关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
上一节介绍了langchain4j的初步入门,这一节我们继续介绍。AI多轮对话的是怎么记忆的,RAG又是怎么实现的呢?
02 让 AI 记住对话
LLM 本身不记忆对话历史,ChatMemory 解决的就是这个问题。主要包含两种实现:
MessageWindowChatMemory:保留最近 N 条消息TokenWindowChatMemory:保留最近 N 个 token(按 token 而非消息数滑动)
2.1 案例
我们以最近N条为例。
java
OllamaChatModel model = OllamaChatModel.builder()
.baseUrl("http://10.100.213.26:11434")
.modelName("modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest")
.build();
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(model)
.chatMemory(chatMemory)
.build();
String askMsg = "你好,我叫Simon,请记住我的名字。";
String response1 = assistant.chat(askMsg);
System.out.println("Round 1 ASK: " + askMsg);
System.out.println("Round 1 RESP: " + response1);
String askMsg2 = "我叫什么名字?";
String response2 = assistant.chat(askMsg2);
System.out.println("Round 2 ASK: " + askMsg2);
System.out.println("Round 2 RESP: " + response2);
String askMsg3 = "我喜欢吃川菜,尤其是火锅。";
String response3 = assistant.chat(askMsg3);
System.out.println("Round 3 ASK: " + askMsg3);
System.out.println("Round 3 RESP: " + response3);
String askMsg4 = "我平时喜欢吃什么类型的菜?";
String response4 = assistant.chat(askMsg4);
System.out.println("Round 4 ASK: " + askMsg4);
System.out.println("Round 4 RESP: " + response4);我们做了两轮测试,看看AI是否记得我们是说话的话。
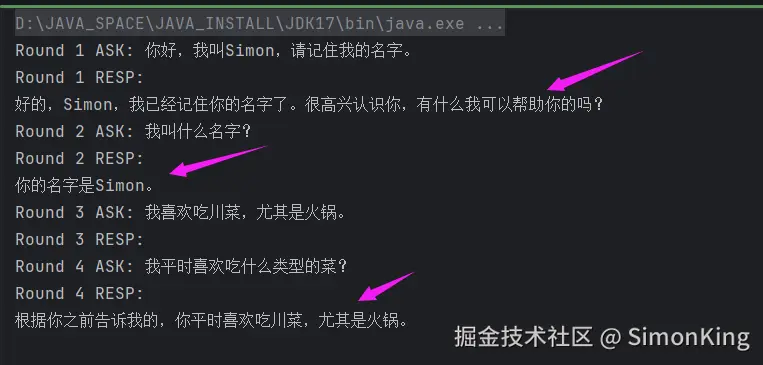
从结果可以看出,确实是记住之前的对话内容。
2.2 优化
案例的对话记忆默认是基于内存的。官方提供了扩展接口可以实现对话的定制化存储。
通过构建chatMemoryStore来实现多轮对话的存储。
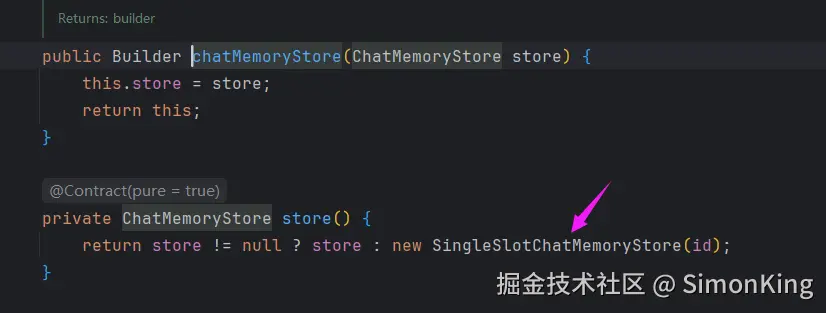
而扩展的关键类为dev.langchain4j.store.memory.chat.ChatMemoryStore
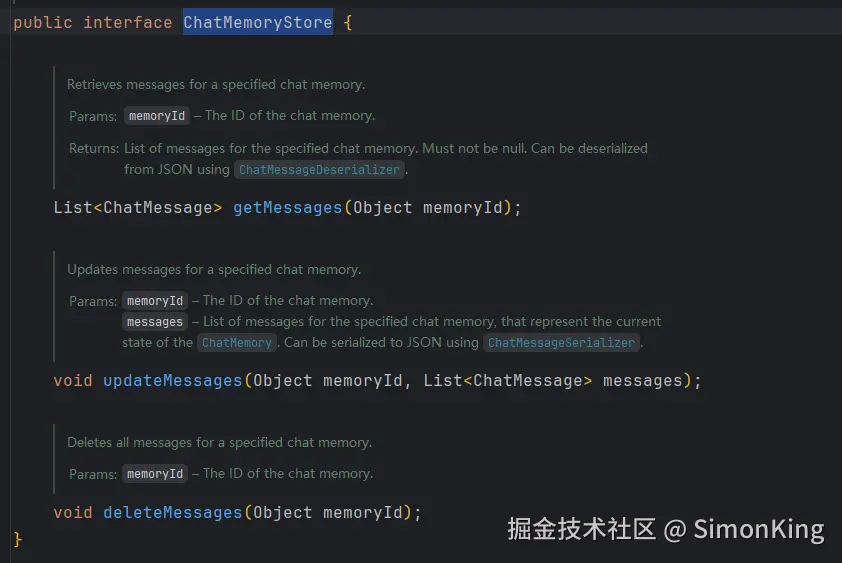
在我们的实际业务中,内存的存储自然是不可行的,我们需要将多轮对话持久化处理。
注意:
LangChain4j 区分"memory"和"history"。History 是原样保留所有对话记录;Memory 则是经过算法处理后呈现给 LLM 的内容,可能会摘要、丢弃或注入额外信息。两者概念不同,不要混淆。
03 RAG
让 AI 读懂你的私有数据。LLM 的知识受限于训练数据,RAG(Retrieval-Augmented Generation)让你把私有文档知识注入给 LLM,是目前最主流的落地模式。
其原理主要分为三个阶段:
- 索引阶段:文档解析 → 分块(chunking)→ 向量化 → 存入向量数据库
- 检索阶段:用户问题向量化 → 在向量库中找相似内容
- 生成阶段:将检索到的内容注入 Prompt → LLM 基于知识回答
3.1 Easy RAG
这是一个独立的RAG依赖,可以零门槛起步。
Maven依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>案例代码
java
OllamaChatModel chatModel = OllamaChatModel.builder()
.baseUrl("http://127.0.0.1:11434")
.modelName("modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest")
.build();
// 加载文档(自动识别格式,PDF/Word/HTML 都行)
List<Document> documents = FileSystemDocumentLoader.loadDocuments("C:\\Users\\ws\\Desktop\\test");
// 一行 ingestion,自动分块、向量化、存入内存向量库
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 对接 AI Service
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
String question = "编程朝花夕拾公众号是什么?";
String answer = assistant.chat(question);
System.out.println("提问: " + question);
System.out.println("回答: " + answer);代码说明
案例中通过主要分了三步:
- 加载文档
- 文档自动拆分,向量化
- 调用
其中文档加载是按照目录加载的,只需要给出文件目录。目录的文件的内容如下:
markdown
编程朝花夕拾专注编程技术分享,积累多年的开发经验,分享日常编程技巧、思想等,喜欢技术的朋友可以关注一下。测试结果

3.2 Advanced RAG
除了简单的上手工具外,还可以定制高级的RAG。这时需要向量化模型。
初始化模型
这里需要两个模型:
- 聊天模型:用来提问问题
- 向量化模型:将文档内容向量化
java
OllamaChatModel chatModel = OllamaChatModel.builder()
.baseUrl("http://127.0.0.1:11434")
.modelName("modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:latest")
.build();
// 使用 Ollama 的 embedding 模型
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("127.0.0.1:11434")
.modelName("modelscope.cn/Embedding-GGUF/nomic-embed-text-v1.5-GGUF:latest")
.build();文本分段
将文本内容分割成文本段
java
List<TextSegment> segments = Arrays.asList(
TextSegment.from("LangChain4j 是一个用于 Java 的 LLM 应用开发框架,提供了与 OpenAI、Ollama、HuggingFace 等模型的集成能力。"),
TextSegment.from("RAG(Retrieval-Augmented Generation)通过从外部知识库检索相关文档,将其作为上下文提供给 LLM,从而增强生成回答的准确性和时效性。"),
TextSegment.from("基础 RAG 通常包括文档加载、文本切分、向量化、相似度检索和答案生成五个步骤。"),
TextSegment.from("Advanced RAG 在基础 RAG 之上引入了多种优化技术,如查询扩展(Query Expansion)、假设文档嵌入(HyDE)、重排序(Re-ranking)、上下文压缩(Contextual Compression)和父文档检索器(Parent Document Retriever)。"),
TextSegment.from("Spring Boot 可以通过 starter 依赖方便地集成 LangChain4j,开发者只需定义接口和配置模型参数即可快速构建 AI 应用。")
);向量化
java
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
for (TextSegment segment : segments) {
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment);
}这里直接将文本向量化到内存里,也可以直接使用向量数据库。
HyDE 查询转换器
思路:不直接用用户问题去检索,而是先让 LLM 生成一个"假设的答案文档",再用这个假设文档去做 Embedding 检索,通常能召回更相关的文本。
java
QueryTransformer hydeTransformer = new QueryTransformer() {
@Override
public Collection<Query> transform(Query query) {
String hypotheticalDoc = chatModel.chat(
"请直接回答以下问题,只输出答案本身,不要任何解释:\n" + query.text()
);
System.out.println("[HyDE] 原始查询: " + query.text());
System.out.println("[HyDE] 假设文档: " + hypotheticalDoc);
return Arrays.asList(
query,
Query.from(hypotheticalDoc, query.metadata())
);
}
};组装 RetrievalAugmentor
java
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryTransformer(hydeTransformer)
.contentRetriever(EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
.minScore(0.5)
.build())
.build();创建Agent
java
Assistant assistant = AiServices.builder(Assistant.class)
.chatModel(chatModel)
.retrievalAugmentor(retrievalAugmentor)
.build();测试
JAVA
String question = "什么是 Advanced RAG?它和基础 RAG 有什么区别?";
System.out.println("提问: " + question);
String answer = assistant.chat(question);
System.out.println("回答: " + answer);04 小结
AI记忆和RAG是AI应用中不可或缺的两个功能,Langchain4j通过简单的配置和API呈现给Java程序员,Java程序员可以构建属于自己的Agent了。