卷积核的输入通道维度进行缩放。
这就是权重调制的核心思想:
我们不需要先对输入特征图做缩放,再做卷积;我们可以先对卷积核做缩放,再做卷积。两者的数学效果完全等价。
结合之前Rocky讲过的仿射变换层,权重调制的完整流程是:
- 风格向量 w w w通过仿射变换层,得到每个输入通道的缩放因子 s i s_i si: s = A ⋅ w + b , s ∈ R C in s = A \cdot w + b, \quad s \in \mathbb{R}^{C_{\text{in}}} s=A⋅w+b,s∈RCin
- 用 s i s_i si对卷积核的每个输入通道进行缩放: w i , j ′ = s i ⋅ w i , j w'{i,j} = s_i \cdot w{i,j} wi,j′=si⋅wi,j
- 用调制后的卷积核 w ′ w' w′进行标准卷积操作: y = Conv ( x , w ′ ) y = \text{Conv}(x, w') y=Conv(x,w′)
这就完成了风格信息的注入,完全不需要在激活层做任何操作。
现在权重调制解决了风格注入的问题,但它带来了一个新的问题:卷积核的缩放会导致输出特征图的标准差发生变化。
如果我们不对这个变化进行补偿,那么随着网络层数的加深,特征图的标准差会越来越大或越来越小,导致训练不稳定。这就是为什么我们需要权重解调。
假设输入特征图 x i x_i xi的每个元素都是独立同分布的随机变量,均值为0,标准差为1:
E x i = 0 , Var x i = 1 \mathbb{E}x_i = 0, \quad \text{Var}x_i = 1 Exi=0,Varxi=1
那么,卷积输出 y j y_j yj的方差为:
Var y j = Var ∑ i w i , j ′ ⋅ x i = ∑ i Var w i , j ′ ⋅ x i = ∑ i ( w i , j ′ ) 2 ⋅ Var x i = ∑ i ( s i ⋅ w i , j ) 2 \begin{align*} \text{Var}y_j &= \text{Var}\left \\sum_{i} w'_{i,j} \\cdot x_i \\right \\ &= \sum_{i} \text{Var}w'_{i,j} \\cdot x_i \\ &= \sum_{i} (w'{i,j})^2 \cdot \text{Var}x_i \\ &= \sum{i} (s_i \cdot w_{i,j})^2 \end{align*} Varyj=Vari∑wi,j′⋅xi=i∑Varwi,j′⋅xi=i∑(wi,j′)2⋅Varxi=i∑(si⋅wi,j)2
可以看到,输出特征图的方差完全由调制后的卷积核权重的平方和决定。如果 s i s_i si很大,那么输出方差也会很大;如果 s i s_i si很小,输出方差也会很小。这就是标准差漂移问题。
权重解调的目标非常明确:对调制后的卷积核进行归一化,使得每个输出通道的权重的平方和为1,从而保证输出特征图的标准差为1。
完整的解调公式是:
w i , j ′ ′ = w i , j ′ ∑ i ′ ( w i ′ , j ′ ) 2 + ϵ = s i ⋅ w i , j ∑ i ′ ( s i ′ ⋅ w i ′ , j ) 2 + ϵ w''{i,j} = \frac{w'{i,j}}{\sqrt{\sum_{i'} (w'{i',j})^2 + \epsilon}} = \frac{s_i \cdot w{i,j}}{\sqrt{\sum_{i'} (s_{i'} \cdot w_{i',j})^2 + \epsilon}} wi,j′′=∑i′(wi′,j′)2+ϵ wi,j′=∑i′(si′⋅wi′,j)2+ϵ si⋅wi,j
其中:
- ϵ \epsilon ϵ是一个很小的常数,用于防止除以零,官方代码中取 ϵ = 10 − 8 \epsilon=10^{-8} ϵ=10−8
- 归一化是在输入通道维度 上进行的,对每个输出通道 j j j独立计算
现在,我们再计算解调后的卷积输出的方差:
Var y j = ∑ i ( w i , j ′ ′ ) 2 = ∑ i ( s i ⋅ w i , j ) 2 ∑ i ′ ( s i ′ ⋅ w i ′ , j ) 2 + ϵ ≈ 1 \begin{align*} \text{Var}y_j &= \sum_{i} (w''{i,j})^2 \\ &= \sum{i} \frac{(s_i \cdot w_{i,j})^2}{\sum_{i'} (s_{i'} \cdot w_{i',j})^2 + \epsilon} \\ &\approx 1 \end{align*} Varyj=i∑(wi,j′′)2=i∑∑i′(si′⋅wi′,j)2+ϵ(si⋅wi,j)2≈1
我们可以看到,权重解调保证了无论风格缩放因子 s i s_i si是多少,输出特征图的标准差始终近似为1。这就解决了标准差漂移问题,保证了训练的稳定性。
总的来说,这样的设计既保留了风格控制的能力,又完全保留了特征的空间相关性,消除了AdaIN带来的伪影,同时保持了前向传播的高效性。
【摒弃渐进式增长,重构多尺度架构】
此外,StyleGAN1继承了Progressive GAN的渐进式训练(从4×4逐步增长到1024×1024),虽提升了训练稳定性,但会导致生成特征的相位不一致,物体细节在分辨率增长时出现错位。
基于这个问题,StyleGAN2做了两大改进:
- 用残差连接+双线性上/下采样替代渐进式增长,保证高低分辨率特征的相位对齐;
- 用跳连结构重构生成器/判别器,生成器用残差块,判别器用残差连接,大幅提升高分辨率图像的生成质量和训练稳定性。
具体来说,它的核心思想是将跳跃连接从RGB空间移到特征空间,实现最高效的多尺度信息融合。
生成器结构(上图(c)上半部分,灰色标注):
- 彻底移除了所有低分辨率的tRGB层,只保留最高分辨率的一个tRGB层作为最终输出
- 每个分辨率块先进行
Up上采样,然后与下一个高分辨率块的输出逐元素相加(残差连接) - 完整数据流: Feat 256 → Up Feat 512 → + Feat 512 ′ → Up Feat 1024 → + Feat 1024 ′ → tRGB Output \text{Feat}{256} \xrightarrow{\text{Up}} \text{Feat}{512} \xrightarrow{+} \text{Feat}{512}' \xrightarrow{\text{Up}} \text{Feat}{1024} \xrightarrow{+} \text{Feat}_{1024}' \xrightarrow{\text{tRGB}} \text{Output} Feat256Up Feat512+ Feat512′Up Feat1024+ Feat1024′tRGB Output
判别器结构(上图(c)下半部分,绿色标注):
- 彻底移除了所有低分辨率的fRGB层,只保留最高分辨率的一个fRGB层作为输入
- 每个分辨率块先进行
Down下采样,然后与下一个低分辨率块的输出逐元素相加(残差连接) - 完整数据流: Input → fRGB Feat 1024 → Down Feat 512 → + Feat 512 ′ → Down Feat 256 → + Feat 256 ′ → Output \text{Input} \xrightarrow{\text{fRGB}} \text{Feat}{1024} \xrightarrow{\text{Down}} \text{Feat}{512} \xrightarrow{+} \text{Feat}{512}' \xrightarrow{\text{Down}} \text{Feat}{256} \xrightarrow{+} \text{Feat}_{256}' \xrightarrow{} \text{Output} InputfRGB Feat1024Down Feat512+ Feat512′Down Feat256+ Feat256′ Output
同时Up和Down层中都包含一个1×1卷积,用于调整特征图的通道数,保证残差连接的两个特征图维度完全一致。这是残差连接能够正常工作的必要条件。
StyleGAN2构建全新架构的核心优势:
- 融合效率最高:跳跃连接发生在高维特征空间,能够完整传递语义和结构信息,融合效果远好于RGB空间
- 生成质量最优:FID分数比渐进式生长低约10%,超过了当时所有的端到端架构
- 训练最稳定:残差连接缓解了梯度消失问题,训练过程非常平稳,没有模式崩溃
- 编辑效果最好:彻底解决了渐进式生长的特征断层问题,隐空间插值和属性编辑更加平滑连续
- 架构最简洁:只有一个输入和一个输出,没有多余的分支,计算效率更高
【针对性正则化技术】
StyleGAN2中加入了路径长度正则化(Path Length Regularization) ,强制隐空间 W W W 的微小变化与生成图像的变化呈线性关系,让 W W W 空间的插值更平滑,进一步提升特征解耦性。其核心逻辑是让生成器雅可比矩阵的范数保持恒定,避免隐空间的非线性扭曲,让用户对生成结果的控制更精准。
StyleGAN1通过映射网络已经将扭曲的 z z z 空间拉直成了相对平坦的 w w w 空间,但仍然存在一个致命缺陷: w w w 空间中不同方向的"拉伸程度"差异巨大 。我们想象 w w w 空间是一张被拉伸过的橡皮膜:
- 有些方向被拉得很长:沿着这些方向移动很小的距离,图像就会发生剧烈变化
- 有些方向被压得很短:沿着这些方向移动很大的距离,图像几乎没有任何变化
这个问题可以用生成器的雅可比矩阵 来精确描述。对于生成器 G ( w ) G(w) G(w),它在点 w w w处的雅可比矩阵 J w J_w Jw是一个 H W C × 512 HWC \times 512 HWC×512的矩阵,其中每个元素 J i , j = ∂ G ( w ) i ∂ w j J_{i,j} = \frac{\partial G(w)_i}{\partial w_j} Ji,j=∂wj∂G(w)i,表示w的第j个维度的微小变化对图像第i个像素的影响。
雅可比矩阵的奇异值 σ k \sigma_k σk,就对应了w空间中各个方向的拉伸程度:
- 奇异值大:该方向拉伸程度大,微小的w变化会导致巨大的图像变化
- 奇异值小:该方向拉伸程度小,巨大的w变化只会导致微小的图像变化
StyleGAN1的问题在于,雅可比矩阵的奇异值分布非常不均匀,极差可以达到几个数量级。
这个问题带来的严重后果:
- 编辑强度不可控:同样的编辑强度α,在不同属性方向上产生的效果差异巨大。例如,α=1在"性别"方向上可能会让一个人完全变性,而在"微笑"方向上可能几乎看不到任何变化。
- 插值不平滑:在两个w向量之间线性插值时,图像的变化速度会忽快忽慢,出现"跳跃"现象。
- 语义方向不正交:不同属性的语义方向之间会相互干扰,编辑一个属性会不可避免地影响其他属性。
- 部分方向不可用:奇异值非常小的方向几乎不会对图像产生任何影响,相当于浪费了隐空间的维度。
在这个背景下,路径长度正则化的目标非常简单直接:强制w空间中所有方向的路径长度都相等。
换句话说,我们希望雅可比矩阵的所有奇异值都相等。这样,无论沿着哪个方向移动相同的距离,图像都会产生相同程度的变化。
论文中定义了期望路径长度的概念:
E w ∼ p w , ϵ ∼ N ( 0 , I ) ∥ J w ϵ ∥ 2 \mathbb{E}_{w \sim p_w, \epsilon \sim \mathcal{N}(0,I)} \left \\\| J_w \\epsilon \\\|_2 \\right Ew∼pw,ϵ∼N(0,I)∥Jwϵ∥2
这个式子的含义是:随机采样一个w向量,再随机采样一个单位方向向量ε,计算沿着ε方向移动单位距离后,图像的平均变化量。我们希望这个期望路径长度是一个常数,不随w和ε的变化而变化。
论文中没有直接惩罚奇异值的方差,而是提出了一个更巧妙、计算更高效的方法。
第一步:利用雅可比向量积(JVP)简化计算
直接计算雅可比矩阵 J w J_w Jw的计算量是巨大的(对于1024×1024的图像, J w J_w Jw有超过300万个元素)。但我们不需要完整的雅可比矩阵,只需要计算雅可比矩阵与一个随机向量的乘积 J w ϵ J_w \epsilon Jwϵ。
幸运的是,雅可比向量积可以通过一次反向传播高效计算,时间复杂度与一次前向传播相同,不需要存储完整的雅可比矩阵。
第二步:引入移动平均a
我们不要求路径长度在每一点都精确等于某个固定值,只要求它的期望等于一个移动平均值a。a在训练过程中动态更新:
a ← μ a + ( 1 − μ ) E ∥ J w ϵ ∥ 2 a \leftarrow \mu a + (1-\mu) \mathbb{E} \left \\\| J_w \\epsilon \\\|_2 \\right a←μa+(1−μ)E∥Jwϵ∥2
其中μ是移动平均的衰减率,论文中使用μ=0.99。
第三步:最终的正则化损失
PL正则的损失函数就是路径长度与移动平均值a的平方差:
R pl = E w ∼ p w , ϵ ∼ N ( 0 , I ) ( ∥ J w ϵ ∥ 2 − a ) 2 \mathcal{R}{\text{pl}} = \mathbb{E}{w \sim p_w, \epsilon \sim \mathcal{N}(0,I)} \left \\left( \\\| J_w \\epsilon \\\|_2 - a \\right)\^2 \\right Rpl=Ew∼pw,ϵ∼N(0,I)(∥Jwϵ∥2−a)2
这个损失函数会惩罚所有偏离平均路径长度的方向,让所有方向的路径长度逐渐趋近于同一个值。
论文中给出了PL正则的精确实现细节,这些细节对最终效果至关重要:
- 随机向量ε的采样 :ε从标准正态分布 N ( 0 , I ) \mathcal{N}(0,I) N(0,I)中采样,而不是均匀分布在单位球面上。论文证明这两种采样方式在期望上是等价的,但正态分布采样更方便。
- 梯度缩放 :在计算雅可比向量积之前,需要将生成器的输出乘以一个缩放因子 1 H W C \frac{1}{\sqrt{HWC}} HWC 1,其中HWC是图像的高度、宽度和通道数。这是为了让路径长度的数值范围合理,不受图像分辨率的影响。
- 权重 :PL正则的损失权重 λ pl = 2 \lambda_{\text{pl}}=2 λpl=2。这个权重是论文中通过实验确定的,在所有数据集上都表现良好。
- 计算频率:PL正则不是每一步都计算,而是每隔16步计算一次(配合懒惰正则化)。
同时论文第4.3节通过大量实验证明了PL正则的效果:
- 隐空间线性度提升10倍:PL正则将隐空间的路径长度标准差从约1.0降低到了约0.1,线性度提升了一个数量级。
- 插值完美平滑:w空间的线性插值现在几乎是完美线性的,没有任何跳跃和扭曲。
- 编辑精度大幅提升:编辑强度α现在可以精确控制,不同属性的编辑强度可以统一。
- 语义方向更加正交:不同属性的语义方向之间的平均余弦相似度从约0.1降低到了约0.03,几乎完全正交。
- 可编辑属性数量增加:可以发现更多更细粒度的语义方向,如眉毛粗细、嘴唇厚度等。
持此之外还设计了懒惰正则化(Lazy Regularization) 的策略,使得R1正则化和路径长度正则化无需每轮迭代都计算,改为每16步计算一次,在不损失效果的前提下,将训练速度提升了近2倍。
5.4 StyleGAN3的核心改进
StyleGAN3是整个系列的又一次范式革新,从连续信号处理的底层理论出发,解决了之前版本的 纹理粘连(Texture Sticking) 问题,实现了生成图像的平移/旋转等变性,为GAN的数字人动画生成领域铺平了道路。
StyleGAN3是怎么做到的呢?首先,我们要知道,什么是几何等变性:先变换隐向量再生成图像,和先生成图像再变换图像,得到的结果完全一致。
严格的数学定义:对于生成器 G G G和任意几何变换 T T T(平移、旋转、缩放),如果满足:
G ( T ( z ) ) = T ( G ( z ) ) G(T(z)) = T(G(z)) G(T(z))=T(G(z))
则称生成器 G G G对变换 T T T是等变的。
StyleGAN1/2中,生成人脸的细节(毛发、纹理、皮肤毛孔)会"粘在图像的像素坐标上",而非物体表面;当隐空间插值让物体平移/旋转时,细节不会跟随物体移动,导致动画生成时出现严重的不自然感,缺乏几何等变性。
这说明StyleGAN2的生成器感知到了绝对像素坐标,它生成的纹理是"粘"在像素网格上的,而不是"长"在物体表面的。
上述问题的根源是由信号混叠(Aliasing) 和 坐标泄露 产生的。
信号混叠(Aliasing) 主要表现为高频信号的错误采样。很多主流的 GAN 的操作都违反了奈奎斯特采样定理, 为了无失真地重建一个连续信号,采样频率必须至少是信号最高频率的 2 倍。在GAN的生成器中,逐点非线性激活(如 Leaky ReLU) 是混叠的最大来源。当我们对一个带限信号应用逐点非线性时,会产生无穷多的高频谐波分量。这些高频分量超过了当前分辨率的奈奎斯特频率,会被错误地采样为低频分量,这就是混叠。
混叠的直观表现就是纹理粘连:当、我们平移或旋转图像时,这些错误的低频分量不会跟着物体一起移动,而是留在原地,看起来就像是纹理粘在了像素网格上。
绝对坐标泄露 表现为GAN生成器中有很多操作会向网络泄露绝对像素坐标。比如:
- 固定的常量输入:StyleGAN1/2 最顶层的 4×4 常量张量,本身就包含了绝对坐标信息
- 逐像素噪声:噪声是和像素坐标绑定的,平移图像时噪声不会跟着动
- 边界填充:零填充、反射填充都会在图像边界产生不连续,泄露绝对位置
- 非对称卷积核:3×3 卷积核本身不是径向对称的,会破坏旋转等变性
这两个问题相互作用,共同导致了之前的一些主流GAN生成器的不等变性。StyleGAN3 的所有设计,都是围绕着系统性消除混叠和全链路封堵坐标泄露这两个目标展开的。
【StyleGAN3核心思想:连续信号视角的建模重构】
StyleGAN3最伟大的贡献,就是提出了一个全新的生成器建模范式:
将网络中所有的离散特征图,都视为连续带限信号的离散采样。
这个思想转变是革命性的。之前的所有生成模型,都把特征图看作是一个个独立的像素格子;而StyleGAN3把特征图看作是对一个无限大、连续的二维函数的采样点。
在StyleGAN3的视角下,生成器不再是一个从隐向量到像素张量的映射,而是一个从隐向量到连续二维函数的映射:
G : W → ( R 2 → R C ) G: \mathcal{W} \to \left( \mathbb{R}^2 \to \mathbb{R}^C \right) G:W→(R2→RC)
其中 R 2 \mathbb{R}^2 R2是连续的二维平面, R C \mathbb{R}^C RC是C通道的信号值。
我们最终看到的离散图像,只是这个连续函数在整数像素坐标上的采样:
I i , j = G ( w ) ( i , j ) , i , j ∈ Z Ii,j = G(w)(i,j), \quad i,j \in \mathbb{Z} Ii,j=G(w)(i,j),i,j∈Z
在这个新视角下,几何等变性变成了一个自然而然的属性:
- 平移图像,等价于平移连续函数的采样坐标
- 旋转图像,等价于旋转连续函数的采样坐标
- 缩放图像,等价于缩放连续函数的采样坐标
只要生成器生成的连续函数是正确的,那么无论我们在什么位置、什么角度、什么尺度采样,得到的图像都是正确的。纹理自然会跟着物体一起移动,不会有任何粘连。
这就是StyleGAN3解决纹理粘连问题的根本思路:它不再生成"像素",而是生成"连续的纹理场"。
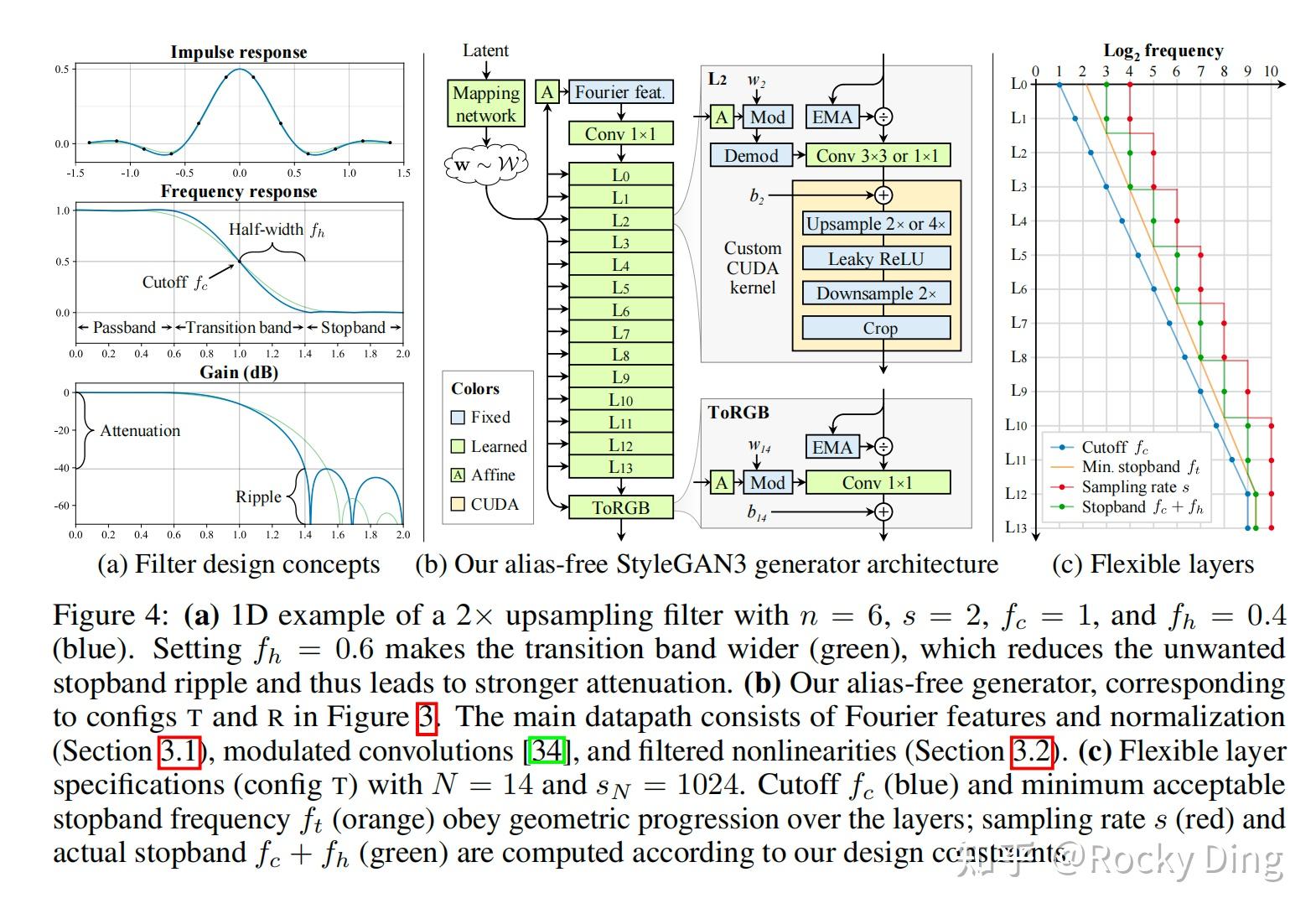
【第一步:混叠的系统性消除】
混叠是等变性的最大敌人。StyleGAN3对生成器的每一个操作都进行了重新设计,确保整个网络的所有环节都严格遵循奈奎斯特采样定理,不会产生任何混叠。
上采样/下采样滤波器的全面升级:传统的双线性和双三次上采样滤波器,频率响应都很差,会让大量高频信号通过,产生严重的混叠。
理想的低通滤波器是sinc函数:
sinc ( x ) = sin ( π x ) π x \text{sinc}(x) = \frac{\sin(\pi x)}{\pi x} sinc(x)=πxsin(πx)
它的频率响应是一个完美的矩形,能完全滤除所有超过截止频率的信号。但理想sinc滤波器是无限长的,无法在实际中使用。
StyleGAN3使用了Kaiser窗截断的sinc滤波器,它在有限长度下实现了接近理想的频率响应:
- 滤波器长度:6×6个抽头
- 带外衰减:>100dB(这意味着超过截止频率的信号被衰减了10万倍以上)
- 过渡带宽度:仅为奈奎斯特频率的10%
相比之下,双线性滤波器的带外衰减只有约12dB,几乎无法有效滤除高频信号。
Kaiser窗sinc滤波器是可分离的(可以分解为水平和垂直两个一维滤波器),计算效率高,但它不是径向对称的。当旋转图像时,不同方向的频率响应不同,会产生混叠。
为了实现旋转等变性,StyleGAN3-R使用了径向对称的jinc滤波器:
jinc ( r ) = J 1 ( π r ) π r \text{jinc}(r) = \frac{J_1(\pi r)}{\pi r} jinc(r)=πrJ1(πr)
其中 J 1 J_1 J1是第一类一阶贝塞尔函数。jinc函数是二维sinc函数的径向对称版本,它的频率响应是一个完美的圆形,在所有方向上都完全一致。
逐点非线性是混叠的最大来源,也是最难解决的问题。因为任何逐点非线性都会产生无穷多的高频分量。
StyleGAN3提出了一个简单但极其有效的解决方案:过采样非线性。 完整流程是:
- 2×上采样:用带限滤波器将特征图上采样到2倍分辨率,此时奈奎斯特频率也提高了2倍
- 应用非线性激活:对过采样后的特征图应用Leaky ReLU,此时产生的高频分量仍然低于新的奈奎斯特频率,不会产生混叠
- 2×带限下采样:用带限滤波器将特征图下采样回原始分辨率,滤除所有超过原始奈奎斯特频率的分量
这个流程的数学原理是:只要在足够高的分辨率下应用非线性,产生的所有高频分量都能被正确采样,然后再通过带限下采样滤除不需要的高频。
这个流程看起来计算量很大(上采样+非线性+下采样),但StyleGAN3开发了一个高度优化的自定义CUDA内核,将这三个操作融合成了一个单一的内核。它避免了中间结果的内存读写,同时利用了GPU的并行计算能力,最终实现了比原始非线性操作还要快的速度。
奈奎斯特采样定理要求采样频率至少是信号最高频率的2倍,这被称为"临界采样"。但在实际应用中,临界采样的抗混叠能力很差,因为滤波器不可能是理想的。
StyleGAN3采用了分层非临界采样策略:
- 低分辨率层:使用0.7×的截止频率(即采样频率是信号最高频率的2.8倍),为非线性操作留出充足的频谱余量,实现更强的抗混叠
- 高分辨率层:使用0.9×的截止频率(接近临界采样),保证输出图像的锐度和细节
这个策略在抗混叠和生成质量之间取得了较好的平衡。低分辨率层负责全局结构,需要更强的抗混叠;高分辨率层负责细节,需要更高的锐度。
【第二步:绝对坐标泄露的全链路封堵】
即使完全消除了混叠,如果网络能感知到绝对像素坐标,仍然无法实现等变性。StyleGAN3对生成器进行了全方位的检查,封堵了所有可能泄露绝对坐标的渠道。
StyleGAN1/2中的逐像素显式噪声,是最明显的坐标泄露源。噪声是和像素坐标绑定的,当我们平移图像时,噪声不会跟着物体一起移动,而是留在原地。
StyleGAN3用全局傅里叶噪声替代了逐像素噪声:
- 首先生成一个全局的连续傅里叶噪声场,它的频率分量是随机的,但相位是连续的
- 这个噪声场可以在任意坐标、任意分辨率下采样
- 当你平移或旋转图像时,只需要相应地平移或旋转噪声场的采样坐标即可
这样,噪声就不再是和像素坐标绑定的,而是和物体表面绑定的,会跟着物体一起移动。
接下来,传统的卷积操作都需要边界填充(零填充、反射填充等),这些填充方式都会在图像边界产生不连续,泄露绝对坐标。
StyleGAN3彻底移除了所有边界填充,改用固定边缘余量的策略:
- 生成器内部的所有特征图,都比目标分辨率大10个像素
- 卷积操作只在特征图的内部进行,不需要任何填充
- 最终输出图像时,只裁剪特征图的中心部分作为输出
这个策略虽然增加了一点计算量,但深度消除了边界带来的坐标泄露。
最后再用傅里叶特征替换固定常量输入,这是StyleGAN3最关键的改动之一。StyleGAN1/2最顶层的4×4常量输入,本身就包含了绝对坐标信息,是最大的坐标泄露源。
StyleGAN3用可学习的傅里叶特征输入替换了固定常量输入:
F ( u , v ) = A ⋅ cos ( 2 π ( f u u + f v v + ϕ ) ) sin ( 2 π ( f u u + f v v + ϕ ) ) + b F(u,v) = A \cdot \begin{bmatrix} \cos(2\pi (f_u u + f_v v + \phi)) \\ \sin(2\pi (f_u u + f_v v + \phi)) \end{bmatrix} + b F(u,v)=A⋅cos(2π(fuu+fvv+ϕ))sin(2π(fuu+fvv+ϕ))+b
其中:
- ( u , v ) (u,v) (u,v)是连续的像素坐标
- f u , f v f_u, f_v fu,fv是可学习的频率参数
- ϕ \phi ϕ是可学习的相位参数
- A , b A, b A,b是可学习的幅度和偏置参数
傅里叶特征天生具备完美的平移和旋转等变性:
- 平移坐标 ( u , v ) → ( u + Δ u , v + Δ v ) (u,v) \to (u+\Delta u, v+\Delta v) (u,v)→(u+Δu,v+Δv),等价于相位偏移 ϕ → ϕ + f u Δ u + f v Δ v \phi \to \phi + f_u \Delta u + f_v \Delta v ϕ→ϕ+fuΔu+fvΔv
- 旋转坐标 ( u , v ) → R ( θ ) ( u , v ) (u,v) \to R(\theta)(u,v) (u,v)→R(θ)(u,v),等价于频率向量旋转 ( f u , f v ) → R ( θ ) ( f u , f v ) (f_u, f_v) \to R(\theta)(f_u, f_v) (fu,fv)→R(θ)(fu,fv)
这意味着,通过调整傅里叶特征的相位和频率参数,就可以实现生成内容的全局平移和旋转,而不需要改变生成器的任何其他参数。
【最终实现:StyleGAN3-T与StyleGAN3-R的设计权衡】
在消除了混叠和坐标泄露之后,StyleGAN3提供了StyleGAN3-T与StyleGAN3-R两个不同的变体,分别针对平移等变性和旋转等变性进行了优化:
StyleGAN3-T保留了StyleGAN2的3×3卷积结构,实现了亚像素级的平移等变性。
为什么3×3卷积只能实现平移等变,不能实现旋转等变?
卷积操作的等变性条件是:卷积核必须与几何变换对易。
- 对于平移变换,任何卷积核都是平移等变的
- 对于旋转变换,只有当卷积核是径向对称的时候,才是旋转等变的
3×3卷积核不是径向对称的,所以StyleGAN3-T只能实现平移等变,不能实现完美的旋转等变。但它的生成质量和计算效率都很高,是大多数应用场景的首选。
为了实现完美的旋转等变性,StyleGAN3-R做了一个极端的设计选择:将所有3×3卷积替换为1×1卷积。
1×1卷积是逐点操作,本身就是完美的旋转等变的。像素之间的信息传播完全通过径向对称的jinc上采样/下采样滤波器来实现。这个设计虽然实现了完美的旋转等变性,但也带来了一些代价:
- 计算效率略有下降
- 生成质量比StyleGAN3-T略低
- 无法很好地建模长距离的空间依赖关系
因此,StyleGAN3-R主要用于需要精确旋转控制的特殊场景,如3D人脸动画、物体姿态生成等。
StyleGAN3通过这一系列的设计,最终实现了:
- 亚像素级的平移等变性:平移图像时,所有细节较好跟随,没有任何粘连
- 近似完美的旋转等变性:旋转图像时,所有细节较好跟随,没有任何扭曲
- 与StyleGAN2相当的生成质量:FID分数几乎没有下降,图像锐度和细节甚至略有提升
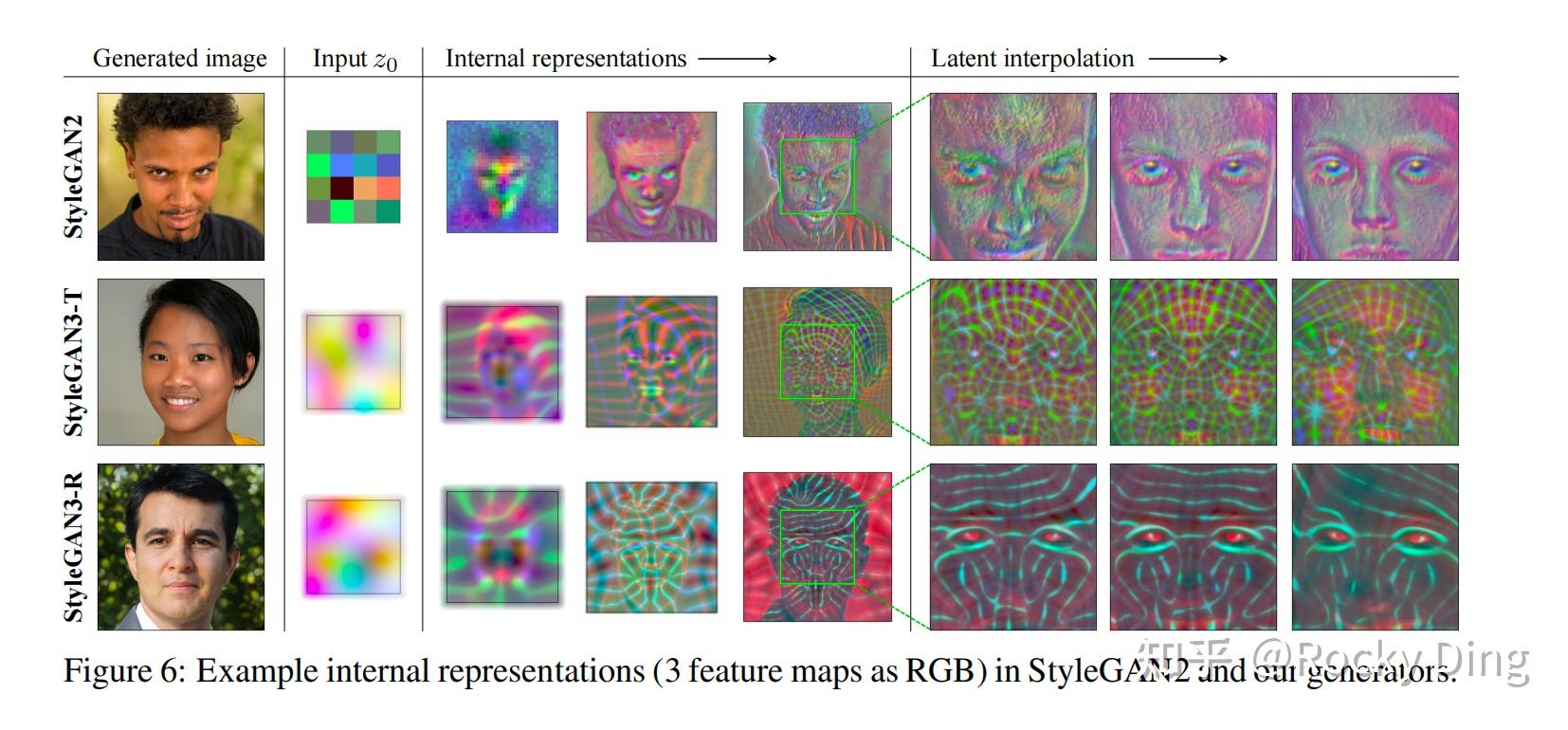
到此为止,Rocky再总结一下StyleGAN系列的迭代路径,方便大家更加清晰的梳理:
- StyleGAN1解决了"能不能控"的问题,让GAN从黑盒变成了可分层调控的生成工具;
- StyleGAN2解决了"好不好看"的问题,消除伪影,提升了生成质量和稳定性;
- StyleGAN3解决了"动起来自不自然"的问题,让GAN从静态图像生成,拓展到了数字人动画生成领域。
5.5 StyleGAN系列的损失函数解析
在开始全面讲解之前,Rocky先定义必要的符号和其含义:
- p data p_{\text{data}} pdata :真实训练图像的数据分布
- p z p_z pz :隐向量的先验分布(标准多元高斯分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I) ,默认512维)
- z z z :从 p z p_z pz 中采样的输入隐向量
- w w w :映射网络(Mapping Network)输出的风格向量, w = f ( z ) w=f(z) w=f(z) , f ( ⋅ ) f(\cdot) f(⋅) 为8层MLP
- G ( ⋅ ) G(\cdot) G(⋅) :生成器网络,输入风格/隐向量,输出生成图像
- D ( ⋅ ) D(\cdot) D(⋅) :判别器网络,输入图像,输出该图像为真实样本的对数概率评分
- E x ∼ p ⋅ \mathbb{E}_{x\sim p}\\cdot Ex∼p⋅ :对分布 p p p 采样的样本求数学期望
- ∇ x \nabla_x ∇x :对输入 x x x 求梯度
- λ \lambda λ :正则项的权重系数,均为官方默认取值
【StyleGAN1 完整损失函数】
StyleGAN1提供了两套损失方案,早期基线用WGAN-GP损失函数,后续优化切换为非饱和损失+R1正则,无额外专属辅助损失。
WGAN-GP损失函数通过梯度惩罚强制判别器满足1-Lipschitz约束,解决原始GAN的模式崩溃和训练不稳定问题。
- 判别器总损失:
L D = E G ( z ) ∼ p g D ( G ( z ) ) − E x ∼ p data D ( x ) ⏟ WGAN核心损失 + λ gp ⋅ E x ^ ∼ p x ^ ( ∥ ∇ x \^ D ( x \^ ) ∥ 2 − 1 ) 2 ⏟ 梯度惩罚项(GP) \mathcal{L}D = \underbrace{\mathbb{E}{G(z)\sim p_g}D(G(z)) - \mathbb{E}{x\sim p{\text{data}}}D(x)}{\text{WGAN核心损失}} + \underbrace{\lambda{\text{gp}} \cdot \mathbb{E}{\hat{x}\sim p{\hat{x}}}\left \\left( \\\|\\nabla_{\\hat{x}} D(\\hat{x}) \\\|_2 - 1 \\right)\^2 \\right}_{\text{梯度惩罚项(GP)}} LD=WGAN核心损失 EG(z)∼pgD(G(z))−Ex∼pdataD(x)+梯度惩罚项(GP) λgp⋅Ex^∼px^(∥∇x\^D(x\^)∥2−1)2
- 生成器损失:
L G = − E z ∼ p z D ( G ( z ) ) \mathcal{L}G = - \mathbb{E}{z\sim p_z}D(G(z)) LG=−Ez∼pzD(G(z))
其中:
- x ^ \hat{x} x^ 为真实样本与生成样本的随机插值: x ^ = ϵ x + ( 1 − ϵ ) G ( z ) \hat{x} = \epsilon x + (1-\epsilon)G(z) x^=ϵx+(1−ϵ)G(z) , ϵ ∼ U ( 0 , 1 ) \epsilon \sim U(0,1) ϵ∼U(0,1) (0-1均匀分布)
- λ gp \lambda_{\text{gp}} λgp 为梯度惩罚权重,官方默认取值为10
- 此处 D ( ⋅ ) D(\cdot) D(⋅) 输出为Wasserstein距离拟合值,而非概率评分
后续StyleGAN又采用了优化方案:非饱和逻辑损失 + R1正则化,与ProGAN方案一致,训练稳定性和生成效果优于WGAN-GP损失,后续StyleGAN系列全面沿用该核心框架。
- 判别器总损失:
L D = − E x ∼ p data log D ( x ) − E z ∼ p z log ( 1 − D ( G ( z ) ) ) ⏟ 非饱和逻辑损失(判别器项) + λ r1 ⋅ R 1 ⏟ R1梯度惩罚正则项 \mathcal{L}D = \underbrace{ - \mathbb{E}{x\sim p_{\text{data}}}\\log D(x) - \mathbb{E}{z\sim p_z}\\log(1 - D(G(z))) }{\text{非饱和逻辑损失(判别器项)}} + \underbrace{ \lambda_{\text{r1}} \cdot \mathcal{R}1 }{\text{R1梯度惩罚正则项}} LD=非饱和逻辑损失(判别器项) −Ex∼pdatalogD(x)−Ez∼pzlog(1−D(G(z)))+R1梯度惩罚正则项 λr1⋅R1
- 生成器总损失(仅非饱和损失,无正则项):
L G = − E z ∼ p z log D ( G ( z ) ) \mathcal{L}G = - \mathbb{E}{z\sim p_z}\\log D(G(z)) LG=−Ez∼pzlogD(G(z))
- R1正则项完整公式:
R 1 = E x ∼ p data ∥ ∇ x D ( x ) ∥ 2 2 \mathcal{R}1 = \mathbb{E}{x\sim p_{\text{data}}} \left \\\| \\nabla_x D(x) \\\|_2\^2 \\right R1=Ex∼pdata∥∇xD(x)∥22
其中:
- λ r1 \lambda_{\text{r1}} λr1 为R1正则权重,StyleGAN1官方默认固定取值为10
- R1正则核心:仅对真实样本的判别器梯度做惩罚,强制梯度平滑,满足Lipschitz约束,计算效率和稳定性优于WGAN-GP
【StyleGAN2 完整损失函数】
StyleGAN2固定了「非饱和逻辑损失+R1正则化」的核心框架,核心新增路径长度正则化(PL正则),解决StyleGAN1隐空间编辑不稳定的问题,是该版本最核心的损失升级。
- PL正则项完整公式:
R pl = E z ∼ p z , w ∼ N ( 0 , I ) ( ∥ J w T w ∥ 2 − a ) 2 \mathcal{R}{\text{pl}} = \mathbb{E}{z\sim p_z, w\sim \mathcal{N}(0,I)} \left \\left( \\\| J_w\^T w \\\|_2 - a \\right)\^2 \\right Rpl=Ez∼pz,w∼N(0,I)(∥JwTw∥2−a)2
其中:
- J w J_w Jw:生成器合成网络对风格向量 w w w 的雅可比矩阵,表征 w w w 的微小变化对生成图像的影响
- a a a:路径长度的移动平均值,训练中动态更新,更新公式为 a ← μ a + ( 1 − μ ) ∥ J w T w ∥ 2 a \leftarrow \mu a + (1-\mu) \| J_w^T w \|_2 a←μa+(1−μ)∥JwTw∥2 ,平滑系数 μ \mu μ 官方默认0.99
生成器总损失:
L G = L G adv + λ pl ⋅ R pl = − E z ∼ p z log D ( G ( z ) ) ⏟ 非饱和对抗损失 + λ pl ⋅ R pl ⏟ 路径长度正则项 \mathcal{L}G = \mathcal{L}G^{\text{adv}} + \lambda{\text{pl}} \cdot \mathcal{R}{\text{pl}} = \underbrace{ - \mathbb{E}{z\sim p_z}\\log D(G(z)) }{\text{非饱和对抗损失}} + \underbrace{ \lambda_{\text{pl}} \cdot \mathcal{R}{\text{pl}} }{\text{路径长度正则项}} LG=LGadv+λpl⋅Rpl=非饱和对抗损失 −Ez∼pzlogD(G(z))+路径长度正则项 λpl⋅Rpl
判别器总损失:
L D = L D adv + λ r1 ⋅ R 1 = − E x ∼ p data log D ( x ) − E z ∼ p z log ( 1 − D ( G ( z ) ) ) ⏟ 非饱和对抗损失 + λ r1 ⋅ E x ∼ p data ∥ ∇ x D ( x ) ∥ 2 2 ⏟ R1正则项 \mathcal{L}D = \mathcal{L}D^{\text{adv}} + \lambda{\text{r1}} \cdot \mathcal{R}1 = \underbrace{ - \mathbb{E}{x\sim p{\text{data}}}\\log D(x) - \mathbb{E}{z\sim p_z}\\log(1 - D(G(z))) }{\text{非饱和对抗损失}} + \underbrace{ \lambda_{\text{r1}} \cdot \mathbb{E}{x\sim p{\text{data}}} \left \\\| \\nabla_x D(x) \\\|_2\^2 \\right }_{\text{R1正则项}} LD=LDadv+λr1⋅R1=非饱和对抗损失 −Ex∼pdatalogD(x)−Ez∼pzlog(1−D(G(z)))+R1正则项 λr1⋅Ex∼pdata∥∇xD(x)∥22
其中StyleGAN2对权重做了分辨率适配,官方公式为 λ r1 = γ 2 \lambda_{\text{r1}} = \frac{\gamma}{2} λr1=2γ,其中 γ = 0.0002 × 分辨率 2 \gamma=0.0002 \times \text{分辨率}^2 γ=0.0002×分辨率2 ;例如1024×1024分辨率下, γ = 204.8 \gamma=204.8 γ=204.8 , λ r1 = 102.4 \lambda_{\text{r1}}=102.4 λr1=102.4 。核心目标是让隐空间的线性插值对应图像空间的均匀变化,提升隐空间可编辑性,让风格调制更平滑。同时 λ pl \lambda_{\text{pl}} λpl 为PL正则权重,官方默认取值为2,可选开启,开启后不损失生成质量,显著提升隐空间编辑能力。
【StyleGAN3 完整损失函数】
StyleGAN3核心损失框架继承自StyleGAN2,无核心公式修改;同时在3D感知变体模型中新增了相机姿态一致性辅助损失。
仅在StyleGAN3-T这个3D感知变体(人脸/场景视角生成)模型中引入了相机姿态一致性损失,核心目标是保证同一隐向量、不同相机姿态的生成结果,保持身份/内容一致性,仅改变视角。
- 姿态一致性损失公式:
L pose = E z ∼ p z , ξ 1 , ξ 2 ∼ p ξ ∥ Enc ( G ( z , ξ 1 ) ) − Enc ( G ( z , ξ 2 ) ) ∥ 1 \mathcal{L}{\text{pose}} = \mathbb{E}{z\sim p_z, \xi_1, \xi_2 \sim p_{\xi}} \left \\\| \\text{Enc}(G(z, \\xi_1)) - \\text{Enc}(G(z, \\xi_2)) \\\|_1 \\right Lpose=Ez∼pz,ξ1,ξ2∼pξ∥Enc(G(z,ξ1))−Enc(G(z,ξ2))∥1
- 加入该损失后的生成器总损失:
L G = L G adv + λ pl ⋅ R pl + λ pose ⋅ L pose \mathcal{L}G = \mathcal{L}G^{\text{adv}} + \lambda{\text{pl}} \cdot \mathcal{R}{\text{pl}} + \lambda_{\text{pose}} \cdot \mathcal{L}_{\text{pose}} LG=LGadv+λpl⋅Rpl+λpose⋅Lpose
其中:
- ξ 1 , ξ 2 \xi_1, \xi_2 ξ1,ξ2:从相机姿态分布 p ξ p_\xi pξ 采样的两组不同相机外参(平移、旋转、视角等)
- Enc ( ⋅ ) \text{Enc}(\cdot) Enc(⋅):预训练特征编码器(人脸场景用ArcFace,通用场景用CLIP)
- λ pose \lambda_{\text{pose}} λpose 为姿态一致性损失的权重,官方默认取值0.1~1,根据场景调整
到这里,Rocky再总结一下StyleGAN系列损失函数的演进核心过程:
- StyleGAN1:完成从WGAN-GP到「非饱和损失+R1正则」的切换,奠定系列基础框架
- StyleGAN2:新增PL正则,补齐隐空间可编辑性的短板,成为系列最优通用方案
- StyleGAN3:完全继承StyleGAN2的损失体系,仅做场景化适配,核心优化集中在架构抗混叠
6. GigaGAN核心基础知识详解
在进入AIGC时代后,扩散模型几乎统治整个图像生成领域,GigaGAN可以说是GAN技术绽放出的"最后光芒"。GigaGAN是迄今为止参数量最大的文生图GAN模型,一共有1B(10亿)的参数量,是AIGC时代的GAN大模型。GigaGAN主要以下的几个特点:
- 首个在LAION 2B上训练成功的超大规模文生图GAN模型。
- 仅需0.13 秒就能单步生成512*512像素的图像。
- 单步生成4k分辨率的超高分辨率图像仅需 3.66 秒。
- 和StyleGAN一样具有解耦可控的潜在向量空间,可以用于风格迁移、Prompt插值和Prompt混合等可控生成任务。
- 生成效果在COCO 零样本的FID为9.09,低于当时的 DALL・E 2、Stable Diffusion 1.5。
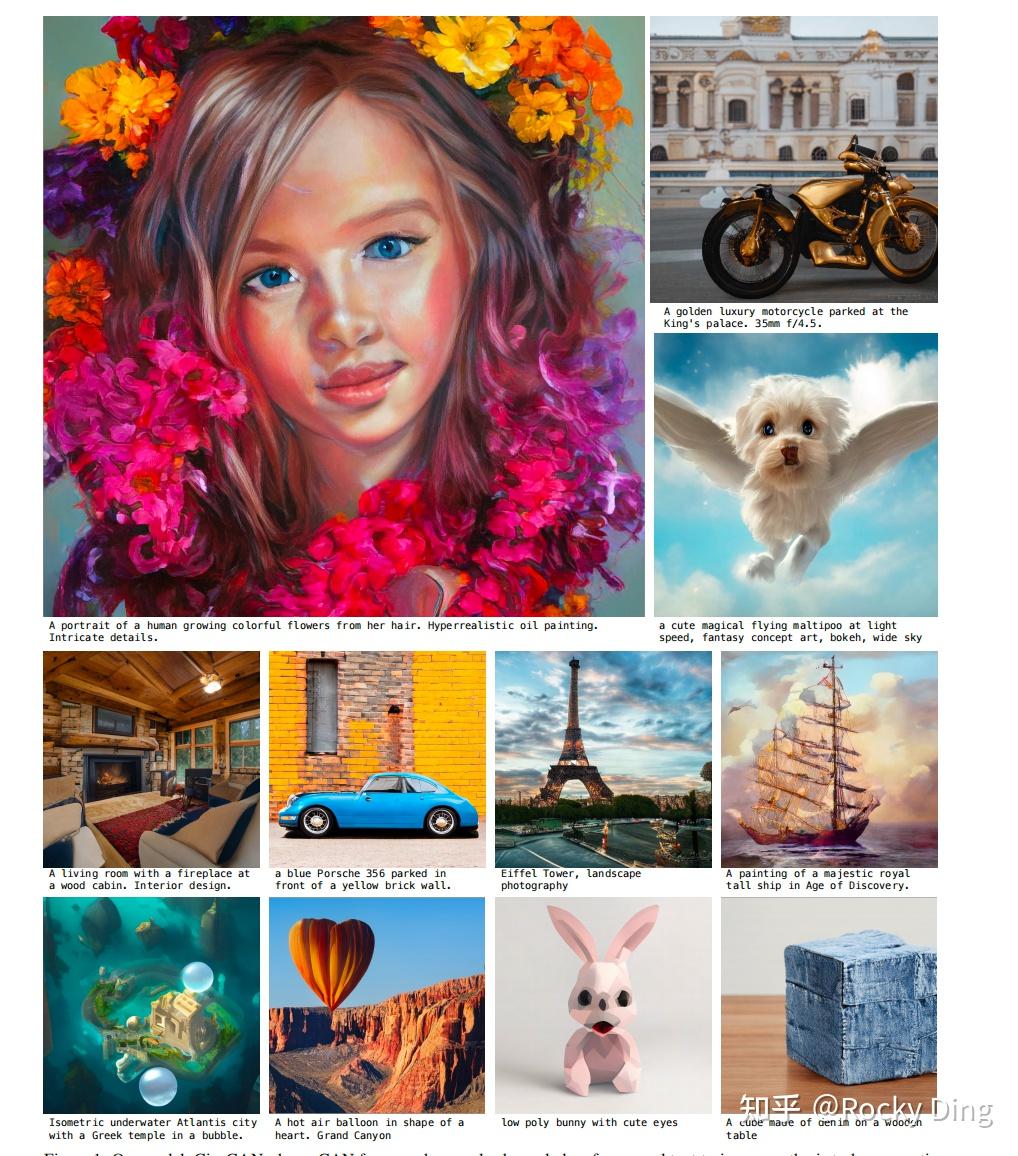
GigaGAN模型的文生图效果
GigaGAN 的核心价值,是打破了 "GAN 无法适配大模型开放世界文生图" 的行业共识 ,证明了GAN在速度、可控性、部署友好性上,依然具备一定的优势。而 AuraSR 则把 GigaGAN 的前沿技术,落地成了工业界可大规模使用的超分工具,是学术成果产业落地的典型范例。二者也印证了AIGC的发展,不是单一技术路线的独舞,而是GAN与扩散模型相互借鉴、互补融合的过程。
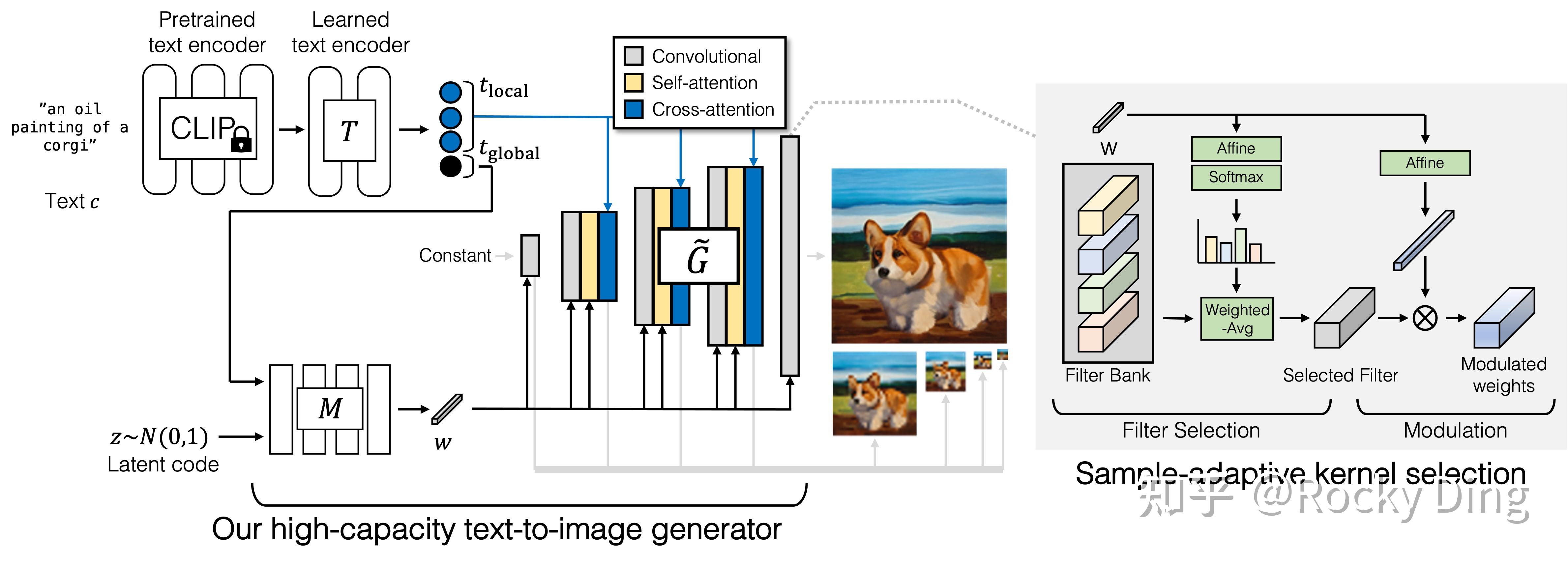
6.1 GigaGAN生成器架构详解
生成器模块是 GigaGAN 的核心,它在 StyleGAN 的基础上进行了优化,整体分为三大子模块:
文本编码模块 为权重冻结的 CLIP ViT-L/14 ,把 prompt 提取成文本特征,再过一个可学习的 Transformer 层 T T T,把文本拆成两部分:
- 全局文本特征 t g l o b a l t_{global} tglobal:对整个 prompt 的整体理解,拿去和随机隐向量 z z z 一起生成风格码 w w w;
- 局部词嵌入 t l o c a l t_{local} tlocal :每个单词的细粒度特征,用于交叉注意力机制,让生成器精准对应 prompt 里的每个词,解决图文对齐问题。
这和传统 StyleGAN 只靠一个全局风格码调制完全不同,相当于既给了整体的「创作指令」,又给了逐词的「细节要求」。
风格映射网络 M M M :一个 4 层的 MLP,把随机隐向量 z z z 和全局文本特征 t g l o b a l t_{global} tglobal ,映射成 1024 维的风格码 w w w。这个 w w w 就是整个生成器的「指挥棒」,不仅要调制卷积层,还要动态选择卷积核,是整个生成器的核心控制信号。
合成网络 :经典的 StyleGAN 就是一串上采样卷积块,而 GigaGAN 的每个卷积块,都变成了自适应卷积核选择→L2 自注意力→文本 - 图像交叉注意力的三件套,一层一层上采样,最终输出的不是单张图,而是一个 5 级的图像金字塔(4×4→8×8→16×16→32×32→64×64)。
这个设计一箭双雕:
- 一是每个模块同时解决了「表达力」「长距离建模」「图文对齐」三个问题。
- 二是多尺度金字塔输出,给判别器提供了全尺度的监督信号,解决低分辨率层训练不充分的问题。
下图是GigaGAN的生成器架构:
GigaGAN模型的生成器架构
6.2 GigaGAN判别器架构详解
GigaGAN 能稳定训练,核心就在这个独创的MS-I/O(多尺度输入 - 多尺度输出)判别器:
- **双分支基础结构:**一个文本分支提取全局文本特征,一个图像分支处理生成器输出的多尺度图像金字塔,两个分支的特征最终做对比,对「图像是不是真的」和「图像和文本对不对得上」两个维度同时判断。
- **MS-I/O 核心设计:**这是 GigaGAN 最优雅的设计之一。传统 GAN 的判别器,只对最终的高分辨率图做一次真假判断;而 GigaGAN 的判别器,对生成器输出的每一个尺度的图像,都在判别器后续的所有下采样层做独立的真假判断。举个例子,64×64 的输入图,会在 32、16、8、4、1 五个尺度都做预测;32×32 的输入图,会在 16、8、4、1 四个尺度做预测,以此类推,总共 15 个预测分支。这就相当于给生成器的每一个分辨率层,都提供了独立的梯度信号,低分辨率层也要学好整体结构和语义,不然直接被判别器惩罚。这样的设计解决了大模型低分辨率层失活的问题,生成的图结构更合理,图文对齐也更好。
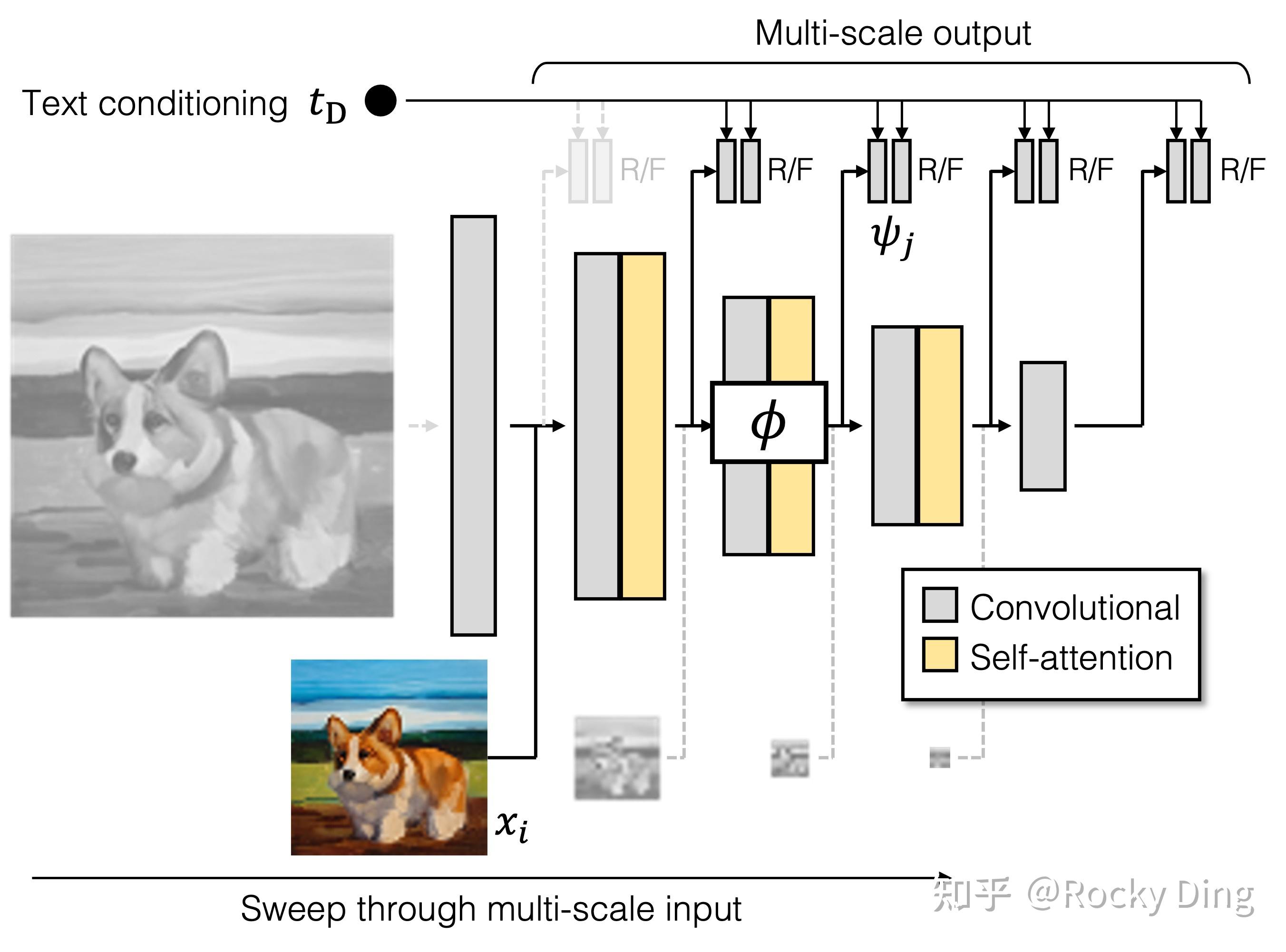
GigaGAN判别器架构
6.3 GigaGAN的超分模块和AuraSR模型
GigaGAN 构建了一个两阶段生成的整体设计:先用基础生成器生成 64×64 的图像,再用单独训练的 GAN 超分模块,超分到 512×512 甚至 4096×4096分辨率。
这个超分模块用的是非对称 U-Net 架构,3 个下采样残差块 + 6 个带注意力的上采样残差块,还有同分辨率的跳跃连接,训练的时候除了基础的 GAN 损失,还加了 LPIPS 感知损失,保证超分后图像和原图的一致性。
值得一提的是,这个超分模块是即插即用的,可以作为AIGC图像领域通用的超分工具,效果比 Real-ESRGAN等经典超分模型更好。而GigaGAN中的这个超分模块这也是后面 AuraSR 诞生的核心基础。
AuraSR 是Fal AI 团队基于 GigaGAN 超分器架构,做开源复刻、算法与工程优化的4 倍图像超分 GAN 模型,是 GigaGAN 超分能力的独立落地版本,也是当前工业界最主流的轻量高效超分方案之一。

GigaGAN超分模块的效果
AuraSR 的整体架构分为 3 个核心模块:
- 风格网络: 4 层特征编码器,输入低分辨率图像,提取全局风格向量,用于调制生成器卷积层,保证超分后完全保留原图的风格、色调与结构。
- 生成器Backbone: 非对称 U-Net 架构,3 个下采样残差块 + 6 个带自注意力的上采样残差块,搭配同分辨率跳跃连接,兼顾结构保留与高清细节生成。
- 相对论判别器: 同时监督两个核心目标,分别是超分图像的真实感以及超分图像与原图的结构一致性,避免生成虚假细节、篡改原图内容。
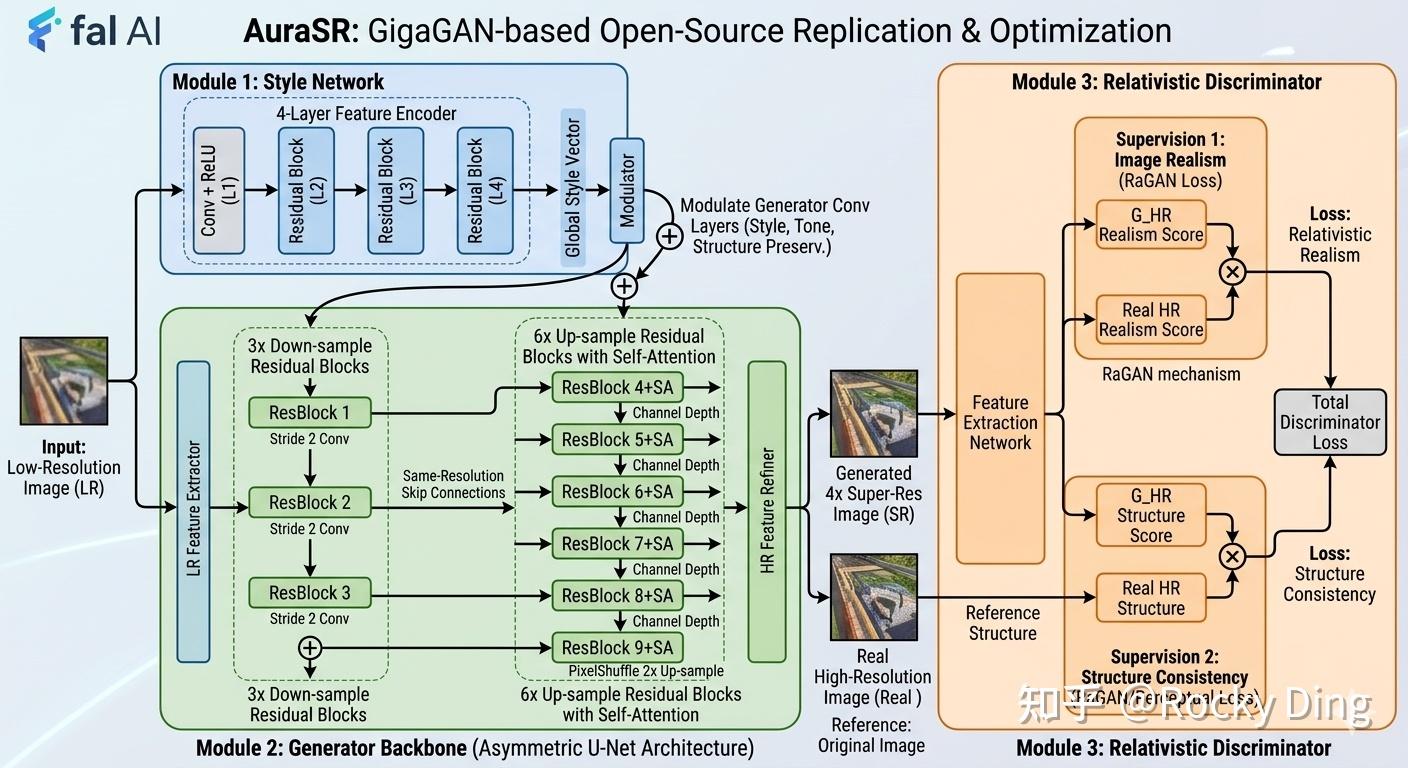
AuraSR模型的架构图
目前AuraSR 系列主要有两个版本:
- AuraSR v1 版本: 权重完全开源,并针对 AI 生成的图像做专项训练优化,消费级显卡即可运行。
- AuraSR v2 核心升级:(1)模拟退化预处理:训练时加入 JPG 压缩、高斯模糊、噪声等真实图像退化模拟,让模型适配真实世界的低清照片,不再局限于干净的 AI 生成图;(2)分块训练对齐:训练时采用小块切分训练,和推理过程完全对齐,解决超分后细节过度、乱加虚假纹理的问题;(3)重叠分块推理:新增重叠分块 + 双次推理平均算法,彻底消除大图超分的拼接接缝问题。
最好,Rocky再总结一下AuraSR 的核心优势与落地场景:
- 速度极致: 512px→1024px 超分仅需 0.25 秒,比扩散超分、Real-ESRGAN 快数十倍;
- 效果均衡: 兼顾保真度与细节生成,不篡改原图结构 / 风格,同时适配 AI 生成图与真实照片;
- 部署友好: 轻量化设计,消费级显卡、端侧设备均可流畅运行,支持批量处理。
- 核心落地场景: AI 生成图高清化、老照片 / 模糊图像修复、电商 / 商业素材高清生产、视频帧批量超分、直播 / 游戏实时画面超分。
6.4 GigaGAN的损失函数
GigaGAN能实现十亿级参数在LAION级数据集上的稳定训练 ,同时兼顾生成真实感与图文对齐度,Rocky认为其核心就在于设计了一套 "1个核心对抗损失 + 3个关键辅助损失" 的组合损失函数体系。这套损失函数深度解决了传统文生图GAN模型的三大顽疾:训练易崩塌、低分辨率层失活、图文对齐差。
传统文生图GAN模型的损失函数通常只有"对抗损失+简单匹配损失",这种设计在小模型、小数据集上勉强能用,但一到大模型、开放世界场景就会全面崩盘:
- 只对最终高分辨率图做对抗监督 → 低分辨率层收不到梯度,彻底躺平,生成图结构混乱。
- 判别器早期只看图像真假,根本不管文本对不对 → 生成的图和prompt驴唇不对马嘴。
- 仅靠原始像素做判别,在超大大参数量的判别器中逻辑失效 → 大模型容量足够大,会过拟合到训练集的像素级细节,变成只会 "扣像素细节" 的记忆库;它给生成器的梯度要么极端大(梯度爆炸)要么极端小(梯度消失),最终迫使生成器只能复制训练集的少数模式,导致模式崩塌。
针对上述的问题,GigaGAN在损失函数中进行了如下的设计:
- 用MS-I/O多尺度对抗损失解决低分辨率层失活问题
- 用改进版匹配感知损失强制判别器必须关注文本条件
- 用CLIP对比损失进一步拉齐图文特征空间,提升细粒度对齐
- 用视觉辅助GAN损失用预训练模型做"第三方评委",保证十亿参数模型训练稳定
最终GigaGAN的总损失函数公式为:
V ( G , D ) = V M S − I O ( G , D ) + λ C L I P L C L I P ( G ) + λ V i s i o n L V i s i o n ( G ) \mathcal{V}(G, D) = \mathcal{V}{MS-IO}(G, D) + \lambda{CLIP}\mathcal{L}{CLIP}(G) + \lambda{Vision}\mathcal{L}_{Vision}(G) V(G,D)=VMS−IO(G,D)+λCLIPLCLIP(G)+λVisionLVision(G)
其中 λ C L I P = 1.0 \lambda_{CLIP}=1.0 λCLIP=1.0, λ V i s i o n = 0.1 \lambda_{Vision}=0.1 λVision=0.1,是论文中经过消融实验验证的最优权重。
接下来Rocky带着大家详细讲解GigaGAN的总损失函数中的每项的价值。
【核心损失1:MS-I/O多尺度对抗损失】
传统GAN的对抗损失,只对生成器输出的最终高分辨率图做一次真假判断。当模型放大到十亿参数时,梯度只能传到最后几层高分辨率块,前面的低分辨率块完全收不到梯度信号,变成了"死参数"。这样的后果是生成的图像细节看起来还行,但整体结构稀碎(比如床有8条腿、花瓶歪歪扭扭),图文对齐一塌糊涂。
我们知道GigaGAN的生成器会输出一个5级图像金字塔 (4×4 → 8×8 → 16×16 → 32×32 → 64×64),而它独创的MS-I/O(多尺度输入-多尺度输出)判别器,会对每一个尺度的输入图像,在所有后续下采样层都做独立的真假预测。即具体的MS-I/O多尺度对抗损失公式为:
V M S − I O ( G , D ) = ∑ i = 0 L − 1 ∑ j = i + 1 L V G A N ( G i , D i j ) + V m a t c h ( G i , D i j ) \mathcal{V}{MS-IO}(G, D) = \sum{i=0}^{L-1} \sum_{j=i+1}^{L} \left \\mathcal{V}_{GAN}(G_i, D_{ij}) + \\mathcal{V}_{match}(G_i, D_{ij}) \\right VMS−IO(G,D)=i=0∑L−1j=i+1∑LVGAN(Gi,Dij)+Vmatch(Gi,Dij)
- L = 5 L=5 L=5是图像金字塔的层数
- G i G_i Gi是生成器输出的第 i i i级分辨率图像
- D i j D_{ij} Dij是判别器对第 i i i级输入,在第 j j j级下采样层的预测分支
- V G A N \mathcal{V}_{GAN} VGAN是标准的非饱和GAN损失
- V m a t c h \mathcal{V}_{match} Vmatch是匹配感知损失,后面会单独讲
Rocky再举个具体的例子,让大家更好理解:
- 64×64的输入图,会在32、16、8、4、1五个尺度都做真假预测(5个分支)
- 32×32的输入图,会在16、8、4、1四个尺度做预测(4个分支)
- 以此类推,总共会产生 5 + 4 + 3 + 2 + 1 = 15 5+4+3+2+1=15 5+4+3+2+1=15个独立的对抗预测分支
从通俗角度解释,这就像老师批改作文。传统老师只看最终的整篇作文,给一个总分 → 学生只会练结尾,开头和大纲写得一塌糊涂。GigaGAN的老师不仅看整篇作文,还要单独批改大纲、段落、句子、单词,每个部分都给分 → 学生必须把每个层级都写好,才能拿到高分
总的来说,给生成器的每一个分辨率层都提供了独立的梯度信号,低分辨率层再也没法躺平。低分辨率层负责学习整体结构、语义和布局,高分辨率层负责学习细节,分工明确。同时生成的图结构更合理,图文对齐效果大幅提升。
【核心损失2:改进版匹配感知损失】
文生图GAN最核心的痛点是训练早期生成的图像满是噪点,非常好分辨真假。判别器只需要看图像有没有噪点,就能100%准确判断真假,根本不需要看文本条件。这就导致判别器永远学不会"图文匹配",生成的图再好看,也和prompt没关系。
传统的匹配损失只对生成图像做负样本匹配:把"生成图像+错误文本"判为假。但这还不够,因为判别器还是可以只靠图像真假来得分,不需要关注文本。
因此,GigaGAN对匹配损失做了关键改进:同时对真实图像和生成图像做负样本匹配,把"真实图像+错误文本"也判为假。具体公式如下:
V m a t c h = E x , c , c ^ l o g ( 1 + e x p ( D ( x , c \^ ) ) ) + l o g ( 1 + e x p ( D ( G ( c ) , c \^ ) ) ) \mathcal{V}{match} = \mathbb{E}{x,c,\hat{c}} \left log(1+exp(D(x,\\hat{c}))) + log(1+exp(D(G(c),\\hat{c}))) \\right Vmatch=Ex,c,c^log(1+exp(D(x,c\^)))+log(1+exp(D(G(c),c\^)))
- x x x是真实图像, c c c是对应的正确文本, c ^ \hat{c} c^是随机采样的错误文本
- D ( x , c ^ ) D(x,\hat{c}) D(x,c^)是判别器对"真实图+错误文本"的预测
- D ( G ( c ) , c ^ ) D(G(c),\hat{c}) D(G(c),c^)是判别器对"生成图+错误文本"的预测
这个损失函数的目标是让判别器对所有不匹配的图文对,不管图像是真还是假,都输出"假"的判断。这样彻底强制判别器必须同时关注图像和文本,从训练第一天起就重视图文对齐,解决了文生图GAN"图文脱节"的历史遗留问题。论文消融实验显示,加入这个损失后,CLIP分数直接从0.235提升到0.250,提升非常显著。
【辅助损失1:CLIP对比损失】
匹配感知损失是让判别器学会判断图文是否匹配,但它只能提供"对/错"的二值信号,没法提供细粒度的语义对齐信号。而CLIP模型在大规模图文对上预训练,已经学到了非常好的图文特征对齐能力,可以用来给生成器提供额外的监督。
让生成图像的CLIP图像特征,和对应prompt的CLIP文本特征的相似度,远高于和其他随机prompt的文本特征的相似度,用标准的对比交叉熵损失来训练。具体公式如下:
L C L I P = E { c n } − l o g e x p ( E i m g ( G ( c 0 ) ) ⊤ E t x t ( c 0 ) ) ∑ n e x p ( E i m g ( G ( c 0 ) ) ⊤ E t x t ( c n ) ) \mathcal{L}{CLIP} = \mathbb{E}{\{c_n\}} \left -log \\frac{exp(\\mathcal{E}_{img}(G(c_0))\^\\top \\mathcal{E}_{txt}(c_0))}{\\sum_{n} exp(\\mathcal{E}_{img}(G(c_0))\^\\top \\mathcal{E}_{txt}(c_n))} \\right LCLIP=E{cn}−log∑nexp(Eimg(G(c0))⊤Etxt(cn))exp(Eimg(G(c0))⊤Etxt(c0))
- E i m g \mathcal{E}_{img} Eimg是冻结的CLIP图像编码器
- E t x t \mathcal{E}_{txt} Etxt是冻结的CLIP文本编码器
- c 0 c_0 c0是正确的prompt, { c n } \{c_n\} {cn}是包含 c 0 c_0 c0的一批随机prompt
这样做能够提供细粒度的语义对齐信号,提升生成图和prompt的匹配度。并且CLIP的特征是预训练好的,提供的梯度非常稳定,能进一步提升训练稳定性。论文消融实验显示,加入CLIP损失后,FID从19.18直接降到14.88,是所有改进中提升最大的一项
【辅助损失2:视觉辅助GAN损失】
当GAN的参数量达到十亿级别时,仅靠原始像素做判别,训练会变得极其不稳定,很容易出现梯度爆炸、模式崩塌。因为原始像素的噪声很大,判别器很容易过拟合,给出错误的梯度信号。
因此,GigaGAN用冻结的预训练CLIP图像编码器做一个辅助判别器:
- 把生成图和真实图输入CLIP,提取中间层的多尺度特征
- 用一个简单的3×3卷积网络,基于这些特征来判断真假
- 加入固定随机投影层(借鉴Projected GAN),进一步提升稳定性
这个辅助判别器和主判别器一起训练,给生成器提供额外的梯度信号,从而大幅提升十亿级参数大模型的训练稳定性,是GigaGAN能训练成功的关键之一。同时,用预训练模型的高级语义特征做判别,生成的图像感知质量更好。论文消融实验显示,加入这个损失后,FID从14.92降到13.67,同时训练稳定性大幅提升
【损失函数的整体训练逻辑】
GigaGAN的整体训练流程如下:
- 生成器输入随机隐向量z和文本prompt,输出5级图像金字塔
- 主判别器对15个多尺度分支做对抗预测和匹配预测,计算 V M S − I O \mathcal{V}_{MS-IO} VMS−IO
- 生成图输入CLIP,计算CLIP对比损失 L C L I P \mathcal{L}_{CLIP} LCLIP
- 生成图输入视觉辅助判别器,计算视觉辅助损失 L V i s i o n \mathcal{L}_{Vision} LVision
- 总损失反向传播,更新生成器和判别器的参数(生成器和判别器1:1更新)
7. GAN模型在AI数字人领域的完整算法解决方案
7.1 AI数字人场景介绍
GAN数字人解决方案的核心设计原则是低成本、高可控、强实时、易落地,解决传统3D数字人方案"成本高、周期长、门槛高、实时性差"的核心痛点,能够适配虚拟直播、智能交互客服、短视频内容生产、企业品牌代言、元宇宙交互等全场景商用需求。
整个方案按数字人从生产到落地的完整生命周期,分为五大核心模块,形成完整闭环:
- 数字人资产生产与定制模块:方案的基石,解决"从0到1造出数字人"的问题
- 多模态驱动与控制模块:方案的核心引擎,解决"让数字人精准动起来、说起来"的问题
- 端到端内容生成模块:方案的商用价值核心,解决"用数字人批量生产内容"的问题
- 实时渲染与画质增强模块:方案的画质底线,解决"数字人看起来真不真"的问题
- 部署与业务集成模块:方案的落地出口,解决"数字人怎么用到业务里"的问题
7.2 模块一:数字人资产生产与定制模块
这个模块是整个方案的地基,核心目标是用极低的成本,快速生成可驱动、可定制、符合商用需求的数字人完整资产。模块下拆分为4个核心子模块,全流程基于GAN实现:
基础数字人资产生成子模块 。核心功能 :从零批量生成不同风格、不同人设的数字人基础资产,包括超写实人脸、全身人体、毛发、基础服饰,覆盖超写实、二次元、卡通、国风等全风格需求。 技术逻辑与所用GAN模型:
- 以StyleGAN系列为核心底座:用StyleGAN v2生成1024×1024分辨率的写实人脸,精准还原毛孔、发丝、皮肤纹理等细节;用StyleGAN XL/StyleHuman生成全身人体资产,控制身高、体型、肢体比例;用AnimeStyleGAN/ToonStyleGAN生成二次元/卡通风格数字人。
- 基于StyleGAN的解耦隐空间,批量生成不同人设的数字人,通过隐空间向量筛选,快速锁定符合品牌调性、人设要求的基础资产。
- 用SinGAN做风格化微调,针对小众风格(比如国潮、赛博朋克),用少量参考图就能完成风格迁移,生成专属风格的数字人资产。
真人数字人复刻子模块 。核心功能 :基于用户的单张/少量照片,1:1复刻和真人完全一致的数字人,是个人分身、企业创始人数字人、明星数字人、政务/银行客服数字人的核心刚需。 技术逻辑与所用GAN模型:
- 前置修复:用GFPGAN/CodeFormer对输入照片做高清修复、去噪、去遮挡,解决照片模糊、光照不佳、角度不正的问题。
- 身份逆映射:用StyleGAN逆映射(Inversion)技术,把修复后的照片映射到StyleGAN的W/W+隐空间,得到唯一的身份特征向量,保证生成的数字人和真人100%身份匹配。
- 少样本微调:用LoRA对StyleGAN做轻量微调,结合PIFuHD(GAN-based人体重建模型),从2D照片生成3D人脸/人体网格,还原真人的面部细节、五官特征、体型特征。
数字人个性化定制与编辑子模块 。核心功能 :对数字人做全维度、零门槛的个性化修改,包括五官、年龄、妆容、发型、服饰、体型、风格,满足企业品牌定制、用户个性化分身的需求。 技术逻辑与所用GAN模型:
- 基于StyleGAN的解耦隐空间,用InterfaceGAN/StyleSpace预训练的属性编辑向量,实现人脸特征的精准控制------比如调整年龄、性别、脸型、五官、表情、肤色,修改一个维度不会影响其他特征,完全解耦。
- 用StyleBody实现人体体型、服饰的编辑,调整身高、胖瘦、肩宽、服装款式,实时预览效果。
- 用StyleGAN-NADA实现零样本风格迁移,不用微调,就能把写实数字人转换成国风、二次元、油画等任意风格。
数字人资产标准化输出子模块 。核心功能 :把生成的2D/3D数字人资产,转换成驱动引擎可识别的标准化格式,打通"资产生产"和"实时驱动"的链路,避免生成的资产"只能看,不能用"。 技术逻辑与所用GAN模型:
- 用3DMM+StyleGAN融合方案,从2D人脸生成标准化的52维Blendshape表情基、人脸骨骼绑定,输出兼容Unity/Unreal/所有主流驱动引擎的格式。
- 用PIFuHD/ICON(GAN-based 3D人体重建模型),从2D全身照生成带蒙皮、骨骼绑定的3D人体网格,输出FBX/GLB通用格式。
- 用MaterialGAN 生成PBR材质贴图,包括皮肤、毛发、服饰的金属度、粗糙度、法线贴图,保证资产在不同引擎里的材质质感一致。 核心作用与商用价值: 省掉了传统数字人流程中"手动绑定、蒙皮、画材质"的90%工作量,生成的数字人资产直接就能导入驱动引擎,实现实时驱动,打通了资产生产到落地的最后一公里。
7.3 模块二:多模态驱动与控制模块
这个模块是数字人的"大脑和神经中枢",是整个方案的核心引擎,核心目标是让数字人按照需求精准、自然、流畅地动起来、说起来,同时保证身份不崩坏、实时低延迟。模块下拆分为4个核心子模块:
实时面部表情驱动子模块 。核心功能 :实现数字人面部表情、头部姿态的精准实时控制,支持两种核心模式:一是真人摄像头实时动捕迁移,二是参数化/文本控制表情,保证微表情精准、面部肌肉联动自然、长时长运行不崩坏。 技术逻辑与所用GAN模型:
- 零样本实时摄像头驱动 :用MediaPipe提取真人面部21/106个关键点,用First Order Motion Model (FOMM) 实现无标记实时表情迁移,把真人的表情、头部姿态实时映射到数字人脸上,消费级摄像头就能实现,延迟低于30ms。
- 超写实精准表情驱动 :针对商用超写实数字人,用StyleRig/StyleHEAT,把人脸关键点/Blendshape参数直接映射到StyleGAN的隐空间,实现面部肌肉级的精准控制------从张嘴、闭眼的大动作,到挑眉、嘴角微动的微表情,都能1:1还原,完全符合真人面部解剖学规律,解决传统驱动的"僵尸脸"问题。
- 身份安全锁 :用FaceSwap-GAN做实时身份校验,保证驱动过程中数字人的身份特征不变,不会出现"动着动着脸就变了"的致命问题。
语音驱动口型与全脸表情子模块 。核心功能 :输入语音,自动生成和语音精准同步的口型,同时根据语音的情绪、语调,生成匹配的全脸联动表情,是数字人"说话自然不违和"的生死线。 技术逻辑与所用GAN模型:
- 精准唇形同步 :以Wav2Lip 为核心底座(工业界标配),输入语音和数字人画面,端到端生成和语音音素100%匹配的唇形,支持中文、英文、日语等所有语种,支持快速念白、歌曲演唱等全场景,哪怕是嘈杂环境的语音,也能保证口型精准同步,完全不破坏数字人的身份和表情。针对4K超写实数字人,用TalkLip做升级优化,还原嘴唇纹理、牙齿细节等超高清细节。
- 情绪联动全脸表情 :用Audio2Face/EmotionGAN,解析语音的语调、语速、情绪特征,映射成对应的全脸表情参数------比如开心的语气自动生成挑眉、微笑、苹果肌上提,严肃的语气自动生成皱眉、面部肌肉紧绷,实现"语音-口型-全脸表情"的端到端联动,彻底解决数字人"只动嘴,脸上没表情"的违和感。
- 时序平滑优化:用GAN-based的时序平滑模型,对连续帧的口型、表情参数做滤波,保证帧间过渡自然,不会出现卡顿、跳变、闪烁。
全身动作与肢体驱动子模块 。核心功能 :实现数字人全身动作、肢体姿态、手势的精准控制,解决数字人"站着不动像木桩"的问题,让全身数字人动作自然流畅,不穿模、不崩坏。 技术逻辑与所用GAN模型:
- 实时动作迁移 :用普通摄像头提取人体2D/3D关键点,用Recycle-GAN/Everybody Dance Now实现无监督的全身动作迁移,把真人的舞蹈、演讲、肢体动作,实时迁移到数字人身上,不用配对训练数据,就能保证动作自然、肢体不穿模。
- 智能动作生成 :用Action-GAN/StyleHuman,根据文本内容、语音情绪,自动生成匹配的肢体动作、手势------比如演讲时的抬手手势、开心时的肢体摆动、讲解时的指向动作,同时保证动作和口型、表情的联动一致性,不用手动K帧,就能生成自然的全身动作。
- 穿模防护:用GAN-based的姿态优化模型,对生成的动作参数做实时校验,修正超出合理范围的肢体姿态,避免出现肢体穿模、人体结构崩坏的问题。
驱动参数管控与平滑优化子模块 。核心功能 :给整个驱动系统加一层"安全锁",对所有驱动参数做实时管控、过滤、平滑优化,避免出现跳变、抖动、穿模、表情崩坏,保证长时长运行的稳定性和流畅性。 技术逻辑与所用GAN模型:
- 用时序GAN模型,对连续帧的驱动参数(表情、口型、动作)做卡尔曼滤波和时序平滑,补全缺失的关键点,修正异常的参数跳变,保证帧间过渡自然流畅。
- 设置参数安全阈值,对超出人脸/人体解剖学合理范围的参数做自动修正,防止出现表情崩坏、肢体穿模。
- 对驱动信号做延迟优化,保证音视频、口型、动作的同步误差低于20ms,避免出现"音画不同步"的问题。
7.4 模块三:端到端内容生成模块
这个模块是数字人方案的商用价值核心,核心目标是用数字人实现低成本、批量化的内容生产,解决企业内容产能不足、制作成本高的核心痛点,也是目前数字人最主流的商用场景。模块下拆分为3个核心子模块:
文本驱动数字人视频生成子模块 。核心功能 :输入文本,一键生成完整的数字人视频,包括语音、口型、表情、动作、背景、字幕,不用任何拍摄、剪辑、后期,实现"一句话生成一条数字人视频"。 技术逻辑与所用GAN模型:
- 多模态内容解析:输入文本后,自动拆分文案内容,用TTS生成对应语音,用NLP解析文案的语义、情绪、重点,匹配对应的表情、动作、语速。
- 端到端视频生成:用StyleVideoGAN 做核心生成引擎,结合语音驱动模块生成的口型、表情参数,动作生成模块生成的肢体动作,用SPADE/GauGAN生成匹配文案内容的背景画面,端到端生成高分辨率、时序流畅的数字人视频,全程保证数字人身份一致、口型同步、动作自然。
- 自动后期包装:用Text2Video-GAN自动添加字幕、贴纸、转场、背景音乐,生成符合平台要求的成品视频。
数字人视频编辑与二次创作子模块 。核心功能 :对已生成的数字人视频做零门槛二次编辑,比如改台词、换数字人、换表情、换动作、换背景,不用重新生成整个视频,极大提升内容修改效率。 技术逻辑与所用GAN模型:
- 改台词:重新输入修改后的文本,用Wav2Lip重新生成同步的口型,无缝替换原视频的对应片段,不用重新生成整条视频。
- 换数字人/改表情:用GAN反演技术把视频帧映射到StyleGAN隐空间,修改隐空间向量就能替换数字人身份、调整表情、修改年龄妆容,用FaceSwap-GAN实现全视频的身份替换,全程保证时序一致性,不闪烁、不穿帮。
- 改画面/换背景:用LaMa/Inpaint-GAN 做画面修复和背景替换,用RelightGAN调整数字人光影,和新背景完美融合。
多场景内容适配子模块 。核心功能 :把生成的数字人内容,一键适配不同的平台、场景、设备,自动调整分辨率、画幅、帧率、风格,实现"一次生成,全平台分发"。 技术逻辑与所用GAN模型:
- 画幅适配:用CropGAN做智能画幅裁剪,自动把横屏视频转换成抖音/视频号的竖屏格式,保证数字人始终在画面C位,不会出现关键内容被裁剪的问题。
- 画质适配:用Real-ESRGAN做分辨率自适应调整,适配手机端、PC端、线下大屏、广播级设备的不同分辨率要求。
- 帧率适配:用DAIN/IFRNet做智能帧率转换,把30fps的视频转换成60/120fps,适配高刷设备,让画面更流畅。
- 风格适配:用CycleGAN/StyleGAN-NADA做画面风格迁移,一键把写实数字人视频转换成二次元、国潮、电影感等不同风格,适配不同的内容场景。
7.5 模块四:实时渲染与画质增强模块
这个模块是数字人方案的"画质底线",核心目标是保证数字人画面的真实感、清晰度、一致性,不管是实时直播还是生成的视频,都能达到影视级/广播级的商用标准。模块下拆分为3个核心子模块:
实时人脸画质增强子模块 。核心功能 :对实时驱动/生成的数字人人脸画面,做实时的高清修复、去伪影、细节优化,保证每一帧的人脸都是超高清、细节丰富、无崩坏的。 技术逻辑与所用GAN模型:
- 以GFPGAN/GPEN为核心,针对实时生成的人脸画面,做毫秒级的画质增强,修复模糊、伪影、细节缺失的问题,还原皮肤纹理、发丝、五官细节,同时100%保持数字人的身份和表情不变。
- 针对严重低质的画面,用CodeFormer做极致修复,哪怕是驱动生成的低分辨率人脸,也能还原成4K超高清画面。
- 所有模型都做了TensorRT优化,在消费级显卡上就能实现30fps以上的实时推理,延迟低于30ms,完全不影响直播的实时性。
全局画面与视频画质优化子模块 。核心功能 :对整个数字人画面(包括人体、服饰、背景)做全局的画质优化,包括超分辨率、去噪、去闪烁、智能补帧,保证整个画面的一致性和流畅性。 技术逻辑与所用GAN模型:
- 全局超分:用Real-ESRGAN做全局画面超分辨率,把720P的画面无损升到4K/8K,完美保留人物边缘、服饰褶皱、背景细节,不会出现模糊、边缘虚化的问题。
- 视频时序优化:用**BasicVSR++**做视频去噪和帧间优化,消除实时生成画面的帧间闪烁、噪点,保证长时长视频/直播的画面稳定性。
- 智能补帧:用DAIN做帧率提升,把30fps的画面升到60/120fps,让动作、画面过渡更流畅,没有卡顿感。
- 智能抠像:用MattingGAN做实时数字人抠像,精准分离人物和背景,没有绿边、毛边,完美适配虚拟背景、绿幕直播场景。
光影与材质实时优化子模块 。核心功能 :优化数字人的光影、材质质感,让数字人和背景环境完美融合,解决数字人"像贴在背景上"的违和感,提升真实感和沉浸感。 技术逻辑与所用GAN模型:
- 实时重光照:用RelightGAN/Illumination-GAN,根据背景画面的光照环境、光源方向,实时调整数字人的光影、明暗、阴影,让数字人看起来是真实处于背景环境中,而不是贴上去的。
- 材质质感优化:用MaterialGAN优化数字人的皮肤、毛发、服饰的材质质感,让皮肤有通透的次表面散射效果,毛发有层次感和蓬松感,服饰有真实的褶皱、粗糙度和反光效果,彻底解决"塑料感"问题。
7.6 模块五:部署与集成模块
这个模块是数字人方案的落地出口,核心目标是把前面的所有能力,封装成可商用、可集成、高稳定的系统,适配不同的业务场景、硬件设备、平台环境,让数字人真正能用起来。模块下拆分为4个核心子模块:
多端部署适配子模块 。核心功能 :把数字人系统部署到不同的硬件和平台上,适配云端、本地PC、手机端、嵌入式设备、线下大屏等全场景,兼顾高并发和端侧离线运行的需求。 技术逻辑与落地要点:
- 模型轻量化:用模型量化、剪枝、知识蒸馏技术,把GAN模型轻量化,压缩模型体积,降低算力要求,同时保证生成效果和推理速度。
- 云端部署:用Docker/K8s做容器化部署,基于云端GPU集群做分布式调度,支持高并发的数字人视频生成、直播推流需求,弹性扩缩容,应对流量波动。
- 本地部署:优化模型适配消费级显卡(RTX 3060及以上),实现本地PC端的实时驱动、直播、内容生成,不用依赖云端,保证数据安全。
- 端侧部署:用TNN/NCNN/MNN等端侧推理框架,把轻量化后的GAN模型部署到Android/iOS手机、嵌入式设备上,实现离线实时数字人驱动和交互,不用联网就能运行。 核心作用与商用价值: 让数字人系统能适配所有的商用场景,不管是云端高并发的无人直播,还是手机端的离线交互,还是线下大屏的数字人展示,都能流畅运行,彻底打破了部署环境的限制。
高并发直播与推流子模块 。核心功能 :支持数字人7×24小时无人直播,高并发推流到抖音、视频号、快手、B站等所有主流直播平台,支持多直播间同时开播,实时互动。 技术逻辑与落地要点:
- 分布式推流架构:每个数字人直播实例对应一个独立的GPU进程,用FFmpeg做实时编码和推流,把GAN生成的数字人画面和音频,实时编码成RTMP/RTSP/WebRTC直播流,推送到各个直播平台。
- 实时互动能力:通过API和直播间的弹幕、礼物、评论系统集成,根据用户的互动内容,实时触发数字人的话术、表情、动作,实现智能互动直播。
- 稳定性保障:用主备实例切换机制,当一个实例出现故障时,自动切换到备用实例,保证直播不中断,7×24小时稳定运行。 核心作用与商用价值: 是电商虚拟主播、品牌直播间的核心落地能力,支持多平台、多直播间同时开播,7×24小时无人值守,极大降低了直播的人力成本,是目前数字人最主流的商用场景。
系统API集成子模块 。核心功能 :把数字人系统的所有能力,封装成标准化的API接口和SDK,快速和整体系统集成,不用从零开发。 技术逻辑与落地要点:
- 把数字人资产生成、驱动控制、内容生成、画质增强的所有能力,封装成RESTful API,提供标准化的调用接口,支持文本生成视频、实时驱动、数字人编辑、直播推流等所有功能。
- 提供多平台SDK,适配Windows、Linux、Android、iOS等操作系统,支持和Unity、Unreal引擎、Web前端、小程序集成。
- 完善的鉴权、限流、监控机制,保证接口调用的安全性和稳定性。 核心作用与商用价值: 企业不用从零搭建数字人系统,通过API/SDK就能快速把数字人能力集成到自己的业务系统里,比如智能客服系统、教育平台、企业官网、银行终端、元宇宙平台,极大降低了数字人的落地门槛。
运维与监控子模块 。核心功能 :对数字人系统的运行状态做7×24小时实时监控和运维管理,保证系统稳定运行,不宕机、不出现商用事故。 技术逻辑与落地要点:
- 用Prometheus+Grafana搭建实时监控看板,监控GPU利用率、内存占用、接口响应时间、直播推流状态、并发量等核心指标。
- 异常告警机制:当出现算力不足、推流中断、接口异常、画面质量下降时,通过短信、邮件、企业微信自动告警,运维人员能快速处理。
- 画质质检:用GAN-based的画质质检模型,实时监控生成的数字人画面质量,当出现身份崩坏、画面模糊、伪影时,自动触发优化流程,保证商用画面的质量。 核心作用与商用价值: 保证数字人系统的企业级稳定性,满足7×24小时商用运行的需求,是数字人系统能规模化落地的核心运维保障。
推荐阅读
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:深入浅出完整解析扩散模型DDPM、DDIM、SDE、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
3. 深入浅出完整解析FLUX.2、Seedream(即梦)、Z-image、GLM-Image核心基础知识
https://zhuanlan.zhihu.com/p/1975174691049189562
4. 深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
深入浅出完整解析FLUX.1 Kontext和FLUX.1 Krea核心基础知识
5. 深入浅出完整解析DeepSeek系列核心基础知识
6、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:深入浅出完整解析Sora、Wan2.1、AnimateDiff、CogVideoX等AI视频大模型核心基础知识
7、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
8、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
9、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:深入浅出完整解析Stable Diffusion(SD)核心基础知识
10、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:深入浅出完整解析ControlNet核心基础知识
11、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:深入浅出完整解析LoRA(Low-Rank Adaptation)模型核心基础知识
12、深入浅出完整解析AIGC时代Transformer核心基础知识
在AIGC时代中,Transformer为AI行业带来了深刻的变革。Transformer架构正在一步一步重构所有的AI技术方向,成为AI技术架构大一统与多模态整合的关键核心基座,大有一统"AI江湖"之势。Rocky也对Transformer模型进行持续的深入浅出梳理与解析:
Transformer文章地址:深入浅出完整解析AIGC时代Transformer核心基础知识
13、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:手把手教你成为AIGC算法工程师,斩获AIGC算法offer!
14、50万字大汇总《"三年面试五年模拟"之算法工程师的求职面试"独孤九剑"秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
15、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:深入浅出完整解析主流AI绘画框架(ComfyUI、Stable Diffusion WebUI、Fooocus)核心基础知识
16、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
17. AI算法工程师的《三年面试五年模拟》求职秘籍
18. AIGC产业的深度思考与分析
2023年3月21日,微软创始人比尔·盖茨在其博客文章《The Age of AI has begun》中表示,自从1980年首次看到图形用户界面(graphical user interface)以来,以OpenAI为代表的科技公司发布的AIGC模型是他所见过的最具革命性的技术进步。
Rocky也认为,AIGC及其生态,会成为AI行业重大变革的主导力量。AIGC会带来一个全新的红利期,未来随着AIGC的全面落地和深度商用,会深刻改变我们的工作、生活、学习以及交流方式,各行各业都将被重新定义,过程会非常有趣。
那么,在此基础上,我们该如何更好的审视AIGC的未来?我们该如何更好地拥抱AIGC引领的革新?Rocky准备从技术、产品、商业模式、长期主义等维度持续分享一些个人的核心思考与观点,希望能帮助各位读者对AIGC有一个全面的了解: